
Bir Ajansta Yeni Bir Sunucusuz Veritabanı Teknolojisi Seçme (Örnek Olay)
Yayınlanan: 2022-03-10Bu makale, operasyonel verilerle çalışmayı her yazılım geliştirme ekibi için verimli, ölçeklenebilir ve güvenli hale getiren Fauna'daki sevgili dostlarımız tarafından desteklenmiştir. Teşekkür ederim!

Yeni bir teknolojiyi benimsemek, liderlik rolündeki bir teknoloji uzmanı için en zor kararlardan biridir. İster başka bir kuruluş için ister kendi kuruluşunuzda yazılım geliştiriyor olun, bu genellikle büyük ve rahatsız edici bir risk alanıdır.
Bir yazılım mühendisi olarak son on iki yılda, kendimi yeni bir teknolojiyi giderek artan sıklıkta değerlendirme durumunda buldum. Bu, bir sonraki ön uç çerçevesi, yeni bir dil veya hatta sunucusuz gibi tamamen yeni mimariler olabilir.
Deney aşaması genellikle eğlenceli ve heyecan vericidir. Yazılım mühendislerinin en çok evlerinde oldukları yer burasıdır ve yeni konseptler keşfederken “aha” anlarının yeniliğini ve coşkusunu benimser. Mühendisler olarak düşünmeyi ve kurcalamayı severiz, ancak yeterli deneyime sahip her mühendis, en inanılmaz teknolojinin bile kusurları olduğunu öğrenir. Sadece onları henüz bulamadın.
Şimdi, bir yaratıcı ajansın kurucu ortağı olarak ekibim ve ben genellikle yeni teknolojileri kullanmak için benzersiz bir konumdayız. Yeni bir şey tanıtmak için mükemmel bir fırsat haline gelen birçok sıfırdan proje görüyoruz. Bu projeler aynı zamanda daha büyük organizasyondan bir düzeyde teknik izolasyon görüyor ve genellikle önceki kararlardan daha az yükleniyor.
Bununla birlikte, iyi bir ajans lideri, bir başkasının büyük fikriyle ilgilenmek ve onu dünyaya sunmakla görevlendirilir. Kendi projelerimizden daha dikkatli davranmalıyız. Ne zaman yeni bir teknolojiyle ilgili son kararı vermek üzere olsam, genellikle kurucu ortak Stack Overflow Joel Spolski'nin şu bilgeliğini düşünürüm:
“Yeterince iyi olduğunu gerçekten bilmeden ya da ne kadar denersen dene, yapamayacağını anlamadan önce bir ya da iki yıl boyunca o şeyle terleyip kanaman gerekiyor...”
Bu korkudur, hiçbir teknoloji liderinin kendini bulmak istemediği yer burasıdır. Gerçek dünyadaki bir proje için yeni bir teknoloji seçmek yeterince zordur, ancak bir ajans olarak bu kararları başka birinin projesiyle, birisiyle birlikte vermelisiniz. başkasının hayali, başkasının parası. Bir ajansta, bir proje için son teslim tarihine yakın bu kusurlardan birini bulmak isteyeceğiniz son şey olur. Sıkı zaman çizelgeleri ve bütçeler, belirli bir eşik aşıldıktan sonra rotayı tersine çevirmeyi neredeyse imkansız hale getirir, bu nedenle bir teknolojinin kritik bir şey yapamayacağını veya bir projede çok geç güvenilmez olduğunu bulmak felaket olabilir.
Yazılım mühendisi olarak kariyerim boyunca SaaS şirketlerinde ve yaratıcı ajanslarda çalıştım. Bir proje için yeni bir teknolojinin benimsenmesi söz konusu olduğunda, bu iki ortamın çok farklı kriterleri vardır. Kriterlerde örtüşme var, ancak genel olarak ajans ortamı katı bütçeler ve katı zaman kısıtlamaları ile çalışmak zorunda. Ürettiğimiz ürünlerin zaman içinde eskimesini istesek de, daha az kanıtlanmış bir şeye yatırım yapmak veya daha dik öğrenme eğrileri ve pürüzlü kenarları olan teknolojiyi benimsemek genellikle daha zordur.
Bununla birlikte, ajansların da tek bir organizasyonun sahip olamayacağı bazı benzersiz kısıtlamaları vardır. Verimlilik ve istikrar için önyargılı olmalıyız. Bir proje tamamlandığında, faturalandırılabilir saat genellikle son ölçüm birimidir. Kurulum veya inşa hattı için bir veya iki gün harcamanın önemli olmadığı SaaS şirketlerinde bulundum.
Bir ajansta, finans ekipleri çok az görünür sonuçlar için daralan kar marjları gördüğünden, bu tür bir zaman maliyeti ilişkileri zorlar. Ayrıca, bir projenin uzun vadeli bakımını ve bunun tersine, bir projenin müşteriye geri verilmesi gerektiğinde ne olacağını da düşünmeliyiz. Bu nedenle, seçtiğimiz teknolojide verimlilik, öğrenme eğrisi ve istikrar için önyargılı olmalıyız.
Yeni bir teknoloji parçasını değerlendirirken üç kapsayıcı alana bakarım:
- Teknoloji
- Geliştirici Deneyimi
- iş
Bu alanların her birinin, gerçekten koda dalmaya ve denemeye başlamadan önce karşılamayı sevdiğim bir dizi kriteri var. Bu yazıda, bu kriterlere bir göz atacağız ve bir proje için yeni bir veritabanı düşünme örneğini kullanacağız ve her mercek altında üst düzeyde gözden geçireceğiz. Bunun gibi somut bir karar almak, bu çerçeveyi gerçek dünyada nasıl uygulayabileceğimizi göstermeye yardımcı olacaktır.
Teknoloji
Yeni bir teknolojiyi değerlendirirken bakılması gereken ilk şey, o çözümün çözdüğünü iddia ettiği sorunları çözüp çözemeyeceğidir. Bir teknolojinin süreçlerimize ve iş operasyonlarımıza nasıl yardımcı olabileceğine dalmadan önce, işlevsel gereksinimlerimizi karşılayıp karşılamadığını belirlemek önemlidir. Burası aynı zamanda hangi mevcut çözümleri kullandığımıza ve bu yenisinin onlara karşı nasıl biriktiğine bir göz atmayı sevdiğim yer.
Kendime şöyle sorular soracağım:
- En azından mevcut çözümümün yaptığı sorunu çözüyor mu?
- Bu çözüm hangi yönlerden daha iyi?
- Hangi yönlerden daha kötü?
- Daha kötü olduğu alanlar için, bu eksikliklerin üstesinden gelmek için ne gerekecek?
- Birden fazla aracın yerini alacak mı?
- Teknoloji ne kadar kararlı?
Bizim Neden?
Bu noktada neden başka bir çözüm aradığımızı da gözden geçirmek istiyorum. Basit bir cevap, mevcut çözümlerin çözmediği bir sorunla karşılaşıyoruz. Ancak, bu genellikle nadiren olur. Bugün sahip olduğumuz tüm teknoloji ile yıllar içinde birçok yazılım sorununu çözdük. Tipik olarak şu anda yaptığımız bir şeyi daha kolay, daha istikrarlı, daha hızlı veya daha ucuz hale getiren yeni bir teknolojiye dönüşüyoruz.
Örnek olarak React'i alalım. JQuery veya Vanilla JavaScript işi yaparken neden React'i benimsemeye karar verdik? Bu durumda, çerçeveyi kullanmak, bunun durum bilgisi olan ön uçları işlemenin çok daha iyi bir yolu olduğunu vurguladı. Doğrudan DOM manipülasyonu yerine veri yapılarıyla çalışarak filtreleme ve sıralama özellikleri oluşturmamız bizim için daha hızlı hale geldi. Bu, zamandan tasarruf sağladı ve çözümlerimizin kararlılığını artırdı.
TypeScript , kodumuzun kararlılığında ve sürdürülebilirlikte artışlar bulduğumuz için onu benimsemeye karar verdiğimiz başka bir örnektir. Yeni teknolojileri benimsemekle birlikte, genellikle çözmeye çalıştığımız net bir sorun değil, sadece güncel kalmaya ve ardından şu anda kullanmakta olduğumuzdan daha verimli ve istikrarlı çözümler keşfetmeye çalışıyoruz.
Bir veritabanı söz konusu olduğunda, özellikle sunucusuz bir seçeneğe geçmeyi düşünüyorduk. Bir kuruluş olarak ek yükümüzü azaltan sunucusuz uygulamalar ve dağıtımlarla birçok başarı elde etmiştik. Bunun eksik olduğunu hissettiğimiz alanlardan biri veri katmanımızdı. Veritabanlarına sunucusuz ilkeleri uygulayan Amazon Aurora, Fauna, Cosmos ve Firebase gibi hizmetleri gördük ve bu adımı kendimiz atmanın zamanının gelip gelmediğini görmek istedik. Bu durumda, operasyonel ek yükümüzü düşürmeyi ve geliştirme hızımızı ve verimliliğimizi artırmayı düşünüyorduk.
Yeni tekliflere dalmaya başlamadan önce nedeninizi anlamak bu seviyede önemlidir. Bunun nedeni, yeni bir sorunu çözüyor olmanız olabilir, ancak çok daha sık olarak, halihazırda çözmekte olduğunuz bir tür sorunu çözme yeteneğinizi geliştirmeye çalışıyorsunuzdur. Bu durumda, iş akışınızda neyin anlamlı bir iyileştirme sağlayacağını anlamak için bulunduğunuz yerin envanterini çıkarmanız gerekir. Sunucusuz veritabanlarına bakma örneğimizi temel alarak, şu anda sorunları nasıl çözdüğümüze ve bu çözümlerin nerede yetersiz kaldığına bakmamız gerekecek.
Neredeydik…
Bir ajans olarak daha önce MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery ve Firebase Cloud Storage dahil ancak bunlarla sınırlı olmamak üzere çok çeşitli veritabanlarını kullandık. Yine de çalışmalarımızın büyük çoğunluğu üç temel veritabanı etrafında toplandı: PostgreSQL, MongoDB ve Firebase Realtime Database. Bunların her birinin aslında yarı sunucusuz teklifleri var, ancak daha yeni tekliflerin bazı temel özellikleri, önceki varsayımlarımızı yeniden değerlendirmemize neden oldu. Önce bunların her biri ile ilgili tarihsel deneyimimize ve neden ilk etapta alternatifleri düşünmekten vazgeçtiğimize bir göz atalım.
Genellikle daha büyük, uzun vadeli projeler için PostgreSQL'i seçtik, çünkü bu neredeyse her şey için savaşta test edilmiş altın standarttır. Klasik işlemleri, normalleştirilmiş verileri destekler ve ACID uyumludur. Hemen hemen her dilde çok sayıda araç ve ORM bulunur ve JSON sütun desteğiyle geçici bir NoSQL veritabanı olarak bile kullanılabilir. Mevcut birçok çerçeve, kitaplık ve programlama diliyle iyi bir şekilde bütünleşir ve onu gerçek bir her yere götüren iş gücü haline getirir. Aynı zamanda açık kaynaklıdır ve bu nedenle bizi herhangi bir satıcıya kilitlemez. Dedikleri gibi, hiç kimse Postgres'i seçtiği için kovulmadı.
Bununla birlikte, daha çok Düğüm odaklı bir mağaza haline geldikçe PostgreSQL'i giderek daha az kullanmaya başladık. Düğüm için ORM'lerin cansız olduğunu ve daha fazla özel sorgu gerektirdiğini (bu artık daha az sorunlu hale gelmesine rağmen) bulduk ve NoSQL, bir JavaScript veya TypeScript çalışma zamanında çalışırken daha doğal bir uyum olduğunu hissetti. Bununla birlikte, e-ticaret iş akışları gibi klasik ilişkisel modelleme ile oldukça hızlı bir şekilde yapılabilecek projelerimiz vardı. Ancak, veritabanının yerel kurulumuyla uğraşmak, ekipler arasında test akışını birleştirmek ve yerel geçişlerle uğraşmak, NoSQL olarak bulut tabanlı veritabanları daha popüler hale geldikçe sevmediğimiz ve geride bırakmaktan mutlu olduğumuz şeylerdi.
Node.js'yi tercih ettiğimiz arka uç olarak benimsediğimiz için MongoDB giderek daha fazla başvurulan veritabanımız oldu. MongoDB Atlas ile çalışmak, ekibimizin kullanabileceği hızlı geliştirme ve test veritabanlarına sahip olmayı kolaylaştırdı. Bir süredir MongoDB, ACID uyumlu değildi, işlemleri desteklemiyordu ve çok fazla iç birleştirme benzeri işlemi engelledi, bu nedenle e-ticaret uygulamaları için hala Postgres'i en sık kullanıyorduk. Bununla birlikte, onunla birlikte gelen çok sayıda kütüphane var ve Mongo'nun sorgu dili ve birinci sınıf JSON desteği, ilişkisel veritabanlarında deneyimlemediğimiz hız ve verimliliği bize verdi. MongoDB yakın zamanda ACID işlemleri için destek ekledi, ancak uzun bir süredir Postgres'i tercih etmemizin başlıca nedeni buydu.
MongoDB ayrıca bizi yeni bir esneklik düzeyiyle tanıştırdı. Bir ajans projesinin ortasında, gereksinimler değişmek zorundadır. Buna karşı ne kadar savunma yaparsanız yapın, her zaman bir son dakika veri gereksinimi vardır. NoSQL veritabanlarında, genel olarak, veri yapısının esnekliği bu tür değişiklikleri daha az zor hale getirdi. Bir proje gün ışığını görmeden önce, eklenen, kaldırılan ve eklenen sütunları yeniden yönetmek için taşıma dosyalarıyla dolu bir klasöre sahip olmadık.
Hizmet olarak Mongo Atlas da bir veritabanı bulut hizmetinde istediğimize oldukça yakındı. Atlas'ı yarı sunucusuz bir teklif olarak düşünmeyi seviyorum, çünkü onu yönetmek için hala operasyonel yükünüz var. Belirli bir boyutta bir veritabanı sağlamanız ve önceden bir miktar bellek seçmeniz gerekir. Bu şeyler sizin için otomatik olarak ölçeklenmeyecek, bu nedenle daha fazla alan veya bellek sağlama zamanı geldiğinde onu izlemeniz gerekecek. Gerçekten sunucusuz bir veritabanında, bunların tümü otomatik olarak ve isteğe bağlı olarak gerçekleşir.
Ayrıca birkaç proje için Firebase Realtime Database'i kullandık. Bu gerçekten de veritabanının isteğe bağlı olarak büyütüldüğü ve küçültüldüğü sunucusuz bir teklifti ve kullandıkça öde fiyatlandırmasıyla ölçeğin önceden bilinmediği ve bütçenin sınırlı olduğu uygulamalar için anlamlıydı. Basit veri gereksinimleri olan kısa ömürlü projeler için MongoDB yerine bunu kullandık.
Firebase ile ilgili hoşlanmadığımız bir şey, alıştığımız normalleştirilmiş veriler etrafında oluşturulmuş tipik ilişkisel modelden daha uzak olduğu hissedilmesiydi. Veri yapılarını düz tutmak, genellikle daha fazla tekrarlamamız olduğu anlamına geliyordu, bu da bir proje büyüdükçe biraz çirkinleşebilirdi. Sonunda, aynı verileri birden çok yerde güncellemek zorunda kalırsınız veya farklı referansları bir araya getirmeye çalışırsınız, bu da kodda akıl yürütmesi zor olabilecek birden çok sorguya neden olur. Firebase'i sevsek de, sorgu diline hiçbir zaman gerçekten aşık olmadık ve bazen belgelerin cansız olduğunu gördük.
Genel olarak, hem MongoDB hem de Firebase, normal olmayan verilere benzer bir şekilde odaklandı ve verimli işlemlere erişim olmadan, genellikle ilişkisel veritabanlarında modellenmesi kolay iş akışlarının çoğunu bulduk, bu da uygulama katmanında daha karmaşık kodlara yol açtı. NoSQL karşılıkları. Geleneksel bir SQL veritabanının sağlamlığı ve ilişkisel modellemesi ile bu NoSQL tekliflerinin esnekliğini ve kolaylığını elde edebilseydik, gerçekten harika bir eşleşme bulmuş olurduk. MongoDB'nin daha iyi API'ye ve yeteneklere sahip olduğunu hissettik, ancak Firebase operasyonel olarak gerçekten sunucusuz modele sahipti.
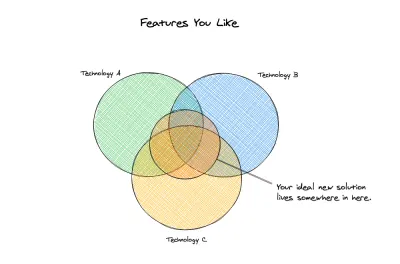
bizim idealimiz
Bu noktada, hangi yeni seçenekleri dikkate alacağımıza bakmaya başlayabiliriz. Önceki çözümlerimizi net bir şekilde tanımladık ve yeni çözümümüzde minimumda olması bizim için önemli olan şeyleri belirledik. Yalnızca bir temel veya minimum gereksinimlerimiz değil, aynı zamanda yeni çözümün bizim için hafifletmesini istediğimiz bir dizi sorunumuz da var. İşte sahip olduğumuz teknik gereksinimler :
- İsteğe bağlı ölçekle operasyonel olarak sunucusuz
- Esnek modelleme (şemasız)
- Geçişlere veya ORM'lere güvenilmez
- ASİT uyumlu işlemler
- İlişkileri ve normalleştirilmiş verileri destekler
- Hem sunucusuz hem de geleneksel arka uçlarla çalışır
Artık olmazsa olmazların bir listesine sahip olduğumuza göre, aslında bazı seçenekleri değerlendirebiliriz. Yeni çözümün burada her hedefi tutturması önemli olmayabilir. Mevcut çözümlerin örtüşmediği durumlarda, doğru özellik kombinasyonunu yakalayabilir. Örneğin şemasız esneklik istiyorsanız ACID işlemlerinden vazgeçmeniz gerekiyordu. (Bu, veritabanlarında uzun süredir böyleydi.)
Başka bir etki alanından bir örnek, şablon oluşturma işleminizde daktilo doğrulaması istiyorsanız, TSX ve React kullanmanız gerekir. Svelte veya Vue gibi seçeneklerle giderseniz, buna kısmen ama tamamen değil, şablon oluşturma yoluyla sahip olabilirsiniz. Bu nedenle, React ve TypeScript'in şablon düzeyinde tür denetimiyle size Svelte'nin küçük ayak izini ve hızını veren bir çözüm, başka bir özelliği eksik olsa bile benimseme için yeterli olabilir. İstek ve ihtiyaçların dengesi projeden projeye değişecektir. Değerin nerede olacağını bulmak ve analizinizde en önemli noktaları nasıl işaretleyeceğinize karar vermek size kalmıştır.
Artık bir çözüme göz atabilir ve istediğimiz çözüme göre nasıl değerlendirildiğini görebiliriz. Fauna , küresel dağıtım ile isteğe bağlı bir ölçeğe sahip sunucusuz bir veritabanı çözümüdür . ACID uyumlu işlemler sağlayan ve bir özellik olarak ilişkisel sorguları ve normalleştirilmiş verileri destekleyen şemasız bir veritabanıdır. Fauna, hem sunucusuz uygulamalarda hem de daha geleneksel arka uçlarda kullanılabilir ve kitaplıkların en popüler dillerle çalışmasını sağlar. Fauna ayrıca, kolay ve verimli çoklu kiracılığın yanı sıra kimlik doğrulama için iş akışları sağlar. Bunların her ikisi de dikkate alınması gereken sağlam ek özelliklerdir, çünkü değerlendirmemizde iki teknoloji burun buruna olduğunda sallanan faktörler olabilirler.
Şimdi tüm bu güçlü yönlere baktıktan sonra zayıf yönleri değerlendirmemiz gerekiyor. Fauna da açık kaynak kodlu değildir. Bu, satıcıya bağlı kalma riskleri veya kontrolünüz dışında olan iş ve fiyatlandırma değişiklikleri olduğu anlamına gelir. Açık kaynak güzel olabilir, çünkü projeye katkıda bulunursanız veya potansiyel olarak katkıda bulunursanız, teknolojiyi sık sık başka bir satıcıya götürebilirsiniz.
Ajans dünyasında, satıcı kilitlenmesi , fiyat nedeniyle çok fazla değil, yakından izlememiz gereken bir şeydir, ancak temel alınan işin uygulanabilirliği önemlidir. Geliştirme aşamasında olan veya birkaç yaşında olan bir projedeki veri tabanlarını değiştirmek, bir ajans için felakettir. Genellikle bir müşteri bunun için faturayı ödemek zorunda kalacak, bu da hoş bir sohbet değil.
İlgilendiğimiz diğer bir zayıflık da JAMstack'e odaklanmak. JAMstack'i sevsek de, kendimizi daha sık olarak çok çeşitli geleneksel web uygulamaları oluştururken buluyoruz. Fauna'nın bu kullanım durumlarını desteklemeye devam ettiğinden emin olmak istiyoruz. Geçmişte her şeyi JAMstack'e dahil eden bir barındırma sağlayıcısıyla kötü bir deneyim yaşadık ve hizmetten oldukça büyük bir site grubunu taşımak zorunda kaldık, bu nedenle tüm kullanım durumlarının görülmeye devam edeceğinden emin olmak istiyoruz. sağlam destek. Şu anda durum böyle görünüyor ve Fauna tarafından sağlanan sunucusuz iş akışları aslında daha geleneksel bir uygulamayı oldukça güzel bir şekilde tamamlayabilir.

Bu noktada, işlevsel araştırmamızı yaptık ve bu çözümün uygulanabilir olup olmadığını bilmenin tek yolu aşağı inip bir kod yazmak. Bir ajans ortamında, insanların birden fazla çözümü değerlendirmesi için programdan haftalar alamayız. Bu, bir SaaS ortamına karşı bir ajansta çalışmanın doğasıdır. İkincisinde, doğru çözüme ulaşmaya çalışmak için birkaç prototip oluşturabilirsiniz. Bir ajansta, deney yapmak için birkaç gününüz olacak veya belki bir yan proje yapma fırsatınız olacak ama genel olarak bu aşamada bunu gerçekten bir veya iki teknolojiye indirgememiz ve ardından parmakları klavyeye koymamız gerekiyor.
Geliştirici Deneyimi
Yeni bir teknolojinin deneyim tarafını değerlendirmek, doğası gereği öznel olduğu için üç alanın belki de en zorudur. Ayrıca takımdan takıma değişkenlik gösterecektir. Örneğin, bir Ruby programcısına, bir Python programcısına ve bir Rust programcısına farklı dil özellikleri hakkındaki görüşlerini sorduysanız, oldukça çeşitli yanıtlar alırsınız. Bu nedenle, bir deneyimi yargılamaya başlamadan önce, genel olarak ekibiniz için hangi özelliklerin en önemli olduğuna karar vermelisiniz.

Ajanslar için geliştirici deneyimiyle ilgili olarak ortaya çıkan iki büyük darboğaz olduğunu düşünüyorum:
- Kurulum süresi ve yapılandırma
- öğrenilebilirlik
Bunların her ikisi de yeni bir teknolojinin uzun vadeli uygulanabilirliğini farklı şekillerde etkiler. Bir ajansta geçici geliştirici ekiplerini senkronize tutmak baş ağrısı olabilir. Çok sayıda ön kurulum maliyeti ve yapılandırması olan araçlar, ajansların çalışması için herkesin bildiği gibi zor. Diğeri ise öğrenilebilirlik ve geliştiricilerin yeni teknolojiyi geliştirmesinin ne kadar kolay olduğu. Bunları ve geliştirici deneyimini değerlendirmeye başlarken neden benim temelim olduklarını daha ayrıntılı olarak ele alacağız.
Kurulum Süresi ve Yapılandırma
Ajanslar, yapılandırma için çok az sabra ve zamana sahip olma eğilimindedir. Benim için, eldeki iş sorunu üzerinde hızlı bir şekilde çalışmamı sağlayan ergonomik tasarımlara sahip keskin araçları seviyorum. Birkaç yıl önce, birçok yapılandırmayı içeren ve genellikle kurulum sürecinde rastgele noktalarda başarısız olan karmaşık bir yerel kuruluma sahip bir SaaS şirketinde çalıştım. Bir kez kurulduktan sonra, geleneksel bilgelik hiçbir şeye dokunmamaktı ve şirkette onu başka bir makineye yeniden kurmak zorunda kalacak kadar uzun süre kalmadığınızı ummaktı. Emacs kurulumlarının her küçük parçasını yapılandırmaktan büyük zevk alan ve bozuk bir yerel ortama birkaç saat kaybetmeyi düşünmeyen geliştiricilerle tanıştım.
Genel olarak, ajans mühendislerinin günlük işlerinde bu tür şeyleri küçümsediklerini gördüm. Evdeyken bu tür araçları kurcalayabilirler, ancak son teslim tarihi geldiğinde sadece çalışan araçlar gibisi yoktur. Ajanslarda, her bir teknoloji parçasını her bir bireyin kişisel zevkine göre yapılandırmak yerine, sürekli olarak iyi çalışan birkaç yeni şey öğrenmeyi tercih ederiz.
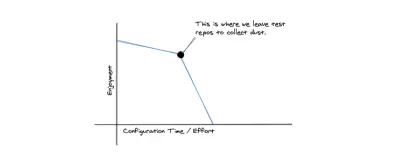
Açık kaynak olmayan bir bulut platformuyla çalışmanın iyi yanlarından biri, kurulum ve yapılandırmaya tamamen sahip olmalarıdır. Bunun bir dezavantajı, satıcıya kilitlenme olsa da, iyi tarafı, bu tür araçların genellikle iyi yapmak için ayarlandıkları şeyi yapmalarıdır. Ortamlarla uğraşmak, yerel kurulumlar ve dağıtım işlem hatları yoktur. Ayrıca verecek daha az kararımız var.
Bu, doğası gereği sunucusuzun çekiciliğidir . Genel olarak sunucusuz, tescilli hizmetlere ve araçlara daha fazla güvenir. Daha fazla istikrar kazanabilmemiz ve çözmeye çalıştığımız iş alanının sorunlarına odaklanabilmemiz için barındırma ve kaynak kodunun esnekliğini değiştiriyoruz. Ayrıca, bir teknolojiyi değerlendirirken ve bir platformdan taşınmanın gerekli olabileceği hissine kapıldığımda, bunun başlangıçta genellikle kötüye işaret olduğunu da belirteceğim.
Veritabanları söz konusu olduğunda, kur ve unut kurulumu, veritabanı ihtiyaçlarının belirsiz olabileceği istemcilerle çalışırken idealdir. Bir programın veya uygulamanın ne kadar popüler olacağından emin olmayan müşterilerimiz oldu. Teknik olarak bu şekilde desteklemek için sözleşmeli olmadığımız ancak yine de veritabanlarını veya uygulamalarını ölçeklendirmemiz gerektiğinde panik içinde bizi aradık müşterilerimiz oldu.
Geçmişte, SOW'larımızı oluştururken ölçeklendirmek için artıklık, veri çoğaltma ve parçalama gibi şeyleri her zaman hesaba katmamız gerekirdi. Bir veritabanının ölçeklenmemesi durumunda tam bir iş kitabını taşımaya hazırlanırken her bir senaryoyu kapsamaya çalışmak, hazırlanmak için imkansız bir durumdur. Sonunda, sunucusuz bir veritabanı bu işleri kolaylaştırır.
Hiçbir zaman veri kaybetmezsiniz , verileri bir ağ üzerinden kopyalamak ya da onu çalıştırmak için daha büyük bir veritabanı ve makine sağlamak konusunda endişelenmenize gerek yoktur - hepsi çalışır. Sadece eldeki iş sorununa odaklanıyoruz, teknik mimari ve ölçek her zaman yönetilecek. Geliştirme ekibimiz için bu büyük bir kazanç; daha az yangın tatbikatı, izleme ve bağlam değiştirmeye sahibiz.
öğrenilebilirlik
Geliştirici deneyimi için geçerli olduğunu düşündüğüm, öğrenilebilirlik olan klasik bir kullanıcı deneyimi ölçüsü var. Belirli bir kullanıcı deneyimi için tasarım yaparken, yalnızca ilk denemede bir şeyin görünür veya kolay olup olmadığına bakmıyoruz. Teknoloji çoğu zaman olduğundan daha karmaşıktır. Önemli olan yeni bir kullanıcının sistemi ne kadar kolay öğrenip ustalaşabileceğidir.
Teknik araçlar söz konusu olduğunda, özellikle güçlü olanlar, sıfır öğrenme eğrisi olmasını istemek çok fazla olacaktır. Genellikle aradığımız şey, en yaygın kullanım durumları için harika belgeler olması ve bu bilginin bir projedeyken kolayca ve hızlı bir şekilde üzerine inşa edilmesidir. Bir teknoloji ile ilk projeyi öğrenmek için biraz zaman kaybetmek sorun değil. Bundan sonra, birbirini takip eden her projede verimliliğin arttığını görmeliyiz.
Burada özellikle aradığım şey, öğrenme eğrisini kısaltmaya yardımcı olmak için zaten bildiğimiz bilgi ve kalıplardan nasıl yararlanabileceğimizdir. Örneğin, sunucusuz veritabanlarıyla, onları bulutta kurmak ve dağıtmak için neredeyse sıfır öğrenme eğrisi olacaktır. Veritabanını kullanmaya gelince, sevdiğim şeylerden biri, ilişkisel veritabanlarında yıllarca ustalaşmanın ve bu öğrendikleri yeni kurulumumuza uygulayabilmemizdir. Bu durumda, yeni bir aracın nasıl kullanılacağını öğreniyoruz, ancak bu bizi veri modellememizi sıfırdan yeniden düşünmeye zorlamıyor.

Buna bir örnek olarak, Firebase, MongoDB ve DynamoDB kullanırken, farklı belgeleri birleştirmeye çalışmak yerine normal olmayan verileri teşvik ettiğini gördük. Bu, ticari varlıklar yerine erişim kalıpları açısından düşünmemiz gerektiğinden, verilerimizi modellerken çok fazla bilişsel sürtüşme yarattı. Bu Fauna'nın diğer tarafında, veri modelleme söz konusu olduğunda, yıllarca süren ilişkisel bilgimizden ve normalleştirilmiş veri tercihimizden yararlanmamızı sağladı.
Alışmamız gereken kısım, bu parçaları bir araya getirmek için indeksler ve yeni bir sorgu dili kullanmaktı. Genel olarak, daha büyük yazılım tasarım paradigmalarının bir parçası olan kavramları korumanın, geliştirme ekibinin öğrenilebilirlik ve benimseme açısından işini kolaylaştırdığını buldum.
Bir ekibin yeni bir teknolojiyi benimsediğini ve onu sevdiğini nasıl anlarız? Bence en iyi işaret, kendimizi bu aracın söz konusu yeni teknolojiyle bütünleşip bütünleşmediğini sorduğumuzda bulmamızdır. Yeni bir teknoloji, ekibin onu daha fazla projeye dahil etmenin yollarını aradığı bir arzu ve zevk düzeyine ulaştığında, bu bir kazananınız olduğuna dair iyi bir işarettir.
iş
Bu bölümde, yeni bir teknolojinin iş ihtiyaçlarımızı nasıl karşıladığına bakmamız gerekiyor. Bunlar aşağıdaki gibi soruları içerir:
- Destek planlarımıza ne kadar kolay fiyatlandırılabilir ve entegre edilebilir?
- Müşterilere kolayca aktarabilir miyiz?
- Gerekirse müşteriler bu araca dahil edilebilir mi?
- Bu araç, eğer varsa, gerçekte ne kadar zaman kazandırır?
Sunucusuz yaklaşımın bir paradigma olarak yükselişi ajanslara çok yakışıyor. Veritabanları ve DevOps hakkında konuştuğumuzda, ajanslarda bu alanlarda uzman ihtiyacı sınırlıdır. Çoğu zaman bir projeyi bitirdiğimizde teslim ediyoruz ya da sınırlı bir kapasitede uzun vadede destekliyoruz. Tam donanımlı mühendislere karşı önyargılı olma eğilimindeyiz çünkü bu ihtiyaçlar DevOps ihtiyaçlarını büyük bir farkla geride bırakıyor. Bir DevOps mühendisi tutsaydık, muhtemelen bir projeyi dağıtmak için birkaç saat harcarlar ve yangını beklemek için çok daha fazla saat harcarlardı.
Bu bağlamda, her zaman hazır bazı DevOps yüklenicilerimiz var, ancak bu pozisyonlar için tam zamanlı personel yapmıyoruz. Bu, beklenmedik bir soruna atlamaya hazır olması için bir DevOps mühendisine güvenemeyeceğimiz anlamına gelir. Bizim için doğrudan AWS'ye giderek daha iyi barındırma oranları elde edebileceğimizi biliyoruz, ancak Heroku'yu kullanarak çoğu sorunda hata ayıklamak için mevcut personelimize güvenebileceğimizi de biliyoruz. Belirli arka uç ihtiyaçlarıyla uzun vadeli desteklememiz gereken bir müşterimiz olmadığı sürece, varsayılan olarak yönetilen platformları bir hizmet olarak kullanmayı seviyoruz.
Veritabanları bir istisna değildir. Bu süreci olabildiğince kolaylaştırmak için Mongo Atlas veya Heroku Postgres gibi hizmetlere güvenmeyi seviyoruz. Vercel, Netlify veya AWS Lambda gibi sunucusuz araçlarda yığınımızın giderek daha fazlasını görmeye başladığımızda, veritabanı ihtiyaçlarımız da bununla birlikte gelişmek zorunda kaldı. Firebase, DynamoDB ve Fauna gibi sunucusuz veritabanları , sunucusuz uygulamalarla iyi bir şekilde bütünleştikleri ve aynı zamanda işletmemizi tedarik ve ölçeklendirmeden tamamen kurtardıkları için harikadır.
Bu çözümler, sunucusuz bir uygulamamızın olmadığı ancak yine de veritabanı düzeyinde sunucusuz verimlilikten yararlanabildiğimiz daha geleneksel uygulamalar için de işe yarar. Bir işletme olarak, bağlam değiştirmeden ziyade her iki dünya için de geçerli olabilecek tek bir veritabanı öğrenmek bizim için daha verimlidir. Bu, Node ve izomorfik JavaScript'i (ve TypeScript) benimseme kararımıza benzer.
Sunucusuz ile bulduğumuz dezavantajlardan biri, bu hizmetleri yönettiğimiz müşteriler için fiyatlandırma yapmaktır. Daha geleneksel bir mimaride, sabit oranlı katmanlar, bunları, meydana gelen artışlar ve aşımlar için öngörülebilir koşullara sahip müşteriler için bir orana çevirmeyi çok kolaylaştırır. Sunucusuz söz konusu olduğunda bu belirsiz olabilir. Finans çalışanları, 1 milyonu aşan her okuma için bir kuruşun 1/10'u gibi şeyler duymaktan hoşlanmazlar.
Bunun, mühendisler için bile sabit bir sayıya çevrilmesi zordur, çünkü genellikle kullanımın ne olacağından emin olmadığımız uygulamalar geliştiriyoruz. Katmanları genellikle kendimiz oluşturmamız gerekir, ancak bir lambda'nın maliyet hesaplamasına giren birçok değişkeni anlamak zor olabilir. Sonuç olarak, bir SaaS ürünü için bu kullandıkça öde fiyatlandırma modelleri harikadır ancak ajanslar için muhasebeciler daha somut ve öngörülebilir sayıları sever.
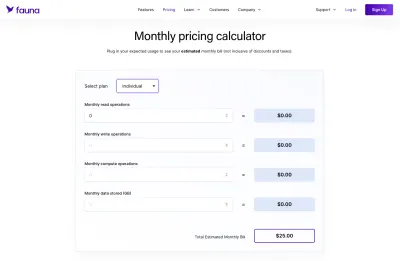
Fauna söz konusu olduğunda, bunu anlamak, belirli bir miktar alan için sabit oranlı barındırmaya sahip standart bir MySQL veritabanı demekten kesinlikle daha belirsizdi. İyi tarafı ise Fauna'nın kendi fiyatlandırma planlarımızı bir araya getirmek için kullanabileceğimiz güzel bir hesap makinesi sağlamasıydı.
Sunucusuz sistemin bir başka zor yönü, bu sağlayıcıların çoğunun barındırılan her uygulamanın kolayca bozulmasına izin vermemesi olabilir. Örneğin, Heroku platformu, yeni boru hatları ve ekipler oluşturarak bunu oldukça kolaylaştırır. Barındırma planlarımızı kullanmak istememeleri durumunda müşterinin kredi kartını bile girebiliriz. Bunların hepsi aynı kontrol panelinde de yapılabilir, böylece birden fazla oturum açmamız gerekmedi.
Diğer sunucusuz araçlar söz konusu olduğunda bu çok daha zordu. Firebase, sunucusuz veritabanlarını değerlendirirken, ödemelerin projeye göre bölünmesini destekler. Fauna veya DynamoDB söz konusu olduğunda bu mümkün değildir, bu nedenle gösterge tablosundaki kullanımı izlemek için bazı çalışmalar yapmamız gerekiyor ve müşteri hizmetimizden ayrılmak isterse veritabanını kendi hesabına aktarmamız gerekir.
Sonuç olarak, sunucusuz araçlar maliyet tasarrufu, yönetim ve süreç verimliliği açısından harika iş fırsatları sunar. Ancak, fiyatlandırma ve hesap yönetimi söz konusu olduğunda , ajanslar için genellikle zorlayıcıdırlar . Bu, kendi öngörülebilir fiyatlandırma katmanlarımızı oluşturmak için maliyet hesaplayıcılardan yararlanmak veya ödemeleri doğrudan yapabilmeleri için müşterileri kendi hesaplarıyla ayarlamak zorunda kaldığımız bir alandır.
Çözüm
Bir ajans olarak yeni bir teknolojiyi benimsemek zor bir görev olabilir. Yeni teknolojiler için fırsatlar sunan sıfırdan yeni projelerle çalışmak için eşsiz bir konumdayken, bunların uzun vadeli yatırımlarını da düşünmek zorundayız. Nasıl performans gösterecekler? İnsanlarımız üretken olacak ve bunları kullanmaktan keyif alacak mı? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Daha fazla okuma
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience