
คำถามและคำตอบสัมภาษณ์ Hadoop 15 อันดับแรกในปี 2022
เผยแพร่แล้ว: 2021-01-09ด้วยการวิเคราะห์ข้อมูลที่ได้รับโมเมนตัม ความต้องการบุคลากรที่ดีในการจัดการ Big Data จึงเพิ่มขึ้นอย่างรวดเร็ว จากนักวิเคราะห์ข้อมูลไปจนถึงนักวิทยาศาสตร์ด้านข้อมูล Big Data กำลังสร้างอาร์เรย์ของโปรไฟล์งานในปัจจุบัน สิ่งแรกและสำคัญที่สุดที่คุณคาดหวังให้ลงมือทำคือ Hadoop
ไม่ว่าบทบาท/โปรไฟล์งานใด คุณอาจจะกำลังทำงานบน Hadoop ไม่ทางใดก็ทางหนึ่ง ดังนั้น คุณสามารถคาดหวังให้ผู้สัมภาษณ์ยิง Hadoop สองสามคำถามในแบบของคุณอย่างสม่ำเสมอ
สำหรับสิ่งนั้นและอื่น ๆ ให้เราดูคำถามสัมภาษณ์ 15 คำถามยอดนิยมของ Hadoop ที่คุณสามารถคาดหวังได้ในการสัมภาษณ์ใด ๆ ที่คุณเข้าร่วม
Hadoop คืออะไร? Hadoop ส่วนประกอบหลักคืออะไร?
Hadoop เป็นโครงสร้างพื้นฐานที่มีเครื่องมือและบริการที่เกี่ยวข้องซึ่งจำเป็นในการประมวลผลและจัดเก็บข้อมูลขนาดใหญ่ เพื่อความชัดเจน Hadoop คือ 'โซลูชัน' สำหรับความท้าทายของ Big Data นอกจากนี้ กรอบงาน Hadoop ยังช่วยให้องค์กรสามารถวิเคราะห์ Big Data และตัดสินใจทางธุรกิจได้ดีขึ้น
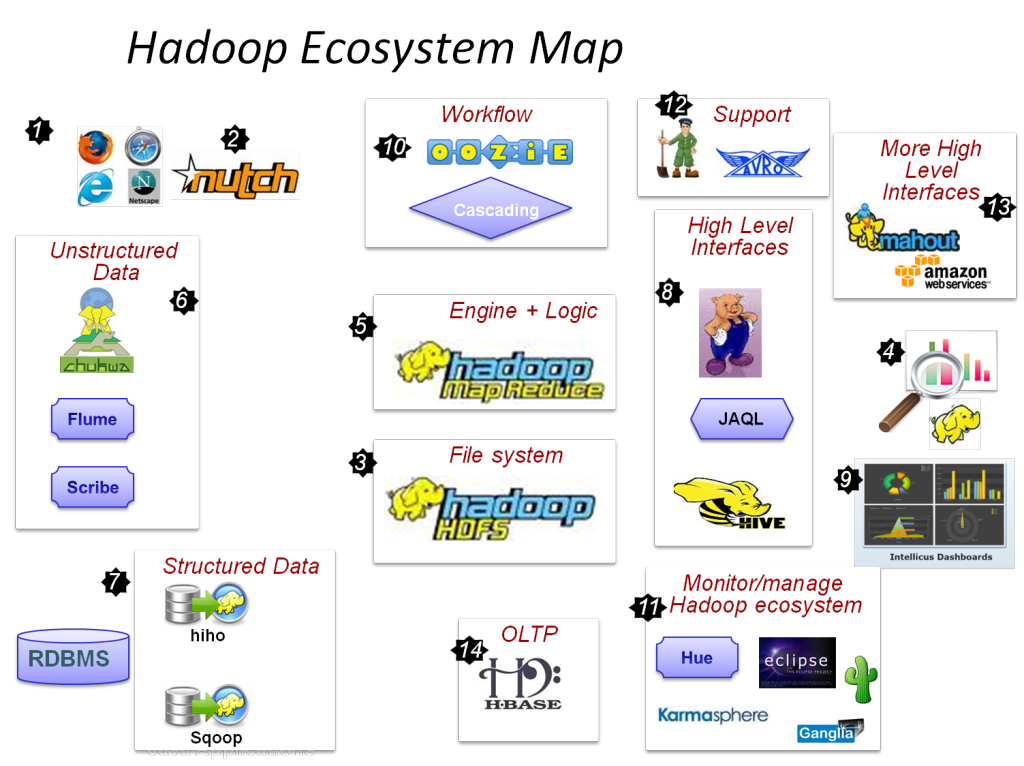
องค์ประกอบหลักของ Hadoop คือ:
- HDFS
- Hadoop MapReduce
- Hadoop Common
- เส้นด้าย
- PIG and HIVE – ส่วนประกอบการเข้าถึงข้อมูล
- HBase – สำหรับการจัดเก็บข้อมูล
- Ambari, Oozie และ ZooKeeper – ส่วนประกอบการจัดการและตรวจสอบข้อมูล
- Thrift and Avro – ส่วนประกอบการทำให้เป็นอนุกรมของข้อมูล
- Apache Flume, Sqoop, Chukwa – ส่วนประกอบการรวมข้อมูล
- Apache Mahout and Drill – ส่วนประกอบข่าวกรองข้อมูล
แนวคิดหลักของเฟรมเวิร์ก Hadoop คืออะไร
Hadoop มีพื้นฐานมาจากแนวคิดหลักสองประการ พวกเขาเป็น:
- HDFS: HDFS หรือ Hadoop Distributed File System เป็นระบบไฟล์ที่ใช้ Java ที่เชื่อถือได้ซึ่งใช้สำหรับจัดเก็บชุดข้อมูลจำนวนมากในรูปแบบบล็อก สถาปัตยกรรม Master-Slave ให้พลังแก่มัน
- MapReduce: MapReduce เป็นโครงสร้างการเขียนโปรแกรมที่ช่วยประมวลผลชุดข้อมูลขนาดใหญ่ ฟังก์ชันนี้แบ่งออกเป็นสองส่วนเพิ่มเติม - ในขณะที่ 'map' แยกชุดข้อมูลออกเป็น tuples 'reduce' ใช้ tuples ของแผนที่และสร้างการรวมกันของ tuples ที่มีขนาดเล็กลง
ตั้งชื่อรูปแบบอินพุตที่พบบ่อยที่สุดใน Hadoop หรือไม่
มีรูปแบบอินพุตทั่วไปสามรูปแบบใน Hadoop:
- รูปแบบการป้อนข้อความ: นี่คือรูปแบบการป้อนข้อมูลเริ่มต้นใน Hadoop
- รูปแบบอินพุตไฟล์ตามลำดับ: รูปแบบอินพุตนี้ใช้สำหรับอ่านไฟล์ตามลำดับ
- รูปแบบการป้อนค่าคีย์: ใช้เพื่ออ่านไฟล์ข้อความธรรมดา
เส้นด้ายคืออะไร?
YARN เป็นตัวย่อของ Yet Another Resource Negotiator เป็นเฟรมเวิร์กการประมวลผลข้อมูลของ Hadoop ที่จัดการทรัพยากรข้อมูลและสร้างสภาพแวดล้อมสำหรับการประมวลผลที่ประสบความสำเร็จ 
“Rack Awareness” คืออะไร?
“Rack Awareness” เป็นอัลกอริธึมที่ NameNode ใช้ในการกำหนดรูปแบบที่บล็อคข้อมูลและแบบจำลองของพวกเขาถูกจัดเก็บไว้ในคลัสเตอร์ Hadoop สิ่งนี้ทำได้ด้วยความช่วยเหลือของคำจำกัดความของชั้นวางที่ลดความแออัดระหว่างโหนดข้อมูลที่อยู่ในชั้นวางเดียวกัน

NameNodes ที่ใช้งานอยู่และแบบพาสซีฟคืออะไร?
ระบบ Hadoop ที่มีความพร้อมใช้งานสูงมักประกอบด้วย NameNodes สองรายการ – Active NameNode และ Passive NameNode
NameNode ที่รันคลัสเตอร์ Hadoop เรียกว่า Active NameNode และ NameNode สแตนด์บายที่เก็บข้อมูลของ Active NameNode คือ Passive NameNode
จุดประสงค์ของการมีสอง NameNodes คือถ้า Active NameNode ขัดข้อง Passive NameNode สามารถเป็นผู้นำได้ ดังนั้น NameNode จะทำงานอยู่ในคลัสเตอร์เสมอ และระบบไม่เคยล้มเหลว
ตัวกำหนดตารางเวลาที่แตกต่างกันในเฟรมเวิร์ก Hadoop คืออะไร
มีตัวกำหนดตารางเวลาที่แตกต่างกันสามตัวในเฟรมเวิร์ก Hadoop:
- COSHH – COSHH ช่วยจัดกำหนดการการตัดสินใจโดยการตรวจสอบคลัสเตอร์และปริมาณงานรวมกับความแตกต่าง
- FIFO Scheduler – FIFO จัดเรียงงานในคิวตามเวลาที่มาถึงโดยไม่ต้องใช้ความแตกต่าง
- การแบ่งปันที่ยุติธรรม – การแบ่งปันที่ยุติธรรมสร้างกลุ่มสำหรับผู้ใช้แต่ละรายที่มีแผนที่หลายฉบับ และลดช่องว่างในทรัพยากรที่พวกเขาสามารถใช้เพื่อดำเนินงานเฉพาะ
การดำเนินการเก็งกำไรคืออะไร?
บ่อยครั้งในเฟรมเวิร์ก Hadoop บางโหนดอาจทำงานช้ากว่าที่เหลือ นี้มีแนวโน้มที่จะจำกัดโปรแกรมทั้งหมด เพื่อแก้ปัญหานี้ Hadoop ตรวจพบหรือ 'คาดเดา' ก่อนเมื่องานทำงานช้ากว่าปกติ จากนั้นจึงเปิดการสำรองข้อมูลที่เทียบเท่าสำหรับงานนั้น ดังนั้น ในกระบวนการนี้ โหนดหลักจะดำเนินการทั้งงานพร้อมกัน และงานใดเสร็จสิ้นก่อนจะได้รับการยอมรับในขณะที่อีกงานหนึ่งถูกฆ่า คุณลักษณะการสำรองข้อมูลของ Hadoop นี้เรียกว่า Speculative Execution

ตั้งชื่อส่วนประกอบหลักของ Apache HBase หรือไม่
Apache HBase ประกอบด้วยสามองค์ประกอบ:
- เซิร์ฟเวอร์ภูมิภาค: หลังจากที่ตารางถูกแบ่งออกเป็นหลายภูมิภาค กลุ่มของภูมิภาคเหล่านี้จะถูกส่งต่อไปยังไคลเอนต์ผ่านเซิร์ฟเวอร์ภูมิภาค
- HMaster: นี่คือเครื่องมือที่ช่วยจัดการและประสานงานกับเซิร์ฟเวอร์ภูมิภาค
- ZooKeeper: ZooKeeper เป็นผู้ประสานงานภายในสภาพแวดล้อมแบบกระจายของ HBase ช่วยรักษาสถานะเซิร์ฟเวอร์ภายในคลัสเตอร์ผ่านการสื่อสารในเซสชัน
“จุดตรวจ” คืออะไร? ประโยชน์ของมันคืออะไร?
Checkpointing หมายถึงขั้นตอนที่รวมบันทึก FsImage และ Edit เข้าด้วยกันเพื่อสร้าง FsImage ใหม่ ดังนั้น แทนที่จะเล่นบันทึกการแก้ไขซ้ำ NameNode สามารถโหลดสถานะในหน่วยความจำสุดท้ายจาก FsImage ได้โดยตรง NameNode สำรองมีหน้าที่รับผิดชอบในกระบวนการนี้
ประโยชน์ที่ Checkpointing มอบให้คือช่วยลดเวลาเริ่มต้นของ NameNode ซึ่งจะทำให้กระบวนการทั้งหมดมีประสิทธิภาพมากขึ้น
การประยุกต์ใช้ Big Data ใน Pop-Culture
จะดีบักโค้ด Hadoop ได้อย่างไร
ในการดีบักโค้ด Hadoop ก่อนอื่น คุณต้องตรวจสอบรายการงาน MapReduce ที่กำลังทำงานอยู่ จากนั้นคุณต้องตรวจสอบว่างานที่กำพร้าทำงานพร้อมกันหรือไม่ ถ้าใช่ คุณต้องค้นหาตำแหน่งของบันทึกของตัวจัดการทรัพยากรโดยทำตามขั้นตอนง่าย ๆ เหล่านี้:
เรียกใช้ “ps –ef | grep –I ResourceManager” และในผลลัพธ์ที่แสดง ให้ลองค้นหาว่ามีข้อผิดพลาดที่เกี่ยวข้องกับรหัสงานเฉพาะหรือไม่
ตอนนี้ ระบุโหนดผู้ปฏิบัติงานที่ใช้ในการดำเนินงาน ล็อกอินเข้าสู่โหนดและเรียกใช้ “ps –ef | grep –iNodeManager”
สุดท้าย ตรวจสอบบันทึก Node Manager ข้อผิดพลาดส่วนใหญ่เกิดจากบันทึกระดับผู้ใช้สำหรับงานลดแผนที่แต่ละงาน
จุดประสงค์ของ RecordReader ใน Hadoop คืออะไร?
Hadoop แบ่งข้อมูลออกเป็นรูปแบบบล็อก RecordReader ช่วยรวมบล็อคข้อมูลเหล่านี้ไว้ในเรกคอร์ดเดียวที่สามารถอ่านได้ ตัวอย่างเช่น หากข้อมูลที่ป้อนถูกแบ่งออกเป็นสองช่วงตึก –
แถวที่ 1 – ยินดีต้อนรับสู่
แถวที่ 2 – UpGrad
RecordReader จะอ่านข้อความนี้ว่า "ยินดีต้อนรับสู่ UpG rad"
โหมดใดบ้างที่ Hadoop สามารถทำงานได้?
โหมดที่ Hadoop สามารถทำงานได้คือ:
- โหมดสแตนด์อโลน – นี่คือโหมดเริ่มต้นของ Hadoop ที่ใช้สำหรับการดีบัก ไม่รองรับ HDFS
- โหมดกระจายหลอก – โหมดนี้จำเป็นต้องมีการกำหนดค่าไฟล์ mapred-site.xml, core-site.xml และ hdfs-site.xml ทั้ง Master และ Slave Node เหมือนกันที่นี่
- โหมดกระจายอย่างเต็มที่ – โหมดกระจายอย่างเต็มที่คือขั้นตอนการผลิตของ Hadoop ซึ่งข้อมูลจะถูกกระจายไปทั่วโหนดต่างๆ บนคลัสเตอร์ Hadoop ที่นี่ Master และ Slave Nodes ได้รับการจัดสรรแยกกัน
ตั้งชื่อแอปพลิเคชันที่ใช้งานได้จริงของ Hadoop
ต่อไปนี้คือตัวอย่างบางส่วนในชีวิตจริงที่ Hadoop กำลังสร้างความแตกต่าง :
- การจัดการการจราจรบนถนน
- การตรวจจับและป้องกันการฉ้อโกง
- วิเคราะห์ข้อมูลลูกค้าแบบเรียลไทม์เพื่อปรับปรุงการบริการลูกค้า
- การเข้าถึงข้อมูลทางการแพทย์ที่ไม่มีโครงสร้างจากแพทย์ HCP ฯลฯ เพื่อปรับปรุงบริการด้านสุขภาพ
อะไรคือเครื่องมือ Hadoop ที่สำคัญที่สามารถปรับปรุงประสิทธิภาพของ Big Data ได้?
เครื่องมือ Hadoop ที่ช่วยเพิ่มประสิทธิภาพ Big Data ได้อย่างมากคือ

• ไฮฟ์
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• เมฆ
• รว์
• ฟลูม
• ZooKeeper
วิศวกรข้อมูลขนาดใหญ่: ตำนานกับความเป็นจริง
บทสรุป
คำถามสัมภาษณ์ Hadoop เหล่านี้น่าจะช่วยคุณได้ดีในการสัมภาษณ์ครั้งต่อไป แม้ว่าบางครั้งผู้สัมภาษณ์จะมีแนวโน้มที่จะบิดเบือนคำถามสัมภาษณ์ของ Hadoop แต่ก็ไม่ควรเป็นปัญหาสำหรับคุณหากคุณมีพื้นฐานที่จัดเรียงไว้
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ