
Makine Öğreniminde Veri Ön İşleme: İzlenecek 7 Kolay Adım
Yayınlanan: 2021-07-15Makine Öğreniminde veri ön işleme, verilerden anlamlı içgörülerin çıkarılmasını teşvik etmek için verilerin kalitesini artırmaya yardımcı olan çok önemli bir adımdır. Makine Öğreniminde veri ön işlemesi, bir bina ve Makine Öğrenimi modellerini eğitmeye uygun hale getirmek için ham verileri hazırlama (temizleme ve düzenleme) tekniğini ifade eder. Basit bir deyişle, Machine Learning'de veri ön işleme, ham verileri anlaşılır ve okunabilir bir formata dönüştüren bir veri madenciliği tekniğidir.
İçindekiler
Neden Makine Öğreniminde Veri Ön İşleme?
Bir Makine Öğrenimi modeli oluşturmaya gelince, veri ön işleme, sürecin başladığını gösteren ilk adımdır. Tipik olarak, gerçek dünya verileri eksik, tutarsız, hatalıdır (hatalar veya aykırı değerler içerir) ve genellikle belirli öznitelik değerlerinden/eğilimlerinden yoksundur. Bu, veri ön işlemenin senaryoya girdiği yerdir - ham verileri temizlemeye, biçimlendirmeye ve düzenlemeye yardımcı olur, böylece onu Makine Öğrenimi modelleri için kullanıma hazır hale getirir. Makine öğreniminde veri ön işlemenin çeşitli adımlarını inceleyelim.
Kariyerinizi hızlandırmak için Dünyanın En İyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zeka alanında İleri Düzey Sertifika Programından çevrimiçi Yapay Zeka Kursuna katılın .
Makine Öğreniminde Veri Ön İşleme Adımları
Machine Learning'de veri ön işlemede yedi önemli adım vardır:
1. Veri kümesini edinin
Veri kümesinin elde edilmesi, makine öğreniminde veri ön işlemenin ilk adımıdır. Machine Learning modelleri oluşturmak ve geliştirmek için öncelikle ilgili veri setini edinmelisiniz. Bu veri kümesi, daha sonra bir veri kümesi oluşturmak için uygun bir biçimde birleştirilen birden çok ve farklı kaynaktan toplanan verilerden oluşacaktır. Veri kümesi biçimleri, kullanım durumlarına göre farklılık gösterir. Örneğin, bir iş veri kümesi tıbbi bir veri kümesinden tamamen farklı olacaktır. Bir iş veri kümesi, ilgili endüstri ve iş verilerini içerirken, tıbbi bir veri kümesi, sağlıkla ilgili verileri içerecektir.
https://www.kaggle.com/uciml/datasets ve https://archive.ics.uci.edu/ml/index.php gibi veri kümelerini indirebileceğiniz birkaç çevrimiçi kaynak vardır . Farklı Python API'leri aracılığıyla veri toplayarak da bir veri seti oluşturabilirsiniz. Veri kümesi hazır olduğunda, onu CSV, HTML veya XLSX dosya biçimlerine koymalısınız.

2. Tüm önemli kitaplıkları içe aktarın
Python, dünya çapında Veri Bilimcileri tarafından en yaygın olarak kullanılan ve aynı zamanda en çok tercih edilen kitaplık olduğundan, Makine Öğreniminde veri ön işleme için Python kitaplıklarının nasıl içe aktarılacağını göstereceğiz. Veri Bilimi için Python kitaplıkları hakkında daha fazla bilgiyi buradan okuyun. Önceden tanımlanmış Python kitaplıkları, belirli veri ön işleme işlerini gerçekleştirebilir. Tüm önemli kitaplıkları içe aktarmak, makine öğreniminde veri ön işlemede ikinci adımdır. Machine Learning'de bu veri ön işleme için kullanılan üç temel Python kitaplığı şunlardır:
- NumPy – NumPy, Python'da bilimsel hesaplama için temel pakettir. Bu nedenle, koda her türlü matematiksel işlemi eklemek için kullanılır. NumPy'yi kullanarak kodunuza çok boyutlu büyük diziler ve matrisler de ekleyebilirsiniz.
- Pandalar – Pandalar, veri işleme ve analizi için mükemmel bir açık kaynaklı Python kütüphanesidir. Veri kümelerini içe aktarmak ve yönetmek için yaygın olarak kullanılır. Python için yüksek performanslı, kullanımı kolay veri yapıları ve veri analiz araçları içerir.
- Matplotlib – Matplotlib, Python'da her türlü grafiği çizmek için kullanılan bir Python 2D çizim kitaplığıdır. Platformlar arasında (IPython kabukları, Jupyter notebook, web uygulama sunucuları, vb.) çok sayıda basılı kopya biçiminde ve etkileşimli ortamlarda yayın kalitesinde rakamlar sunabilir.
Okuyun : Yeni Başlayanlar İçin Makine Öğrenimi Proje Fikirleri
3. Veri kümesini içe aktarın
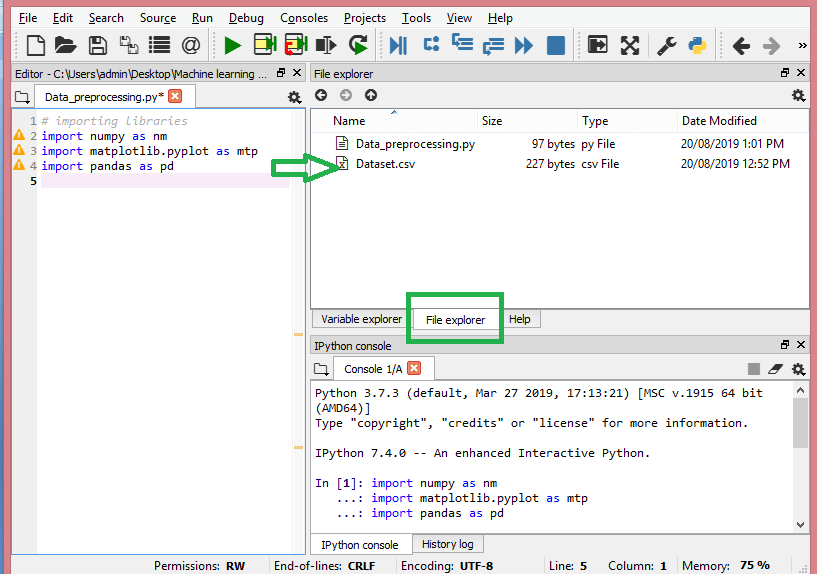
Bu adımda, eldeki ML projesi için topladığınız veri setini/setlerini içe aktarmanız gerekir. Veri kümesini içe aktarmak, makine öğrenmesinde veri ön işlemede önemli adımlardan biridir. Ancak, veri kümelerini/kümelerini içe aktarabilmeniz için geçerli dizini çalışma dizini olarak ayarlamanız gerekir. Spyder IDE'deki çalışma dizinini üç basit adımda ayarlayabilirsiniz:
- Python dosyanızı veri kümesini içeren dizine kaydedin.
- Spyder IDE'de Dosya Gezgini seçeneğine gidin ve gerekli dizini seçin.
- Şimdi, dosyayı çalıştırmak için F5 düğmesine veya Çalıştır seçeneğine tıklayın.
Kaynak
Çalışma dizini bu şekilde görünmelidir.
İlgili veri kümesini içeren çalışma dizinini ayarladıktan sonra, Pandas kitaplığının “read_csv()” işlevini kullanarak veri kümesini içe aktarabilirsiniz. Bu işlev, bir CSV dosyasını (yerel olarak veya bir URL aracılığıyla) okuyabilir ve ayrıca üzerinde çeşitli işlemler gerçekleştirebilir. read_csv() şu şekilde yazılır:
data_set= pd.read_csv('Dataset.csv')
Bu kod satırında, "data_set", veri kümesini depoladığınız değişkenin adını belirtir. İşlev, veri kümesinin adını da içerir. Bu kodu çalıştırdığınızda, veri kümesi başarıyla içe aktarılacaktır.
Veri kümesi içe aktarma işlemi sırasında yapmanız gereken başka bir önemli şey daha vardır: bağımlı ve bağımsız değişkenleri çıkarmak. Her Makine Öğrenimi modeli için, bir veri kümesindeki bağımsız değişkenleri (özellikler matrisi) ve bağımlı değişkenleri ayırmak gerekir.
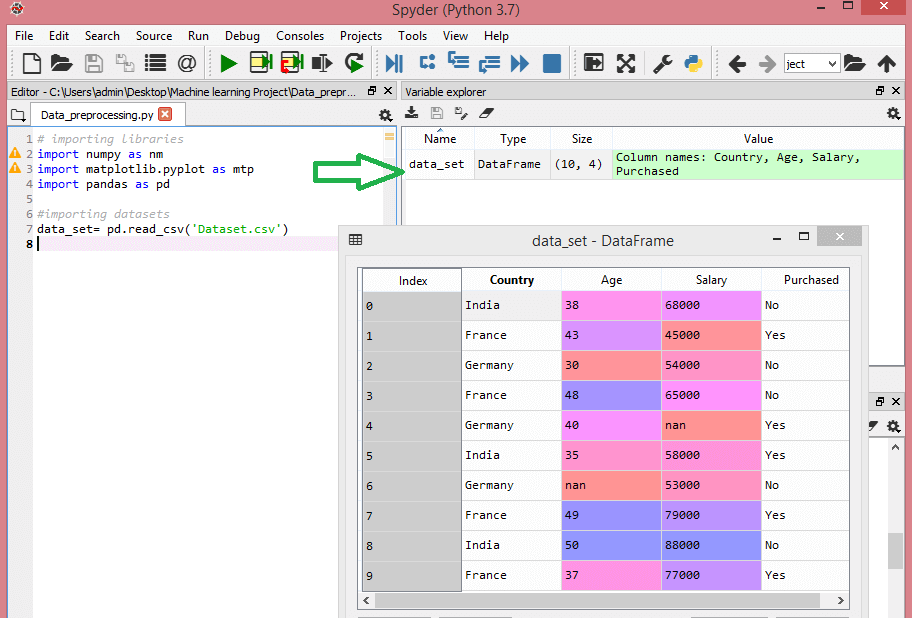
Bu veri kümesini göz önünde bulundurun:
Kaynak
Bu veri seti, ülke, yaş ve maaş olmak üzere üç bağımsız değişken ve satın alınan bir bağımlı değişken içerir.
Bağımsız değişkenler nasıl çıkarılır?
Bağımsız değişkenleri çıkarmak için Pandas kütüphanesinin “iloc[ ]” fonksiyonunu kullanabilirsiniz. Bu işlev, veri kümesinden seçilen satırları ve sütunları çıkarabilir.
x= data_set.iloc[:,:-1].değerler
Yukarıdaki kod satırında, ilk iki nokta üst üste(:) tüm satırları, ikinci iki nokta üst üste(:) tüm sütunları dikkate alır. Bağımlı değişkeni içeren son sütunu dışarıda bırakmanız gerektiğinden kod “:-1” içerir. Bu kodu çalıştırarak, bunun gibi bir özellik matrisini elde edeceksiniz -
[['Hindistan' 38.0 68000.0]
['Fransa' 43.0 45000.0]
['Almanya' 30.0 54000.0]
['Fransa' 48.0 65000.0]
['Almanya' 40.0 nan]
['Hindistan' 35.0 58000.0]
['Almanya' 53000.0]
['Fransa' 49.0 79000.0]
['Hindistan' 50.0 88000.0]
['Fransa' 37.0 77000.0]]
Bağımlı değişken nasıl çıkarılır?
Bağımlı değişkeni çıkarmak için “iloc[ ]” işlevini de kullanabilirsiniz. İşte nasıl yazacağınız:
y= data_set.iloc[:,3].değerler
Bu kod satırı, yalnızca son sütuna sahip tüm satırları dikkate alır. Yukarıdaki kodu çalıştırarak, aşağıdaki gibi bağımlı değişkenler dizisini alacaksınız -
dizi(['Hayır', 'Evet', 'Hayır', 'Hayır', 'Evet', 'Evet', 'Hayır', 'Evet', 'Hayır', 'Evet'],
dtype=nesne)
4. Eksik değerlerin belirlenmesi ve ele alınması
Veri ön işlemede, eksik değerleri belirlemek ve doğru bir şekilde ele almak çok önemlidir, bunu yapmadığınız takdirde verilerden yanlış ve hatalı sonuçlar ve çıkarımlar yapabilirsiniz. Söylemeye gerek yok, bu ML projenizi engelleyecektir.
Temel olarak, eksik verileri işlemenin iki yolu vardır:
- Belirli bir satırı silme – Bu yöntemde, bir özellik için boş değere sahip belirli bir satırı veya değerlerin %75'inden fazlasının eksik olduğu belirli bir sütunu kaldırırsınız. Ancak bu yöntem %100 verimli değildir ve yalnızca veri kümesinde yeterli örnek olduğunda kullanmanız önerilir. Verileri sildikten sonra, herhangi bir yanlılık eki kalmadığından emin olmalısınız.
- Ortalamayı hesaplama – Bu yöntem, yaş, maaş, yıl vb. gibi sayısal verilere sahip özellikler için kullanışlıdır. Burada, eksik bir değer içeren belirli bir özelliğin veya sütunun veya satırın ortalamasını, medyanı veya modunu hesaplayabilir ve eksik değer için sonuç. Bu yöntem, veri kümesine varyans ekleyebilir ve herhangi bir veri kaybı verimli bir şekilde reddedilebilir. Bu nedenle, ilk yönteme (satır/sütun ihmali) göre daha iyi sonuçlar verir. Yaklaştırmanın başka bir yolu da komşu değerlerin sapmasıdır. Ancak bu, doğrusal veriler için en iyi sonucu verir.
Okuyun: Bulut Kullanan Makine Öğrenimi Uygulamaları Uygulamaları
5. Kategorik verilerin kodlanması
Kategorik veriler, veri kümesi içinde belirli kategorilere sahip bilgileri ifade eder. Yukarıda belirtilen veri setinde, ülke ve satın alınan olmak üzere iki kategorik değişken vardır.
Makine Öğrenimi modelleri öncelikle matematiksel denklemlere dayanır. Böylece, denklemlerde yalnızca sayılara ihtiyacınız olacağından, kategorik verileri denklemde tutmanın belirli sorunlara neden olacağını sezgisel olarak anlayabilirsiniz.
Ülke değişkeni nasıl kodlanır?
Veri seti örneğimizde görüldüğü gibi ülke sütunu sorun yaratacağı için onu sayısal değerlere çevirmeniz gerekir. Bunu yapmak için sci-kit öğrenme kitaplığındaki LabelEncoder() sınıfını kullanabilirsiniz. Kod aşağıdaki gibi olacaktır -
#Kategorik veriler
#Ülke Değişkeni için
sklearn.preprocessing'den LabelEncoder'ı içe aktarın
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
Ve çıktı olacak -
Çıkış[15]:
dizi([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=nesne)
Burada LabelEncoder sınıfının değişkenleri rakamlara başarıyla kodladığını görebiliriz. Ancak, yukarıda gösterilen çıktıda 0, 1 ve 2 olarak kodlanmış ülke değişkenleri vardır. Dolayısıyla, ML modeli, üç değişken arasında bir miktar korelasyon olduğunu ve dolayısıyla hatalı çıktı ürettiğini varsayabilir. Bu sorunu ortadan kaldırmak için şimdi Dummy Encoding kullanacağız.
Kukla değişkenler, sonucu değiştirebilecek belirli bir kategorik etkinin yokluğunu veya varlığını belirtmek için 0 veya 1 değerlerini alan değişkenlerdir. Bu durumda, 1 değeri belirli bir sütunda o değişkenin varlığını gösterirken diğer değişkenler 0 değerine ulaşır. Kukla kodlamada, sütun sayısı kategori sayısına eşittir.
Veri kümemiz üç kategoriye sahip olduğundan 0 ve 1 değerlerine sahip üç sütun üretecektir. Dummy Encoding için scikit-learn kitaplığının OneHotEncoder sınıfını kullanacağız. Giriş kodu aşağıdaki gibi olacaktır -
#Ülke Değişkeni için
sklearn.preprocessing'den LabelEncoder, OneHotEncoder'ı içe aktarın
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Kukla değişkenler için kodlama
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()

Bu kodu çalıştırdığınızda aşağıdaki çıktıyı alacaksınız –
dizi([[0.00000000e+00, 0.000000000e+00, 1.000000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.000000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.000000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.000000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.000000000e+00, 0.00000000e+00, 0.00000000e+00, 4.9000000e+01,
7.900000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.000000000e+01,
8.80000000e+04],
[1.000000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
Yukarıda gösterilen çıktıda, tüm değişkenler üç sütuna bölünür ve 0 ve 1 değerlerine kodlanır.
Satın alınan değişken nasıl kodlanır?
Satın alınan ikinci kategorik değişken için LableEncoder sınıfının “labelencoder” nesnesini kullanabilirsiniz. Satın alınan değişkenin her ikisi de 0 ve 1 olarak kodlanmış yalnızca evet veya hayır olmak üzere iki kategorisi olduğundan OneHotEncoder sınıfını kullanmıyoruz.
Bu değişken için giriş kodu şöyle olacaktır:
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
Çıktı olacak -
Çıkış[17]: dizi([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
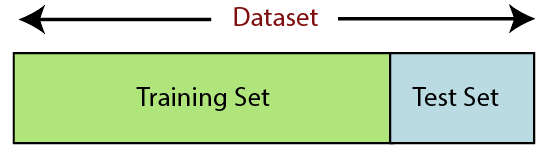
6. Veri kümesini bölme
Veri kümesini bölmek, makine öğreniminde veri ön işlemede bir sonraki adımdır. Machine Learning modeli için her veri seti, eğitim seti ve test seti olmak üzere iki ayrı sete ayrılmalıdır.
Kaynak
Eğitim kümesi, makine öğrenimi modelini eğitmek için kullanılan bir veri kümesinin alt kümesini belirtir. Burada, çıktının zaten farkındasınız. Test seti ise, makine öğrenme modelini test etmek için kullanılan veri setinin alt setidir. ML modeli, sonuçları tahmin etmek için test setini kullanır.
Genellikle, veri kümesi 70:30 oranına veya 80:20 oranına bölünür. Bu, modeli eğitmek için verilerin %70 veya %80'ini alırken geri kalan %30 veya %20'yi dışarıda bıraktığınız anlamına gelir. Bölme işlemi, söz konusu veri kümesinin şekline ve boyutuna göre değişir.
Veri kümesini bölmek için aşağıdaki kod satırını yazmanız gerekir –
sklearn.model_selection'dan train_test_split'i içe aktarın
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Burada ilk satır, veri kümesinin dizilerini rastgele tren ve test alt kümelerine böler. İkinci kod satırı dört değişken içerir:
- x_train – eğitim verileri için özellikler
- x_test – test verileri için özellikler
- y_train – eğitim verileri için bağımlı değişkenler
- y_test – verileri test etmek için bağımsız değişken
Bu nedenle, train_test_split() işlevi, ilk ikisi veri dizileri için olan dört parametre içerir. test_size işlevi, test kümesinin boyutunu belirtir. test_size belki .5, .3 veya .2 – bu, eğitim ve test setleri arasındaki bölme oranını belirtir. Son parametre olan "random_state", çıktının her zaman aynı olması için rastgele bir üreteç için tohum ayarlar.
7. Özellik ölçeklendirme
Özellik ölçeklendirme , Machine Learning'de veri ön işlemenin sonunu işaretler. Bir veri kümesinin bağımsız değişkenlerini belirli bir aralıkta standartlaştırma yöntemidir. Başka bir deyişle, özellik ölçekleme, değişkenlerin aralığını sınırlar, böylece bunları ortak zeminlerde karşılaştırabilirsiniz.
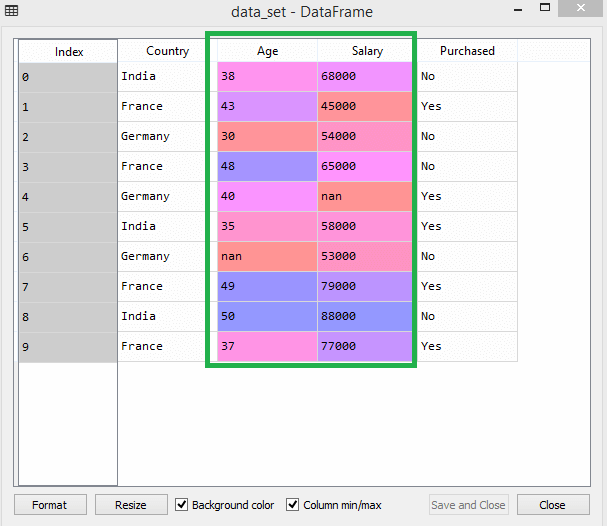
Örneğin bu veri kümesini düşünün -
Kaynak
Veri setinde yaş ve maaş sütunlarının aynı ölçeğe sahip olmadığını fark edebilirsiniz. Böyle bir senaryoda, yaş ve maaş sütunlarından herhangi iki değer hesaplarsanız, maaş değerleri yaş değerlerine hakim olacak ve yanlış sonuçlar verecektir. Bu nedenle, Machine Learning için özellik ölçeklendirmesi yaparak bu sorunu ortadan kaldırmalısınız.
Çoğu ML modeli, şu şekilde temsil edilen Öklid Mesafesine dayanır:
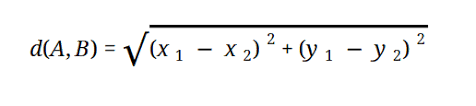
Kaynak
Makine Öğrenimi'nde özellik ölçeklendirmeyi iki şekilde gerçekleştirebilirsiniz:
Standardizasyon
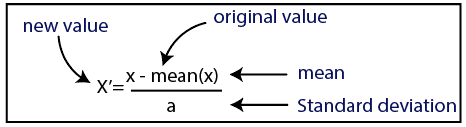
Kaynak
normalleştirme
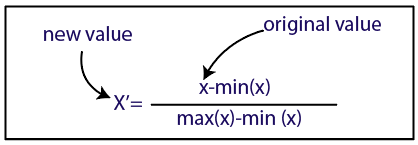
Kaynak
Veri setimiz için standardizasyon yöntemini kullanacağız. Bunu yapmak için, aşağıdaki kod satırını kullanarak sci-kit-learn kitaplığının StandardScaler sınıfını içe aktaracağız:
sklearn.preprocessing'den içe aktarma StandardScaler
Bir sonraki adım, bağımsız değişkenler için StandardScaler sınıfının nesnesini oluşturmak olacaktır. Bundan sonra, aşağıdaki kodu kullanarak eğitim veri kümesini sığdırabilir ve dönüştürebilirsiniz:
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
Test veri kümesi için, transform() işlevini doğrudan uygulayabilirsiniz (fit_transform() işlevini kullanmanıza gerek yoktur, çünkü bu zaten eğitim kümesinde yapılmıştır). Kod aşağıdaki gibi olacaktır -
x_test= st_x.transform(x_test)
Test veri kümesinin çıktısı, x_train ve x_test için ölçeklenmiş değerleri şu şekilde gösterecektir:
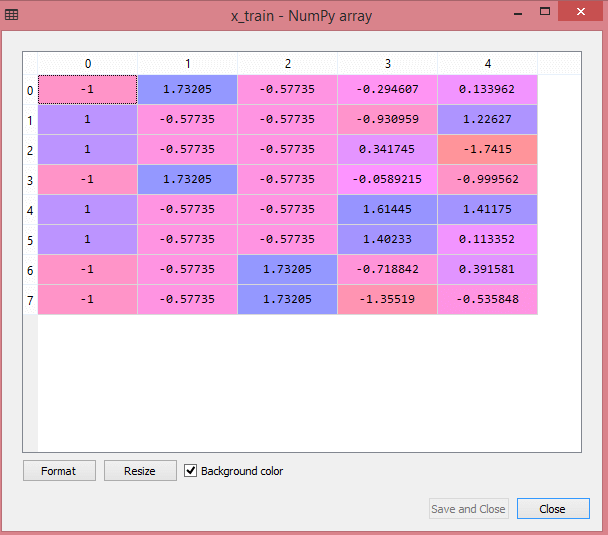
Kaynak
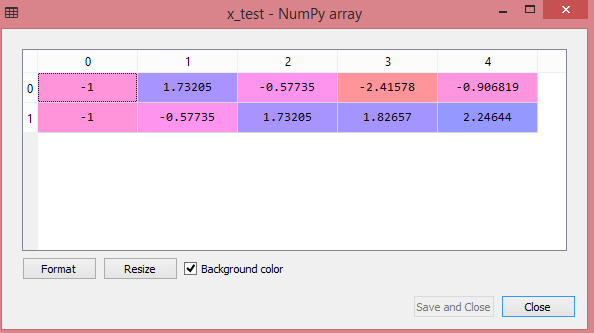
Kaynak
Çıktıdaki tüm değişkenler -1 ve 1 değerleri arasında ölçeklenir.
Şimdi, şimdiye kadar gerçekleştirdiğimiz tüm adımları birleştirmek için şunları elde edersiniz:
# kitaplıkları içe aktarma
numpy'yi nm olarak içe aktar
matplotlib.pyplot'u mtp olarak içe aktar
pandaları pd olarak içe aktar
#veri kümelerini içe aktarma
data_set= pd.read_csv('Dataset.csv')
#Bağımsız Değişken Çıkarma
x= data_set.iloc[:, :-1].değerler
#Bağımlı değişken ayıklanıyor
y= data_set.iloc[:, 3].değerler
#eksik verileri işleme (Eksik verileri ortalama değerle değiştirme)
sklearn.preprocessing'den Imputer'ı içe aktarın
imputer= Imputer(missing_values ='NaN', strateji='ortalama', eksen = 0)
#İnputer nesnesini bağımsız değişkenlere x uydurmak.
imputerimputer= imputer.fit(x[:, 1:3])
#Eksik verileri hesaplanan ortalama değerle değiştirme
x[:, 1:3]= imputer.transform(x[:, 1:3])
#Ülke Değişkeni için
sklearn.preprocessing'den LabelEncoder, OneHotEncoder'ı içe aktarın
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Kukla değişkenler için kodlama
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#satın alınan değişken için kodlama
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Veri kümesini eğitim ve test kümesine bölme.
sklearn.model_selection'dan train_test_split'i içe aktarın
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Özellik Veri kümelerinin Ölçeklendirilmesi
sklearn.preprocessing'den içe aktarma StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Yani, kısaca Makine Öğreniminde veri işleme budur!
IIT Delhi'nin, upGrad ile birlikte Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programını inceleyebilirsiniz. IIT Delhi , Hindistan'daki en prestijli kurumlardan biridir. Konularında en iyi olan 500'den fazla kurum içi öğretim üyesi ile.
Veri ön işlemenin önemi nedir?
Hatalar, fazlalıklar, eksik değerler ve tutarsızlıkların tümü veri kümesinin bütünlüğünü tehlikeye attığından, daha doğru bir sonuç için hepsini ele almalısınız. Müşterilerinizin satın almalarıyla ilgilenmek üzere bir Makine Öğrenimi sistemini eğitmek için kusurlu bir veri kümesi kullandığınızı varsayalım. Sistemin, kötü bir kullanıcı deneyimiyle sonuçlanan önyargılar ve sapmalar oluşturması muhtemeldir. Sonuç olarak, bu verileri amacınız için kullanmadan önce, mümkün olduğu kadar düzenli ve 'temiz' olmalıdır. Karşılaştığınız zorluğun türüne bağlı olarak, çok sayıda seçenek vardır.
Veri temizleme nedir?
Veri kümelerinizde neredeyse kesinlikle eksik ve gürültülü veriler olacaktır. Veri toplama prosedürü ideal olmadığı için, birçok işe yaramaz ve eksik bilgiye sahip olacaksınız. Veri temizleme, bu sorunla başa çıkmak için kullanmanız gereken yoldur. Bu iki kategoriye ayrılabilir. İlki, eksik verilerle nasıl başa çıkılacağını tartışır. Veri toplamanın bu bölümünde (bir demet olarak adlandırılır) eksik değerleri yok saymayı seçebilirsiniz. İkinci veri temizleme yöntemi, gürültülü olan veriler içindir. Tüm sürecin sorunsuz yürümesini istiyorsanız, sistemler tarafından okunamayan gereksiz verilerden kurtulmak çok önemlidir.
Veri dönüştürme ve azaltma ile ne demek istiyorsunuz?
Veri ön işleme, endişeleri giderdikten sonra dönüşüm aşamasına geçer. Verileri analiz için ilgili biçimlere dönüştürmek için kullanırsınız. Normalleştirme, öznitelik seçimi, ayrıklaştırma ve Kavram Hiyerarşisi Oluşturma, bunu başarmak için kullanılabilecek yaklaşımlardan bazılarıdır. Otomatik yöntemler için bile, büyük veri kümelerini gözden geçirmek uzun zaman alabilir. Bu nedenle veri azaltma aşaması çok önemlidir: en önemli bilgilerle sınırlayarak veri kümelerinin boyutunu azaltır, depolama verimliliğini artırırken bunlarla çalışmanın finansal ve zaman maliyetlerini düşürür.