
Bir GraphQL Primer: API Tasarımının Evrimi (Bölüm 2)
Yayınlanan: 2022-03-10Bölüm 1'de API'lerin son birkaç on yılda nasıl geliştiğine ve her birinin bir sonrakine nasıl yol açtığına baktık. Ayrıca, mobil istemci geliştirme için REST kullanmanın bazı dezavantajlarından da bahsettik. Bu makalede, özellikle GraphQL'ye vurgu yaparak, mobil istemci API tasarımının nereye doğru gittiğine bakmak istiyorum.
Elbette, yıllar boyunca REST'lerin eksikliklerini gidermeye çalışan birçok kişi, şirket ve proje var: HAL, Swagger/OpenAPI, OData JSON API ve düzinelerce daha küçük veya dahili projenin tümü, REST'in düzenini sağlamaya çalıştı. REST'in özelliksiz dünyası. Dünyayı olduğu gibi alıp kademeli iyileştirmeler önermek veya REST'i ihtiyacım olan şeye dönüştürmek için yeterince farklı parçaları bir araya getirmeye çalışmak yerine, bir düşünce deneyi denemek istiyorum. Geçmişte işe yarayan ve yaramayan teknikleri anladığımızda, istediğimiz API'yi denemek ve çizmek için günümüzün kısıtlamalarını ve son derece daha anlamlı dillerimizi almak istiyorum. Uygulamadan ileriye değil, geliştirici deneyiminden geriye doğru çalışalım (size SQL bakıyorum).
Minimum HTTP Trafiği
Gecikme süresinden pil ömrüne kadar her (HTTP/1) ağ isteğinin maliyetinin yüksek olduğunu biliyoruz. İdeal olarak, yeni API'mizin müşterilerinin ihtiyaç duydukları tüm verileri mümkün olduğunca az gidiş-dönüşte istemenin bir yoluna ihtiyacı olacaktır.
Minimum Yükler
Ortalama bir müşterinin bant genişliği, CPU ve bellek açısından kısıtlı kaynaklara sahip olduğunu da biliyoruz, bu nedenle amacımız yalnızca müşterimizin ihtiyaç duyduğu bilgileri göndermek olmalıdır. Bunu yapmak için, muhtemelen müşterinin belirli veri parçalarını istemesi için bir yola ihtiyacımız olacak.
Okunabilir
Bir API ile etkileşim kurmanın kolay olmadığını SOAP günlerinden öğrendik, insanlar ondan bahsedince yüzünü buruşturacak. Mühendislik ekipleri, curl , wget ve Charles gibi yıllardır güvendiğimiz araçları ve tarayıcılarımızın ağ sekmesini kullanmak istiyor.
Zengin Takım
XML-RPC ve SOAP'tan öğrendiğimiz bir başka şey de, özellikle istemci/sunucu sözleşmelerinin ve tür sistemlerinin inanılmaz derecede faydalı olduğudur. Mümkünse, herhangi bir yeni API, daha yapılandırılmış ve tür güvenli sözleşmelerin iç gözlem yeteneği ile JSON veya YAML gibi bir formatın hafifliğine sahip olacaktır.
Yerel Akıl Yürütmenin Korunması
Yıllar geçtikçe, büyük kod tabanlarının nasıl organize edileceğine dair bazı yol gösterici ilkeler üzerinde anlaşmaya vardık - ana prensip “endişelerin ayrılması”. Ne yazık ki çoğu proje için bu, merkezi bir veri erişim katmanı şeklinde bozulma eğilimindedir. Mümkünse, bir uygulamanın farklı bölümleri, diğer işlevleriyle birlikte kendi veri ihtiyaçlarını yönetme seçeneğine sahip olmalıdır.
İstemci merkezli bir API tasarladığımız için, bunun gibi bir API'de veri getirmenin nasıl görünebileceği ile başlayalım. Hem minimum gidiş-dönüş yapmamız gerektiğini hem de istemediğimiz alanları filtreleyebilmemiz gerektiğini biliyorsak, hem büyük veri kümeleri arasında geçiş yapmanın hem de yalnızca verinin yalnızca ilgili kısımlarını talep etmenin bir yoluna ihtiyacımız var. bizim için yararlıdır. Bir sorgu dili buraya çok yakışacak gibi görünüyor.
Bir veritabanıyla yaptığınız gibi verilerimizle ilgili sorular sormamıza gerek yok, bu nedenle SQL gibi zorunlu bir dil yanlış araç gibi görünüyor. Aslında, birincil hedeflerimiz önceden var olan ilişkileri geçmek ve görece basit ve bildirimsel bir şeyle yapabilmemiz gereken alanları sınırlamaktır. Endüstri, ikili olmayan veriler için JSON'a oldukça iyi karar verdi, bu yüzden JSON benzeri bir bildirim sorgu dili ile başlayalım. İhtiyacımız olan verileri tanımlayabilmeliyiz ve sunucu bu alanları içeren JSON'u döndürmelidir.

Bildirime dayalı bir sorgu dili, hem minimum veri yükü hem de minimum HTTP trafiği gereksinimini karşılar, ancak tasarım hedeflerimizden birinde bize yardımcı olacak başka bir fayda daha vardır. Sorgu ve diğer birçok bildirim dili, veriymiş gibi verimli bir şekilde manipüle edilebilir. Dikkatli bir şekilde tasarlarsak, sorgu dilimiz geliştiricilerin büyük istekleri parçalara ayırmasına ve projelerine anlamlı gelen herhangi bir şekilde yeniden birleştirmesine olanak tanır. Bunun gibi bir sorgulama dili kullanmak, nihai hedefimiz olan Yerel Akıl Yürütmenin Korunması'na doğru ilerlememize yardımcı olacaktır.
Sorgularınız "veri" haline geldiğinde yapabileceğiniz pek çok heyecan verici şey var. Örneğin, tüm istekleri durdurabilir ve bunları bir Sanal DOM'nin DOM güncellemelerini toplulaştırmasına benzer şekilde gruplayabilirsiniz, ayrıca derleme sırasında küçük sorguları verileri önbelleğe almak için ayıklamak için bir derleyici kullanabilir veya karmaşık bir önbellek sistemi oluşturabilirsiniz. Apollo Cache gibi.
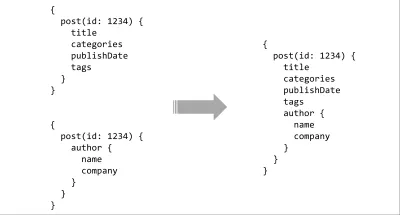
API istek listesindeki son öğe takımlardır. Bunun bir kısmını zaten bir sorgu dili kullanarak elde ediyoruz, ancak gerçek güç, onu bir tür sistemiyle eşleştirdiğinizde gelir. Sunucuda basit bir yazılı şema ile zengin araçlar için neredeyse sonsuz olasılık vardır. Sorgular statik olarak analiz edilebilir ve sözleşmeye göre doğrulanabilir, IDE entegrasyonları ipuçları veya otomatik tamamlama sağlayabilir, derleyiciler sorgular için derleme zamanı optimizasyonları yapabilir veya bitişik bir API yüzeyi oluşturmak için birden çok şema birleştirilebilir.

Bir sorgu dilini ve bir tür sistemini eşleştiren bir API tasarlamak kulağa dramatik bir teklif gibi gelebilir, ancak insanlar bunu çeşitli biçimlerde yıllardır deniyorlar. XML-RPC, 90'ların ortalarında yazılı yanıtlar için zorladı ve halefi SOAP, yıllarca egemen oldu! Daha yakın zamanlarda, Meteor'ın MongoDB soyutlaması, RethinkDB'nin (RIP) Horizon'u, Netflix'in yıllardır Netflix.com için kullandıkları muhteşem Falcor gibi şeyler var ve son olarak Facebook'un GraphQL'si var. Bu makalenin geri kalanında GraphQL'ye odaklanacağım çünkü Falcor gibi diğer projeler benzer şeyler yaparken, topluluk zihniyeti ezici bir çoğunlukla onu destekliyor gibi görünüyor.
GraphQL Nedir?
Öncelikle biraz yalan söylediğimi söylemeliyim. Yukarıda oluşturduğumuz API GraphQL idi. GraphQL, verileriniz için yalnızca bir tür sistemi, onu geçmek için bir sorgu dilidir - gerisi sadece ayrıntıdır. GraphQL'de verilerinizi bir ara bağlantı grafiği olarak tanımlarsınız ve müşteriniz özellikle ihtiyaç duyduğu verilerin alt kümesini ister. GraphQL'in sağladığı tüm inanılmaz şeyler hakkında çokça konuşulur ve yazılır, ancak temel kavramlar çok kolay yönetilebilir ve karmaşık değildir.
Bu kavramları daha somut hale getirmek ve GraphQL'in Bölüm 1'deki bazı sorunları nasıl çözmeye çalıştığını göstermeye yardımcı olmak için, bu yazının geri kalanında bu dizinin 1. Bölümündeki blogu güçlendirebilecek bir GraphQL API oluşturulacaktır. Koda geçmeden önce, GraphQL hakkında akılda tutulması gereken birkaç şey var.
GraphQL Bir Spesifikasyondur (Uygulama Değil)
GraphQL yalnızca bir özelliktir. Basit bir sorgu diliyle birlikte bir tür sistemi tanımlar ve bu kadar. Buradan çıkan ilk şey, GraphQL'nin hiçbir şekilde belirli bir dile bağlı olmamasıdır. Haskell'den C++'a kadar her şeyde JavaScript'in yalnızca bir tane olduğu iki düzineden fazla uygulama vardır. Spesifikasyonun açıklanmasından kısa bir süre sonra Facebook, JavaScript'te bir referans uygulaması yayınladı, ancak bunu dahili olarak kullanmadıkları için Go ve Clojure gibi dillerdeki uygulamalar daha da iyi veya daha hızlı olabilir.
GraphQL'nin Spesifikasyonu İstemcilerden veya Verilerden Bahsetmiyor
Spesifikasyonu okursanız, iki şeyin bariz bir şekilde eksik olduğunu fark edeceksiniz. İlk olarak, sorgu dilinin ötesinde, istemci entegrasyonlarından söz edilmez. Apollo, Relay, Loka ve benzerleri gibi araçlar GraphQL'nin tasarımı nedeniyle mümkündür, ancak hiçbir şekilde onun bir parçası veya kullanımı için gerekli değildir. İkincisi, belirli bir veri katmanından bahsedilmiyor. Aynı GraphQL sunucusu, heterojen bir dizi kaynaktan veri alabilir ve sıklıkla yapar. Redis'ten önbelleğe alınmış verileri talep edebilir, USPS API'sinden bir adres araması yapabilir ve protobuff tabanlı mikro hizmetleri çağırabilir ve müşteri farkı asla anlayamaz.
Karmaşıklığın Aşamalı Açıklaması
GraphQL, birçok insan için güç ve basitliğin ender bir kesişim noktasına ulaştı. Basit şeyleri basit ve zor şeyleri mümkün kılmak için harika bir iş çıkarıyor. HTTP üzerinden yazılan verileri çalıştıran ve sunan bir sunucu elde etmek, hayal edebileceğiniz herhangi bir dilde yalnızca birkaç satır kod olabilir.
Örneğin, bir GraphQL sunucusu mevcut bir REST API'sini sarabilir ve istemcileri, tıpkı diğer hizmetlerle etkileşim kuracağınız gibi, normal GET istekleriyle veri alabilir. Burada bir demo görebilirsiniz. Veya projenin daha karmaşık bir araç setine ihtiyacı varsa, alan düzeyinde kimlik doğrulama, yayın/alt abonelikler veya önceden derlenmiş/önbelleğe alınmış sorgular gibi şeyler yapmak için GraphQL kullanmak mümkündür.
Örnek Bir Uygulama
Bu örneğin amacı, kapsamlı bir öğretici yazmak değil, yaklaşık 70 satır JavaScript'te GraphQL'nin gücünü ve basitliğini göstermektir. Sözdizimi ve anlambilim hakkında çok fazla ayrıntıya girmeyeceğim, ancak buradaki tüm kodlar çalıştırılabilir ve makalenin sonunda projenin indirilebilir bir sürümüne bağlantı var. Bunu yaptıktan sonra biraz daha derine inmek isterseniz, blogumda daha büyük ve daha sağlam hizmetler oluşturmanıza yardımcı olacak bir kaynak koleksiyonum var.
Demo için JavaScript kullanacağım, ancak adımlar herhangi bir dilde çok benzer. Muhteşem Mocky.io'yu kullanarak bazı örnek verilerle başlayalım.
Yazarlar
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Gönderiler
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] İlk adım, express ve express-graphql ara katman yazılımı ile yeni bir proje oluşturmaktır.

bash npm init -y && npm install --save graphql express express-graphql Ve bir ekspres sunucu ile bir index.js dosyası oluşturmak için.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); GraphQL ile çalışmaya başlamak için verileri REST API'sinde modelleyerek başlayabiliriz. schema.js adlı yeni bir dosyaya aşağıdakileri ekleyin:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Yukarıdaki kod, API'mizin JSON yanıtlarındaki türleri GraphQL'in türlerine eşler. Bir GraphQLObjectType , bir JavaScript Object karşılık gelir, bir String , bir JavaScript GraphQLString karşılık gelir vb. Dikkat edilmesi gereken özel tür, son birkaç satırdaki GraphQLSchema . GraphQLSchema , bir GraphQL'nin kök düzeyinde dışa aktarımıdır - sorguların grafiği çaprazlamasına yönelik başlangıç noktası. Bu temel örnekte, yalnızca query tanımlıyoruz; mutasyonları (yazma) ve abonelikleri tanımlayacağınız yer burasıdır.
Daha sonra şemayı index.js dosyasındaki ekspres sunucumuza ekleyeceğiz. Bunu yapmak için express-graphql ara katman yazılımını ekleyeceğiz ve şemaya ileteceğiz.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Bu noktada, herhangi bir veri döndürmememize rağmen, şemasını istemcilere sağlayan çalışan bir GraphQL sunucumuz var. Uygulamayı başlatmayı kolaylaştırmak için package.json dosyasına bir başlatma komut dosyası da ekleyeceğiz.
"scripts": { "start": "nodemon index.js" }, Projeyi çalıştırmak ve https://localhost:5000/ adresine gitmek, GraphiQL adlı bir veri gezgini göstermelidir. HTTP Accept başlığı application/json olarak ayarlanmadığı sürece GraphiQL varsayılan olarak yüklenecektir. Bu aynı URL'yi application/json kullanarak fetch veya cURL ile çağırmak bir JSON sonucu döndürür. Yerleşik belgelerle oynamaktan ve bir sorgu yazmaktan çekinmeyin.

Sunucuyu tamamlamak için geriye kalan tek şey, alttaki verileri şemaya bağlamaktır. Bunu yapmak için, resolve işlevlerini tanımlamamız gerekir. GraphQL'de, ağaçtan geçerken bir resolve işlevi çağıran yukarıdan aşağıya bir sorgu çalıştırılır. Örneğin, aşağıdaki sorgu için:
query homepage { posts { title } } GraphQL önce posts.resolve(parentData) , ardından posts.title.resolve(parentData) . Blog gönderileri listemizde çözümleyiciyi tanımlayarak başlayalım.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Bir çözümleyiciden bir Sözün nasıl döndürüleceğini güzel bir şekilde gösterdiğinden, HTTP isteği yapmak için burada isomorphic-fetch paketini kullanıyorum, ancak istediğiniz herhangi bir şeyi kullanabilirsiniz. Bu işlev, Blog türüne bir dizi Gönderi döndürür. GraphQL'nin JavaScript uygulaması için varsayılan çözümleme işlevi parentData.<fieldName> . Örneğin, Yazarın adı alanı için varsayılan çözümleyici şöyle olacaktır:
rawAuthorObject => rawAuthorObject.nameBu tek geçersiz kılma çözümleyicisi, tüm gönderi nesnesi için veri sağlamalıdır. Hala Yazar için çözümleyiciyi tanımlamamız gerekiyor, ancak ana sayfa için gereken verileri getirmek için bir sorgu çalıştırırsanız, çalıştığını görmelisiniz.
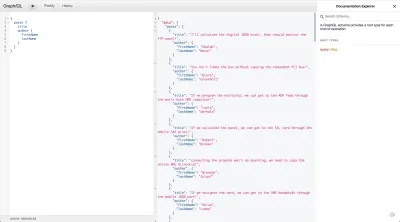
Yazılar API'mızdaki yazar özniteliği yalnızca yazar kimliği olduğundan, GraphQL adı ve şirketi tanımlayan bir Nesne aradığında ve bir Dize bulduğunda, yalnızca null değerini döndürür. Yazarı bağlamak için Post şemamızı aşağıdaki gibi görünecek şekilde değiştirmemiz gerekiyor:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Artık, bir REST API'sini saran tamamen çalışan bir GraphQL sunucumuz var. Tam kaynak bu Github bağlantısından indirilebilir veya bu GraphQL başlatma panelinden çalıştırılabilir.
Bunun gibi bir GraphQL uç noktasını kullanmak için kullanmanız gereken araçları merak ediyor olabilirsiniz. Relay ve Apollo gibi pek çok seçenek var ama başlangıç için basit yaklaşımın en iyisi olduğunu düşünüyorum. GraphiQL ile çok oynadıysanız, uzun bir URL'si olduğunu fark etmiş olabilirsiniz. Bu URL, sorgunuzun yalnızca URI ile kodlanmış bir sürümüdür. JavaScript'te bir GraphQL sorgusu oluşturmak için şöyle bir şey yapabilirsiniz:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Veya isterseniz, URL'yi doğrudan GraphiQL'den şu şekilde kopyalayıp yapıştırabilirsiniz:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageBir GraphQL uç noktamız ve onu kullanma yöntemimiz olduğundan, onu RESTish API'miz ile karşılaştırabiliriz. Verilerimizi RESTish API kullanarak almak için yazmamız gereken kod şöyle görünüyordu:
RESTish API Kullanmak
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };GraphQL API'sini Kullanma
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Özetle, GraphQL'yi şu amaçlarla kullandık:
- Dokuz isteği azaltın (gönderi listesi, dört blog gönderisi ve her gönderinin yazarı).
- Önemli bir yüzde ile gönderilen veri miktarını azaltın.
- Sorgularımızı oluşturmak için inanılmaz geliştirici araçlarını kullanın.
- İstemcimize çok daha temiz kod yazın.
GraphQL'deki Kusurlar
Hype'ın haklı olduğuna inansam da, gümüş kurşun yok ve GraphQL kadar büyük, hatasız değil.
Veri bütünlüğü
GraphQL bazen iyi veriler için özel olarak oluşturulmuş bir araç gibi görünür. Genellikle en iyi şekilde, farklı hizmetleri veya yüksek düzeyde normalleştirilmiş tabloları bir araya getiren bir tür ağ geçidi olarak çalışır. Kullandığınız hizmetlerden geri gelen veriler dağınık ve yapılandırılmamışsa, GraphQL'nin altına bir veri dönüştürme hattı eklemek gerçek bir zorluk olabilir. Bir GraphQL çözümleme işlevinin kapsamı, yalnızca kendisinin ve alt öğelerinin verileridir. Bir düzenleme görevinin ağaçtaki bir kardeş veya üst öğedeki verilere erişmesi gerekiyorsa, bu özellikle zor olabilir.
Karmaşık Hata İşleme
Bir GraphQL isteği, isteğe bağlı sayıda sorgu çalıştırabilir ve her sorgu, isteğe bağlı sayıda hizmete ulaşabilir. İsteğin herhangi bir kısmı başarısız olursa, isteğin tamamı yerine başarısız olursa, GraphQL varsayılan olarak kısmi verileri döndürür. Kısmi veriler teknik olarak muhtemelen doğru seçimdir ve inanılmaz derecede faydalı ve verimli olabilir. Dezavantajı, hata işlemenin artık HTTP durum kodunu kontrol etmek kadar basit olmamasıdır. Bu davranış kapatılabilir, ancak çoğu zaman istemciler daha karmaşık hata durumları ile sonuçlanır.
Önbelleğe almak
Statik GraphQL sorguları kullanmak genellikle iyi bir fikir olsa da, Github gibi rastgele sorgulara izin veren kuruluşlar için Varnish veya Fastly gibi standart araçlarla ağ önbelleğe alma artık mümkün olmayacaktır.
Yüksek CPU Maliyeti
Bir sorgunun ayrıştırılması, doğrulanması ve tür denetimi, JavaScript gibi tek iş parçacıklı dillerde performans sorunlarına yol açabilen CPU'ya bağlı bir işlemdir.
Bu, yalnızca çalışma zamanı sorgu değerlendirmesi için bir sorundur.
Kapanış Düşünceleri
GraphQL'in özellikleri bir devrim değil - bazıları yaklaşık 30 yıldır piyasada. GraphQL'i güçlü yapan şey, cila, entegrasyon ve kullanım kolaylığının onu parçalarının toplamından daha fazlasını yapmasıdır.
GraphQL'in başardığı şeylerin çoğu, çaba ve disiplinle, REST veya RPC kullanılarak başarılabilir, ancak GraphQL, bunu kendileri yapacak zamana, kaynağa veya araca sahip olmayan çok sayıda projeye son teknoloji API'ler getirir. GraphQL'nin gümüş bir kurşun olmadığı da doğrudur, ancak kusurları küçük ve iyi anlaşılır olma eğilimindedir. Oldukça karmaşık bir GraphQL sunucusu kurmuş biri olarak, faydalarının maliyetten daha ağır bastığını rahatlıkla söyleyebilirim.
Bu makale neredeyse tamamen GraphQL'in neden var olduğuna ve çözdüğü sorunlara odaklanmıştır. Bu, semantiği ve nasıl kullanılacağı hakkında daha fazla şey öğrenmeye ilginizi çektiyse, bloglar, youtube ya da sadece kaynak okumak (Nasıl Yapılır GraphQL özellikle iyidir) sizin için en iyi olanı öğrenmenizi tavsiye ederim.
Bu makaleyi beğendiyseniz (veya nefret ettiyseniz) ve bana geri bildirimde bulunmak istiyorsanız, lütfen beni Twitter'da @ebaerbaerbaer veya LinkedIn'de ericjbaer olarak bulun.