
การถดถอยพหุนาม: ความสำคัญ การดำเนินการทีละขั้นตอน
เผยแพร่แล้ว: 2021-01-29สารบัญ
บทนำ
ในสาขา Machine Learning อันกว้างใหญ่นี้ อัลกอริธึมแรกที่พวกเราส่วนใหญ่จะศึกษาคืออะไร? ใช่ มันเป็นการถดถอยเชิงเส้น ส่วนใหญ่เป็นโปรแกรมและอัลกอริธึมแรกที่เราจะได้เรียนรู้ในช่วงเริ่มต้นของการเขียนโปรแกรมการเรียนรู้ด้วยเครื่อง การถดถอยเชิงเส้นมีความสำคัญและมีอำนาจในตัวเองด้วยประเภทข้อมูลเชิงเส้น
จะเกิดอะไรขึ้นถ้าชุดข้อมูลที่เราเจอไม่สามารถแยกเชิงเส้นได้? จะเกิดอะไรขึ้นถ้าตัวแบบการถดถอยเชิงเส้นไม่สามารถหาความสัมพันธ์ระหว่างตัวแปรอิสระและตัวแปรตามได้?
มีการถดถอยอีกประเภทหนึ่งที่เรียกว่าการถดถอยพหุนาม ตามชื่อของมัน พหุนามถดถอยคืออัลกอริธึมการถดถอยที่จำลองความสัมพันธ์ระหว่างตัวแปรตาม (y) และตัวแปรอิสระ (x) เป็นพหุนามดีกรีที่ n ในบทความนี้ เราจะเข้าใจอัลกอริทึมและคณิตศาสตร์ที่อยู่เบื้องหลังการถดถอยพหุนามพร้อมกับการใช้งานใน Python
การถดถอยพหุนามคืออะไร?
ตามที่กำหนดไว้ก่อนหน้านี้ การถดถอยพหุนามเป็นกรณีพิเศษของการถดถอยเชิงเส้น ซึ่งสมการพหุนามที่มีดีกรี (n) ที่ระบุจะพอดีกับข้อมูลที่ไม่เป็นเชิงเส้นซึ่งก่อให้เกิดความสัมพันธ์แบบโค้งระหว่างตัวแปรตามและตัวแปรอิสระ
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
ที่นี่,

y เป็นตัวแปรตาม (ตัวแปรเอาต์พุต)
x1 เป็นตัวแปรอิสระ (ตัวทำนาย)
b 0 คืออคติ
b 1 , b 2 , ….b n คือน้ำหนักในสมการถดถอย
เมื่อระดับของสมการพหุนาม ( n ) สูงขึ้น สมการพหุนามจะซับซ้อนมากขึ้น และมีความเป็นไปได้ที่ตัวแบบจะมีแนวโน้มมากเกินไปซึ่งจะกล่าวถึงในตอนต่อไป
การเปรียบเทียบสมการถดถอย
การถดถอยเชิงเส้นอย่างง่าย ===> y= b0+b1x
การถดถอยเชิงเส้นพหุคูณ ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
การถดถอยพหุนาม ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
จากสมการทั้งสามข้างต้น เราจะเห็นว่ามีความแตกต่างเล็กน้อยในสมการเหล่านี้ การถดถอยเชิงเส้นเชิงเดี่ยวและเชิงพหุนั้นแตกต่างจากสมการถดถอยพหุนามตรงที่มีดีกรีเป็น 1 เท่านั้น การถดถอยเชิงเส้นพหุคูณประกอบด้วยตัวแปรหลายตัว x1, x2 และอื่นๆ แม้ว่าสมการถดถอยพหุนามจะมีตัวแปร x1 เพียงตัวเดียว แต่ก็มีดีกรี n ซึ่งแตกต่างจากอีกสองตัว
ต้องการการถดถอยพหุนาม
จากไดอะแกรมด้านล่าง เราจะเห็นว่าในไดอะแกรมแรก มีการพยายามให้เส้นเชิงเส้นพอดีกับชุดของจุดข้อมูลที่ไม่เป็นเชิงเส้นที่กำหนด เป็นที่เข้าใจกันว่าเป็นเรื่องยากมากที่เส้นตรงจะสร้างความสัมพันธ์กับข้อมูลที่ไม่เป็นเชิงเส้นนี้ ด้วยเหตุนี้เมื่อเราฝึกโมเดล ฟังก์ชันการสูญเสียเพิ่มขึ้นทำให้เกิดข้อผิดพลาดสูง
ในทางกลับกัน เมื่อเราใช้การถดถอยพหุนาม จะมองเห็นได้ชัดเจนว่าเส้นตรงพอดีกับจุดข้อมูล นี่หมายความว่าสมการพหุนามที่เหมาะกับจุดข้อมูลทำให้เกิดความสัมพันธ์บางอย่างระหว่างตัวแปรในชุดข้อมูล ดังนั้น สำหรับกรณีดังกล่าวที่จุดข้อมูลถูกจัดเรียงในลักษณะที่ไม่เป็นเชิงเส้น เราจำเป็นต้องใช้แบบจำลองการถดถอยพหุนาม
การใช้การถดถอยพหุนามใน Python
จากที่นี่ เราจะสร้างแบบจำลองการเรียนรู้ของเครื่องใน Python โดยใช้การถดถอยพหุนาม เราจะเปรียบเทียบผลลัพธ์ที่ได้กับการถดถอยเชิงเส้นและการถดถอยพหุนาม ให้เราเข้าใจปัญหาที่เราจะแก้ด้วยการถดถอยพหุนามก่อน
คำอธิบายปัญหา
ในกรณีนี้ ลองพิจารณากรณีของ Start-up ที่ต้องการจ้างผู้สมัครหลายคนจากบริษัทหนึ่งๆ มีตำแหน่งงานว่างที่แตกต่างกันสำหรับตำแหน่งงานที่แตกต่างกันในบริษัท สตาร์ทอัพมีรายละเอียดของเงินเดือนแต่ละตำแหน่งในบริษัทเดิม ดังนั้น เมื่อผู้สมัครกล่าวถึงเงินเดือนก่อนหน้านี้ ฝ่ายทรัพยากรบุคคลของสตาร์ทอัพจำเป็นต้องตรวจสอบกับข้อมูลที่มีอยู่ ดังนั้นเราจึงมีตัวแปรอิสระ 2 ตัวคือ Position และ Level ตัวแปรตาม (เอาต์พุต) คือ เงินเดือน ที่คาดการณ์โดยใช้การถดถอยพหุนาม
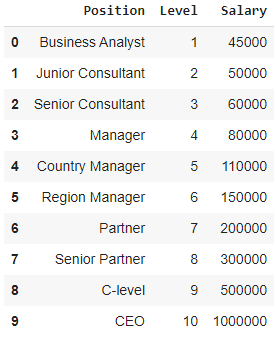
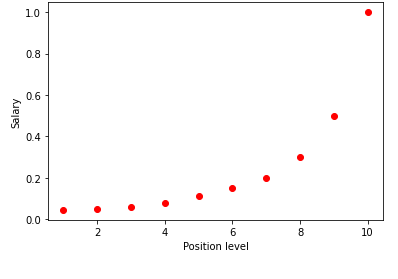
ในการแสดงภาพตารางด้านบนในกราฟ เราจะเห็นว่าข้อมูลไม่เป็นเชิงเส้น กล่าวอีกนัยหนึ่งเมื่อระดับเพิ่มขึ้นเงินเดือนจะเพิ่มขึ้นในอัตราที่สูงขึ้นซึ่งทำให้เรามีเส้นโค้งดังแสดงด้านล่าง
ขั้นตอนที่ 1: การประมวลผลข้อมูลล่วงหน้าขั้นตอนแรกในการสร้างโมเดล Machine Learning คือการนำเข้าไลบรารี ที่นี่ เรามีไลบรารีพื้นฐานเพียงสามไลบรารีที่จะนำเข้า หลังจากนี้ ชุดข้อมูลจะถูกนำเข้าจากที่เก็บ GitHub ของฉัน และกำหนดตัวแปรตามและตัวแปรอิสระ ตัวแปรอิสระถูกเก็บไว้ในตัวแปร X และตัวแปรตามจะถูกเก็บไว้ในตัวแปร y
นำเข้า numpy เป็น np
นำเข้า matplotlib.pyplot เป็น plt
นำเข้าแพนด้าเป็น pd
ชุดข้อมูล = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
ในเทอม [:, 1:-1] เครื่องหมายทวิภาคแรกแสดงว่าต้องมีแถวทั้งหมด และระยะ 1:-1 แสดงว่าคอลัมน์ที่จะรวมมาจากคอลัมน์แรกถึงคอลัมน์สุดท้ายซึ่งกำหนดโดย -1.
ขั้นตอนที่ 2: ตัวแบบการถดถอยเชิงเส้นในขั้นตอนต่อไป เราจะสร้างแบบจำลองการถดถอยเชิงเส้นพหุคูณ และใช้เพื่อทำนายข้อมูลเงินเดือนจากตัวแปรอิสระ สำหรับสิ่งนี้ คลาส LinearRegression จะถูกนำเข้าจากไลบรารี sklearn จากนั้นจะติดตั้งบนตัวแปร X และ y เพื่อวัตถุประสงค์ในการฝึกอบรม
จาก sklearn.linear_model นำเข้า LinearRegression
ตัวถดถอย = การถดถอยเชิงเส้น ()
regressor.fit(X, y)
เมื่อสร้างแบบจำลองแล้ว ในการแสดงภาพผลลัพธ์ เราจะได้กราฟต่อไปนี้
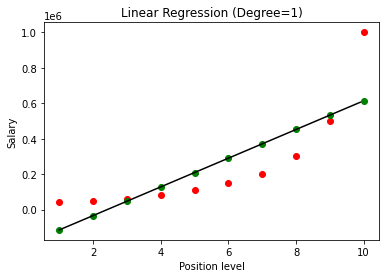
ดังที่เห็นได้ชัดเจน การพยายามปรับเส้นตรงให้พอดีกับชุดข้อมูลที่ไม่เป็นเชิงเส้น ไม่มีความสัมพันธ์ที่โมเดล Machine Learning ได้มา ดังนั้นเราต้องไปหาพหุนามถดถอยเพื่อให้ได้ความสัมพันธ์ระหว่างตัวแปร
ขั้นตอนที่ 3: แบบจำลองการถดถอยพหุนามในขั้นตอนต่อไปนี้ เราจะใส่แบบจำลองการถดถอยพหุนามในชุดข้อมูลนี้และแสดงผลลัพธ์เป็นภาพ สำหรับสิ่งนี้ เรานำเข้าคลาสอื่นจากโมดูล sklearn ที่ชื่อว่า PolynomialFeatures ซึ่งเรากำหนดระดับของสมการพหุนามที่จะสร้าง จากนั้นคลาส LinearRegression จะใช้เพื่อให้พอดีกับสมการพหุนามกับชุดข้อมูล
จาก sklearn.preprocessing นำเข้า PolynomialFeatures
จาก sklearn.linear_model นำเข้า LinearRegression
poly_reg = คุณสมบัติพหุนาม (ดีกรี = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = การถดถอยเชิงเส้น ()
lin_reg.fit(X_poly, y)
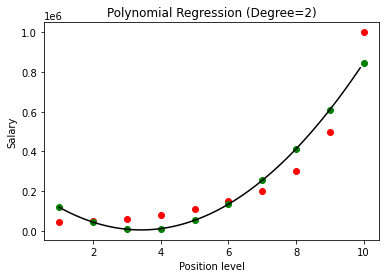
ในกรณีข้างต้น เราได้ให้ดีกรีของสมการพหุนามเท่ากับ 2 ในการพล็อตกราฟ เราจะเห็นว่ามีเส้นโค้งบางประเภทที่ได้รับมา แต่ก็ยังมีความคลาดเคลื่อนจากข้อมูลจริงมาก (สีแดง ) และจุดโค้งที่คาดการณ์ไว้ (สีเขียว) ดังนั้น ในขั้นต่อไป เราจะเพิ่มดีกรีของพหุนามเป็นจำนวนที่สูงกว่า เช่น 3 & 4 แล้วเปรียบเทียบกัน
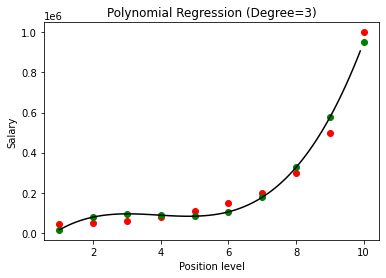
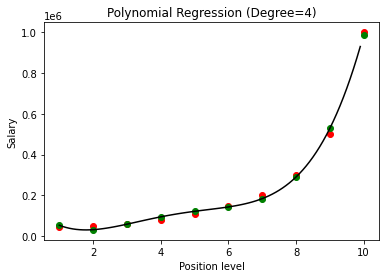
ในการเปรียบเทียบผลลัพธ์ของการถดถอยพหุนามกับองศา 3 และ 4 เราเห็นว่าเมื่อระดับเพิ่มขึ้น แบบจำลองจะฝึกกับข้อมูลได้ดี ดังนั้น เราสามารถอนุมานได้ว่าระดับที่สูงขึ้นจะทำให้สมการพหุนามพอดีกับข้อมูลการฝึกได้แม่นยำยิ่งขึ้น อย่างไรก็ตาม นี่เป็นกรณีที่สมบูรณ์แบบของการสวมใส่มากเกินไป ดังนั้นจึงเป็นเรื่องสำคัญที่จะต้องเลือกค่า n อย่างแม่นยำเพื่อป้องกันการ overfitting
Overfitting คืออะไร?
ตามชื่อที่กล่าวไว้ การใส่มากเกินไปจะเรียกว่าเป็นสถานการณ์ในสถิติเมื่อฟังก์ชัน (หรือแบบจำลองการเรียนรู้ของเครื่องในกรณีนี้) ใกล้เคียงกับชุดของจุดข้อมูลที่จำกัดมากเกินไป ทำให้ฟังก์ชันทำงานได้ไม่ดีกับจุดข้อมูลใหม่
ในการเรียนรู้ของเครื่อง หากมีการกล่าวกันว่าแบบจำลองมีความเหมาะสมมากเกินไปกับชุดจุดข้อมูลการฝึกอบรมที่กำหนด จากนั้นเมื่อมีการแนะนำแบบจำลองเดียวกันไปยังชุดจุดใหม่ทั้งหมด (เช่น ชุดข้อมูลทดสอบ) แบบจำลองนั้นจะทำงานได้ดีมากเนื่องจาก โมเดล overfitting ไม่ได้มีลักษณะทั่วไปที่ดีกับข้อมูล และมีเพียง overfitting ในจุดข้อมูลการฝึกอบรมเท่านั้น
ในการถดถอยพหุนาม มีโอกาสดีที่แบบจำลองจะพอดีกับข้อมูลการฝึกเมื่อระดับของพหุนามเพิ่มขึ้น ในตัวอย่างที่แสดงด้านบน เราจะเห็นกรณีทั่วไปของการใส่มากเกินไปในการถดถอยพหุนามซึ่งสามารถแก้ไขได้โดยใช้เพียงการทดลองและข้อผิดพลาดในการเลือกค่าที่เหมาะสมที่สุดของดีกรี
อ่านเพิ่มเติม: แนวคิดโครงการการเรียนรู้ของเครื่อง
บทสรุป
สรุปได้ว่า การถดถอยพหุนามถูกนำมาใช้ในหลายสถานการณ์ที่มีความสัมพันธ์แบบไม่เชิงเส้นระหว่างตัวแปรตามและตัวแปรอิสระ แม้ว่าอัลกอริธึมนี้จะทนทุกข์ทรมานจากความไวต่อค่าผิดปกติ แต่ก็สามารถแก้ไขได้ด้วยการปฏิบัติก่อนที่จะปรับแนวการถดถอย ดังนั้น ในบทความนี้ เราจึงได้รับการแนะนำให้รู้จักกับแนวคิดเรื่องการถดถอยพหุนามพร้อมกับตัวอย่างการใช้งานในการเขียนโปรแกรม Python ในชุดข้อมูลอย่างง่าย
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
เรียนรู้ หลักสูตร ML จากมหาวิทยาลัยชั้นนำของโลก รับ Masters, Executive PGP หรือ Advanced Certificate Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
คุณหมายถึงอะไรโดยการถดถอยเชิงเส้น?
การถดถอยเชิงเส้นเป็นประเภทของการวิเคราะห์เชิงตัวเลขเชิงทำนาย ซึ่งเราสามารถหาค่าของตัวแปรที่ไม่รู้จักได้โดยใช้ตัวแปรตาม นอกจากนี้ยังอธิบายความเชื่อมโยงระหว่างตัวแปรอิสระหนึ่งตัวกับตัวแปรอิสระอย่างน้อยหนึ่งตัว การถดถอยเชิงเส้นเป็นเทคนิคทางสถิติสำหรับการแสดงความเชื่อมโยงระหว่างตัวแปรสองตัว การถดถอยเชิงเส้นพล็อตเส้นแนวโน้มจากชุดของจุดข้อมูล สามารถใช้การถดถอยเชิงเส้นเพื่อสร้างแบบจำลองการคาดการณ์จากข้อมูลที่ดูเหมือนสุ่มได้ เช่น การวินิจฉัยโรคมะเร็งหรือราคาหุ้น มีหลายวิธีในการคำนวณการถดถอยเชิงเส้น วิธีกำลังสองน้อยที่สุดแบบธรรมดา ซึ่งประเมินตัวแปรที่ไม่รู้จักในข้อมูลและแปลงด้วยสายตาเป็นผลรวมของระยะทางแนวตั้งระหว่างจุดข้อมูลและเส้นแนวโน้ม เป็นแนวทางที่แพร่หลายที่สุดวิธีหนึ่ง
ข้อเสียของการถดถอยเชิงเส้นคืออะไร?
ในกรณีส่วนใหญ่ การวิเคราะห์การถดถอยจะใช้ในการวิจัยเพื่อสร้างความเชื่อมโยงระหว่างตัวแปร อย่างไรก็ตาม ความสัมพันธ์ไม่ได้หมายความถึงสาเหตุเนื่องจากความเชื่อมโยงระหว่างตัวแปรสองตัวไม่ได้หมายความว่าตัวแปรหนึ่งเป็นสาเหตุให้อีกตัวแปรหนึ่งเกิดขึ้น แม้แต่เส้นตรงในการถดถอยเชิงเส้นพื้นฐานที่เหมาะสมกับจุดข้อมูลก็อาจไม่รับประกันความสัมพันธ์ระหว่างสถานการณ์และผลลัพธ์เชิงตรรกะ การใช้ตัวแบบการถดถอยเชิงเส้น คุณอาจกำหนดได้ว่าตัวแปรมีความสัมพันธ์กันหรือไม่ จำเป็นต้องมีการตรวจสอบเพิ่มเติมและการวิเคราะห์ทางสถิติเพื่อกำหนดลักษณะที่แน่นอนของลิงก์และดูว่าตัวแปรหนึ่งเป็นสาเหตุของอีกตัวแปรหนึ่งหรือไม่
สมมติฐานพื้นฐานของการถดถอยเชิงเส้นคืออะไร?
ในการถดถอยเชิงเส้น มีสมมติฐานสำคัญสามข้อ ตัวแปรตามและตัวแปรอิสระต้องมีการเชื่อมต่อเชิงเส้นก่อน พล็อตกระจายของตัวแปรตามและตัวแปรอิสระจะใช้เพื่อตรวจสอบความสัมพันธ์นี้ ประการที่สอง ตัวแปรอิสระในชุดข้อมูลควรมีความสอดคล้องกันระหว่างตัวแปรอิสระน้อยที่สุดหรือเป็นศูนย์ แสดงว่าตัวแปรอิสระไม่เกี่ยวข้องกัน ค่าต้องถูกจำกัด ซึ่งกำหนดโดยข้อกำหนดของโดเมน Homoscedasticity เป็นปัจจัยที่สาม สมมติฐานที่ว่าข้อผิดพลาดมีการกระจายอย่างสม่ำเสมอเป็นหนึ่งในสมมติฐานที่สำคัญที่สุด