
Python'da Keşifsel Veri Analizi: Bilmeniz Gerekenler?
Yayınlanan: 2021-03-12Keşifsel Veri Analizi (EDA), tüm veri bilimcileri tarafından takip edilen çok yaygın ve önemli bir uygulamadır. Verileri tam olarak anlamak için tablo ve tablolara farklı açılardan bakma işlemidir. Verileri iyi anlamak, verileri temizlememize ve özetlememize yardımcı olur, bu da aksi halde belirsiz olan içgörüleri ve eğilimleri ortaya çıkarır.
EDA'nın, örneğin 'veri analizi'nde olduğu gibi uyulması gereken katı kurallar dizisi yoktur. Alanda yeni olan insanlar, çoğunlukla benzer ancak amaçları farklı olan iki terim arasında her zaman kafa karıştırmaya meyillidir. EDA'dan farklı olarak, veri analizi, farklı değişkenler arasındaki gerçekleri ve ilişkileri ortaya çıkarmak için olasılıkların ve istatistiksel yöntemlerin uygulanmasına daha yatkındır.
Geri dönersek, EDA'yı gerçekleştirmenin doğru ya da yanlış bir yolu yoktur. Kişiden kişiye değişir, ancak aşağıda listelenen genel olarak izlenen bazı ana yönergeler vardır.
- Eksik değerlerin ele alınması: Toplama sırasında tüm veriler mevcut olmadığında veya kaydedilmediğinde boş değerler görülebilir.
- Yinelenen verileri kaldırma: Tekrarlanan veri kayıtlarını kullanarak makine öğrenimi algoritmasının eğitimi sırasında oluşturulan herhangi bir fazla uydurmayı veya önyargıyı önlemek önemlidir.
- Aykırı değerlerin işlenmesi: Aykırı değerler, verilerin geri kalanından önemli ölçüde farklı olan ve trendi takip etmeyen kayıtlardır. Veri toplama sırasında belirli istisnalar veya yanlışlıklar nedeniyle ortaya çıkabilir.
- Ölçekleme ve normalleştirme: Bu yalnızca sayısal veri değişkenleri için yapılır. Çoğu zaman değişkenler, aralıkları ve ölçekleri bakımından büyük ölçüde farklılık gösterir ve bu da onları karşılaştırmayı ve korelasyonları bulmayı zorlaştırır.
- Tek Değişkenli ve İki Değişkenli Analiz: Tek değişkenli analiz genellikle bir değişkenin hedef değişkeni nasıl etkilediğini görerek yapılır. İki değişkenli analiz herhangi 2 değişken arasında gerçekleştirilir, sayısal veya kategorik veya her ikisi de olabilir.
Kaggle'da bulunan çok ünlü 'Ev Kredisi Temerrüt Riski' veri setini kullanarak bunlardan bazılarının nasıl uygulandığına bakacağız . Veriler, kredi başvurusu sırasında kredi başvurusunda bulunan kişi hakkında bilgi içerir. İki tür senaryo içerir:
- Ödeme güçlüğü çeken müşteri : X günden fazla gecikmeli ödemesi oldu
Örneğimizdeki kredinin ilk Y taksitlerinden en az birinde,
- Diğer tüm durumlar : Ödemenin zamanında ödendiği diğer tüm durumlar.
Bu makalenin hatırına sadece uygulama veri dosyaları üzerinde çalışacağız.
İlgili: Yeni Başlayanlar için Python Proje Fikirleri ve Konuları
İçindekiler
Verilere Bakmak
app_data = pd.read_csv('application_data.csv' )
app_data.info()
Uygulama verilerini okuduktan sonra, ilgileneceğimiz verilere kısa bir genel bakış elde etmek için info() işlevini kullanırız. Aşağıdaki çıktı bize 122 değişkenli yaklaşık 300000 kredi kaydımız olduğunu bildiriyor. Bunların dışında 16 kategorik değişken ve geri kalanı sayısaldır.
<sınıf 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 giriş, 0 - 307510
Sütunlar: 122 giriş, SK_ID_CURR - AMT_REQ_CREDIT_BUREAU_YEAR
türler: float64(65), int64(41), nesne(16)
bellek kullanımı: 286.2+ MB
Sayısal ve kategorik verileri ayrı ayrı ele almak ve analiz etmek her zaman iyi bir uygulamadır.
kategorik = app_data.select_dtypes(include = nesne).sütunlar
app_data[kategorik].apply(pd.Series.nunique, eksen = 0)
Yalnızca aşağıdaki kategorik özelliklere baktığımızda, çoğunun basit grafikler kullanarak analiz etmeyi kolaylaştıran yalnızca birkaç kategoriye sahip olduğunu görüyoruz.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAREMONT_MODE 4
HOUSETYPE_MODE 3
DUVAR MALZEME_MOD 7
ACİL DURUM_MOD 2
tür: int64
Şimdi sayısal özellikler için, tarif() yöntemi bize verilerimizin istatistiklerini verir:
sayı= app_data.describe()
sayısal= sayı.sütunlar
sayı
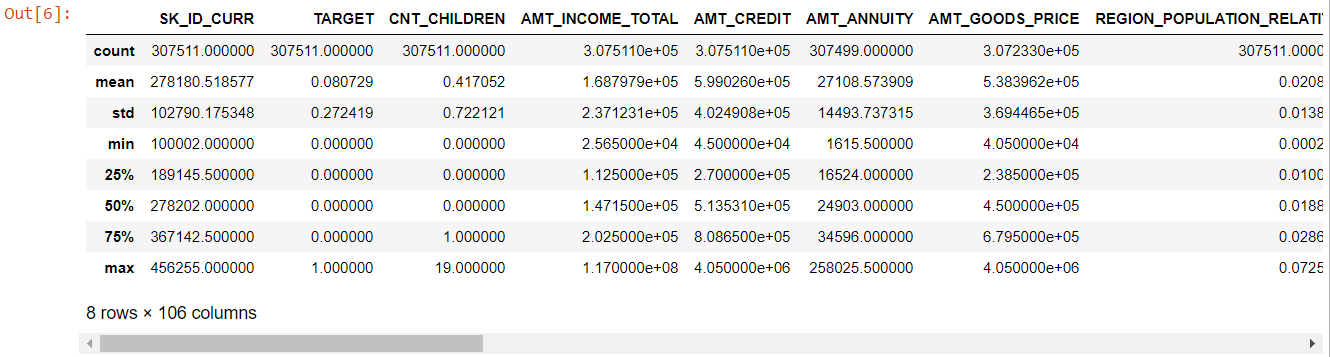
Tablonun tamamına bakıldığında açıkça görülüyor ki:
- day_birth negatiftir: başvuru gününe göre başvuru sahibinin yaşı (gün olarak)
- days_employed aykırı değerlere sahip (maksimum değer yaklaşık 100 yıldır) (635243)
- amt_annuity- maksimum değerden çok daha küçük anlamına gelir
Artık hangi özelliklerin daha fazla analiz edilmesi gerektiğini biliyoruz.
Kayıp veri
Eksik verilerin yüzdesini Y ekseni boyunca çizerek, eksik değerlere sahip tüm özelliklerin bir nokta grafiğini yapabiliriz.
eksik = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.şekil(şekil = (16,5))
ax = sns.pointplot('index', 0, veri = eksik)

plt.xticks(döndürme = 90, yazı tipi boyutu = 7)
plt.title(“Eksik Değerlerin Yüzdesi”)
plt.ylabel(“YÜZDE”)
plt.göster()
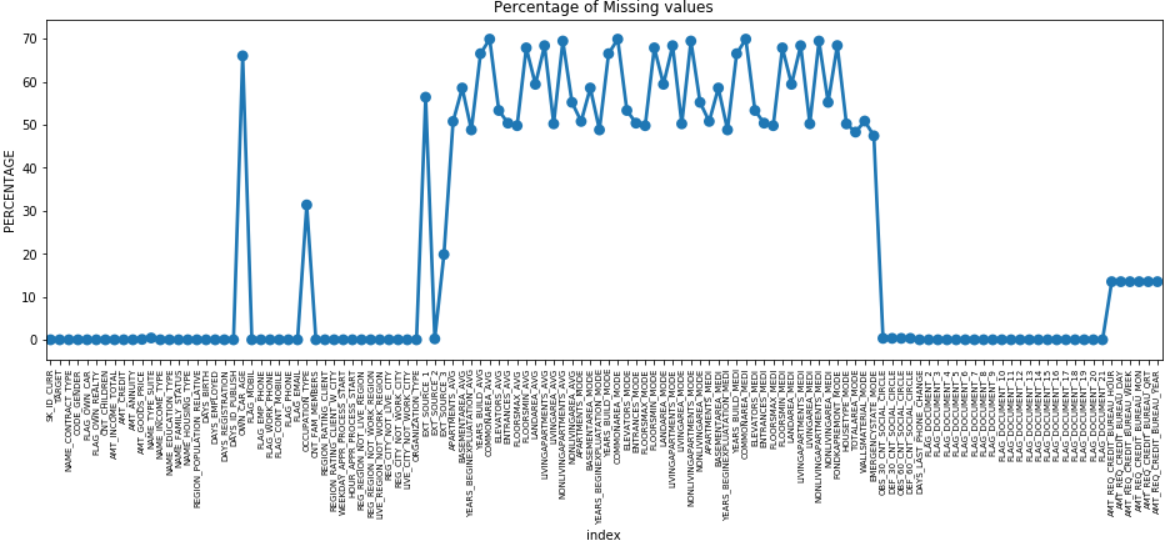
Birçok sütunda çok fazla eksik veri var (%30-70), bazılarında çok az veri var (%13-19) ve birçok sütunda hiç eksik veri yok. Sadece EDA yapmanız gerektiğinde veri setini değiştirmeniz gerçekten gerekli değildir. Ancak, veri ön işleme ile devam ederken, eksik değerlerin nasıl ele alınacağını bilmeliyiz.
Daha az eksik değere sahip özellikler için, özelliğe bağlı olarak eksik değerleri tahmin etmek veya mevcut değerlerin ortalamasını doldurmak için regresyon kullanabiliriz. Ve çok yüksek sayıda eksik değere sahip özellikler için, analiz hakkında çok daha az içgörü sağladıkları için bu sütunları bırakmak daha iyidir.
Veri Dengesizliği
Bu veri setinde, kredi temerrüde düşenler 'TARGET' ikili değişkeni kullanılarak tanımlanır.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
İsim: TARGET, dtype: float64
Verilerin 92:8 oranında oldukça dengesiz olduğunu görüyoruz. Kredilerin çoğu zamanında geri ödenmiştir (hedef = 0). Bu nedenle, bu kadar büyük bir dengesizlik olduğunda, bu özelliklerdeki hangi kategorilerin kredilerde diğerlerinden daha fazla temerrüde düşme eğiliminde olduğunu belirlemek için özellikleri almak ve bunları hedef değişkenle (hedeflenen analiz) karşılaştırmak daha iyidir.
Aşağıda, seaborn python kitaplığı ve basit kullanıcı tanımlı işlevler kullanılarak yapılabilecek birkaç grafik örneği verilmiştir .
Cinsiyet
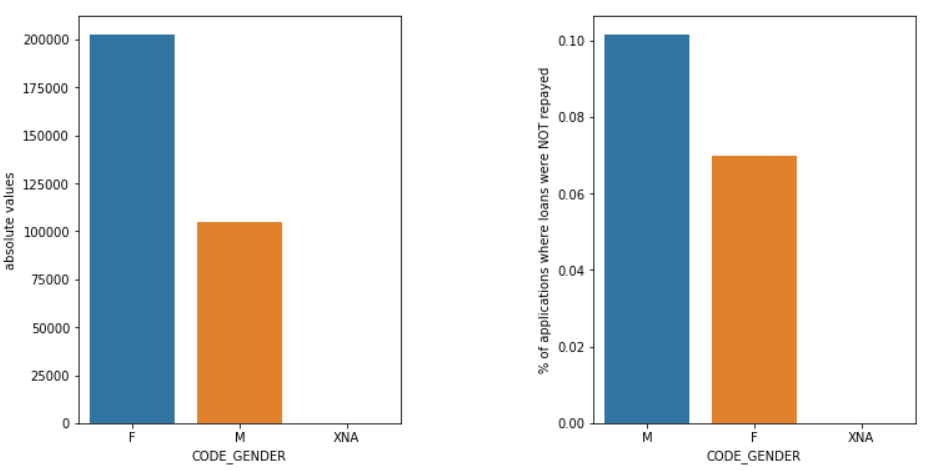
Kadın başvuranların sayısı neredeyse iki kat daha fazla olmasına rağmen, erkeklerin (E) kadınlara (K) kıyasla temerrüde düşme şansları daha yüksektir. Dolayısıyla kadınlar kredilerini geri ödeme konusunda erkeklerden daha güvenilirdir.
Eğitim Türü
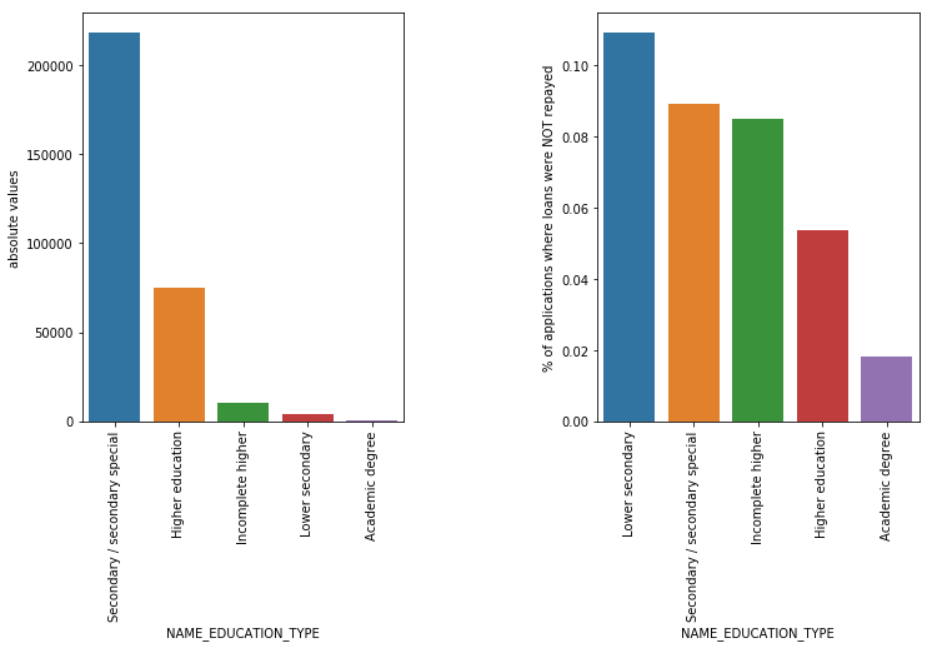
Öğrenci kredilerinin çoğu orta öğretim veya yüksek öğrenim için olsa da, şirket için en riskli olan alt orta öğretim kredileridir ve bunu ortaöğretim izlemektedir.
Ayrıca Okuyun: Veri Biliminde Kariyer
Çözüm
Yukarıda görülen bu tür bir analiz, büyük ölçüde bankacılık ve finansal hizmetlerde risk analitiğinde yapılır. Bu şekilde, müşterilere borç verirken para kaybetme riskini en aza indirmek için veri arşivleri kullanılabilir. EDA'nın diğer tüm sektörlerde kapsamı sonsuzdur ve yaygın olarak kullanılmalıdır.
Veri bilimi hakkında bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için oluşturulan ve 10'dan fazla vaka çalışması ve proje, uygulamalı uygulamalı atölye çalışmaları, endüstri uzmanlarıyla mentorluk sunan Veri Biliminde Yönetici PG'sine göz atın, 1- endüstri danışmanlarıyla bire bir, en iyi firmalarla 400+ saat öğrenim ve iş yardımı.
Keşifsel Veri Analizi, verilerinizi modellemeye başladığınızda başlangıç seviyesi olarak kabul edilir. Bu, verilerinizi modellemek için en iyi uygulamaları analiz etmek için oldukça anlayışlı bir tekniktir. Tam olarak anlamak için verilerden görsel grafikler, grafikler ve raporlar çıkarabileceksiniz. Aykırı değerler, verilerinizdeki anormalliklere veya küçük farklılıklara atıfta bulunur. Veri toplama sırasında olabilir. Veri setinde bir aykırı değeri tespit etmenin 4 yolu vardır. Bu yöntemler aşağıdaki gibidir: Veri analizinden farklı olarak, EDA için uyulması gereken katı ve hızlı kurallar ve düzenlemeler yoktur. EDA yapmak için bunun doğru yöntem ya da yanlış yöntem olduğu söylenemez. Yeni başlayanlar genellikle yanlış anlaşılır ve EDA ile veri analizi arasında kafa karıştırır.Keşifsel Veri Analizi (EDA) neden gereklidir?
EDA, istatistiksel sonuçların türetilmesi, eksik veri değerlerinin bulunması, hatalı veri girişlerinin ele alınması ve son olarak çeşitli çizimler ve grafikler çıkarılması dahil olmak üzere verileri tamamen analiz etmek için belirli adımları içerir.
Bu analizin birincil amacı, kullandığınız veri setinin modelleme algoritmalarını uygulamaya başlamak için uygun olduğundan emin olmaktır. Modelleme aşamasına geçmeden önce verileriniz üzerinde gerçekleştirmeniz gereken ilk adımın bu olmasının nedeni budur. Aykırı değerler nelerdir ve bunlarla nasıl başa çıkılır?
1. Boxplot - Boxplot, verileri çeyreklerine göre ayırdığımız bir aykırı değeri tespit etmenin bir yöntemidir.
2. Dağılım grafiği - Bir dağılım grafiği, kartezyen düzlemde işaretlenmiş noktaların bir koleksiyonu şeklinde 2 değişkenin verilerini görüntüler. Bir değişkenin değeri yatay ekseni (x-ais) ve diğer değişkenin değeri dikey ekseni (y ekseni) temsil eder.
3. Z-skoru - Z-skorunu hesaplarken merkezden uzaktaki noktaları arar ve uç değer olarak kabul ederiz.
4. Çeyrekler Arası Aralık (IQR) - Çeyrekler Arası Aralık veya IQR, genellikle istatistiksel dağılım olarak adlandırılan üst ve alt çeyrekler veya 75. ve 25. çeyrekler arasındaki farktır. EDA yapmak için yönergeler nelerdir?
Bununla birlikte, yaygın olarak uygulanan bazı yönergeler vardır:
1. Eksik değerlerin ele alınması
2. Yinelenen verileri kaldırma
3. Aykırı değerlerin ele alınması
4. Ölçekleme ve normalleştirme
5. Tek değişkenli ve İki değişkenli analiz