
เครื่องมือข้อมูลเชิงปริมาณสำหรับนักออกแบบ UX
เผยแพร่แล้ว: 2022-03-10นักออกแบบ UX หลายคนค่อนข้างกลัวข้อมูล โดยเชื่อว่าต้องใช้ความรู้ทางสถิติและคณิตศาสตร์อย่างลึกซึ้ง แม้ว่านั่นอาจเป็นความจริงสำหรับวิทยาศาสตร์ข้อมูลขั้นสูง แต่ก็ไม่เป็นความจริงสำหรับการวิเคราะห์ข้อมูลการวิจัยขั้นพื้นฐานที่นักออกแบบ UX ส่วนใหญ่ต้องการ เนื่องจากเราอาศัยอยู่ในโลกที่ขับเคลื่อนด้วยข้อมูลมากขึ้นเรื่อยๆ การรู้เท่าทันข้อมูลพื้นฐานจึงมีประโยชน์สำหรับมืออาชีพเกือบ ทุกคน ไม่ใช่แค่นักออกแบบ UX เท่านั้น
Aaron Gitlin นักออกแบบการโต้ตอบของ Google ให้เหตุผลว่านักออกแบบหลายคนยังไม่ได้ขับเคลื่อนด้วยข้อมูล:
“ในขณะที่ธุรกิจจำนวนมากส่งเสริมตนเองว่าขับเคลื่อนด้วยข้อมูล นักออกแบบส่วนใหญ่ขับเคลื่อนด้วยสัญชาตญาณ การทำงานร่วมกัน และวิธีการวิจัยเชิงคุณภาพ”
— Aaron Gitlin, “การเป็นนักออกแบบที่มีความรู้ด้านข้อมูล”
ในบทความนี้ ฉันต้องการให้ความรู้และเครื่องมือแก่นักออกแบบ UX เพื่อรวมข้อมูลเข้ากับกิจวัตรประจำวันของพวกเขา
แต่ก่อนอื่น แนวคิดของข้อมูลบางอย่าง
ในบทความนี้ ผมจะพูดถึงข้อมูลที่มีโครงสร้าง ซึ่งหมายถึงข้อมูลที่สามารถแสดงในตาราง โดยมีแถวและคอลัมน์ ข้อมูลที่ไม่มีโครงสร้างซึ่งเป็นหัวเรื่องในตัวเองนั้นวิเคราะห์ได้ยากกว่า ดังที่ Devin Pickell (ผู้เชี่ยวชาญด้านการตลาดเนื้อหาที่ G2 Crowd เขียนเกี่ยวกับข้อมูลและการวิเคราะห์) ชี้ให้เห็นในบทความของเขาเรื่อง “Structured vs Unstructured Data – What's the Difference?” หากข้อมูลที่มีโครงสร้างสามารถแสดงในรูปแบบตารางได้ แนวคิดหลักคือ:
ชุดข้อมูล
ชุดข้อมูลทั้งหมดที่เราตั้งใจจะวิเคราะห์ อาจเป็นเช่นตาราง Excel รูปแบบที่นิยมอีกรูปแบบหนึ่งสำหรับการจัดเก็บชุดข้อมูลคือไฟล์ค่าที่คั่นด้วยเครื่องหมายจุลภาค (CSV) ไฟล์ CSV เป็นไฟล์ข้อความธรรมดาที่ใช้เก็บข้อมูลแบบตาราง แถว CSV แต่ละแถวสอดคล้องกับแถวในตาราง และแต่ละแถว CSV มีค่าคั่น (ปกติ) ด้วยเครื่องหมายจุลภาค ซึ่งสอดคล้องกับเซลล์ตาราง
จุดข้อมูล
แถวเดียวจากตารางชุดข้อมูลคือจุดข้อมูล ด้วยวิธีนี้ ชุดข้อมูลคือชุดของจุดข้อมูล
ตัวแปรข้อมูล
ค่าเดียวจากแถวจุดข้อมูลแสดงถึงตัวแปรข้อมูล กล่าวง่ายๆ ก็คือ เซลล์ตาราง เราสามารถมีตัวแปรข้อมูลได้สองประเภท: ตัวแปรเชิงคุณภาพและตัวแปรเชิงปริมาณ ตัวแปรเชิงคุณภาพ (หรือที่เรียกว่าตัวแปรตามหมวดหมู่) มีชุดค่าที่ไม่ต่อเนื่อง เช่น color = red/green/blue ตัวแปรเชิงปริมาณมีค่าตัวเลข เช่น height = 167 ตัวแปรเชิงปริมาณซึ่งแตกต่างจากตัวแปรเชิงคุณภาพสามารถรับค่าใดก็ได้
การสร้างโครงการข้อมูลของเรา
ตอนนี้เรารู้พื้นฐานแล้ว ถึงเวลาที่จะทำให้มือสกปรกและสร้างโครงการข้อมูลแรกของเรา ขอบเขตของโปรเจ็กต์คือการวิเคราะห์ชุดข้อมูลโดยผ่านโฟลว์ข้อมูลทั้งหมดของการนำเข้า ประมวลผล และวางแผนข้อมูล อันดับแรก เราจะเลือกชุดข้อมูล จากนั้นเราจะดาวน์โหลดและติดตั้งเครื่องมือสำหรับวิเคราะห์ข้อมูล
ชุดข้อมูลรถยนต์
สำหรับจุดประสงค์ของบทความนี้ ฉันเลือกชุดข้อมูลรถยนต์ เพราะมันเรียบง่ายและเข้าใจง่าย การวิเคราะห์ข้อมูลจะยืนยันสิ่งที่เรารู้อยู่แล้วเกี่ยวกับรถยนต์ ซึ่งเป็นเรื่องปกติ เนื่องจากเรามุ่งเน้นที่การไหลของข้อมูลและเครื่องมือ
เราสามารถดาวน์โหลดชุดข้อมูลรถยนต์มือสองจาก Kaggle ซึ่งเป็นหนึ่งในแหล่งข้อมูลฟรีที่ใหญ่ที่สุด คุณจะต้องลงทะเบียนก่อน
หลังจากดาวน์โหลดไฟล์แล้วให้เปิดและดู มันเป็นไฟล์ CSV ที่ใหญ่มาก แต่คุณควรเข้าใจส่วนสำคัญ บรรทัดในไฟล์นี้จะมีลักษณะดังนี้:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3อย่างที่คุณเห็น จุดข้อมูลนี้มีตัวแปรหลายตัวคั่นด้วยเครื่องหมายจุลภาค เนื่องจากตอนนี้เรามีชุดข้อมูลแล้ว เรามาพูดถึงเครื่องมือกันสักหน่อย
เครื่องมือทางการค้า
เราจะใช้ภาษา R และ RStudio เพื่อวิเคราะห์ชุดข้อมูล R เป็นภาษาที่ได้รับความนิยมและเรียนรู้ได้ง่าย ไม่เพียงแต่ใช้โดยนักวิทยาศาสตร์ด้านข้อมูลเท่านั้น แต่ยังรวมถึงผู้คนในตลาดการเงิน ยารักษาโรค และอื่นๆ อีกมากมาย RStudio คือสภาพแวดล้อมที่มีการพัฒนาโปรเจ็กต์ R และมีเวอร์ชันฟรี ซึ่งเพียงพอสำหรับความต้องการของเราในฐานะนักออกแบบ UX
มีแนวโน้มว่านักออกแบบ UX บางคนใช้ Excel สำหรับเวิร์กโฟลว์ข้อมูล ถ้านั่นหมายถึงคุณ ให้ลองใช้ R ดูสิ มีโอกาสดีที่คุณจะชอบ เนื่องจากเรียนรู้ได้ง่าย ยืดหยุ่นและมีประสิทธิภาพมากกว่า Excel การเพิ่ม R ลงในชุดเครื่องมือของคุณจะสร้างความแตกต่างได้
การติดตั้งเครื่องมือ
ขั้นแรก เราต้องดาวน์โหลดและติดตั้ง R และ RStudio คุณควรติดตั้ง R ก่อน จากนั้นจึง RStudio ขั้นตอนการติดตั้งสำหรับทั้ง R และ RStudio นั้นเรียบง่ายและตรงไปตรงมา
การติดตั้งโครงการ
เมื่อการติดตั้งเสร็จสิ้น ให้สร้างโฟลเดอร์โปรเจ็กต์ — ฉันเรียกมันว่า used-cars-prj ในโฟลเดอร์นั้น ให้สร้างโฟลเดอร์ย่อยชื่อ data จากนั้นคัดลอกไฟล์ชุดข้อมูล (ดาวน์โหลดจาก Kaggle) ลงในโฟลเดอร์นั้นแล้วเปลี่ยนชื่อเป็น used-cars.csv กลับไปที่โฟลเดอร์โครงการของเรา ( used-cars-prj ) และสร้างไฟล์ข้อความธรรมดาชื่อ used-cars.r คุณควรลงเอยด้วยโครงสร้างเดียวกับในภาพหน้าจอด้านล่าง
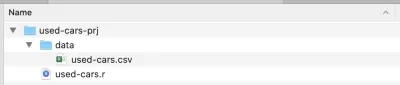
ตอนนี้เรามีโครงสร้างโฟลเดอร์แล้ว เราสามารถเปิด RStudio และสร้างโปรเจ็กต์ R ใหม่ได้ เลือก New Project... จากเมนู File และเลือกตัวเลือกที่สอง Existing Directory จากนั้นเลือกไดเรกทอรีโครงการ ( used-cars-prj ) สุดท้ายให้กดปุ่ม สร้างโครงการ และคุณทำเสร็จแล้ว เมื่อสร้างโปรเจ็กต์แล้ว ให้เปิด used-cars.r ใน RStudio — นี่คือไฟล์ที่เราจะเพิ่มโค้ด R ทั้งหมดของเรา
การนำเข้าข้อมูล
เราจะเพิ่มบรรทัดแรกของเราใน used-cars.r เพื่ออ่านข้อมูลจากไฟล์ used-cars.csv โปรดจำไว้ว่าไฟล์ CSV เป็นเพียงไฟล์ข้อความธรรมดาที่ใช้สำหรับจัดเก็บข้อมูล รหัส R บรรทัดแรกของเราจะมีลักษณะดังนี้:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") อาจดูน่ากลัวเล็กน้อย แต่จริงๆ แล้วไม่ใช่เลย เพราะนี่คือบรรทัดที่ซับซ้อนที่สุดในบทความทั้งหมด สิ่งที่เรามีคือฟังก์ชัน read.csv ซึ่งรับพารามิเตอร์สามตัว
พารามิเตอร์แรกคือไฟล์ที่จะอ่าน ในกรณีของเรา used-cars.csv ซึ่งอยู่ในโฟลเดอร์ ข้อมูล พารามิเตอร์ที่สอง stringsAsFactors=FALSE ถูกตั้งค่าเพื่อให้แน่ใจว่าสตริงเช่น “BMW” หรือ “Audi” ไม่ถูกแปลงเป็นปัจจัย (ศัพท์แสง R สำหรับข้อมูลหมวดหมู่) เมื่อคุณจำได้ ตัวแปรเชิงคุณภาพหรือเชิงหมวดหมู่สามารถมีค่าที่ไม่ต่อเนื่องได้เท่านั้น เช่น red/green/blue . สุดท้าย พารามิเตอร์ที่สาม sep="," ระบุชนิดของตัวคั่นที่ใช้แยกค่าในไฟล์ CSV: เครื่องหมายจุลภาค
หลังจากอ่านไฟล์ CSV ข้อมูลจะถูกเก็บไว้ในออบเจกต์ data frame ของ cars กรอบข้อมูล เป็นโครงสร้างข้อมูลสองมิติ (เช่น ตาราง Excel) ซึ่งมีประโยชน์มากใน R เพื่อจัดการข้อมูล หลังจากแนะนำไลน์และใช้งานแล้ว ระบบจะสร้างกรอบข้อมูล cars ให้คุณ หากคุณดูที่ด้านบนขวาใน RStudio คุณจะสังเกตเห็นกรอบข้อมูล cars ในส่วน ข้อมูล ใต้แท็บ สภาพแวดล้อม หากคุณดับเบิลคลิกที่ รถยนต์ แท็บใหม่จะเปิดขึ้นในจตุภาคซ้ายบนของ RStudio และจะแสดงกรอบข้อมูล cars อย่างที่คุณคาดไว้ ดูเหมือนว่าตาราง Excel
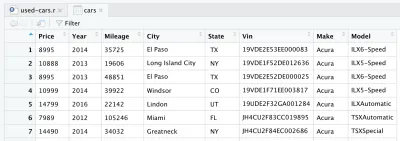
นี่คือข้อมูลดิบที่เราดาวน์โหลดจาก Kaggle จริงๆ แต่เนื่องจากเราต้องการวิเคราะห์ข้อมูล เราจึงต้องประมวลผลชุดข้อมูลของเราก่อน
การประมวลผลข้อมูล
ในการประมวลผล เราหมายถึงการลบ แปลง หรือเพิ่มข้อมูลลงในชุดข้อมูลของเรา เพื่อเตรียมพร้อมสำหรับประเภทของการวิเคราะห์ที่เราต้องการดำเนินการ เรามีข้อมูลใน data frame object ดังนั้นตอนนี้เราจำเป็นต้องติดตั้ง dplyr library ซึ่งเป็นไลบรารีที่ทรงพลังสำหรับจัดการข้อมูล ในการติดตั้งไลบรารีในสภาพแวดล้อม R ของเรา เราต้องเขียนบรรทัดต่อไปนี้ที่ด้านบนสุดของไฟล์ R ของเรา
install.packages("dplyr")จากนั้น เพื่อเพิ่มไลบรารีลงในโครงการปัจจุบันของเรา เราจะใช้บรรทัดถัดไป:
library(dplyr) เมื่อเพิ่มไลบรารี dplyr ในโครงการของเราแล้ว เราสามารถเริ่มประมวลผลข้อมูลได้ เรามีชุดข้อมูลขนาดใหญ่จริงๆ และเราต้องการเพียงข้อมูลที่แสดงถึงผู้ผลิตรถยนต์และรุ่นเดียวกันเท่านั้น เพื่อที่จะสัมพันธ์กับราคา เราจะใช้รหัส R ต่อไปนี้เพื่อเก็บเฉพาะข้อมูลเกี่ยวกับ BMW 3 Series และลบส่วนที่เหลือ แน่นอน คุณสามารถเลือกผู้ผลิตและรุ่นอื่นๆ จากชุดข้อมูล และคาดว่าจะมีลักษณะข้อมูลเหมือนกัน
cars <- cars %>% filter(Make == "BMW", Model == "3")ตอนนี้ เรามีชุดข้อมูลที่สามารถจัดการได้มากขึ้น แม้ว่าจะมีจุดข้อมูลมากกว่า 11,000 จุด ซึ่งตรงกับวัตถุประสงค์ที่เราตั้งใจไว้ นั่นคือ เพื่อวิเคราะห์ราคารถยนต์ อายุ และการกระจายระยะทาง และความสัมพันธ์ระหว่างกัน สำหรับเรื่องนั้น เราจำเป็นต้องเก็บเฉพาะคอลัมน์ "ราคา" "ปี" และ "ไมล์สะสม" และนำส่วนที่เหลือออก ให้ดำเนินการตามบรรทัดต่อไปนี้
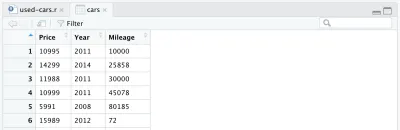
cars <- cars %>% select(Price, Year, Mileage)หลังจากลบคอลัมน์อื่นแล้ว data frame ของเราจะมีลักษณะดังนี้:

มีการเปลี่ยนแปลงอีกอย่างหนึ่งที่เราต้องการจะทำกับชุดข้อมูลของเรา นั่นคือ เพื่อแทนที่ปีที่ผลิตด้วยอายุของรถ เราสามารถเพิ่มสองบรรทัดต่อไปนี้ อันแรกเพื่อคำนวณอายุ อันที่สองเพื่อเปลี่ยนชื่อคอลัมน์
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)สุดท้าย กรอบข้อมูลที่ประมวลผลเต็มรูปแบบของเรามีลักษณะดังนี้:
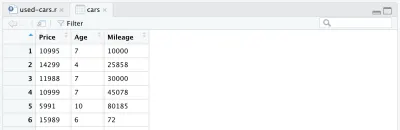
ณ จุดนี้ รหัส R ของเราจะมีลักษณะดังนี้ และนั่นคือทั้งหมดสำหรับการประมวลผลข้อมูล ตอนนี้เราสามารถเห็นได้ว่าภาษา R นั้นง่ายและมีประสิทธิภาพเพียงใด เราได้ประมวลผลชุดข้อมูลเริ่มต้นค่อนข้างมากด้วยโค้ดเพียงไม่กี่บรรทัด
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)การวิเคราะห์ข้อมูล
ข้อมูลของเราอยู่ในรูปแบบที่ถูกต้องแล้ว ดังนั้นเราจึงสามารถแปลงร่างได้ ดังที่ได้กล่าวไปแล้ว เราจะมุ่งเน้นไปที่สองด้าน: การแจกแจงตัวแปรแต่ละตัว และความสัมพันธ์ระหว่างตัวแปรทั้งสอง การกระจายตัวแปรช่วยให้เราเข้าใจว่าอะไรถือเป็นราคากลางหรือสูงสำหรับรถยนต์มือสอง — หรือเปอร์เซ็นต์ของรถยนต์ที่สูงกว่าราคาเฉพาะ เช่นเดียวกับอายุและระยะของรถยนต์ ในทางกลับกัน ความสัมพันธ์จะเป็นประโยชน์ในการทำความเข้าใจว่าตัวแปรต่างๆ เช่น อายุและระยะทางมีความสัมพันธ์กันอย่างไร
ที่กล่าวว่า เราจะใช้การสร้างภาพข้อมูลสองประเภท: ฮิสโตแกรมสำหรับการกระจายตัวแปร และแผนภาพกระจายสำหรับความสัมพันธ์
การกระจายราคา
การพล็อตฮิสโตแกรมราคารถในภาษา R นั้นง่ายดังนี้:
hist(cars$Price)เคล็ดลับเล็กน้อย: หากคุณอยู่ใน RStudio คุณสามารถเรียกใช้โค้ดทีละบรรทัด ตัวอย่างเช่น ในกรณีของเรา คุณต้องเรียกใช้เฉพาะบรรทัดด้านบนเพื่อแสดงฮิสโตแกรม ไม่จำเป็นต้องเรียกใช้โค้ดทั้งหมดอีกครั้ง เนื่องจากคุณเคยรันมาแล้วครั้งหนึ่งแล้ว ฮิสโตแกรมควรมีลักษณะดังนี้:
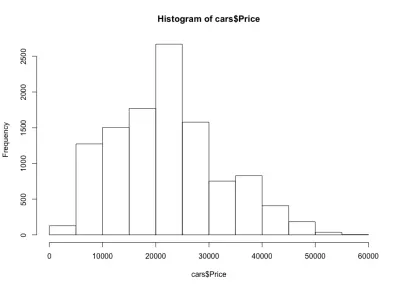
หากเราดูที่ฮิสโตแกรม เราจะสังเกตเห็นการกระจายราคาของรถยนต์แบบกระดิ่ง ซึ่งเป็นสิ่งที่เราคาดไว้ รถส่วนใหญ่อยู่ตรงกลาง และเรามีรถน้อยลงเรื่อยๆ เมื่อเราเคลื่อนไปแต่ละข้าง เกือบ 80% ของรถยนต์อยู่ระหว่าง 10,000 ถึง 30,000 ดอลลาร์สหรัฐฯ และเรามีรถยนต์สูงสุด 2,500 คันระหว่าง 20,000 ถึง 25,000 ดอลลาร์สหรัฐฯ ทางด้านซ้าย เรามีรถประมาณ 150 คันที่ราคาต่ำกว่า 5,000 เหรียญสหรัฐ และทางด้านขวาจะมีน้อยกว่านั้นอีก เราสามารถเห็นได้อย่างง่ายดายว่าแผนดังกล่าวมีประโยชน์เพียงใดในการรับข้อมูลเชิงลึก
การกระจายอายุ
เช่นเดียวกับราคาของรถยนต์ เราจะใช้บรรทัดที่คล้ายกันเพื่อพล็อตฮิสโตแกรมอายุของรถยนต์
hist(cars$Age)และนี่คือฮิสโตแกรม:
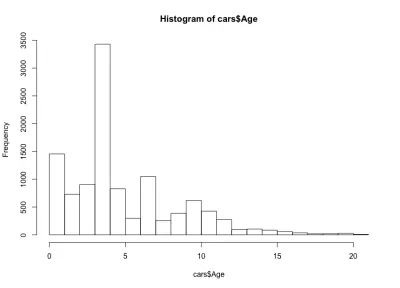
คราวนี้ฮิสโตแกรมดูไม่เป็นธรรมชาติ — แทนที่จะเป็นรูประฆังธรรมดา เรามีระฆังสี่อันที่นี่ โดยพื้นฐานแล้ว การแจกจ่ายมีค่าสูงสุดสามรายการและสูงสุดหนึ่งรายการทั่วโลก ซึ่งไม่คาดคิด คงจะเป็นเรื่องที่น่าสนใจที่จะดูว่าการแจกแจงอายุที่แปลกประหลาดนี้ยังคงเป็นจริงสำหรับผู้ผลิตรถยนต์และรุ่นอื่นๆ หรือไม่ สำหรับวัตถุประสงค์ของบทความนี้ เราจะใช้ชุดข้อมูล BMW 3 Series แต่คุณสามารถเจาะลึกข้อมูลได้หากคุณสงสัย เกี่ยวกับการแบ่งอายุรถของเรา เราสังเกตเห็นว่ามากกว่า 90% ของรถยนต์มีอายุน้อยกว่า 10 ปี และมากกว่า 80% น้อยกว่า 7 ปี นอกจากนี้เรายังสังเกตเห็นว่ารถยนต์ส่วนใหญ่มีอายุน้อยกว่า 5 ปี
การกระจายไมล์
ทีนี้ เราจะพูดอะไรเกี่ยวกับระยะทางได้บ้าง แน่นอน เราคาดว่าจะมีรูปร่างระฆังเหมือนกันกับราคา นี่คือรหัส R และฮิสโตแกรม:
hist(cars$Mileage) 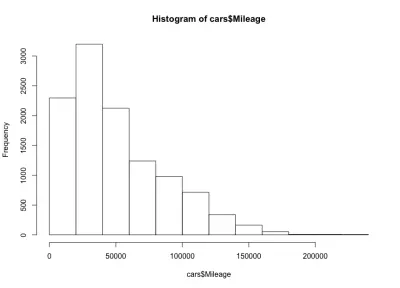
ที่นี่เรามีรูประฆังเบ้ซ้าย หมายความว่ามีรถยนต์จำนวนมากขึ้นที่มีระยะทางน้อยกว่าในตลาด นอกจากนี้เรายังสังเกตเห็นว่ารถยนต์ส่วนใหญ่มีระยะทางน้อยกว่า 60,000 ไมล์ และเรามีระยะทางสูงสุดประมาณ 20,000 ถึง 40,000 ไมล์
ความสัมพันธ์ระหว่างอายุ-ราคา
เกี่ยวกับความสัมพันธ์ เรามาดูความสัมพันธ์ระหว่างอายุกับราคารถยนต์กัน เราอาจคาดว่าราคาจะมีความสัมพันธ์เชิงลบกับอายุ เมื่ออายุของรถยนต์เพิ่มขึ้น ราคาก็จะลดลง เราจะใช้ฟังก์ชัน plot R เพื่อแสดงความสัมพันธ์ระหว่างราคากับอายุดังนี้:
plot(cars$Age, cars$Price)และโครงเรื่องมีลักษณะดังนี้:
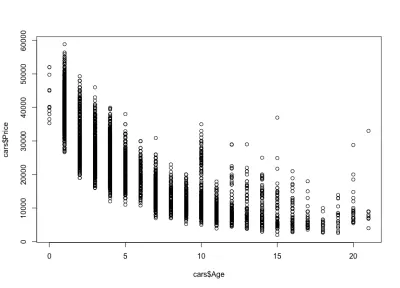
เราสังเกตว่าราคาของรถยนต์นั้นลดลงตามอายุ: มีรถใหม่ราคาแพงและรถเก่าราคาถูก เรายังสามารถดูช่วงการเปลี่ยนแปลงราคาสำหรับช่วงอายุใด ๆ ก็ได้ ซึ่งเป็นการเปลี่ยนแปลงที่ลดลงตามอายุของรถยนต์ รูปแบบนี้ส่วนใหญ่ขับเคลื่อนโดยระยะทาง การกำหนดค่า และสถานะโดยรวมของรถ ตัวอย่างเช่น ในกรณีของรถยนต์อายุ 4 ปี ราคาจะแตกต่างกันไประหว่าง 10,000 ถึง 40,000 ดอลลาร์สหรัฐ
ความสัมพันธ์ระหว่างระยะทางกับอายุ
เมื่อพิจารณาจากความสัมพันธ์ระหว่างระยะทางกับอายุ เราคาดว่าระยะทางจะเพิ่มขึ้นตามอายุ ซึ่งหมายถึงความสัมพันธ์เชิงบวก นี่คือรหัส:
plot(cars$Mileage, cars$Age)และนี่คือโครงเรื่อง:
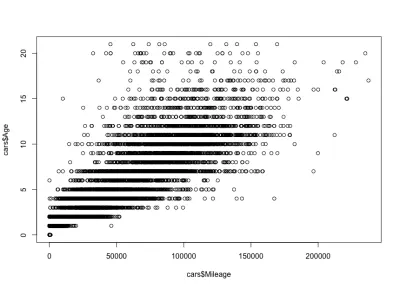
อย่างที่คุณเห็น อายุและระยะทางของรถมีความสัมพันธ์ในทางบวก ไม่เหมือนกับราคาและอายุของรถซึ่งมีความสัมพันธ์เชิงลบ นอกจากนี้เรายังมีรูปแบบระยะทางที่คาดหวังสำหรับอายุที่เฉพาะเจาะจง นั่นคือรถยนต์ในวัยเดียวกันมีระยะทางต่างกันไป ตัวอย่างเช่น รถยนต์อายุ 4 ปีส่วนใหญ่มีระยะทางระหว่าง 10,000 ถึง 80,000 ไมล์ แต่ก็มีค่าผิดปกติเช่นกันด้วยระยะทางที่มากกว่า
ความสัมพันธ์ระหว่างระยะทาง-ราคา
ตามที่คาดไว้ จะมีความสัมพันธ์เชิงลบระหว่างระยะทางของรถยนต์กับราคา ซึ่งหมายความว่าการเพิ่มระยะทางจะทำให้ราคาลดลง
plot(cars$Mileage, cars$Price)และนี่คือโครงเรื่อง:
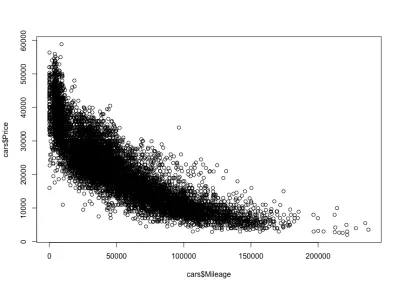
อย่างที่เราคาดไว้ ความสัมพันธ์เชิงลบ นอกจากนี้เรายังสามารถสังเกตช่วงราคารวมระหว่าง $3,000 ถึง $50,000 USD และระยะทางระหว่าง 0 ถึง 150,000 หากเราดูรูปร่างการกระจายอย่างใกล้ชิด เราจะเห็นว่าราคาลดลงเร็วกว่ามากสำหรับรถยนต์ที่มีระยะทางน้อยกว่าราคาสำหรับรถยนต์ที่มีระยะทางมากกว่า มีรถยนต์วิ่งเกือบเป็นศูนย์ซึ่งราคาลดลงอย่างมาก นอกจากนี้ ระยะทางที่สูงกว่า 200,000 ไมล์ — เนื่องจากระยะทางที่สูงมาก — ราคาจึงคงที่
จากตัวเลขสู่การแสดงข้อมูล
ในบทความนี้ เราใช้การแสดงภาพสองประเภท: ฮิสโตแกรมสำหรับการกระจายข้อมูล และแผนภาพกระจายสำหรับความสัมพันธ์ของข้อมูล ฮิสโตแกรมเป็นการแสดงภาพที่นำค่าของตัวแปรข้อมูล ( จำนวน จริง ) และแสดงให้เห็นว่ามีการกระจายอย่างไรในช่วง เราใช้ฟังก์ชัน R hist() เพื่อพล็อตฮิสโตแกรม
ในทางกลับกัน แผนภาพแบบกระจาย จะใช้คู่ของตัวเลขและแสดงเป็นสองแกน พล็อตกระจายใช้ฟังก์ชัน plot() และจัดเตรียมพารามิเตอร์สองตัว: ตัวแปรข้อมูลตัวแรกและตัวที่สองของความสัมพันธ์ที่เราต้องการตรวจสอบ ดังนั้น ฟังก์ชัน R ทั้งสองฟังก์ชัน hist() และ plot() จึงช่วยเราแปลชุดตัวเลขในรูปแบบการแสดงภาพที่มีความหมาย
บทสรุป
เมื่อเราจัดการกับกระแสข้อมูลทั้งหมดของการนำเข้า การประมวลผล และการวางแผนข้อมูล สิ่งต่างๆ ก็ดูชัดเจนขึ้นมากในขณะนี้ คุณสามารถใช้โฟลว์ข้อมูลเดียวกันกับชุดข้อมูลใหม่ที่เป็นประกายที่คุณจะพบได้ ตัวอย่างเช่น ในการวิจัยผู้ใช้ คุณสามารถสร้างกราฟเวลาของงานหรือการกระจายข้อผิดพลาด และคุณยังสามารถวางแผนเวลาบนงานกับความสัมพันธ์ของข้อผิดพลาด
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับภาษา R Quick-R เป็นจุดเริ่มต้นที่ดี แต่คุณสามารถพิจารณา R Bloggers ได้เช่นกัน สำหรับเอกสารเกี่ยวกับแพ็คเกจ R เช่น dplyr คุณสามารถไปที่ RDocumentation การเล่นข้อมูลเป็นเรื่องสนุก แต่ก็มีประโยชน์อย่างมากสำหรับนักออกแบบ UX ในโลกที่ขับเคลื่อนด้วยข้อมูล เมื่อมีการรวบรวมและใช้ข้อมูลมากขึ้นในการตัดสินใจทางธุรกิจ นักออกแบบจึงมีโอกาสมากขึ้นในการทำงานในการสร้างภาพข้อมูลหรือผลิตภัณฑ์ข้อมูล ซึ่งการทำความเข้าใจธรรมชาติของข้อมูลเป็นสิ่งสำคัญ