
การแบ่งปันข้อมูลระหว่างหลายเซิร์ฟเวอร์ผ่าน AWS S3
เผยแพร่แล้ว: 2022-03-10เมื่อจัดเตรียมฟังก์ชันการทำงานบางอย่างสำหรับการประมวลผลไฟล์ที่ผู้ใช้อัปโหลด ไฟล์จะต้องพร้อมใช้งานสำหรับกระบวนการตลอดการดำเนินการ การดำเนินการอัปโหลดและบันทึกอย่างง่ายไม่มีปัญหา อย่างไรก็ตาม หากต้องจัดการไฟล์เพิ่มเติมก่อนที่จะบันทึก และแอปพลิเคชันทำงานบนเซิร์ฟเวอร์หลายเครื่องที่อยู่เบื้องหลังโหลดบาลานเซอร์ เราต้องตรวจสอบให้แน่ใจว่าไฟล์นั้นพร้อมใช้งานสำหรับเซิร์ฟเวอร์ใดก็ตามที่เรียกใช้กระบวนการในแต่ละครั้ง
ตัวอย่างเช่น การทำงานหลายขั้นตอน “อัปโหลดอวาตาร์ผู้ใช้ของคุณ” อาจต้องการให้ผู้ใช้อัปโหลดอวาตาร์ในขั้นตอนที่ 1 ครอบตัดในขั้นตอนที่ 2 และสุดท้ายบันทึกในขั้นตอนที่ 3 หลังจากอัปโหลดไฟล์ไปยังเซิร์ฟเวอร์ในขั้นตอนที่ 1 ไฟล์ต้องพร้อมใช้งานสำหรับเซิร์ฟเวอร์ใดก็ตามที่จัดการคำขอสำหรับขั้นตอนที่ 2 และ 3 ซึ่งอาจเป็นไฟล์เดียวกันสำหรับขั้นตอนที่ 1
แนวทางที่ไร้เดียงสาคือการคัดลอกไฟล์ที่อัปโหลดในขั้นตอนที่ 1 ไปยังเซิร์ฟเวอร์อื่นทั้งหมด ดังนั้นไฟล์จะพร้อมใช้งานในเซิร์ฟเวอร์ทั้งหมด อย่างไรก็ตาม วิธีการนี้ไม่เพียงแต่ซับซ้อนอย่างยิ่งแต่ยังทำไม่ได้ เช่น หากไซต์ทำงานบนเซิร์ฟเวอร์หลายร้อยเครื่อง จากหลายภูมิภาค ก็ไม่สามารถทำได้
วิธีแก้ปัญหาที่เป็นไปได้คือเปิดใช้งาน "เซสชันที่ติดขัด" บนตัวโหลดบาลานซ์ ซึ่งจะกำหนดเซิร์ฟเวอร์เดียวกันสำหรับเซสชันที่กำหนดเสมอ จากนั้น ขั้นตอนที่ 1, 2 และ 3 จะได้รับการจัดการโดยเซิร์ฟเวอร์เดียวกัน และไฟล์ที่อัปโหลดไปยังเซิร์ฟเวอร์นี้ในขั้นตอนที่ 1 จะยังคงอยู่สำหรับขั้นตอนที่ 2 และ 3 อย่างไรก็ตาม เซสชัน Sticky ไม่น่าเชื่อถืออย่างสมบูรณ์: หากอยู่ระหว่างขั้นตอนที่ 1 และ 2 เซิร์ฟเวอร์นั้นขัดข้อง จากนั้นโหลดบาลานเซอร์จะต้องกำหนดเซิร์ฟเวอร์อื่น ทำให้การทำงานและประสบการณ์ของผู้ใช้หยุดชะงัก ในทำนองเดียวกัน การกำหนดเซิร์ฟเวอร์เดียวกันสำหรับเซสชันเสมออาจทำให้เวลาตอบสนองช้าลงจากเซิร์ฟเวอร์ที่มีภาระมากเกินไปภายใต้สถานการณ์พิเศษ
วิธีแก้ปัญหาที่เหมาะสมกว่าคือเก็บสำเนาของไฟล์ไว้บนที่เก็บที่เซิร์ฟเวอร์ทั้งหมดสามารถเข้าถึงได้ จากนั้น หลังจากที่ไฟล์ถูกอัปโหลดไปยังเซิร์ฟเวอร์ในขั้นตอนที่ 1 แล้ว เซิร์ฟเวอร์นี้จะอัปโหลดไปยังที่เก็บ (หรืออีกทางหนึ่ง ไฟล์สามารถอัปโหลดไปยังที่เก็บได้โดยตรงจากไคลเอ็นต์ โดยข้ามเซิร์ฟเวอร์) เซิร์ฟเวอร์จัดการขั้นตอนที่ 2 จะดาวน์โหลดไฟล์จากที่เก็บ จัดการ และอัปโหลดที่นั่นอีกครั้ง และสุดท้ายเซิร์ฟเวอร์จัดการขั้นตอนที่ 3 จะดาวน์โหลดจากที่เก็บและบันทึก
ในบทความนี้ ฉันจะอธิบายโซลูชันหลังนี้ โดยอิงตามแอปพลิเคชัน WordPress ที่จัดเก็บไฟล์บน Amazon Web Services (AWS) Simple Storage Service (S3) (โซลูชันพื้นที่จัดเก็บอ็อบเจ็กต์บนคลาวด์เพื่อจัดเก็บและดึงข้อมูล) ซึ่งทำงานผ่าน AWS SDK
หมายเหตุ 1: สำหรับฟังก์ชันที่เรียบง่าย เช่น การครอบตัดภาพแทนตัว อีกวิธีหนึ่งคือการข้ามเซิร์ฟเวอร์โดยสมบูรณ์ และใช้งานโดยตรงในระบบคลาวด์ผ่านฟังก์ชันของแลมบ์ดา แต่เนื่องจากบทความนี้เกี่ยวกับการเชื่อมต่อแอปพลิเคชันที่ทำงานบนเซิร์ฟเวอร์กับ AWS S3 เราจึงไม่พิจารณาวิธีแก้ปัญหานี้
หมายเหตุ 2: ในการใช้ AWS S3 (หรือบริการอื่นๆ ของ AWS) เราจำเป็นต้องมีบัญชีผู้ใช้ Amazon เสนอช่วงทดลองใช้ฟรีที่นี่เป็นเวลา 1 ปี ซึ่งดีเพียงพอสำหรับการทดลองใช้บริการของพวกเขา
หมายเหตุ 3: มีปลั๊กอินของบุคคลที่สามสำหรับการอัปโหลดไฟล์จาก WordPress ไปยัง S3 ปลั๊กอินตัวหนึ่งดังกล่าวคือ WP Media Offload (เวอร์ชัน lite มีให้ที่นี่) ซึ่งมีคุณสมบัติที่ยอดเยี่ยม: ถ่ายโอนไฟล์ที่อัปโหลดไปยัง Media Library ไปยังบัคเก็ต S3 ได้อย่างราบรื่น ซึ่งช่วยให้แยกเนื้อหาของไซต์ได้ (เช่น ทุกอย่างภายใต้ /wp-content/uploads) จากรหัสแอปพลิเคชัน การแยกส่วนเนื้อหาและโค้ดทำให้เราสามารถปรับใช้แอปพลิเคชัน WordPress ของเราโดยใช้ Git (ไม่เช่นนั้นเราจะทำไม่ได้ เนื่องจากเนื้อหาที่ผู้ใช้อัปโหลดไม่ได้โฮสต์อยู่ในที่เก็บ Git) และโฮสต์แอปพลิเคชันบนเซิร์ฟเวอร์หลายเครื่อง (ไม่เช่นนั้น แต่ละเซิร์ฟเวอร์จะต้องเก็บไว้ สำเนาของเนื้อหาที่ผู้ใช้อัปโหลดทั้งหมด)
การสร้างถัง
เมื่อสร้างบัคเก็ต เราต้องจ่ายการพิจารณาชื่อบัคเก็ต: ชื่อบัคเก็ตแต่ละชื่อต้องไม่ซ้ำกันทั่วโลกบนเครือข่าย AWS ดังนั้นแม้ว่าเราต้องการเรียกบัคเก็ตของเราว่า "อวตาร" ธรรมดา แต่ชื่อนั้นก็อาจมีคนใช้อยู่แล้ว จากนั้นเราอาจเลือกสิ่งที่โดดเด่นกว่าเช่น "avatars-name-of-my-company"
เราจะต้องเลือกภูมิภาคที่ที่ฝากข้อมูลตั้งอยู่ด้วย (ภูมิภาคคือตำแหน่งทางกายภาพที่ศูนย์ข้อมูลตั้งอยู่ โดยมีสถานที่อยู่ทั่วโลก)
ภูมิภาคจะต้องเป็นภูมิภาคเดียวกับที่แอปพลิเคชันของเราถูกปรับใช้ เพื่อให้การเข้าถึง S3 ระหว่างการดำเนินการของกระบวนการนั้นรวดเร็ว มิฉะนั้น ผู้ใช้อาจต้องรอนานเป็นพิเศษเพื่ออัปโหลด/ดาวน์โหลดภาพไปยัง/จากตำแหน่งที่ห่างไกล
หมายเหตุ: ควรใช้ S3 เป็นโซลูชันพื้นที่จัดเก็บอ็อบเจ็กต์บนคลาวด์ก็ต่อเมื่อเราใช้บริการของ Amazon สำหรับเซิร์ฟเวอร์เสมือนบนคลาวด์ EC2 สำหรับการเรียกใช้แอปพลิเคชันเท่านั้น หากเราพึ่งพาบริษัทอื่นในการโฮสต์แอปพลิเคชัน เช่น Microsoft Azure หรือ DigitalOcean เราก็ควรใช้บริการพื้นที่จัดเก็บอ็อบเจ็กต์บนคลาวด์ของบริษัทเหล่านั้นด้วย มิฉะนั้น ไซต์ของเราจะเสียค่าใช้จ่ายจากข้อมูลที่เดินทางระหว่างเครือข่ายของบริษัทต่างๆ
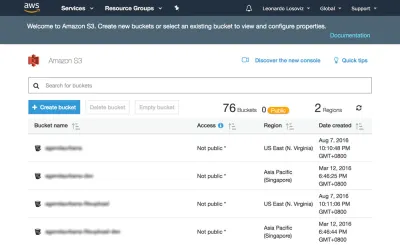
ในภาพหน้าจอด้านล่าง เราจะเห็นวิธีการสร้างบัคเก็ตเพื่ออัปโหลดอวาตาร์ของผู้ใช้สำหรับการครอบตัด ก่อนอื่นเราไปที่แดชบอร์ด S3 และคลิกที่ "สร้างที่เก็บข้อมูล":
จากนั้นเราพิมพ์ชื่อที่ฝากข้อมูล (ในกรณีนี้คือ "ภาพแทนตัวยอดเยี่ยม") และเลือกภูมิภาค ("EU (แฟรงค์เฟิร์ต)"):
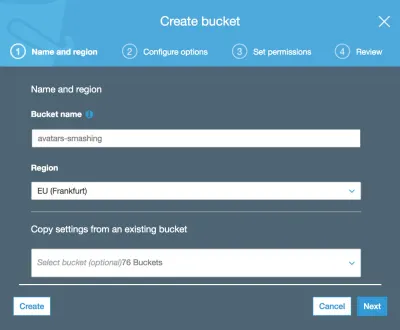
บังคับเฉพาะชื่อที่เก็บข้อมูลและภูมิภาคเท่านั้น สำหรับขั้นตอนต่อไปนี้ เราสามารถเก็บตัวเลือกเริ่มต้นไว้ได้ ดังนั้นเราจึงคลิก "ถัดไป" จนกระทั่งคลิก "สร้างที่เก็บข้อมูล" ในที่สุด จากนั้นเราจะสร้างที่เก็บข้อมูล
การตั้งค่าการอนุญาตผู้ใช้
เมื่อเชื่อมต่อกับ AWS ผ่าน SDK เราจะต้องป้อนข้อมูลรับรองผู้ใช้ของเรา (คู่ของรหัสคีย์การเข้าถึงและรหัสการเข้าถึงลับ) เพื่อตรวจสอบว่าเรามีสิทธิ์เข้าถึงบริการและอ็อบเจ็กต์ที่ร้องขอ สิทธิ์ของผู้ใช้อาจเป็นแบบทั่วไปมาก (บทบาท "ผู้ดูแลระบบ" สามารถทำทุกอย่าง) หรือละเอียดมาก เพียงแค่ให้สิทธิ์ในการดำเนินการเฉพาะที่จำเป็นเท่านั้น
ตามกฎทั่วไป ยิ่งการอนุญาตที่เราให้มาเฉพาะเจาะจงมากเท่าไหร่ ก็ยิ่งดีเท่านั้นที่จะหลีกเลี่ยงปัญหาด้านความปลอดภัย เมื่อสร้างผู้ใช้ใหม่ เราจะต้องสร้างนโยบาย ซึ่งเป็นเอกสาร JSON ธรรมดาที่แสดงรายการสิทธิ์ที่จะมอบให้แก่ผู้ใช้ ในกรณีของเรา สิทธิ์ผู้ใช้ของเราจะอนุญาตให้เข้าถึง S3 สำหรับถัง "avatars-smashing" สำหรับการทำงานของ "Put" (สำหรับการอัปโหลดวัตถุ), "Get" (สำหรับการดาวน์โหลดวัตถุ) และ "List" ( สำหรับการแสดงรายการวัตถุทั้งหมดในที่เก็บข้อมูล) ส่งผลให้นโยบายต่อไปนี้:
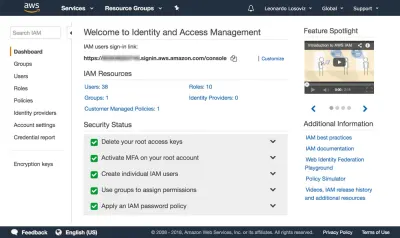
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }ในภาพหน้าจอด้านล่าง เราสามารถเห็นวิธีการเพิ่มการอนุญาตของผู้ใช้ เราต้องไปที่แดชบอร์ด Identity and Access Management (IAM):
ในแดชบอร์ด เราคลิก "ผู้ใช้" และคลิก "เพิ่มผู้ใช้" ทันที ในหน้าเพิ่มผู้ใช้ เราเลือกชื่อผู้ใช้ (“crop-avatars”) และทำเครื่องหมายที่ “Programmatic access” เป็นประเภท Access ซึ่งจะจัดเตรียมรหัสคีย์การเข้าถึงและคีย์การเข้าถึงลับสำหรับการเชื่อมต่อผ่าน SDK:
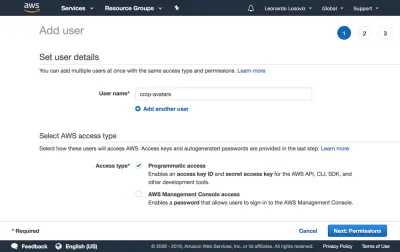
จากนั้นเราคลิกที่ปุ่ม "ถัดไป: การอนุญาต" คลิกที่ "แนบนโยบายที่มีอยู่โดยตรง" และคลิกที่ "สร้างนโยบาย" ซึ่งจะเป็นการเปิดแท็บใหม่ในเบราว์เซอร์ พร้อมด้วยหน้าสร้างนโยบาย เราคลิกที่แท็บ JSON และป้อนรหัส JSON สำหรับนโยบายที่กำหนดไว้ด้านบน:
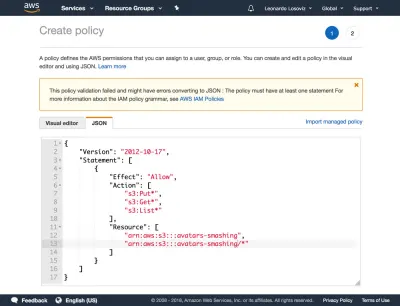
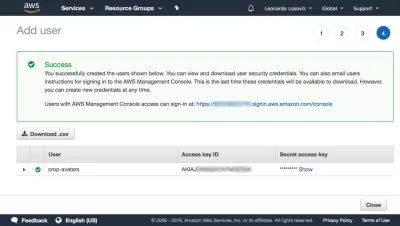
จากนั้นเราคลิกที่นโยบายการทบทวน ตั้งชื่อ ("CropAvatars") และสุดท้ายคลิกที่สร้างนโยบาย เมื่อสร้างนโยบายแล้ว เราจะสลับกลับไปที่แท็บก่อนหน้า เลือกนโยบาย CropAvatars (เราอาจต้องรีเฟรชรายการนโยบายเพื่อดู) คลิกถัดไป: ตรวจสอบ และสุดท้ายสร้างผู้ใช้ หลังจากเสร็จสิ้น เราสามารถดาวน์โหลดรหัสรหัสการเข้าถึงและรหัสลับได้ในที่สุด (โปรดสังเกตว่าข้อมูลประจำตัวเหล่านี้มีให้ในช่วงเวลาพิเศษนี้ หากเราไม่คัดลอกหรือดาวน์โหลดตอนนี้ เราจะต้องสร้างคู่ใหม่ ):

การเชื่อมต่อกับ AWS ผ่าน SDK
SDK มีให้บริการในภาษาต่างๆ มากมาย สำหรับแอปพลิเคชัน WordPress เราต้องการ SDK สำหรับ PHP ซึ่งสามารถดาวน์โหลดได้จากที่นี่ และคำแนะนำในการติดตั้งอยู่ที่นี่
เมื่อเราสร้างบัคเก็ตแล้ว ข้อมูลรับรองผู้ใช้พร้อม และติดตั้ง SDK แล้ว เราก็เริ่มอัปโหลดไฟล์ไปยัง S3 ได้
การอัพโหลดและดาวน์โหลดไฟล์
เพื่อความสะดวก เรากำหนดข้อมูลรับรองผู้ใช้และภูมิภาคเป็นค่าคงที่ในไฟล์ wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" ในกรณีของเรา เรากำลังใช้ฟังก์ชันครอบตัดภาพแทนตัว ซึ่งรูปแทนตัวจะถูกเก็บไว้ในถัง "ภาพแทนตัวที่ยอดเยี่ยม" อย่างไรก็ตาม ในแอปพลิเคชันของเรา เราอาจมีบัคเก็ตอื่นๆ อีกหลายบัคเก็ตสำหรับฟังก์ชันอื่นๆ ซึ่งต้องใช้การดำเนินการเดียวกันกับการอัปโหลด ดาวน์โหลด และแสดงรายการไฟล์ ดังนั้นเราจึงใช้เมธอดทั่วไปในคลาสนามธรรม AWS_S3 และเราได้รับอินพุต เช่น ชื่อบัคเก็ตที่กำหนดผ่านฟังก์ชัน get_bucket ในการนำคลาสย่อยไปใช้
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } คลาส S3Client เปิดเผย API สำหรับการโต้ตอบกับ S3 เรายกตัวอย่างเมื่อจำเป็นเท่านั้น (ผ่าน lazy-initialization) และบันทึกการอ้างอิงไว้ใต้ $this->s3Client เพื่อใช้งานอินสแตนซ์เดิมต่อไป:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } เมื่อเรากำลังจัดการกับ $file ในแอปพลิเคชันของเรา ตัวแปรนี้มีพาธสัมบูรณ์ไปยังไฟล์ในดิสก์ (เช่น /var/app/current/wp-content/uploads/users/654/leo.jpg ) แต่เมื่ออัปโหลด ไฟล์ไปยัง S3 เราไม่ควรเก็บวัตถุไว้ใต้เส้นทางเดียวกัน โดยเฉพาะอย่างยิ่ง เราต้องลบบิตเริ่มต้นที่เกี่ยวข้องกับข้อมูลระบบ ( /var/app/current ) ด้วยเหตุผลด้านความปลอดภัย และทางเลือกที่เราสามารถลบ /wp-content บิต (เนื่องจากไฟล์ทั้งหมดถูกเก็บไว้ภายใต้โฟลเดอร์นี้ ข้อมูลนี้เป็นข้อมูลที่ซ้ำซ้อน ) เก็บเฉพาะพาธที่สัมพันธ์กับไฟล์ ( /uploads/users/654/leo.jpg ) สะดวก สามารถทำได้โดยลบทุกอย่างหลังจาก WP_CONTENT_DIR ออกจากเส้นทางที่แน่นอน ฟังก์ชั่น get_file และ get_file_relative_path ด้านล่างสลับไปมาระหว่างพาธไฟล์แบบสัมบูรณ์และแบบสัมพันธ์:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }เมื่ออัปโหลดอ็อบเจ็กต์ไปยัง S3 เราสามารถกำหนดได้ว่าใครได้รับอนุญาตให้เข้าถึงอ็อบเจ็กต์และประเภทการเข้าถึง โดยดำเนินการผ่านสิทธิ์รายการควบคุมการเข้าถึง (ACL) ตัวเลือกที่พบบ่อยที่สุดคือการทำให้ไฟล์เป็นส่วนตัว (ACL => “ส่วนตัว”) และทำให้สามารถเข้าถึงได้สำหรับการอ่านบนอินเทอร์เน็ต (ACL => “public-read”) เนื่องจากเราจะต้องร้องขอไฟล์โดยตรงจาก S3 เพื่อแสดงให้ผู้ใช้เห็น เราจึงต้องการ ACL => “public-read”:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }สุดท้าย เราใช้วิธีการในการอัปโหลดอ็อบเจ็กต์ไปยัง และดาวน์โหลดอ็อบเจ็กต์จากบัคเก็ต S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }จากนั้นในคลาสลูกที่นำไปใช้เราจะกำหนดชื่อของที่ฝากข้อมูล:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } สุดท้าย เราเพียงแค่ยกตัวอย่างคลาสเพื่ออัปโหลดอวาตาร์หรือดาวน์โหลดจาก S3 นอกจากนี้ เมื่อเปลี่ยนจากขั้นตอนที่ 1 เป็น 2 และ 2 เป็น 3 เราจำเป็นต้องสื่อสารถึงคุณค่าของ $file เราสามารถทำได้โดยส่งฟิลด์ "file_relative_path" ด้วยค่าของพาธสัมพัทธ์ของ $file ผ่านการดำเนินการ POST (เราไม่ผ่านพาธสัมบูรณ์ด้วยเหตุผลด้านความปลอดภัย: ไม่จำเป็นต้องรวม "/var/www/current" ” ข้อมูลให้บุคคลภายนอกดู ):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...การแสดงไฟล์โดยตรงจาก S3
หากเราต้องการแสดงสถานะกลางของไฟล์หลังจากจัดการในขั้นตอนที่ 2 (เช่น avatar ของผู้ใช้หลังจากครอบตัด) เราต้องอ้างอิงไฟล์โดยตรงจาก S3 URL ไม่สามารถชี้ไปที่ไฟล์บนเซิร์ฟเวอร์ได้ เนื่องจากเราไม่ทราบว่าเซิร์ฟเวอร์ใดจะจัดการกับคำขอนั้นอีกครั้ง
ด้านล่างนี้ เราเพิ่มฟังก์ชัน get_file_url($file) ซึ่งรับ URL สำหรับไฟล์นั้นใน S3 หากใช้ฟังก์ชันนี้ โปรดตรวจสอบให้แน่ใจว่า ACL ของไฟล์ที่อัปโหลด "อ่านแบบสาธารณะ" มิฉะนั้น ผู้ใช้จะไม่สามารถเข้าถึงได้
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }จากนั้น เราก็สามารถรับ URL ของไฟล์บน S3 และพิมพ์รูปภาพได้:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );รายการไฟล์
หากในแอปพลิเคชันของเรา เราต้องการอนุญาตให้ผู้ใช้ดูอวาตาร์ที่อัปโหลดก่อนหน้านี้ทั้งหมด เราสามารถทำได้ สำหรับสิ่งนั้น เราแนะนำฟังก์ชัน get_file_urls ซึ่งแสดงรายการ URL สำหรับไฟล์ทั้งหมดที่จัดเก็บภายใต้พาธที่แน่นอน (ในเงื่อนไข S3 จะเรียกว่าคำนำหน้า):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }จากนั้น หากเราจัดเก็บอวาตาร์แต่ละตัวไว้ใต้พาธ “/users/${user_id}/“ โดยการส่งคำนำหน้านี้ เราจะได้รับรายการไฟล์ทั้งหมด:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }บทสรุป
ในบทความนี้ เราได้สำรวจวิธีการใช้โซลูชันการจัดเก็บอ็อบเจ็กต์บนคลาวด์เพื่อทำหน้าที่เป็นที่เก็บข้อมูลทั่วไปในการจัดเก็บไฟล์สำหรับแอปพลิเคชันที่ปรับใช้บนเซิร์ฟเวอร์หลายเครื่อง สำหรับโซลูชัน เราเน้นที่ AWS S3 และดำเนินการเพื่อแสดงขั้นตอนที่จำเป็นในการผสานรวมกับแอปพลิเคชัน: การสร้างบัคเก็ต การตั้งค่าการอนุญาตของผู้ใช้ และการดาวน์โหลดและติดตั้ง SDK สุดท้าย เราได้อธิบายวิธีหลีกเลี่ยงข้อผิดพลาดด้านความปลอดภัยในแอปพลิเคชัน และได้เห็นตัวอย่างโค้ดที่สาธิตวิธีดำเนินการขั้นพื้นฐานที่สุดใน S3 ได้แก่ การอัปโหลด ดาวน์โหลด และแสดงรายการไฟล์ ซึ่งแต่ละโค้ดแทบไม่ต้องใช้โค้ดสองสามบรรทัด ความเรียบง่ายของโซลูชันแสดงให้เห็นว่าการรวมบริการคลาวด์เข้ากับแอปพลิเคชันนั้นไม่ใช่เรื่องยาก และนักพัฒนาที่ไม่ค่อยมีประสบการณ์กับคลาวด์ก็สามารถทำได้เช่นกัน