
Decision Tree ใน Data Mining คืออะไร? ประเภท ตัวอย่างและการใช้งานจริง
เผยแพร่แล้ว: 2021-06-15สารบัญ
ข้อมูลเบื้องต้นเกี่ยวกับการทำเหมืองข้อมูล
ข้อมูลมักจะแสดงเป็นข้อมูลดิบซึ่งจำเป็นต้องได้รับการประมวลผลอย่างมีประสิทธิภาพเพื่อแปลงเป็นข้อมูลที่เป็นประโยชน์ การคาดคะเนผลลัพธ์มักขึ้นอยู่กับกระบวนการค้นหารูปแบบ ความผิดปกติ หรือความสัมพันธ์ภายในข้อมูล กระบวนการนี้เรียกว่า "การค้นพบความรู้ในฐานข้อมูล"
เฉพาะในทศวรรษ 1990 เมื่อมีการประกาศใช้คำว่า "การทำเหมืองข้อมูล" การทำเหมืองข้อมูลก่อตั้งขึ้นในสามสาขาวิชา ได้แก่ สถิติ ปัญญาประดิษฐ์ และการเรียนรู้ของเครื่อง การทำเหมืองข้อมูลอัตโนมัติได้เปลี่ยนกระบวนการวิเคราะห์จากวิธีที่ยุ่งยากมาเป็นแนวทางที่เร็วขึ้น การทำเหมืองข้อมูลทำให้ผู้ใช้สามารถ
- ลบข้อมูลที่มีเสียงดังและวุ่นวายทั้งหมด
- ทำความเข้าใจข้อมูลที่เกี่ยวข้องและใช้เพื่อคาดการณ์ข้อมูลที่เป็นประโยชน์
- กระบวนการคาดการณ์การตัดสินใจอย่างมีข้อมูลถูกเร่ง ขึ้น
การทำเหมืองข้อมูลอาจเรียกได้ว่าเป็นกระบวนการระบุรูปแบบข้อมูลที่ซ่อนอยู่ซึ่งต้องมีการจัดหมวดหมู่ จากนั้นข้อมูลเท่านั้นที่สามารถแปลงเป็นข้อมูลที่เป็นประโยชน์ได้ ข้อมูลที่เป็นประโยชน์สามารถป้อนเข้าในคลังข้อมูล อัลกอริธึมการทำเหมืองข้อมูล การวิเคราะห์ข้อมูลเพื่อการตัดสินใจ
โครงสร้างการตัดสินใจในการทำเหมืองข้อมูล
เทคนิคการทำเหมืองข้อมูลประเภทหนึ่ง โครงสร้างการตัดสินใจในการขุดข้อมูล สร้างแบบจำลองสำหรับการจำแนกประเภทของข้อมูล โมเดลถูกสร้างขึ้นในรูปแบบของโครงสร้างต้นไม้และด้วยเหตุนี้จึงอยู่ในรูปแบบการเรียนรู้ภายใต้การดูแล นอกเหนือจากแบบจำลองการจำแนกประเภทแล้ว ต้นไม้การตัดสินใจยังใช้ในการสร้างแบบจำลองการถดถอยเพื่อทำนายป้ายกำกับคลาสหรือค่าที่ช่วยในกระบวนการตัดสินใจ ทั้งข้อมูลที่เป็นตัวเลขและหมวดหมู่ เช่น เพศ อายุ ฯลฯ สามารถใช้โดยแผนภูมิการตัดสินใจ
โครงสร้างของแผนผังการตัดสินใจ
โครงสร้างของแผนผังการตัดสินใจประกอบด้วยโหนดราก กิ่ง และโหนดปลายสุด โหนดที่แตกแขนงเป็นผลของแผนผัง และโหนดภายในแสดงถึงการทดสอบในแอตทริบิวต์ โหนดปลายสุดแสดงถึงป้ายชื่อคลาส
การทำงานของแผนผังการตัดสินใจ
1. โครงสร้างการตัดสินใจทำงานภายใต้แนวทางการเรียนรู้แบบมีผู้ดูแลสำหรับตัวแปรที่รอบคอบและต่อเนื่อง ชุดข้อมูลแบ่งออกเป็นชุดย่อยตามแอตทริบิวต์ที่สำคัญที่สุดของชุดข้อมูล การระบุแอตทริบิวต์และการแยกทำได้ผ่านอัลกอริทึม
2. โครงสร้างของแผนผังการตัดสินใจประกอบด้วยโหนดรูท ซึ่งเป็นโหนดตัวทำนายที่มีนัยสำคัญ กระบวนการแยกเกิดขึ้นจากโหนดการตัดสินใจซึ่งเป็นโหนดย่อยของทรี โหนดที่ไม่แยกเพิ่มเติมจะเรียกว่าโหนดปลายหรือปลาย
3. ชุดข้อมูลแบ่งออกเป็นบริเวณที่เป็นเนื้อเดียวกันและไม่ทับซ้อนกันตามวิธีการจากบนลงล่าง ชั้นบนสุดให้ข้อสังเกตในที่เดียวซึ่งแยกออกเป็นกิ่งก้าน กระบวนการนี้เรียกว่า "Greedy Approach" เนื่องจากเน้นเฉพาะโหนดปัจจุบันมากกว่าโหนดในอนาคต
4. จนกว่าจะถึงเกณฑ์หยุด ต้นไม้การตัดสินใจจะทำงานต่อไป
5. ด้วยการสร้างแผนผังการตัดสินใจ จะมีการสร้างสัญญาณรบกวนและสิ่งผิดปกติจำนวนมาก ในการลบค่าผิดปกติเหล่านี้และข้อมูลที่มีเสียงดัง จะใช้วิธีการ "ตัดแต่งต้นไม้" ดังนั้นความแม่นยำของแบบจำลองจึงเพิ่มขึ้น
6. ตรวจสอบความถูกต้องของแบบจำลองในชุดการทดสอบที่ประกอบด้วยสิ่งอันดับทดสอบและฉลากของคลาส โมเดลที่แม่นยำถูกกำหนดโดยอิงตามเปอร์เซ็นต์ของชุดทูเพิลและคลาสของชุดการทดสอบการจัดหมวดหมู่ตามโมเดล
ภาพที่ 1 : ตัวอย่างต้นไม้ที่ไม่ได้ตัดแต่งกิ่งและตัดแต่งกิ่ง
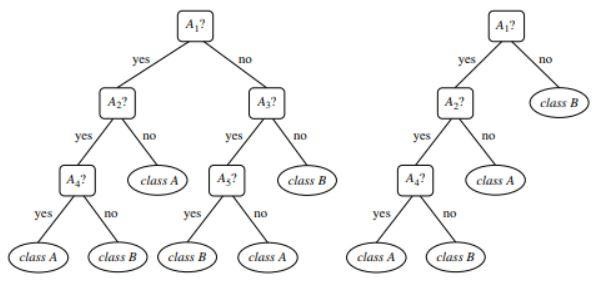
แหล่งที่มา
ประเภทของโครงสร้างการตัดสินใจ
ต้นไม้แห่งการตัดสินใจนำไปสู่การพัฒนาแบบจำลองสำหรับการจำแนกประเภทและการถดถอยตามโครงสร้างแบบต้นไม้ ข้อมูลถูกแบ่งออกเป็นส่วนย่อยที่เล็กกว่า ผลลัพธ์ของแผนผังการตัดสินใจคือทรีที่มีโหนดการตัดสินใจและโหนดปลายสุด แผนผังการตัดสินใจสองประเภทมีคำอธิบายด้านล่าง:
1. การจำแนกประเภท
การจัดประเภทรวมถึงการสร้างแบบจำลองที่อธิบายป้ายชื่อชั้นที่สำคัญ สิ่งเหล่านี้ถูกนำไปใช้ในด้านการเรียนรู้ของเครื่องและการจดจำรูปแบบ แผนผังการตัดสินใจในแมชชีนเลิ ร์นนิง ผ่านแบบจำลองการจัดหมวดหมู่นำไปสู่การตรวจหาการฉ้อโกง การวินิจฉัยทางการแพทย์ ฯลฯ กระบวนการสองขั้นตอนของแบบจำลองการจัดหมวดหมู่ประกอบด้วย:
- การเรียนรู้: มีการสร้างแบบจำลองการจัดหมวดหมู่ตามข้อมูลการฝึกอบรม
- การจัดประเภท: มีการตรวจสอบความถูกต้องของแบบจำลองแล้วใช้สำหรับการจัดหมวดหมู่ข้อมูลใหม่ ป้ายกำกับคลาสจะอยู่ในรูปแบบของค่าที่ไม่ต่อเนื่อง เช่น "ใช่" หรือ "ไม่ใช่" เป็นต้น
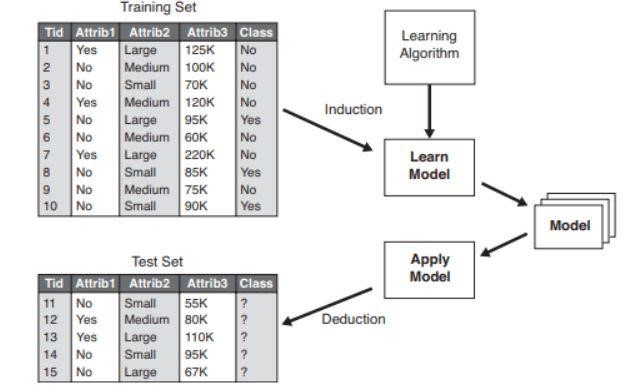
รูปที่ 2 : ตัวอย่างแบบจำลองการจัด ประเภท
แหล่งที่มา
2. การถดถอย
ตัวแบบการถดถอยจะใช้สำหรับการวิเคราะห์การถดถอยของข้อมูล เช่น การทำนายคุณลักษณะเชิงตัวเลข สิ่งเหล่านี้เรียกว่าค่าต่อเนื่อง ดังนั้น แทนที่จะทำนายป้ายกำกับคลาส ตัวแบบการถดถอยจะทำนายค่าที่ต่อเนื่องกัน
รายการอัลกอริทึมที่ใช้
อัลกอริธึมแผนผังการตัดสินใจที่เรียกว่า “ID3” ได้รับการพัฒนาในปี 1980 โดยนักวิจัยเครื่องจักรชื่อ J. Ross Quinlan อัลกอริทึมนี้ประสบความสำเร็จโดยอัลกอริทึมอื่นๆ เช่น C4.5 ที่พัฒนาโดยเขา อัลกอริธึมทั้งสองใช้วิธีโลภ อัลกอริธึม C4.5 ไม่ใช้การย้อนรอย และต้นไม้ถูกสร้างขึ้นในลักษณะการแบ่งและพิชิตแบบเรียกซ้ำจากบนลงล่าง อัลกอริธึมใช้ชุดข้อมูลการฝึกอบรมที่มีป้ายกำกับคลาส ซึ่งแบ่งออกเป็นชุดย่อยที่เล็กกว่าเมื่อสร้างแผนผัง
- พารามิเตอร์สามตัวถูกเลือกในตอนแรก - รายการแอตทริบิวต์ วิธีการเลือกแอตทริบิวต์ และพาร์ติชันข้อมูล คุณสมบัติของชุดการฝึกมีอธิบายไว้ในรายการแอตทริบิวต์
- วิธีการเลือกการระบุแหล่งที่มารวมถึงวิธีการเลือกแอตทริบิวต์ที่ดีที่สุดสำหรับการเลือกปฏิบัติระหว่างทูเพิล
- โครงสร้างแบบต้นไม้ขึ้นอยู่กับวิธีการเลือกแอตทริบิวต์
- การสร้างต้นไม้เริ่มต้นด้วยโหนดเดียว
- การแยกทูเปิลเกิดขึ้นเมื่อเลเบลคลาสต่างกันแสดงในทูเพิล ซึ่งจะนำไปสู่การสร้างกิ่งก้านของต้นไม้
- วิธีการแยกเป็นตัวกำหนดว่าควรเลือกแอตทริบิวต์ใดสำหรับพาร์ติชันข้อมูล ตามวิธีนี้ กิ่งก้านจะเติบโตจากโหนดตามผลการทดสอบ
- วิธีการแยกและการแบ่งพาร์ติชั่นจะดำเนินการแบบเรียกซ้ำ ในท้ายที่สุด ส่งผลให้เกิดแผนผังการตัดสินใจสำหรับ tuples ชุดข้อมูลการฝึกอบรม
- กระบวนการสร้างต้นไม้ยังคงดำเนินต่อไป จนกว่าทูเพิลที่หลงเหลืออยู่จะไม่สามารถแบ่งแยกออกไปได้อีก
- ความซับซ้อนของอัลกอริทึมแสดงโดย
n * |D| * บันทึก |D|
โดยที่ n คือจำนวนแอตทริบิวต์ในชุดข้อมูลการฝึกอบรม D และ |D| คือจำนวนของสิ่งอันดับ
แหล่งที่มา
รูปที่ 3: การแยกค่าที่ไม่ต่อเนื่อง
รายการอัลกอริทึมที่ใช้ในแผนผังการตัดสินใจ ได้แก่
ID3
ชุดข้อมูล S ทั้งหมดถือเป็นโหนดรูทขณะสร้างแผนผังการตัดสินใจ จากนั้นทำซ้ำกับทุกแอตทริบิวต์และแยกข้อมูลออกเป็นส่วนย่อย อัลกอริธึมจะตรวจสอบและนำแอตทริบิวต์เหล่านั้นซึ่งไม่ได้นำมาใช้ก่อนแอตทริบิวต์ที่ทำซ้ำ การแยกข้อมูลในอัลกอริธึม ID3 นั้นใช้เวลานานและไม่ใช่อัลกอริธึมในอุดมคติเพราะมันจะเกินข้อมูล
C4.5
เป็นรูปแบบขั้นสูงของอัลกอริธึมเนื่องจากข้อมูลถูกจัดประเภทเป็นตัวอย่าง ทั้งค่าต่อเนื่องและค่าที่ไม่ต่อเนื่องสามารถจัดการได้อย่างมีประสิทธิภาพไม่เหมือนกับ ID3 มีวิธีการตัดแต่งกิ่งเพื่อเอากิ่งที่ไม่ต้องการออก
รถเข็น
ทั้งงานการจำแนกและการถดถอยสามารถทำได้โดยอัลกอริทึม ต่างจาก ID3 และ C4.5 จุดตัดสินใจถูกสร้างขึ้นโดยพิจารณาจากดัชนี Gini ใช้อัลกอริธึมที่โลภสำหรับวิธีการแยกที่มีเป้าหมายเพื่อลดฟังก์ชันต้นทุน ในงานจำแนกประเภท ดัชนี Gini ถูกใช้เป็นฟังก์ชันต้นทุนเพื่อระบุความบริสุทธิ์ของโหนดปลายสุด ในงานถดถอย ข้อผิดพลาดผลรวมกำลังสองถูกใช้เป็นฟังก์ชันต้นทุนเพื่อค้นหาการคาดการณ์ที่ดีที่สุด
CHAID
ตามชื่อที่แนะนำ มันย่อมาจาก Chi-square Automatic Interaction Detector ซึ่งเป็นกระบวนการที่เกี่ยวข้องกับตัวแปรทุกประเภท อาจเป็นตัวแปรระบุ ลำดับ หรือตัวแปรต่อเนื่อง ต้นไม้การถดถอยใช้การทดสอบ F ในขณะที่การทดสอบ Chi-square ใช้ในแบบจำลองการจำแนกประเภท
MARS
มันย่อมาจากเส้นโค้งการถดถอยแบบปรับได้หลายตัวแปร อัลกอริธึมถูกนำมาใช้เป็นพิเศษในงานถดถอย โดยที่ข้อมูลส่วนใหญ่ไม่เป็นเชิงเส้น

การแยกไบนารีแบบเรียกซ้ำโลภ
วิธีการแยกไบนารีเกิดขึ้นทำให้เกิดสองสาขา การแยกสิ่งอันดับจะดำเนินการด้วยการคำนวณฟังก์ชันต้นทุนแยก มีการเลือกการแบ่งต้นทุนต่ำสุด และดำเนินการกระบวนการแบบวนซ้ำเพื่อคำนวณฟังก์ชันต้นทุนของทูเพิลอื่นๆ
ต้นไม้แห่งการตัดสินใจพร้อมตัวอย่างในโลกแห่งความเป็นจริง
คาดการณ์กระบวนการมีสิทธิ์ได้รับเงินกู้จากข้อมูลที่กำหนด
ขั้นที่ 1: กำลังโหลดข้อมูล
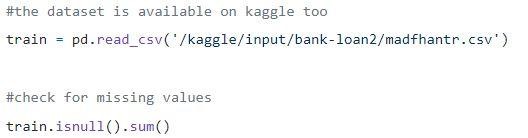
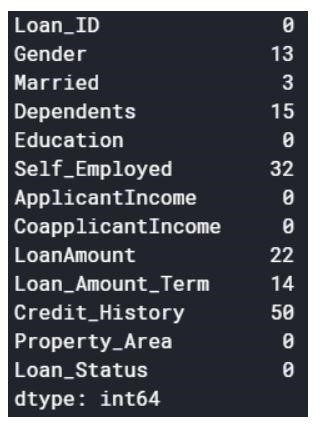
ค่า Null สามารถลบออกหรือเติมด้วยค่าบางค่าได้ รูปร่างของชุดข้อมูลเดิมคือ (614,13) และชุดข้อมูลใหม่หลังจากปล่อยค่า Null คือ (480,13)
ขั้นที่ 2: ดูชุดข้อมูล

ขั้นที่ 3: แบ่งข้อมูลออกเป็นชุดฝึกและทดสอบ
ขั้นตอนที่ 4: สร้างแบบจำลองและติดตั้งชุดรถไฟ

ก่อนการแสดงภาพจะต้องมีการคำนวณบางอย่าง
การคำนวณที่ 1: คำนวณเอนโทรปีของชุดข้อมูลทั้งหมด

การคำนวณที่ 2: ค้นหาเอนโทรปีและรับทุกคอลัมน์
- คอลัมน์เพศ
- เงื่อนไขที่ 1: ชุดข้อมูลที่มีเพศชายทั้งหมดอยู่ในนั้นแล้ว
p = 278, n=116 , p+n=489
เอนโทรปี(G=ชาย) = 0.87
- เงื่อนไข 2: ชุดข้อมูลที่มีผู้หญิงทั้งหมดอยู่ในนั้นแล้ว
p = 54 , n = 32 , p+n = 86
เอนโทรปี(G=เพศหญิง) = 0.95
- ข้อมูลเฉลี่ยในคอลัมน์เพศ

- คอลัมน์แต่งงาน
- เงื่อนไข 1: แต่งงานแล้ว = ใช่(1)
ในส่วนนี้แยกชุดข้อมูลทั้งหมดที่มีสถานะแต่งงานแล้วใช่
p = 227 , n = 84 , p+n = 311
E(แต่งงานแล้ว = ใช่) = 0.84
- เงื่อนไข 2: แต่งงานแล้ว = ไม่(0)
ในนี้แยกชุดข้อมูลทั้งหมดที่มีสถานะสมรส no
p = 105 , n = 64 , p+n = 169
E(แต่งงานแล้ว = ไม่) = 0.957
- ข้อมูลเฉลี่ยในคอลัมน์ที่แต่งงานแล้วคือ
- คอลัมน์การศึกษา
- เงื่อนไข 1: การศึกษา = บัณฑิต(1)
p = 271 , n = 112 , p+n = 383
E(การศึกษา = บัณฑิต) = 0.87
- เงื่อนไข 2: การศึกษา = ไม่จบการศึกษา(0)
p = 61 , n = 36 , p+n = 97
E(การศึกษา = ไม่จบการศึกษา) = 0.95
- คอลัมน์ข้อมูลการศึกษาเฉลี่ย= 0.886
กำไร = 0.01
4) คอลัมน์ประกอบอาชีพอิสระ
- เงื่อนไขที่ 1: การประกอบอาชีพอิสระ = ใช่(1)
p = 43 , n = 23 , p+n = 66
E(ประกอบอาชีพอิสระ=ใช่) = 0.93
- เงื่อนไข 2: การประกอบอาชีพอิสระ = ไม่(0)
p = 289 , n = 125 , p+n = 414
E(ประกอบอาชีพอิสระ=ไม่) = 0.88
- ข้อมูลเฉลี่ยในการประกอบอาชีพอิสระในคอลัมน์การศึกษา = 0.886
กำไร = 0.01
- คอลัมน์คะแนนเครดิต: คอลัมน์มีค่า 0 และ 1
- เงื่อนไข 1: คะแนนเครดิต = 1
p = 325 , n = 85 , p+n = 410
E(คะแนนเครดิต = 1) = 0.73
- เงื่อนไข 2: คะแนนเครดิต = 0
p = 63 , n = 7 , p+n = 70
E(คะแนนเครดิต = 0) = 0.46
- ข้อมูลเฉลี่ยในคอลัมน์คะแนนเครดิต = 0.69
กำไร = 0.2
เปรียบเทียบค่าที่ได้รับทั้งหมด

คะแนนเครดิตมีกำไรสูงสุด ดังนั้นมันจะถูกใช้เป็นโหนดรูท
ขั้นตอนที่ 5: เห็นภาพแผนผังการตัดสินใจ

รูปที่ 5: โครงสร้างการตัดสินใจพร้อมเกณฑ์ Gini
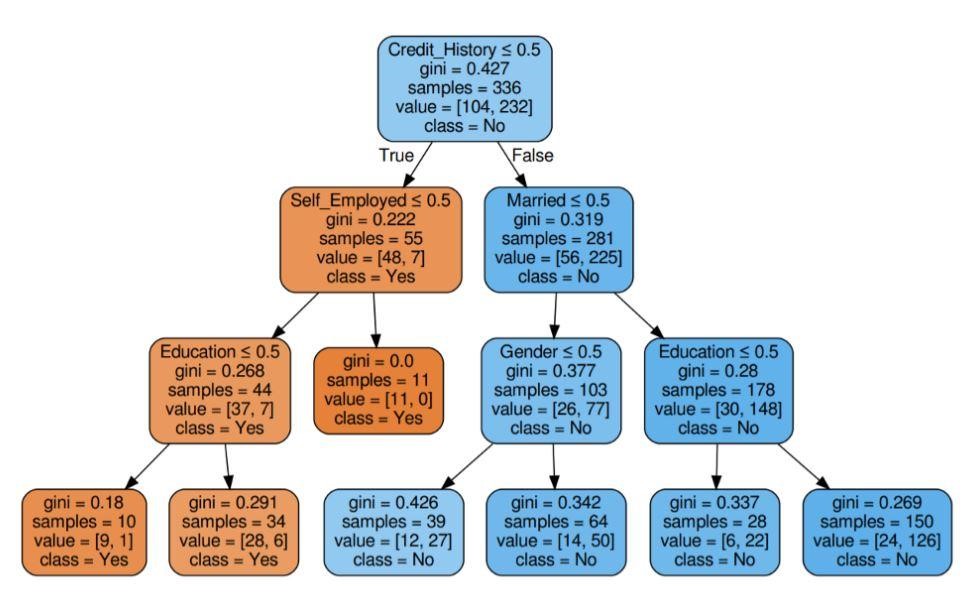 แหล่งที่มา
แหล่งที่มา
รูปที่ 6: ต้นไม้ตัดสินใจพร้อมเอนโทรปีเกณฑ์
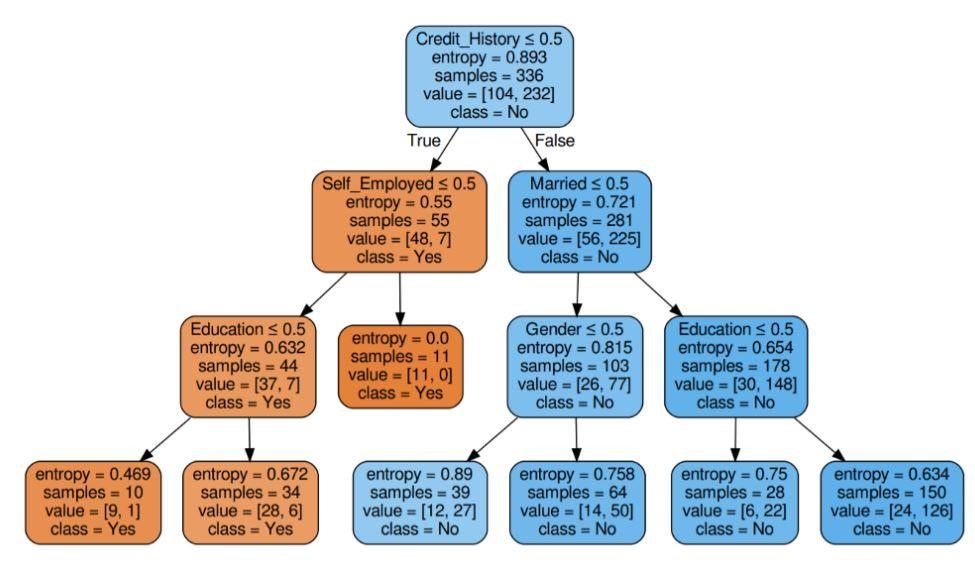
แหล่งที่มา
ขั้นตอนที่ 6: ตรวจสอบคะแนนของนางแบบ
ได้คะแนนความแม่นยำเกือบ 80%
รายการแอปพลิเคชัน
แผนภูมิการตัดสินใจส่วนใหญ่จะใช้โดยผู้เชี่ยวชาญด้านข้อมูลเพื่อทำการตรวจสอบเชิงวิเคราะห์ อาจถูกนำไปใช้อย่างกว้างขวางเพื่อวัตถุประสงค์ทางธุรกิจเพื่อวิเคราะห์หรือคาดการณ์ปัญหา ความยืดหยุ่นของโครงสร้างการตัดสินใจทำให้สามารถใช้ในพื้นที่ต่างๆ ได้:
1. การดูแลสุขภาพ
แผนผังการตัดสินใจช่วยให้สามารถคาดการณ์ได้ว่าผู้ป่วยเป็นโรคใดโรคหนึ่งที่มีเงื่อนไขอายุ น้ำหนัก เพศ ฯลฯ หรือไม่ การคาดคะเนอื่นๆ ได้แก่ การตัดสินใจผลของยาโดยพิจารณาจากปัจจัยต่างๆ เช่น องค์ประกอบ ระยะเวลาในการผลิต เป็นต้น
2. ภาคการธนาคาร
โครงสร้างการตัดสินใจช่วยในการทำนายว่าบุคคลมีสิทธิ์ได้รับเงินกู้หรือไม่ โดยพิจารณาจากสถานะทางการเงิน เงินเดือน สมาชิกในครอบครัว ฯลฯ นอกจากนี้ยังสามารถระบุการฉ้อโกงบัตรเครดิต การผิดนัดชำระหนี้ เป็นต้น
3. ภาคการศึกษา
การคัดเลือกนักเรียนโดยพิจารณาจากคะแนนการทำบุญ การเข้าร่วม ฯลฯ สามารถตัดสินใจได้โดยใช้แผนภูมิการตัดสินใจ
รายการข้อดี
- ผลลัพธ์ที่ตีความได้ของรูปแบบการตัดสินใจสามารถนำเสนอต่อผู้บริหารระดับสูงและผู้มีส่วนได้ส่วนเสีย
- ขณะสร้างแบบจำลองแผนผังการตัดสินใจ ไม่จำเป็นต้องมีการประมวลผลข้อมูลล่วงหน้า เช่น การทำให้เป็นมาตรฐาน การปรับขนาด ฯลฯ
- ข้อมูลทั้งสองประเภท - ตัวเลขและหมวดหมู่สามารถจัดการได้โดยแผนผังการตัดสินใจซึ่งแสดงประสิทธิภาพการใช้งานที่สูงกว่าอัลกอริธึมอื่น ๆ
- ค่าที่หายไปในข้อมูลจะไม่ส่งผลต่อกระบวนการของโครงสร้างการตัดสินใจ จึงทำให้เป็นอัลกอริธึมที่ยืดหยุ่นได้
อะไรต่อไป?
หากคุณสนใจที่จะหาประสบการณ์ตรงในการทำเหมืองข้อมูลและรับการฝึกอบรมจากผู้เชี่ยวชาญ คุณสามารถดูโปรแกรม Executive PG ของ upGrad ในสาขา Data Science ได้ หลักสูตรนี้จัดทำขึ้นสำหรับกลุ่มอายุใด ๆ ที่มีอายุระหว่าง 21-45 ปี โดยมีเกณฑ์คุณสมบัติขั้นต่ำ 50% หรือคะแนนผ่านเทียบเท่าในการสำเร็จการศึกษา ผู้เชี่ยวชาญด้านการทำงานทุกคนสามารถเข้าร่วมโปรแกรม PG สำหรับผู้บริหารที่ได้รับการรับรองจาก IIIT Bangalore
Decision Trees ใน Data mining มีความสามารถในการจัดการข้อมูลที่ซับซ้อนมาก ต้นไม้การตัดสินใจทั้งหมดมีสามโหนดหรือส่วนที่สำคัญ มาพูดคุยกันด้านล่าง ตอนนี้เราเข้าใจการทำงานของ Decision tree แล้ว เรามาลองดูข้อดีบางประการของการใช้ Decision tree ในการทำ Data Miningโครงสร้างการตัดสินใจในการทำเหมืองข้อมูลคืออะไร?
โครงสร้างการตัดสินใจเป็นวิธีสร้างแบบจำลองในการขุดข้อมูล สามารถเข้าใจได้ว่าเป็นต้นไม้ไบนารีกลับด้าน ประกอบด้วยโหนดรูท บางสาขา และโหนดปลายสุด
โหนดภายในแต่ละโหนดในแผนผังการตัดสินใจหมายถึงการศึกษาแอตทริบิวต์ แผนกแต่ละแผนกหมายถึงผลที่ตามมาของการศึกษาหรือการสอบนั้น ๆ และสุดท้ายโหนดปลายแต่ละอันแสดงถึงแท็กของคลาส
วัตถุประสงค์หลักของการสร้างโครงสร้างการตัดสินใจคือการสร้างอุดมคติที่สามารถใช้เพื่อคาดการณ์ชั้นเฉพาะโดยใช้ขั้นตอนการตัดสินใจเกี่ยวกับข้อมูลก่อนหน้า
เราเริ่มต้นด้วยโหนดรูท สร้างความสัมพันธ์บางอย่างกับตัวแปรรูท และสร้างส่วนต่างๆ ที่ยอมรับค่าเหล่านั้น ตามตัวเลือกพื้นฐาน เราข้ามไปยังโหนดที่ตามมา โหนดสำคัญใดบ้างที่ใช้ในแผนผังการตัดสินใจ
เมื่อเราเชื่อมต่อโหนดเหล่านี้ทั้งหมด เราจะได้รับการแบ่งส่วน เราสามารถสร้างต้นไม้ที่มีความยากได้หลากหลายโดยใช้โหนดและส่วนเหล่านี้ในจำนวนครั้งไม่สิ้นสุด ข้อดีของการใช้ Decision Trees คืออะไร?
1. เมื่อเราเปรียบเทียบกับวิธีอื่น โครงสร้างการตัดสินใจไม่ต้องการการคำนวณมากสำหรับการฝึกข้อมูลระหว่างการประมวลผลล่วงหน้า
2. การรักษาเสถียรภาพของข้อมูลไม่เกี่ยวข้องกับแผนผังการตัดสินใจ
3. นอกจากนี้ พวกเขายังไม่ต้องการการปรับขนาดข้อมูลด้วยซ้ำ
4. แม้ว่าค่าบางค่าจะถูกละไว้ในชุดข้อมูล แต่ก็ไม่รบกวนการสร้างต้นไม้
5. โมเดลเหล่านี้มีสัญชาตญาณเหมือนกัน คำอธิบายเหล่านี้ปราศจากความเครียดเช่นกัน