
FaunaDB, Netlify ve 11ty ile Bookmarking Uygulaması Oluşturun
Yayınlanan: 2022-03-10JAMstack (JavaScript, API'ler ve İşaretleme) devrimi tüm hızıyla devam ediyor. Statik siteler güvenli, hızlı, güvenilir ve üzerinde çalışmak eğlencelidir. JAMstack'in kalbinde, verilerinizi düz dosyalar olarak depolayan statik site oluşturucular (SSG'ler) bulunur: Markdown, YAML, JSON, HTML vb. Bazen verileri bu şekilde yönetmek aşırı derecede karmaşık olabilir. Bazen, hala bir veritabanına ihtiyacımız var.
Bunu akılda tutarak, statik bir site ana bilgisayarı olan Netlify ve sunucusuz bir bulut veritabanı olan FaunaDB, her iki sistemi birleştirmeyi kolaylaştırmak için işbirliği yaptı.
Neden Bookmarking Sitesi?
JAMstack, birçok profesyonel kullanım için harikadır, ancak bu teknoloji setinin en sevdiğim yönlerinden biri, kişisel araçlar ve projeler için giriş engelinin düşük olmasıdır.
Piyasada bulabileceğim çoğu uygulama için çok sayıda iyi ürün var, ancak hiçbiri tam olarak benim için kurulmamıştı. Hiçbiri içeriğim üzerinde tam kontrol sağlamaz. Hiçbiri bedelsiz gelmezdi (parasal veya bilgi amaçlı).
Bunu akılda tutarak, JAMstack yöntemlerini kullanarak kendi mini servislerimizi oluşturabiliriz. Bu durumda, günlük teknoloji okumalarımda karşılaştığım ilginç makaleleri depolamak ve yayınlamak için bir site oluşturacağız.
Twitter'da paylaşılan makaleleri okumak için çok zaman harcıyorum. Birini beğendiğimde “kalp” simgesine basarım. Ardından, birkaç gün içinde yeni favorilerin akını ile bulmak neredeyse imkansız. “Kalbin” rahatlığına yakın ama sahip olduğum ve kontrol ettiğim bir şey inşa etmek istiyorum.
Bunu nasıl yapacağız? Sorduğuna sevindim.
Kodu almakla ilgileniyor musunuz? Github'dan alabilir veya doğrudan o depodan Netlify'a dağıtabilirsiniz! Bitmiş ürüne buradan bir göz atın.
Teknolojilerimiz
Barındırma ve Sunucusuz İşlevler: Netlify
Barındırma ve sunucusuz işlevler için Netlify'ı kullanacağız. Ek bir avantaj olarak, yukarıda bahsedilen yeni işbirliği ile Netlify'ın CLI'si — “Netlify Dev” — otomatik olarak FaunaDB'ye bağlanacak ve API anahtarlarımızı ortam değişkenleri olarak depolayacaktır.
Veritabanı: FaunaDB
FaunaDB, "sunucusuz" bir NoSQL veritabanıdır. Yer imleri verilerimizi depolamak için kullanacağız.
Statik Site Oluşturucu: 11ty
HTML'ye büyük bir inancım var. Bu nedenle öğretici, yer imlerimizi oluşturmak için ön uç JavaScript kullanmayacak. Bunun yerine, 11ty'yi statik site oluşturucu olarak kullanacağız. 11ty, bir API'den veri almayı birkaç kısa JavaScript işlevi yazmak kadar kolay hale getiren yerleşik veri işlevine sahiptir.
iOS Kısayolları
Veritabanımıza veri göndermek için kolay bir yola ihtiyacımız olacak. Bu durumda iOS'un Kısayollar uygulamasını kullanacağız. Bu, bir Android veya masaüstü JavaScript yer işaretine de dönüştürülebilir.
FaunaDB'yi Netlify Dev Aracılığıyla Kurma
FaunaDB'ye önceden kaydolmuş olsanız da veya yeni bir hesap oluşturmanız gerekse de, FaunaDB ile Netlify arasında bir bağlantı kurmanın en kolay yolu Netlify'ın CLI'si: Netlify Dev. FaunaDB'nin tüm talimatlarını burada bulabilir veya aşağıdan takip edebilirsiniz.
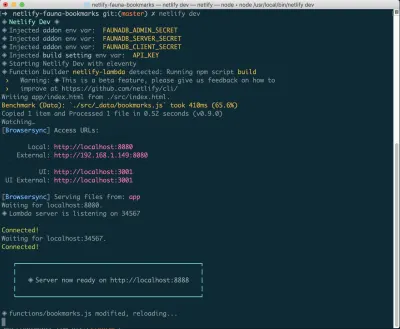
Bu zaten kurulu değilse, Terminal'de aşağıdaki komutu çalıştırabilirsiniz:
npm install netlify-cli -gProje dizininizin içinden aşağıdaki komutları çalıştırın:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Bunların hepsi bağlandıktan sonra, projenizde netlify dev çalıştırabilirsiniz. Bu, kurduğumuz tüm derleme komut dosyalarını çalıştırır, ancak aynı zamanda Netlify ve FaunaDB hizmetlerine bağlanır ve gerekli ortam değişkenlerini alır. Kullanışlı!
İlk Verilerimizi Oluşturmak
Buradan FaunaDB'ye giriş yapacağız ve ilk veri setimizi oluşturacağız. “Yer imleri” adında yeni bir Veritabanı oluşturarak başlayacağız. Bir Veritabanının içinde Koleksiyonlarımız, Belgelerimiz ve İndekslerimiz var.
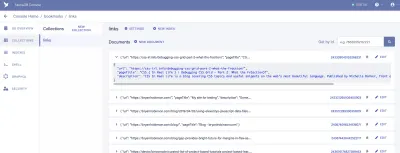
Koleksiyon, kategorilere ayrılmış bir veri grubudur. Her veri parçası bir Belge şeklini alır. Fauna'nın belgelerine göre Belge, "FaunaDB veritabanındaki tek, değiştirilebilir kayıttır". Koleksiyonları geleneksel bir veritabanı tablosu ve bir Belgeyi bir satır olarak düşünebilirsiniz.
Uygulamamız için “bağlantılar” diyeceğimiz bir Koleksiyona ihtiyacımız var. "Bağlantılar" Koleksiyonundaki her belge, üç özelliğe sahip basit bir JSON nesnesi olacaktır. Başlamak için, ilk veri getirmemizi oluşturmak için kullanacağımız yeni bir Belge ekleyeceğiz.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Bu, yer imlerimizden almamız gereken bilgilerin temelini oluşturur ve ayrıca bize şablonumuza çekmek için ilk veri setimizi sağlar.
Benim gibiyseniz, emeğinizin meyvelerini hemen görmek istersiniz. Haydi sayfaya bir şeyler koyalım!
11ty Yükleme ve Verileri Bir Şablona Çekme
Yer imlerinin HTML olarak oluşturulmasını ve tarayıcı tarafından getirilmemesini istediğimizden, oluşturma işlemini yapacak bir şeye ihtiyacımız olacak. Bunu yapmanın birçok harika yolu var, ancak kolaylık ve güç için 11ty statik site oluşturucuyu kullanmayı seviyorum.
11ty bir JavaScript statik site oluşturucu olduğundan, onu NPM aracılığıyla kurabiliriz.
npm install --save @11ty/eleventy Bu kurulumdan, çalışmaya başlamak için projemizde onbir veya eleventy --serve eleventy .
Netlify Dev genellikle bir gereklilik olarak 11ty'yi algılar ve bizim için komutu çalıştırır. Bu işi yapmak ve dağıtıma hazır olduğumuzdan emin olmak için package.json "serve" ve "build" komutları da oluşturabiliriz.
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11ty'nin Veri Dosyaları
Çoğu statik site oluşturucu, yerleşik bir "veri dosyası" fikrine sahiptir. Genellikle bu dosyalar, sitenize ekstra bilgi eklemenize olanak tanıyan JSON veya YAML dosyaları olacaktır.
11ty'de JSON veri dosyalarını veya JavaScript veri dosyalarını kullanabilirsiniz. Bir JavaScript dosyası kullanarak, aslında API çağrılarımızı yapabilir ve verileri doğrudan bir şablona döndürebiliriz.
Varsayılan olarak, 11ty bir _data dizininde saklanan veri dosyalarını ister. Ardından, şablonlarınızda dosya adını bir değişken olarak kullanarak verilere erişebilirsiniz. Bizim durumumuzda, _data/bookmarks.js bir dosya oluşturacağız ve buna {{ bookmarks }} değişken adı aracılığıyla erişeceğiz.
Veri dosyası yapılandırmasında daha derine inmek istiyorsanız, 11ty belgelerindeki örnekleri okuyabilir veya 11ty veri dosyalarını Meetup API ile kullanmayla ilgili bu eğiticiye göz atabilirsiniz.
Dosya bir JavaScript modülü olacaktır. Bu nedenle, herhangi bir şeyin çalışması için verilerimizi veya bir işlevi dışa aktarmamız gerekir. Bizim durumumuzda, bir işlevi dışa aktaracağız.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Bunu parçalayalım. Burada ana işimizi yapan iki fonksiyonumuz var: mapBookmarks() ve getBookmarks() .
getBookmarks() işlevi, FaunaDB veritabanımızdan verilerimizi getirecek ve mapBookmarks() , bir dizi yer imini alacak ve şablonumuz için daha iyi çalışacak şekilde yeniden yapılandıracaktır.
getBookmarks() 'ın derinliklerine inelim.
getBookmarks()
İlk olarak, FaunaDB JavaScript sürücüsünün bir örneğini kurmamız ve başlatmamız gerekecek.
npm install --save faunadbŞimdi yüklediğimize göre data dosyamızın başına ekleyelim. Bu kod doğrudan Fauna'nın dokümanlarından alınmıştır.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Daha sonra fonksiyonumuzu oluşturabiliriz. Sürücüde yerleşik yöntemleri kullanarak ilk sorgumuzu oluşturarak başlayacağız. Bu ilk kod parçası, işaretlenmiş tüm bağlantılarımız için tam veri almak için kullanabileceğimiz veritabanı referanslarını döndürür. Verileri 11ty'ye teslim etmeden önce sayfalandırmaya karar vermemiz durumunda, imleç durumunu yönetmek için bir yardımcı olarak Paginate yöntemini kullanıyoruz. Bizim durumumuzda, sadece tüm referansları döndüreceğiz.
Bu örnekte, Netlify Dev CLI aracılığıyla FaunaDB'yi kurduğunuzu ve bağladığınızı varsayıyorum. Bu işlemi kullanarak FaunaDB sırlarının yerel ortam değişkenlerini elde edersiniz. Bu şekilde yüklemediyseniz veya projenizde netlify dev çalıştırmıyorsanız, ortam değişkenlerini oluşturmak için dotenv gibi bir pakete ihtiyacınız olacak. Ayrıca, dağıtımların daha sonra çalışması için ortam değişkenlerinizi Netlify site yapılandırmanıza eklemeniz gerekir.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Bu kod, tüm bağlantılarımızın bir dizisini referans biçiminde döndürür. Artık veritabanımıza göndermek için bir sorgu listesi oluşturabiliriz.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) Buradan, döndürülen verileri temizlememiz gerekiyor. İşte burada mapBookmarks() giriyor!
mapBookmarks()
Bu fonksiyonda, verilerin iki yönü ile ilgileniyoruz.
İlk olarak FaunaDB'de ücretsiz bir dateTime alıyoruz. Oluşturulan herhangi bir veri için bir zaman damgası ( ts ) özelliği vardır. Liquid'in varsayılan tarih filtresini mutlu edecek şekilde biçimlendirilmemiş, o yüzden düzeltelim.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Bunun dışında, verilerimiz için yeni bir nesne oluşturabiliriz. Bu durumda, bir time özelliğine sahip olacak ve hepsini tek bir seviyede canlı hale getirmek için data nesnemizi yok etmek için Spread operatörünü kullanacağız.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Fonksiyonumuzdan önceki verilerimiz:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Fonksiyonumuzdan sonraki verilerimiz:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Şimdi, şablonumuz için hazır, iyi biçimlendirilmiş verilerimiz var!
Basit bir şablon yazalım. Yer imlerimiz arasında dolaşacağız ve aptal görünmemek için her birinin bir pageTitle ve bir url sahip olduğunu doğrulayacağız.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Şimdi FaunaDB'den veri alıyor ve görüntülüyoruz. Bir dakikanızı ayıralım ve bunun saf HTML oluşturmasının ve istemci tarafında veri almaya gerek olmamasının ne kadar güzel olduğunu düşünelim!
Ancak bu bizim için yararlı bir uygulama yapmak için gerçekten yeterli değil. FaunaDB konsoluna bir yer imi eklemekten daha iyi bir yol bulalım.
Netlify İşlevlerini Girin
Netlify'ın İşlevler eklentisi, AWS lambda işlevlerini dağıtmanın daha kolay yollarından biridir. Yapılandırma adımı olmadığından, sadece kodu yazmak istediğiniz Kendin Yap projeleri için mükemmeldir.
Bu işlev, projenizde şuna benzeyen bir URL'de yaşayacak: https://myproject.com/.netlify/functions/bookmarks function klasörümüzde oluşturduğumuz dosyanın bookmarks.js olduğunu varsayarsak.
Temel Akış
- İşlev URL'mize sorgu parametresi olarak bir URL iletin.
- URL'yi yüklemek ve varsa sayfanın başlığını ve açıklamasını sıyırmak için işlevi kullanın.
- FaunaDB için ayrıntıları biçimlendirin.
- Ayrıntıları FaunaDB Koleksiyonumuza aktarın.
- Siteyi yeniden oluşturun.
Gereksinimler
Bunu oluştururken ihtiyaç duyacağımız birkaç paketimiz var. İşlevlerimizi yerel olarak oluşturmak için netlify-lambda CLI'yi kullanacağız. request-promise , istek yapmak için kullanacağımız pakettir. Cheerio.js, istenen sayfamızdan belirli öğeleri sıyırmak için kullanacağımız pakettir (Düğüm için jQuery'yi düşünün). Ve son olarak, FaunaDb'ye ihtiyacımız olacak (önceden kurulmuş olması gerekir.
npm install --save netlify-lambda request-promise cheerioBu yüklendikten sonra, fonksiyonları yerel olarak oluşturmak ve sunmak için projemizi yapılandıralım.
package.json "build" ve "serve" betiklerimizi şöyle görünecek şekilde değiştireceğiz:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Uyarı: Netlify'ın İşlevlerinin oluşturmak için kullandığı Webpack ile derleme yaparken Fauna'nın NodeJS sürücüsünde bir hata var. Bunu aşmak için Webpack için bir konfigürasyon dosyası tanımlamamız gerekiyor. Aşağıdaki kodu yeni veya mevcut bir webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Bu dosya bir kez var olduğunda, netlify-lambda komutunu kullandığımızda, ona bu konfigürasyondan çalışmasını söylememiz gerekecek. Bu nedenle "serve" ve "build komut dosyalarımız bu komut için --config değerini kullanır.
İşlev Kat Hizmetleri
Ana İşlev dosyamızı olabildiğince temiz tutmak için, işlevlerimizi ayrı bir bookmarks dizininde oluşturacağız ve bunları ana İşlev dosyamıza aktaracağız.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails() işlevi, dışa aktarılan işleyicimizden geçirilen bir URL alacaktır. Oradan, o URL'deki siteye ulaşacağız ve yer imimiz için veri olarak depolamak üzere sayfanın ilgili kısımlarını alacağız.
İhtiyacımız olan NPM paketlerini isteyerek başlıyoruz:
const rp = require('request-promise'); const cheerio = require('cheerio'); Ardından, istenen sayfa için bir HTML dizesi döndürmek için request-promise modülünü kullanacağız ve bunu bize jQuery benzeri bir arayüz vermek için cheerio .
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Buradan sayfa başlığını ve meta açıklamasını almamız gerekiyor. Bunu yapmak için jQuery'de yaptığınız gibi seçiciler kullanacağız.
Not: Bu kodda, sayfanın başlığını almak için seçici olarak 'head > title' kullanıyoruz. Bunu belirtmezseniz , sayfadaki tüm SVG'lerin içinde ideal olandan daha az olan <title> etiketleri alabilirsiniz.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Eldeki verilerle, yer imimizi FaunaDB'deki Koleksiyonumuza göndermenin zamanı geldi!
saveBookmark(details)
Kaydetme işlevimiz için, URL'nin yanı sıra getDetails aldığımız ayrıntıları tekil bir nesne olarak iletmek isteyeceğiz. Spread operatörü tekrar saldırdı!
const savedResponse = await saveBookmark({url, ...details}); create.js dosyamızda FaunaDB sürücümüze ihtiyaç duymamız ve kurmamız gerekiyor. Bu, 11ty veri dosyamızdan çok tanıdık gelmelidir.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Bunu aradan çıkardığımızda, kodlayabiliriz.
İlk olarak, detaylarımızı Fauna'nın sorgumuz için beklediği bir veri yapısına formatlamamız gerekiyor. Fauna, depolamak istediğimiz verileri içeren data özelliğine sahip bir nesne bekler.
const saveBookmark = async function(details) { const data = { data: details }; ... }Ardından Koleksiyonumuza eklemek için yeni bir sorgu açacağız. Bu durumda sorgu yardımcımızı ve Create yöntemini kullanacağız. Create() iki argüman alır. Birincisi, verilerimizi depolamak istediğimiz Koleksiyon, ikincisi ise verilerin kendisidir.
Kaydettikten sonra, işleyicimize başarı veya başarısızlığı döndürürüz.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Şimdi tam Function dosyasına bir göz atalım.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
Ayırt edici bir göz, işleyicimize aktarılan bir fonksiyonumuz daha olduğunu fark edecek: rebuildSite() . Bu işlev, her yeni — başarılı — yer imi kaydı gönderdiğimizde sitemizi yeni verilerden yeniden oluşturmak için Netlify'ın Kancayı Dağıt işlevini kullanır.
Netlify'da sitenizin ayarlarında, Build & Deploy ayarlarınıza erişebilir ve yeni bir "Build Hook" oluşturabilirsiniz. Kancaların, Dağıtım bölümünde görünen bir adı ve isterseniz ana olmayan bir dalın dağıtılması için bir seçeneği vardır. Bizim durumumuzda buna “new_link” adını vereceğiz ve ana dalımızı dağıtacağız.
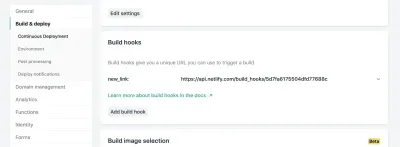
Oradan, sağlanan URL'ye bir POST isteği göndermemiz yeterlidir.
İstek yapmak için bir yola ihtiyacımız var ve zaten request-promise yüklediğimiz için bu paketi dosyamızın en üstünde isteyerek kullanmaya devam edeceğiz.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Bir iOS Kısayolu Ayarlama
Dolayısıyla, bir veritabanımız, verileri görüntülemenin bir yolu ve veri ekleme işlevimiz var, ancak yine de çok kullanıcı dostu değiliz.
Netlify, Lambda işlevlerimiz için URL'ler sağlar, ancak bir mobil cihaza yazmak eğlenceli değildir. Ayrıca bir URL'yi sorgu parametresi olarak ona iletmemiz gerekir. Bu çok fazla çaba. Bunu mümkün olduğunca az çabayla nasıl yapabiliriz?
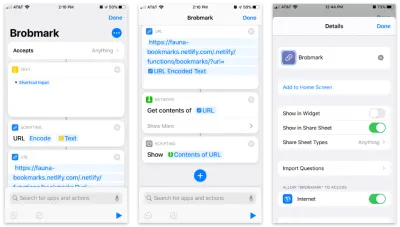
Apple'ın Kısayollar uygulaması, özel öğelerin oluşturulmasının paylaşım sayfanıza girmesini sağlar. Bu kısayolların içinde, paylaşım sürecinde toplanan çeşitli veri isteklerini gönderebiliriz.
İşte adım adım Kısayol:
- Herhangi bir öğeyi kabul edin ve bu öğeyi bir "metin" bloğunda saklayın.
- URL kodlaması için bu metni bir "Komut Dosyası" bloğuna iletin (her ihtimale karşı).
- Bu dizeyi Netlify İşlevimizin URL'si ve
urlsorgu parametresiyle bir URL bloğuna iletin. - "Ağ"dan, URL'mize POST'tan JSON'a bir "İçerik al" bloğu kullanın.
- İsteğe bağlı: "Komut Dosyası Oluşturma" bölümünden son adımın içeriğini "Göster" (gönderdiğimiz verileri onaylamak için).
Buna paylaşım menüsünden erişmek için bu Kısayolun ayarlarını açıyoruz ve “Paylaşım Sayfasında Göster” seçeneğini değiştiriyoruz.
iOS13'ten itibaren, bu paylaşım “Eylemler” sık kullanılanlara eklenebilir ve iletişim kutusunda yüksek bir konuma taşınabilir.
Artık yer imlerini birden fazla platformda paylaşmak için çalışan bir "uygulamamız" var!
Ekstra Mil Git!
Bunu kendiniz denemek için ilham aldıysanız, işlevsellik eklemek için birçok başka olasılık vardır. Kendin Yap ağının sevinci, bu tür uygulamaların sizin için çalışmasını sağlayabilmenizdir. İşte birkaç fikir:
- Hızlı kimlik doğrulama için sahte bir "API anahtarı" kullanın, böylece diğer kullanıcılar sitenize gönderi göndermez (benimki bir API anahtarı kullanır, bu yüzden siteye gönderi göndermeye çalışmayın!).
- Yer imlerini düzenlemek için etiket işlevi ekleyin.
- Başkalarının abone olabilmesi için siteniz için bir RSS beslemesi ekleyin.
- Eklediğiniz bağlantılar için programlı olarak haftalık bir özet e-posta gönderin.
Gerçekten, gökyüzü sınırdır, bu yüzden denemeye başlayın!