
Makine Öğrenimi için Özellik Seçim Yöntemi Nasıl Seçilir
Yayınlanan: 2021-06-22İçindekiler
Özellik Seçimi Giriş
Bir makine öğrenimi modeli tarafından yalnızca birkaçının önemli olduğu pek çok özellik kullanılır. Bir veri modelini eğitmek için gereksiz özellikler kullanılırsa, modelin doğruluğu azalır. Ayrıca, modelin karmaşıklığında bir artış ve önyargılı bir modelle sonuçlanan Genelleme yeteneğinde bir azalma vardır. "Bazen daha azı daha iyidir" sözü, makine öğrenimi kavramıyla uyumludur. Sorun, verilerinden ilgili özellikler kümesini tanımlamayı zor buldukları ve tüm alakasız özellik kümelerini görmezden geldikleri birçok kullanıcı tarafından karşı karşıya kalmıştır. Daha az önemli özellikler, hedef değişkene katkıda bulunmadıkları için adlandırılır.
Bu nedenle makine öğrenmesinde önemli süreçlerden biri özellik seçimidir . Amaç, bir makine öğrenimi modelinin geliştirilmesi için mümkün olan en iyi özellik setini seçmektir. Özellik seçiminin modelin performansı üzerinde büyük bir etkisi vardır. Veri temizleme ile birlikte, özellik seçimi bir model tasarımında ilk adım olmalıdır.
Makine Öğreniminde özellik seçimi şu şekilde özetlenebilir:
- Tahmin değişkenine veya çıktıya en çok katkıda bulunan özelliklerin otomatik veya manuel seçimi.
- Alakasız özelliklerin varlığı, alakasız özelliklerden öğreneceği için modelin doğruluğunun azalmasına neden olabilir.
Özellik Seçiminin Faydaları
- Verilerin fazla takılmasını azaltır: Daha az sayıda veri, daha az fazlalık sağlar. Bu nedenle gürültü konusunda karar verme şansı daha azdır.
- Modelin doğruluğunu artırır: Daha az yanıltıcı veri olasılığı ile modelin doğruluğu artar.
- Eğitim süresi azalır: alakasız özelliklerin kaldırılması, yalnızca daha az veri noktası bulunduğundan algoritma karmaşıklığını azaltır. Bu nedenle, algoritmalar daha hızlı çalışır.
- Modelin karmaşıklığı, verilerin daha iyi yorumlanmasıyla azalır.
Denetimli ve Denetimsiz özellik seçimi yöntemleri
Özellik seçim algoritmalarının temel amacı , modelin geliştirilmesi için bir dizi en iyi özelliği seçmektir. Makine öğrenmesinde özellik seçme yöntemleri denetimli ve denetimsiz yöntemler olarak sınıflandırılabilir.
- Denetimli yöntem: Denetimli yöntem , etiketlenmiş verilerden özniteliklerin seçilmesi ve ilgili özniteliklerin sınıflandırılması için kullanılır. Bu nedenle, oluşturulan modellerin verimliliği artar.
- Denetimsiz yöntem : Bu özellik seçimi yöntemi, etiketlenmemiş veriler için kullanılır.
Denetimli Yöntemler Kapsamındaki Yöntemlerin Listesi
Makine öğreniminde denetimli özellik seçimi yöntemleri şu şekilde sınıflandırılabilir:

1. Sarıcı Yöntemler
Bu tür özellik seçim algoritması , algoritmanın sonuçlarına göre özelliklerin performans sürecini değerlendirir. Açgözlü algoritma olarak da bilinir, yinelemeli olarak bir özellik alt kümesini kullanarak algoritmayı eğitir. Durdurma kriterleri genellikle algoritmayı eğiten kişi tarafından tanımlanır. Modeldeki özelliklerin eklenmesi ve çıkarılması, modelin önceki eğitimine dayalı olarak gerçekleşir. Bu arama stratejisinde her türlü öğrenme algoritması uygulanabilir. Modeller, filtre yöntemlerine kıyasla daha doğrudur.
Wrapper yöntemlerinde kullanılan teknikler şunlardır:
- İleriye doğru seçim: İleriye doğru seçim süreci, her yinelemeden sonra modeli iyileştiren yeni özelliklerin eklendiği yinelemeli bir süreçtir. Boş bir dizi özellik ile başlar. Yineleme, modelin performansını daha da iyileştirmeyen bir özellik eklenene kadar devam eder ve durur.
- Geriye doğru seçim/eleme: Süreç, tüm özelliklerle başlayan yinelemeli bir süreçtir. Her yinelemeden sonra, en az anlamlı olan özellikler, ilk özellikler kümesinden çıkarılır. Yineleme için durdurma kriteri, özelliğin kaldırılmasıyla modelin performansının daha fazla gelişmediği zamandır. Bu algoritmalar mlxtend paketinde uygulanmaktadır.
- Çift Yönlü eleme : Tek bir çözüme ulaşmak için Çift Yönlü eleme yönteminde hem ileri seçim hem de geriye doğru eleme tekniği aynı anda uygulanır .
- Kapsamlı özellik seçimi: Özellik alt kümelerinin değerlendirilmesi için kaba kuvvet yaklaşımı olarak da bilinir. Bir dizi olası alt küme oluşturulur ve her alt küme için bir öğrenme algoritması oluşturulur. Bu alt küme, modeli en iyi performansı veren seçilir.
- Özyinelemeli Özellik eleme (RFE): Daha küçük ve daha küçük özellik kümesini yinelemeli olarak göz önünde bulundurarak öznitelikleri seçtiği için yöntem açgözlü olarak adlandırılır. Tahminciyi eğitmek için bir ilk özellik seti kullanılır ve bunların önemi, feature_importance_attribute kullanılarak elde edilir. Daha sonra, sadece gerekli sayıda özellik bırakarak en az önemli özelliklerin kaldırılmasıyla takip edilir. Algoritmalar, scikit-learn paketinde uygulanmaktadır.
Şekil 4: Özyinelemeli özellik eleme tekniğini gösteren bir kod örneği
2. Gömülü yöntemler
Makine öğrenimindeki gömülü özellik seçim yöntemleri, özellik etkileşimini dahil ederek ve ayrıca makul bir hesaplama maliyetini koruyarak filtre ve sarma yöntemlerine göre belirli bir avantaja sahiptir. Gömülü yöntemlerde kullanılan teknikler şunlardır:
- Düzenlileştirme: Modelin parametrelerine bir ceza eklenerek model tarafından verilerin fazla takılması önlenir. Katsayılar, bazı katsayıların sıfır olmasıyla sonuçlanan ceza ile eklenir. Bu nedenle, sıfır katsayısına sahip olan özellikler, özellik kümesinden çıkarılır. Özellik seçimi yaklaşımı, Kement (L1 düzenlileştirme) ve Elastik ağları (L1 ve L2 düzenlileştirme) kullanır.
- SMLR (Sparse Multinomial Logistic Regression): Algoritma, klasik çok uluslu lojistik regresyon için önceden ARD (Otomatik uygunluk belirleme) tarafından seyrek bir düzenleme uygular. Bu düzenlileştirme, her özelliğin önemini tahmin eder ve tahmin için yararlı olmayan boyutları budaır. Algoritmanın uygulaması SMLR'de yapılır.
- ARD (Otomatik Uygunluk Belirleme Regresyonu): Algoritma, katsayı ağırlıklarını sıfıra kaydırır ve Bayesian Ridge Regresyonunu temel alır. Algoritma scikit-learn'de uygulanabilir.
- Rastgele Orman Önemi: Bu özellik seçim algoritması , belirli sayıda ağacın toplanmasıdır. Bu algoritmadaki ağaç tabanlı stratejiler, bir düğümün safsızlığının arttırılması veya safsızlığın azaltılması (Gini safsızlığı) temelinde sıralanır. Ağaçların sonu, kirlilikte en az azalmaya sahip düğümlerden oluşur ve ağaçların başlangıcı, kirlilikte en büyük azalmaya sahip düğümlerden oluşur. Bu nedenle, belirli bir düğümün altındaki ağacın budanması yoluyla önemli özellikler seçilebilir.
3. Filtre yöntemleri
Yöntemler ön işleme adımları sırasında uygulanır. Yöntemler oldukça hızlı ve ucuzdur ve yinelenen, ilişkili ve gereksiz özelliklerin kaldırılmasında en iyi sonucu verir. Herhangi bir denetimli öğrenme yöntemi uygulamak yerine, özelliklerin önemi, onların doğal özelliklerine göre değerlendirilir. Algoritmanın hesaplama maliyeti, özellik seçiminin sarmalayıcı yöntemlerine kıyasla daha düşüktür. Ancak, özellikler arasındaki istatistiksel korelasyonu elde etmek için yeterli veri yoksa, sonuçlar sarmalayıcı yöntemlerden daha kötü olabilir. Bu nedenle, algoritmalar yüksek boyutlu veriler üzerinde kullanılır, bu da sarma yöntemleri uygulanacaksa daha yüksek bir hesaplama maliyetine yol açar.

Filtre yöntemlerinde kullanılan teknikler şunlardır :
- Bilgi Kazanımı : Bilgi kazancı, hedef değeri belirlemek için özelliklerden ne kadar bilgi kazanıldığını ifade eder. Daha sonra entropi değerlerindeki azalmayı ölçer. Her özniteliğin bilgi kazancı, öznitelik seçimi için hedef değerler dikkate alınarak hesaplanır.
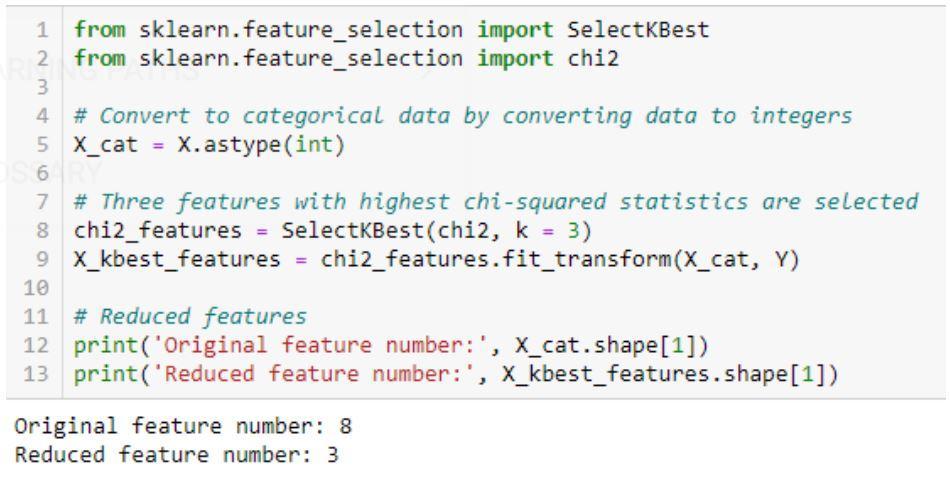
- Ki-kare testi : Ki-kare yöntemi (X 2 ) genellikle iki kategorik değişken arasındaki ilişkiyi test etmek için kullanılır. Test, veri setinin farklı özniteliklerinden beklenen değerine göre gözlemlenen değerler arasında anlamlı bir fark olup olmadığını belirlemek için kullanılır. Boş bir hipotez, iki değişken arasında bir ilişki olmadığını belirtir.
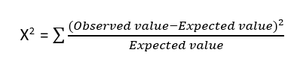
Kaynak
Ki-kare testi için formül
Ki-Kare algoritmasının uygulanması: sklearn, scipy
Ki-kare testi için bir kod örneği
Kaynak
- CFS (Korelasyona dayalı özellik seçimi): Yöntem şu şekildedir: " CFS'nin Uygulanması (Korelasyona dayalı özellik seçimi): scikit-özellik
Kariyerinizi hızlandırmak için Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zekada İleri Düzey Sertifika Programından çevrimiçi olarak AI ve ML Kurslarına katılın .
- FCBF (Hızlı korelasyona dayalı filtre): Yukarıda belirtilen Rölyef ve CFS yöntemleriyle karşılaştırıldığında, FCBF yöntemi daha hızlı ve daha verimlidir. Başlangıçta tüm özellikler için Simetrik Belirsizlik hesabı yapılır. Bu kriterler kullanılarak, özellikler sıralanır ve gereksiz özellikler kaldırılır.
Simetrik Belirsizlik= x'in bilgi kazancı | entropilerinin toplamına bölünür. FCBF'nin Uygulanması: sk özelliği
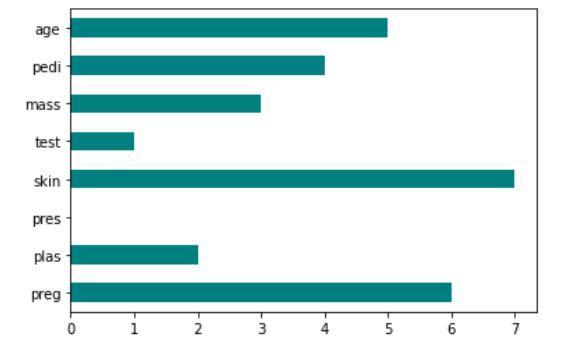
- Fischer puanı: Fischer oranı (FIR), özellik başına her sınıf için örnek ortalamalar arasındaki mesafenin, bunların varyanslarına bölünmesi olarak tanımlanır. Her özellik, Fisher kriteri altında aldıkları puanlara göre bağımsız olarak seçilir. Bu, optimal olmayan bir özellik kümesine yol açar. Daha büyük bir Fisher puanı, daha iyi seçilmiş bir özelliği gösterir.
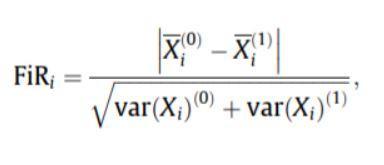
Kaynak
Fischer puanının formülü
Fisher puanının uygulanması: scikit özelliği
Fisher skor tekniğini gösteren kodun çıktısı
Kaynak
Pearson Korelasyon Katsayısı: İki sürekli değişken arasındaki ilişkiyi nicelleştirmenin bir ölçüsüdür. Korelasyon katsayısının değerleri, değişkenler arasındaki ilişkinin yönünü tanımlayan -1 ile 1 arasında değişmektedir.
- Varyans Eşiği: Varyansı belirli eşiği karşılamayan özellikler kaldırılır. Bu yöntemle sıfır varyansa sahip özellikler kaldırılır. Dikkate alınan varsayım, daha yüksek varyans özelliklerinin daha fazla bilgi içermesinin muhtemel olduğudur.
Şekil 15: Varyans eşiğinin uygulanmasını gösteren bir kod örneği
- Ortalama Mutlak Fark (MAD): Yöntem, ortalama mutlak değeri hesaplar.
ortalama değerden fark.
Ortalama Mutlak Farkın (MAD) uygulamasını gösteren bir kod örneği ve çıktısı
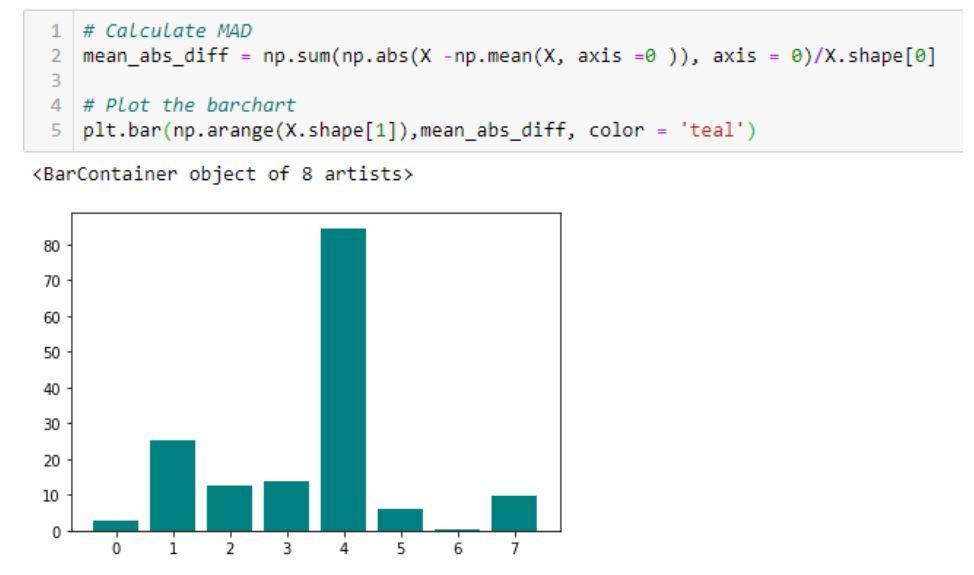
Kaynak
- Dağılım Oranı: Dağılım oranı, belirli bir özellik için Aritmetik ortalamanın (AM) Geometrik ortalamaya (GM) oranı olarak tanımlanır. Değeri, belirli bir özellik için AM ≥ GM olarak +1 ile ∞ arasında değişir.
Daha yüksek bir dağılım oranı, daha yüksek bir Ri değeri ve dolayısıyla daha alakalı bir özellik anlamına gelir. Tersine, Ri 1'e yakın olduğunda, düşük alaka düzeyi özelliğine işaret eder.
- Karşılıklı Bağımlılık: Yöntem, iki değişken arasındaki karşılıklı bağımlılığı ölçmek için kullanılır. Bir değişkenden elde edilen bilgiler, diğer değişken için bilgi elde etmek için kullanılabilir.
- Laplacian Skoru: Aynı sınıfa ait veriler genellikle birbirine yakındır. Bir özelliğin önemi, yerelliğini koruma gücü ile değerlendirilebilir. Her özellik için Laplace Puanı hesaplanır. En küçük değerler önemli boyutları belirler. Laplacian puanının uygulanması: scikit özelliği.
Çözüm
Makine öğrenimi sürecinde öznitelik seçimi, herhangi bir makine öğrenimi modelinin geliştirilmesine yönelik önemli adımlardan biri olarak özetlenebilir. Öznitelik seçme algoritmasının süreci, söz konusu modelle ilgili veya önemli olmayan özniteliklerin kaldırılmasıyla verilerin boyutluluğunda azalmaya yol açar. İlgili özellikler, modellerin eğitim süresini hızlandırarak yüksek performans sağlayabilir.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programına göz atın. -B Mezunu statüsü, 5'ten fazla pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
Filtre yönteminin sarma yönteminden farkı nedir?
Sarma yöntemi, özelliklerin sınıflandırıcı performansına dayalı olarak ne kadar yararlı olduğunu ölçmeye yardımcı olur. Öte yandan filtre yöntemi, çapraz doğrulama performansından ziyade tek değişkenli istatistikler kullanarak özniteliklerin içsel niteliklerini değerlendirir, bu da özniteliklerin uygunluğunu yargıladıklarını ima eder. Sonuç olarak, sınıflandırıcı performansını optimize ettiği için sarma yöntemi daha etkilidir. Bununla birlikte, tekrarlanan öğrenme süreçleri ve çapraz doğrulama nedeniyle sarma tekniği, filtreleme yönteminden hesaplama açısından daha pahalıdır.
Makine Öğreniminde Sıralı İleri Seçim Nedir?
Filtre seçiminden çok daha maliyetli olmasına rağmen, bir tür sıralı özellik seçimidir. İdeal özellik alt kümesini keşfetmek için sınıflandırıcı performansına dayalı olarak özellikleri yinelemeli olarak seçen açgözlü bir arama tekniğidir. Boş bir özellik alt kümesiyle başlar ve her turda bir özellik eklemeye devam eder. Bu özellik, özellik alt kümemizde olmayan tüm özelliklerin bulunduğu bir havuzdan seçilir ve diğerleriyle birleştirildiğinde en iyi sınıflandırıcı performansıyla sonuçlanan özelliktir.
Özellik seçimi için filtre yöntemini kullanmanın sınırlamaları nelerdir?
Filtre yaklaşımı, sarmalayıcı ve gömülü özellik seçim yöntemlerinden hesaplama açısından daha ucuzdur, ancak bazı dezavantajları vardır. Tek değişkenli yaklaşımlar söz konusu olduğunda, bu strateji, öznitelikleri seçerken sıklıkla özniteliklerin karşılıklı bağımlılığını göz ardı eder ve her bir özniteliği bağımsız olarak değerlendirir. Diğer iki özellik seçimi yöntemiyle karşılaştırıldığında, bu bazen düşük bilgi işlem performansına neden olabilir.