
Node.js ile Amazon Ürün Kazıyıcı Nasıl Oluşturulur
Yayınlanan: 2022-03-10Hiç belirli bir ürün için piyasayı yakından tanımanız gereken bir durumda bulundunuz mu? Belki bir yazılım başlatıyorsunuz ve nasıl fiyatlandırılacağını bilmeniz gerekiyor. Veya belki de piyasada kendi ürününüz var ve rekabet avantajı için hangi özellikleri ekleyeceğinizi görmek istiyorsunuz. Ya da belki sadece kendiniz için bir şeyler satın almak istiyorsunuz ve paranızın karşılığını en iyi şekilde aldığınızdan emin olmak istiyorsunuz.
Tüm bu durumların ortak bir yanı var: doğru kararı vermek için doğru verilere ihtiyacınız var . Aslında paylaştıkları başka bir şey daha var. Tüm senaryolar bir web kazıyıcı kullanımından yararlanabilir.
Web kazıma, yazılım kullanılarak büyük miktarda web verisinin çıkarılması uygulamasıdır. Bu nedenle, özünde, 200 kez 'kopyala' ve ardından 'yapıştır' tuşuna basmanın sıkıcı sürecini otomatikleştirmenin bir yolu. Elbette, bir bot bunu sizin bu cümleyi okumanız için geçen süre içinde yapabilir, bu nedenle hem daha az sıkıcı hem de çok daha hızlıdır.
Ancak can alıcı soru şudur: Neden biri Amazon sayfalarını kazımak istesin ki?
Öğrenmek üzeresin! Ama her şeyden önce, şu anda bir şeyi açıklığa kavuşturmak istiyorum - herkese açık verileri kazıma eylemi yasal olsa da, Amazon'un sayfalarında bunu önlemek için bazı önlemleri var. Bu nedenle, siteyi kazırken her zaman dikkatli olmanızı, siteye zarar vermemeye özen göstermenizi ve etik kurallara uymanızı tavsiye ederim.
Önerilen Kaynaklar : Andreas Altheimer tarafından yazılan “Node.js ve Puppeteer ile Dinamik Web Sitelerinin Etik Kazıma Rehberi”
Amazon Ürün Verilerini Neden Çıkarmalısınız?
Gezegendeki en büyük çevrimiçi perakendeci olarak, bir şey satın almak istiyorsanız muhtemelen Amazon'dan alabileceğinizi söyleyebiliriz. Bu nedenle, web sitesinin ne kadar büyük bir veri hazinesi olduğunu söylemeye gerek yok.
Web'i kazırken, birincil sorunuz tüm bu verilerle ne yapacağınız olmalıdır. Pek çok bireysel neden olsa da, iki belirgin kullanım durumu özetleniyor: ürünlerinizi optimize etmek ve en iyi fırsatları bulmak.
“
İlk senaryo ile başlayalım. Gerçekten yenilikçi bir ürün tasarlamadıysanız, Amazon'da en azından benzer bir ürün bulma şansınız var. Bu ürün sayfalarını kazımak size aşağıdakiler gibi çok değerli veriler sağlayabilir:
- Rakiplerin fiyatlandırma stratejisi
Böylece, fiyatlarınızı rekabetçi olacak şekilde ayarlayabilir ve başkalarının promosyon fırsatlarını nasıl ele aldığını anlayabilirsiniz; - Müşteri görüşleri
Gelecekteki müşteri tabanınızın en çok neye önem verdiğini ve deneyimlerini nasıl iyileştirebileceğinizi görmek için; - En yaygın özellikler
Hangi işlevlerin çok önemli olduğunu ve hangilerinin daha sonraya bırakılabileceğini bilmek için rekabetinizin neler sunduğunu görmek.
Özünde Amazon, derin bir pazar ve ürün analizi için ihtiyacınız olan her şeye sahiptir. Bu verilerle ürün yelpazenizi tasarlamaya, piyasaya sürmeye ve genişletmeye daha hazırlıklı olacaksınız.
İkinci senaryo hem işletmeler hem de sıradan insanlar için geçerli olabilir. Fikir, daha önce bahsettiğim şeye oldukça benziyor. Seçebileceğiniz tüm ürünlerin fiyatlarını, özelliklerini ve incelemelerini sıyırabilirsiniz ve böylece en düşük fiyata en fazla avantajı sunanı seçebileceksiniz. Sonuçta, kim iyi bir anlaşmayı sevmez ki?
Tüm ürünler bu kadar ayrıntıya dikkat etmeyi hak etmez, ancak pahalı satın alımlarda büyük bir fark yaratabilir. Ne yazık ki, faydaları açık olsa da, Amazon'u kazımanın birçok zorluğu var.
Amazon Ürün Verilerini Kazımanın Zorlukları
Tüm web siteleri aynı değildir. Genel bir kural olarak, bir web sitesi ne kadar karmaşık ve yaygınsa, onu kazımak o kadar zor olur. Amazon'un en önemli e-ticaret sitesi olduğunu söylediğimi hatırlıyor musunuz? Bu onu hem son derece popüler hem de oldukça karmaşık kılıyor.
Öncelikle, Amazon kazıma botlarının nasıl davrandığını biliyor, bu nedenle web sitesinde karşı önlemler var. Yani, kazıyıcı önceden tahmin edilebilir bir model izlerse, sabit aralıklarla, bir insandan daha hızlı veya neredeyse aynı parametrelerle istek gönderirse, Amazon IP'yi fark edecek ve engelleyecektir. Proxy'ler bu sorunu çözebilir, ancak örnekte çok fazla sayfa kazımayacağımız için onlara ihtiyacım olmadı.
Ardından Amazon, ürünleri için kasıtlı olarak değişen sayfa yapıları kullanır. Başka bir deyişle, sayfaları farklı ürünler için incelerseniz, yapılarında ve özelliklerinde önemli farklılıklar bulma ihtimaliniz yüksektir. Bunun arkasındaki sebep oldukça basittir. Sıyırıcınızın kodunu belirli bir sistem için uyarlamanız gerekir ve aynı komut dosyasını yeni bir tür sayfada kullanırsanız, bazı bölümlerini yeniden yazmanız gerekir. Yani, aslında sizi veriler için daha çok çalıştırıyorlar.
Son olarak, Amazon geniş bir web sitesidir. Büyük miktarda veri toplamak istiyorsanız, kazıma yazılımını bilgisayarınızda çalıştırmak ihtiyaçlarınız için çok fazla zaman alabilir. Bu sorun, çok hızlı gitmenin sıyırıcınızı bloke edeceği gerçeğiyle daha da pekiştirilir. Bu nedenle, hızlı bir şekilde bir sürü veri istiyorsanız, gerçekten güçlü bir kazıyıcıya ihtiyacınız olacak.
Pekala, bu kadar sorunlardan bahsetmek yeter, çözümlere odaklanalım!
Amazon İçin Bir Web Kazıyıcı Nasıl Yapılır
İşleri basit tutmak için, kodu yazarken adım adım bir yaklaşım izleyeceğiz. Kılavuzla paralel olarak çalışmaktan çekinmeyin.
İhtiyacımız olan verileri arayın
İşte bir senaryo: Birkaç ay içinde yeni bir yere taşınıyorum ve kitap ve dergileri tutmak için birkaç yeni rafa ihtiyacım olacak. Tüm seçeneklerimi bilmek ve elimden geldiğince iyi bir anlaşma yapmak istiyorum. Öyleyse Amazon pazarına gidelim, “rafları” arayalım ve ne elde ettiğimizi görelim.
Bu aramanın URL'si ve kazıyacağımız sayfa burada.
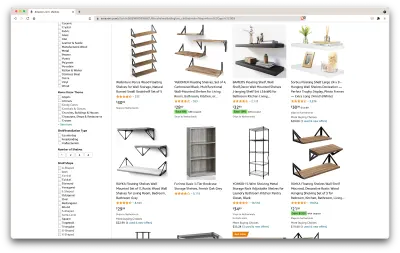
Tamam, elimizdekilerin stokunu alalım. Sadece sayfaya bir göz atarak, aşağıdakiler hakkında iyi bir fikir edinebiliriz:
- raflar nasıl görünüyor;
- paketin içeriği;
- müşterilerin onları nasıl değerlendirdiği;
- onların fiyatı;
- ürün linki;
- bazı öğeler için daha ucuz bir alternatif için bir öneri.
Bu isteyebileceğimizden daha fazlası!
Gerekli araçları edinin
Bir sonraki adıma geçmeden önce aşağıdaki tüm araçların kurulu ve yapılandırılmış olduğundan emin olalım.
- Krom
Buradan indirebiliriz. - VSCode
Özel cihazınıza yüklemek için bu sayfadaki talimatları izleyin. - Node.js
Axios veya Cheerio'yu kullanmaya başlamadan önce Node.js ve Node Paket Yöneticisini kurmamız gerekiyor. Node.js ve NPM'yi kurmanın en kolay yolu, yükleyicilerden birini Node.Js resmi kaynağından alıp çalıştırmaktır.
Şimdi yeni bir NPM projesi oluşturalım. Proje için yeni bir klasör oluşturun ve aşağıdaki komutu çalıştırın:
npm init -yWeb kazıyıcıyı oluşturmak için projemize birkaç bağımlılık yüklememiz gerekiyor:
- tezahürat
İşaretlemeyi ayrıştırarak ve elde edilen verileri işlemek için bir API sağlayarak yararlı bilgileri çıkarmamıza yardımcı olan açık kaynaklı bir kitaplık. Cheerio, seçicileri kullanarak bir HTML belgesinin etiketlerini seçmemize olanak tanır:$("div"). Bu özel seçici, bir sayfadaki tüm<div>öğelerini seçmemize yardımcı olur. Cheerio'yu yüklemek için lütfen projelerin klasöründe aşağıdaki komutu çalıştırın:
npm install cheerio- aksiyolar
Node.js'den HTTP istekleri yapmak için kullanılan bir JavaScript kitaplığı.
npm install axiosSayfa kaynağını inceleyin
Aşağıdaki adımlarda, bilgilerin sayfada nasıl düzenlendiği hakkında daha fazla bilgi edineceğiz. Buradaki fikir, kaynağımızdan neleri kazıyabileceğimizi daha iyi anlamaktır.
Geliştirici araçları, web sitesinin Belge Nesne Modelini (DOM) etkileşimli olarak keşfetmemize yardımcı olur. Geliştirici araçlarını Chrome'da kullanacağız, ancak rahat ettiğiniz herhangi bir web tarayıcısını kullanabilirsiniz.
Sayfada herhangi bir yere sağ tıklayıp “İncele” seçeneğini seçerek açalım:
Bu, sayfanın kaynak kodunu içeren yeni bir pencere açacaktır. Daha önce de söylediğimiz gibi, her rafın bilgisini sıyırmaya çalışıyoruz.
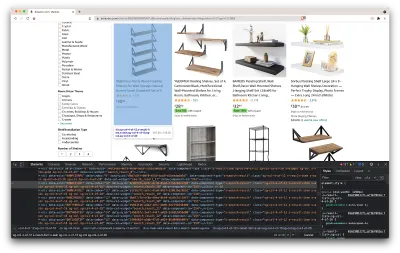
Yukarıdaki ekran görüntüsünden de görebileceğimiz gibi, tüm verileri tutan kaplar aşağıdaki sınıflara sahiptir:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20Bir sonraki adımda, ihtiyacımız olan verileri içeren tüm öğeleri seçmek için Cheerio'yu kullanacağız.

verileri getir
Yukarıda verdiğimiz tüm bağımlılıkları yükledikten sonra yeni bir index.js dosyası oluşturalım ve aşağıdaki kod satırlarını yazalım:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Gördüğümüz gibi, ilk iki satırda ihtiyacımız olan bağımlılıkları içe aktarıyoruz ve ardından Cheerio'yu kullanarak ürünlerimizin bilgilerini içeren tüm öğeleri sayfadan alan bir fetchShelves() işlevi oluşturuyoruz.
Her birini yineler ve daha iyi biçimlendirilmiş bir sonuç elde etmek için onu boş bir diziye iter.
fetchShelves() işlevi şu anda yalnızca ürünün başlığını döndürür, bu yüzden ihtiyacımız olan bilgilerin geri kalanını alalım. Lütfen title değişkenini tanımladığımız satırdan sonra aşağıdaki kod satırlarını ekleyin.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } Ve shelves.push(title) ile shelves.push(element) değiştirin.
Şimdi ihtiyacımız olan tüm bilgileri seçiyoruz ve onu element adlı yeni bir nesneye ekliyoruz. Daha sonra her öğe, yalnızca aradığımız verileri içeren nesnelerin bir listesini almak için shelves dizisine gönderilir.
Bir shelf nesnesi listemize eklenmeden önce şöyle görünmelidir:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }verileri biçimlendir
İhtiyacımız olan verileri getirmeyi başardığımıza göre, okunabilirliği artırmak için onu bir .CSV dosyası olarak kaydetmek iyi bir fikirdir. Tüm verileri aldıktan sonra Node.js tarafından sağlanan fs modülünü kullanacağız ve save saved-shelves.csv adlı yeni bir dosyayı projenin klasörüne kaydedeceğiz. Dosyanın en üstündeki fs modülünü içe aktarın ve aşağıdaki kod satırlarını kopyalayın veya yazın:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Gördüğümüz gibi ilk üç satırda daha önce topladığımız verileri bir raf nesnesinin tüm değerlerini virgülle birleştirerek formatlıyoruz. Ardından fs modülünü kullanarak saved-shelves.csv adında bir dosya oluşturuyoruz, sütun başlıklarını içeren yeni bir satır ekliyoruz, yeni biçimlendirdiğimiz verileri ekliyoruz ve hataları işleyen bir geri çağırma işlevi oluşturuyoruz.
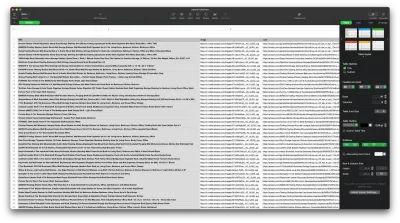
Sonuç şöyle görünmelidir:
Bonus İpuçları!
Tek Sayfa Uygulamalarını Kazıma
Web siteleri her zamankinden daha karmaşık olduğundan, dinamik içerik günümüzde standart hale geliyor. Mümkün olan en iyi kullanıcı deneyimini sağlamak için geliştiricilerin dinamik içerik için farklı yükleme mekanizmaları benimsemesi gerekir , bu da işimizi biraz daha karmaşık hale getirir. Bunun ne anlama geldiğini bilmiyorsanız, grafik kullanıcı arabirimi olmayan bir tarayıcı düşünün. Neyse ki, bir Chrome örneğini DevTools Protokolü üzerinden kontrol etmek için üst düzey bir API sağlayan büyülü Düğüm kitaplığı olan Kuklacı var. Yine de, bir tarayıcı ile aynı işlevselliği sunar, ancak birkaç satır kod yazarak programlı olarak kontrol edilmesi gerekir. Bunun nasıl çalıştığını görelim.
Önceden oluşturulmuş projede, npm install puppeteer çalıştırarak Puppeteer kitaplığını kurun, yeni bir puppeteer.js dosyası oluşturun ve aşağıdaki kod satırlarını kopyalayın veya yazın:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() Yukarıdaki örnekte, bir Chrome örneği oluşturuyoruz ve bu bağlantıya gitmek için gerekli olan yeni bir tarayıcı sayfası açıyoruz. Aşağıdaki satırda başsız tarayıcıya rpBJOHq2PR60pnwJlUyP0 sınıfına sahip eleman sayfada görünene kadar beklemesini söylüyoruz. Ayrıca tarayıcının sayfanın yüklenmesi için ne kadar beklemesi gerektiğini (2000 milisaniye) belirledik.
page değişkenindeki evaluate yöntemini kullanarak, Puppeteer'a, öğe nihayet yüklendikten hemen sonra Javascript parçacıklarını sayfa bağlamında yürütmesi talimatını verdik. Bu, sayfanın HTML içeriğine erişmemize ve sayfanın gövdesini çıktı olarak döndürmemize olanak tanır. Ardından, chrome değişkeni üzerinde close yöntemini çağırarak Chrome örneğini kapatıyoruz. Ortaya çıkan çalışma, dinamik olarak oluşturulan tüm HTML kodlarından oluşmalıdır. Kuklacı bu şekilde dinamik HTML içeriği yüklememize yardımcı olabilir.
Puppeteer'ı kullanmakta kendinizi rahat hissetmiyorsanız, NightwatchJS, NightmareJS veya CasperJS gibi birkaç alternatif olduğunu unutmayın. Biraz farklıdırlar, ancak sonunda süreç oldukça benzerdir.
user-agent Başlıklarını ayarlama
user-agent , ziyaret ettiğiniz web sitesine kendiniz, yani tarayıcınız ve işletim sisteminiz hakkında bilgi veren bir istek başlığıdır. Bu, kurulumunuz için içeriği optimize etmek için kullanılır, ancak web siteleri, IPS'yi değiştirse bile, tonlarca istek gönderen botları tanımlamak için de kullanır.
Bir user-agent başlığı şöyle görünür:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Tespit edilmemek ve engellenmemek için bu başlığı düzenli olarak değiştirmelisiniz. Boş veya modası geçmiş bir başlık göndermemeye özen gösterin, çünkü bu, fabrikada çalışan bir kullanıcı için asla gerçekleşmemelidir ve göze çarparsınız.
Hız Sınırlama
Web kazıyıcılar içeriği son derece hızlı toplayabilir, ancak en yüksek hızda gitmekten kaçınmalısınız. Bunun iki nedeni vardır:
- Kısa sürede çok fazla istek , web sitesinin sunucusunu yavaşlatabilir ve hatta sunucunun çökmesine neden olarak, site sahibi ve diğer ziyaretçiler için sorun yaratabilir. Esasen bir DoS saldırısı haline gelebilir.
- Dönen proxy'ler olmadan, hiçbir insan saniyede yüzlerce veya binlerce istek göndermeyeceğinden , bir bot kullandığınızı yüksek sesle duyurmaya benzer.
Çözüm, “hız sınırlama” adı verilen bir uygulama olan istekleriniz arasına bir gecikme getirmektir. ( Uygulaması da oldukça basit! )
Yukarıda verilen Kuklacı örneğinde, body değişkenini oluşturmadan önce, başka bir istek yapmadan önce birkaç saniye beklemek için Kuklacı tarafından sağlanan waitForTimeout yöntemini kullanabiliriz:
await page.waitForTimeout(3000); Burada ms , beklemek isteyeceğiniz saniye sayısıdır.
Ayrıca, axios örneği için aynı şeyi yapmak istersek, istediğimiz milisaniye sayısını beklememize yardımcı olması için setTimeout() yöntemini çağıran bir söz oluşturabiliriz:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))Bu şekilde, hedeflenen sunucuya çok fazla baskı yapmaktan kaçınabilir ve ayrıca web kazıma işlemine daha insani bir yaklaşım getirebilirsiniz.
Kapanış Düşünceleri
Ve işte karşınızda, Amazon ürün verileri için kendi web kazıyıcınızı oluşturmaya yönelik adım adım bir kılavuz! Ama unutmayın, bu sadece bir durumdu. Farklı bir web sitesini sıyırmak isterseniz, anlamlı sonuçlar elde etmek için birkaç ince ayar yapmanız gerekir.
İlgili Okuma
Hala daha fazla web kazıma işlemi görmek istiyorsanız, işte size bazı yararlı okuma materyalleri:
- “JavaScript ve Node.Js ile Web Scraping için Nihai Kılavuz,” Robert Sfichi
- "Puppeteer ile Gelişmiş Node.JS Web Kazıma," Gabriel Cioci
- Raluca Penciuc, "Python Web Kazıma: Kazıyıcınızı İnşa Etmek İçin Nihai Kılavuz"