
คณิตศาสตร์เบื้องหลังการเรียนรู้ของเครื่อง: สิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2021-03-10แมชชีนเลิร์นนิงเป็นแผนกหนึ่งของ AI ที่เน้นการสร้างแอปพลิเคชันโดยการประมวลผลข้อมูลที่มีอยู่อย่างถูกต้อง จุดมุ่งหมายหลักของการเรียนรู้ของเครื่องคือการช่วยให้คอมพิวเตอร์ประมวลผลการคำนวณโดยปราศจากการแทรกแซงของมนุษย์ สิ่งนี้เกิดขึ้นได้โดยการอนุญาตให้เครื่องเรียนรู้ที่จะเลียนแบบสติปัญญาของมนุษย์ผ่านวิธีการเรียนรู้ที่มีผู้ดูแลหรือไม่มีผู้ดูแล
การเรียนรู้ของเครื่องเป็นการรวมกันของหลายสาขา ซึ่งรวมถึงสถิติ ความน่าจะเป็น พีชคณิตเชิงเส้น แคลคูลัส และอื่นๆ โดยอิงจากรูปแบบการเรียนรู้ของเครื่องที่สามารถสร้างหรือป้อนอัลกอริธึมเพื่อด้นสดตามสติปัญญาของมนุษย์ ยิ่งแอปพลิเคชันซับซ้อนมากเท่าไร อัลกอริทึมก็จะยิ่งซับซ้อนมากขึ้นเท่านั้น
ตั้งแต่ผู้ช่วยดิจิทัล และอุปกรณ์อัจฉริยะไปจนถึงเว็บไซต์ที่แนะนำผลิตภัณฑ์โปรดของคุณโดยอิงจากกิจกรรมออนไลน์ของคุณ และโทรศัพท์มือถือที่แจ้งให้คุณทราบเกี่ยวกับตารางเที่ยวบินของคุณ ผลิตภัณฑ์และเครื่องมือที่ใช้การเรียนรู้ด้วยเครื่องอยู่รอบตัวเรา ในขณะที่การพึ่งพาอุปกรณ์อัจฉริยะและเครื่องใช้ของเราเพิ่มขึ้น ความจำเป็นในการใช้การเรียนรู้ของเครื่องก็จะเพิ่มขึ้นเช่นกัน
ด้วยเหตุนี้ ในบทความนี้ เราจะสำรวจแนวคิดทางคณิตศาสตร์ที่จำเป็นในการเขียนอัลกอริธึมการเรียนรู้ของเครื่องและนำไปใช้
สารบัญ
ความสำคัญของคณิตศาสตร์ในการเรียนรู้ของเครื่องคืออะไร?
แอปพลิเคชันการเรียนรู้ของเครื่องให้การวิเคราะห์และข้อมูลเชิงลึกที่รวบรวมจากข้อมูลที่มีอยู่ซึ่งนำไปสู่การตัดสินใจที่นำไปปฏิบัติได้จริงในธุรกิจ เนื่องจากแมชชีนเลิร์นนิงเกี่ยวข้องกับการศึกษาและการนำอัลกอริทึมไปใช้ สิ่งสำคัญคือต้องเสริมทักษะทางคณิตศาสตร์ของคุณ ช่วยในการขจัดความไม่แน่นอนและคาดการณ์ค่าข้อมูลได้อย่างแม่นยำซึ่งเกี่ยวข้องกับพารามิเตอร์และคุณลักษณะของข้อมูลที่ซับซ้อน นอกจากนี้ยังช่วยให้เราเข้าใจการแลกเปลี่ยนความแปรปรวนอคติได้ดีขึ้น
การเรียนรู้ด้วยเครื่องแมชชีนเลิ ร์นนิง ต้องการความรู้เกี่ยวกับ แนวคิดทางคณิตศาสตร์ เช่น พีชคณิตเชิงเส้น แคลคูลัสเวกเตอร์ เรขาคณิตวิเคราะห์ การสลายตัวของเมทริกซ์ ความน่าจะเป็น และสถิติ ความเข้าใจอย่างถ่องแท้เหล่านี้ช่วยในการสร้างแอปพลิเคชันการเรียนรู้ของเครื่องที่ใช้งานง่าย

พีชคณิตเชิงเส้น
พีชคณิตเชิงเส้นเกี่ยวข้องกับเวกเตอร์และเมทริกซ์ และส่วนใหญ่หมุนรอบการคำนวณ มีบทบาทสำคัญในการเรียนรู้ของเครื่องและเทคนิคการเรียนรู้เชิงลึก ตาม Skyler Speakman มันคือคณิตศาสตร์ของศตวรรษที่ 21
โดยปกติแล้ว วิศวกร ML และนักวิทยาศาสตร์ข้อมูลหรือนักวิจัยจะใช้พีชคณิตเชิงเส้นเพื่อสร้างอัลกอริธึมเชิงเส้น การถดถอยโลจิสติก แผนผังการตัดสินใจ และเวกเตอร์เครื่องสนับสนุน
แคลคูลัส
แคลคูลัสขับเคลื่อนอัลกอริธึมการเรียนรู้ของเครื่อง หากปราศจากความรู้เกี่ยวกับแนวคิด จะไม่สามารถคาดการณ์ผลลัพธ์โดยใช้ชุดข้อมูลที่กำหนดได้ แคลคูลัสช่วยวิเคราะห์อัตราที่ปริมาณเปลี่ยนแปลง และเกี่ยวข้องกับประสิทธิภาพสูงสุดของอัลกอริธึมการเรียนรู้ของเครื่อง การบูรณาการ ดิฟเฟอเรนเชียล ลิมิต และอนุพันธ์เป็นแนวคิดบางประการของแคลคูลัสที่ช่วยฝึกโครงข่ายประสาทเทียมในระดับลึก
ความน่าจะเป็น
ความน่าจะเป็นในแมชชีนเลิร์นนิงทำนายชุดของผลลัพธ์ ในขณะที่สถิติผลักดันผลลัพธ์ที่น่าพอใจไปสู่ข้อสรุป เหตุการณ์อาจง่ายเหมือนการโยนเหรียญ ความน่าจะเป็นสามารถแบ่งออกเป็นสองประเภท: ความน่าจะเป็นแบบมีเงื่อนไขและความน่าจะเป็นร่วม ความน่าจะเป็นร่วมกันเกิดขึ้นเมื่อเหตุการณ์ไม่สัมพันธ์กัน ในขณะที่ความน่าจะเป็นแบบมีเงื่อนไขเกิดขึ้นเมื่อเหตุการณ์หนึ่งแทนที่อีกเหตุการณ์หนึ่ง
สถิติ
สถิติมุ่งเน้นไปที่แง่มุมเชิงปริมาณและคุณภาพของอัลกอริทึม ช่วยให้เราระบุเป้าหมายและแปลงข้อมูลที่เก็บรวบรวมเป็นการสังเกตที่แม่นยำโดยนำเสนออย่างกระชับ สถิติในการเรียนรู้ของเครื่องจะเน้นที่สถิติเชิงพรรณนาและสถิติเชิงอนุมาน
สถิติเชิงพรรณนาเกี่ยวข้องกับการอธิบายและสรุปชุดข้อมูลขนาดเล็กที่โมเดลกำลังทำงานอยู่ วิธีการที่ใช้ในที่นี้คือ ค่าเฉลี่ย ค่ามัธยฐาน โหมด ค่าเบี่ยงเบนมาตรฐาน และการแปรผัน ผลลัพธ์สุดท้ายจะถูกนำเสนอเป็นภาพแทน
สถิติอนุมานเกี่ยวข้องกับการแยกข้อมูลเชิงลึกจากตัวอย่างที่กำหนดในขณะที่ทำงานกับชุดข้อมูลขนาดใหญ่ สถิติเชิงอนุมานทำให้เครื่องสามารถวิเคราะห์ข้อมูลที่อยู่นอกเหนือขอบเขตของข้อมูลที่ให้มา การทดสอบสมมติฐาน การแจกแจงตัวอย่าง การวิเคราะห์ความแปรปรวน เป็นบางแง่มุมของสถิติอนุมาน
นอกเหนือจากนี้ ความสามารถในการเขียนโค้ดยังเป็นข้อกำหนดเบื้องต้นที่สำคัญสำหรับแมชชีนเลิร์นนิง ความเชี่ยวชาญในภาษาต่างๆ เช่น Python และ Java ช่วยให้เข้าใจการสร้างแบบจำลองข้อมูลได้ดีขึ้น การจัดรูปแบบสตริง การกำหนดฟังก์ชัน การวนซ้ำที่มีตัววนซ้ำหลายตัวแปร ถ้าหรืออย่างอื่น นิพจน์เงื่อนไขเป็นฟังก์ชันพื้นฐานบางส่วน
สำหรับการสร้างแบบจำลองข้อมูล เป็นกระบวนการที่เราประเมินโครงสร้างของชุดข้อมูลและตรวจหารูปแบบและรูปแบบที่เป็นไปได้ เพื่อให้สามารถทำนายได้อย่างแม่นยำ เราจะต้องตระหนักถึงคุณสมบัติต่างๆ ของข้อมูลส่วนรวม
คุณจะเรียนรู้แมชชีนเลิร์นนิงได้อย่างไร
แม้ว่าแมชชีนเลิร์นนิงจะเป็นสาขาที่ทำกำไรได้ แต่ก็ต้องอาศัยการฝึกฝนและความอดทนเป็นอย่างมาก ด้วยการใช้งานในเกือบทุกอุตสาหกรรมในปัจจุบัน วิศวกรแมชชีนเลิร์นนิ่งเป็นที่ต้องการอย่างมาก
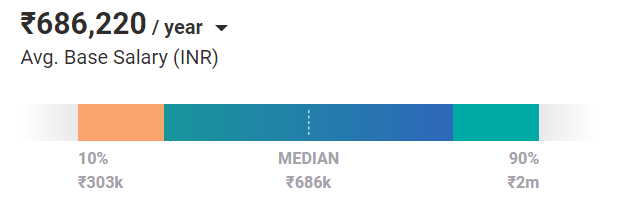
เงินเดือน เฉลี่ยของวิศวกรระดับเริ่มต้น ที่มีพื้นฐานการเรียนรู้ด้วยเครื่องคือ 686k / ปี และด้วยประสบการณ์และทักษะที่เพิ่มขึ้น ศักยภาพในการได้รับเงินเดือนที่สูงขึ้นก็เพิ่มขึ้นอย่างทวีคูณ
มีหลายหลักสูตรสำหรับผู้ที่ประสงค์จะเพิ่มฐานความรู้ในการเรียนรู้ของเครื่อง คุณต้องใช้เวลาอย่างน้อย 6 เดือนถึง 2 ปีในการเรียนรู้เรื่องนี้
ด้วยวุฒิการศึกษาขั้นต่ำปริญญาตรีและประสบการณ์การทำงานหนึ่งปี ยิ่งไปกว่านั้นคือปริญญาทางคณิตศาสตร์หรือสถิติ คุณสามารถเรียนหลักสูตรใดหลักสูตรหนึ่งต่อไปนี้ใน upGrad เพื่อเพิ่มโอกาสในการประสบความสำเร็จในสาขานี้
- หลักสูตรประกาศนียบัตรขั้นสูงด้านการเรียนรู้ของเครื่องและการเรียนรู้เชิงลึก จาก IIT Bangalore (6 เดือน)
- Advanced Certificate Program in Machine Learning และ NLP จาก IIT Bangalore (6 เดือน)
- Executive PG Program in Machine Learning & AI จาก IIT Bangalore (12 เดือน)
- การรับรองขั้นสูงด้าน Machine Learning และ Cloud จาก IIT Madras (12 เดือน)
- วิทยาศาสตรมหาบัณฑิตสาขาวิชา Machine Learning และ AI จาก LJMU และ IIT Bangalore (18 เดือน)
หลักสูตรทั้งหมดเหล่านี้มีการเรียนรู้อย่างน้อย 240 ชั่วโมงขึ้นไป และกรณีศึกษาอย่างน้อย 5 กรณี ซึ่งจะช่วยให้คุณได้รับความเข้าใจในเชิงลึกเกี่ยวกับแมชชีนเลิร์นนิงและเป็นสาขาเสริมต่างๆ คุณสามารถครอบคลุมหัวข้อสำคัญๆ เช่น Python, MySQL, Tensor, NLTK, statsmodels, excel และอื่นๆ ซึ่งเป็นแกนหลักของการเข้ารหัส นี่คือรายละเอียดเกี่ยวกับ หลักสูตร upGrad ต่างๆ ในการเรียนรู้ของเครื่อง เพื่อให้คุณสามารถเลือกหลักสูตรที่เหมาะสมกับคุณมากที่สุดได้

เข้าร่วม หลักสูตรปัญญาประดิษฐ์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
การประยุกต์ใช้แมชชีนเลิร์นนิง
แมชชีนเลิร์นนิงมีบทบาทสำคัญในชีวิตประจำวันของเรา ทั้งในเชิงอาชีพและส่วนบุคคล ความสามารถในการวิเคราะห์และใช้งานง่ายมีศักยภาพที่จะส่งผลกระทบอย่างมากต่อวิธีที่เราดำเนินงานประจำวันของเรา ได้รับการพิสูจน์แล้วว่าชาญฉลาดในการประหยัดเงินและเวลาสำหรับองค์กร
แม้ว่าแมชชีนเลิร์นนิงจะเป็นสาขากว้างที่มีการใช้งานในเกือบทุกอุตสาหกรรม แต่ต่อไปนี้คือตัวอย่างที่โดดเด่นที่สุดบางส่วน:
- การจดจำภาพเป็นหนึ่งในแอพพลิเคชั่นที่ใช้กันมากที่สุดเนื่องจากช่วยในการตรวจจับใบหน้า ดังนั้นจึงสร้างฐานข้อมูลแยกต่างหากสำหรับแต่ละบุคคล สามารถใช้เพื่อระบุลักษณะการเขียนด้วยลายมือได้เช่นกัน
- แมชชีนเลิร์นนิงในภาคสุขภาพได้เพิ่มขีดความสามารถของผู้ให้บริการด้านสุขภาพ สามารถใช้ในการวินิจฉัยทางการแพทย์ได้เร็วขึ้น ในหลายกรณี AI ได้ช่วยในการวินิจฉัยโรคในระยะเริ่มต้น ทำให้แพทย์สามารถแนะนำการรักษาและมาตรการป้องกันที่อาจช่วยชีวิตได้
- แมชชีนเลิร์นนิงมีการใช้งานที่สำคัญในภาคการเงินที่เกี่ยวข้องกับการลงทุน การควบรวมกิจการ และการเข้าซื้อกิจการ ช่วยธนาคารและสถาบันทางเศรษฐกิจอื่น ๆ ในการตัดสินใจเลือกอย่างชาญฉลาด
- ประสิทธิภาพของมันน่าจะชัดเจนที่สุดในอุตสาหกรรมการดูแลลูกค้าและการบริการ เนื่องจากแมชชีนเลิร์นนิงทำให้การปฏิบัติงานมีความคล่องตัวและให้บริการโซลูชั่นที่รวดเร็วและมีประสิทธิภาพมากขึ้น
- แมชชีนเลิร์นนิงทำให้งานต่างๆ ที่มนุษย์ต้องทำในสนามเป็นไปโดยอัตโนมัติ ตัวอย่างเช่น หากเราต้องพิจารณาผู้ช่วยเสมือน อาจเป็นงานง่ายๆ เช่น การเปลี่ยนรหัสผ่าน หรือตรวจสอบยอดเงินในธนาคารของคุณในตอนเย็น ด้วยแมชชีนเลิร์นนิง ทำให้ตอนนี้สามารถจัดสรรทรัพยากรบุคคลให้กับงานที่เร่งด่วนมากขึ้น ซึ่งต้องใช้การตัดสินใจที่ซับซ้อนหรือการสัมผัสของมนุษย์เพื่อให้สำเร็จ
ขอบเขตการเรียนรู้ของเครื่องในอนาคต
แม้ว่าแมชชีนเลิร์นนิงจะมีมาหลายทศวรรษแล้ว แต่การใช้งานก็ชัดเจนที่สุดในปัจจุบัน อุตสาหกรรมยังไม่เจริญและด้นสด ซึ่งหมายความว่าอนาคตของการเรียนรู้ของเครื่องจะสดใส บริษัทขนาดใหญ่ส่วนใหญ่ได้รับประโยชน์จากการเรียนรู้ของเครื่องและปรับขนาดบริการและผลิตภัณฑ์เพื่อขับเคลื่อนการเติบโตแล้ว
โดยธรรมชาติแล้ว วิศวกร ML มีความต้องการอย่างมาก และแมชชีนเลิร์นนิงก็นำเสนอตัวเองว่าเป็นอาชีพที่ทำกำไรได้ มันหมายถึงธุรกิจที่พวกเขาต้องการ AI ได้สร้างโอกาสงานประมาณ 2.3 ล้านตำแหน่งจนถึงปัจจุบัน มีการคาดการณ์ว่าภายในสิ้นปี พ.ศ. 2565 อุตสาหกรรม ML ทั่วโลกจะเติบโตที่ CAGR ที่ 42.2% เป็นมูลค่าถึง 9 พันล้านดอลลาร์ สหรัฐ
ต่อไปนี้คือแนวโน้มสำคัญบางประการในการเรียนรู้ของเครื่อง:
- อัลกอริธึมกำลังเรียนรู้เกี่ยวกับการใช้งานแบบไม่มีผู้ดูแลมากขึ้นเรื่อยๆ ธุรกิจต่างๆ กำลังลงทุนใน Quantum Computing โดยใช้อัลกอริธึมที่ไม่มีผู้ดูแลซึ่งมีศักยภาพในการเปลี่ยนแปลงการเรียนรู้ของเครื่อง สิ่งเหล่านี้มีส่วนช่วยในการวิเคราะห์และดึงข้อมูลเชิงลึกที่มีความหมาย ซึ่งช่วยให้ธุรกิจบรรลุผลลัพธ์ที่ดีขึ้นซึ่งเป็นไปไม่ได้โดยใช้เทคนิคการเรียนรู้ของเครื่องแบบคลาสสิก
- หุ่นยนต์ที่ขับเคลื่อนด้วย AI กำลังถูกนำไปใช้ในการดำเนินธุรกิจ อย่างไรก็ตาม เทคโนโลยีเหล่านี้อยู่ในขั้นเริ่มต้น และในขณะที่ธุรกิจต่างๆ ลงทุนเพื่อสร้างฐานที่มั่นของ AI และ ML หุ่นยนต์จะช่วยเพิ่มผลิตภาพอย่างทวีคูณในเร็วๆ นี้ ตัวอย่างเช่น เรามีโดรนซึ่งวางตัวเป็นเครื่องมือทางธุรกิจที่ทรงพลังในตลาดผู้บริโภค ซึ่งถูกนำไปใช้เพื่อดำเนินการเชิงพาณิชย์ให้สำเร็จและงานง่ายๆ เช่น การส่งมอบสินค้า
- อัลกอริธึมการเรียนรู้ของเครื่องสนับสนุนการปรับเปลี่ยนในแบบของคุณ อัลกอริทึมเหล่านี้จะสำรวจพฤติกรรมออนไลน์ของผู้มีโอกาสเป็นลูกค้าและส่งข้อมูลกลับไปยังบริษัทต่างๆ บริษัทจะส่งคำแนะนำเกี่ยวกับผลิตภัณฑ์และบริการให้กับพวกเขา เทคนิคการเรียนรู้ของเครื่องเหล่านี้ช่วยระบุความชอบและไม่ชอบของลูกค้า ด้วยแมชชีนเลิร์นนิง บริษัทต่างๆ จะมอบสิ่งที่พวกเขาต้องการให้กับลูกค้าและเมื่อพวกเขาต้องการ ซึ่งช่วยเพิ่มการรักษาลูกค้าและดึงดูดธุรกิจมายังองค์กรมากขึ้น การปรับเปลี่ยนในแบบของคุณให้ดีขึ้นคืออนาคตของการเรียนรู้ของเครื่อง
- ด้วยอัลกอริธึมการเรียนรู้ของเครื่องที่ได้รับการปรับปรุง แอปพลิเคชันมือถือและเว็บจึงฉลาดกว่าที่เคย บริการองค์ความรู้ที่ได้รับการปรับปรุงช่วยให้นักพัฒนาสามารถสร้างฐานข้อมูลแยกสำหรับลูกค้าแต่ละราย โดยอิงจากการจดจำภาพ คำพูด เสียง เสียง และอื่นๆ
สิ่งนี้นำเราไปสู่จุดสิ้นสุดของบทความ เราหวังว่าคุณจะพบว่าข้อมูลนี้มีประโยชน์!
เหตุใดจึงต้องมีการ homoscedasticity ในการถดถอยเชิงเส้น
Homoscedasticity อธิบายว่าข้อมูลมีความคล้ายคลึงหรือเบี่ยงเบนไปจากค่าเฉลี่ยเพียงใด นี่เป็นข้อสันนิษฐานที่สำคัญที่ต้องทำเนื่องจากการทดสอบทางสถิติเชิงพาราเมตริกมีความอ่อนไหวต่อความแตกต่าง ความแตกต่างไม่ก่อให้เกิดอคติในการประมาณค่าสัมประสิทธิ์ แต่จะลดความแม่นยำของค่าสัมประสิทธิ์ ด้วยความแม่นยำที่ต่ำกว่า การประมาณค่าสัมประสิทธิ์จึงมีแนวโน้มมากกว่าค่าประชากรที่ถูกต้อง เพื่อหลีกเลี่ยงปัญหานี้ homoscedasticity เป็นข้อสันนิษฐานที่สำคัญในการยืนยัน
multicollinearity สองประเภทในการถดถอยเชิงเส้นคืออะไร?
multicollinearity ข้อมูลและโครงสร้างเป็นสองประเภทพื้นฐานของ multicollinearity เมื่อเราสร้างเทอมแบบจำลองจากเงื่อนไขอื่น เราจะได้โครงสร้างหลายคอลลิเนียร์ กล่าวอีกนัยหนึ่ง แทนที่จะปรากฏในข้อมูลเอง มันเป็นผลมาจากแบบจำลองที่เราจัดเตรียมให้ แม้ว่า data multicollinearity จะไม่ใช่สิ่งประดิษฐ์ของโมเดลของเรา แต่ก็มีอยู่ในตัวข้อมูล multicollinearity ของข้อมูลเป็นเรื่องปกติมากขึ้นในการตรวจสอบเชิงสังเกต
ข้อเสียของการใช้ t-test สำหรับการทดสอบอิสระคืออะไร?
มีปัญหาเกี่ยวกับการวัดซ้ำแทนความแตกต่างระหว่างการออกแบบกลุ่มเมื่อใช้การทดสอบ t ตัวอย่างที่จับคู่กัน ซึ่งนำไปสู่ผลกระทบที่ตามมา เนื่องจากข้อผิดพลาดประเภทที่ 1 การทดสอบ t จึงไม่สามารถนำมาใช้ในการเปรียบเทียบหลายรายการได้ เป็นการยากที่จะปฏิเสธสมมติฐานว่างเมื่อทำการทดสอบ t คู่กับชุดตัวอย่าง การรับอาสาสมัครสำหรับข้อมูลตัวอย่างเป็นกระบวนการที่ใช้เวลานานและมีค่าใช้จ่ายสูงในกระบวนการวิจัย