
คู่มือง่าย ๆ ในการสร้างระบบการเรียนรู้ของเครื่องแนะนำ [2022]
เผยแพร่แล้ว: 2021-03-11ธุรกิจอินเทอร์เน็ตในปัจจุบันส่วนใหญ่มักจะนำเสนอประสบการณ์ผู้ใช้ที่เป็นส่วนตัว ระบบคำแนะนำในการเรียนรู้ด้วยเครื่อง เป็นแอปพลิเคชันบนเว็บที่ปรับให้เหมาะกับแต่ละบุคคลซึ่งให้คำแนะนำส่วนบุคคลเกี่ยวกับเนื้อหาที่พวกเขาอาจสนใจแก่ผู้ใช้ ระบบการแนะนำเรียกอีกอย่างว่าระบบผู้แนะนำ
สารบัญ
ระบบการแนะนำคืออะไร?
ระบบ การ แนะนำในแมชชีนเลิ ร์นนิง สามารถคาดการณ์ความต้องการของผู้ใช้หลายๆ อย่าง และแนะนำสิ่งสำคัญที่อาจจำเป็นได้
ระบบคำแนะนำเป็นหนึ่งในการประยุกต์ใช้เทคโนโลยีแมชชีนเลิร์นนิงที่แพร่หลายที่สุดสำหรับธุรกิจ
เราสามารถค้นหาระบบแนะนำขนาดใหญ่ในร้านค้าปลีก วิดีโอออนดีมานด์ หรือการสตรีมเพลง
ระบบคำแนะนำพยายามสร้างหุ่นยนต์บางส่วนของแบบจำลองการเปิดเผยข้อมูลที่ไม่เหมือนใคร โดยที่บุคคลพยายามค้นหาผู้อื่นที่มีรสนิยมใกล้เคียงกัน และขอให้พวกเขาแนะนำรายการใหม่ในภายหลัง
เข้าร่วม หลักสูตรแมชชีนเลิ ร์นนิง ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว

ประเภทของระบบคำแนะนำ
- ส่วนบุคคล- คำแนะนำตามความสนใจของคุณ
- ไม่ใช่ส่วนบุคคล- สิ่งที่ลูกค้ารายอื่นกำลังดูอยู่ในขณะนี้
ความต้องการระบบข้อเสนอแนะคืออะไร?
เหตุผลสำคัญประการหนึ่งที่เราต้องการ ระบบคำแนะนำในการเรียนรู้ของเครื่อง ก็คือ เนื่องจากอินเทอร์เน็ต ผู้คนจึงมีตัวเลือกมากมายเกินกว่าจะเลือกซื้อได้
ในอดีต ผู้คนเคยซื้อของที่ร้านค้าจริงซึ่งมีสินค้าจำกัด
ตัวอย่างเช่น จำนวนภาพยนตร์ที่วางที่ร้านเช่าวิดีโอขึ้นอยู่กับขนาดของร้าน เว็บอนุญาตให้ผู้คนเข้าถึงแหล่งข้อมูลออนไลน์มากมาย Netflix มีคอลเลกชั่นภาพยนตร์มากมาย เมื่อปริมาณข้อมูลที่มีอยู่เพิ่มขึ้น ปัญหาใหม่ก็เกิดขึ้นและผู้คนพบว่าเป็นการยากที่จะเลือกจากตัวเลือกที่หลากหลาย จึงมีการนำระบบการแนะนำมาใช้
ระบบแนะนำใช้ที่ไหน?
- เว็บไซต์อีคอมเมิร์ซขนาดใหญ่ใช้เครื่องมือนี้เพื่อแนะนำสินค้าที่ผู้บริโภคอาจต้องการซื้อ
- การปรับแต่งเว็บ
ระบบคำแนะนำทำงานอย่างไร?
- เราสามารถแนะนำสิ่งต่าง ๆ ให้กับลูกค้าที่โดยทั่วไปแล้วเป็นที่นิยมในหมู่ลูกค้ารายอื่น
- เราสามารถแบ่งลูกค้าออกเป็นหลายกลุ่มตามการเลือกผลิตภัณฑ์และแนะนำสิ่งที่พวกเขาอาจซื้อ
เทคนิคทั้งสองข้างต้นมีข้อเสีย ในกรณีแรก สิ่งที่ได้รับความนิยมและเป็นที่นิยมมากที่สุดจะเหมือนกันสำหรับลูกค้าทุกราย ดังนั้น ทุกคนคงได้รับคำแนะนำที่คล้ายคลึงกัน ในขณะที่ในครั้งที่สอง เมื่อจำนวนลูกค้าเพิ่มขึ้น จำนวนสิ่งที่เน้นเป็นคำแนะนำก็จะเพิ่มขึ้นเช่นกัน ดังนั้นจึงเป็นการยากที่จะจัดกลุ่มลูกค้าทั้งหมดภายใต้ส่วนต่างๆ
ตอนนี้เราจะมาดูกันว่าระบบคำแนะนำทำงานอย่างไร
การเก็บรวบรวมข้อมูล
นี่เป็นขั้นตอนแรกที่สำคัญที่สุดในการสร้างระบบการแนะนำ ข้อมูลมักถูกรวบรวมโดยสองวิธี: ชัดแจ้งและโดยนัย
ข้อมูลที่โจ่งแจ้งจะเป็นข้อมูลที่ให้โดยเจตนา กล่าวคือ การมีส่วนร่วมของลูกค้า เช่น บทวิจารณ์ภาพยนตร์ ข้อมูลโดยนัยคือข้อมูลที่ไม่ได้รับโดยเจตนา แต่รวบรวมจากสตรีมข้อมูลที่เข้าถึงได้ เช่น การคลิก ประวัติการค้นหา ประวัติคำขอ และอื่นๆ
ที่เก็บข้อมูล
ปริมาณข้อมูลบ่งบอกถึงความซื่อสัตย์ของคำแนะนำของแบบจำลอง ชนิดข้อมูลมีบทบาทสำคัญในการเลือกข้อมูลจากประชากรจำนวนมาก ความจุสามารถประกอบด้วยฐานข้อมูล SQL และ NoSQL มาตรฐานหรือรูปแบบการจัดเก็บบทความ
การกรองข้อมูล
หลังจากรวบรวมและจัดเก็บ ข้อมูลนี้จะต้องถูกกรองเพื่อดึงข้อมูลเพื่อให้คำแนะนำขั้นสุดท้าย อัลกอริธึมต่างๆ ทำให้กระบวนการกรองง่ายขึ้น
อัลกอริทึมสำหรับระบบคำแนะนำ
ระบบซอฟต์แวร์ให้คำแนะนำแก่ผู้ใช้โดยใช้การทำซ้ำในอดีตและคุณลักษณะของรายการ/ผู้ใช้
มีสองวิธีในการสร้างระบบการแนะนำ
1. คำแนะนำตามเนื้อหา
- ใช้แอตทริบิวต์ของรายการ/ผู้ใช้
- แนะนำรายการที่คล้ายกับที่ผู้ใช้เคยชอบในอดีต
2. การกรองการทำงานร่วมกัน
- รายการแนะนำโดยผู้ใช้ที่คล้ายกัน
- เปิดใช้งานการสำรวจเนื้อหาที่หลากหลาย
คำแนะนำตามเนื้อหา
แมชชีนเลิร์นนิงภายใต้การดูแลจะกระตุ้นตัวแยกประเภทเพื่อแยกความแตกต่างระหว่างไอเท็มผู้ใช้ที่น่าสนใจและไม่น่าสนใจ
วัตถุประสงค์ของระบบการแนะนำคือการคาดการณ์คะแนนสำหรับสิ่งที่ไม่ได้รับการจัดอันดับของผู้ใช้ แนวคิดพื้นฐานที่อยู่เบื้องหลังการกรองเนื้อหาคือทุกอย่างมีไฮไลท์ x อยู่เล็กน้อย

ตัวอย่างเช่น ภาพยนตร์เรื่อง “Love at Last” เป็นภาพยนตร์โรแมนติกและได้คะแนนสูงสำหรับไฮไลท์ x1 แต่คะแนน x2 ต่ำ
( ข้อมูล การ จัดอันดับ ภาพยนตร์ )
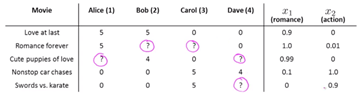
แหล่งที่มา
แต่ละคนมีตัวแปร θ ที่บอกว่าพวกเขารักหนังโรแมนติกมากแค่ไหน และรักหนังแอคชั่นมากแค่ไหน
ถ้า θ = [1, 0.1] บุคคลนั้นชอบหนังโรแมนติกแต่ไม่ใช่หนังแอคชั่น
เราสามารถหาค่า θ ที่เหมาะสมที่สุดได้ด้วยการถดถอยเชิงเส้นสำหรับทุกคน
(โน้ต)
r(i,j): 1 ถ้าผู้ใช้ j ได้ให้คะแนนภาพยนตร์ i (0 อย่างอื่น)
y(i,j): ผู้ใช้ j ให้คะแนนในภาพยนตร์ i (ถ้ากำหนดไว้)
θ(j): พารามิเตอร์เวกเตอร์ผู้ใช้
x(i): ภาพยนตร์ i นำเสนอเวกเตอร์
คะแนนที่คาดคะเน [ผู้ใช้ j, หนัง i]: (θ(j))ᵀx(i)
m(j): # จำนวนภาพยนตร์ของผู้ใช้ j อัตรา
nᵤ: # ของผู้ใช้
n: # คุณสมบัติของภาพยนตร์
อ่าน: แนวคิดและหัวข้อโครงการการเรียนรู้ของเครื่อง
การกรองการทำงานร่วมกัน
ข้อเสียของการกรองเนื้อหาคือต้องการข้อมูลด้านข้างสำหรับทุกอย่าง
ตัวอย่างเช่น การจำแนกประเภทอย่างโรแมนติกและแอ็คชั่นเป็นข้อมูลด้านข้างของภาพยนตร์ การหาคนที่ดูหนังและเพิ่มข้อมูลด้านข้างสำหรับภาพยนตร์แต่ละเรื่องมีค่าใช้จ่ายสูง
สมมติฐานพื้นฐาน
- ผู้ใช้ที่มีความสนใจคล้ายกันมีความชอบร่วมกัน
- มีการตั้งค่าผู้ใช้จำนวนมากเพียงพอ
แนวทางหลัก
- อิงจากผู้ใช้
- ตามรายการ
เราจะแสดงรายการคุณสมบัติทั้งหมดของภาพยนตร์ได้อย่างไร? เกิดอะไรขึ้นถ้าใครอยากเพิ่มคุณสมบัติใหม่? เราควรเพิ่มคุณสมบัติใหม่ให้กับภาพยนตร์ทุกเรื่องหรือไม่?
การกรองการทำงานร่วมกันช่วยแก้ปัญหานี้ได้
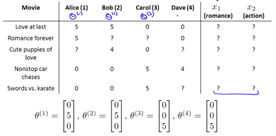
( ทำนายคุณสมบัติของหนัง ) ที่มา
ปัญหาและการบำรุงรักษาด้วยระบบคำแนะนำในการเรียนรู้ของเครื่อง
ปัญหา
- โครงสร้างการป้อนข้อมูลของผู้ใช้ที่สรุปไม่ได้
- กำลังมองหาผู้ใช้ที่จะมีส่วนร่วมในการศึกษาวิจารณ์
- การคำนวณที่อ่อนแอ
- ผลลัพธ์ไม่ดี
- ข้อมูลแย่
- ขาดข้อมูล
- การควบคุมความเป็นส่วนตัว (อาจไม่ร่วมมือกับใบเสร็จอย่างชัดเจน)
การซ่อมบำรุง
- ราคาแพง
- ข้อมูลล้าสมัย
- คุณภาพของข้อมูล (ขนาดใหญ่ การพัฒนาพื้นที่วงกลม)
ระบบคำแนะนำในการเรียนรู้ของเครื่อง มีรากฐานมาจากพื้นที่การวิจัยที่หลากหลาย เช่น การดึงข้อมูล การจัดประเภทข้อความ และการใช้วิธีการที่แตกต่างจากส่วนต่างๆ เช่น การเรียนรู้ของเครื่อง การทำเหมืองข้อมูล และระบบฐานความรู้
อนาคตของระบบคำแนะนำ
- Extract เข้าใจการประเมินเชิงลบผ่านการตรวจสอบสิ่งของที่นำกลับมา
- วิธีการรวมพื้นที่ท้องถิ่นเข้ากับข้อเสนอ
- ระบบจะใช้ระบบคำแนะนำในภายหลังเพื่อคาดการณ์ความสนใจสำหรับสินค้า ซึ่งช่วยให้ติดต่อกลับมาที่เครือข่ายร้านค้าได้
อัพเกรดอาชีพของคุณในการเรียนรู้ของเครื่องด้วย upGrad
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT -B สถานะศิษย์เก่า 5+ โครงการหลักที่ปฏิบัติได้จริง & ความช่วยเหลืองานกับ บริษัท ชั้นนำ
คุณสามารถหาระบบการแนะนำในชีวิตจริงได้ที่ไหน?
ระบบการแนะนำหรือระบบผู้แนะนำสามารถกำหนดแนวคิดเป็นแอปพลิเคชันการกรองข้อมูลที่ใช้การเรียนรู้ของเครื่องเพื่อการทำงาน ปัจจุบันระบบคำแนะนำใช้กันอย่างแพร่หลายเพื่อส่งคำแนะนำไปยังกลุ่มผู้ใช้เฉพาะหรือผู้บริโภคแต่ละรายเกี่ยวกับผลิตภัณฑ์หรือบริการที่เกี่ยวข้องมากที่สุด โดยจะค้นหารูปแบบเฉพาะที่ซ่อนอยู่ภายในข้อมูลพฤติกรรมของลูกค้า รวบรวมข้อมูลโดยชัดแจ้งหรือโดยปริยาย แล้วสร้างคำแนะนำตามนั้น แบรนด์ที่มีชื่อเสียงที่สุดบางแบรนด์ที่ใช้ระบบแนะนำ ได้แก่ Google, Netflix, Facebook และ Amazon รวมถึงองค์กรระดับโลกอื่นๆ จากการศึกษาพบว่า 35 เปอร์เซ็นต์ของการซื้อโดยรวมของ Amazon เป็นผลมาจากการแนะนำผลิตภัณฑ์
บริษัทใดบ้างที่ใช้ปัญญาประดิษฐ์ในปัจจุบัน
นับตั้งแต่การปรับปรุงประสบการณ์ของลูกค้าไปจนถึงการเพิ่มประสิทธิภาพทางธุรกิจในอุตสาหกรรมต่างๆ และการพัฒนาประสิทธิภาพในการดำเนินงาน องค์กรต่างๆ ต่างลงทุนอย่างหนักในด้านปัญญาประดิษฐ์ในปัจจุบัน ในความเป็นจริง ทั้งที่รู้และไม่รู้ เราทุกคนต่างก็เผชิญกับปัญญาประดิษฐ์ในชีวิตประจำวันของเราเช่นกัน นอกเหนือจาก Tesla, Apple และ Google แล้ว องค์กรที่มีชื่อเสียงอื่น ๆ ที่ประสบความสำเร็จในการใช้ AI ในปัจจุบัน ได้แก่ Twitter, Uber, Amazon, YouTube และอื่น ๆ Twitter ได้ใช้ปัญญาประดิษฐ์และการประมวลผลภาษาธรรมชาติมาตั้งแต่ปี 2560 และ Netflix มุ่งเน้นที่ทั้งหมด การดำเนินการเกี่ยวกับข้อมูลและ AI
งาน AI อันดับต้น ๆ ในอินเดียในปัจจุบันคืออะไร?
ด้วยการพัฒนาครั้งใหญ่อย่างต่อเนื่องในด้านปัญญาประดิษฐ์ มีความต้องการที่ไม่เคยมีมาก่อนในตลาดสำหรับผู้เชี่ยวชาญด้านปัญญาประดิษฐ์ เป็นผลให้อุตสาหกรรมดูมีแนวโน้มค่อนข้างดีสำหรับผู้ที่ต้องการแกะสลักเฉพาะในด้านเทคโนโลยีนี้ด้วยตัวเลือกงานที่น่าตื่นเต้นมากมายที่จ่ายอย่างดีเช่นกัน งานอันดับต้นๆ ในสาขาปัญญาประดิษฐ์ในปัจจุบัน ได้แก่ บทบาทของนักวิทยาศาสตร์ข้อมูลหลัก วิศวกรวิจัย AI นักวิทยาศาสตร์คอมพิวเตอร์ วิศวกรการเรียนรู้ของเครื่องจักร โดยมีเงินเดือนประจำปีตั้งแต่ INR 9.5 ถึง 18 แสนบาท และมากกว่านั้นตามประสบการณ์การทำงาน , ชุดทักษะ และปัจจัยอื่นๆ