
การสร้างทักษะเสียงสำหรับ Google Assistant และ Amazon Alexa
เผยแพร่แล้ว: 2022-03-10ในช่วงทศวรรษที่ผ่านมา มีการเปลี่ยนแปลงคลื่นไหวสะเทือนไปสู่ส่วนต่อประสานการสนทนา เมื่อผู้คนเข้าถึง 'หน้าจอสูงสุด' และเริ่มลดขนาดการใช้อุปกรณ์ของพวกเขากลับคืนมา ด้วยฟีเจอร์ไลฟ์สไตล์ดิจิทัลที่รวมเข้ากับระบบปฏิบัติการส่วนใหญ่
เพื่อต่อสู้กับความล้าของหน้าจอ ผู้ช่วยเสียงได้เข้าสู่ตลาดเพื่อเป็นตัวเลือกที่ต้องการสำหรับการดึงข้อมูลอย่างรวดเร็ว สถิติที่กล่าวกันบ่อยๆ ระบุว่า 50% ของการค้นหาจะดำเนินการด้วยเสียงในปี 2020 นอกจากนี้ เมื่อมีการนำไปใช้เพิ่มขึ้น ก็ขึ้นอยู่กับนักพัฒนาที่จะเพิ่ม “Conversational Interfaces” และ “Voice Assistants” ลงในแถบเครื่องมือ
การออกแบบสิ่งที่มองไม่เห็น
สำหรับหลายๆ คน การเริ่มต้นใช้งานโปรเจ็กต์ Voice UI (VUI) อาจเหมือนกับการเข้าสู่ Unknown เรียนรู้เพิ่มเติมเกี่ยวกับบทเรียนที่เรียนรู้โดย William Merrill เมื่อออกแบบเสียง อ่านบทความที่เกี่ยวข้อง →
อินเทอร์เฟซการสนทนาคืออะไร?
Conversational Interface (บางครั้งสั้นลงเหลือ CUI คืออินเทอร์เฟซใดๆ ในภาษามนุษย์ ซึ่งได้รับการแนะนำให้เป็นอินเทอร์เฟซที่เป็นธรรมชาติสำหรับประชาชนทั่วไปมากกว่า Graphic User Interface GUI ซึ่งนักพัฒนาส่วนหน้าคุ้นเคยกับการสร้าง GUI ต้องใช้มนุษย์ เพื่อเรียนรู้ไวยากรณ์เฉพาะของอินเทอร์เฟซ (ปุ่มคิด ตัวเลื่อน และดรอปดาวน์)
ความแตกต่างที่สำคัญในการใช้ภาษามนุษย์ทำให้ CUI เป็นธรรมชาติมากขึ้นสำหรับผู้คน มันต้องใช้ความรู้เพียงเล็กน้อยและทำให้เกิดภาระในการทำความเข้าใจกับอุปกรณ์
CUI ทั่วไปมาในสองรูปแบบ: Chatbots และ Voice Assistants ทั้งสองได้เห็นการเพิ่มขึ้นอย่างมากในทศวรรษที่ผ่านมาด้วยความก้าวหน้าในการประมวลผลภาษาธรรมชาติ (NLP)
ทำความเข้าใจศัพท์แสง

| คำสำคัญ | ความหมาย |
|---|---|
| ทักษะ/การกระทำ | แอปพลิเคชั่นเสียงที่สามารถตอบสนองชุดของความตั้งใจ |
| ความตั้งใจ | การกระทำที่ตั้งใจไว้เพื่อให้ทักษะบรรลุผล สิ่งที่ผู้ใช้ต้องการให้ทักษะทำเพื่อตอบสนองต่อสิ่งที่พวกเขาพูด |
| คำพูด | ประโยคที่ผู้ใช้พูดหรือพูด |
| ปลุกคำ | คำหรือวลีที่ใช้เริ่มการฟังของผู้ช่วยเสียง เช่น 'Hey google', 'Alexa' หรือ 'Hey Siri' |
| บริบท | ข้อมูลเชิงบริบทภายในคำพูด ที่ช่วยให้ทักษะบรรลุความตั้งใจ เช่น 'วันนี้', 'ตอนนี้', 'เมื่อฉันกลับถึงบ้าน' |
ผู้ช่วยเสียงคืออะไร?
ผู้ช่วยเสียงเป็นซอฟต์แวร์ที่มีความสามารถ NLP (การประมวลผลภาษาธรรมชาติ) รับคำสั่งเสียงและส่งคืนคำตอบในรูปแบบเสียง ในช่วงไม่กี่ปีมานี้ ขอบเขตของวิธีที่คุณสามารถมีส่วนร่วมกับผู้ช่วยกำลังขยายและพัฒนา แต่หัวใจสำคัญของเทคโนโลยีคือการใช้ภาษาธรรมชาติ การคำนวณจำนวนมาก ภาษาธรรมชาติ
สำหรับผู้ที่มองหารายละเอียดเพิ่มเติมเล็กน้อย:
- ซอฟต์แวร์ได้รับคำขอเสียงจากผู้ใช้ ประมวลผลเสียงเป็นหน่วยเสียง ซึ่งเป็นหน่วยการสร้างของภาษา
- ด้วยความมหัศจรรย์ของ AI (เฉพาะคำพูดเป็นข้อความ) หน่วยเสียงเหล่านี้จะถูกแปลงเป็นสตริงของคำขอโดยประมาณ ซึ่งจะถูกเก็บไว้ในไฟล์ JSON ซึ่งมีข้อมูลเพิ่มเติมเกี่ยวกับผู้ใช้ คำขอ และเซสชันด้วย
- จากนั้น JSON จะได้รับการประมวลผล (โดยปกติในระบบคลาวด์) เพื่อกำหนดบริบทและเจตนาของคำขอ
- ตามเจตนา การตอบกลับจะถูกส่งกลับอีกครั้งภายในการตอบสนอง JSON ที่ใหญ่ขึ้น ไม่ว่าจะเป็นสตริงหรือเป็น SSML (เพิ่มเติมในภายหลัง)
- การตอบสนองจะได้รับการประมวลผลกลับโดยใช้ AI (โดยธรรมชาติแล้วกลับกัน - Text-to-Speech) ซึ่งจะถูกส่งคืนไปยังผู้ใช้
มีอะไรหลายอย่างเกิดขึ้นที่นั่น ซึ่งส่วนใหญ่ไม่ต้องคิดมาก แต่แต่ละแพลตฟอร์มทำสิ่งนี้แตกต่างกัน และมันเป็นความแตกต่างของแพลตฟอร์มที่ต้องการความเข้าใจมากขึ้นอีกเล็กน้อย

อุปกรณ์สั่งงานด้วยเสียง
ข้อกำหนดสำหรับอุปกรณ์เพื่อให้สามารถมีผู้ช่วยเสียงในตัวนั้นค่อนข้างต่ำ ต้องใช้ไมโครโฟน การเชื่อมต่ออินเทอร์เน็ต และลำโพง ลำโพงอัจฉริยะ เช่น Nest Mini & Echo Dot ให้การควบคุมด้วยเสียงแบบ low-fi
ลำดับถัดมาคือเสียง + หน้าจอ ซึ่งเรียกว่าอุปกรณ์ 'หลายรูปแบบ' (เพิ่มเติมในภายหลัง) และเป็นอุปกรณ์เช่น Nest Hub และ Echo Show เนื่องจากสมาร์ทโฟนมีฟังก์ชันนี้ จึงถือได้ว่าเป็นอุปกรณ์ที่เปิดใช้งานเสียงแบบต่อเนื่องหลายรูปแบบ
ทักษะการใช้เสียง
ก่อนอื่น ทุกแพลตฟอร์มมีชื่อที่แตกต่างกันสำหรับ 'ทักษะด้านเสียง' ของพวกเขา Amazon มาพร้อมกับทักษะต่างๆ ซึ่งฉันจะยึดถือตามคำศัพท์ที่เข้าใจกันโดยทั่วไป Google เลือกใช้ 'Actions' และ Samsung เลือกใช้ 'capsule'
แต่ละแพลตฟอร์มมีทักษะเฉพาะตัว เช่น การถามเวลา สภาพอากาศ และเกมกีฬา ทักษะที่สร้างโดยนักพัฒนา (บุคคลที่สาม) สามารถเรียกใช้ด้วยวลีเฉพาะ หรือหากแพลตฟอร์มชอบก็สามารถเรียกใช้โดยปริยายได้โดยไม่ต้องใช้วลีสำคัญ
การ ร้องขออย่างชัดแจ้ง : ”Ok Google คุยกับ <ชื่อแอป>”
มีการระบุไว้อย่างชัดเจนว่าต้องการทักษะใด:
การ วิงวอนโดยปริยาย : "Ok Google วันนี้อากาศเป็นอย่างไร"
มันบอกเป็นนัยโดยบริบทของคำขอว่าบริการใดที่ผู้ใช้ต้องการ
มีผู้ช่วยเสียงอะไรบ้าง?
ในตลาดตะวันตก ผู้ช่วยเสียงเป็นม้าสามตัวเป็นอย่างมาก Apple, Google และ Amazon มีแนวทางที่แตกต่างกันมากสำหรับผู้ช่วยของพวกเขา และด้วยเหตุนี้จึงดึงดูดนักพัฒนาและลูกค้าประเภทต่างๆ
สิริของ Apple
ชื่ออุปกรณ์ : ”Siri”
วลีปลุก : “หวัดดี สิริ”
Siri มีผู้ใช้งานมากกว่า 375 ล้านคน แต่เพื่อความกระชับ ฉันจะไม่ลงรายละเอียดมากเกินไปสำหรับ Siri แม้ว่าแอปนี้อาจเป็นที่ยอมรับกันทั่วโลกและนำไปปรับใช้กับอุปกรณ์ Apple ส่วนใหญ่ แต่นักพัฒนาก็ต้องมีแอปอยู่แล้วบนหนึ่งในแพลตฟอร์มของ Apple และต้องเขียนอย่างรวดเร็ว (ในขณะที่แอปอื่นๆ สามารถเขียนด้วย Javascript ที่ทุกคนชื่นชอบได้) ยกเว้นกรณีที่คุณเป็นนักพัฒนาแอพที่ต้องการขยายข้อเสนอของแอพ คุณสามารถข้าม apple ที่ผ่านไปแล้วได้จนกว่าพวกเขาจะเปิดแพลตฟอร์มของพวกเขา
Google Assistant
ชื่ออุปกรณ์ : ”Google Home, Nest”
วลีปลุก : ”Ok Google”
Google มีอุปกรณ์ส่วนใหญ่ในสามกลุ่มใหญ่ โดยมีมากกว่า 1 พันล้านเครื่องทั่วโลก ซึ่งส่วนใหญ่เป็นเพราะอุปกรณ์ Android จำนวนมากที่มี Google Assistant ในตัว ในแง่ของลำโพงอัจฉริยะเฉพาะของพวกเขา ตัวเลขนั้นเล็กกว่าเล็กน้อย ภารกิจโดยรวมของ Google กับผู้ช่วยคือการสร้างความพอใจให้กับผู้ใช้ และพวกเขาก็ทำได้ดีมากในการจัดหาอินเทอร์เฟซที่ใช้งานง่ายและเบา
เป้าหมายหลักของพวกเขาบนแพลตฟอร์มคือการใช้เวลา — ด้วยแนวคิดที่จะกลายมาเป็นส่วนสำคัญของกิจวัตรประจำวันของลูกค้า ดังนั้นพวกเขาจึงเน้นที่ประโยชน์ใช้สอย ความสนุกสนานในครอบครัว และประสบการณ์ที่น่ารื่นรมย์เป็นหลัก
ทักษะที่สร้างขึ้นสำหรับ Google นั้นดีที่สุดเมื่อเป็นงานและเกม โดยเน้นที่ความสนุกสนานที่เหมาะสำหรับครอบครัวเป็นหลัก การเพิ่มผ้าใบสำหรับเกมล่าสุดของพวกเขาเป็นข้อพิสูจน์ถึงแนวทางนี้ แพลตฟอร์มของ Google เข้มงวดกว่ามากในการส่งทักษะ และด้วยเหตุนี้ ไดเร็กทอรีจึงเล็กกว่ามาก
Amazon Alexa
ชื่ออุปกรณ์ : “Amazon Fire, Amazon Echo”
วลีปลุก : “อเล็กซ่า”
ในปี 2019 อเมซอนมีอุปกรณ์เกิน 100 ล้านเครื่อง โดยส่วนใหญ่มาจากการขายลำโพงอัจฉริยะและจอแสดงผลอัจฉริยะ รวมถึงอุปกรณ์ 'ไฟ' หรือแท็บเล็ตและอุปกรณ์สตรีมมิ่ง
ทักษะที่สร้างขึ้นสำหรับ Amazon มักจะมุ่งเป้าไปที่การซื้อทักษะ หากคุณกำลังมองหาแพลตฟอร์มเพื่อขยายอีคอมเมิร์ซ/บริการของคุณ หรือเสนอการสมัครสมาชิก Amazon นั้นเหมาะสำหรับคุณ ดังที่กล่าวไว้ ISP ไม่ใช่ข้อกำหนดสำหรับ Alexa Skills พวกเขารองรับการใช้งานทุกประเภทและเปิดรับการส่งมากขึ้น
คนอื่น ๆ
ยังมีผู้ช่วยด้านเสียงอีกมากมาย เช่น Bixby ของ Samsung, Cortana ของ Microsoft และ Mycroft ผู้ช่วยเสียงโอเพนซอร์สยอดนิยม ทั้งสามมีการติดตามที่สมเหตุสมผล แต่ก็ยังอยู่ในส่วนน้อยเมื่อเทียบกับโกลิอัททั้งสามของ Amazon, Google และ Apple
สร้างบน Amazon Alexa
ระบบนิเวศสำหรับเสียงของ Amazons ได้พัฒนาขึ้นเพื่อให้นักพัฒนาสามารถสร้างทักษะทั้งหมดของตนภายในคอนโซลของ Alexa ได้ ดังนั้นเพื่อเป็นตัวอย่างง่ายๆ ฉันจะใช้คุณสมบัติในตัวของมัน
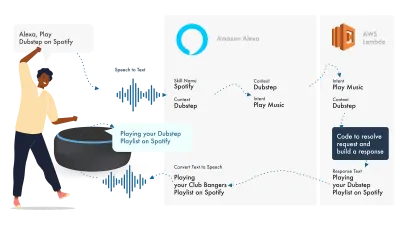
Alexa จัดการกับ Natural Language Processing แล้วจึงพบ Intent ที่เหมาะสม ซึ่งจะถูกส่งต่อไปยังฟังก์ชัน Lambda ของเราเพื่อจัดการกับตรรกะ การดำเนินการนี้จะส่งคืนบิตการสนทนา (SSML, ข้อความ, การ์ด และอื่นๆ) ไปยัง Alexa ซึ่งจะแปลงบิตเหล่านั้นเป็นเสียงและภาพเพื่อแสดงบนอุปกรณ์
การทำงานกับ Amazon นั้นค่อนข้างง่าย เนื่องจากช่วยให้คุณสร้างทักษะทุกส่วนภายใน Alexa Developer Console มีความยืดหยุ่นในการใช้ AWS หรือจุดปลาย HTTPS แต่สำหรับทักษะง่ายๆ การรันทุกอย่างภายในคอนโซล Dev น่าจะเพียงพอ
มาสร้างทักษะ Alexa อย่างง่ายกันเถอะ
ตรงไปที่คอนโซล Amazon Alexa สร้างบัญชี หากคุณยังไม่มี และเข้าสู่ระบบ
คลิก Create Skill จากนั้นตั้งชื่อ
เลือก custom เป็นรุ่นของคุณ
และเลือก Alexa-Hosted (Node.js) สำหรับทรัพยากรแบ็กเอนด์ของคุณ
เมื่อเตรียมใช้งานเสร็จแล้ว คุณจะมีทักษะพื้นฐานของ Alexa โดยจะมีความตั้งใจสร้างมาเพื่อคุณ และโค้ดส่วนหลังบางส่วนเพื่อเริ่มต้นใช้งาน
หากคุณคลิกที่ HelloWorldIntent ใน Intent ของคุณ คุณจะเห็นตัวอย่างคำพูดที่ตั้งไว้แล้วสำหรับคุณ มาเพิ่มคำใหม่ที่ด้านบนกัน ทักษะของเราเรียกว่า สวัสดีชาวโลก ดังนั้นให้เพิ่ม Hello World เป็นตัวอย่างคำพูด แนวคิดคือการจับภาพทุกอย่างที่ผู้ใช้อาจพูดเพื่อกระตุ้นความตั้งใจนี้ นี่อาจเป็น "Hi World", "Howdy World" เป็นต้น
เกิดอะไรขึ้นในการปฏิบัติตาม JS?
แล้วโค้ดมันทำอะไร? นี่คือรหัสเริ่มต้น:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; สิ่งนี้ใช้ ask-sdk-core และกำลังสร้าง JSON สำหรับเราเป็นหลัก canHandle กำลังแจ้งให้ ask ทราบว่าสามารถจัดการกับ Intent ได้ โดยเฉพาะ 'HelloWorldIntent' handle รับอินพุตและสร้างการตอบสนอง สิ่งนี้สร้างมีลักษณะดังนี้:
{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
เราจะเห็นว่า speak outputs ssml ใน json ของเราซึ่งเป็นสิ่งที่ผู้ใช้จะได้ยินเมื่อพูดโดย Alexa

การสร้างสำหรับ Google Assistant
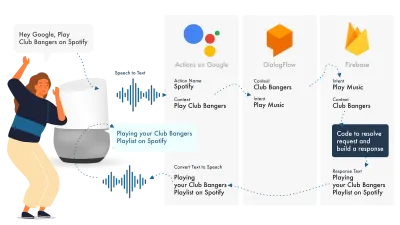
วิธีที่ง่ายที่สุดในการสร้าง Actions บน Google คือการใช้คอนโซล AoG ร่วมกับ Dialogflow คุณสามารถขยายทักษะของคุณด้วย firebase แต่เช่นเดียวกับบทช่วยสอนของ Amazon Alexa เรามาทำให้เรื่องง่ายขึ้นกันเถอะ
Google Assistant ใช้สามส่วนหลักคือ AoG ซึ่งเกี่ยวข้องกับ NLP, Dialogflow ซึ่งทำงานตามเจตนารมณ์ของคุณ และ Firebase ที่ตอบสนองคำขอ และสร้างการตอบสนองที่จะถูกส่งกลับไปยัง AoG
เช่นเดียวกับ Alexa Dialogflow ช่วยให้คุณสร้างฟังก์ชันของคุณได้โดยตรงภายในแพลตฟอร์ม
มาสร้างการกระทำบน Google กันเถอะ
มีสามแพลตฟอร์มที่จะเล่นปาหี่พร้อมกันด้วยโซลูชันของ Google ซึ่งสามารถเข้าถึงได้โดยคอนโซลที่แตกต่างกันสามตัว ดังนั้นแท็บเลย!
การตั้งค่าไดอะล็อกโฟลว์
เริ่มต้นด้วยการลงชื่อเข้าใช้คอนโซล Dialogflow เมื่อคุณเข้าสู่ระบบแล้ว ให้สร้างตัวแทนใหม่จากดรอปดาวน์ด้านล่างโลโก้ Dialogflow
ตั้งชื่อให้ตัวแทนของคุณ และเพิ่มใน 'Google Project Dropdown' โดยเลือก "สร้างโครงการ Google ใหม่"
คลิกปุ่มสร้าง และปล่อยให้มันใช้เวทย์มนตร์ มันจะต้องใช้เวลาเล็กน้อยในการตั้งค่าตัวแทน ดังนั้นโปรดอดทนรอ
การตั้งค่าฟังก์ชัน Firebase
ตอนนี้ เราสามารถเริ่มเสียบตรรกะ Fulfillment ได้แล้ว
ตรงไปที่แท็บการเติมเต็ม ติ๊กเพื่อเปิดใช้งานตัวแก้ไขอินไลน์ และใช้ตัวอย่าง JS ด้านล่าง:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);package.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }กลับไปที่ความตั้งใจของคุณ ไปที่ Default Welcome Intent และเลื่อนลงมาเพื่อเติมเต็ม ตรวจสอบให้แน่ใจว่าได้เลือก 'Enable webhook call for this Intent' สำหรับทุกความตั้งใจที่คุณต้องการทำให้สำเร็จด้วย javascript กดบันทึก
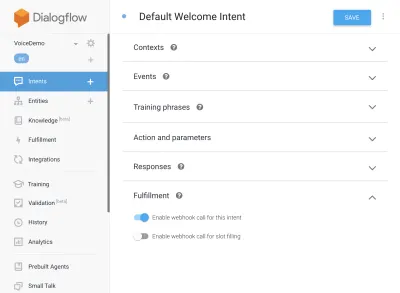
การตั้งค่า AoG
ตอนนี้เราใกล้จะถึงเส้นชัยแล้ว ตรงไปที่แท็บ Integrations แล้วคลิก Integration Settings ในตัวเลือก Google Assistant ที่ด้านบน การดำเนินการนี้จะเปิด modal ดังนั้นเรามาคลิกทดสอบกัน ซึ่งจะทำให้ Dialogflow ของคุณผสานรวมกับ Google และเปิดหน้าต่างทดสอบใน Actions on Google
ในหน้าต่างการทดสอบ เราสามารถคลิก พูดคุยกับแอปทดสอบของฉัน (เราจะเปลี่ยนแปลงสิ่งนี้ในไม่กี่วินาที) และ voila เรามีข้อความจากจาวาสคริปต์ของเราแสดงบนการทดสอบผู้ช่วยของ Google
เราสามารถเปลี่ยนชื่อผู้ช่วยในแท็บ Develop ด้านบนสุดได้
เกิดอะไรขึ้นในการปฏิบัติตาม JS?
ก่อนอื่น เราใช้แพ็คเกจ npm สองแพ็คเกจ, actions-on-google ซึ่งตอบสนองความต้องการทั้งหมดที่ทั้ง AoG และ Dialogflow และฟังก์ชัน firebase-function อย่างที่สองที่คุณเดาได้ว่ามีตัวช่วยสำหรับ firebase
จากนั้นเราจะสร้าง 'แอป' ซึ่งเป็นวัตถุที่มีความตั้งใจทั้งหมดของเรา
แต่ละเจตนาที่สร้างขึ้นผ่าน 'Conv' ซึ่งเป็นออบเจ็กต์การสนทนาที่ Actions On Google ส่งไป เราสามารถใช้เนื้อหาของ Conv. เพื่อตรวจจับข้อมูลเกี่ยวกับการโต้ตอบกับผู้ใช้ครั้งก่อนๆ ได้ (เช่น ID ของผู้ใช้และข้อมูลเกี่ยวกับเซสชันที่ผู้ใช้ทำกับเรา)
เราส่งคืน 'Conv.ask object' ซึ่งมีข้อความส่งคืนของเราถึงผู้ใช้ พร้อมให้ผู้ใช้ตอบกลับด้วยความตั้งใจอื่น เราสามารถใช้ 'conv.close' เพื่อสิ้นสุดการสนทนาได้ หากเราต้องการสิ้นสุดการสนทนาที่นั่น
สุดท้าย เรารวมทุกอย่างไว้ในฟังก์ชัน firebase HTTPS ที่เกี่ยวข้องกับลอจิกการตอบกลับคำขอฝั่งเซิร์ฟเวอร์สำหรับเรา
อีกครั้ง หากเราดูการตอบสนองที่สร้างขึ้น:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } เราจะเห็นว่า conv.ask ได้แทรกข้อความลงในพื้นที่ textToSpeech หากเราเลือก conv.close ความคาด expectUserResponse ของผู้ใช้จะถูกตั้งค่าเป็น " false " และการสนทนาจะปิดลงหลังจากส่งข้อความแล้ว
ผู้สร้างเสียงบุคคลที่สาม
เช่นเดียวกับอุตสาหกรรมแอป เนื่องจากเสียงได้รับแรงฉุด เครื่องมือของบุคคลที่สามได้เริ่มปรากฏขึ้นเพื่อพยายามบรรเทาภาระของนักพัฒนาซอฟต์แวร์ ทำให้พวกเขาสามารถสร้างได้ครั้งเดียวปรับใช้สองครั้ง
ปัจจุบัน Jovo และ Voiceflow ได้รับความนิยมสูงสุด 2 รายการ โดยเฉพาะอย่างยิ่งเมื่อ Apple เข้าซื้อกิจการของ PullString แต่ละแพลตฟอร์มนำเสนอระดับนามธรรมที่แตกต่างกัน ดังนั้นมันจึงขึ้นอยู่กับความเรียบง่ายที่คุณเป็นเหมือนอินเทอร์เฟซของคุณ
ขยายทักษะของคุณ
เมื่อคุณได้ใช้ความคิดในการสร้างทักษะ 'สวัสดีชาวโลก' ขั้นพื้นฐานแล้ว มีเสียงระฆังและนกหวีดมากมายที่คุณสามารถเพิ่มให้กับทักษะของคุณได้ สิ่งเหล่านี้เป็นส่วนเสริมของ Voice Assistants และจะมอบคุณค่าพิเศษให้กับผู้ใช้ของคุณ นำไปสู่แบบกำหนดเองซ้ำๆ และโอกาสทางการค้าที่อาจเกิดขึ้น
SSML
SSML ย่อมาจากภาษามาร์กอัปการสังเคราะห์เสียงพูดและดำเนินการด้วยไวยากรณ์ที่คล้ายกับ HTML ความแตกต่างที่สำคัญคือคุณกำลังสร้างการตอบกลับด้วยคำพูด ไม่ใช่เนื้อหาบนหน้าเว็บ
คำว่า 'SSML' ทำให้เข้าใจผิดเล็กน้อย ทำได้มากกว่าการสังเคราะห์เสียง! คุณสามารถให้เสียงพูดคู่กันได้ คุณสามารถใส่เสียงบรรยากาศ คำพูด (ควรค่าแก่การฟังในตัวเอง คิดอิโมจิสำหรับวลีที่มีชื่อเสียง) และดนตรี
ฉันควรใช้ SSML เมื่อใด
SSML นั้นยอดเยี่ยม มันทำให้ผู้ใช้มีส่วนร่วมมากขึ้นประสบการณ์ แต่สิ่งที่ยังทำคือลดความยืดหยุ่นของเอาต์พุตเสียง ฉันแนะนำให้ใช้สำหรับพื้นที่การพูดที่นิ่งมากขึ้น คุณสามารถใช้ตัวแปรในนั้นสำหรับชื่อ ฯลฯ แต่ถ้าคุณไม่ต้องการสร้างตัวสร้าง SSML SSML ส่วนใหญ่จะค่อนข้างคงที่
เริ่มต้นด้วยการพูดง่ายๆ ในทักษะของคุณ และเมื่อเสร็จแล้ว ให้ปรับปรุงส่วนที่ไม่แน่นอนมากขึ้นด้วย SSML แต่ใช้หลักของคุณให้ถูกต้องก่อนที่จะไปต่อที่ระฆังและนกหวีด รายงานล่าสุดระบุว่า 71% ของผู้ใช้ชอบเสียงมนุษย์ (ของจริง) มากกว่าเสียงสังเคราะห์ ดังนั้นหากคุณมีสิ่งอำนวยความสะดวกในการทำเช่นนั้น ออกไปและทำเลย!

ในการซื้อทักษะ
การซื้อในทักษะ (หรือ ISP) คล้ายกับแนวคิดของการซื้อในแอป ทักษะมักจะไม่เสียค่าใช้จ่าย แต่บางทักษะอนุญาตให้ซื้อเนื้อหา/การสมัครรับข้อมูล 'พรีเมียม' ภายในแอป สิ่งเหล่านี้สามารถปรับปรุงประสบการณ์ของผู้ใช้ ปลดล็อกระดับใหม่ในเกม หรืออนุญาตให้เข้าถึงเนื้อหาเพย์วอลล์
หลายรูปแบบ
การตอบสนองต่อเนื่องหลายรูปแบบครอบคลุมมากกว่าเสียง ซึ่งเป็นที่ที่ผู้ช่วยเสียงสามารถเปล่งประกายด้วยภาพเสริมบนอุปกรณ์ที่รองรับได้ คำจำกัดความของประสบการณ์หลายรูปแบบนั้นกว้างกว่ามาก และโดยพื้นฐานแล้วหมายถึงอินพุตที่หลากหลาย (คีย์บอร์ด เมาส์ หน้าจอสัมผัส เสียง และอื่นๆ)
ทักษะต่อเนื่องหลายรูปแบบมีจุดมุ่งหมายเพื่อเสริมประสบการณ์เสียงหลัก โดยให้ข้อมูลเสริมเพิ่มเติมเพื่อเพิ่ม UX เมื่อสร้างประสบการณ์ต่อเนื่องหลายรูปแบบ จำไว้ว่าเสียงเป็นสื่อกลางในการให้ข้อมูล อุปกรณ์จำนวนมากไม่มีหน้าจอ ดังนั้นทักษะของคุณยังต้องทำงานโดยไม่มีหน้าจอ ดังนั้นอย่าลืมทดสอบกับอุปกรณ์หลายประเภท ไม่ว่าจะเป็นของจริงหรือในเครื่องจำลอง

พูดได้หลายภาษา
ทักษะหลายภาษาเป็นทักษะที่ทำงานในหลายภาษาและเปิดทักษะของคุณไปสู่ตลาดต่างๆ
ความซับซ้อนในการทำให้ทักษะของคุณพูดได้หลายภาษานั้นขึ้นอยู่กับการตอบสนองของคุณแบบไดนามิก ทักษะที่มีการตอบสนองค่อนข้างคงที่ เช่น การส่งคืนวลีเดิมทุกครั้ง หรือใช้วลีกลุ่มเล็กๆ เท่านั้น จะทำให้พูดได้หลายภาษาได้ง่ายกว่าทักษะแบบไดนามิกที่แผ่ขยายออกไป
เคล็ดลับสำหรับหลายภาษาคือการมีหุ้นส่วนการแปลที่น่าเชื่อถือ ไม่ว่าจะผ่านเอเจนซี่หรือนักแปลใน Fiverr คุณต้องสามารถเชื่อถือคำแปลที่มีให้ โดยเฉพาะอย่างยิ่งหากคุณไม่เข้าใจภาษาที่กำลังแปล Google Translate จะไม่ตัดมัสตาร์ดที่นี่!
บทสรุป
ถ้ามีเวลาเข้าสู่อุตสาหกรรมเสียง ก็คงเป็นตอนนี้ ทั้งในช่วงวัยแรกรุ่นและวัยทารก เช่นเดียวกับกลุ่มใหญ่เก้าคน กำลังทุ่มเงินหลายพันล้านเพื่อปลูกมันและนำผู้ช่วยเสียงมาที่บ้านและกิจวัตรประจำวันของทุกคน
การเลือกแพลตฟอร์มที่จะใช้อาจเป็นเรื่องยุ่งยาก แต่ขึ้นอยู่กับสิ่งที่คุณตั้งใจจะสร้าง แพลตฟอร์มที่ใช้ควรโดดเด่นหรือล้มเหลว ใช้เครื่องมือของบุคคลที่สามเพื่อป้องกันความเสี่ยงในการเดิมพันของคุณ และสร้างบนหลายแพลตฟอร์ม โดยเฉพาะถ้าทักษะของคุณ ซับซ้อนน้อยกว่าด้วยชิ้นส่วนที่เคลื่อนไหวน้อยลง
ประการหนึ่ง ข้าพเจ้ารู้สึกตื่นเต้นเกี่ยวกับอนาคตของเสียงที่แพร่หลาย การพึ่งพาหน้าจอจะลดลงและลูกค้าจะสามารถโต้ตอบกับผู้ช่วยได้อย่างเป็นธรรมชาติ แต่ก่อนอื่น มันขึ้นอยู่กับเราที่จะสร้างทักษะที่ผู้คนต้องการจากผู้ช่วยของพวกเขา