
Şirket İçinde Merkezi Kayıt Hizmeti Oluşturma
Yayınlanan: 2022-03-10Uygulama performansını ve özelliklerini iyileştirmek için hata ayıklamanın ne kadar önemli olduğunu hepimiz biliyoruz. BrowserStack, yüksek oranda dağıtılmış bir uygulama yığınında günde bir milyon oturum çalıştırır! Her biri birkaç hareketli parça içerir, çünkü bir müşterinin tek oturumu birkaç coğrafi bölgede birden çok bileşene yayılabilir.
Doğru çerçeve ve araçlar olmadan hata ayıklama süreci bir kabus olabilir. Bizim durumumuzda, bir seans sırasında meydana gelen her şeyi derinlemesine anlamak için her sürecin farklı aşamalarında meydana gelen olayları toplamanın bir yoluna ihtiyacımız vardı. Altyapımızla, her bileşenin bir isteği işleme yaşam döngüsünden birden fazla olayı olabileceğinden, bu sorunu çözmek karmaşık hale geldi.
Bu nedenle, bir oturum sırasında günlüğe kaydedilen tüm önemli olayları kaydetmek için kendi şirket içi Merkezi Kayıt Hizmeti aracımızı (CLS) geliştirdik. Bu olaylar, geliştiricilerimizin bir oturumda bir şeylerin yanlış gittiği durumları belirlemesine ve belirli temel ürün ölçümlerinin izlenmesine yardımcı olur.
Hata ayıklama verileri, API yanıt gecikmesi gibi basit şeylerden bir kullanıcının ağ sağlığını izlemeye kadar uzanır. Bu makalede, 100'den fazla bileşenden günde 70G ilgili kronolojik veri toplayan CLS aracımızı güvenilir, ölçekte ve iki M3.large EC2 bulut sunucusuyla oluşturma hikayemizi paylaşıyoruz.
Şirket İçi İnşa Etme Kararı
İlk olarak, mevcut bir çözümü kullanmak yerine neden CLS aracımızı şirket içinde oluşturduğumuzu düşünelim. Seanslarımızın her biri, birden fazla bileşenden hizmete ortalama 15 olay gönderir ve bu, günde yaklaşık 15 milyon toplam olay anlamına gelir.
Hizmetimizin tüm bu verileri saklama yeteneğine ihtiyacı vardı. Olaylar arasında olay depolama, gönderme ve sorgulamayı desteklemek için eksiksiz bir çözüm aradık. Amplitude ve Keen gibi üçüncü taraf çözümlerini göz önünde bulundurduğumuz için, değerlendirme metriklerimiz maliyet, yüksek paralel isteklerin ele alınmasındaki performans ve benimseme kolaylığını içeriyordu. Ne yazık ki, bütçe dahilinde tüm gereksinimlerimizi karşılayan bir uyum bulamadık - ancak faydaları arasında zaman tasarrufu ve uyarıları en aza indirmesi yer alacaktı. Ek çaba gerektirse de, kendimiz bir şirket içi çözüm geliştirmeye karar verdik.

Teknik detaylar
Bileşenimizin mimarisi açısından aşağıdaki temel gereksinimleri belirledik:
- Müşteri Performansı
Olayları gönderen istemcinin/bileşenin performansını etkilemez. - Ölçek
Çok sayıda talebi paralel olarak işleyebilir. - Servis performansı
Kendisine gönderilen tüm olayları işlemek için hızlı. - Verilere ilişkin içgörü
Bileşeni veya kullanıcıyı, hesabı veya mesajı benzersiz bir şekilde tanımlayabilmek ve geliştiricinin daha hızlı hata ayıklamasına yardımcı olmak için daha fazla bilgi verebilmek için günlüğe kaydedilen her olayın bazı meta bilgilere sahip olması gerekir. - sorgulanabilir arayüz
Geliştiriciler, belirli bir oturum için tüm olayları sorgulayarak belirli bir oturumda hata ayıklamaya, bileşen sağlık raporları oluşturmaya veya sistemlerimizin anlamlı performans istatistiklerini oluşturmaya yardımcı olabilir. - Daha hızlı ve daha kolay benimseme
Ekiplere yük olmadan ve kaynaklarını tüketmeden mevcut veya yeni bir bileşenle kolay entegrasyon. - Düşük bakım
Biz küçük bir mühendislik ekibiyiz, bu yüzden uyarıları en aza indirecek bir çözüm aradık!
CLS Çözümümüzü Oluşturma
Karar 1: Ortaya Çıkarılacak Bir Arayüz Seçme
CLS'yi geliştirirken, verilerimizin hiçbirini kaybetmek istemedik, ancak bileşen performansının da etkilenmesini istemedik. Genel olarak benimsemeyi ve yayınlamayı geciktireceğinden, mevcut bileşenlerin daha karmaşık hale gelmesini önleyen ek faktörden bahsetmiyorum bile. Arayüzümüzü belirlerken aşağıdaki seçenekleri göz önünde bulundurduk:
- Bir arka plan işlemcisi onu CLS'ye ittiğinden, olayları her bileşende yerel Redis'te depolamak. Ancak bu, tüm bileşenlerde bir değişikliğin yanı sıra, henüz onu içermeyen bileşenler için Redis'in sunulmasını gerektirir.
- Bir Yayıncı - Redis'in CLS'ye daha yakın olduğu abone modeli. Herkes olayları yayınlarken, yine dünya genelinde çalışan bileşenler faktörüne sahibiz. Yoğun trafik sırasında bu, bileşenleri geciktirir. Ayrıca, bu yazma işlemi aralıklı olarak beş saniyeye kadar atlayabilir (yalnızca internet nedeniyle).
- Uygulama performansı üzerinde daha az etki sağlayan olayları UDP üzerinden gönderme. Bu durumda veriler gönderilecek ve unutulacaktır, ancak buradaki dezavantaj veri kaybı olacaktır.
İlginç bir şekilde, UDP üzerinden veri kaybımız yüzde 0,1'den azdı ve bu, böyle bir hizmet oluşturmayı düşünmemiz için kabul edilebilir bir miktardı. Tüm ekipleri, bu kayıp miktarının performansa değdiğine ikna edebildik ve gönderilen tüm olayları dinleyen bir UDP arayüzünden yararlanmaya devam ettik.
Sonuçlardan biri uygulamanın performansı üzerinde daha küçük bir etki olsa da, tüm ağlardan, çoğunlukla kullanıcılarımızdan gelen UDP trafiğine izin verilmediğinden ve bazı durumlarda hiç veri almamamıza neden olan bir sorunla karşılaştık. Geçici bir çözüm olarak, olayları HTTP isteklerini kullanarak günlüğe kaydetmeyi destekledik. Kullanıcı tarafından gelen tüm olaylar HTTP yoluyla gönderilirken, bileşenlerimizden kaydedilen tüm olaylar UDP aracılığıyla olacaktır.
Karar 2: Teknik Yığın (Dil, Çerçeve ve Depolama)
Biz bir Ruby dükkanıyız. Ancak, Ruby'nin bizim özel sorunumuz için daha iyi bir seçim olup olmayacağından emin değildik. Hizmetimiz, çok sayıda gelen isteğin yanı sıra çok sayıda yazma işlemini de işlemek zorunda kalacaktı. Global Tercüman kilidiyle, Ruby'de çoklu kullanım veya eşzamanlılık elde etmek zor olurdu (lütfen gücenmeyin - Ruby'yi seviyoruz!). Dolayısıyla, bu tür bir eşzamanlılık elde etmemize yardımcı olacak bir çözüme ihtiyacımız vardı.
Ayrıca teknoloji yığınımızdaki yeni bir dili değerlendirmeye de hevesliydik ve bu proje yeni şeyler denemek için mükemmel görünüyordu. İşte o zaman Golang'a bir şans vermeye karar verdik çünkü eşzamanlılık ve hafif iplikler ve hareket rutinleri için dahili destek sundu. Günlüğe kaydedilen her veri noktası, bir anahtar/değer çiftine benzer; burada 'anahtar' olaydır ve 'değer', ilişkili değeri olarak hizmet eder.
Ancak basit bir anahtara ve değere sahip olmak, oturumla ilgili verileri almak için yeterli değildir - daha fazla meta veri vardır. Bunu ele almak için, günlüğe kaydedilmesi gereken herhangi bir olayın, anahtarı ve değeri ile birlikte bir oturum kimliğine sahip olacağına karar verdik. Ayrıca, verileri getirmeyi ve analiz etmeyi daha kolay hale getirmek için zaman damgası, kullanıcı kimliği ve verileri günlüğe kaydeden bileşen gibi ekstra alanlar ekledik.

Yük yapımıza karar verdiğimize göre, veri depomuzu seçmemiz gerekiyordu. Elastik Aramayı düşündük, ancak anahtarlar için güncelleme isteklerini de desteklemek istedik. Bu, tüm belgenin yeniden dizine eklenmesini tetikler ve bu da yazmalarımızın performansını etkileyebilir. MongoDB, eklenecek herhangi bir veri alanına dayalı olarak tüm olayları sorgulamak daha kolay olacağından, bir veri deposu olarak daha mantıklıydı. Bu kolaydı!
Karar 3: DB Boyutu Çok Büyük Ve Sorgulama Ve Arşivleme Berbat!
Bakımı azaltmak için hizmetimizin mümkün olduğu kadar çok olayla ilgilenmesi gerekir. BrowserStack'in özellikleri ve ürünleri piyasaya sürme hızı göz önüne alındığında, etkinliklerimizin sayısının zaman içinde daha yüksek oranlarda artacağından emindik, bu da hizmetimizin iyi performans göstermeye devam etmesi gerektiği anlamına geliyordu. Alan arttıkça, okuma ve yazma işlemleri daha fazla zaman alır - bu da hizmetin performansı üzerinde büyük bir darbe olabilir.
Araştırdığımız ilk çözüm, günlükleri belirli bir süre veritabanından uzaklaştırmaktı (bizim durumumuzda 15 gün olarak karar verdik). Bunu yapmak için, her gün için farklı bir veritabanı oluşturduk ve tüm yazılı belgeleri taramaya gerek kalmadan belirli bir dönemden daha eski günlükleri bulmamıza izin verdik. Şimdi, her ihtimale karşı yedekleri tutarken, 15 günden eski veritabanlarını sürekli olarak Mongo'dan kaldırıyoruz.
Kalan tek parça, oturumla ilgili verileri sorgulamak için bir geliştirici arayüzüydü. Dürüst olmak gerekirse, bu çözülmesi en kolay problemdi. Belirli bir oturum kimliğine sahip herhangi bir veri için, kişilerin MongoDB'deki ilgili veritabanındaki oturumla ilgili olayları sorgulayabileceği bir HTTP arabirimi sağlıyoruz.
Mimari
Aşağıdaki noktaları göz önünde bulundurarak hizmetin iç bileşenlerinden bahsedelim:
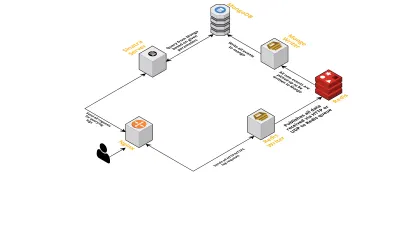
- Daha önce tartışıldığı gibi, biri UDP üzerinden dinleme ve diğeri HTTP üzerinden dinleme olmak üzere iki arayüze ihtiyacımız vardı. Bu yüzden olayları dinlemek için yine her arayüz için bir tane olmak üzere iki sunucu oluşturduk. Bir olay gelir gelmez, gerekli alanlara sahip olup olmadığını kontrol etmek için onu ayrıştırırız - bunlar oturum kimliği, anahtar ve değerdir. Olmazsa, veriler düşürülür. Aksi takdirde, veriler bir Go kanalı üzerinden, tek sorumluluğu MongoDB'ye yazmak olan başka bir goroutine iletilir.
- Burada olası bir endişe MongoDB'ye yazmaktır. MongoDB'ye yapılan yazmalar, alınan hız verisinden daha yavaşsa, bu bir darboğaz yaratır. Bu da diğer gelen olayları aç bırakır ve verinin düşmesi anlamına gelir. Bu nedenle sunucu, gelen günlükleri işlemede hızlı olmalı ve yaklaşan günlükleri işlemeye hazır olmalıdır. Bu sorunu çözmek için sunucuyu iki bölüme ayırdık: ilki tüm olayları alır ve ikincisi için sıraya koyar, bu da onları işleyip MongoDB'ye yazar.
- Sıralama için Redis'i seçtik. Tüm bileşeni bu iki parçaya bölerek sunucunun iş yükünü azalttık ve ona daha fazla günlük işlemesi için alan sağladık.
- Verilen parametrelerle MongoDB'yi sorgulamanın tüm işlerini halletmek için Sinatra sunucusunu kullanarak küçük bir servis yazdık. Belirli bir oturum hakkında bilgiye ihtiyaç duyduklarında geliştiricilere bir HTML/JSON yanıtı döndürür.
Tüm bu işlemler tek bir m3.large bulut sunucusunda mutlu bir şekilde çalışır.
Özellik talepleri
CLS aracımız zamanla daha fazla kullanıldığından daha fazla özelliğe ihtiyaç duydu. Aşağıda, bunları ve nasıl eklendiklerini tartışıyoruz.
Eksik Meta Veriler
Yavaş yavaş BrowserStack'teki bileşenlerin sayısı arttıkça, CLS'den daha fazlasını talep ettik. Örneğin, oturum kimliği olmayan bileşenlerden olayları günlüğe kaydetme yeteneğine ihtiyacımız vardı. Aksi takdirde, bir tane edinmek, uygulama performansını etkileme ve ana sunucularımızda trafik oluşması şeklinde altyapımıza yük olur.
Bunu, terminal ve kullanıcı kimlikleri gibi diğer anahtarları kullanarak olay günlüğünü etkinleştirerek ele aldık. Artık bir oturum oluşturulduğunda veya güncellendiğinde, CLS, ilgili kullanıcı ve terminal kimliklerinin yanı sıra oturum kimliğiyle bilgilendirilir. MongoDB'ye yazma işlemiyle alınabilecek bir haritayı saklar. Kullanıcı veya terminal kimliğini içeren bir olay alındığında, oturum kimliği eklenir.
İstenmeyen Postaları Yönetin (Diğer Bileşenlerdeki Kod Sorunları)
CLS ayrıca istenmeyen posta olaylarını ele alırken olağan zorluklarla da karşı karşıya kaldı. Sıklıkla, CLS'ye gönderilen çok büyük miktarda istek oluşturan bileşenlerde dağıtımlar bulduk. Sunucu bunları işleyemeyecek kadar meşgul olduğundan ve önemli günlükler atıldığından, diğer günlükler bu süreçte zarar görecektir.
Çoğunlukla, günlüğe kaydedilen verilerin çoğu HTTP istekleri aracılığıylaydı. Bunları kontrol etmek için nginx'te (limit_req_zone modülünü kullanarak) hız sınırlamayı etkinleştiriyoruz, bu da küçük bir süre içinde belirli bir sayıdan daha fazla istek isabet ettiğini bulduğumuz herhangi bir IP'den gelen istekleri engelliyor. Elbette, engellenen tüm IP'lerde sağlık raporlarından yararlanıyoruz ve sorumlu ekipleri bilgilendiriyoruz.
Ölçek v2
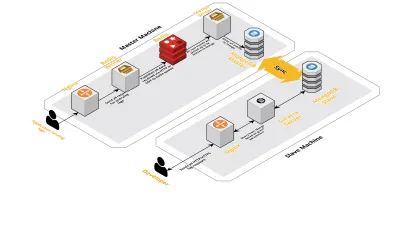
Günlük oturumlarımız arttıkça, CLS'ye kaydedilen veriler de artıyordu. Bu, geliştiricilerimizin günlük olarak çalıştırdığı sorguları etkiledi ve kısa süre sonra sahip olduğumuz darboğaz makinenin kendisindeydi. Kurulumumuz, yukarıdaki bileşenlerin tümünü çalıştıran iki çekirdek makinenin yanı sıra Mongo'yu sorgulamak ve her ürün için temel ölçümleri takip etmek için bir dizi komut dosyasından oluşuyordu. Zamanla, makinedeki veriler yoğun bir şekilde arttı ve komut dosyaları çok fazla CPU zamanı almaya başladı. Mongo sorgularını optimize etmeye çalıştıktan sonra bile her zaman aynı sorunlara geri döndük.
Bunu çözmek için, sağlık raporu komut dosyalarını çalıştırmak için başka bir makine ve bu oturumları sorgulamak için bir arayüz ekledik. Süreç, yeni bir makineyi başlatmayı ve ana makinede çalışan Mongo'nun bir kölesini kurmayı içeriyordu. Bu, bu komut dosyalarının neden olduğu her gün gördüğümüz CPU artışlarını azaltmaya yardımcı oldu.
Çözüm
Veri kaydı kadar basit bir görev için hizmet oluşturmak, veri miktarı arttıkça karmaşık hale gelebilir. Bu makale, bu sorunu çözerken karşılaştığımız zorluklarla birlikte keşfettiğimiz çözümleri tartışıyor. Ekosistemimize ne kadar uygun olacağını görmek için Golang ile deneyler yaptık ve şu ana kadar memnun kaldık. Harici bir hizmet için ödeme yapmak yerine dahili bir hizmet oluşturma seçimimiz harika bir maliyet etkin oldu. Ayrıca, oturumlarımızın hacmi arttığında çok daha sonraya kadar kurulumumuzu başka bir makineye ölçeklendirmek zorunda kalmadık. Tabii ki, CLS'yi geliştirme konusundaki seçimlerimiz tamamen gereksinimlerimize ve önceliklerimize dayanıyordu.
Bugün CLS, her gün 70 GB'a kadar veri oluşturan 15 milyona kadar olayı işliyor. Bu veriler, müşterilerimizin herhangi bir oturum sırasında karşılaştıkları sorunları çözmemize yardımcı olmak için kullanılmaktadır. Bu verileri başka amaçlar için de kullanırız. Her oturumun verilerinin farklı ürünler ve dahili bileşenlerle ilgili sağladığı içgörüler göz önüne alındığında, her bir ürünü takip etmek için bu verilerden yararlanmaya başladık. Bu, tüm önemli bileşenler için temel metriklerin çıkarılmasıyla elde edilir.
Sonuç olarak, kendi CLS aracımızı oluşturmada büyük başarı elde ettik. Size mantıklı geliyorsa, aynısını yapmayı düşünmenizi tavsiye ederim!