
Python'da Keşifsel Veri Analizi Nedir? Sıfırdan Öğrenin
Yayınlanan: 2021-03-04Keşifsel Veri Analizi veya EDA, kısaca, Veri Bilimi Projesi'nin neredeyse %70'ini oluşturmaktadır. EDA, verilerden çıkarımsal istatistikleri çıkarmak için çeşitli analitik araçları kullanarak verileri keşfetme sürecidir. Bu keşifler, ya düz sayıları görerek ya da farklı türlerde grafik ve çizelgeler çizerek yapılır.
Her grafik veya çizelge, farklı bir hikayeyi ve aynı verilere bir açıyı gösterir. Veri analizi ve temizleme bölümünün çoğu için Pandalar en çok kullanılan araçtır. Görselleştirmeler ve grafik/tabloların çizilmesi için Matplotlib, Seaborn ve Plotly gibi çizim kütüphaneleri kullanılır.
Verileri size itiraf ettirdiği için EDA'nın yapılması son derece gereklidir. Çok iyi bir EDA yapan bir Veri Bilimcisi, veriler hakkında çok şey bilir ve bu nedenle oluşturacakları model, otomatik olarak iyi bir EDA yapmayan Veri Bilimcisinden daha iyi olacaktır.
Bu eğitimin sonunda aşağıdakileri bileceksiniz:
- Verilerin temel genel görünümünü kontrol etme
- Verilerin tanımlayıcı istatistiklerinin kontrol edilmesi
- Sütun adlarını ve veri türlerini değiştirme
- Eksik değerleri ve yinelenen satırları işleme
- İki Değişkenli Analiz
İçindekiler
Verilere Genel Bakış
Bu eğitim için Kaggle'dan indirilebilen Otomobil Veri Kümesini kullanacağız. Hemen hemen her veri kümesi için ilk adım, onu içe aktarmak ve temel genel bakışını kontrol etmektir - şekli, sütunları, sütun türleri, ilk 5 satırı vb. Bu adım, üzerinde çalışacağınız verilerin hızlı bir özetini verir. Bunu Python'da nasıl yapacağımızı görelim.
| # Gerekli kitaplıkları içe aktarma pandaları pd olarak içe aktar numpy'yi np olarak içe aktar seaborn'u sns #visualisation olarak içe aktar matplotlib.pyplot'u plt olarak içe aktar #visualization %matplotlib satır içi sns.set(color_codes= Doğru ) |
Veri Başı ve Kuyruğu
| veri = pd.read_csv( “yol/dataset.csv” ) # Veri çerçevesinin ilk 5 satırını kontrol edin veri.kafa() |
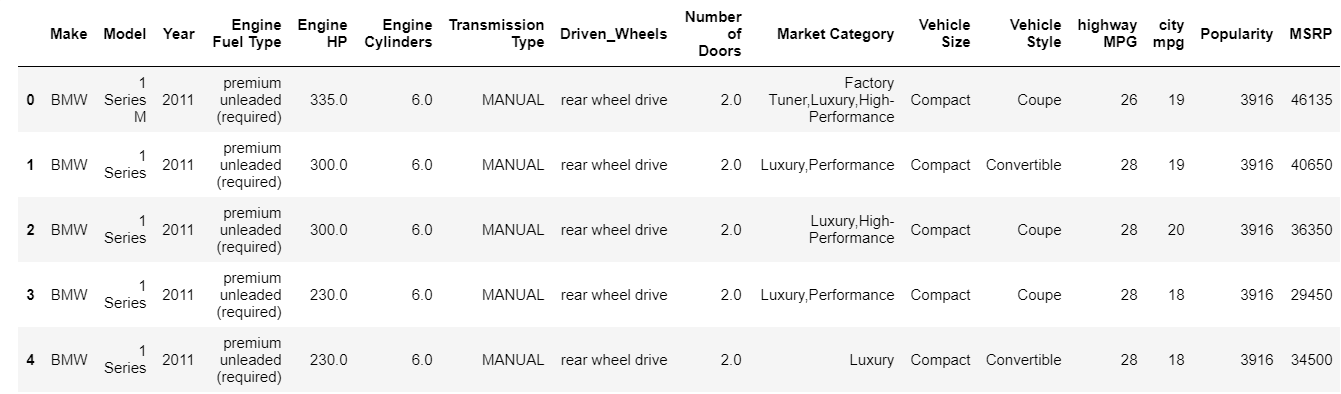
Head işlevi, varsayılan olarak veri çerçevesinin ilk 5 dizinini yazdırır. Bu değeri başa atlayarak kaç tane üst dizin görmeniz gerektiğini de belirleyebilirsiniz. Kafayı anında yazdırmak bize ne tür verilere sahip olduğumuza, ne tür özelliklerin mevcut olduğuna ve hangi değerleri içerdiğine hızlıca bakmamızı sağlar. Tabii ki, bu verilerle ilgili tüm hikayeyi anlatmıyor, ancak size verilere hızlı bir göz atmanızı sağlıyor. Benzer şekilde, kuyruk işlevini kullanarak veri çerçevesinin alt kısmını yazdırabilirsiniz.
| # Veri çerçevesinin son 10 satırını yazdır veri.kuyruk( 10 ) |
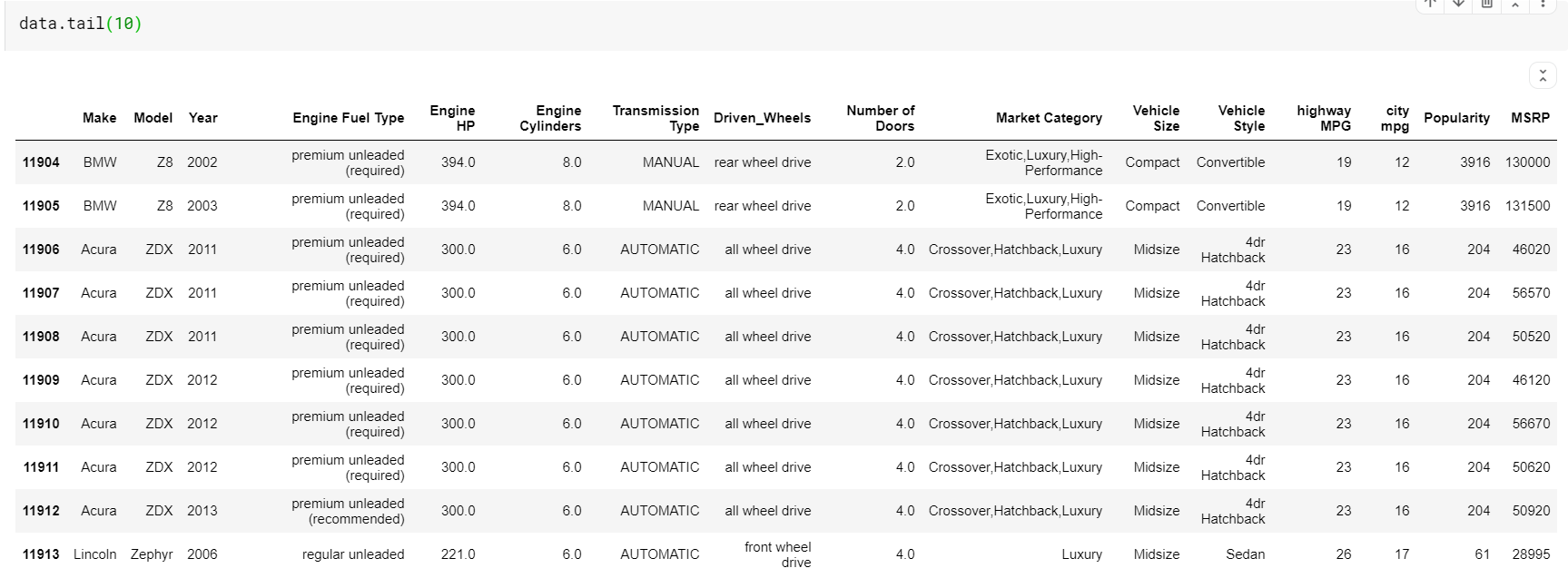
Burada dikkat edilmesi gereken bir şey, hem function-head hem de tail bize üst veya alt dizinleri vermesidir. Ancak üst veya alt satırlar her zaman verilerin iyi bir önizlemesi değildir. Böylece, sample() işlevini kullanarak veri kümesinden rastgele örneklenmiş herhangi bir sayıda satırı da yazdırabilirsiniz.
| # 5 rastgele satır yazdır veri.örnek( 5 ) |
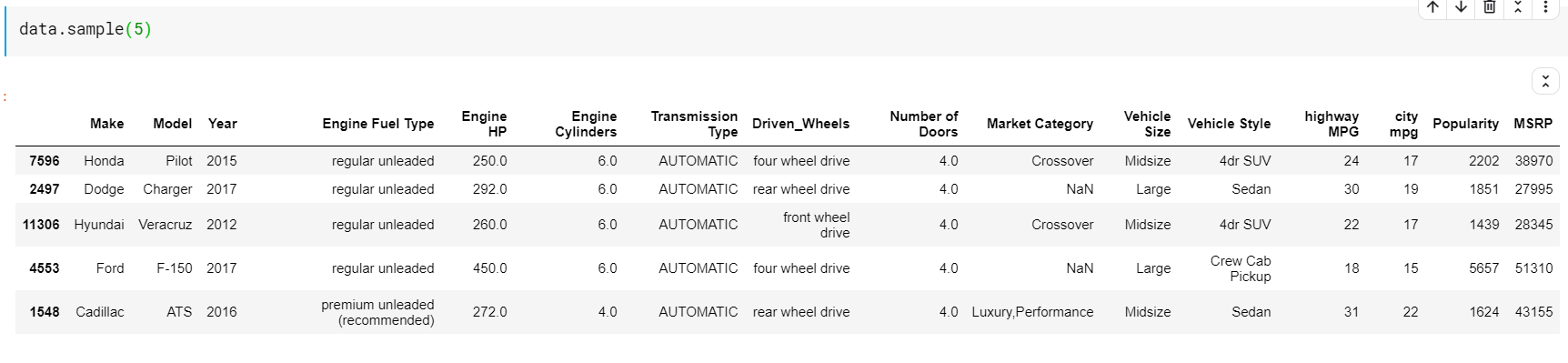
Tanımlayıcı istatistikler
Ardından, veri kümesinin tanımlayıcı istatistiklerini kontrol edelim. Tanımlayıcı istatistikler, veri kümesini "tanımlayan" her şeyden oluşur. Veri çerçevesinin şeklini, tüm sütunların ne olduğunu, tüm sayısal ve kategorik özelliklerin neler olduğunu kontrol ediyoruz. Tüm bunları basit fonksiyonlarda nasıl yapacağımızı da göreceğiz.
Şekil
| # Veri çerçevesi şeklinin kontrol edilmesi (mxn) # m=satır sayısı # n=sütun sayısı veri.şekil |

Gördüğümüz gibi, bu veri çerçevesi 11914 satır ve 16 sütun içermektedir.
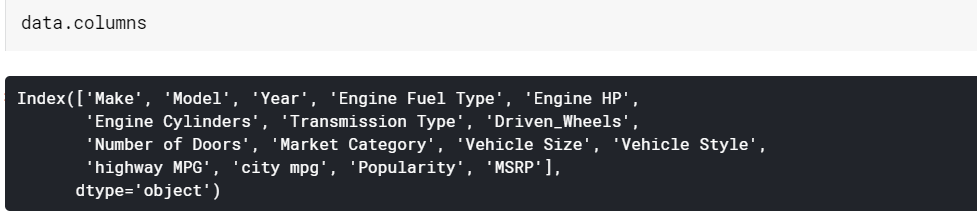
sütunlar
| # Sütun adlarını yazdırın data.columns |
Veri çerçevesi bilgileri
| # Sütun veri türlerini ve eksik olmayan değerlerin sayısını yazdırın veri.bilgi() |
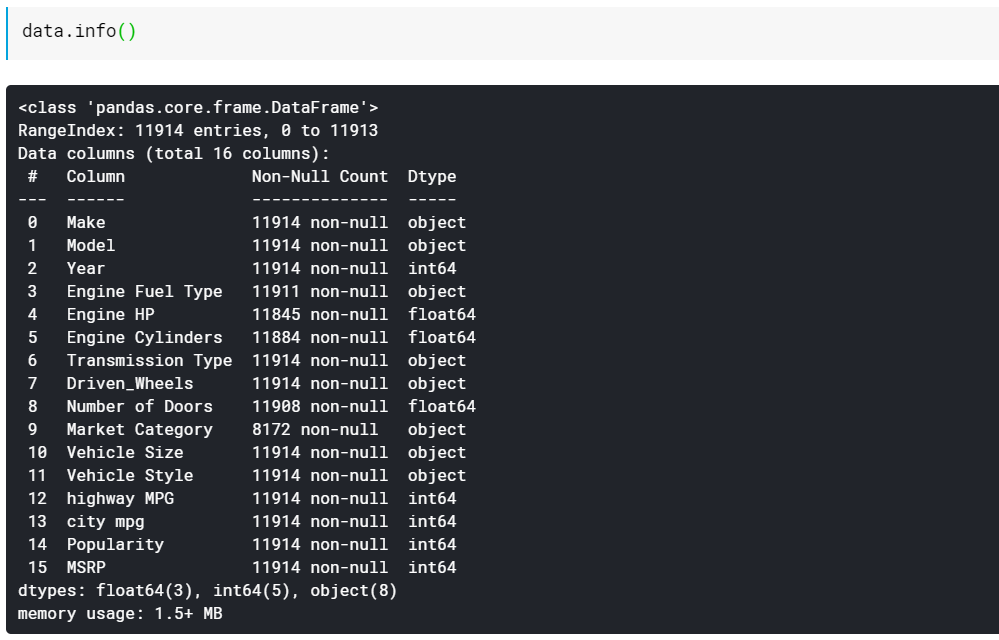
Gördüğünüz gibi, info() işlevi bize tüm sütunları, bu sütunlarda kaç tane boş olmayan veya eksik olmayan değer olduğunu ve son olarak bu sütunların veri tipini verir. Bu, hangi özelliklerin sayısal, hangilerinin kategorik/metin tabanlı olduğunu görmenin güzel ve hızlı bir yoludur. Ayrıca, artık hangi sütunların eksik değerleri olduğu hakkında bilgimiz var. Eksik değerlerle nasıl çalışılacağına daha sonra bakacağız.
Sütun Adlarını ve Veri Türlerini Değiştirme
EDA'da her bir sütunu dikkatlice kontrol etmek ve değiştirmek son derece önemlidir. Bir sütunun/özelliğin ne tür içerik içerdiğini ve pandaların veri türünü ne okuduğunu görmemiz gerekir. Sayısal veri türleri çoğunlukla int64 veya float64'tür. Metin tabanlı veya kategorik özelliklere 'nesne' veri türü atanır.
Tarih-zamana dayalı özellikler atanır Pandaların bir özelliğin veri türünü anlamadığı zamanlar vardır. Bu gibi durumlarda, tembelce ona 'nesne' veri tipini atar. Read_csv ile verileri okurken sütun veri tiplerini açıkça belirtebiliriz.
Kategorik ve Sayısal Sütunları Seçme
| # Tüm kategorik ve sayısal sütunları ayrı listelere ekleyin kategorik = data.select_dtypes( 'nesne' ) .sütunlar sayısal = data.select_dtypes( 'sayı' ) .sütunlar |


Burada 'sayı' olarak ilettiğimiz tür, int64 veya float64 olsun, herhangi bir sayıya sahip veri türlerine sahip tüm sütunları seçer.
Sütunları Yeniden Adlandırma
| # Sütun adlarını yeniden adlandırma data = data.rename(columns={ “Motor HP” : “HP” , “Motor Silindirleri” : “Silindirler” , “İletim Tipi” : “İletim” , "Driven_Wheels" : "Sürüş Modu" , “otoyol MPG” : “MPG-H” , “MSRP” : “Fiyat” }) veri.kafa( 5 ) |

Yeniden adlandırma işlevi, yalnızca yeniden adlandırılacak sütun adlarını ve yeni adlarını içeren bir sözlük alır.
Eksik Değerleri ve Yinelenen Satırları İşleme
Eksik değerler, gerçek hayattaki herhangi bir veri kümesindeki en yaygın sorunlardan/tutarsızlıklardan biridir. Bunu yapmanın birden fazla yolu olduğundan, eksik değerleri ele almak başlı başına geniş bir konudur. Bazı yollar daha genel yöntemlerdir ve bazıları kişinin uğraşabileceği veri kümesine daha özeldir.
Eksik Değerleri Kontrol Etme
| # Eksik değerler kontrol ediliyor data.isnull().sum() |
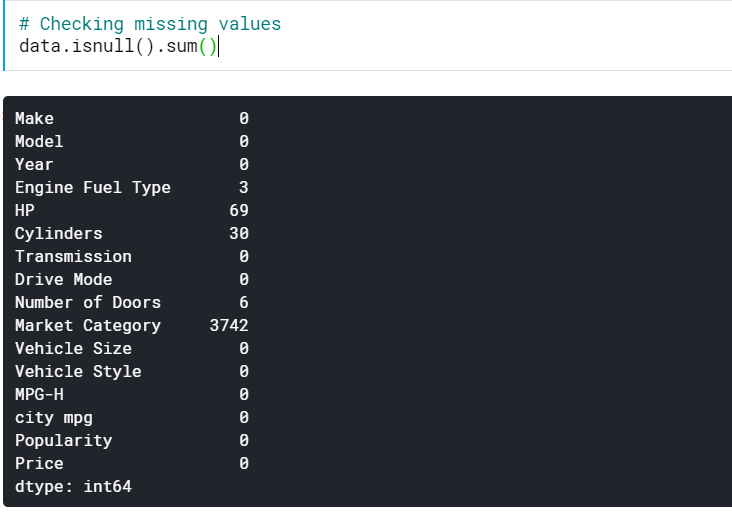
Bu bize tüm sütunlarda eksik olan değerlerin sayısını verir. Kayıp değerlerin yüzdesini de görebiliriz.
| # Eksik değerlerin yüzdesi data.isnull().mean()* 100 |
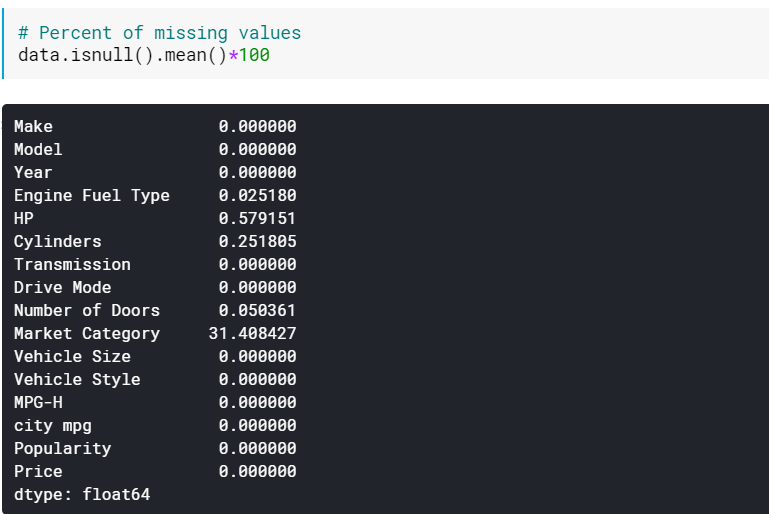
Eksik değerleri olan çok sayıda sütun olduğunda yüzdeleri kontrol etmek faydalı olabilir. Bu gibi durumlarda, çok sayıda eksik değere sahip sütunlar (örneğin, >%60 eksik) bırakılabilir.
Eksik Değerleri Atama
| #Sayısal sütunların eksik değerlerini ortalamaya göre yerleştirme veri[sayısal] = veri[sayısal].fillna(veri[sayısal].mean().iloc[ 0 ]) #Kategorik sütunların eksik değerlerini moda göre yerleştirme data[kategorik] = data[kategorik].fillna(veri[kategorik].mode().iloc[ 0 ]) |
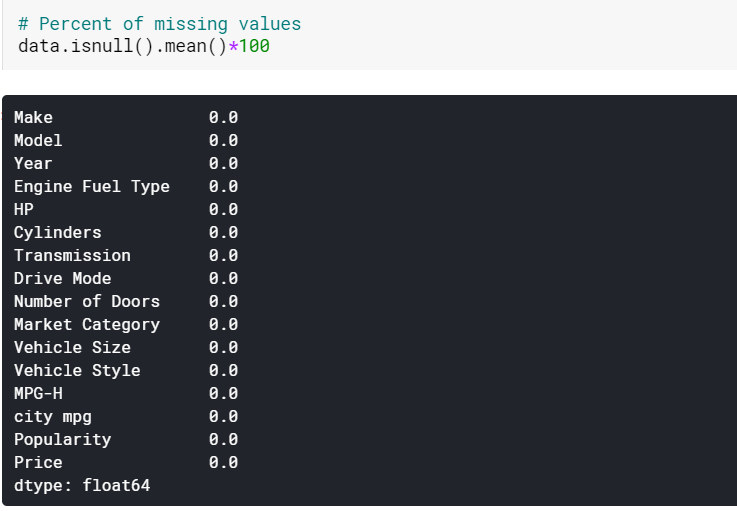
Burada, sayısal sütunlardaki eksik değerleri ilgili araçlarına göre ve kategorik sütunlardakileri modlarına göre atıyoruz. Ve gördüğümüz gibi, artık hiçbir kayıp değer yok.
Lütfen bunun değerleri yüklemenin en ilkel yolu olduğunu ve enterpolasyon, KNN vb. gibi daha karmaşık yolların geliştirildiği gerçek yaşam durumlarında çalışmadığını unutmayın.
Yinelenen Satırları İşleme
| # Yinelenen satırları bırak data.drop_duplicates(inplace= True ) |
Bu sadece yinelenen satırları düşürür.
Ödeme: Python Proje Fikirleri ve Konuları
İki Değişkenli Analiz
Şimdi iki değişkenli analiz yaparak nasıl daha fazla bilgi edinebileceğimizi görelim. Bivariate, 2 değişken veya özellikten oluşan bir analiz anlamına gelir. Farklı özellik türleri için farklı türlerde araziler mevcuttur.
Sayısal için – Sayısal
- Dağılım grafiği
- Çizgi grafiği
- Korelasyonlar için ısı haritası
Kategorik-Sayısal için
- Grafik çubuğu
- keman arsa
- sürü planı
Kategorik-Kategorik için
- Grafik çubuğu
- nokta grafiği
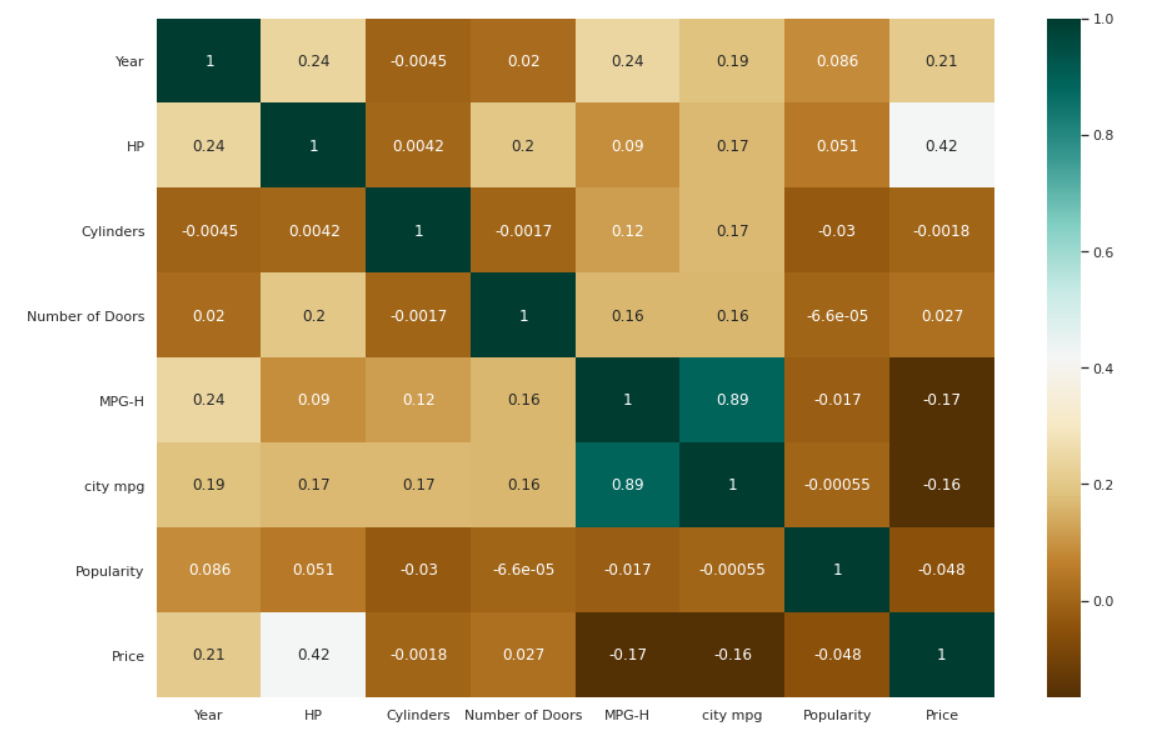
Korelasyonlar için Isı Haritası
| # Değişkenler arasındaki korelasyonların kontrol edilmesi. plt.şekil(şekil=( 15 , 10 )) c= veri.corr() sns.heatmap(c,cmap= “BrBG” ,annot= Doğru ) |
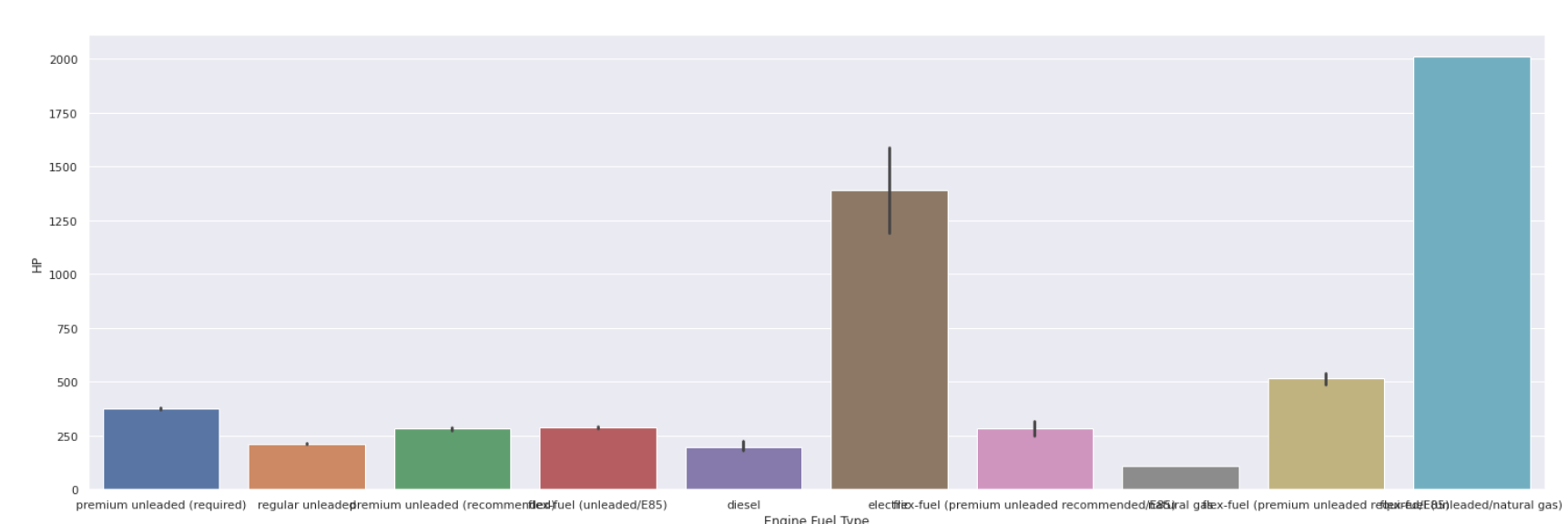
çubuk arsa
| sns.barplot(veri[ 'Motor Yakıt Tipi' ], veri[ 'HP' ]) |
Dünyanın en iyi Üniversitelerinden veri bilimi sertifikası alın . Kariyerinizi hızlandırmak için Yönetici PG Programları, İleri Düzey Sertifika Programları veya Yüksek Lisans Programları öğrenin.
Çözüm
Gördüğümüz gibi, bir veri kümesini keşfederken ele alınması gereken birçok adım vardır. Bu eğitimde yalnızca birkaç yönü ele aldık, ancak bu size iyi bir EDA hakkında temel bilgilerden fazlasını verecektir.
Python hakkında bilgi edinmek, veri bilimi hakkında her şeyi merak ediyorsanız, çalışan profesyoneller için oluşturulan ve 10'dan fazla vaka çalışması ve proje, pratik uygulamalı atölye çalışmaları, endüstri ile mentorluk sunan IIIT-B & upGrad'ın Veri Biliminde PG Diplomasına göz atın uzmanlar, sektör danışmanlarıyla bire bir, 400+ saat öğrenim ve en iyi firmalarla iş yardımı.
Keşfedici veri analizindeki adımlar nelerdir?
Keşfedici veri analizi yapmak için gerçekleştirmeniz gereken ana adımlar şunlardır:
Değişkenler ve veri türleri tanımlanmalıdır.
Temel metrikleri analiz etme
Tek Değişkenli Grafik Olmayan Analiz
Tek Değişkenli Grafik Analizi
İki Değişkenli Verilerin Analizi
Değişken olan dönüşümler
Eksik değer tedavisi
Aykırı değerlerin tedavisi
Korelasyon Analizi
Boyutsallığın Azaltılması
Keşfedici veri analizinin amacı nedir?
EDA'nın birincil amacı, herhangi bir varsayımda bulunmadan önce verilerin analizine yardımcı olmaktır. Belirgin hataların saptanmasına, veri modellerinin daha iyi anlaşılmasına, aykırı değerlerin veya olağandışı olayların saptanmasına ve değişkenler arasındaki ilginç ilişkilerin keşfedilmesine yardımcı olabilir.
Keşif analizi, veri bilimcileri tarafından, yarattıkları sonuçların doğru ve hedeflenen iş sonuçları ve hedeflerine uygun olduğunu garanti etmek için kullanılabilir. EDA ayrıca paydaşlara uygun soruları yanıtlamalarını sağlayarak yardımcı olur. Standart sapmalar, kategorik veriler ve güven aralıklarının tümü EDA ile yanıtlanabilir. EDA'nın tamamlanmasının ve içgörülerin çıkarılmasının ardından özellikleri, makine öğrenimi de dahil olmak üzere daha gelişmiş veri analizine veya modellemeye uygulanabilir.
Keşfedici veri analizinin farklı türleri nelerdir?
İki tür EDA tekniği vardır: grafiksel ve nicel (grafik olmayan). Nicel yaklaşım ise özet istatistiklerin derlenmesini gerektirirken, grafiksel yöntemler verilerin şematik veya görsel bir şekilde toplanmasını gerektirir. Tek değişkenli ve çok değişkenli yaklaşımlar, bu iki tür metodolojinin alt kümeleridir.
İlişkileri araştırmak için, tek değişkenli yaklaşımlar bir seferde bir değişkene (veri sütunu) bakarken, çok değişkenli yöntemler aynı anda iki veya daha fazla değişkene bakar. Tek değişkenli ve çok değişkenli grafiksel ve grafiksel olmayan, EDA'nın dört biçimidir. Nicel prosedürler daha nesnelken, resimli yöntemler daha özneldir.