
การสร้างบริการ Pub/Sub ภายในองค์กรโดยใช้ Node.js และ Redis
เผยแพร่แล้ว: 2022-03-10โลกปัจจุบันทำงานตามเวลาจริง ไม่ว่าจะเป็นการซื้อขายหุ้นหรือสั่งอาหาร ผู้บริโภคในปัจจุบันคาดหวังผลลัพธ์ในทันที ในทำนองเดียวกัน เราทุกคนต่างก็คาดหวังที่จะรู้สิ่งต่างๆ ในทันที ไม่ว่าจะเป็นในข่าวหรือกีฬา Zero กล่าวอีกนัยหนึ่งคือฮีโร่ตัวใหม่
สิ่งนี้ใช้ได้กับนักพัฒนาซอฟต์แวร์เช่นกัน — บางคนที่ใจร้อนที่สุด! ก่อนดำดิ่งสู่เรื่องราวของ BrowserStack ฉันคงจะสะเพร่าที่จะไม่ให้ข้อมูลพื้นฐานเกี่ยวกับ Pub/Sub สำหรับผู้ที่คุ้นเคยกับพื้นฐานแล้ว โปรดข้ามสองย่อหน้าถัดไป
แอปพลิเคชั่นจำนวนมากในปัจจุบันพึ่งพาการถ่ายโอนข้อมูลตามเวลาจริง มาดูตัวอย่างกันดีกว่า: โซเชียลเน็ตเวิร์ก ไลค์ของ Facebook และ Twitter สร้างฟีดที่เกี่ยวข้อง และคุณ (ผ่านแอพของพวกเขา) ใช้งานมันและสอดแนมเพื่อนของคุณ พวกเขาทำสิ่งนี้ได้สำเร็จด้วยคุณสมบัติการส่งข้อความ ซึ่งหากผู้ใช้สร้างข้อมูล ข้อมูลนั้นจะถูกโพสต์เพื่อให้ผู้อื่นบริโภคในชั่วพริบตา ความล่าช้าที่สำคัญใดๆ และผู้ใช้จะบ่น การใช้งานจะลดลง และหากยังคงมีอยู่ ให้เลิกใช้ เงินเดิมพันสูงและความคาดหวังของผู้ใช้ก็เช่นกัน แล้วบริการต่างๆ เช่น WhatsApp, Facebook, TD Ameritrade, Wall Street Journal และ GrubHub รองรับการถ่ายโอนข้อมูลแบบเรียลไทม์ในปริมาณมากได้อย่างไร
ทั้งหมดใช้สถาปัตยกรรมซอฟต์แวร์ที่คล้ายคลึงกันในระดับสูงที่เรียกว่าโมเดล “เผยแพร่-สมัครสมาชิก” ซึ่งโดยทั่วไปจะเรียกว่า Pub/Sub
“ในสถาปัตยกรรมซอฟต์แวร์ publish–subscribe เป็นรูปแบบการส่งข้อความที่ผู้ส่งข้อความ เรียกว่า Publishers ไม่ได้ตั้งโปรแกรมข้อความที่จะส่งโดยตรงไปยังผู้รับเฉพาะ เรียกว่า Subscriber แต่ให้จัดหมวดหมู่ข้อความที่เผยแพร่เป็นคลาสโดยไม่ทราบว่าสมาชิกคนไหน ถ้า ใด ๆ อาจมี ในทำนองเดียวกัน สมาชิกแสดงความสนใจในคลาสหนึ่งหรือหลายคลาส และรับเฉพาะข้อความที่น่าสนใจ โดยไม่ทราบว่าผู้จัดพิมพ์รายใด หากมี”
— วิกิพีเดีย
เบื่อกับคำจำกัดความ? กลับมาที่เรื่องของเรา
ที่ BrowserStack ผลิตภัณฑ์ทั้งหมดของเรารองรับซอฟต์แวร์ (ไม่ทางใดก็ทางหนึ่ง) ที่มีองค์ประกอบการพึ่งพาแบบเรียลไทม์ที่สำคัญ ไม่ว่าจะเป็นการบันทึกการทดสอบอัตโนมัติ ภาพหน้าจอของเบราว์เซอร์ที่เพิ่งอบใหม่ หรือการสตรีมบนมือถือ 15fps
ในกรณีเช่นนี้ หากข้อความ หนึ่งหายไป ลูกค้าอาจสูญเสียข้อมูลที่สำคัญในการป้องกันจุดบกพร่อง ดังนั้นเราจึงจำเป็นต้องปรับขนาดสำหรับข้อกำหนดด้านขนาดข้อมูลที่หลากหลาย ตัวอย่างเช่น ด้วยบริการตัวบันทึกอุปกรณ์ ณ เวลาที่กำหนด อาจมีข้อมูล 50MB ที่สร้างขึ้นภายใต้ข้อความเดียว ขนาดเช่นนี้อาจทำให้เบราว์เซอร์ขัดข้อง ไม่ต้องพูดถึงว่าระบบของ BrowserStack จะต้องปรับขนาดสำหรับผลิตภัณฑ์เพิ่มเติมในอนาคต
เนื่องจากขนาดของข้อมูลสำหรับแต่ละข้อความแตกต่างกันไปตั้งแต่สองสามไบต์จนถึงสูงสุด 100MB เราจึงต้องการโซลูชันที่ปรับขนาดได้ซึ่งสามารถรองรับสถานการณ์ต่างๆ ได้มากมาย กล่าวอีกนัยหนึ่ง เราแสวงหาดาบที่สามารถตัดเค้กทั้งหมดได้ ในบทความนี้ ผมจะพูดถึงสาเหตุ วิธี และผลลัพธ์ของการสร้างบริการ Pub/Sub ของเราภายในบริษัท
ด้วยมุมมองของปัญหาในโลกแห่งความเป็นจริงของ BrowserStack คุณจะได้รับ ความเข้าใจอย่างลึกซึ้งถึงข้อกำหนดและขั้นตอนการสร้าง Pub/Sub ของคุณเอง
ความต้องการบริการผับ/ย่อยของเรา
BrowserStack มีข้อความประมาณ 100 ล้านข้อความ โดยแต่ละข้อความมีขนาดประมาณ 2 ไบต์ถึง 100+ MB สิ่งเหล่านี้ถูกส่งไปทั่วโลกได้ทุกเมื่อด้วยความเร็วอินเทอร์เน็ตที่แตกต่างกัน
ตัวสร้างข้อความที่ใหญ่ที่สุดตามขนาดข้อความคือผลิตภัณฑ์ BrowserStack Automate ของเรา ทั้งสองมีแดชบอร์ดแบบเรียลไทม์ที่แสดงคำขอและการตอบสนองทั้งหมดสำหรับแต่ละคำสั่งของการทดสอบผู้ใช้ ดังนั้น หากมีผู้ดำเนินการทดสอบกับคำขอ 100 รายการโดยที่ขนาดการตอบกลับคำขอเฉลี่ยคือ 10 ไบต์ การดำเนินการนี้จะส่ง 1×100×10 = 1,000 ไบต์
ตอนนี้ ลองพิจารณาภาพรวมว่า — แน่นอน — เราไม่ได้ทำการทดสอบเพียงวันเดียว การทดสอบ BrowserStack Automate และ App Automate มากกว่า 850,000 รายการทำงานด้วย BrowserStack ทุกวัน และใช่ เราเฉลี่ยการตอบกลับคำขอประมาณ 235 รายการต่อการทดสอบ เนื่องจากผู้ใช้สามารถจับภาพหน้าจอหรือขอแหล่งที่มาของหน้าใน Selenium ได้ ขนาดของคำตอบคำขอโดยเฉลี่ยของเราจึงอยู่ที่ประมาณ 220 ไบต์
กลับไปที่เครื่องคิดเลขของเรา:
850,000×235×220 = 43,945,000,000 ไบต์ (โดยประมาณ) หรือเพียง 43.945GB ต่อวัน
ทีนี้มาพูดถึง BrowserStack Live และ App Live กัน แน่นอนว่าเรามี Automate เป็นผู้ชนะในรูปแบบของขนาดของข้อมูล อย่างไรก็ตาม ผลิตภัณฑ์ Live เป็นผู้นำในเรื่องจำนวนข้อความที่ส่งผ่าน สำหรับการทดสอบสดทุกครั้ง จะมีการส่งข้อความประมาณ 20 ข้อความในแต่ละนาทีที่ผลัดกัน เราดำเนินการทดสอบจริงประมาณ 100,000 ครั้ง ซึ่งแต่ละการทดสอบเฉลี่ยประมาณ 12 นาที หมายความว่า:
100,000×12×20 = 24,000,000 ข้อความต่อวัน
ตอนนี้สำหรับส่วนที่ยอดเยี่ยมและน่าทึ่ง: เราสร้าง เรียกใช้ และบำรุงรักษาแอปพลิเคชันสำหรับสิ่งนี้ที่เรียกว่า pusher ด้วยอินสแตนซ์ t1.micro 6 ตัวของ ec2 ค่าใช้จ่ายในการดำเนินการบริการ? ประมาณ 70 เหรียญ ต่อเดือน
การเลือกสร้างกับการซื้อ
อย่างแรกเลย: ในฐานะที่เป็นสตาร์ทอัพ เรารู้สึกตื่นเต้นเสมอที่จะสร้างสิ่งต่างๆ ขึ้นเองภายในบริษัท แต่เรายังคงประเมินบริการบางอย่างที่มีอยู่ ข้อกำหนดเบื้องต้นที่เรามีคือ:
- ความน่าเชื่อถือและความมั่นคง
- ประสิทธิภาพสูงและ
- ลดค่าใช้จ่าย.
เลิกใช้เกณฑ์ความคุ้มค่ากันเถอะ เพราะฉันไม่สามารถนึกถึงบริการภายนอกใดๆ ที่มีราคาต่ำกว่า 70 ดอลลาร์ต่อเดือน (ทวีตฉันถ้าคุณรู้จักบริการนั้น!) ดังนั้นคำตอบของเราจึงชัดเจน
ในแง่ของความน่าเชื่อถือและความเสถียร เราพบว่าบริษัทที่ให้บริการ Pub/Sub เป็นบริการที่มี SLA ความพร้อมในการทำงาน 99.9+ เปอร์เซ็นต์ แต่มีข้อกำหนดและเงื่อนไขจำนวนมากที่แนบมาด้วย ปัญหาไม่ได้ง่ายอย่างที่คุณคิด โดยเฉพาะอย่างยิ่งเมื่อคุณพิจารณาถึงพื้นที่กว้างใหญ่ของอินเทอร์เน็ตแบบเปิดซึ่งอยู่ระหว่างระบบและไคลเอนต์ ใครก็ตามที่คุ้นเคยกับโครงสร้างพื้นฐานทางอินเทอร์เน็ตจะรู้ว่าการเชื่อมต่อที่เสถียรคือความท้าทายที่ใหญ่ที่สุด นอกจากนี้ ปริมาณข้อมูลที่ส่งขึ้นอยู่กับการรับส่งข้อมูล ตัวอย่างเช่น ไปป์ข้อมูลที่ศูนย์เป็นเวลาหนึ่งนาทีอาจแตกออกในช่วงถัดไป บริการที่ให้ความน่าเชื่อถือเพียงพอในช่วงเวลาดังกล่าวนั้นหายาก (Google และ Amazon)
ประสิทธิภาพสำหรับโปรเจ็กต์ของเราหมายถึง การรับและส่งข้อมูลไปยังโหนดการรับฟังทั้งหมดที่เวลาแฝงใกล้เป็นศูนย์ ที่ BrowserStack เราใช้บริการระบบคลาวด์ (AWS) พร้อมกับการโฮสต์ร่วม อย่างไรก็ตาม ผู้เผยแพร่และ/หรือสมาชิกของเราสามารถวางไว้ที่ใดก็ได้ ตัวอย่างเช่น อาจเกี่ยวข้องกับแอปพลิเคชันเซิร์ฟเวอร์ของ AWS ที่สร้างข้อมูลบันทึกที่จำเป็นมาก หรือเทอร์มินัล (เครื่องที่ผู้ใช้สามารถเชื่อมต่อได้อย่างปลอดภัยสำหรับการทดสอบ) กลับมาที่ปัญหาอินเทอร์เน็ตแบบเปิดอีกครั้ง หากเราต้องลดความเสี่ยง เราจะต้องตรวจสอบให้แน่ใจว่า Pub/Sub ของเราใช้ประโยชน์จากบริการโฮสต์และ AWS ที่ดีที่สุด
ข้อกำหนดที่สำคัญอีกประการหนึ่งคือความสามารถในการส่งข้อมูลทุกประเภท (ไบต์ ข้อความ ข้อมูลสื่อแปลก ๆ ฯลฯ) เมื่อพิจารณาทั้งหมดแล้ว จึงไม่สมเหตุสมผลที่จะพึ่งพาโซลูชันของบุคคลที่สามเพื่อสนับสนุนผลิตภัณฑ์ของเรา ในทางกลับกัน เราตัดสินใจที่จะรื้อฟื้นจิตวิญญาณการเริ่มต้นของเรา พับแขนเสื้อขึ้นเพื่อเขียนโค้ดโซลูชันของเราเอง
การสร้างโซลูชันของเรา
Pub/Sub โดยการออกแบบหมายความว่าจะมีผู้เผยแพร่ สร้างและส่งข้อมูล และสมาชิกที่ยอมรับและประมวลผล สิ่งนี้คล้ายกับวิทยุ: ช่องวิทยุออกอากาศ (เผยแพร่) เนื้อหาทุกที่ภายในช่วง ในฐานะสมาชิก คุณสามารถตัดสินใจว่าจะปรับเป็นช่องนั้นและฟังหรือไม่ (หรือปิดวิทยุทั้งหมด)

ต่างจากการเปรียบเทียบทางวิทยุที่ข้อมูลฟรีสำหรับทุกคนและทุกคนสามารถตัดสินใจปรับแต่งได้ ในสถานการณ์ดิจิทัลของเรา เราต้องการการรับรองความถูกต้อง ซึ่งหมายความว่าข้อมูลที่สร้างโดยผู้เผยแพร่สามารถเป็นได้สำหรับลูกค้าหรือผู้สมัครสมาชิกรายเดียวเท่านั้น
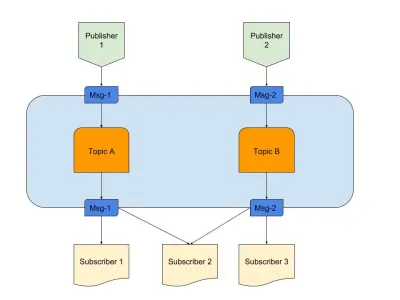
ด้านบนเป็นไดอะแกรมที่แสดงตัวอย่าง Pub/Sub ที่ดีด้วย:
- สำนักพิมพ์
เรามีผู้เผยแพร่ 2 รายที่สร้างข้อความตามตรรกะที่กำหนดไว้ล่วงหน้า ในการเปรียบเทียบวิทยุของเรา คนเหล่านี้คือนักจัดรายการวิทยุของเราที่สร้างเนื้อหา - หัวข้อ
มีสองที่นี่ หมายความว่ามีข้อมูลสองประเภท เราสามารถพูดได้ว่านี่คือช่องวิทยุ 1 และ 2 ของเรา - สมาชิก
เรามีสามที่แต่ละคนอ่านข้อมูลในหัวข้อใดหัวข้อหนึ่ง สิ่งหนึ่งที่ควรสังเกตคือ Subscriber 2 กำลังอ่านจากหลายหัวข้อ ในการเปรียบเทียบวิทยุของเรา คนเหล่านี้คือผู้ที่ปรับช่องสัญญาณวิทยุ
มาเริ่มทำความเข้าใจข้อกำหนดที่จำเป็นสำหรับบริการกัน
- องค์ประกอบเหตุการณ์
สิ่งนี้จะเกิดขึ้นก็ต่อเมื่อมีบางสิ่งที่จะเตะเข้า - การจัดเก็บชั่วคราว
วิธีนี้จะทำให้ข้อมูลคงอยู่ในช่วงเวลาสั้นๆ ดังนั้นหากผู้สมัครสมาชิกช้า ก็ยังมีหน้าต่างให้ใช้งาน - ลดเวลาแฝง
เชื่อมต่อสองเอนทิตีผ่านเครือข่ายที่มีการกระโดดและระยะทางขั้นต่ำ
เราเลือกกลุ่มเทคโนโลยีที่ตรงตามข้อกำหนดข้างต้น:
- Node.js
เพราะเหตุใด เมื่อถึงตอนนั้น เราก็ไม่ต้องการการประมวลผลข้อมูลจำนวนมาก แถมยังง่ายต่อการเริ่มต้นใช้งานอีกด้วย - Redis
รองรับข้อมูลที่มีอายุสั้นอย่างสมบูรณ์แบบ มีความสามารถทั้งหมดในการเริ่มต้น อัปเดต และหมดอายุอัตโนมัติ นอกจากนี้ยังทำให้โหลดแอปพลิเคชันน้อยลง
Node.js สำหรับการเชื่อมต่อลอจิกธุรกิจ
Node.js เป็นภาษาที่เกือบจะสมบูรณ์แบบในการเขียนโค้ดที่รวม IO และเหตุการณ์ต่างๆ ปัญหาของเรามีทั้งสองอย่าง ทำให้ตัวเลือกนี้เหมาะกับความต้องการของเรามากที่สุด
แน่นอนว่าภาษาอื่นๆ เช่น Java สามารถเพิ่มประสิทธิภาพได้มากกว่า หรือภาษาอย่าง Python มีความสามารถในการปรับขนาดได้ อย่างไรก็ตาม ค่าใช้จ่ายในการเริ่มต้นกับภาษาเหล่านี้สูงมากจนนักพัฒนาสามารถเขียนโค้ดใน Node ให้เสร็จภายในระยะเวลาเดียวกันได้
พูดตามตรง หากบริการมีโอกาสที่จะเพิ่มคุณสมบัติที่ซับซ้อนมากขึ้น เราอาจดูภาษาอื่นหรือกลุ่มที่สมบูรณ์ แต่นี่คือการแต่งงานที่เกิดขึ้นในสวรรค์ นี่คือ package.json ของเรา:
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }พูดง่ายๆ ก็คือ เราเชื่อในความเรียบง่ายโดยเฉพาะอย่างยิ่งเมื่อต้องเขียนโค้ด ในทางกลับกัน เราสามารถใช้ไลบรารี่อย่าง Express เพื่อเขียนโค้ดที่ขยายได้สำหรับโปรเจ็กต์นี้ อย่างไรก็ตาม สัญชาตญาณการเริ่มต้นของเราตัดสินใจที่จะส่งต่อสิ่งนี้และบันทึกไว้สำหรับโครงการต่อไป เครื่องมือเพิ่มเติมที่เราใช้:
- ไอเรดิส
นี่เป็นหนึ่งในไลบรารี่ที่ได้รับการสนับสนุนมากที่สุดสำหรับการเชื่อมต่อ Redis กับ Node.js ที่ใช้โดยบริษัทต่างๆ รวมถึงอาลีบาบา - socket.io
ไลบรารี่ที่ดีที่สุดสำหรับการเชื่อมต่อและทางเลือกที่นุ่มนวลด้วย WebSocket และ HTTP
Redis สำหรับการจัดเก็บชั่วคราว
Redis เป็นมาตราส่วนการบริการมีความน่าเชื่อถืออย่างมากและสามารถกำหนดค่าได้ นอกจากนี้ยังมีผู้ให้บริการที่มีการจัดการที่เชื่อถือได้มากมายสำหรับ Redis รวมถึง AWS แม้ว่าคุณจะไม่ต้องการใช้ผู้ให้บริการ แต่ Redis ก็สามารถเริ่มต้นได้ง่าย
มาทำลายส่วนที่กำหนดค่าได้ เราเริ่มต้นด้วยการกำหนดค่ามาสเตอร์-สเลฟตามปกติ แต่ Redis ยังมาพร้อมกับโหมดคลัสเตอร์หรือยามรักษาการณ์ ทุกโหมดมีข้อดีของตัวเอง
หากเราสามารถแบ่งปันข้อมูลด้วยวิธีใดวิธีหนึ่ง คลัสเตอร์ Redis จะเป็นตัวเลือกที่ดีที่สุด แต่ถ้าเราแบ่งปันข้อมูลโดยใช้การวิเคราะห์พฤติกรรมใดๆ เราก็มีความยืดหยุ่นน้อยลง เนื่องจากต้องติดตามการวิเคราะห์พฤติกรรมทั่วๆ ไป กฎที่น้อยลง การควบคุมที่มากขึ้น เป็นผลดีต่อชีวิต!
Redis Sentinel ทำงานได้ดีที่สุดสำหรับเรา เนื่องจากการค้นหาข้อมูลทำได้ในโหนดเดียว โดยเชื่อมต่อ ณ จุดที่กำหนดในเวลาในขณะที่ข้อมูลไม่ถูกแบ่งส่วน นี่ยังหมายความว่าแม้ว่าหลายโหนดจะสูญหาย แต่ข้อมูลก็ยังถูกกระจายและแสดงอยู่ในโหนดอื่น ดังนั้นคุณจึงมี HA มากขึ้นและมีโอกาสสูญเสียน้อยลง แน่นอนว่าสิ่งนี้ได้ลบข้อดีจากการมีคลัสเตอร์ แต่กรณีการใช้งานของเราแตกต่างออกไป
สถาปัตยกรรมที่ 30000 ฟุต
ไดอะแกรมด้านล่างแสดงภาพระดับสูงว่าแดชบอร์ด Automate และ App Automate ทำงานอย่างไร จำระบบเรียลไทม์ที่เรามีจากส่วนก่อนหน้านี้หรือไม่?
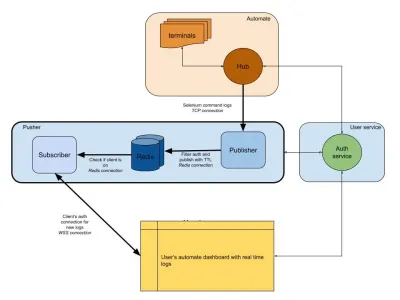
ในไดอะแกรมของเรา เวิร์กโฟลว์หลักของเราจะถูกเน้นด้วยเส้นขอบที่หนาขึ้น ส่วน "อัตโนมัติ" ประกอบด้วย:
- เทอร์มินัล
ประกอบด้วย Windows, OSX, Android หรือ iOS เวอร์ชันดั้งเดิมที่คุณได้รับขณะทดสอบบน BrowserStack - Hub
จุดติดต่อสำหรับการทดสอบ Selenium และ Appium ทั้งหมดของคุณด้วย BrowserStack
ส่วน "บริการผู้ใช้" ที่นี่คือผู้รักษาประตูของเรา เพื่อให้มั่นใจว่าข้อมูลจะถูกส่งไปยังและบันทึกไว้สำหรับบุคคลที่เหมาะสม ยังเป็นเจ้าหน้าที่รักษาความปลอดภัยของเราอีกด้วย ส่วน "ดัน" รวมหัวใจของสิ่งที่เรากล่าวถึงในบทความนี้ ประกอบด้วยผู้ต้องสงสัยตามปกติ ได้แก่ :
- Redis
ที่เก็บข้อมูลชั่วคราวของเราสำหรับข้อความ ซึ่งในกรณีของเรา บันทึกอัตโนมัติจะถูกเก็บไว้ชั่วคราว - สำนักพิมพ์
โดยพื้นฐานแล้วเป็นเอนทิตีที่ได้รับข้อมูลจากฮับ การตอบสนองคำขอทั้งหมดของคุณถูกจับโดยคอมโพเนนต์นี้ซึ่งเขียนถึง Redis โดยมีsession_idเป็นช่องทาง - สมาชิก
สิ่งนี้จะอ่านข้อมูลจาก Redis ที่สร้างขึ้นสำหรับsession_idนอกจากนี้ยังเป็นเว็บเซิร์ฟเวอร์สำหรับไคลเอนต์ในการเชื่อมต่อผ่าน WebSocket (หรือ HTTP) เพื่อรับข้อมูลแล้วส่งไปยังไคลเอนต์ที่รับรองความถูกต้อง
สุดท้าย เรามีส่วนเบราว์เซอร์ของผู้ใช้ ซึ่งแสดงถึงการเชื่อมต่อ WebSocket ที่ตรวจสอบสิทธิ์เพื่อให้แน่ใจว่ามีการส่งบันทึกของ session_id ซึ่งช่วยให้ JS ส่วนหน้าสามารถแยกวิเคราะห์และตกแต่งให้สวยงามสำหรับผู้ใช้
คล้ายกับบริการบันทึก เรามีตัวผลักดันที่นี่ซึ่งใช้สำหรับการรวมผลิตภัณฑ์อื่นๆ แทนที่จะใช้ session_id เราใช้ ID รูปแบบอื่นเพื่อเป็นตัวแทนของช่องนั้น ทั้งหมดนี้ใช้การได้หมด!
บทสรุป (TLDR)
เราประสบความสำเร็จอย่างมากในการสร้าง Pub/Sub เพื่อสรุปว่าทำไมเราจึงสร้างมันขึ้นมาในบ้าน:
- ตาชั่งได้ดีกว่าสำหรับความต้องการของเรา
- ถูกกว่าบริการภายนอก
- ควบคุมสถาปัตยกรรมโดยรวมได้อย่างสมบูรณ์
ไม่ต้องพูดถึงว่า JS เหมาะสมที่สุดสำหรับสถานการณ์ประเภทนี้ วงเหตุการณ์และ IO จำนวนมากคือสิ่งที่ปัญหาต้องการ! JavaScript เป็นเวทย์มนตร์ของเธรดหลอกเดียว
กิจกรรมและ Redis เป็นระบบที่ช่วยให้นักพัฒนาทำสิ่งต่างๆ ได้ง่าย เนื่องจากคุณสามารถรับข้อมูลจากแหล่งหนึ่งและส่งไปยังอีกแหล่งหนึ่งผ่าน Redis ดังนั้นเราจึงสร้างมันขึ้นมา
หากการใช้งานเข้ากับระบบของคุณ ขอแนะนำให้ทำเช่นเดียวกัน!