
WordPress ile “Bir Kez Oluşturun, Her Yerde Yayınlayın”
Yayınlanan: 2022-03-10COPE, içeriğimizi web sitesi, e-posta, uygulamalar ve diğerleri gibi farklı ortamlarda yayınlamak için gereken iş miktarını azaltmaya yönelik bir stratejidir. İlk olarak NPR'nin öncülük ettiği içerik için tüm farklı ortamlar için kullanılabilecek tek bir gerçek kaynağı oluşturarak amacına ulaşır.
Her yerde işe yarayan içeriğe sahip olmak, her ortamın kendi gereksinimleri olacağı için önemsiz bir iş değildir. Örneğin, HTML web için içerik yazdırmak için geçerliyken, bu dil bir iOS/Android uygulaması için geçerli değildir. Benzer şekilde, web için HTML'mize sınıflar ekleyebiliriz, ancak bunların e-posta için stillere dönüştürülmesi gerekir.
Bu bilmecenin çözümü, biçimi içerikten ayırmaktır: İçeriğin sunumu ve anlamı birbirinden ayrılmalıdır ve gerçeğin tek kaynağı olarak yalnızca anlam kullanılmalıdır. Sunum daha sonra başka bir katmana eklenebilir (seçilen ortama özel).
Örneğin, aşağıdaki HTML kodu parçası göz önüne alındığında, <p> çoğunlukla web için geçerli olan bir HTML etiketidir ve class="align-center" özniteliği sunumdur (bir öğeyi "ortaya" yerleştirmek, ekran tabanlı ortam, ancak Amazon Alexa gibi ses tabanlı bir ortam için değil):
<p class="align-center">Hello world!</p>Bu nedenle, bu içerik parçası tek bir doğruluk kaynağı olarak kullanılamaz ve aşağıdaki JSON kodu parçası gibi anlamı sunumdan ayıran bir biçime dönüştürülmelidir:
{ content: "Hello world!", placement: "center", type: "paragraph" }Bu kod parçası, web için kullanmak üzere HTML kodunu bir kez daha yeniden oluşturabileceğimiz ve diğer ortamlar için uygun bir format temin edebileceğimizden, içerik için tek bir doğruluk kaynağı olarak kullanılabilir.
Neden WordPress
WordPress, birkaç nedenden dolayı COPE stratejisini uygulamak için idealdir:
- Çok yönlüdür.
WordPress veritabanı modeli, sabit, katı bir içerik modeli tanımlamaz; aksine, çok yönlülük için yaratılmıştır, meta alanı kullanılarak çeşitli içerik modelleri oluşturmaya olanak tanır ve dört farklı varlık için ek veri parçalarının depolanmasına izin verir: gönderiler ve özel gönderi türleri, kullanıcılar, yorumlar ve sınıflandırmalar ( etiketler ve kategoriler). - Güçlüdür.
WordPress, bir CMS (İçerik Yönetim Sistemi) olarak öne çıkıyor ve eklenti ekosistemi, yeni işlevlerin kolayca eklenmesini sağlıyor. - Yaygındır.
Web sitelerinin 1/3'ünün WordPress üzerinde çalıştığı tahmin edilmektedir. Ardından, web üzerinde çalışan oldukça fazla sayıda insan WordPress'i biliyor ve kullanabiliyor. Sadece geliştiriciler değil, aynı zamanda blogcular, satıcılar, pazarlama personeli vb. O zaman, teknik geçmişleri ne olursa olsun birçok farklı paydaş, tek gerçek kaynağı olarak hareket eden içeriği üretebilecektir. - Başsız.
Başsızlık, içeriği sunum katmanından ayırma yeteneğidir ve COPE'nin uygulanması için temel bir özelliktir (verileri farklı ortamlara besleyebilmek için).
WP REST API'yi sürüm 4.7'den başlayarak çekirdeğe dahil ettiğinden ve daha belirgin bir şekilde sürüm 5.0'da Gutenberg'in piyasaya sürülmesinden bu yana (bunun için bol miktarda REST API uç noktasının uygulanması gerekiyordu), WordPress başsız bir CMS olarak kabul edilebilir, çünkü çoğu WordPress içeriği herhangi bir yığın üzerine kurulu herhangi bir uygulama tarafından bir REST API aracılığıyla erişilebilir.
Ek olarak, yakın zamanda oluşturulan WPGraphQL, WordPress ve GraphQL'yi entegre ederek, giderek daha popüler hale gelen bu API'yi kullanarak WordPress'ten herhangi bir uygulamaya içerik beslemeyi sağlar. Son olarak, kendi projem PoP, yakın zamanda WordPress verilerini REST, GraphQL veya PoP yerel formatları olarak dışa aktarmaya izin veren bir WordPress API uygulaması ekledi. - COPE'nin uygulanmasına büyük ölçüde yardımcı olan blok tabanlı bir düzenleyici olan Gutenberg'e sahiptir, çünkü blok kavramına dayanmaktadır (aşağıdaki bölümlerde açıklandığı gibi).
Bilgileri Temsil Etmek İçin Bloklara Karşı Bloblar
Blob, veri tabanında hep birlikte depolanan tek bir bilgi birimidir. Örneğin, aşağıdaki blog gönderisini bilgi depolamak için bloblara dayanan bir CMS'ye yazmak, blog gönderisi içeriğini aynı içeriği içeren tek bir veritabanı girişinde depolayacaktır:
<p>Look at this wonderful tango:</p> <figure> <iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> <figcaption>An exquisite tango performance</figcaption> </figure>Takdir edilebileceği gibi, bu blog gönderisindeki önemli bilgilere (paragraftaki içerik ve URL, Youtube videosunun boyutları ve nitelikleri gibi) kolayca erişilemiyor: Bunlardan herhangi birini almak istiyorsak kendi başlarına, onları çıkarmak için HTML kodunu ayrıştırmamız gerekir - ki bu ideal bir çözüm olmaktan uzaktır.
Bloklar farklı davranır. Bilgileri bir blok listesi olarak temsil ederek içeriği daha semantik ve erişilebilir bir şekilde saklayabiliriz. Her blok, kendi içeriğini ve türüne bağlı olabilen kendi özelliklerini iletir (örneğin, bir paragraf mı yoksa bir video mu?).
Örneğin, yukarıdaki HTML kodu aşağıdaki gibi bir blok listesi olarak gösterilebilir:
{ [ type: "paragraph", content: "Look at this wonderful tango:" ], [ type: "embed", provider: "Youtube", url: "https://www.youtube.com/embed/sxm3Xyutc1s", width: 951, height: 535, frameborder: 0, allowfullscreen: true, allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture", caption: "An exquisite tango performance" ] } Bilgiyi temsil etmenin bu yolu sayesinde, herhangi bir veri parçasını kendi başına kolayca kullanabilir ve görüntülenmesi gereken belirli ortama uyarlayabiliriz. Örneğin, bir araba eğlence sisteminde göstermek için blog gönderisindeki tüm videoları çıkarmak istiyorsak, tüm bilgi bloklarını yineleyebilir, type="embed" ve provider="Youtube" ile olanları seçebilir ve aşağıdakileri ayıklayabiliriz. onlardan URL. Benzer şekilde, videoyu bir Apple Watch'ta göstermek istiyorsak, videonun boyutlarıyla ilgilenmemize gerek yok, böylece width ve height niteliklerini basit bir şekilde yok sayabiliriz.
Gutenberg Blokları Nasıl Uygular?
WordPress sürüm 5.0'dan önce WordPress, gönderi içeriğini veritabanında depolamak için bloblar kullanırdı. 5.0 sürümünden itibaren WordPress, blok tabanlı bir düzenleyici olan Gutenberg ile birlikte gelir ve yukarıda bahsedilen içeriği işlemek için gelişmiş bir yol sağlar ve bu, COPE'nin uygulanmasına yönelik bir atılımı temsil eder. Ne yazık ki, Gutenberg bu özel kullanım durumu için tasarlanmamıştır ve bilgilerin temsili, bloklar için açıklanandan farklıdır ve bu da, uğraşmamız gereken çeşitli rahatsızlıklara neden olur.
Önce yukarıda açıklanan blog gönderisinin Gutenberg aracılığıyla nasıl kaydedildiğine bir göz atalım:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->Bu kod parçasından aşağıdaki gözlemleri yapabiliriz:
Bloklar Hep Birlikte Aynı Veritabanı Girişinde Kaydedilir
Yukarıdaki kodda iki blok vardır:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube --> Veritabanında kendilerine ait bir girişi olan ve doğrudan kimlikleri aracılığıyla başvurulabilen global ("yeniden kullanılabilir" olarak da adlandırılır) bloklar dışında, tüm bloklar blog gönderisinin wp_posts tablosundaki girişinde birlikte kaydedilir.
Bu nedenle, belirli bir blok için bilgi almak için önce içeriği ayrıştırmamız ve tüm blokları birbirinden ayırmamız gerekecek. Uygun bir şekilde, WordPress tam da bunu yapmak için parse_blocks($content) işlevini sağlar. Bu işlev, blog gönderisi içeriğini (HTML biçiminde) içeren bir dize alır ve içerilen tüm bloklar için verileri içeren bir JSON nesnesi döndürür.
Blok Türü ve Nitelikleri HTML Yorumları İle İletilir
Her blok bir başlangıç etiketi <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> ve bir bitiş etiketi <!-- /wp:{block-type} --> ile sınırlandırılmıştır. <!-- /wp:{block-type} --> hangi (HTML yorumları olarak), bu bilgilerin bir web sitesinde görüntülenirken görünmemesini sağlar. Ancak, blog gönderisini doğrudan başka bir ortamda görüntüleyemiyoruz, çünkü HTML yorumu bozuk içerik olarak görünebilir. Ancak bu çok önemli değil, çünkü içeriği parse_blocks($content) işlevi aracılığıyla ayrıştırdıktan sonra, HTML yorumları kaldırılır ve bir JSON nesnesi olarak doğrudan blok verileriyle çalışabiliriz.
Bloklar HTML İçerir
Paragraf bloğunun içeriği olarak "Look at this wonderful tango:" yerine "<p>Look at this wonderful tango:</p>" " vardır. Bu nedenle, diğer ortamlar için yararlı olmayan HTML kodunu ( <p> ve </p> etiketleri) içerir ve bu nedenle örneğin PHP işlevi strip_tags($content) aracılığıyla kaldırılması gerekir.
Etiketleri çıkarırken, <strong> ve <em> etiketleri gibi (yalnızca ekran tabanlı bir ortam için geçerli olan <b> ve <i> karşılıkları yerine) semantik bilgileri açıkça ileten HTML etiketlerini tutabiliriz ve diğer tüm etiketleri kaldırın. Bunun nedeni, anlamsal etiketlerin diğer ortamlar için de doğru şekilde yorumlanabilme şansının yüksek olmasıdır (örneğin, Amazon Alexa <strong> ve <em> etiketlerini tanıyabilir ve bir metin parçasını okurken sesini ve tonlamasını buna göre değiştirebilir). Bunu yapmak için, izin verilen etiketleri içeren 2. bir parametreyle strip_tags işlevini çağırırız ve kolaylık sağlamak için onu bir sarma işlevinin içine yerleştiririz:
function strip_html_tags($content) { return strip_tags($content, '<strong><em>'); }Videonun Altyazısı Bir Nitelik Olarak Değil, HTML İçinde Kaydedilmiştir
Youtube video bloğunda görülebileceği gibi, "An exquisite tango performance" başlığı HTML kodunun içinde ( <figcaption /> etiketiyle çevrelenmiştir) depolanır, ancak JSON kodlu öznitelikler nesnesinin içinde saklanmaz. Sonuç olarak, başlığı çıkarmak için, örneğin normal bir ifade aracılığıyla blok içeriğini ayrıştırmamız gerekecek:
function extract_caption($content) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; }Bu, bir Gutenberg bloğundan tüm meta verileri çıkarmak için üstesinden gelmemiz gereken bir engeldir. Bu, birkaç blokta gerçekleşir; Tüm meta veri parçaları öznitelik olarak kaydedilmediğinden, önce bu meta veri parçalarının hangileri olduğunu belirlemeli ve ardından bunları blok blok ve parça bazında çıkarmak için HTML içeriğini ayrıştırmalıyız.
COPE ile ilgili olarak, bu, gerçekten optimal bir çözüme sahip olmak için boşa giden bir şansı temsil eder. Alternatif seçeneğin de ideal olmadığı tartışılabilir, çünkü bilgileri çoğaltacak, hem HTML içinde hem de bir öznitelik olarak depolayacak ve bu da DRY ( D on't Repeat Y yourself ) ilkesini ihlal edecektir. Ancak, bu ihlal zaten gerçekleşiyor: Örneğin className niteliği, HTML niteliği class altında içeriğin içinde de yazdırılan "wp-embed-aspect-16-9 wp-has-aspect-ratio" değerini içeriyor.
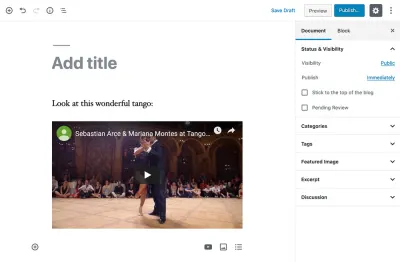
COPE'nin Uygulanması
Not: Aşağıda açıklanan tüm kodlar da dahil olmak üzere bu işlevi WordPress eklentisi Blok Meta Verileri olarak yayınladım. COPE'un gücünün tadına varabilmeniz için onu yükleyebilir ve onunla oynayabilirsiniz. Kaynak kodu bu GitHub deposunda mevcuttur.
Artık bir bloğun iç temsilinin neye benzediğini bildiğimize göre, Gutenberg aracılığıyla COPE'yi uygulamaya geçelim. Prosedür aşağıdaki adımları içerecektir:
-
parse_blocks($content)işlevi, iç içe düzeylere sahip bir JSON nesnesi döndürdüğü için, önce bu yapıyı basitleştirmemiz gerekir. - Tüm blokları yineliyoruz ve her biri için meta veri parçalarını tanımlıyor ve onları süreçte orta-agnostik bir formata dönüştürerek ayıklıyoruz. Yanıta hangi özniteliklerin ekleneceği blok türüne göre değişiklik gösterebilir.
- Sonunda verileri bir API (REST/GraphQL/PoP) aracılığıyla kullanılabilir hale getiriyoruz.
Bu adımları tek tek uygulayalım.
1. JSON Nesnesinin Yapısının Basitleştirilmesi
parse_blocks($content) işlevinden döndürülen JSON nesnesi, normal blok verilerinin birinci düzeyde göründüğü, ancak başvurulan yeniden kullanılabilir bir bloğa ilişkin verilerin eksik olduğu (yalnızca başvuru bloğu için veriler eklendiği) iç içe geçmiş bir mimariye sahiptir, ve iç içe bloklar (diğer blokların içine eklenir) ve gruplanmış bloklar (birkaç bloğun birlikte gruplanabileceği) için veriler 1 veya daha fazla alt düzey altında görünür. Bu mimari, gönderi içeriğindeki tüm bloklardan gelen blok verilerinin işlenmesini zorlaştırır, çünkü bir tarafta bazı veriler eksiktir ve diğer tarafta verinin kaç seviye altında bulunduğunu önceden bilmeyiz. Ayrıca, hiçbir içerik içermeyen ve güvenli bir şekilde göz ardı edilebilecek her blok çiftinin yerleştirildiği bir blok bölücü vardır.
Örneğin, bir basit blok, bir global blok, bir basit blok içeren bir iç içe blok ve bir grup basit blok içeren bir gönderiden elde edilen yanıt, bu sırayla aşağıdaki gibidir:
[ // Simple block { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Reference to reusable block { "blockName": "core/block", "attrs": { "ref": 218 }, "innerBlocks": [], "innerHTML": "", "innerContent": [] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Nested block { "blockName": "core/columns", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Block group { "blockName": "core/group", "attrs": [], // Contained grouped blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] } ]Tüm verilerin birinci düzeyde olması daha iyi bir çözümdür, bu nedenle tüm blok verilerinin yinelenmesi mantığı büyük ölçüde basitleştirilmiştir. Bu nedenle, bu yeniden kullanılabilir/iç içe/gruplanmış bloklar için verileri getirmeli ve ilk seviyeye de eklemeliyiz. Yukarıdaki JSON kodunda görüldüğü gibi:
- Boş bölücü blok,
NULLdeğerine sahip"blockName"özelliğine sahip - Yeniden kullanılabilir bir bloğa referans,
$block["attrs"]["ref"]ile tanımlanır - Yuvalanmış ve grup blokları, içerdiği blokları
$block["innerBlocks"]altında tanımlar
Bu nedenle, aşağıdaki PHP kodu boş bölücü blokları kaldırır, yeniden kullanılabilir/iç içe/gruplanmış blokları tanımlar ve verilerini birinci düzeye ekler ve tüm alt düzeylerdeki tüm verileri kaldırır:
/** * Export all (Gutenberg) blocks' data from a WordPress post */ function get_block_data($content, $remove_divider_block = true) { // Parse the blocks, and convert them into a single-level array $ret = []; $blocks = parse_blocks($content); recursively_add_blocks($ret, $blocks); // Maybe remove blocks without name if ($remove_divider_block) { $ret = remove_blocks_without_name($ret); } // Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated) foreach ($ret as &$block) { unset($block['innerBlocks']); } return $ret; } /** * Remove the blocks without name, such as the empty block divider */ function remove_blocks_without_name($blocks) { return array_values(array_filter( $blocks, function($block) { return $block['blockName']; } )); } /** * Add block data (including global and nested blocks) into the first level of the array */ function recursively_add_blocks(&$ret, $blocks) { foreach ($blocks as $block) { // Global block: add the referenced block instead of this one if ($block['attrs']['ref']) { $ret = array_merge( $ret, recursively_render_block_core_block($block['attrs']) ); } // Normal block: add it directly else { $ret[] = $block; } // If it contains nested or grouped blocks, add them too if ($block['innerBlocks']) { recursively_add_blocks($ret, $block['innerBlocks']); } } } /** * Function based on `render_block_core_block` */ function recursively_render_block_core_block($attributes) { if (empty($attributes['ref'])) { return []; } $reusable_block = get_post($attributes['ref']); if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) { return []; } if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) { return []; } return get_block_data($reusable_block->post_content); } Gönderi içeriğini ( $post->post_content ) parametre olarak geçiren get_block_data($content) işlevini çağırarak, şimdi aşağıdaki yanıtı alıyoruz:
[[ { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n", "innerContent": [ "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n" ] }, { "blockName": "core/columns", "attrs": [], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] }, { "blockName": "core/group", "attrs": [], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ] Kesinlikle gerekli olmasa da, belirli bir gönderide hangi blokların bulunduğunu ve bunların nasıl olduğunu kolayca anlamamızı sağlayacak olan get_block_data($content) yeni işlevimizin sonucunu çıkarmak için bir REST API uç noktası oluşturmak çok yararlıdır. yapılandırılmış. Aşağıdaki kod, /wp-json/block-metadata/v1/data/{POST_ID} altına böyle bir uç nokta ekler:

/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }
Eylem halinde görmek için, bu gönderi için verileri dışa aktaran bu bağlantıya göz atın.
2. Tüm Blok Meta Verilerini Orta-Agnostik Bir Formata Çıkarma
Bu aşamada elimizde COPE'a uygun olmayan HTML kodu içeren blok verilerimiz bulunmaktadır. Bu nedenle, her blok için anlamsal olmayan HTML etiketlerini, onu orta-agnostik bir biçime dönüştürmek için çıkarmamız gerekir.
Blok tipi bazında çıkarılması gereken özniteliklerin hangileri olduğuna karar verebiliriz (örneğin, "paragraph" blokları için metin hizalama özelliğini, "youtube embed" bloğu için video URL özelliğini vb.) .
Daha önce gördüğümüz gibi, tüm öznitelikler aslında blok öznitelikleri olarak değil, bloğun iç içeriğinde kaydedilir, bu nedenle, bu durumlarda, bu meta veri parçalarını çıkarmak için HTML içeriğini normal ifadeler kullanarak ayrıştırmamız gerekecek.
WordPress çekirdeği aracılığıyla gönderilen tüm blokları inceledikten sonra, aşağıdakiler için meta veri çıkarmamaya karar verdim:
"core/columns""core/column""core/cover" | Bunlar yalnızca ekran tabanlı ortamlar için geçerlidir ve (iç içe bloklar) başa çıkmak zordur. |
"core/html" | Bu sadece web için mantıklı. |
"core/table""core/button""core/media-text" | Verilerini orta-agnostik bir tarzda nasıl temsil edeceğime ya da mantıklı olup olmadığına dair hiçbir fikrim yoktu. |
Bu bana, meta verilerini çıkarmaya devam edeceğim aşağıdaki blokları bırakıyor:
-
'core/paragraph' -
'core/image' -
'core-embed/youtube'(tüm'core-embed'bloklarının bir temsilcisi olarak) -
'core/heading' -
'core/gallery' -
'core/list' -
'core/audio' -
'core/file' -
'core/video' -
'core/code' -
'core/preformatted' -
'core/quote've'core/pullquote' -
'core/verse'
Meta verileri ayıklamak için, her blok için blok verilerini içeren bir dizi alan get_block_metadata($block_data) işlevini yaratırız (yani daha önce uygulanan get_block_data ) ve blok türüne bağlı olarak ( "blockName" özelliği altında sağlanır) ), hangi niteliklerin gerekli olduğuna ve bunların nasıl çıkarılacağına karar verir:
/** * Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post */ function get_block_metadata($block_data) { $ret = []; foreach ($block_data as $block) { $blockMeta = null; switch ($block['blockName']) { case ...: $blockMeta = ... break; case ...: $blockMeta = ... break; ... } if ($blockMeta) { $ret[] = [ 'blockName' => $block['blockName'], 'meta' => $blockMeta, ]; } } return $ret; }Her blok türü için meta verileri tek tek çıkarmaya devam edelim:
“core/paragraph”
HTML etiketlerini içerikten kaldırmanız ve sondaki kesme çizgilerini kaldırmanız yeterlidir.
case 'core/paragraph': $blockMeta = [ 'content' => trim(strip_html_tags($block['innerHTML'])), ]; break; 'core/image'
Blok, ya yüklenen bir medya dosyasına atıfta bulunan bir kimliğe sahiptir ya da değilse, görüntü kaynağının <img src="..."> altından çıkarılması gerekir. Birkaç öznitelik (başlık, linkDestination, link, hizalama) isteğe bağlıdır.
case 'core/image': $blockMeta = []; // If inserting the image from the Media Manager, it has an ID if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) { $blockMeta['img'] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } elseif ($src = extract_image_src($block['innerHTML'])) { $blockMeta['src'] = $src; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } if ($linkDestination = $block['attrs']['linkDestination']) { $blockMeta['linkDestination'] = $linkDestination; if ($link = extract_link($block['innerHTML'])) { $blockMeta['link'] = $link; } } if ($align = $block['attrs']['align']) { $blockMeta['align'] = $align; } break; extract_image_src , extract_caption ve extract_link işlevlerini oluşturmak mantıklıdır, çünkü düzenli ifadeleri birkaç blok için tekrar tekrar kullanılacaktır. Lütfen Gutenberg'deki bir başlığın bağlantılar ( <a href="..."> ) içerebileceğini unutmayın, ancak strip_html_tags bunlar başlıktan kaldırılır.
Üzücü olsa da, web dışı platformlarda çalışacak bir bağlantı garanti edemediğimiz için bu uygulamayı kaçınılmaz buluyorum. Bu nedenle, içerik farklı ortamlar için kullanılabildiğinden evrensellik kazanıyor olsa da, özgünlüğünü de kaybediyor, bu nedenle kalitesi belirli bir platform için oluşturulmuş ve özelleştirilmiş içeriğe göre daha düşük.
function extract_caption($innerHTML) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; } function extract_link($innerHTML) { $matches = []; preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches); if ($link = $matches[1]) { return $link; } return null; } function extract_image_src($innerHTML) { $matches = []; preg_match('/<img src="(.*?)"/', $innerHTML, $matches); if ($src = $matches[1]) { return $src; } return null; } 'core-embed/youtube'
Video URL'sini blok özniteliklerinden alın ve varsa altyazısını HTML içeriğinden çıkarın.
case 'core-embed/youtube': $blockMeta = [ 'url' => $block['attrs']['url'], ]; if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break; 'core/heading'
Hem başlık boyutu (h1, h2, …, h6) hem de başlık metni nitelik değildir, bu nedenle bunlar HTML içeriğinden alınmalıdır. Lütfen, başlık için HTML etiketini döndürmek yerine, size özniteliğinin, daha agnostik olan ve web dışı platformlar için daha anlamlı olan eşdeğer bir temsil olduğuna dikkat edin.
case 'core/heading': $matches = []; preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches); $sizes = [ null, 'xxl', 'xl', 'l', 'm', 'sm', 'xs', ]; $blockMeta = [ 'size' => $sizes[$matches[1]], 'heading' => $matches[2], ]; break; 'core/gallery'
Ne yazık ki, resim galerisi için her bir resimden resim yazısı çıkaramadım, çünkü bunlar nitelik değildir ve bunları basit bir normal ifadeyle çıkarmak başarısız olabilir: Birinci ve üçüncü öğeler için bir resim yazısı varsa, ancak hiçbiri yoksa ikincisi, o zaman hangi resim yazısının hangi resme karşılık geldiğini bilemezdim (ve karmaşık bir regex oluşturmak için zaman ayırmadım). Aynı şekilde, aşağıdaki mantıkta her zaman "full" görüntü boyutunu alıyorum, ancak durum böyle olmak zorunda değil ve daha uygun boyutun nasıl çıkarılabileceğinin farkında değilim.
case 'core/gallery': $imgs = []; foreach ($block['attrs']['ids'] as $img_id) { $img = wp_get_attachment_image_src($img_id, 'full'); $imgs[] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } $blockMeta = [ 'imgs' => $imgs, ]; break; 'core/list'
Basitçe <li> öğelerini bir dizi öğeye dönüştürün.
case 'core/list': $matches = []; preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches); if ($items = $matches[1]) { $blockMeta = [ 'items' => array_map('strip_html_tags', $items), ]; } break; 'core/audio'
Karşılık gelen yüklenen medya dosyasının URL'sini alın.
case 'core/audio': $blockMeta = [ 'src' => wp_get_attachment_url($block['attrs']['id']), ]; break; 'core/file'
Dosyanın URL'si bir öznitelik olsa da, metni iç içerikten çıkarılmalıdır.
case 'core/file': $href = $block['attrs']['href']; $matches = []; preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches); $blockMeta = [ 'href' => $href, 'text' => strip_html_tags($matches[1]), ]; break; 'core/video'
Videonun normal bir ifadeyle nasıl oynatılacağını yapılandırmak için video URL'sini ve tüm özellikleri edinin. Gutenberg, bu özelliklerin kodda yazdırılma sırasını değiştirirse, bu normal ifade çalışmayı durduracak ve bu, doğrudan blok öznitelikleri aracılığıyla meta veri eklememe sorunlarından birini ortaya çıkaracaktır.
case 'core/video': $matches = []; preg_match('/ 'core/code'
Simply extract the code from within <code /> .
case 'core/code': $matches = []; preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches); $blockMeta = [ 'code' => $matches[1], ]; break; 'core/preformatted'
Similar to <code /> , but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted': $matches = []; preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break; 'core/quote' and 'core/pullquote'
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote': case 'core/pullquote': $matches = []; $regexes = [ 'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/', 'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/', ]; preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches); if ($quoteHTML = $matches[1]) { preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches); $blockMeta = [ 'quote' => strip_html_tags(implode('\n', $matches[1])), ]; preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches); if ($cite = $matches[1]) { $blockMeta['cite'] = strip_html_tags($cite); } } break; 'core/verse'
Similar situation to <pre /> .
case 'core/verse': $matches = []; preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
- REST, through the WP REST API (integrated in WordPress core)
- GraphQL, through WPGraphQL
- PoP, through its implementation for WordPress
Let's see how to export the data through each of them.
DİNLENMEK
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API's power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata ) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way .
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata" :
/** * Define WPGraphQL field "jsonencoded_block_metadata" */ add_action('graphql_register_types', function() { register_graphql_field( 'Post', 'jsonencoded_block_metadata', [ 'type' => 'String', 'description' => __('Post blocks encoded as JSON', 'wp-graphql'), 'resolve' => function($post) { $post = get_post($post->ID); $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); return json_encode($block_metadata); } ] ); });PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I've been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver { public static function getClassesToAttachTo(): array { return array(\PoP\Posts\FieldResolver::class); } public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = []) { $post = $resultItem; switch ($fieldName) { case 'block-metadata': $block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content); $block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data); // Filter by blockName if ($blockName = $fieldArgs['blockname']) { $block_metadata = array_filter( $block_metadata, function($block) use($blockName) { return $block['blockName'] == $blockName; } ); } return $block_metadata; } return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs); } }To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, a la GraphQL) for a list of posts.
Ek olarak, GraphQL argümanlarına benzer şekilde, sorgumuz alan argümanları aracılığıyla özelleştirilebilir, bu da yalnızca belirli bir platform için anlamlı olan verilerin elde edilmesini sağlar. Örneğin, tüm gönderilere eklenen tüm Youtube videolarını çıkarmak istiyorsak, bu bağlantıdaki gibi uç nokta URL'sindeki alan block-metadata verisine değiştirici (blockname:core-embed/youtube) ekleyebiliriz. Veya belirli bir gönderideki tüm resimleri çıkarmak istiyorsak, bu diğer bağlantıda olduğu gibi değiştirici (blockname:core/image) ekleyebiliriz|id|başlık).
Çözüm
COPE (“Bir Kez Oluştur, Her Yerde Yayınla”) stratejisi, tek bir kaynak oluşturarak farklı ortamlarda (web, e-posta, uygulamalar, ev asistanları, sanal gerçeklik, vb.) çalışması gereken birkaç uygulama oluşturmak için gereken iş miktarını azaltmamıza yardımcı olur. içeriğimiz için gerçeğin WordPress ile ilgili olarak, her zaman bir İçerik Yönetim Sistemi olarak öne çıkmasına rağmen, COPE stratejisinin uygulanmasının tarihsel olarak zor olduğu kanıtlanmıştır.
Bununla birlikte, son zamanlardaki birkaç gelişme, bu stratejiyi WordPress için uygulamayı giderek daha uygun hale getirdi. Bir tarafta, WP REST API'sinin çekirdeğine entegrasyondan ve daha belirgin olarak Gutenberg'in piyasaya sürülmesinden bu yana, çoğu WordPress içeriğine API'ler aracılığıyla erişilebilir, bu da onu gerçek bir başsız sistem haline getirir. Öte yandan, Gutenberg (yeni varsayılan içerik düzenleyicisi) blok tabanlıdır ve bir blog gönderisindeki tüm meta verilere API'ler tarafından kolayca erişilebilir hale gelir.
Sonuç olarak, WordPress için COPE'u uygulamak basittir. Bu yazıda, nasıl yapılacağını gördük ve ilgili tüm kodlar birkaç depo aracılığıyla kullanıma sunuldu. Çözüm optimal olmasa da (çok sayıda HTML kodunu ayrıştırma içerdiğinden), yine de oldukça iyi çalışıyor ve bunun sonucunda uygulamalarımızı birden çok platforma yayınlamak için gereken çaba büyük ölçüde azaltılabilir. Buna şükret!