
การทำนายตลาดหุ้นโดยใช้การเรียนรู้ของเครื่อง [การใช้งานทีละขั้นตอน]
เผยแพร่แล้ว: 2021-02-26สารบัญ
บทนำ
การทำนายและวิเคราะห์ตลาดหุ้นเป็นงานที่ซับซ้อนที่สุดที่ต้องทำ มีเหตุผลหลายประการสำหรับเรื่องนี้ เช่น ความผันผวนของตลาดและปัจจัยอิสระอื่น ๆ อีกมากมายในการตัดสินใจมูลค่าของหุ้นตัวใดตัวหนึ่งในตลาด ปัจจัยเหล่านี้ทำให้ยากสำหรับนักวิเคราะห์ตลาดหุ้นในการทำนายการเพิ่มขึ้นและลดลงด้วยองศาที่มีความแม่นยำสูง
อย่างไรก็ตาม ด้วยการถือกำเนิดของ Machine Learning และอัลกอริธึมที่แข็งแกร่ง การวิเคราะห์ตลาดล่าสุดและการพัฒนาการทำนายตลาดหุ้นได้เริ่มผสมผสานเทคนิคดังกล่าวในการทำความเข้าใจข้อมูลตลาดหุ้น
กล่าวโดยย่อ อัลกอริทึมการเรียนรู้ของเครื่องกำลังถูกใช้อย่างกว้างขวางในองค์กรจำนวนมากในการวิเคราะห์และคาดการณ์มูลค่าหุ้น บทความนี้จะกล่าวถึงการใช้งานอย่างง่ายในการวิเคราะห์และคาดการณ์มูลค่าหุ้นของร้านค้าปลีกออนไลน์ยอดนิยมทั่วโลกโดยใช้อัลกอริธึมการเรียนรู้ของเครื่องหลายตัวใน Python
คำชี้แจงปัญหา
ก่อนที่เราจะเข้าสู่การใช้งานโปรแกรมเพื่อทำนายมูลค่าตลาดหุ้น ให้เราเห็นภาพข้อมูลที่เราจะดำเนินการ เราจะวิเคราะห์มูลค่าหุ้นของ Microsoft Corporation (MSFT) จาก National Association of Securities Dealers Automated Quotations (NASDAQ) ข้อมูลมูลค่าหุ้นจะแสดงในรูปแบบของไฟล์คั่นด้วยเครื่องหมายจุลภาค (.csv) ซึ่งสามารถเปิดและดูได้โดยใช้ Excel หรือสเปรดชีต
MSFT มีหุ้นจดทะเบียนใน NASDAQ และมีค่าอัพเดททุกวันทำการของตลาดหุ้น โปรดทราบว่าตลาดไม่อนุญาตให้มีการซื้อขายในวันเสาร์และวันอาทิตย์ ดังนั้นจึงมีช่องว่างระหว่างวันทั้งสอง ในแต่ละวัน จะมีการบันทึกมูลค่าเปิดของหุ้น มูลค่าสูงสุดและต่ำสุดของหุ้นนั้นในวันเดียวกัน พร้อมกับมูลค่าปิดท้ายวัน
มูลค่าการปิดที่ปรับปรุงแล้วจะแสดงมูลค่าของหุ้นหลังจากผ่านรายการเงินปันผลแล้ว (เทคนิคเกินไป!) นอกจากนี้ยังให้ปริมาณรวมของหุ้นในตลาด ด้วย ด้วยข้อมูลเหล่านี้ มันขึ้นอยู่กับการทำงานของ Machine Learning/Data Scientist ที่จะศึกษาข้อมูลและใช้อัลกอริธึมหลายอย่างที่สามารถดึงรูปแบบจากประวัติหุ้นของ Microsoft Corporation ข้อมูล.

หน่วยความจำระยะสั้นระยะยาว
ในการพัฒนาโมเดล Machine Learning เพื่อทำนายราคาหุ้นของ Microsoft Corporation เราจะใช้เทคนิค Long Short-Term Memory (LSTM) ใช้เพื่อแก้ไขข้อมูลเล็กน้อยโดยการคูณและเพิ่มเติม ตามคำจำกัดความ หน่วยความจำระยะยาว (LSTM) เป็นสถาปัตยกรรมโครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN) ซึ่งใช้ในการเรียนรู้เชิงลึก
ต่างจากโครงข่ายประสาทเทียมแบบฟีดฟอร์เวิร์ดมาตรฐาน LSTM มีการเชื่อมต่อแบบป้อนกลับ มันสามารถประมวลผลจุดข้อมูลเดียว (เช่นรูปภาพ) และลำดับข้อมูลทั้งหมด (เช่นคำพูดหรือวิดีโอ) เพื่อให้เข้าใจแนวคิดเบื้องหลัง LSTM ให้เรายกตัวอย่างง่ายๆ ของบทวิจารณ์ของลูกค้าออนไลน์เกี่ยวกับโทรศัพท์มือถือ
สมมติว่าเราต้องการซื้อโทรศัพท์มือถือ เรามักจะอ้างถึงบทวิจารณ์โดยผู้ใช้ที่ผ่านการรับรอง ขึ้นอยู่กับความคิดและปัจจัยการผลิต เราตัดสินใจว่ามือถือดีหรือไม่ดี จากนั้นจึงซื้อ ขณะที่เราอ่านบทวิจารณ์ต่อไป เราจะมองหาคำหลักเช่น "น่าทึ่ง" "กล้องดี" "แบตเตอรี่สำรองที่ดีที่สุด" และคำอื่นๆ ที่เกี่ยวข้องกับโทรศัพท์มือถือ
เรามักจะมองข้ามคำทั่วไปในภาษาอังกฤษ เช่น “it”, “gave”, “this” เป็นต้น ดังนั้น เมื่อเราตัดสินใจว่าจะซื้อโทรศัพท์มือถือหรือไม่ เราจำเฉพาะคำหลักเหล่านี้ที่กำหนดไว้ข้างต้นเท่านั้น เป็นไปได้มากว่าเราลืมคำอื่น ๆ
นี่เป็นวิธีเดียวกับที่อัลกอริธึมหน่วยความจำระยะสั้นระยะยาวทำงาน โดยจะจำเฉพาะข้อมูลที่เกี่ยวข้องและใช้เพื่อคาดการณ์โดยไม่สนใจข้อมูลที่ไม่เกี่ยวข้อง ด้วยวิธีนี้ เราต้องสร้างแบบจำลอง LSTM ที่รับรู้เฉพาะข้อมูลที่จำเป็นเกี่ยวกับสต็อกนั้นเป็นหลักและละทิ้งค่าผิดปกติ
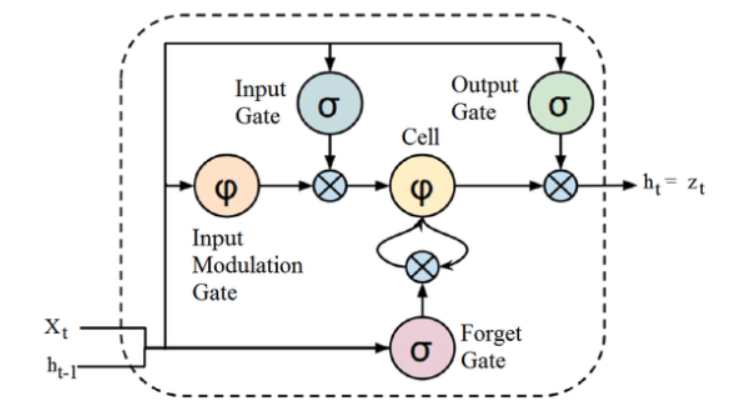
แหล่งที่มา
แม้ว่าโครงสร้างที่กล่าวข้างต้นของสถาปัตยกรรม LSTM อาจดูน่าสนใจในตอนแรก แต่ก็เพียงพอที่จะจำไว้ว่า LSTM เป็นรุ่นขั้นสูงของ Recurrent Neural Networks ที่เก็บรักษาหน่วยความจำไว้เพื่อประมวลผลลำดับของข้อมูล มันสามารถลบหรือเพิ่มข้อมูลไปยังสถานะของเซลล์ ควบคุมอย่างระมัดระวังโดยโครงสร้างที่เรียกว่าเกต
หน่วย LSTM ประกอบด้วยเซลล์ ประตูทางเข้า ประตูทางออก และประตูลืม เซลล์จะจดจำค่าในช่วงเวลาที่กำหนด และประตูทั้งสามจะควบคุมการไหลของข้อมูลเข้าและออกจากเซลล์
การใช้งานโปรแกรม
เราจะไปยังส่วนที่เรานำ LSTM ไปใช้ในการทำนายมูลค่าหุ้นโดยใช้การเรียนรู้ของเครื่องใน Python
ขั้นตอนที่ 1 – การนำเข้าไลบรารี
อย่างที่เราทราบกันดี ขั้นตอนแรกคือการนำเข้าไลบรารีที่จำเป็นในการประมวลผลข้อมูลสต็อกของ Microsoft Corporation และไลบรารีที่จำเป็นอื่นๆ สำหรับการสร้างและการแสดงภาพผลลัพธ์ของโมเดล LSTM สำหรับสิ่งนี้ เราจะใช้ไลบรารี Keras ภายใต้เฟรมเวิร์ก TensorFlow โมดูลที่จำเป็นนำเข้าจากไลบรารี Keras ทีละรายการ
#นำเข้าห้องสมุด
นำเข้าแพนด้าเป็น PD
นำเข้า NumPy เป็น np
%matplotlib แบบอินไลน์
นำเข้า matplotlib pyplot เป็น plt
นำเข้า matplotlib
จาก sklearn การนำเข้าการประมวลผลล่วงหน้า MinMaxScaler
จากเคราส์. เลเยอร์นำเข้า LSTM, Dense, Dropout
จาก sklearn.model_selection นำเข้า TimeSeriesSplit
จาก sklearn.metrics นำเข้า mean_squared_error, r2_score
นำเข้า matplotlib วันที่ตามคำสั่ง
จาก sklearn การนำเข้าการประมวลผลล่วงหน้า MinMaxScaler
จาก sklearn นำเข้า linear_model
จากเคราส์. โมเดลนำเข้า Sequential
จากเคราส์. เลเยอร์นำเข้าหนาแน่น
นำเข้า Keras แบ็กเอนด์เป็น K
จากเคราส์. การโทรกลับนำเข้า EarlyStopping
จากเคราส์. นักเพิ่มประสิทธิภาพนำเข้า Adam
จากเคราส์. โมเดลนำเข้า load_model
จากเคราส์. เลเยอร์นำเข้าLSTM
จากเคราส์. utils.vis_utils นำเข้า plot_model
ขั้นตอนที่ 2 – การสร้างภาพข้อมูล
การใช้ไลบรารีโปรแกรมอ่าน Pandas Data เราจะอัปโหลดข้อมูลสต็อกของระบบโลคัลเป็นไฟล์ Comma Separated Value (.csv) และจัดเก็บไว้ใน DataFrame ของแพนด้า สุดท้ายเราจะดูข้อมูลด้วย
#รับชุดข้อมูล
df = pd.read_csv("MicrosoftStockData.csv",na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.head()
รับ ใบรับรอง AI ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท, Executive Post Graduate Programs และ Advanced Certificate Program ใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ขั้นตอนที่ 3 – พิมพ์รูปร่าง DataFrame และตรวจสอบค่า Null
ในขั้นตอนสำคัญอีกขั้นนี้ ขั้นแรกเราจะพิมพ์รูปร่างของชุดข้อมูล เพื่อให้แน่ใจว่าไม่มีค่า null ใน data frame เราตรวจสอบค่าเหล่านี้ การมีอยู่ของค่า Null ในชุดข้อมูลมักจะทำให้เกิดปัญหาระหว่างการฝึก เนื่องจากค่าเหล่านี้ทำหน้าที่เป็นค่าผิดปกติทำให้เกิดความแปรปรวนในวงกว้างในกระบวนการฝึกอบรม
#พิมพ์รูปร่าง Dataframe และตรวจสอบค่า Null
พิมพ์("รูปร่างของดาต้าเฟรม: ", df. รูปร่าง)
พิมพ์("ค่า Null ปัจจุบัน: ", df.IsNull().values.any())
>> รูปร่างดาต้าเฟรม: (7334, 6)
>>ค่า Null ปัจจุบัน: เท็จ
| วันที่ | เปิด | สูง | ต่ำ | ปิด I | Adj ปิด | ปริมาณ |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
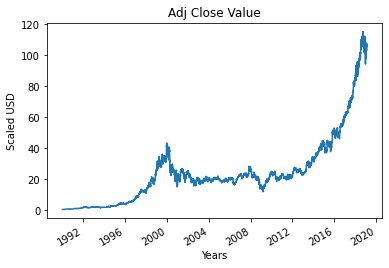
ขั้นตอนที่ 4 – พล็อตมูลค่าปิดที่ปรับปรุงจริง
ค่าผลลัพธ์สุดท้ายที่จะคาดการณ์โดยใช้แบบจำลองการเรียนรู้ของเครื่องคือค่าปิดที่ปรับปรุง ค่านี้แสดงถึงมูลค่าปิดของหุ้นในวันนั้น ๆ ของการซื้อขายในตลาดหุ้น
#พล็อตมูลค่าปิดของ Adj ที่แท้จริง
df['Adj ปิด'].plot()
ขั้นตอนที่ 5 – การตั้งค่าตัวแปรเป้าหมายและเลือกคุณสมบัติ
ในขั้นตอนต่อไป เราจะกำหนดคอลัมน์ผลลัพธ์ให้กับตัวแปรเป้าหมาย ในกรณีนี้ เป็นค่าสัมพัทธ์ที่ปรับปรุงแล้วของ Microsoft Stock นอกจากนี้ เรายังเลือกคุณสมบัติที่ทำหน้าที่เป็นตัวแปรอิสระให้กับตัวแปรเป้าหมาย (ตัวแปรตาม) เพื่อวัตถุประสงค์ในการฝึกอบรม เราเลือกคุณลักษณะสี่ประการ ได้แก่ :
- เปิด
- สูง
- ต่ำ
- ปริมาณ
#ตั้งค่าตัวแปรเป้าหมาย

output_var = PD.DataFrame(df['Adj Close'])
#การเลือกคุณสมบัติ
คุณสมบัติ = ['เปิด', 'สูง', 'ต่ำ', 'ระดับเสียง']
ขั้นตอนที่ 6 – การปรับขนาด
เพื่อลดต้นทุนการคำนวณของข้อมูลในตาราง เราจะลดมูลค่าสต็อคลงเป็นค่าระหว่าง 0 ถึง 1 ด้วยวิธีนี้ ข้อมูลทั้งหมดในจำนวนมากจะลดลง ซึ่งจะเป็นการลดการใช้หน่วยความจำ นอกจากนี้เรายังมีความแม่นยำมากขึ้นโดยการลดขนาดลงเนื่องจากข้อมูลไม่ได้ถูกกระจายออกไปในมูลค่ามหาศาล สิ่งนี้ดำเนินการโดยคลาส MinMaxScaler ของไลบรารี sci-kit-learn
#สเกล
ตัวปรับขนาด = MinMaxScaler ()
feature_transform = scaler.fit_transform (df [คุณสมบัติ])
feature_transform= pd.DataFrame(คอลัมน์=คุณสมบัติ, data=feature_transform,ดัชนี=df.index)
feature_transform.head()
| วันที่ | เปิด | สูง | ต่ำ | ปริมาณ |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
ดังที่กล่าวไว้ข้างต้น เราเห็นว่าค่าของตัวแปรคุณลักษณะถูกลดขนาดลงเป็นค่าที่น้อยกว่าเมื่อเทียบกับค่าจริงที่ให้ไว้ข้างต้น
ขั้นตอนที่ 7 – แยกออกเป็นชุดการฝึกและชุดทดสอบ
ก่อนป้อนข้อมูลลงในโมเดลการฝึก เราต้องแยกชุดข้อมูลทั้งหมดออกเป็นชุดฝึกและชุดทดสอบ โมเดล Machine Learning LSTM จะได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่มีอยู่ในชุดการฝึกและทดสอบกับชุดทดสอบเพื่อความถูกต้องและการแพร่กระจายกลับ
สำหรับสิ่งนี้ เราจะใช้คลาส TimeSeriesSplit ของไลบรารี sci-kit-learn เรากำหนดจำนวนการแยกเป็น 10 ซึ่งแสดงว่า 10% ของข้อมูลจะถูกใช้เป็นชุดทดสอบ และ 90% ของข้อมูลจะถูกใช้สำหรับการฝึกโมเดล LSTM ข้อดีของการใช้การแบ่งอนุกรมเวลานี้คือจะสังเกตตัวอย่างข้อมูลอนุกรมเวลาแบบแยกตามช่วงเวลาที่กำหนด
#แยกเป็นชุดซ้อมและชุดทดสอบ
ไทม์สปลิต= ไทม์ซีรีส์สปลิต(n_splits=10)
สำหรับ train_index, test_index ใน timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
ขั้นตอนที่ 8 – การประมวลผลข้อมูลสำหรับ LSTM
เมื่อชุดการฝึกและการทดสอบพร้อมแล้ว เราสามารถป้อนข้อมูลลงในแบบจำลอง LSTM ได้เมื่อสร้างเสร็จแล้ว ก่อนหน้านั้น เราต้องแปลงข้อมูลชุดการฝึกและทดสอบเป็นประเภทข้อมูลที่โมเดล LSTM จะยอมรับ ก่อนอื่นเราจะแปลงข้อมูลการฝึกอบรมและทดสอบข้อมูลเป็นอาร์เรย์ NumPy จากนั้นจัดรูปแบบใหม่ให้อยู่ในรูปแบบ (จำนวนตัวอย่าง 1 จำนวนคุณลักษณะ) เนื่องจาก LSTM กำหนดให้ป้อนข้อมูลในรูปแบบ 3 มิติ อย่างที่เราทราบ จำนวนตัวอย่างในชุดการฝึกคือ 90% ของ 7334 ซึ่งเท่ากับ 6667 และจำนวนคุณสมบัติคือ 4 ชุดการฝึกจะเปลี่ยนรูปร่างเป็น (6667, 1, 4) ชุดทดสอบก็เปลี่ยนรูปร่างเช่นกัน
#ประมวลผลข้อมูลสำหรับLSTM
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
ขั้นตอนที่ 9 – การสร้างแบบจำลอง LSTM
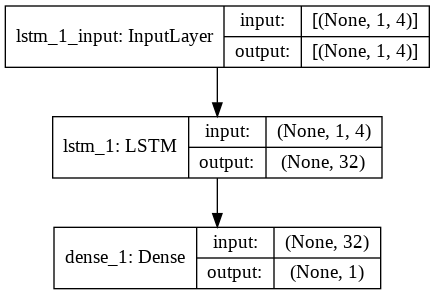
ในที่สุด เราก็มาถึงขั้นตอนที่เราสร้าง LSTM Model ที่นี่ เราสร้างโมเดล Sequential Keras ด้วยหนึ่งเลเยอร์ LSTM เลเยอร์ LSTM มี 32 ยูนิต และตามด้วย Dense Layer ของ 1 เซลล์ประสาท
เราใช้ Adam Optimizer และ Mean Squared Error เป็นฟังก์ชันการสูญเสียสำหรับการรวบรวมแบบจำลอง ทั้งสองนี้เป็นชุดค่าผสมที่ต้องการมากที่สุดสำหรับรุ่น LSTM นอกจากนี้ โมเดลยังถูกวางแผนไว้และแสดงไว้ด้านล่าง
#การสร้างแบบจำลอง LSTM
lstm = ลำดับ ()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), enable='relu', return_sequences=False))
lstm.add(หนาแน่น(1))
lstm.compile(loss='mean_squared_error', เครื่องมือเพิ่มประสิทธิภาพ='adam')
plot_model(lstm, show_shapes=จริง, show_layer_names=True)
ขั้นตอนที่ 10 – ฝึกโมเดล
สุดท้าย เราฝึกโมเดล LSTM ที่ออกแบบไว้ข้างต้นในข้อมูลการฝึกสำหรับ 100 ยุคด้วยขนาดแบทช์ 8 โดยใช้ฟังก์ชันพอดี
#โมเดลเทรนนิ่ง
ประวัติ = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
ยุค 1/100
834/834 [==============================] – 3 วินาที 2ms/ขั้นตอน – การสูญเสีย: 67.1211
ยุค 2/100
834/834 [==============================] – 1 วินาที 2 มิลลิวินาที/ขั้นตอน – ขาดทุน: 70.4911
ยุค 3/100
834/834 [==============================] – 1 วินาที 2 มิลลิวินาที/ขั้นตอน – การสูญเสีย: 48.8155
ยุค 4/100
834/834 [==============================] – 1 วินาที 2 มิลลิวินาที/ขั้นตอน – ขาดทุน: 21.5447
ยุค 5/100
834/834 [=============================] – 1 วินาที 2 มิลลิวินาที/ขั้นตอน – ขาดทุน: 6.1709
ยุค 6/100
834/834 [==============================] – 1 วินาที 2 มิลลิวินาที/ขั้นตอน – ขาดทุน: 1.8726
ยุค 7/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.9380
ยุค 8/100
834/834 [==============================] – 2 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.6566
ยุค 9/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.5369
ยุค 10/100
834/834 [==============================] – 2 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4761
.
.
.
.
ยุค 95/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4542
ยุค 96/100
834/834 [==============================] – 2 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4553
ยุค 97/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4565
ยุค 98/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4576
ยุค 99/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4588
ยุค 100/100
834/834 [==============================] – 1 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.4599
สุดท้ายเราพบว่ามูลค่าการสูญเสียลดลงอย่างทวีคูณเมื่อเวลาผ่านไปในระหว่างกระบวนการฝึกอบรม 100 ยุคและมีมูลค่าถึง 0.4599
ขั้นตอนที่ 11 – การทำนาย LSTM
เมื่อโมเดลของเราพร้อมแล้ว ก็ถึงเวลาที่จะใช้แบบจำลองที่ฝึกโดยใช้เครือข่าย LSTM ในชุดทดสอบและคาดการณ์มูลค่าปิดที่ติดกันของหุ้น Microsoft ทำได้โดยใช้ฟังก์ชันง่ายๆ ของการทำนายบนโมเดล lstm ที่สร้างขึ้น
#คำทำนายLSTM
y_pred= lstm.predict(X_test)
ขั้นตอนที่ 12 – True vs Predicted Adj Close Value – LSTM
สุดท้าย ขณะที่เราคาดการณ์ค่าของชุดทดสอบ เราสามารถพล็อตกราฟเพื่อเปรียบเทียบทั้งค่าจริงของ Adj Close และค่าที่คาดการณ์ของ Adj Close ด้วยโมเดล LSTM Machine Learning
#True vs Predicted Adj มูลค่าปิด – LSTM
plt.plot(y_test, label='True Value')
plt.plot(y_pred, label='ค่า LSTM')
plt.title (“การทำนายโดย LSTM”)
plt.xlabel('มาตราส่วนเวลา')
plt.ylabel('Scaled USD')
plt.ตำนาน()
plt.show()
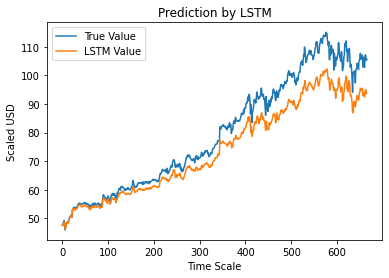
กราฟด้านบนแสดงให้เห็นว่ารูปแบบบางอย่างถูกตรวจพบโดยโมเดลเครือข่าย LSTM เดี่ยวขั้นพื้นฐานที่สร้างขึ้นด้านบน ด้วยการปรับแต่งพารามิเตอร์หลายๆ อย่างอย่างละเอียดและเพิ่มเลเยอร์ LSTM ให้กับโมเดล เราจึงสามารถแสดงมูลค่าหุ้นของบริษัทที่กำหนดได้อย่างแม่นยำยิ่งขึ้น
บทสรุป
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับตัวอย่างปัญญาประดิษฐ์ แมชชีนเลิร์นนิง ลองดู โปรแกรม Executive PG ของ IIIT-B และ upGrad ในการเรียนรู้ของเครื่องและ AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษามากกว่า 30 รายการ & การมอบหมาย, สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับ บริษัท ชั้นนำ
คุณสามารถทำนายตลาดหุ้นโดยใช้การเรียนรู้ของเครื่องได้หรือไม่?
วันนี้ เรามีอินดิเคเตอร์มากมายที่ช่วยทำนายแนวโน้มของตลาด อย่างไรก็ตาม เราต้องมองไม่ไกลจากคอมพิวเตอร์ที่มีพลังสูงเพื่อค้นหาตัวบ่งชี้ที่แม่นยำที่สุดสำหรับตลาดหุ้น ตลาดหุ้นเป็นระบบเปิดและอาจถูกมองว่าเป็นเครือข่ายที่ซับซ้อน เครือข่ายประกอบด้วยความสัมพันธ์ระหว่างหุ้น บริษัท นักลงทุนและปริมาณการค้า ด้วยการใช้อัลกอริธึมการทำเหมืองข้อมูล เช่น เครื่องสนับสนุนเวกเตอร์ คุณสามารถใช้สูตรทางคณิตศาสตร์เพื่อแยกความสัมพันธ์ระหว่างตัวแปรเหล่านี้ได้ ตลาดหุ้นตอนนี้อยู่นอกเหนือการคาดการณ์ของมนุษย์
อัลกอริทึมใดดีที่สุดสำหรับการทำนายตลาดหุ้น
เพื่อผลลัพธ์ที่ดีที่สุด คุณควรใช้การถดถอยเชิงเส้น การถดถอยเชิงเส้นเป็นวิธีการทางสถิติที่ใช้ในการกำหนดความสัมพันธ์ระหว่างตัวแปรสองตัวที่แตกต่างกัน ในตัวอย่างนี้ ตัวแปรคือราคาและเวลา ในการทำนายตลาดหุ้น ราคาคือตัวแปรอิสระ และเวลาคือตัวแปรตาม หากสามารถกำหนดความสัมพันธ์เชิงเส้นตรงระหว่างตัวแปรทั้งสองนี้ได้ ก็เป็นไปได้ที่จะทำนายมูลค่าหุ้นได้อย่างแม่นยำ ณ จุดใดจุดหนึ่งในอนาคต
การทำนายตลาดหุ้นเป็นปัญหาการจำแนกประเภทหรือการถดถอยหรือไม่?
ก่อนที่เราจะตอบ เราต้องเข้าใจความหมายของการทำนายตลาดหุ้นก่อน มันเป็นปัญหาการจำแนกประเภทไบนารีหรือปัญหาการถดถอยหรือไม่? สมมติว่าเราต้องการทำนายอนาคตของหุ้น โดยที่อนาคตหมายถึงวันถัดไป สัปดาห์ เดือน หรือปีถัดไป หากผลการดำเนินงานในอดีตของหุ้นเป็นปัจจัยนำเข้าและอนาคตคือผลผลิต แสดงว่าเป็นปัญหาการถดถอย หากผลการดำเนินงานในอดีตของหุ้นและอนาคตของหุ้นเป็นอิสระจากกัน แสดงว่าเป็นปัญหาการจำแนกประเภท