
Sesli Asistanlara Alternatif Bir Ses Kullanıcı Arayüzü
Yayınlanan: 2022-03-10Çoğu insan için sesli kullanıcı arayüzleri denilince akla gelen ilk şey Siri, Amazon Alexa veya Google Asistan gibi sesli asistanlardır. Aslında asistanlar, çoğu insanın bir bilgisayar sistemiyle etkileşim kurmak için sesi kullandığı tek bağlamdır.
Sesli asistanlar, sesli kullanıcı arayüzlerini ana akım haline getirmiş olsa da, asistan paradigması, sesli kullanıcı arayüzlerini kullanmanın, tasarlamanın ve yaratmanın tek ve hatta en iyi yolu değildir.
Bu yazıda, sesli asistanların yaşadığı sorunları inceleyeceğim ve doğrudan sesli etkileşimler dediğim sesli kullanıcı arayüzleri için yeni bir yaklaşım sunacağım.
Sesli Asistanlar Ses Tabanlı Sohbet Robotlarıdır
Sesli asistan, kullanıcı arayüzü olarak simgeler ve menüler yerine doğal dili kullanan bir yazılım parçasıdır. Asistanlar genellikle soruları yanıtlar ve genellikle proaktif olarak kullanıcıya yardımcı olmaya çalışır.
Basit işlemler ve komutlar yerine, asistanlar bir insan konuşmasını taklit eder ve etkileşim yöntemi olarak iki yönlü olarak doğal dili kullanır, yani hem kullanıcıdan girdi alır hem de doğal dili kullanarak kullanıcıya yanıt verir.
İlk yardımcılar diyalog temelli soru cevap sistemleriydi. İlk örneklerden biri, Microsoft Office kullanıcılarına, kullanıcının başarmaya çalıştığını düşündüğü şeye dayalı olarak talimatlar vererek kötü bir şekilde yardımcı olmaya çalışan Microsoft'un Clippy'sidir. Günümüzde, asistan paradigması için tipik bir kullanım örneği, genellikle bir sohbet tartışmasında müşteri desteği için kullanılan sohbet robotlarıdır.
Sesli asistanlar ise yazma ve metin yerine ses kullanan sohbet robotlarıdır. Kullanıcı girişi, seçimler veya metin değil, konuşmadır ve sistemden gelen yanıt da yüksek sesle söylenir. Bu asistanlar, Google Asistan veya Alexa gibi çok sayıda soruyu makul bir şekilde cevaplayabilen genel asistanlar veya fast-food siparişi gibi özel bir amaç için oluşturulmuş özel asistanlar olabilir.
Kullanıcının girdisi genellikle bir veya iki kelimeden oluşsa ve gerçek metin yerine seçimler olarak sunulabilse de, teknoloji geliştikçe konuşmalar daha açık uçlu ve karmaşık olacaktır. Sohbet robotlarının ve asistanların ilk tanımlayıcı özelliği, tipik bir mobil uygulama veya web sitesi kullanıcı deneyimini tanımlayan simgeler, menüler ve işlem stili yerine doğal dil ve konuşma stilinin kullanılmasıdır.
Önerilen okuma : Web Konuşma API'si ve Node.js ile Basit Bir Yapay Zeka Sohbet Robotu Oluşturma
Doğal dil tepkilerinden türetilen ikinci tanımlayıcı özellik, bir kişilik yanılsamasıdır. Sistemin kullandığı ton, kalite ve dil hem asistan deneyimini, hem empati yanılsamasını ve hizmete yatkınlığı hem de onun kişiliğini tanımlar. İyi bir asistan deneyimi fikri, gerçek bir insanla nişanlanmak gibidir.
Ses, iletişim kurmanın en doğal yolu olduğundan, kulağa harika gelebilir, ancak doğal dil yanıtlarını kullanmanın iki büyük sorunu vardır. Bilgisayarların insanları ne kadar iyi taklit edebileceğiyle ilgili bu sorunlardan biri, gelecekte konuşmalı yapay zeka teknolojilerinin geliştirilmesiyle çözülebilir, ancak insan beyninin bilgiyi nasıl ele aldığı sorunu, bir insan sorunudur ve öngörülebilir gelecekte çözülemez. Şimdi bu sorunlara daha sonra bakalım.
Doğal Dil Yanıtlarıyla İlgili İki Sorun
Sesli kullanıcı arayüzleri, elbette sesi bir modalite olarak kullanan kullanıcı arayüzleridir. Ancak ses modalitesi her iki yönde de kullanılabilir: kullanıcıdan bilgi girişi ve sistemden kullanıcıya bilgi çıkışı için. Örneğin, bazı asansörler, kullanıcı bir düğmeye bastıktan sonra kullanıcı seçimini onaylamak için konuşma sentezini kullanır. Daha sonra bilgi girişi için yalnızca sesi kullanan ve bilgileri kullanıcıya geri göstermek için geleneksel grafik kullanıcı arayüzlerini kullanan sesli kullanıcı arayüzlerini tartışacağız.
Sesli asistanlar ise hem giriş hem de çıkış için sesi kullanır . Bu yaklaşımın iki ana sorunu vardır:
Problem 1: Başarısız Bir İnsanın Taklidi
İnsanlar olarak, insan benzeri özellikleri insan olmayan nesnelere atfetme konusunda doğuştan gelen bir eğilimimiz var. Bir bulutun içinde sürüklenen bir adamın özelliklerini görüyoruz veya bir sandviçe bakıyoruz ve bize sırıtıyor gibi görünüyor. Buna antropomorfizm denir.

Bu fenomen asistanlar için de geçerlidir ve onların doğal dil tepkileriyle tetiklenir. Grafiksel bir kullanıcı arayüzü bir şekilde nötr olarak oluşturulabilirken, bir insanın birinin sesinin genç mi yoksa yaşlı mı olduğunu veya erkek mi yoksa kadın mı olduğunu düşünmeye başlamasına imkan yoktur. Bu nedenle, kullanıcı neredeyse asistanın gerçekten bir insan olduğunu düşünmeye başlar.
Ancak, biz insanlar sahteleri tespit etmede çok iyiyiz. Garip bir şekilde, bir şey insana ne kadar yakınsa, küçük sapmalar o kadar bizi rahatsız etmeye başlar. İnsan gibi olmaya çalışan ama tam olarak buna uygun olmayan bir şeye karşı bir ürperti duygusu var. Robotik ve bilgisayar animasyonlarında buna “tekinsiz vadi” denir.

Asistanı ne kadar iyi ve insani hale getirmeye çalışırsak, bir şeyler ters gittiğinde kullanıcı deneyimi o kadar ürkütücü ve hayal kırıklığı yaratabilir. Asistanları deneyen herkes muhtemelen aptalca ve hatta kaba hissettiren bir şeyle yanıt verme sorunuyla karşılaşmıştır.
Sesli asistanların esrarengiz vadisi, asistan kullanıcı deneyiminde üstesinden gelinmesi zor bir kalite sorunu yaratıyor. Aslında, Turing testi (adını ünlü matematikçi Alan Turing'den almıştır), iki ajan arasında bir konuşma sergileyen bir insan değerlendirici, bunlardan hangisinin makine hangisinin insan olduğunu ayırt edemediğinde geçilir. Şimdiye kadar, hiç geçilmedi.
Bu, asistan paradigmasının asla yerine getirilemeyecek insan benzeri bir hizmet deneyimi vaadi verdiği ve kullanıcının hayal kırıklığına uğramasının kaçınılmaz olduğu anlamına gelir. Kullanıcı, insan benzeri asistanına güvenmeye başladığından, başarılı deneyimler yalnızca nihai hayal kırıklığını artırır.
Problem 2: Sıralı ve Yavaş Etkileşimler
Sesli asistanların ikinci sorunu, doğal dil yanıtlarının sıra tabanlı doğasının etkileşimde gecikmeye neden olmasıdır. Bu, beynimizin bilgiyi nasıl işlediğinden kaynaklanmaktadır.
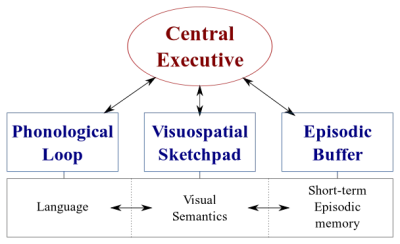
Beynimizde iki tür veri işleme sistemi vardır:
- Konuşmayı işleyen bir dil sistemi ;
- Görsel ve mekansal bilgilerin işlenmesinde uzmanlaşmış bir görsel- uzaysal sistem .
Bu iki sistem paralel olarak çalışabilir, ancak her iki sistem de aynı anda yalnızca bir şeyi işler . Bu nedenle, aynı anda hem konuşabilir hem de araba kullanabilirsiniz, ancak hem mesajlaşıp hem de araba kullanamazsınız çünkü bu faaliyetlerin her ikisi de görsel-uzaysal sistemde gerçekleşecektir.

Benzer şekilde, sesli asistanla konuşurken asistanın sessiz kalması gerekir ve bunun tersi de geçerlidir. Bu, diğer tarafın her zaman tamamen pasif olduğu sıra tabanlı bir konuşma yaratır.
Ancak, arkadaşınızla tartışmak istediğiniz zor bir konuyu düşünün. Muhtemelen telefon yerine yüz yüze konuşursunuz, değil mi? Bunun nedeni, yüz yüze bir konuşmada, konuşma ortağımıza gerçek zamanlı görsel geri bildirim vermek için sözlü olmayan iletişimi kullanmamızdır. Bu, iki yönlü bir bilgi alışverişi döngüsü yaratır ve her iki tarafın da aynı anda konuşmaya aktif olarak katılmasını sağlar.
Asistanlar gerçek zamanlı görsel geri bildirim vermez. Kullanıcının konuşmayı ne zaman durdurduğuna ve ancak bundan sonra yanıt verdiğine karar vermek için uç noktalama adı verilen bir teknolojiye güvenirler. Ve cevap verdiklerinde, aynı anda kullanıcıdan herhangi bir girdi almazlar. Deneyim tamamen tek yönlü ve sıra tabanlıdır.
Çift yönlü ve gerçek zamanlı yüz yüze bir konuşmada, her iki taraf da hem görsel hem de dilsel sinyallere anında tepki verebilir. Bu, insan beyninin farklı bilgi işleme sistemlerini kullanır ve konuşma daha pürüzsüz ve daha verimli hale gelir.
Sesli yardımcılar, hem giriş hem de çıkış kanalları olarak doğal dili kullandıkları için tek yönlü modda takılıp kalıyorlar. Ses, giriş için yazmaya göre dört kata kadar daha hızlı olsa da, sindirmek okumaktan önemli ölçüde daha yavaştır. Bilgilerin sıralı olarak işlenmesi gerektiğinden , bu yaklaşım yalnızca yardımcıdan fazla çıktı gerektirmeyen “ışıkları kapat” gibi basit komutlar için işe yarar.

Daha önce, yalnızca kullanıcıdan veri girişi için ses kullanan sesli kullanıcı arabirimlerini tartışacağıma söz vermiştim. Bu tür sesli kullanıcı arabirimleri, sesli kullanıcı arabirimlerinin en iyi yanlarından - doğallık, hız ve kullanım kolaylığı - yararlanır, ancak kötü kısımlarından - tekinsiz vadi ve sıralı etkileşimlerden - etkilenmez.
Bu alternatifi düşünelim.
Sesli Asistana Daha İyi Bir Alternatif
Sesli asistanlarda bu sorunların üstesinden gelmenin çözümü, doğal dil yanıtlarını bırakmak ve onları gerçek zamanlı görsel geri bildirimle değiştirmektir. Geri bildirimi görsele dönüştürmek, kullanıcının aynı anda geri bildirim vermesini ve almasını sağlayacaktır. Bu, uygulamanın kullanıcıyı kesintiye uğratmadan tepki vermesini ve çift yönlü bir bilgi akışını etkinleştirmesini sağlayacaktır. Bilgi akışı çift yönlü olduğu için verimi daha fazladır.
Şu anda sesli asistanların en çok kullanıldığı durumlar alarm ayarlamak, müzik çalmak, hava durumunu kontrol etmek ve basit sorular sormaktır. Bunların tümü, başarısız olduğunda kullanıcıyı çok fazla hayal kırıklığına uğratmayan düşük riskli görevlerdir .
Wall Street Journal'dan David Pierce'ın bir keresinde yazdığı gibi:
"Bir uçuş rezervasyonu yapmayı veya bir sesli asistan aracılığıyla bütçemi yönetmeyi ya da hoparlörüme bağırarak malzemelerimi bağırarak diyetimi takip etmeyi hayal edemiyorum."
— Wall Street Journal'dan David Pierce
Bunlar doğru gitmesi gereken bilgi ağırlıklı görevlerdir.
Ancak, sonunda sesli kullanıcı arayüzü başarısız olacaktır. Anahtar, bunu mümkün olduğunca hızlı bir şekilde kapatmaktır. Klavyede yazarken veya yüz yüze konuşmada bile birçok hata oluyor. Bununla birlikte, bu hiç de sinir bozucu değildir, çünkü kullanıcı sadece geri al tuşuna tıklayarak ve tekrar deneyerek veya açıklama isteyerek kurtarabilir.
Hatalardan bu hızlı kurtarma , kullanıcının daha verimli olmasını sağlar ve onları bir asistanla garip bir konuşmaya zorlamaz.
Doğrudan Ses Etkileşimleri
Çoğu uygulamada, eylemler, ekrandaki grafik öğeleri manipüle ederek, dürterek veya kaydırarak (dokunmatik ekranlarda), fareyi tıklatarak ve/veya klavyedeki düğmelere basarak gerçekleştirilir. Bu grafik öğelerini işlemek için ek bir seçenek veya modalite olarak ses girişi eklenebilir. Bu tür bir etkileşime doğrudan sesli etkileşim denilebilir.
Doğrudan sesli etkileşimler ve asistanlar arasındaki fark, bir avatar olan asistandan bir görevi yerine getirmesini istemek yerine, kullanıcının grafiksel kullanıcı arayüzünü doğrudan sesle değiştirmesidir.
“Bu semantik değil mi?” diye sorabilirsiniz. Bilgisayarla konuşacaksanız, doğrudan bilgisayara mı yoksa sanal bir kişi aracılığıyla mı konuşuyor olmanız gerçekten önemli mi? Her iki durumda da, sadece bir bilgisayarla konuşuyorsunuz!
Evet, fark ince ama kritik. Bir GUI'de ( Grafik Kullanıcı Arayüzü) bir düğmeyi veya menü öğesini tıklattığınızda, bir makineyi çalıştırdığımız bariz bir şekilde açıktır. Bir kişinin yanılsaması yoktur. Bu tıklamayı sesli komutla değiştirerek insan-bilgisayar etkileşimini iyileştiriyoruz. Asistan paradigma ile ise insandan insana etkileşimin bozulmuş bir versiyonunu yaratıyoruz ve dolayısıyla tekinsiz vadiye yolculuk yapıyoruz.
Ses işlevlerinin grafik kullanıcı arabirimiyle harmanlanması, farklı modalitelerin gücünden yararlanma potansiyeli de sunar. Kullanıcı uygulamayı çalıştırmak için sesi kullanabilirken, geleneksel grafik arayüzü de kullanma becerisine sahiptir. Bu, kullanıcının dokunma ve ses arasında sorunsuz bir şekilde geçiş yapmasına ve bağlamlarına ve görevlerine göre en iyi seçeneği seçmesine olanak tanır.
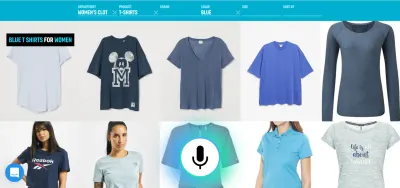
Örneğin ses, zengin bilgi girişi için çok etkili bir yöntemdir. Birkaç geçerli alternatif arasından seçim yapmak, dokunmak veya tıklamak muhtemelen daha iyidir. Kullanıcı daha sonra "Londra'dan New York'a yarın kalkan uçuşları göster" gibi bir şey söyleyerek yazma ve göz atma yerine geçebilir ve dokunmayı kullanarak listeden en iyi seçeneği seçebilir.
Şimdi “Tamam, bu harika görünüyor, öyleyse neden daha önce bu tür sesli kullanıcı arayüzlerinin örneklerini görmedik?” Diye sorabilirsiniz. Neden büyük teknoloji şirketleri böyle bir şey için araçlar geliştirmiyor?” Eh, muhtemelen bunun birçok nedeni var. Bunun bir nedeni, mevcut sesli asistan paradigmasının, son kullanıcılardan aldıkları verilerden yararlanmaları için muhtemelen en iyi yol olmasıdır. Bir başka neden de ses teknolojilerinin inşa edilme şekliyle ilgilidir.
İyi çalışan bir sesli kullanıcı arabirimi iki farklı parça gerektirir:
- Konuşmayı metne dönüştüren konuşma tanıma ;
- Bu metinden anlam çıkaran doğal dil anlama bileşenleri.
İkinci kısım ise “Salon ışıklarını kapat” ve “Salondaki ışıkları kapat lütfen” sözlerini aynı eyleme dönüştüren sihirdir.
Önerilen okuma : API.AI Kullanarak Google Home İçin Kendi Eyleminizi Nasıl Oluşturursunuz
Daha önce ekranlı bir asistan kullandıysanız (Siri veya Google Asistan gibi), konuşma metnini neredeyse gerçek zamanlı olarak aldığınızı fark etmişsinizdir, ancak konuşmayı bıraktıktan sonra sistemin açılması birkaç saniye alır. aslında istediğiniz eylemi gerçekleştirir. Bunun nedeni hem konuşma tanıma hem de doğal dil anlamanın sırayla gerçekleşmesidir.
Bunun nasıl değiştirilebileceğini görelim.
Gerçek Zamanlı Konuşulan Dil Anlayışı: Daha Etkili Sesli Komutlar İçin Gizli Sos
Bir uygulamanın kullanıcı girdisine ne kadar hızlı tepki verdiği, uygulamanın genel kullanıcı deneyiminde önemli bir faktördür. Orijinal iPhone'un en önemli yeniliği, son derece duyarlı ve reaktif dokunmatik ekranıydı. Bir sesli kullanıcı arayüzünün ses girişine anında tepki verme yeteneği de aynı derecede önemlidir.
Kullanıcı ve kullanıcı arayüzü arasında hızlı bir çift yönlü bilgi alışverişi döngüsü oluşturmak için, ses etkin GUI, kullanıcı eyleme geçirilebilir bir şey söylediğinde anında - hatta cümlenin ortasında - tepki verebilmelidir. Bu, akıcı konuşma dili anlayışı adı verilen bir teknik gerektirir.
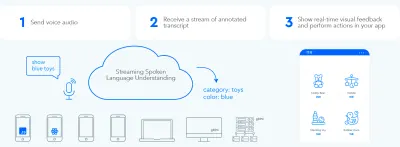
Kullanıcı talebini işleme koymadan önce kullanıcının konuşmayı kesmesini bekleyen geleneksel sıra tabanlı sesli asistan sistemlerinin aksine, akıcı konuşma dili anlayışını kullanan sistemler aktif olarak kullanıcı konuşmaya başladığı andan itibaren kullanıcının niyetini anlamaya çalışır. Kullanıcı eyleme geçirilebilir bir şey söylediğinde, kullanıcı arayüzü anında buna tepki verir.
Anında yanıt, sistemin kullanıcıyı anladığını hemen doğrular ve kullanıcıyı devam etmeye teşvik eder. İnsandan insana iletişimde bir baş sallama veya kısa bir “a-ha” ile benzer. Bu, desteklenen daha uzun ve daha karmaşık ifadelerle sonuçlanır. Sırasıyla, sistem kullanıcıyı anlamıyorsa veya kullanıcı yanlış konuşuyorsa, anında geri bildirim, hızlı kurtarma sağlar . Kullanıcı hemen düzeltip devam edebilir, hatta sözlü olarak kendini düzeltebilir: “Bunu istiyorum, hayır demek istedim, şunu istiyorum.” Bu tür bir uygulamayı sesli arama demomuzda kendiniz deneyebilirsiniz.
Demoda görebileceğiniz gibi, gerçek zamanlı görsel geri bildirim, kullanıcının kendisini doğal olarak düzeltmesini sağlar ve onları ses deneyimine devam etmeye teşvik eder. Sanal bir kişilikle karıştırılmadıkları için, olası hatalarla, kişisel hakaretler olarak değil, yazım hatalarına benzer şekilde ilişki kurabilirler. Kullanıcıya verilen bilgiler, dakikada yaklaşık 150 kelimelik tipik konuşma hızıyla sınırlı olmadığı için, deneyim daha hızlı ve daha doğaldır .
Önerilen okuma : Lyndon Cerejo tarafından Ses Deneyimlerinin Tasarlanması
Sonuçlar
Sesli asistanlar şimdiye kadar sesli kullanıcı arayüzlerinin en yaygın kullanımı olsa da, doğal dil yanıtlarının kullanımı onları verimsiz ve doğal olmayan hale getiriyor. Ses, bilgi girişi için harika bir yöntemdir, ancak bir makinenin konuşmasını dinlemek çok ilham verici değildir. Bu, sesli asistanların büyük sorunudur.
Bu nedenle sesin geleceği bir bilgisayarla yapılan konuşmalarda değil, sıkıcı kullanıcı görevlerinin en doğal iletişim biçimiyle değiştirilmesinde olmalıdır: konuşma . Doğrudan sesli etkileşimler, web veya mobil uygulamalarda form doldurma deneyimini geliştirmek, daha iyi arama deneyimleri oluşturmak ve bir uygulamada kontrol etmek veya gezinmek için daha verimli bir yol sağlamak için kullanılabilir.
Tasarımcılar ve uygulama geliştiriciler, sürekli olarak uygulamalarında veya web sitelerinde sürtünmeyi azaltmanın yollarını arıyor . Mevcut grafiksel kullanıcı arayüzünün bir ses modalitesi ile geliştirilmesi, özellikle son kullanıcının mobilde ve hareket halindeyken ve yazmanın zor olduğu belirli durumlarda, kullanıcı etkileşimlerinin birkaç kat daha hızlı olmasını sağlayacaktır. Aslında, sesli arama, bir masaüstü bilgisayar kullanırken bile, geleneksel bir arama filtreleme kullanıcı arabiriminden beş kata kadar daha hızlı olabilir.
Bir dahaki sefere, uygulamanızda belirli bir kullanıcı görevini nasıl daha kolay, daha eğlenceli hale getirebileceğinizi düşünürken veya dönüşümleri artırmakla ilgileniyorsanız, bu kullanıcı görevinin doğal dilde doğru bir şekilde tanımlanıp tanımlanamayacağını düşünün. Cevabınız evet ise, kullanıcı arabiriminizi bir ses modalitesi ile tamamlayın, ancak kullanıcılarınızı bir bilgisayarla konuşmaya zorlamayın .
Kaynaklar
- Joan Palmiter Bajorek, UXmatters “Önce Ses Karşı Geleceğin Çok Modlu Kullanıcı Arayüzleri”
- Hannes Heikinheimo, Speechly "Üretken Ses Etkin Uygulamalar Oluşturma Yönergeleri"
- Ottomatias Peura, UXmatters “Dokunmatik Ekran Uygulamalarınızın Ses Özelliklerine Sahip Olması İçin 6 Neden”
- Somut ve Maddi Olmayanı Karıştırmak: Adobe XD, Nick Babich, Smashing Magazine Kullanarak Çok Modlu Arayüzler Tasarlamak
( Adobe XD, benzer bir şeyin prototipini oluşturmak için olabilir ) - “Ses Hızında Verimlilik: Ses Destekli Operasyonların Vaadi,” Eric Turkington, RAIN
- E-Ticaret sesli arama filtrelemede (video versiyonu) gerçek zamanlı görsel geri bildirimi gösteren bir demo
- Speechly, bu tür kullanıcı arayüzleri için geliştirici araçları sağlar
- Açık kaynak alternatifi: voice2json