
Makine Öğreniminde Yalan Haber Tespiti [Kodlama Örneği ile Anlatıldı]
Yayınlanan: 2021-02-08Sahte haberler, internet ve sosyal medyanın içinde bulunduğumuz çağın en büyük sorunlarından biridir. Birkaç saat içinde dünyanın bir ucundan diğer ucuna haber akışı olması bir lütuf olsa da, birçok kişi ve grubun yalan haber yaydığını görmek de acı verici.
Doğal Dil İşleme ve Derin Öğrenme kullanan Makine Öğrenimi teknikleri, bu sorunu bir dereceye kadar çözmek için kullanılabilir. Bu eğitimde Makine Öğrenimi kullanarak bir Sahte Haber Algılama modeli oluşturacağız.
Bu makalenin sonunda, aşağıdakileri bileceksiniz:
- Metin verilerini işleme
- NLP işleme teknikleri
- Sayı vektörleştirme ve TF-IDF
- Tahmin yapmak ve haber metnini sınıflandırmak
Kariyerinizi hızlandırmak için Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zeka alanında İleri Düzey Sertifika Programından çevrimiçi olarak AI ve ML kursuna katılın .
İçindekiler
Veri ve Sorun
Bir sınıflandırıcı yapmak için Kaggle Sahte Haber meydan okuma verilerini kullanacağız. Veri seti 4 özellik ve 1 ikili hedeften oluşmaktadır. 4 özellik aşağıdaki gibidir:
- id : bir haber makalesi için benzersiz kimlik
- başlık : bir haber makalesinin başlığı
- yazar : haber makalesinin yazarı
- metin : makalenin metni; eksik olabilir
Hedef ise 0s ve 1s ikili değerlerini içeren “etiket”tir. 0, güvenilir bir haber kaynağı veya başka bir deyişle Sahte Değil anlamına gelir. 1, potansiyel olarak sahte bir haber olduğu ve güvenilir olmadığı anlamına gelir. Sahip olduğumuz veri seti 20800 örnekten oluşuyor. Hemen dalalım.

Veri Ön İşleme ve Temizleme
| pandaları pd olarak içe aktar df=pd.read_csv( 'sahte haberler/train.csv' ) df.head() |
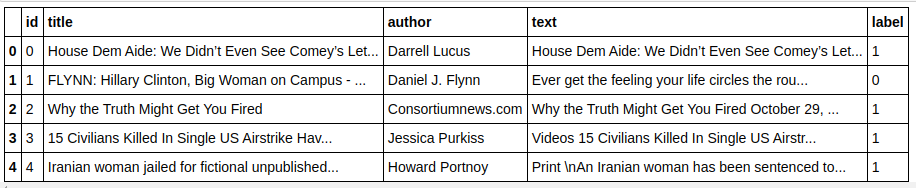
| X=df.drop( 'etiket' ,axis= 1 ) # Özellikler y=df[ 'etiket' ] # Hedef |
Verileri eksik olan örnekleri şimdi bırakmamız gerekiyor.
| df=df.dropna() |
![]()
Gördüğümüz gibi, tüm örnekleri eksik verilerle düşürdü.
| mesajlar=df.kopya() message.reset_index(inplace= True ) mesajlar.kafa( 10 ) |
Verilere bir kez bakalım.
| mesajlar['metin'][6] |

Gördüğümüz gibi, aşağıdaki adımların yapılması gerekiyor:
- Durdurulan kelimeleri kaldırmak: Veriler ne olursa olsun herhangi bir metne değer katmayan birçok kelime vardır. Örneğin, "I", "a", "am" vb. Bu kelimelerin bilgi değeri yoktur ve bu nedenle, yalnızca gerçek değeri olan kelimelere/belirteçlere odaklanabilmemiz için derlemimizin boyutunu küçültmek için kaldırılabilir. .
- Kelimeleri köklendirme : Köklendirme ve Lemmatizasyon, kelimeleri köklerine veya köklerine indirgeme teknikleridir. Bu adımın ana avantajı, kelime dağarcığının boyutunu azaltmaktır. Örneğin Play, Playing, Played gibi kelimeler “Oynat”a indirgenecektir. Stemming, kelimeleri en kısa kelimeye kadar kısaltır ve metnin dilbilgisel yönünü dikkate almaz. Lemmatization ise dilbilgisini de dikkate alır ve bu nedenle çok daha iyi sonuçlar verir. Bununla birlikte, sözlüğe başvurması ve dilbilgisel yönü dikkate alması gerektiğinden, Lemmatization genellikle kökten daha yavaştır.
- Alfabetik değerler dışındaki her şeyi kaldırma: Alfabetik olmayan değerler burada pek kullanışlı olmadığı için kaldırılabilir. Bununla birlikte, sayısal veya diğer veri türlerinin varlığının hedef üzerinde herhangi bir etkisi olup olmadığını görmek için daha fazla keşfedebilirsiniz.
- Kelimeleri küçük harf: Kelime dağarcığını azaltmak için kelimeleri küçük harf yapın.
- Cümleleri tokenize edin: Cümlelerden jeton oluşturma.
| sklearn.feature_extraksiyon.text'ten CountVectorizer, TfidfVectorizer, HashingVectorizer içe aktarın nltk.corpus'tan stopwords içe aktarma nltk.stem.porter'dan PorterStemmer'i içe aktarın yeniden içe aktar ps = PorterStemmer() corpus = [] i in range(0, len(messages)) için: inceleme = re.sub('[^a-zA-Z]', ' ', mesajlar['metin'][i]) gözden geçirme = gözden geçirme.alt() gözden geçirme = gözden geçirme.split() inceleme = [ps.stem(word) kelimesi kelimesine incelemede, eğer stopwords.words('english')'de kelime değilse] inceleme = ' '.join(inceleme) corpus.append(inceleme) |
Şimdi korpusumuza bir göz atalım.
| korpus[ 3 ] |
![]()
Gördüğümüz gibi, kelimeler artık kök kelimelere dayanıyor.
TF-IDF Vektörleştirici
Şimdi kelimeleri vektörleştirme olarak da adlandırılan sayısal verilere vektörleştirmemiz gerekiyor. Vektörleştirmenin en kolay yolu Kelime Torbasını kullanmaktır. Ancak Kelime Torbası seyrek bir matris oluşturur ve bu nedenle çok fazla işlem belleği gerekir. Ayrıca, BoW, onu kötü bir algoritma yapan kelimelerin sıklığını dikkate almaz.
TF-IDF (Terim Frekansı – Ters Belge Frekansı), kelime frekanslarını dikkate alan kelimeleri vektörleştirmenin başka bir yoludur. Örneğin, “biz”, “bizim”, “the” gibi yaygın kelimeler her belgede/örnekte bulunur, dolayısıyla BoW değeri çok yüksek ve dolayısıyla yanıltıcı olacaktır. Bu kötü bir modele yol açacaktır. TF-IDF, Terim Frekansı ile Ters Belge Frekansının çarpımıdır.
Terim Sıklığı, bir belgedeki kelimelerin sıklığını dikkate alır ve Ters Belge Sıklığı, tüm tümcede bulunan kelimeleri hesaba katar. IDF değeri çok daha düşük olduğu için tüm derlemde bulunan kelimelerin önemi azalmıştır. Tek bir belgede özel olarak bulunan kelimelerin, toplam TF-IDF değerini yüksek yapan yüksek bir IDF değerine sahip olması.
| ## TFi df Vektörleştirici sklearn.feature_extraction.text dosyasından TfidfVectorizer içe aktarın tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=mesajlar[ 'etiket' ] |
Yukarıdaki kodda, Sklearn'in özellik çıkarma modülünden TF-IDF Vectorizer'ı içe aktarıyoruz. max_features'ı 5000 ve ngram_range'ı (1,3) olarak geçirerek nesnesini yapıyoruz. max_features parametresi, oluşturmak istediğimiz maksimum özellik vektörü sayısını tanımlar ve ngram_range parametresi, dahil etmek istediğimiz ngram kombinasyonlarını tanımlar. Bizim durumumuzda 1 kelime, 2 kelime ve 3 kelimeden oluşan 3 kombinasyon elde edeceğiz. Oluşturulan bazı özelliklere bir göz atalım.

| tfidf_v.get_feature_names()[: 20 ] |

Gördüğümüz gibi, oluşturulan birden çok kombinasyon türü vardır. 1 jetonlu, 2 jetonlu ve ayrıca 3 jetonlu özellik isimleri vardır.
Veri Çerçevesi Yapmak
| ## Veri kümesini Eğit ve Test Et'e bölün sklearn.model_selection'dan train_test_split'i içe aktarın X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, column=tfidf_v.get_feature_names()) say_df.head() |
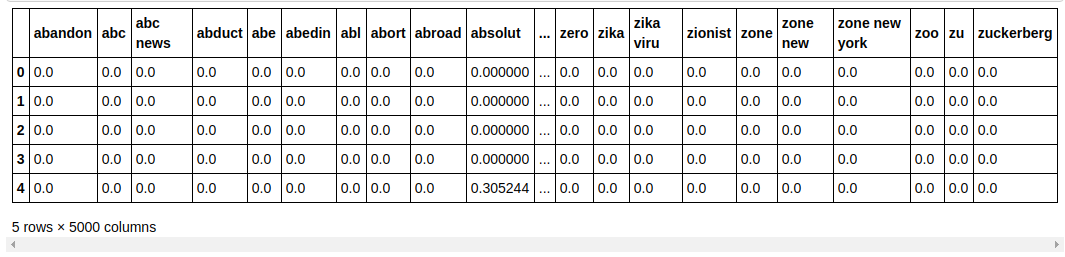
Modelin performansını görünmeyen veriler üzerinde test edebilmemiz için veri setini tren ve test olarak ayırdık. Ardından, içinde yeni özellik vektörlerini içeren yeni bir Veri Çerçevesi oluşturuyoruz.
Modelleme ve Ayarlama
Çok terimliNB Algoritması
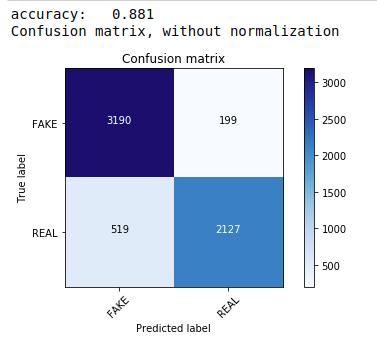
İlk olarak, metin veri sınıflandırması için tercih edilen en yaygın ve en kolay algoritma olan Multinomial Naive Bayes teoremini kullanıyoruz. Eğitim verilerine uyuyoruz ve test verilerini tahmin ediyoruz. Daha sonra karışıklık matrisini hesaplayıp çiziyoruz ve %88.1 doğruluk elde ediyoruz.
| sklearn.naive_bayes'den MultinomialNB'yi içe aktarın sklearn içe aktarma metriklerinden numpy'yi np olarak içe aktar itertools'u içe aktar sklearn.metrics'den plot_confusion_matrix'i içe aktarın sınıflandırıcı=Çok terimliNB() classifier.fit(X_tren, y_tren) pred = classifier.predict(X_test) puan = metrics.accuracy_score(y_test, tahmin) print( “doğruluk: %0.3f” % puan) cm = metrics.confusion_matrix(y_test, tahmin) plot_confusion_matrix(cm, sınıflar=[ 'SAHTE' , 'GERÇEK' ]) |
Hiperparametre Ayarlı Çok Terimli Sınıflandırıcı
MultinomialNB, daha fazla ayarlanabilen bir alfa parametresine sahiptir. Bu nedenle, farklı alfa değerlerine sahip çoklu MultinomialNB sınıflandırıcılarını denemek ve doğruluk puanlarını kontrol etmek için bir döngü çalıştırıyoruz. Ve mevcut puanın önceki puandan fazla olup olmadığını kontrol ediyoruz. Eğer öyleyse, o zaman sınıflandırıcıyı mevcut sınıf olarak ayarladık.
| önceki_score= 0 np.arange( 0 , 1 , 0.1 ) içindeki alfa için : sub_classifier=Çok terimliNB(alfa=alfa) sub_classifier.fit(X_tren,y_tren) y_pred=sub_classifier.predict(X_test) puan = metrics.accuracy_score(y_test, y_pred) eğer skor>önceki_skor: sınıflandırıcı=alt_sınıflandırıcı print( “Alfa: {}, Puan : {}” .format(alfa, puan)) |
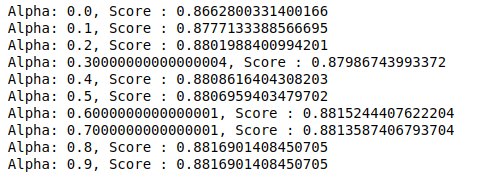
Dolayısıyla, 0,9 veya 0,8'lik bir alfa değerinin en yüksek doğruluk puanını verdiğini görebiliriz.
Sonuçların Yorumlanması
Şimdi bu sınıflandırıcı katsayı değerlerinin ne anlama geldiğini görelim. İlk önce tüm özellik adlarını başka bir değişkene kaydedeceğiz.
| ## Özelliklerin adlarını al feature_names = cv.get_feature_names() |
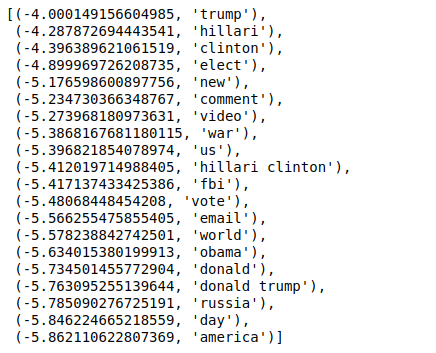
Şimdi değerleri ters sırada sıraladığımızda minimum değeri -4 olan değerler alıyoruz. Bunlar, en gerçek veya en az sahte olan kelimeleri belirtir.
| ### Çoğu gerçek sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
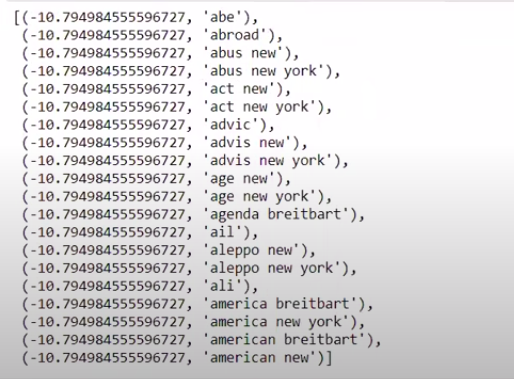
Değerleri ters sırada sıraladığımızda minimum değeri -10 olan değerler elde ederiz. Bunlar, en az gerçek veya en sahte olan kelimeleri belirtir.
| ### Çoğu gerçek sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Çözüm
Bu öğreticide yalnızca makine öğrenimi algoritmalarını kullandık, ancak siz diğer sinir ağları yöntemlerini de kullanıyorsunuz. Ayrıca, metin verilerini vektörleştirmek için TF-IDF vektörleştiricisini kullandık. Count Vectorizer, Hashing Vectorizer, vb. gibi işi yaparken daha iyi olabilecek daha fazla vektörleyici var. Daha iyi sonuçlar üretip üretemeyeceğinizi görmek için diğer algoritmaları ve teknikleri deneyin ve deneyin.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programına göz atın. -B Mezunu statüsü, 5'ten fazla pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
Sahte haberleri tespit etmeye neden ihtiyaç var?
Sosyal medya platformları şu anki durumlarında, kullanıcılarına demokrasi, eğitim, sağlık gibi konularda tartışma ve fikir alışverişi yapma imkanı verdiği için son derece güçlü ve değerlidir. Bununla birlikte, bazı kuruluşlar bu tür platformları bazı durumlarda parasal kazanç sağlamak ve bazı durumlarda önyargılı bakış açıları üretmek, zihniyetleri değiştirmek ve diğerlerinde hiciv veya gülünçlük yaymak için kötü bir şekilde kullanmaktadır. Sahte haberler bu fenomen için kullanılan terimdir. Gerçeğe uymayan çevrimiçi öğelerin yayınlanmasının artması, siyaset, spor, sağlık, bilim ve diğer alanlarda bir dizi sorunla sonuçlandı.
Hangi şirketler asıl olarak sahte haber tespitini kullanıyor?
Sahte haber tespiti, sosyal medya ve haber siteleri gibi platformlarda kullanılmaktadır. Facebook, Instagram ve Twitter gibi sosyal medya devleri, kullanıcılarının çoğu en güncel bilgileri almak için günlük haber kaynakları olarak onlara güvendiği için sahte haberlere karşı savunmasızdır. Sahte tespit teknikleri, medya şirketleri tarafından da sahip oldukları bilgilerin gerçekliğini belirlemek için kullanılmaktadır. E-posta, bireylerin haber alabilecekleri başka bir ortamdır ve bu da onların doğruluğunu tespit etmeyi ve doğrulamayı zorlaştırır. Aldatmacalar, istenmeyen e-postalar ve önemsiz postalar, e-posta üzerinden iletilmeleriyle ünlüdür. Sonuç olarak, e-posta platformlarının çoğu, istenmeyen postaları ve önemsiz postaları belirlemek için yanlış haber tespiti kullanır.