
Machine Learning กับ Java คืออะไร? จะนำไปปฏิบัติได้อย่างไร?
เผยแพร่แล้ว: 2021-03-10สารบัญ
แมชชีนเลิร์นนิงคืออะไร?
แมชชีนเลิร์นนิงเป็นแผนกหนึ่งของปัญญาประดิษฐ์ที่เรียนรู้จากข้อมูล ตัวอย่าง และประสบการณ์ที่มีอยู่เพื่อเลียนแบบพฤติกรรมและสติปัญญาของมนุษย์ โปรแกรมที่สร้างขึ้นโดยใช้การเรียนรู้ของเครื่องสามารถสร้างตรรกะได้ด้วยตัวเองโดยที่มนุษย์ไม่ต้องเขียนโค้ดด้วยตนเอง
ทุกอย่างเริ่มต้นด้วยการทดสอบทัวริงในต้นปี 1950 เมื่อ Alan Turning สรุปว่าเพื่อให้คอมพิวเตอร์มีสติปัญญาที่แท้จริง จะต้องจัดการหรือโน้มน้าวใจมนุษย์ว่าเป็นมนุษย์ด้วย แมชชีนเลิร์นนิงเป็นแนวคิดที่ค่อนข้างเก่า แต่วันนี้เท่านั้นที่สาขาที่เกิดขึ้นใหม่นี้อยู่ภายใต้การตระหนักรู้ เนื่องจากขณะนี้คอมพิวเตอร์สามารถประมวลผลอัลกอริธึมที่ซับซ้อนได้ อัลกอริธึมแมชชีนเลิร์นนิงมีวิวัฒนาการในช่วงทศวรรษที่ผ่านมาเพื่อรวมทักษะการคำนวณที่ซับซ้อน ซึ่งนำไปสู่การเพิ่มประสิทธิภาพในความสามารถในการเลียนแบบ
แอปพลิเคชันการเรียนรู้ของเครื่องเพิ่มขึ้นในอัตราที่น่าตกใจเช่นกัน ตั้งแต่การดูแลสุขภาพ การเงิน การวิเคราะห์ และการศึกษา ไปจนถึงการผลิต การตลาด และการดำเนินงานของรัฐบาล ทุกอุตสาหกรรมได้เห็นการเพิ่มขึ้นอย่างมากในด้านคุณภาพและประสิทธิภาพหลังจากใช้เทคโนโลยีการเรียนรู้ของเครื่อง มีการปรับปรุงเชิงคุณภาพอย่างกว้างขวางทั่วโลก ดังนั้นจึงผลักดันความต้องการมืออาชีพด้านแมชชีนเลิร์นนิง
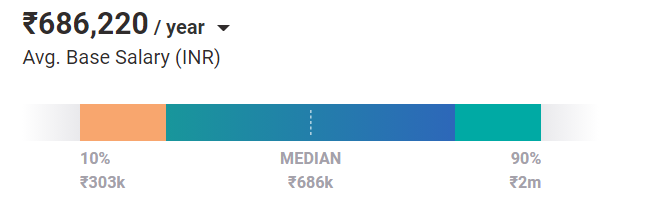
โดยเฉลี่ย วิศวกรแมชชีนเลิร์นนิงจะได้รับ เงินเดือน ₹686,220 / ปีในวันนี้ และนั่นเป็นกรณีของตำแหน่งระดับเริ่มต้น ด้วยประสบการณ์และทักษะ พวกเขาสามารถสร้างรายได้สูงถึง ₹2 ล้านต่อปีในอินเดีย
ประเภทของอัลกอริธึมการเรียนรู้ของเครื่อง
อัลกอริธึมการเรียนรู้ของเครื่องมีสามประเภท:
1. Supervised Learning : ในการเรียนรู้ประเภทนี้ ชุดข้อมูลการฝึกอบรมจะแนะนำอัลกอริธึมในการทำนายหรือวิเคราะห์ที่แม่นยำ ใช้การเรียนรู้จากชุดข้อมูลการฝึกอบรมที่ผ่านมาเพื่อประมวลผลข้อมูลใหม่ ต่อไปนี้คือตัวอย่างบางส่วนของโมเดลการเรียนรู้ของเครื่องภายใต้การดูแล:

- การถดถอยเชิงเส้น
- การถดถอยโลจิสติก
- ต้นไม้แห่งการตัดสินใจ
2. Unsupervised Learning : ในการเรียนรู้ประเภทนี้ โมเดลการเรียนรู้ของเครื่องจะเรียนรู้จากข้อมูลที่ไม่มีป้ายกำกับ ใช้การจัดกลุ่มข้อมูลโดยการจัดกลุ่มวัตถุหรือทำความเข้าใจความสัมพันธ์ระหว่างวัตถุ หรือใช้คุณสมบัติทางสถิติเพื่อวิเคราะห์ ตัวอย่างของอัลกอริธึมการเรียนรู้แบบไม่มีผู้ดูแลคือ:
- K-หมายถึงการจัดกลุ่ม
- การจัดกลุ่มแบบลำดับชั้น
3. Reinforcement Learning : กระบวนการนี้ขึ้นอยู่กับ Hit และ Trial เป็นการเรียนรู้โดยปฏิสัมพันธ์กับพื้นที่หรือสิ่งแวดล้อม อัลกอริทึม RL เรียนรู้จากประสบการณ์ที่ผ่านมาโดยโต้ตอบกับสิ่งแวดล้อมและกำหนดแนวทางปฏิบัติที่ดีที่สุด
จะนำ Machine Learning ไปใช้กับ Java ได้อย่างไร?
Java เป็นหนึ่งในภาษาการเขียนโปรแกรมชั้นนำที่ใช้สำหรับการนำอัลกอริธึมการเรียนรู้ของเครื่องไปใช้ ห้องสมุดส่วนใหญ่เป็นโอเพ่นซอร์ส โดยให้การสนับสนุนเอกสารที่ครอบคลุม บำรุงรักษาง่าย สามารถทำการตลาดได้ และอ่านง่าย
ต่อไปนี้คือไลบรารีแมชชีนเลิร์นนิ่ง 10 อันดับแรกที่ใช้ในการปรับใช้การเรียนรู้ของเครื่องใน Java ทั้งนี้ขึ้นอยู่กับความนิยม
1. อดัมส์
Advanced-Data mining And Machine Learning System หรือ ADAMS เกี่ยวข้องกับการสร้างระบบเวิร์กโฟลว์ที่แปลกใหม่และยืดหยุ่น และเพื่อจัดการกระบวนการในโลกแห่งความเป็นจริงที่ซับซ้อน ADAMS ใช้สถาปัตยกรรมแบบต้นไม้เพื่อจัดการการไหลของข้อมูล แทนที่จะทำการเชื่อมต่ออินพุต-เอาท์พุตด้วยตนเอง
ไม่จำเป็นต้องมีการเชื่อมต่อที่ชัดเจน มันขึ้นอยู่กับหลักการ "น้อยแต่มาก" และทำการดึงข้อมูล การแสดงภาพ และการแสดงภาพที่ขับเคลื่อนด้วยข้อมูล ADAMS เชี่ยวชาญในการประมวลผลข้อมูล การสตรีมข้อมูล การจัดการฐานข้อมูล การเขียนสคริปต์ และเอกสารประกอบ
2. JavaML
JavaML นำเสนอ ML และอัลกอริธึมการทำเหมืองข้อมูลที่หลากหลายซึ่งเขียนขึ้นสำหรับ Java เพื่อสนับสนุนวิศวกรซอฟต์แวร์ โปรแกรมเมอร์ นักวิทยาศาสตร์ข้อมูล และนักวิจัย ทุกอัลกอริธึมมีอินเทอร์เฟซทั่วไปที่ใช้งานง่ายและมีเอกสารสนับสนุนมากมาย แม้ว่าจะไม่มี GUI ก็ตาม
การใช้งานค่อนข้างง่ายและตรงไปตรงมาเมื่อเปรียบเทียบกับอัลกอริธึมการทำคลัสเตอร์อื่นๆ คุณสมบัติหลัก ได้แก่ การจัดการข้อมูล เอกสาร การจัดการฐานข้อมูล การจัดประเภทข้อมูล การจัดกลุ่ม การเลือกคุณสมบัติ และอื่นๆ
เข้าร่วม หลักสูตรแมชชีนเลิ ร์นนิง ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
3. WEKA
Weka ยังเป็นไลบรารีการเรียนรู้ของเครื่องโอเพ่นซอร์สที่เขียนขึ้นสำหรับ Java ที่รองรับการเรียนรู้เชิงลึก มีชุดของอัลกอริธึมการเรียนรู้ของเครื่องและพบการใช้งานอย่างกว้างขวางในการทำเหมืองข้อมูล การเตรียมข้อมูล การจัดกลุ่มข้อมูล การสร้างภาพข้อมูล และการถดถอย รวมถึงการดำเนินการข้อมูลอื่นๆ
ตัวอย่าง: เราจะสาธิตสิ่งนี้โดยใช้ชุดข้อมูลโรคเบาหวานขนาดเล็ก
ขั้นตอนที่ 1 : โหลดข้อมูลโดยใช้ Weka
| นำเข้า weka.core.Instances; นำเข้า weka.core.converters.ConverterUtils.DataSource; คลาสสาธารณะหลัก { โมฆะคงที่สาธารณะหลัก (สตริง [] args) พ่นข้อยกเว้น { // การระบุแหล่งข้อมูล DataSource dataSource = แหล่งข้อมูลใหม่ (“data.arff”); // กำลังโหลดชุดข้อมูล อินสแตนซ์ dataInstances = dataSource.getDataSet(); // แสดงจำนวนอินสแตนซ์ log.info(“จำนวนอินสแตนซ์ที่โหลดคือ: ” + dataInstances.numInstances()); log.info(“data:” + dataInstances.toString()); } } |
ขั้นตอนที่ 2: ชุดข้อมูลมี 768 อินสแตนซ์ เราจำเป็นต้องเข้าถึงจำนวนแอตทริบิวต์ เช่น 9
| log.info(“จำนวนแอตทริบิวต์ (คุณสมบัติ) ในชุดข้อมูล: ” + dataInstances.numAttributes()); |
ขั้นตอนที่ 3 : เราจำเป็นต้องกำหนดคอลัมน์เป้าหมายก่อนที่เราจะสร้างแบบจำลองและค้นหาจำนวนคลาส
| // การระบุดัชนีฉลาก dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // รับจำนวน log.info(“จำนวนคลาส: ” + dataInstances.numClasses()); |
ขั้นตอนที่ 4 : ตอนนี้เราจะสร้างแบบจำลองโดยใช้ตัวแยกประเภทต้นไม้อย่างง่าย J48
| // การสร้างตัวแยกประเภทแผนผังการตัดสินใจ J48 treeClassifier = ใหม่ J48(); treeClassifier.setOptions (สตริงใหม่ [] { “-U” }); treeClassifier.buildClassifier (dataInstances); |
โค้ดด้านบนเน้นถึงวิธีการสร้าง unpruned tree ที่ประกอบด้วยอินสแตนซ์ข้อมูลที่จำเป็นสำหรับการฝึกโมเดล เมื่อโครงสร้างต้นไม้ถูกพิมพ์หลังจากการฝึกแบบจำลอง เราสามารถกำหนดได้ว่ากฎเกณฑ์ถูกสร้างขึ้นภายในอย่างไร
| พลาส <= 127 | มวล <= 26.4 | | ก่อน <= 7: ทดสอบแล้ว_ลบ (117.0/1.0) | | ก่อน > 7 | | | มวล <= 0: ทดสอบแล้ว_บวก (2.0) | | | มวล > 0: ทดสอบแล้ว_ลบ (13.0) | มวล > 26.4 | | อายุ <= 28: ทดสอบแล้ว_ลบ (180.0/22.0) | | อายุ > 28 | | | พลาส <= 99: ทดสอบแล้ว_ลบ (55.0/10.0) | | | พลาส > 99 | | | | pedi <= 0.56: ทดสอบแล้ว_ลบ (84.0/34.0) | | | | pedi > 0.56 | | | | | ก่อน <= 6 | | | | | | อายุ <= 30: ทดสอบแล้ว_บวก (4.0) | | | | | | อายุ > 30 | | | | | | | อายุ <= 34: ทดสอบแล้ว_ลบ (7.0/1.0) | | | | | | | อายุ > 34 | | | | | | | | มวล <= 33.1: ทดสอบแล้ว_บวก (6.0) | | | | | | | | มวล > 33.1: ทดสอบแล้ว_ลบ (4.0/1.0) | | | | | ก่อน > 6: ทดสอบแล้ว_บวก (13.0) พลาส > 127 | มวล <= 29.9 | | พลาส <= 145: ทดสอบแล้ว_ลบ (41.0/6.0) | | พลาส > 145 | | | อายุ <= 25: ทดสอบแล้ว_ลบ (4.0) | | | อายุ > 25 | | | | อายุ <= 61 | | | | | มวล <= 27.1: ทดสอบแล้ว_บวก (12.0/1.0) | | | | | มวล > 27.1 | | | | | | กด <= 82 | | | | | | | pedi <= 0.396: ทดสอบแล้ว_บวก (8.0/1.0)  | | | | | | | pedi > 0.396: ทดสอบแล้ว_ลบ (3.0) | | | | | | ก่อนหน้า > 82: test_negative (4.0) | | | | อายุ > 61: ทดสอบแล้ว_ลบ (4.0) | มวล > 29.9 | | พลาส <= 157 | | | ก่อนหน้า <= 61: ทดสอบแล้ว_บวก (15.0/1.0) | | | ก่อนหน้า > 61 | | | | อายุ <= 30: ทดสอบแล้ว_ลบ (40.0/13.0) | | | | อายุ > 30: ทดสอบแล้ว_บวก (60.0/17.0) | | plas > 157: ทดสอบแล้ว_บวก (92.0/12.0) จำนวนใบ : 22 ขนาดของต้น : 43 |
4. Apache Mahaut
Mahaut คือชุดของอัลกอริทึมที่ช่วยปรับใช้การเรียนรู้ของเครื่องโดยใช้ Java เป็นเฟรมเวิร์กพีชคณิตเชิงเส้นที่ปรับขนาดได้ ซึ่งนักพัฒนาสามารถดำเนินการทางคณิตศาสตร์ การวิเคราะห์นักสถิติได้ มักใช้โดยนักวิทยาศาสตร์ข้อมูล วิศวกรวิจัย และผู้เชี่ยวชาญด้านการวิเคราะห์เพื่อสร้างแอปพลิเคชันที่พร้อมใช้งานสำหรับองค์กร ความสามารถในการปรับขนาดและความยืดหยุ่นทำให้ผู้ใช้สามารถใช้การจัดกลุ่มข้อมูล ระบบแนะนำ และสร้างแอป Machine Learning ที่มีประสิทธิภาพได้อย่างรวดเร็วและง่ายดาย
5. Deeplearning4j
Deeplearning4j เป็นไลบรารีการเขียนโปรแกรมที่เขียนด้วยภาษาจาวาและให้การสนับสนุนอย่างกว้างขวางสำหรับการเรียนรู้เชิงลึก เป็นเฟรมเวิร์กโอเพนซอร์ซที่รวมเครือข่ายนิวรัลเชิงลึกและการเรียนรู้การเสริมแรงเชิงลึกเพื่อรองรับการดำเนินธุรกิจ มันเข้ากันได้กับ Scala, Kotlin, Apache Spark, Hadoop และภาษา JVM อื่น ๆ และเฟรมเวิร์กการประมวลผลข้อมูลขนาดใหญ่
โดยทั่วไปจะใช้เพื่อตรวจจับรูปแบบและอารมณ์ในเสียง คำพูด และข้อความที่เขียน มันทำหน้าที่เป็นเครื่องมือ DIY ที่สามารถค้นพบความคลาดเคลื่อนในการทำธุรกรรมและจัดการงานหลายอย่าง เป็นไลบรารีแบบกระจายเกรดเชิงพาณิชย์ซึ่งมีเอกสาร API โดยละเอียดเนื่องจากมีลักษณะเป็นโอเพนซอร์ส
นี่คือตัวอย่างวิธีที่คุณสามารถใช้การเรียนรู้ของเครื่องโดยใช้ Deeplearning4j
ตัวอย่าง : เมื่อใช้ Deeplearning4j เราจะสร้างโมเดล Convolution Neural Network (CNN) เพื่อจำแนกตัวเลขที่เขียนด้วยลายมือด้วยความช่วยเหลือของไลบรารี MNIST
ขั้นตอนที่ 1 : โหลดชุดข้อมูลเพื่อแสดงขนาด
| DataSetIterator MNISTTrain = MnistDataSetIterator ใหม่ (batchSize, true, seed); DataSetIterator MNISTTest = MnistDataSetIterator ใหม่ (batchSize, false, seed); |
ขั้นตอนที่ 2 : ตรวจสอบให้แน่ใจว่าชุดข้อมูลมีป้ายกำกับที่ไม่ซ้ำกันสิบรายการ
| log.info(“จำนวนป้ายกำกับทั้งหมดที่พบในชุดข้อมูลการฝึก” + MNISTTrain.totalOutcomes()); log.info(“จำนวนป้ายกำกับทั้งหมดที่พบในชุดข้อมูลทดสอบ” + MNISTTest.totalOutcomes()); |
ขั้นตอนที่ 3 : ตอนนี้ เราจะกำหนดค่าสถาปัตยกรรมแบบจำลองโดยใช้เลเยอร์การบิดสองชั้นพร้อมกับเลเยอร์ที่แบนเพื่อแสดงผลลัพธ์
มีตัวเลือกใน Deeplearning4j ที่ให้คุณเริ่มต้นโครงร่างน้ำหนักได้
| // สร้างโมเดล CNN MultiLayerConfiguration conf = ใหม่ NeuralNetConfiguration.Builder () .seed(seed) // สุ่มเมล็ด .l2(0.0005) // การทำให้เป็นมาตรฐาน .weightInit(WeightInit.XAVIER) // การเริ่มต้นของโครงร่างน้ำหนัก .updater(new Adam(1e-3)) // การตั้งค่าอัลกอริธึมการปรับให้เหมาะสม .รายการ() .layer (ConvolutionLayer.Builder ใหม่ (5, 5) //การตั้งค่าการก้าว ขนาดเคอร์เนล และฟังก์ชันการเปิดใช้งาน .nIn(nช่อง) .stride(1,1) .nOut(20) .activation(การเปิดใช้งาน.IDENTITY) .สร้าง()) .layer (ใหม่ SubsamplingLayer.Builder (PoolingType.MAX) // ลดขนาดการสุ่มตัวอย่าง .kernelSize(2,2) .stride(2,2) .สร้าง()) .layer (ConvolutionLayer.Builder ใหม่ (5, 5) // การตั้งค่าก้าวย่าง ขนาดเคอร์เนล และฟังก์ชันการเปิดใช้งาน .stride(1,1) .nOut(50) .activation(การเปิดใช้งาน.IDENTITY) .สร้าง()) .layer (ใหม่ SubsamplingLayer.Builder (PoolingType.MAX) // ลดขนาดการสุ่มตัวอย่าง .kernelSize(2,2) .stride(2,2) .สร้าง()) .layer(ใหม่ DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer (OutputLayer.Builder ใหม่ (LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(เอาต์พุตจำนวน) .activation(การเปิดใช้งาน.SOFTMAX) .สร้าง()) // เลเยอร์เอาต์พุตสุดท้ายคือ 28 × 28 ที่มีความลึก 1 .setInputType(InputType.convolutionalFlat(28,28,1)) .สร้าง(); |
ขั้นตอนที่ 4 : หลังจากที่เรากำหนดค่าสถาปัตยกรรมแล้ว เราจะเริ่มต้นโหมดและชุดข้อมูลการฝึก และเริ่มการฝึกแบบจำลอง
| โมเดล MultiLayerNetwork = MultiLayerNetwork ใหม่ (conf); // เริ่มต้นน้ำหนักโมเดล model.init(); log.info("ขั้นตอนที่ 2: เริ่มฝึกโมเดล"); //ตั้งค่าผู้ฟังทุกๆ 10 ครั้งและประเมินชุดทดสอบในทุกยุค model.setListeners(ใหม่ ScoreIterationListener(10), ใหม่ EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // ฝึกโมเดล model.fit(MNISTTrain, nEpochs); |
เมื่อการฝึกแบบจำลองเริ่มต้นขึ้น คุณจะมีเมทริกซ์ความสับสนของความถูกต้องของการจัดประเภท
ต่อไปนี้คือความแม่นยำของโมเดลหลังการฝึกสิบครั้ง:
| ========================================================================================= == 0 1 2 3 4 5 6 7 8 9 ————————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
สภาพแวดล้อมสำหรับการพัฒนาแอปพลิเคชัน KDD ที่สนับสนุนโดยโครงสร้างดัชนีหรือ ELKI คือชุดของอัลกอริธึมและโปรแกรมในตัวที่ใช้สำหรับการทำเหมืองข้อมูล เขียนด้วยภาษาจาวา เป็นไลบรารีโอเพ่นซอร์สที่ประกอบด้วยพารามิเตอร์ที่กำหนดค่าได้สูงในอัลกอริธึม นักวิทยาศาสตร์และนักศึกษาวิจัยมักใช้ข้อมูลนี้เพื่อรับข้อมูลเชิงลึกเกี่ยวกับชุดข้อมูล ตามชื่อที่แนะนำ มีสภาพแวดล้อมสำหรับการพัฒนาโปรแกรมและฐานข้อมูลการทำเหมืองข้อมูลที่ซับซ้อนโดยใช้โครงสร้างดัชนี
7. JSAT
Java Statistical Analysis Tool หรือ JSAT เป็นไลบรารี GPL3 ที่ใช้เฟรมเวิร์กเชิงวัตถุเพื่อช่วยให้ผู้ใช้นำการเรียนรู้ของเครื่องไปใช้กับ Java โดยทั่วไปจะใช้เพื่อการศึกษาด้วยตนเองโดยนักเรียนและนักพัฒนา เมื่อเทียบกับไลบรารีการใช้งาน AI อื่น ๆ JSAT มีอัลกอริธึม ML จำนวนมากที่สุดและเร็วที่สุดในบรรดาเฟรมเวิร์กทั้งหมด ด้วยการพึ่งพาภายนอกเป็นศูนย์ จึงมีความยืดหยุ่นสูงและมีประสิทธิภาพสูง และให้ประสิทธิภาพสูง
8. กรอบการเรียนรู้ของเครื่อง Encog
Encog เขียนด้วย Java และ C# และประกอบด้วยไลบรารีที่ช่วยปรับใช้อัลกอริธึมการเรียนรู้ของเครื่อง ใช้สำหรับสร้างอัลกอริธึมทางพันธุกรรม Bayesian Networks โมเดลทางสถิติ เช่น Hidden Markov Model และอื่นๆ
9. ตะลุมพุก
Machine Learning for Language Toolkit หรือ Mallet ใช้ใน Natural Language Processing (NLP) เช่นเดียวกับเฟรมเวิร์กการนำ ML ไปใช้งานอื่นๆ ส่วนใหญ่ Mallet ยังให้การสนับสนุนสำหรับการสร้างแบบจำลองข้อมูล การจัดกลุ่มข้อมูล การประมวลผลเอกสาร การจัดประเภทเอกสาร และอื่นๆ
10. Spark MLlib
Spark MLlib ถูกใช้โดยธุรกิจต่างๆ เพื่อเพิ่มประสิทธิภาพและความสามารถในการปรับขนาดของการจัดการเวิร์กโฟลว์ มันประมวลผลข้อมูลจำนวนมากและรองรับอัลกอริธึม ML ที่โหลดหนัก
ชำระเงิน: แนวคิดโครงการการเรียนรู้ของเครื่อง
บทสรุป
สิ่งนี้นำเราไปสู่จุดสิ้นสุดของบทความ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับแนวคิด Machine Learning โปรดติดต่อกับคณาจารย์ชั้นนำของ IIIT Bangalore และ Liverpool John Moores University ผ่านหลักสูตรวิทยาศาสตรมหาบัณฑิตสาขาวิชา Machine Learning & AI ของ upGrad
ทำไมเราจึงควรใช้ Java ร่วมกับ Machine Learning?
ผู้เชี่ยวชาญด้านแมชชีนเลิร์นนิงจะพบว่าง่ายต่อการเชื่อมต่อกับที่เก็บโค้ดปัจจุบัน หากพวกเขาเลือก Java เป็นภาษาการเขียนโปรแกรมสำหรับโครงการของตน เป็นภาษาที่ต้องการของ Machine Learning เนื่องจากคุณลักษณะต่างๆ เช่น การใช้งานง่าย บริการแพ็คเกจ การโต้ตอบกับผู้ใช้ที่ดีขึ้น การดีบักอย่างรวดเร็ว และภาพประกอบกราฟิกของข้อมูล Java ช่วยให้นักพัฒนา Machine Learning สามารถปรับขนาดระบบได้ง่าย ทำให้เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการสร้างแอปพลิเคชัน Machine Learning ขนาดใหญ่ที่มีความซับซ้อนตั้งแต่เริ่มต้น Java Virtual Machine (JVM) รองรับสภาพแวดล้อมการพัฒนาแบบบูรณาการ (IDE) จำนวนหนึ่ง ซึ่งช่วยให้แมชชีนเลิร์นนิงออกแบบเครื่องมือใหม่ได้อย่างรวดเร็ว
การเรียนรู้ Java ง่ายหรือไม่?
เนื่องจาก Java เป็นภาษาระดับสูง จึงง่ายต่อการเข้าใจ ในฐานะผู้เรียน คุณจะไม่ต้องลงรายละเอียดมากเท่ากับที่เป็นภาษาที่มีโครงสร้างดีและมุ่งเน้นวัตถุ ซึ่งง่ายพอสำหรับผู้เริ่มต้นเรียนรู้ เนื่องจากมีขั้นตอนมากมายที่ทำงานโดยอัตโนมัติ คุณจึงเชี่ยวชาญได้อย่างรวดเร็ว คุณไม่จำเป็นต้องลงรายละเอียดมากว่าสิ่งต่างๆ ทำงานอย่างไรในนั้น Java เป็นภาษาการเขียนโปรแกรมที่ไม่ขึ้นกับแพลตฟอร์ม ช่วยให้โปรแกรมเมอร์สร้างแอปพลิเคชันมือถือที่สามารถใช้บนอุปกรณ์ใดก็ได้ เป็นภาษาที่ต้องการของ Internet of Things รวมถึงเครื่องมือที่ดีที่สุดสำหรับการพัฒนาแอปพลิเคชันระดับองค์กร
ADAMS คืออะไร และมีประโยชน์อย่างไรในการเรียนรู้ของเครื่อง
Advanced Data Mining And Machine Learning System (ADAMS) เป็นกลไกจัดการเวิร์กโฟลว์ที่ได้รับอนุญาตจาก GPLv3 สำหรับการสร้างและจัดการเวิร์กโฟลว์เชิงโต้ตอบที่ขับเคลื่อนด้วยข้อมูลอย่างรวดเร็ว ซึ่งอาจรวมเข้ากับกระบวนการทางธุรกิจได้อย่างง่ายดาย เอ็นจิ้นเวิร์กโฟลว์ซึ่งเป็นไปตามหลักการของ Less is more เป็นหัวใจของ ADAMS ADAMS ใช้โครงสร้างแบบต้นไม้แทนการอนุญาตให้ผู้ใช้จัดเรียงตัวดำเนินการ (หรือนักแสดงในศัพท์แสง ADAMS) บนผืนผ้าใบ แล้วเชื่อมโยงอินพุตและเอาต์พุตด้วยตนเอง ไม่จำเป็นต้องมีการเชื่อมต่อที่ชัดเจน เนื่องจากโครงสร้างนี้และผู้ควบคุมจะกำหนดวิธีที่ข้อมูลไหลเข้าสู่กระบวนการ การแสดงวัตถุภายในและการซ้อนตัวดำเนินการย่อยภายในตัวจัดการตัวดำเนินการส่งผลให้มีโครงสร้างเหมือนต้นไม้ ADAMS มีชุดตัวแทนที่หลากหลายสำหรับการดึงข้อมูล การประมวลผล การขุด และการแสดงข้อมูล