
Apache Kafka Mimarisi: Yeni Başlayanlar İçin Kapsamlı Kılavuz [222]
Yayınlanan: 2021-12-23Apache Kafka mimarisinin ayrıntılarına girmeden önce, Kafka'nın neden ilk etapta manşetlere çıktığına biraz ışık tutmak yerinde olacaktır. Başlangıç olarak, Apache Kafka, gerçek zamanlı analitik sağlamak için esas olarak gerçek zamanlı akış veri mimarilerinde kullanım bulur. Dayanıklı, hızlı, ölçeklenebilir ve hataya dayanıklı Kafka'nın yayınla-abone ol mesajlaşma sistemi, IoT sensör verilerini izleme veya hizmet çağrılarını izleme gibi şeyler için kullanım örneklerine sahiptir.
LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal ve diğerleri gibi şirketler, gerçek zamanlı akış verilerini işlemek için Apache Kafka kullanıyor. Örneğin, Kafka'nın ortaya çıktığı LinkedIn, onu operasyonel ölçümleri ve aktivite verilerini izlemek için kullanır. Benzer şekilde, Netflix için Apache Kafka, mesajlaşma, olay oluşturma ve akış işleme ihtiyaçları için fiili standarttır.
Dünyanın en iyi Üniversitelerinden Online yazılım geliştirme eğitimini öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
Apache Kafka'nın faydası, Apache Kafka mimarisinin ve onun temel bileşenlerinin anlaşılmasıyla daha iyi anlaşılır. Öyleyse, Kafka'nın mimarisinin ayrıntılarını keşfedelim.
İçindekiler
Temel Kafka Mimarisi Kavramları
Aşağıdaki kavramlar, Apache Kafka mimarisini anlamak için temeldir:
1. Konular
Kafka konuları, verilerin aktarıldığı kanalları tanımlar. Böylece üreticiler konulara mesajlar yayınlar ve tüketiciler abone oldukları konulardan mesajları okurlar. Bir Kafka kümesi içinde oluşturulan konu sayısında herhangi bir sınırlama yoktur ve her konuyu benzersiz bir ad tanımlar.

2. Brokerler
Aracılar, kapsayıcı olarak çalışan ve farklı bölümlere sahip birden çok konuyu tutan bir Kafka kümesindeki sunuculardır. Benzersiz bir tamsayı kimliği, bir Kafka kümesindeki aracıları tanımlar ve bu aracılardan herhangi biriyle bağlantı, tüm kümeyle bağlantı anlamına gelir.
3. Bölmeler
Kafka konuları, bölümler olarak bilinen birçok bölüme ayrılmıştır. Bölümler sırayla ayrılır ve birden çok tüketicinin belirli bir konudaki verileri paralel olarak okumasına izin verir. Bir konunun bölümleri, Kafka kümesindeki birkaç sunucuya dağıtılır ve her sunucu, çok sayıda bölümü için verileri ve istekleri yönetir. Mesajlar aracıya ve bir anahtara ulaşır ve anahtar, belirli mesajın gideceği bölümü belirler. Bu nedenle, aynı anahtara sahip mesajlar aynı bölüme gider. Anahtarın belirtilmemiş olması durumunda, bölme işlemine döngüsel bir yaklaşım izlenerek karar verilir.
4. Kopyalar
Kafka'da replikalar, planlı bir kapatma veya arıza durumunda veri kaybı olmamasını sağlamak için bölüm yedekleri gibidir. Başka bir deyişle, kopyalar bölümlerin kopyalarıdır.
5. Bölme Ofsetleri
Kafka'daki mesajlar veya kayıtlar bölümlere atandığından, her kayda bölüm içindeki konumunu belirtmek için bir uzaklık verilir. Bu nedenle, bir kayıtla ilişkili ofset değeri, bölüm içinde kolay tanımlanmasına yardımcı olur. Bir bölüm uzaklığı, yalnızca belirli bir bölüm içinde anlam taşır ve kayıtlar bölüm uçlarına eklendiğinden, eski kayıtlar daha düşük ofset değerlerine sahip olacaktır.
6. Üreticiler
Kafka üreticileri bir veya daha fazla konuya mesaj yayınlar ve Kafka kümesine veri gönderir. Bir üretici Kafka konusuna bir mesaj yayınlar yayınlamaz, aracı mesajı alır ve belirli bir bölüme ekler. Ardından üreticiler mesajlarını yayınlamak istedikleri bölümü seçebilirler.
7. Tüketiciler ve Tüketici Grupları
Tüketiciler Kafka kümesinden gelen mesajları okur. Bir tüketici mesajı almaya hazır olduğunda, veriler aracıdan çekilir. Tüketiciler bir tüketici grubuna aittir ve belirli bir gruptaki her tüketici, abone olduğu her konunun bölümlerinin bir alt kümesini okumaktan sorumludur.
8. Lider ve Takipçi
Her Kafka bölümünün lider rolünü oynayan bir sunucusu vardır. Lider, söz konusu bölüm için tüm okuma ve yazma görevlerini yerine getirir. Öte yandan takipçinin görevi liderin verilerini kopyalamaktır. Belirli bir bölümdeki lider başarısız olduğunda, takipçi düğümlerden biri liderin rolünü üstlenir. Bir bölümün takipçisi olmayabilir veya çok sayıda takipçisi olabilir.
Aşağıdaki şema, yukarıda tartışılan Apache Kafka mimarisi bileşenleri arasındaki ilişkilerin basitleştirilmiş bir sunumudur.
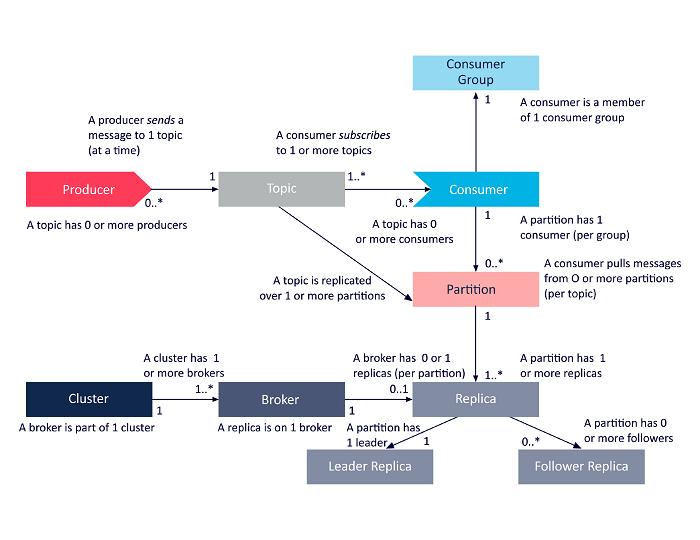
Kaynak
Apache Kafka Küme Mimarisi
İşte ana Kafka mimari bileşenlerine ayrıntılı bir bakış:
1. Kafka Komisyoncuları
Kafka kümeleri genellikle aracılar olarak bilinen birden çok düğüm içerir. Aracılar yük dengesini korur. Her Kafka komisyoncusu, her saniye yüzlerce ve binlerce okuma ve yazma işlemlerini gerçekleştirebilir. Bir komisyoncu, belirli bir bölüm için lider olarak hizmet eder. Liderin bir veya daha fazla takipçisi vardır ve lider hakkındaki veriler söz konusu bölümün takipçileri arasında çoğaltılır.

Takipçilerin liderin verileriyle güncel kalması gerekir. Lider de kendisiyle senkronize olan takipçilerin kaydını tutar. Bir takipçi lideri yakalayamazsa veya artık hayatta değilse, belirli liderle ilişkili senkronize olmayan replika listesinden kaldırılır. Liderin ölümü üzerine takipçiler arasından yeni bir lider seçilir ve seçimi ZooKeeper denetler. Aracılar durumsuz olduğundan, ZooKeeper küme durumunu korur. Bir kümedeki düğümler, ZooKeeper'a hayatta olduklarını bildirmek için kalp atışı mesajları gönderir.
2. Kafka Yapımcıları
Kafka üreticileri, belirli bir bölüm için lider rolü oynayan aracılara doğrudan veri gönderir. Kafka kümelerinin aracıları veya düğümleri, üreticilerin doğrudan mesaj göndermesine yardımcı olur. Bunu, sunucuların canlı olduğu meta veri isteklerini ve bir konunun bölüm liderlerinin canlı durumunu yanıtlayarak, üreticinin isteklerini buna göre yönlendirmesini sağlayarak yaparlar. Yapımcı, mesajları hangi bölüm yayınlamak istediğine karar verir. Kafka'daki mesajlar, kayıt grupları adı verilen gruplar halinde gönderilir. Üreticiler, mesajları bellekte toplar ve belirli bir süre geçtikten sonra veya belirli sayıda mesaj biriktikten sonra toplu olarak gönderir.
3. Kafka Tüketicileri
Kafka tüketicileri, tüketmek istediği bölümleri belirten aracılara istek gönderir. Tüketici, isteğinde bölüm ofsetini belirtir ve aracıdan bir günlük parçası (kaydırma konumundan başlayarak) alır. Günlük, saklama süresi olarak bilinen yapılandırılabilir bir sürenin kayıtlarını içerir.
Günlük verileri içerdiği sürece tüketiciler de verileri yeniden tüketebilir. Kafka tüketicileri, çekme temelli bir yaklaşım üzerinde çalışır; bu, aracıların verileri tüketicilere hemen göndermediği anlamına gelir. Bunun yerine, önce tüketiciler, aracılara veri tüketmeye hazır olduklarını bildiren istekler gönderir. Bu nedenle, çekme tabanlı sistem, tüketicilerin mesajlara boğulmamasını ve geride kaldıklarında yetişebilmelerini sağlar.
Aşağıda basitleştirilmiş bir Apache Kafka mimari diyagramı verilmiştir:
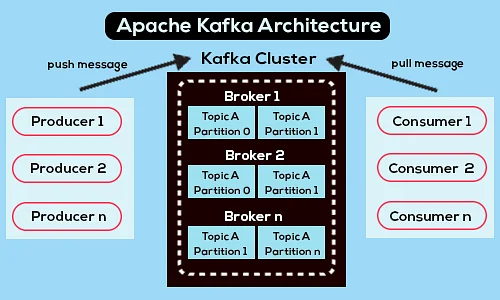
Kaynak
Apache Kafka hakkında daha fazla bilgi edinin.
Apache Kafka API Mimarisi
Apache Kafka'nın dört temel API'si vardır: Streams API, Connector API, Producer API ve Consumer API. Apache Kafka'nın yeteneklerini geliştirmede her birinin hangi rolü oynaması gerektiğini görelim:
1. Akış API'sı
Kafka'nın Akışlar API'si, bir uygulamanın bir akış işleme algoritması kullanarak verileri işlemesine olanak tanır. Uygulamalar, Akışlar API'sini kullanarak bir veya birkaç konudan girdi akışlarını tüketebilir, bunları akış işlemleriyle işleyebilir, çıktı akışları üretebilir ve sonunda bunları bir veya daha fazla konuya gönderebilir. Böylece, Akışlar API'si, giriş akışlarının çıkış akışlarına dönüştürülmesini kolaylaştırır.
2. Bağlayıcı API'sı
Kafka'nın Bağlayıcı API'si, Kafka konularını mevcut veri sistemlerine veya uygulamalarına bağlayan yeniden kullanılabilir üreticileri ve tüketicileri oluşturmak, çalıştırmak ve yönetmek için yararlıdır. Örneğin, ilişkisel bir veritabanına yönelik bir bağlayıcı, tüm güncellemeleri yakalayabilir ve değişikliklerin bir Kafka konusu içinde mevcut olduğundan emin olabilir.

3. Üretici API'sı
Kafka'nın Üretici API'si, uygulamaların Kafka konularına bir kayıt akışı yayınlamasına izin verir.
4. Tüketici API'sı
Kafka'nın Tüketici API'si Uygulamaların Kafka konularına abone olmasına izin verir. Ayrıca, uygulamaların bu Kafka konuları için üretilen kayıt akışlarını işlemesine olanak tanır.
İleriye Doğru
Apache Kafka mimarisi, yazılım geliştiricilerin uğraştığı geniş araç ve dil repertuarının yalnızca küçük bir parçasıdır. Büyük Veriye eğilimi olan, gelişmekte olan bir yazılım geliştiricisi olduğunuzu varsayalım. Bu durumda, upGrad'ın Yazılım Geliştirme - Büyük Veride Uzmanlaşma alanında Executive PG Programı ile hedeflerinize doğru ilk adımı atabilirsiniz .
İşte bazı önemli noktalarla birlikte programa genel bir bakış:
- IIIT Bangalore'dan Veri Bilimi ve Bulut Altyapısı sertifikalarına sahip Yönetici PGP
- 400+ saatlik içerikle çevrimiçi oturumlar ve canlı dersler
- 7+ vaka çalışması ve proje
- 14+ programlama dili ve aracı
- 360 derece kariyer desteği
- Akran ve endüstri ağı
Daha fazla ayrıntı için kaydolun kurs hakkında!
Kafka ne için kullanılır?
Apache Kafka, esas olarak gerçek zamanlı akış verisi ardışık düzenleri ve bu veri akışlarına uyum sağlayan uygulamalar oluşturmak için kullanılır. Mesajlaşma, depolama ve akış işlemenin bir kombinasyonu aracılığıyla gerçek zamanlı ve geçmiş verilerin hem depolanmasına hem de analizine olanak tanır.
Kafka bir çerçeve midir?
Apache Kafka, akış verilerini depolamak, okumak ve analiz etmek için bir çerçeve sağlayan açık kaynaklı bir yazılımdır. Açık kaynaklı olduğu için Kafka, yeni özelliklere, güncellemelere ve yeni kullanıcılar için desteğe katkıda bulunan birçok geliştirici ve kullanıcı ile kullanmakta serbesttir.
Neden Kafka akışlarına ihtiyacımız var?
Kafka Akışları, giriş verilerinin ve çıkış verilerinin Apache Kafka kümesinde depolandığı mikro hizmetler ve akış uygulamaları oluşturmaya yönelik bir istemci kitaplığıdır. Bir yandan Apache Kafka'nın sunucu tarafı küme teknolojisinin avantajlarını sunar. Diğer yandan, istemci tarafında standart Scala ve Java uygulamalarının yazılmasını ve dağıtılmasını kolaylaştırır.