
ต้นไม้ในโครงสร้างข้อมูล: ต้นไม้ 8 ประเภทที่นักวิทยาศาสตร์ข้อมูลทุกคนควรรู้
เผยแพร่แล้ว: 2021-05-26สารบัญ
บทนำ
ในโดเมนการคำนวณ โครงสร้างข้อมูลอ้างอิงถึงรูปแบบของการจัดเรียงข้อมูลบนดิสก์ ซึ่งช่วยให้สามารถจัดเก็บและแสดงผลได้สะดวก พวกเขาเกี่ยวข้องกับสาขาวิทยาศาสตร์ข้อมูลซึ่งได้รับการคาดการณ์ว่าจะเป็นทางเลือกอาชีพที่ร่ำรวยในปี 2564 จากการคาดการณ์ในอีกไม่กี่ปีข้างหน้า โมเดลการเรียนรู้เชิงลึกขนาดใหญ่และอุปกรณ์อัจฉริยะรุ่นต่อไปจะช่วยปูทางอนาคตของ ภาคนี้.
ดังนั้นการได้รับความรู้เกี่ยวกับโครงสร้างข้อมูลจึงเป็นสิ่งจำเป็นสำหรับการค้นหาอาชีพที่เหมาะสมท่ามกลางความก้าวหน้าทางเทคโนโลยี ตามการคาดการณ์ของอุตสาหกรรม Data Science ในปี 2564 สหรัฐอเมริกาและอินเดียจะจ้างนักวิทยาศาสตร์ข้อมูลประมาณ 50000 คนและนักวิเคราะห์ข้อมูล 300,000 คนภายในบริษัทมากกว่า 2,50,000 แห่ง [1]
โครงสร้างข้อมูลถูกนำไปใช้ในการออกแบบเส้นทางสำหรับการจัดสรร การจัดการ และการดึงข้อมูล โครงสร้างข้อมูลมีความจำเป็นอย่างยิ่งสำหรับการร่างและปรับปรุงประสิทธิภาพของข้อมูลที่ประมวลผลโดยรวม พวกเขาจัดการข้อมูลโดยการจัดกลุ่มและจัดระเบียบเพื่ออำนวยความสะดวกในการแลกเปลี่ยนข้อมูลอย่างมีประสิทธิภาพ
ต้นไม้ในโครงสร้างข้อมูล
'ต้นไม้' เป็นประเภทของ ADT (ประเภทข้อมูลนามธรรม) ซึ่งเป็นไปตามรูปแบบลำดับชั้นสำหรับการจัดสรรข้อมูล โดยพื้นฐานแล้ว ต้นไม้คือชุดของโหนดหลายโหนดที่เชื่อมต่อผ่านขอบ "ต้นไม้" เหล่านี้สร้างการออกแบบโครงสร้างข้อมูลที่คล้ายกับต้นไม้ โดยที่โหนด "รูท" จะนำไปสู่โหนด "หลัก" ซึ่ง ท้ายที่สุดจะนำไปสู่ โหนด "ย่อย" การเชื่อมต่อทำด้วยเส้นที่เรียกว่า 'ขอบ'
โหนด 'Leaf' เป็นจุดปลายทางที่ไม่มีโหนดย่อยเพิ่มเติมที่มาจากโหนดเหล่านี้ ต้นไม้ในโครงสร้างข้อมูล มีบทบาทสำคัญในการจัดเรียงที่ไม่เป็นเชิงเส้น ซึ่งช่วยให้ตอบสนองเร็วขึ้นระหว่างการค้นหา พร้อมด้วยความสะดวกตลอดขั้นตอนการออกแบบ
ประเภทของต้นไม้ในโครงสร้างข้อมูล
ต้นไม้ ประเภทต่างๆ ในโครงสร้างข้อมูล มีคำอธิบายในเชิงลึกด้านล่าง:
1. ต้นไม้ทั่วไป
แผนผังทั่วไปมีลักษณะเฉพาะโดยไม่มีข้อกำหนดหรือข้อจำกัดใดๆ เกี่ยวกับจำนวนชายน์ที่โหนดสามารถมีได้ ต้นไม้ใดๆ ที่มีโครงสร้างแบบลำดับชั้นสามารถจัดเป็นต้นไม้ทั่วไปได้ โหนดสามารถมีลูกได้หลายคน และสามารถมีการผสมผสานรูปแบบใดก็ได้สำหรับการวางแนวของต้นไม้ โหนดสามารถมีระดับใดก็ได้ตั้งแต่ 0 ถึง n
ต่อไปนี้เป็นตัวอย่างคลาสสิกของทรีทั่วไปในโครงสร้างข้อมูล โดยที่ '2' ที่ด้านบนสุดคือโหนดรูท
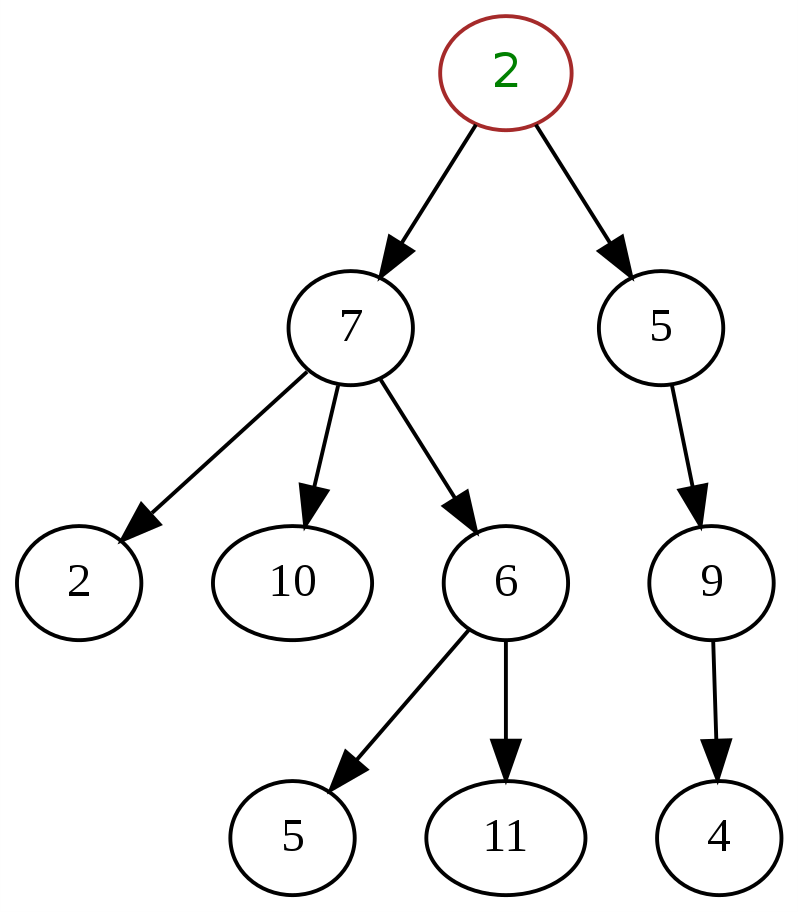
แหล่งที่มา
2. ต้นไม้ไบนารี
ตามคำจำกัดความของคำว่า 'ไบนารี' ซึ่งหมายถึงตัวเลขสองตัว ต้นไม้ไบนารีประกอบด้วยโหนดที่สามารถมีโหนดย่อยได้ 2 โหนด โหนดใดๆ ในไบนารีทรีสามารถมีโหนดได้สูงสุด 0, 1 หรือ 2 โหนด ทรีไบนารี ในโครงสร้างข้อมูล เป็น ADT ที่ใช้งานได้สูง และสามารถแบ่งย่อยได้อีกหลายประเภท ส่วนใหญ่จะใช้ในโครงสร้างข้อมูลเพื่อวัตถุประสงค์สองประการ:
- สำหรับการเข้าถึงโหนดและการติดป้ายกำกับ ตามที่สังเกตพบใน Binary Search Trees
- สำหรับการแสดงข้อมูลผ่านโครงสร้างแบบแยกสองส่วน
ต่อไปนี้เป็นไดอะแกรมพื้นฐานของต้นไม้ไบนารีในโครงสร้างข้อมูล:
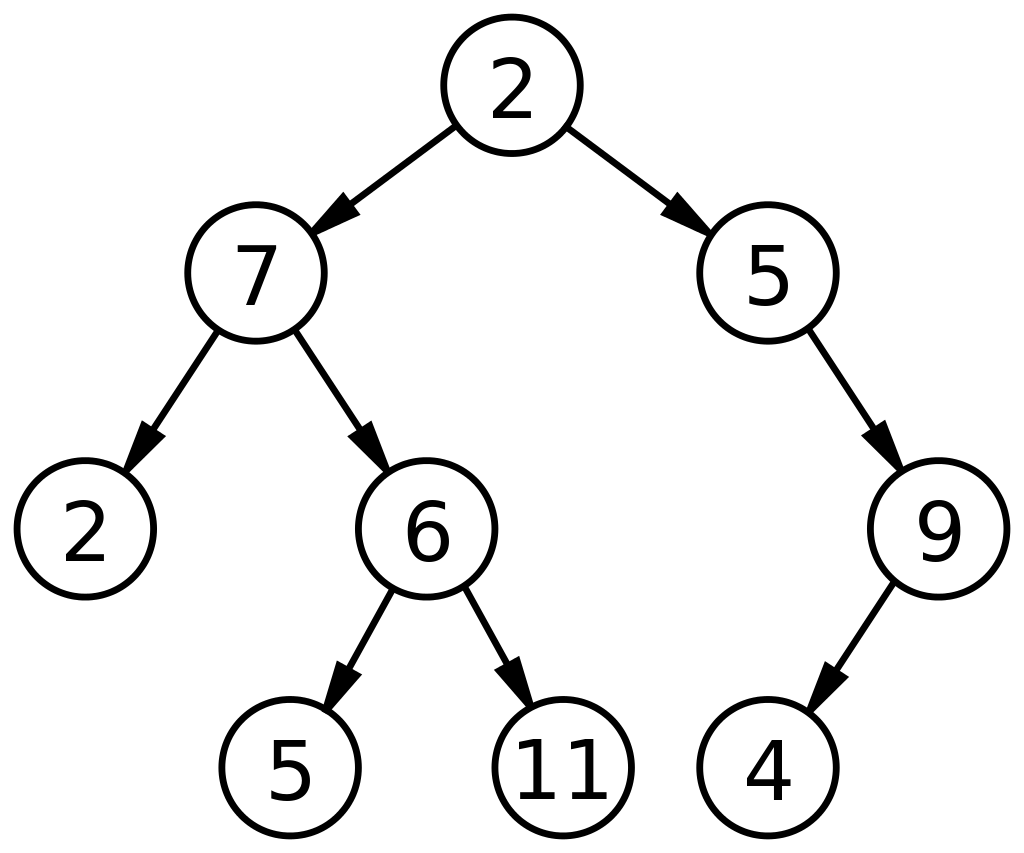
แหล่งที่มา
3. แผนผังการค้นหาไบนารี
Binary Search Tree (BST) เป็นชนิดย่อยเฉพาะของไบนารีทรีที่จัดเรียงในลักษณะที่อำนวยความสะดวกในการค้นหา/ค้นหา หรือเพิ่ม/ลบข้อมูลได้เร็วขึ้น BST ถูกกำหนดโดยการแสดงโหนดตามสามฟิลด์: ข้อมูล ลูกซ้าย และลูกขวา ปัจจัยควบคุมสำหรับ BST คือ:
- ทุกโหนดทางด้านซ้าย (ลูกซ้าย) ต้องมีค่าที่น้อยกว่าโหนดหลัก
- ทุกโหนดทางด้านขวา (ชายด์ด้านขวา) ต้องมีค่าที่สูงกว่าโหนดหลัก
การจัดเรียงดังกล่าวจะลดเวลาในการค้นหาลงเหลือครึ่งหนึ่งของการค้นหาเชิงเส้นตามที่พบในอาร์เรย์ ดังนั้น ต้นไม้การค้นหาแบบไบนารี ในโครงสร้างข้อมูล จึงเหมาะสำหรับการค้นหาและการเรียงลำดับเมื่อเทียบกับ ADT อื่นๆ
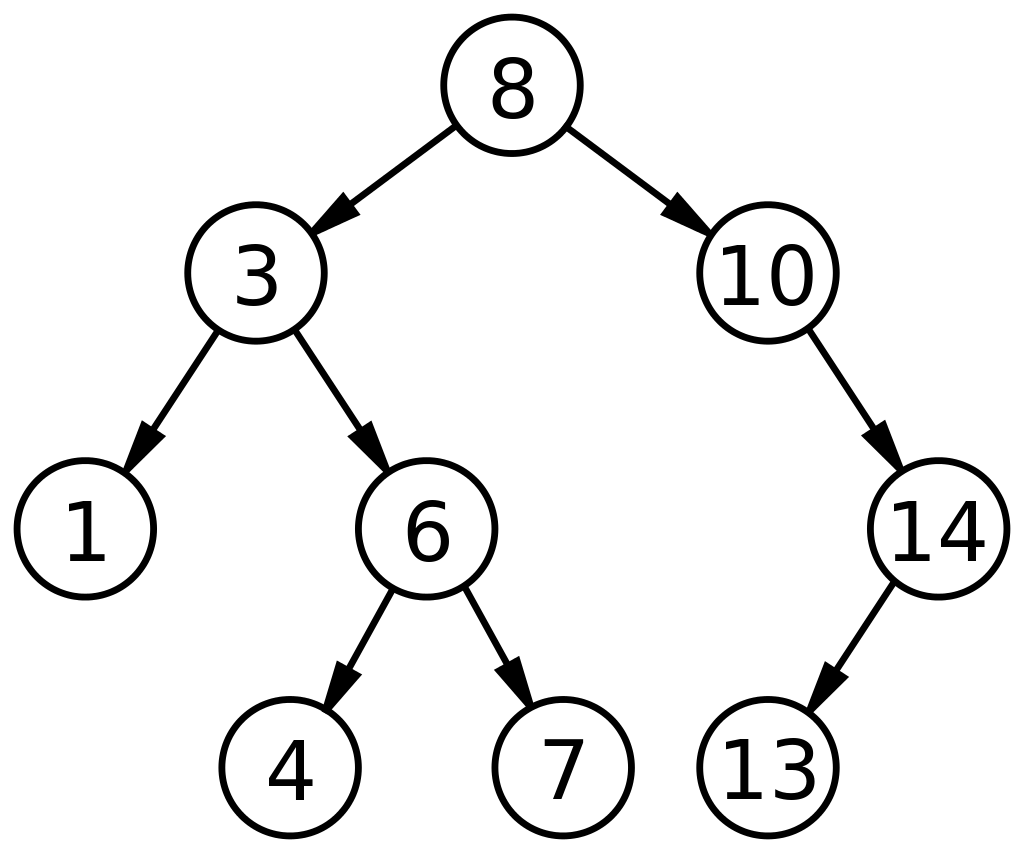
แหล่งที่มา
แม้ว่าทั้ง BT และ BST จะเป็น ต้นไม้ในโครงสร้างข้อมูล แต่อย่าสับสนกับความคล้ายคลึงกันในชื่อ ดูรายละเอียดความ แตกต่างระหว่างไบนารีทรีและทรีการค้นหาไบนารี ได้ที่ upGrad
4. AVL Tree
ต้นไม้ AVL ได้ชื่อมาจากผู้ประดิษฐ์: Adelson-Velsky และ Landis ต้นไม้ AVL มีลักษณะที่สมดุลในตัวเอง ความสูงของต้นไม้ย่อยสองต้นของโหนดรากนั้นจำกัดให้น้อยกว่าสองต้น เมื่อความแตกต่างของความสูงเพิ่มขึ้นมากกว่า 1 โหนดย่อยจะถูกปรับสมดุล
ต้นไม้ AVL มีความสูงสมดุล และการปรับสมดุลนี้เกิดขึ้นผ่านการหมุนเดี่ยวหรือสองครั้ง ปัจจัยการปรับสมดุลคือความแตกต่างระหว่างความสูงของทรีย่อยด้านซ้ายและแผนผังย่อยด้านขวา และค่าคือ -1, 0, และ 1
5. ต้นดำแดง
ประเภทนี้คล้ายกับต้นไม้ AVL เนื่องจากต้นไม้สีดำสีแดงมีความสูงที่สมดุลเช่นกัน สิ่งที่แยกจากกันคือไม่ต้องใช้การหมุนมากกว่าสองครั้งเพื่อให้สมดุล มีบิตพิเศษที่กำหนดสีแดงหรือสีดำของโหนด ซึ่งช่วยให้มั่นใจว่าต้นไม้มีความสมดุลในระหว่างการลบและการแทรก รหัสสีแดงดำยังถูกทาสีใหม่ระหว่างการเปลี่ยนแปลง แต่แทบไม่ต้องเสียค่าหน่วยความจำเพิ่มเลย

6. Splay Tree
ชนิดย่อยอื่นของแผนผังการค้นหาแบบไบนารี คือ สเพลย์ทรี มีคุณสมบัติเฉพาะของการดำเนินการหมุนเพื่อปรับโหนดล่าสุด โหนดที่เข้าถึงล่าสุดจะถูกจัดเรียงเป็นโหนดรูทโดยทำการหมุน เป็นต้นไม้ที่มีความสมดุล แต่ไม่ใช่ต้นไม้ที่มีความสูงสมดุล
การกระทำของ 'splaying' จะดำเนินการหลังจากการค้นหาไบนารีทรีเริ่มต้น เนื่องจากการหมุนของต้นไม้จะดำเนินการในลักษณะเฉพาะ หลังจากดำเนินการทุกครั้ง ต้นไม้จะหมุนเพื่อปรับสมดุล และองค์ประกอบที่ค้นหาจะถูกจัดเรียงไว้ที่ด้านบนสุดเป็นโหนดราก
7. ทรีป
'Treaps' ในโครงสร้างข้อมูลเป็นการรวมกันของต้นไม้และกอง ใน BST ค่าของชายด์ด้านซ้ายต้องน้อยกว่าโหนดรูท และค่าของชายด์ที่ถูกต้องจะต้องสูงกว่า ในโครงสร้างข้อมูลแบบฮีป โหนดรูทมีค่าต่ำสุด และโหนดย่อย (ทั้งซ้ายและขวา) มีค่ามากกว่า
ดังนั้น treap จะเก็บค่าในรูปแบบของคีย์ (คล้ายกับ BST) และลำดับความสำคัญ (เช่น heaps) โหนดที่มีลำดับความสำคัญสูงสุดจะถูกแทรกก่อนในทรีการค้นหาแบบไบนารีในลักษณะที่หมายเลขลำดับความสำคัญเป็นตัวเลขสุ่มที่เป็นอิสระ พวกเขารักษาชุดของคีย์ที่เรียงลำดับแบบไดนามิกและอนุญาตให้ค้นหาแบบไบนารีภายในคีย์ของพวกเขา
8. บี-ทรี
ในฐานะที่เป็นต้นไม้ที่สร้างสมดุลในตัวเองในโครงสร้างข้อมูล B-Tree จะจัดเรียงข้อมูลเพื่อให้สามารถค้นหา เข้าถึงตามลำดับ ลบ และแทรกได้ในเวลาลอการิทึม B-tree ต่างจากไบนารีทรีตรงที่อนุญาตให้โหนดมีลูกมากกว่าสองคน เข้ากันได้กับฐานข้อมูลและระบบไฟล์ที่อ่านและเขียนบล็อกข้อมูลขนาดใหญ่
โครงสร้างข้อมูล B-tree ใช้สำหรับระบบจัดเก็บข้อมูลขนาดใหญ่ เช่น ดิสก์ ใบทั้งหมดไม่มีข้อมูลและปรากฏอยู่ในระดับเดียวกัน โหนดภายในของ B-tree สามารถมีขนาดตัวแปรของโหนดย่อยที่ถูกผูกไว้ด้วยช่วง
สิ่งเหล่านี้คือ ต้นไม้ในโครงสร้างข้อมูล ซึ่งใช้งานโดยโปรแกรมเมอร์ที่ออกแบบการไหลของข้อมูล การเรียนรู้ลักษณะเฉพาะและการประยุกต์ใช้งานเป็นสิ่งสำคัญต่อเส้นทางสู่การเป็นนักวิทยาศาสตร์ข้อมูล อีกวิธีหนึ่งในการเพิ่มทักษะให้กับตัวเองคือการฝึกผ่านโครงการต่างๆ ที่ต้องใช้ความรู้เกี่ยวกับ ต้นไม้ในโครงสร้างข้อมูล และรูปแบบอื่นๆ ของ ADT
เพื่อนำความรู้ของคุณไปใช้กับโปรเจ็กต์ DS ลิงก์บล็อกต่อไปนี้มี แนวคิดและหัวข้อเกี่ยวกับโครงสร้างข้อมูลที่น่าสนใจ 13 รายการสำหรับผู้เริ่มต้น [2021 ]
บทสรุป
การเรียนรู้เกี่ยวกับแนวคิด เช่น ต้นไม้ในโครงสร้างข้อมูลอาจเป็นเรื่องยาก และผู้ที่สนใจในการเขียนโปรแกรมต้องการคำแนะนำจากผู้เชี่ยวชาญในการให้ความรู้ด้วยตนเอง หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับต้นไม้ในโครงสร้างข้อมูล โปรดดูหลักสูตรออนไลน์ โดย upGrad Executive PG Program in Software Development – ความเชี่ยวชาญใน DevOps ด้วย DevOps โดย IIIT-B & upGrad สามารถช่วยคุณสร้างอาชีพของคุณในฐานะโปรแกรมเมอร์
เนื่องจากความชำนาญของโครงสร้างข้อมูลเป็นส่วนสำคัญในกระบวนการเขียนโค้ด จึงช่วยให้นักเรียนกลายเป็นโปรแกรมเมอร์ผู้เชี่ยวชาญและนักพัฒนาซอฟต์แวร์ได้ โปรแกรมเมอร์และนักวิทยาศาสตร์ด้านข้อมูลจำเป็นต้องเป็นที่ต้องการสำหรับทศวรรษ หน้า
เรามีผู้ใช้อินเทอร์เน็ต 500 ล้านคนในอินเดีย สร้างและใช้ข้อมูลปริมาณมาก ซึ่งต้องใช้นักวิทยาศาสตร์ข้อมูลหลายพันคนเพื่อตอบสนองความต้องการ [2] นักวิทยาศาสตร์ด้านข้อมูลเหล่านี้ต้องการการศึกษาที่เหมาะสม พร้อมความเชี่ยวชาญด้านเทคโนโลยีที่เกี่ยวข้อง เพื่อหางานทำในภาคส่วนนี้
โปรแกรม PG สำหรับ ผู้ บริหารด้านการพัฒนาซอฟต์แวร์ - ความเชี่ยวชาญพิเศษด้านการพัฒนาแบบครบวงจร ดูแลจัดการโดย upGrad และ IIIT-บังกาลอร์ สามารถช่วยเหลือคุณในการปรับปรุงโปรไฟล์ของคุณและจัดหาโอกาสการจ้างงานที่ดีขึ้นในฐานะโปรแกรมเมอร์
- โครงสร้างการค้นหาเป็นโครงสร้างข้อมูลที่ใช้เพื่อค้นหาคีย์บางอย่างภายในชุดข้อมูล คีย์ของแต่ละโหนดต้องใหญ่กว่าคีย์ใดๆ ในทรีย่อยทางด้านซ้าย แต่น้อยกว่าคีย์ในทรีย่อยทางด้านขวาเพื่อให้ทรีทำหน้าที่เป็นทรีการค้นหา ข้อมูลแบบลำดับชั้น เช่น โครงสร้างโฟลเดอร์ โครงสร้างองค์กร และข้อมูล XML/HTML ควรเก็บไว้ในแผนผัง ต้นไม้ไบนารีที่สมบูรณ์แบบเป็นต้นไม้ที่โหนดภายในทุกโหนดมีลูกสองคนและใบไม้ทุกใบมีความลึกหรือระดับเท่ากัน แผนภูมิบรรพบุรุษ (ไม่ร่วมประเวณีระหว่างพี่น้อง) ของบุคคลในระดับความลึกเฉพาะเป็นตัวอย่างของต้นไม้ไบนารีที่สมบูรณ์แบบเนื่องจากแต่ละคนมีพ่อแม่ทางสายเลือดสองคน (แม่และพ่อ)ต้นไม้ชนิดใดที่ใช้ค้นหาได้?<br />
- เมื่อต้นไม้มีความสมดุล กล่าวคือ ใบไม้ที่ปลายทั้งสองมีความลึกเท่ากัน ต้นไม้ที่ค้นหามีข้อได้เปรียบในแง่ของเวลาในการค้นหา มีโครงสร้างข้อมูลโครงสร้างการค้นหาที่หลากหลาย ซึ่งบางโครงสร้างช่วยให้สามารถแทรกและลบองค์ประกอบได้อย่างมีประสิทธิภาพ ซึ่งการกระทำจะต้องรักษาสมดุลของต้นไม้ไว้
- อาร์เรย์ที่เชื่อมโยงมักใช้งานโดยใช้แผนผังการค้นหา อัลกอริทึมแผนผังการค้นหาจะระบุตำแหน่งโดยใช้คีย์จากคู่คีย์-ค่า จากนั้นแอปพลิเคชันจะจัดเก็บคู่คีย์-ค่าทั้งหมดไว้ที่ตำแหน่งนั้น
- ต้นไม้ค้นหาไบนารี, ต้นไม้ B, (a, b) - ต้นไม้และต้นไม้การค้นหาแบบสามชั้นเป็นตัวอย่างของการค้นหาต้นไม้ การใช้งานหลักของโครงสร้างข้อมูลต้นไม้คืออะไร?
1. Binary Search Tree เป็นแผนผังที่ช่วยให้คุณสามารถค้นหา แทรก และลบข้อมูลที่จัดเรียงได้อย่างรวดเร็ว นอกจากนี้ยังช่วยให้คุณค้นหารายการที่อยู่ใกล้คุณที่สุด
2. Heap เป็นโครงสร้างข้อมูลแบบทรีที่ใช้อาร์เรย์และใช้เพื่อสร้างลำดับความสำคัญของคิว
3. B-Tree และ B+ Tree เป็นแผนผังการสร้างดัชนีสองประเภทที่ใช้ในฐานข้อมูล
4. คอมไพเลอร์ใช้แผนผังไวยากรณ์
5. ต้นไม้แบ่งพื้นที่ที่ใช้จัดระเบียบจุดในพื้นที่มิติ K เรียกว่า KD Tree
6. Trie เป็นโครงสร้างข้อมูลที่ใช้สร้างพจนานุกรมที่มีการค้นหาคำนำหน้า
7. Suffix Tree ใช้สำหรับค้นหารูปแบบในข้อความคงที่อย่างรวดเร็ว
8. ในเครือข่ายคอมพิวเตอร์ เราเตอร์และบริดจ์ใช้ต้นไม้ที่ทอดข้ามต้นไม้และต้นไม้ที่มีเส้นทางที่สั้นที่สุดตามลำดับ ต้นไม้ที่สมบูรณ์แบบคืออะไร?