
คู่มือขั้นสูงในการสร้างเครื่องขูดเว็บที่ปรับขนาดได้ด้วย Scrapy
เผยแพร่แล้ว: 2022-03-10การขูดเว็บเป็นวิธีการดึงข้อมูลจากเว็บไซต์โดยไม่ต้องเข้าถึง API หรือฐานข้อมูลของเว็บไซต์ คุณต้องการเข้าถึงข้อมูลของไซต์เท่านั้น ตราบใดที่เบราว์เซอร์ของคุณสามารถเข้าถึงข้อมูล คุณจะสามารถขูดข้อมูลได้
ในความเป็นจริง ส่วนใหญ่คุณสามารถเข้าไปที่เว็บไซต์ด้วยตนเองและดึงข้อมูล 'ด้วยมือ' โดยใช้การคัดลอกและวาง แต่ในหลายกรณี ที่จะทำให้คุณต้องใช้เวลาหลายชั่วโมงในการทำงานด้วยตนเอง ซึ่งอาจทำให้คุณต้องเสียค่าใช้จ่าย มีค่ามากกว่าข้อมูล โดยเฉพาะอย่างยิ่งถ้าคุณจ้างคนมาทำงานให้คุณ ทำไมต้องจ้างคนมาทำงานที่เวลา 1-2 นาทีต่อการสืบค้น ในเมื่อคุณสามารถให้โปรแกรมดำเนินการสืบค้นโดยอัตโนมัติทุก ๆ สองสามวินาที
ตัวอย่างเช่น สมมติว่าคุณต้องการรวบรวมรายชื่อผู้ชนะรางวัลออสการ์สำหรับภาพที่ดีที่สุด ร่วมกับผู้กำกับ นักแสดงนำแสดง วันที่ออกฉาย และเวลาแสดง เมื่อใช้ Google คุณจะเห็นว่ามีเว็บไซต์หลายแห่งที่จะแสดงรายการภาพยนตร์เหล่านี้ตามชื่อ และอาจเป็นข้อมูลเพิ่มเติม แต่โดยทั่วไป คุณจะต้องติดตามผ่านลิงก์เพื่อเก็บข้อมูลทั้งหมดที่คุณต้องการ
เห็นได้ชัดว่ามันเป็นไปไม่ได้และใช้เวลานานในการดูทุกลิงก์ตั้งแต่ปี 1927 จนถึงปัจจุบัน และพยายามค้นหาข้อมูลผ่านแต่ละหน้าด้วยตนเอง ด้วยการขูดเว็บ เราเพียงแค่ต้องค้นหาเว็บไซต์ที่มีหน้าเว็บที่มีข้อมูลทั้งหมดนี้ จากนั้นจึงชี้โปรแกรมของเราไปในทิศทางที่ถูกต้องพร้อมคำแนะนำที่ถูกต้อง
ในบทช่วยสอนนี้ เราจะใช้ Wikipedia เป็นเว็บไซต์ของเรา เนื่องจากมีข้อมูลทั้งหมดที่เราต้องการ จากนั้นจึงใช้ Scrapy บน Python เป็นเครื่องมือในการขูดข้อมูลของเรา
คำเตือนสองสามข้อก่อนที่เราจะเริ่ม:
การขูดข้อมูลเกี่ยวข้องกับการเพิ่มโหลดของเซิร์ฟเวอร์สำหรับไซต์ที่คุณกำลังดึงข้อมูล ซึ่งหมายความว่าบริษัทที่โฮสต์ไซต์นั้นมีค่าใช้จ่ายสูงขึ้น และประสบการณ์คุณภาพที่ต่ำกว่าสำหรับผู้ใช้รายอื่นของไซต์นั้น คุณภาพของเซิร์ฟเวอร์ที่ใช้งานเว็บไซต์ จำนวนข้อมูลที่คุณพยายามรับ และอัตราที่คุณส่งคำขอไปยังเซิร์ฟเวอร์จะกลั่นกรองผลกระทบที่คุณมีต่อเซิร์ฟเวอร์ เมื่อคำนึงถึงสิ่งนี้ เราต้องแน่ใจว่าเราปฏิบัติตามกฎสองสามข้อ
ไซต์ส่วนใหญ่ยังมีไฟล์ชื่อ robots.txt ในไดเร็กทอรีหลัก ไฟล์นี้กำหนดกฎสำหรับไซต์ไดเร็กทอรีใดที่ไม่ต้องการให้แครปเปอร์เข้าถึง หน้าข้อกำหนดและเงื่อนไขของเว็บไซต์มักจะแจ้งให้คุณทราบว่านโยบายเกี่ยวกับการขูดข้อมูลคืออะไร ตัวอย่างเช่น หน้าเงื่อนไขของ IMDB มีอนุประโยคดังต่อไปนี้:
หุ่นยนต์และการขูดหน้าจอ: คุณไม่สามารถใช้การขุดข้อมูล หุ่นยนต์ การขูดหน้าจอ หรือเครื่องมือรวบรวมและดึงข้อมูลที่คล้ายกันบนไซต์นี้ ยกเว้นได้รับความยินยอมเป็นลายลักษณ์อักษรโดยชัดแจ้งตามที่ระบุไว้ด้านล่าง
ก่อนที่เราจะพยายามรับข้อมูลของเว็บไซต์ เราควรตรวจสอบข้อกำหนดของเว็บไซต์และ robots.txt เสมอเพื่อให้แน่ใจว่าเราได้รับข้อมูลทางกฎหมาย เมื่อสร้างแครปเปอร์ เราต้องตรวจสอบให้แน่ใจด้วยว่าเราจะไม่ส่งคำขอที่เซิร์ฟเวอร์ไม่สามารถจัดการได้ล้นหลาม
โชคดีที่เว็บไซต์หลายแห่งตระหนักดีถึงความจำเป็นที่ผู้ใช้จะได้รับข้อมูล และทำให้ข้อมูลพร้อมใช้งานผ่าน API หากมีข้อมูลเหล่านี้ มักจะง่ายกว่ามากในการรับข้อมูลผ่าน API มากกว่าการดึงข้อมูล
Wikipedia อนุญาตให้ดึงข้อมูลได้ ตราบใดที่บอทไม่ 'เร็วเกินไป' ตามที่ระบุไว้ใน robots.txt พวกเขายังจัดเตรียมชุดข้อมูลที่ดาวน์โหลดได้เพื่อให้ผู้คนสามารถประมวลผลข้อมูลบนเครื่องของตนเองได้ ถ้าเราไปเร็วเกินไป เซิร์ฟเวอร์จะบล็อก IP ของเราโดยอัตโนมัติ ดังนั้นเราจะใช้ตัวจับเวลาเพื่อให้อยู่ในกฎของพวกเขา
เริ่มต้น ติดตั้งไลบรารีที่เกี่ยวข้องโดยใช้ Pip
ก่อนอื่น มาเริ่มกันเลย ให้ติดตั้ง Scrapy
Windows
ติดตั้ง Python เวอร์ชันล่าสุดจาก https://www.python.org/downloads/windows/
หมายเหตุ: ผู้ใช้ Windows จะต้องใช้ Microsoft Visual C++ 14.0 ซึ่งคุณสามารถคว้าจาก “Microsoft Visual C++ Build Tools” ได้ที่นี่
คุณจะต้องแน่ใจว่าคุณมี pip เวอร์ชันล่าสุด
ใน cmd.exe พิมพ์ใน:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyสิ่งนี้จะติดตั้ง Scrapy และการพึ่งพาทั้งหมดโดยอัตโนมัติ
ลินุกซ์
ก่อนอื่น คุณจะต้องติดตั้งการพึ่งพาทั้งหมด:
ใน Terminal ให้ป้อน:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devเมื่อติดตั้งเสร็จแล้ว เพียงพิมพ์:
pip install --upgrade pipเพื่อให้แน่ใจว่า pip ได้รับการอัปเดตแล้ว:
pip install scrapyและเสร็จแล้ว
Mac
ก่อนอื่นคุณต้องแน่ใจว่าคุณมีคอมไพเลอร์ในระบบของคุณ ใน Terminal ให้ป้อน:
xcode-select --installหลังจากนั้น ติดตั้ง homebrew จาก https://brew.sh/
อัปเดตตัวแปร PATH ของคุณเพื่อให้ใช้แพ็คเกจ homebrew ก่อนแพ็คเกจระบบ:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcติดตั้งไพทอน:
brew install pythonจากนั้นตรวจสอบให้แน่ใจว่าทุกอย่างได้รับการอัปเดต:
brew update; brew upgrade pythonหลังจากทำเสร็จแล้ว เพียงติดตั้ง Scrapy โดยใช้ pip:
pip install Scrapy > ## ภาพรวมของ Scrapy ชิ้นส่วนประกอบเข้าด้วยกัน Parsers แมงมุม ฯลฯ อย่างไรคุณจะต้องเขียนสคริปต์ชื่อ 'Spider' เพื่อให้ Scrapy ทำงาน แต่ไม่ต้องกังวล แมงมุม Scrapy นั้นไม่น่ากลัวเลยแม้แต่ชื่อของมัน สไปเดอร์สไปเดอร์สและสไปเดอร์ตัวจริงที่มีความคล้ายคลึงกันเพียงอย่างเดียวคือพวกมันชอบคลานบนเว็บ
ภายในสไปเดอร์เป็น class ที่คุณกำหนดซึ่งบอก Scrapy ว่าต้องทำอะไร ตัวอย่างเช่น จะเริ่มรวบรวมข้อมูลจากที่ใด ประเภทของคำขอที่ส่ง วิธีติดตามลิงก์บนหน้าเว็บ และวิธีแยกวิเคราะห์ข้อมูล คุณยังสามารถเพิ่มฟังก์ชันแบบกำหนดเองเพื่อประมวลผลข้อมูลได้เช่นกัน ก่อนที่จะส่งออกกลับเป็นไฟล์
ในการเริ่มสไปเดอร์ตัวแรก เราต้องสร้างโปรเจ็กต์ Scrapy ก่อน เมื่อต้องการทำสิ่งนี้ ให้ป้อนสิ่งนี้ลงในบรรทัดคำสั่งของคุณ:
scrapy startproject oscarsนี้จะสร้างโฟลเดอร์ที่มีโครงการของคุณ
เราจะเริ่มต้นด้วยแมงมุมพื้นฐาน รหัสต่อไปนี้จะถูกป้อนลงในสคริปต์หลาม เปิดสคริปต์หลามใหม่ใน /oscars/spiders และตั้งชื่อว่า oscars_spider.py
เราจะนำเข้า Scrapy
import scrapyจากนั้นเราก็เริ่มกำหนดคลาสสไปเดอร์ของเรา ขั้นแรก เราตั้งชื่อแล้วตามด้วยโดเมนที่สไปเดอร์สามารถขูดได้ สุดท้าย เราบอกแมงมุมว่าจะเริ่มขูดจากตรงไหน
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']ต่อไป เราต้องการฟังก์ชันที่จะเก็บข้อมูลที่เราต้องการ สำหรับตอนนี้ เราจะแค่คว้าชื่อหน้า เราใช้ CSS เพื่อค้นหาแท็กที่มีข้อความชื่อ จากนั้นเราแยกมันออกมา สุดท้าย เราจะส่งคืนข้อมูลกลับไปที่ Scrapy เพื่อบันทึกหรือเขียนลงในไฟล์
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data ตอนนี้ให้บันทึกโค้ดใน /oscars/spiders/oscars_spider.py
ในการรันสไปเดอร์นี้ เพียงไปที่บรรทัดคำสั่งของคุณและพิมพ์:
scrapy crawl oscarsคุณควรเห็นผลลัพธ์ดังนี้:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
ขอแสดงความยินดี คุณได้สร้างเครื่องขูด Scrapy พื้นฐานเครื่องแรกของคุณแล้ว!

รหัสเต็ม:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataเห็นได้ชัดว่าเราต้องการให้มันทำอะไรมากกว่านี้ มาดูวิธีใช้ Scrapy เพื่อแยกวิเคราะห์ข้อมูลกัน
อันดับแรก มาทำความรู้จักกับ Scrapy shell กันก่อน เชลล์ Scrapy สามารถช่วยคุณทดสอบโค้ดของคุณเพื่อให้แน่ใจว่า Scrapy กำลังดึงข้อมูลที่คุณต้องการ
ในการเข้าถึงเชลล์ ให้ป้อนสิ่งนี้ลงในบรรทัดคำสั่งของคุณ:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”โดยพื้นฐานแล้วจะเป็นการเปิดหน้าเว็บที่คุณนำทางไป และจะช่วยให้คุณเรียกใช้โค้ดบรรทัดเดียวได้ ตัวอย่างเช่น คุณสามารถดู HTML ดิบของหน้าโดยพิมพ์ใน:
print(response.text)หรือเปิดหน้าในเบราว์เซอร์เริ่มต้นของคุณโดยพิมพ์ใน:
view(response)เป้าหมายของเราคือค้นหาโค้ดที่มีข้อมูลที่เราต้องการ ตอนนี้เรามาลองคว้าชื่อหนังกันก่อนดีกว่า
วิธีที่ง่ายที่สุดในการค้นหาโค้ดที่เราต้องการคือการเปิดหน้าเว็บในเบราว์เซอร์ของเราและตรวจสอบโค้ด ในตัวอย่างนี้ ฉันใช้ Chrome DevTools เพียงคลิกขวาที่ชื่อภาพยนตร์และเลือก 'ตรวจสอบ':
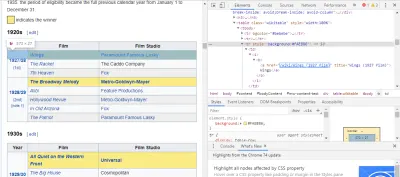
อย่างที่คุณเห็น ผู้ได้รับรางวัลออสการ์มีพื้นหลังสีเหลือง ในขณะที่ผู้ได้รับการเสนอชื่อมีพื้นหลังธรรมดา นอกจากนี้ยังมีลิงก์ไปยังบทความเกี่ยวกับชื่อภาพยนตร์ และลิงก์สำหรับภาพยนตร์ที่ลงท้ายด้วย film) เมื่อรู้แล้ว เราก็สามารถใช้ตัวเลือก CSS เพื่อดึงข้อมูลได้ ในเชลล์ Scrapy พิมพ์ใน:
response.css(r"tr[] a[href*='film)']").extract()อย่างที่คุณเห็น ตอนนี้คุณมีรายชื่อผู้ชนะรางวัลออสการ์สาขาภาพยนตร์ยอดเยี่ยมทั้งหมดแล้ว!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']ย้อนกลับไปที่เป้าหมายหลักของเรา เราต้องการรายชื่อผู้ชนะรางวัลออสการ์สาขาภาพยนตร์ยอดเยี่ยม ร่วมกับผู้กำกับ นักแสดงนำ วันที่ฉาย และเวลาแสดง ในการทำเช่นนี้ เราต้องใช้ Scrapy เพื่อดึงข้อมูลจากหน้าภาพยนตร์แต่ละหน้า
เราจะต้องเขียนบางสิ่งใหม่และเพิ่มฟังก์ชันใหม่ แต่ไม่ต้องกังวล มันค่อนข้างตรงไปตรงมา
เราจะเริ่มต้นด้วยการเริ่มต้นมีดโกนแบบเดียวกับเมื่อก่อน
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] แต่คราวนี้ สองสิ่งจะเปลี่ยนไป อันดับแรก เราจะนำเข้า time พร้อมกับเรื่องที่ scrapy เพราะเราต้องการสร้างตัวจับเวลาเพื่อจำกัดความเร็วที่บอทจะขูด นอกจากนี้ เมื่อเราแยกวิเคราะห์หน้าต่างๆ ในครั้งแรก เราต้องการเพียงรายการลิงก์ไปยังแต่ละชื่อ เพื่อให้เราสามารถดึงข้อมูลออกจากหน้าเหล่านั้นแทน
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req ที่นี่เราทำลูปเพื่อค้นหาทุกลิงก์บนหน้าที่ลงท้ายด้วย film) โดยมีพื้นหลังสีเหลืองอยู่ในนั้น จากนั้นเรารวมลิงก์เหล่านั้นเข้าด้วยกันเป็นรายการ URL ซึ่งเราจะส่งไปยังฟังก์ชัน parse_titles เพื่อส่งต่อ นอกจากนี้เรายังจับเวลาเพื่อขอหน้าทุก ๆ 5 วินาทีเท่านั้น จำไว้ว่าเราสามารถใช้ Scrapy shell เพื่อทดสอบฟิลด์ response.css ของเราเพื่อให้แน่ใจว่าเราได้รับข้อมูลที่ถูกต้อง!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data งานจริงเสร็จสิ้นในฟังก์ชัน parse_data ซึ่งเราสร้างพจนานุกรมที่เรียกว่า data จากนั้นกรอกข้อมูลที่เราต้องการในแต่ละคีย์ อีกครั้ง พบตัวเลือกเหล่านี้ทั้งหมดโดยใช้ Chrome DevTools ดังที่แสดงไว้ก่อนหน้านี้ จากนั้นจึงทดสอบด้วย Scrapy shell
บรรทัดสุดท้ายส่งคืนพจนานุกรมข้อมูลกลับไปที่ Scrapy เพื่อจัดเก็บ
รหัสที่สมบูรณ์:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataบางครั้งเราต้องการใช้พร็อกซี่เนื่องจากเว็บไซต์จะพยายามบล็อกความพยายามของเราในการขูด
ในการทำเช่นนี้ เราต้องเปลี่ยนแปลงบางสิ่งเท่านั้น ใช้ตัวอย่างของเราใน def parse() เราต้องเปลี่ยนเป็นดังต่อไปนี้:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqการดำเนินการนี้จะกำหนดเส้นทางคำขอผ่านพร็อกซีเซิร์ฟเวอร์ของคุณ
การปรับใช้และการบันทึก แสดงวิธีจัดการแมงมุมจริงในการผลิต
ตอนนี้ได้เวลาวิ่งแมงมุมของเราแล้ว หากต้องการให้ Scrapy เริ่มการขูดและส่งออกไปยังไฟล์ CSV ให้ป้อนข้อมูลต่อไปนี้ในพรอมต์คำสั่งของคุณ:
scrapy crawl oscars -o oscars.csvคุณจะเห็นเอาต์พุตขนาดใหญ่ และหลังจากนั้นไม่กี่นาที ไฟล์ก็จะเสร็จสมบูรณ์และคุณจะมีไฟล์ CSV อยู่ในโฟลเดอร์โปรเจ็กต์ของคุณ
รวบรวมผลลัพธ์ แสดงวิธีใช้ผลลัพธ์ที่รวบรวมในขั้นตอนก่อนหน้า
เมื่อคุณเปิดไฟล์ CSV คุณจะเห็นข้อมูลทั้งหมดที่เราต้องการ (จัดเรียงตามคอลัมน์ที่มีส่วนหัว) มันง่ายมากจริงๆ
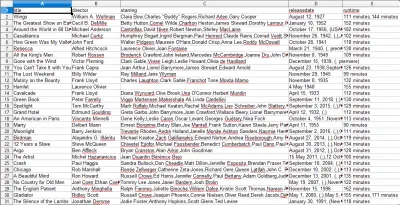
ด้วยการขูดข้อมูล เราสามารถรับชุดข้อมูลที่กำหนดเองเกือบทุกชุดที่เราต้องการ ตราบใดที่ข้อมูลนั้นเปิดเผยต่อสาธารณะ สิ่งที่คุณต้องการทำกับข้อมูลนี้ขึ้นอยู่กับคุณ ทักษะนี้มีประโยชน์อย่างมากสำหรับการทำวิจัยตลาด อัปเดตข้อมูลบนเว็บไซต์ และอื่นๆ อีกมากมาย
ค่อนข้างง่ายในการตั้งค่ามีดโกนเว็บของคุณเองเพื่อรับชุดข้อมูลที่กำหนดเอง อย่างไรก็ตาม โปรดจำไว้เสมอว่าอาจมีวิธีอื่นๆ ในการรับข้อมูลที่คุณต้องการ ธุรกิจลงทุนอย่างมากในการให้ข้อมูลที่คุณต้องการ ดังนั้นจึงยุติธรรมเท่านั้นที่เราเคารพข้อกำหนดและเงื่อนไขของพวกเขา
แหล่งข้อมูลเพิ่มเติมสำหรับการเรียนรู้เพิ่มเติมเกี่ยวกับ Scrapy และ Web Scraping โดยทั่วไป
- เว็บไซต์ Scrapy อย่างเป็นทางการ
- หน้า GitHub ของ Scrapy
- “10 เครื่องมือขูดข้อมูลที่ดีที่สุดและเครื่องมือขูดเว็บ” Scraper API
- “5 เคล็ดลับสำหรับการขูดเว็บโดยไม่ถูกบล็อกหรือขึ้นบัญชีดำ” Scraper API
- Parsel ไลบรารี Python ที่ใช้นิพจน์ทั่วไปเพื่อดึงข้อมูลจาก HTML