
Node.js ve Puppeteer ile Dinamik Web Sitelerinin Etik Kazıma Rehberi
Yayınlanan: 2022-03-10Web kazımanın gerçekte ne anlama geldiğine dair küçük bir bölümle başlayalım. Hepimiz günlük hayatımızda web kazıma kullanıyoruz. Yalnızca bir web sitesinden bilgi çıkarma sürecini tanımlar. Bu nedenle, en sevdiğiniz erişte yemeğinin tarifini internetten kopyalayıp kişisel defterinize yapıştırırsanız, web kazıma işlemi gerçekleştirirsiniz.
Bu terimi yazılım endüstrisinde kullanırken, genellikle bir yazılım parçası kullanarak bu manuel görevin otomasyonuna atıfta bulunuruz. Önceki “erişte yemeği” örneğimize bağlı kalarak, bu işlem genellikle iki adımdan oluşur:
- sayfa getiriliyor
Öncelikle sayfayı bir bütün olarak indirmemiz gerekiyor. Bu adım, manuel olarak kazıma yaparken sayfayı web tarayıcınızda açmaya benzer. - Verileri ayrıştırma
Şimdi, web sitesinin HTML'sindeki tarifi çıkarmamız ve onu JSON veya XML gibi makine tarafından okunabilir bir formata dönüştürmemiz gerekiyor.
Geçmişte birçok şirkette veri danışmanı olarak çalıştım. Sadece birkaç satır kodla kolayca otomatikleştirilebilmelerine rağmen, kaç tane veri çıkarma, toplama ve zenginleştirme görevinin hala manuel olarak yapıldığını görmek beni şaşırttı. Web kazıma benim için tam olarak bununla ilgili: başka bir değer yaratan iş sürecini beslemek için bir web sitesinden değerli bilgi parçalarını çıkarmak ve normalleştirmek .
Bu süre zarfında şirketlerin her türlü kullanım durumu için web kazıma kullandığını gördüm. Yatırım firmaları, finansal yatırımlarını desteklemek için öncelikle ürün incelemeleri , fiyat bilgileri veya sosyal medya gönderileri gibi alternatif veriler toplamaya odaklandı.
İşte bir örnek. Bir müşteri, derecelendirme, gözden geçirenin konumu ve gönderilen her inceleme için inceleme metni dahil olmak üzere çeşitli e-ticaret web sitelerinden kapsamlı bir ürün listesi için ürün inceleme verilerini sıyırmak üzere bana yaklaştı. Sonuç verileri, müşterinin ürünün farklı pazarlardaki popülerliğiyle ilgili eğilimleri belirlemesini sağladı. Bu, görünüşte "işe yaramaz" tek bir bilgi parçasının daha büyük bir miktarla karşılaştırıldığında nasıl değerli hale gelebileceğinin mükemmel bir örneğidir.
Diğer şirketler, olası satış üretimi için web kazıma kullanarak satış süreçlerini hızlandırır. Bu işlem genellikle belirli bir web sitesi listesi için telefon numarası, e-posta adresi ve iletişim adı gibi iletişim bilgilerinin çıkarılmasını içerir. Bu görevi otomatikleştirmek, satış ekiplerine potansiyel müşterilere yaklaşmak için daha fazla zaman verir. Böylece satış sürecinin verimliliği artar.
Kurallara bağlı kal
Genel olarak, halka açık verilerin web'den kazınması, Linkedin ve HiQ davasının yargı yetkisi tarafından onaylandığı üzere yasaldır. Bununla birlikte, yeni bir web kazıma projesine başlarken kendime bağlı kalmayı sevdiğim bir dizi etik kural belirledim. Bu içerir:
- robots.txt dosyasını kontrol etme.
Genellikle sitenin hangi bölümlerine robotlar ve kazıyıcılar tarafından erişilebileceği konusunda net bilgiler içerir ve erişilmemesi gereken bölümleri vurgular. - Şartlar ve koşulları okumak.
Robots.txt ile karşılaştırıldığında, bu bilgi parçası daha az sıklıkla bulunmaz, ancak genellikle veri kazıyıcılarına nasıl davrandıklarını belirtir. - Orta hızda kazıma.
Kazıma, hedef sitenin altyapısında sunucu yükü oluşturur. Neyi sıyırdığınıza ve sıyırıcınızın hangi eşzamanlılık düzeyinde çalıştığına bağlı olarak, trafik hedef sitenin sunucu altyapısı için sorunlara neden olabilir. Elbette bu denklemde sunucu kapasitesinin rolü büyük. Bu nedenle, sıyırıcımın hızı, sıyırmayı hedeflediğim veri miktarı ile hedef sitenin popülaritesi arasında her zaman bir dengedir. Bu dengeyi bulmak, tek bir soruya cevap vererek sağlanabilir: “Planlanan hız sitenin organik trafiğini önemli ölçüde değiştirecek mi?”. Bir sitenin doğal trafik miktarından emin olmadığım durumlarda kabaca bir fikir edinmek için ahrefs gibi araçlar kullanırım.
Doğru Teknolojiyi Seçmek
Aslında, başsız bir tarayıcıyla kazıma , altyapınızı büyük ölçüde etkilediği için kullanabileceğiniz en düşük performanslı teknolojilerden biridir. Makinenizin işlemcisinden bir çekirdek, yaklaşık olarak bir Chrome örneğini işleyebilir.
Bunun gerçek dünyadaki bir web kazıma projesi için ne anlama geldiğini görmek için hızlı bir örnek hesaplama yapalım.
Senaryo
- 20.000 URL'yi kazımak istiyorsunuz.
- Hedef siteden ortalama yanıt süresi 6 saniyedir.
- Sunucunuz 2 CPU çekirdeğine sahiptir.
Projenin tamamlanması 16 saat sürecek.
Bu nedenle, dinamik bir web sitesi için kazıma fizibilite testi yaparken her zaman bir tarayıcı kullanmaktan kaçınmaya çalışırım.
İşte her zaman üzerinden geçtiğim küçük bir kontrol listesi:
- URL'deki GET parametreleri aracılığıyla gerekli sayfa durumunu zorlayabilir miyim? Evetse, eklenen parametrelerle bir HTTP isteği çalıştırabiliriz.
- Dinamik bilgiler sayfa kaynağının bir parçası mı ve DOM'da bir yerde bir JavaScript nesnesi aracılığıyla mı sağlanıyor? Evetse, normal bir HTTP isteğini tekrar kullanabilir ve dizelenmiş nesneden gelen verileri ayrıştırabiliriz.
- Veriler bir XHR talebi yoluyla mı getiriliyor? Öyleyse, bir HTTP istemcisiyle uç noktaya doğrudan erişebilir miyim? Evet ise, doğrudan uç noktaya bir HTTP isteği gönderebiliriz. Çoğu zaman, yanıt JSON'da biçimlendirilir ve bu da hayatımızı çok daha kolaylaştırır.
Tüm sorulara kesin bir "Hayır" yanıtı verilirse, resmi olarak bir HTTP istemcisi kullanmak için uygun seçeneklerimiz tükenir. Elbette, deneyebileceğimiz daha fazla siteye özgü ince ayar olabilir, ancak genellikle bunları çözmek için gereken süre, başsız bir tarayıcının daha yavaş performansına kıyasla çok yüksektir. Bir tarayıcı ile kazımanın güzelliği, aşağıdaki temel kurala tabi olan her şeyi kazıyabilmenizdir:
Bir tarayıcı ile erişebilirseniz, kazıyabilirsiniz.
Aşağıdaki siteyi sıyırıcımız için örnek alalım: https://quotes.toscrape.com/search.aspx. Bir konu listesi için verilen yazarlar listesinden alıntılar içerir. Tüm veriler XHR aracılığıyla alınır.
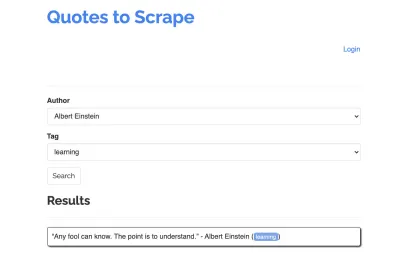
Sitenin işleyişine yakından bakan ve yukarıdaki kontrol listesini gözden geçiren kişi, muhtemelen alıntıların bir HTTP istemcisi kullanılarak kazınabileceğini fark etti, çünkü bunlar doğrudan tırnak uç noktasında bir POST isteği yaparak alınabilecekler. Ancak bu eğitimin Puppeteer kullanarak bir web sitesinin nasıl kazınacağını kapsaması gerektiğinden, bunun imkansız olduğunu farz edeceğiz.
Ön Koşulları Yükleme
Her şeyi Node.js kullanarak oluşturacağımız için öncelikle yeni bir klasör oluşturup açalım ve aşağıdaki komutu çalıştırarak içinde yeni bir Node projesi oluşturalım:
mkdir js-webscraper cd js-webscraper npm initLütfen npm'yi zaten kurduğunuzdan emin olun. Yükleyici bize bu projeyle ilgili meta-bilgiler hakkında birkaç soru soracak ve Enter 'a basarak atlayabiliyoruz.
Kuklacı Kurulumu
Daha önce bir tarayıcı ile kazıma yapmaktan bahsetmiştik. Puppeteer, başsız bir Chrome örneğiyle programlı olarak konuşmamızı sağlayan bir Node.js API'sidir.
npm kullanarak kuralım:
npm install puppeteerKazıyıcımızı İnşa Etmek
Şimdi scraper.js adında yeni bir dosya oluşturarak kazıyıcımızı oluşturmaya başlayalım.
İlk olarak, önceden kurulmuş olan Puppeteer kütüphanesini içe aktarıyoruz:
const puppeteer = require('puppeteer');Bir sonraki adım olarak, Puppeteer'a eşzamansız ve kendi kendine çalışan bir işlev içinde yeni bir tarayıcı örneği açmasını söylüyoruz:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Not : Varsayılan olarak, performansı artırdığı için başsız mod kapalıdır. Ancak, yeni bir sıyırıcı oluştururken, başsız modunu kapatmayı seviyorum. Bu, tarayıcının geçtiği süreci takip etmemize ve oluşturulan tüm içeriği görmemize olanak tanır. Bu, daha sonra komut dosyamızda hata ayıklamamıza yardımcı olacaktır.
Açılan tarayıcı örneğimizde, şimdi yeni bir sayfa açıp hedef URL'mize yönlendiriyoruz:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Eşzamansız işlevin bir parçası olarak, bir sonraki kod satırına geçmeden önce aşağıdaki komutun yürütülmesini await için wait ifadesini kullanacağız.
Artık bir tarayıcı penceresini başarıyla açtığımıza ve sayfaya gittiğimize göre , web sitesinin durumunu oluşturmalıyız , böylece istenen bilgi parçaları kazıma için görünür hale gelir.
Mevcut konular, seçilen bir yazar için dinamik olarak oluşturulur. Bu nedenle, önce 'Albert Einstein'ı seçeceğiz ve oluşturulan konu listesini bekleyeceğiz. Liste tamamen oluşturulduktan sonra, konu olarak 'öğrenme'yi seçiyoruz ve ikinci form parametresi olarak seçiyoruz. Daha sonra gönder'e tıklıyoruz ve sonuçları tutan kapsayıcıdan alınan alıntıları çıkarıyoruz.

Şimdi bunu JavaScript mantığına çevireceğimize göre, önce bir önceki paragrafta bahsettiğimiz tüm eleman seçicilerin bir listesini yapalım:
| Yazar seçme alanı | #author |
| Etiket seçme alanı | #tag |
| Gönder düğmesi | input[type="submit"] |
| Teklif kapsayıcısı | .quote |
Sayfayla etkileşime geçmeden önce, komut dosyamıza aşağıdaki satırları ekleyerek erişeceğimiz tüm öğelerin görünür olmasını sağlayacağız:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Ardından, iki seçim alanımız için değerler seçeceğiz:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Artık sayfadaki “Ara” düğmesine basarak aramamızı yapmaya ve alıntıların görünmesini beklemeye hazırız:
await page.click('.btn'); await page.waitForSelector('.quote'); Şimdi sayfanın HTML DOM yapısına erişeceğimiz için, sağlanan page.evaluate() işlevini çağırıyoruz ve tırnak işaretlerini tutan kapsayıcıyı seçiyoruz (bu durumda yalnızca bir tanesidir). Daha sonra bir nesne oluştururuz ve her object parametresi için geri dönüş değeri olarak null tanımlarız:
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Tüm sonuçları günlüğe kaydederek konsolumuzda görünür hale getirebiliriz:
console.log(quotes);Son olarak tarayıcımızı kapatalım ve bir catch ifadesi ekleyelim:
await browser.close();Tam sıyırıcı aşağıdaki gibi görünür:
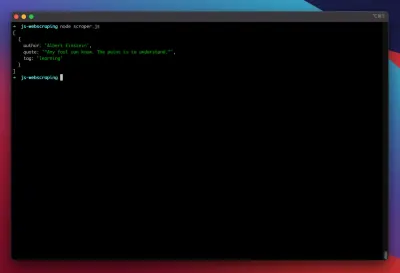
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Kazıyıcımızı şununla çalıştırmayı deneyelim:
node scraper.jsVe işte başlıyoruz! Sıyırıcı, alıntı nesnemizi beklendiği gibi döndürür:
Gelişmiş Optimizasyonlar
Temel sıyırıcımız artık çalışıyor. Daha ciddi kazıma görevlerine hazırlamak için bazı iyileştirmeler ekleyelim.
Bir Kullanıcı Aracısı Ayarlama
Varsayılan olarak, Puppeteer HeadlessChrome dizesini içeren bir kullanıcı aracısı kullanır. Oldukça az sayıda web sitesi bu tür imzalara dikkat eder ve buna benzer bir imzayla gelen istekleri engeller . Bunun, kazıyıcının başarısız olmasının olası bir nedeni olmasını önlemek için, kodumuza aşağıdaki satırı ekleyerek her zaman özel bir kullanıcı aracısı ayarlarım:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Bu, en yaygın 5 kullanıcı aracısından oluşan bir diziden gelen her istekle rastgele bir kullanıcı aracısı seçilerek daha da geliştirilebilir. En yaygın kullanıcı aracılarının bir listesi, En Yaygın Kullanıcı Aracıları bölümünde bulunabilir.
Proxy Uygulaması
Puppeteer, proxy adresi başlatma sırasında Puppeteer'a şu şekilde iletilebildiğinden, bir proxy'ye bağlanmayı çok kolaylaştırır:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies, kullanabileceğiniz geniş bir ücretsiz proxy listesi sağlar. Alternatif olarak, dönen proxy hizmetleri kullanılabilir. Proxy'ler genellikle birçok müşteri (veya bu durumda ücretsiz kullanıcılar) arasında paylaşıldığından, bağlantı normal koşullar altında olduğundan çok daha güvenilmez hale gelir. Bu, hata işleme ve yeniden deneme yönetimi hakkında konuşmak için mükemmel bir an.
Hata Ve Yeniden Deneme Yönetimi
Sıyırıcınızın arızalanmasına birçok faktör neden olabilir. Bu nedenle, hataları ele almak ve bir arıza durumunda ne olacağına karar vermek önemlidir. Kazıyıcımızı bir proxy'ye bağladığımız ve bağlantının kararsız olmasını beklediğimiz için (özellikle ücretsiz proxy'ler kullandığımız için), pes etmeden önce dört kez yeniden denemek istiyoruz.
Ayrıca, daha önce başarısız olmuşsa, aynı IP adresine sahip bir isteği yeniden denemenin bir anlamı yoktur. Bu nedenle, küçük bir proxy döndürme sistemi kuracağız.
Her şeyden önce, iki yeni değişken oluşturuyoruz:
let retry = 0; let maxRetries = 5; scrape() işlevimizi her çalıştırdığımızda, yeniden deneme değişkenimizi 1 artıracağız. Ardından, hataları işleyebilmemiz için tüm kazıma mantığımızı bir try and catch ifadesiyle sarıyoruz. Yeniden deneme yönetimi, catch işlevimizde gerçekleşir:
Önceki tarayıcı örneği kapatılacak ve yeniden deneme değişkenimiz maxRetries değişkenimizden küçükse, kazıma işlevi yinelemeli olarak çağrılır.
Kazıyıcımız şimdi şöyle görünecek:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Şimdi daha önce bahsedilen proxy döndürücüyü ekleyelim.
Önce bir proxy listesi içeren bir dizi oluşturalım:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Şimdi diziden rastgele bir değer seçin:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Artık dinamik olarak oluşturulan proxy'yi Puppeteer örneğimizle birlikte çalıştırabiliriz:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Tabii ki, bu proxy döndürücü, ölü proxy'leri işaretlemek için daha da optimize edilebilir ve bu böyle devam eder, ancak bu kesinlikle bu öğreticinin kapsamını aşacaktır.
Bu, sıyırıcımızın kodudur (tüm iyileştirmeler dahil):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();işte! Sıyırıcımızı terminalimizin içinde çalıştırmak, alıntıları döndürür.
Kuklacıya Alternatif Olarak Oyun Yazarı
Puppeteer, Google tarafından geliştirildi. 2020'nin başında Microsoft, Playwright adlı bir alternatif yayınladı. Microsoft, Puppeteer-Team'den bir çok mühendisi kelle avladı. Bu nedenle Playwright, Puppeteer üzerinde çalışmaya başlamış birçok mühendis tarafından geliştirildi. Playwright'ın blogdaki yeni çocuğu olmasının yanı sıra, Chromium, Firefox ve WebKit'i (Safari) desteklediğinden, Playwright'ın en büyük farklılaşma noktası çapraz tarayıcı desteğidir.
Performans testleri (Checkly tarafından gerçekleştirilen bunun gibi), Puppeteer'ın Playwright'a kıyasla genel olarak yaklaşık %30 daha iyi performans sağladığını gösteriyor - en azından yazım sırasında kendi deneyimime uyan.
Bir tarayıcı örneğiyle birden fazla cihazı çalıştırabilmeniz gibi diğer farklılıklar, web kazıma bağlamında gerçekten değerli değildir.
Kaynaklar ve Ek Bağlantılar
- Kuklacı Belgeleri
- Öğrenme Kuklacı ve Oyun Yazarı
- Zenscrape tarafından Javascript ile Web Kazıma
- En Yaygın Kullanıcı Aracıları
- Kuklacıya Karşı Oyun Yazarı