
การรักษา Node.js ให้รวดเร็ว: เครื่องมือ เทคนิค และเคล็ดลับสำหรับการสร้างเซิร์ฟเวอร์ Node.js ประสิทธิภาพสูง
เผยแพร่แล้ว: 2022-03-10หากคุณสร้างสิ่งใด ๆ ด้วย Node.js มานานพอ ไม่ต้องสงสัยเลยว่าคุณจะประสบปัญหาเกี่ยวกับความเร็วที่ไม่คาดคิดมาก่อนอย่างแน่นอน JavaScript เป็นภาษาที่มีเหตุการณ์แบบอะซิงโครนัส ที่สามารถให้เหตุผลเกี่ยวกับประสิทธิภาพที่ ยุ่งยาก อย่างที่จะเห็นได้ชัดเจน ความนิยมที่เพิ่มขึ้นของ Node.js ทำให้เห็นถึงความจำเป็นในการใช้เครื่องมือ เทคนิค และการคิดที่เหมาะสมกับข้อจำกัดของ JavaScript ฝั่งเซิร์ฟเวอร์
เมื่อพูดถึงประสิทธิภาพ สิ่งที่ใช้งานได้ในเบราว์เซอร์อาจไม่เหมาะกับ Node.js เสมอไป แล้วเราจะแน่ใจได้อย่างไรว่าการติดตั้ง Node.js นั้นรวดเร็วและเหมาะสมกับวัตถุประสงค์ มาดูตัวอย่างเชิงปฏิบัติกัน
เครื่องมือ
Node เป็นแพลตฟอร์มที่ใช้งานได้หลากหลายมาก แต่หนึ่งในแอปพลิเคชั่นที่โดดเด่นคือการสร้างกระบวนการในเครือข่าย เราจะมุ่งเน้นไปที่การทำโปรไฟล์โดยทั่วไป: เว็บเซิร์ฟเวอร์ HTTP
เราต้องการเครื่องมือที่สามารถทำลายเซิร์ฟเวอร์ที่มีคำขอจำนวนมากในขณะที่วัดประสิทธิภาพ ตัวอย่างเช่น เราสามารถใช้ AutoCannon:
npm install -g autocannonเครื่องมือเปรียบเทียบ HTTP ที่ดีอื่น ๆ ได้แก่ Apache Bench (ab) และ wrk2 แต่ AutoCannon เขียนด้วย Node ให้แรงกดในการโหลดที่คล้ายกัน (หรือบางครั้งสูงกว่า) และติดตั้งได้ง่ายมากบน Windows, Linux และ Mac OS X
หลังจากที่เราสร้างการวัดประสิทธิภาพพื้นฐานแล้ว หากเราตัดสินใจว่ากระบวนการของเราอาจเร็วขึ้น เราจะต้องใช้วิธีใดในการวินิจฉัยปัญหาของกระบวนการ เครื่องมือที่ยอดเยี่ยมสำหรับการวินิจฉัยปัญหาด้านประสิทธิภาพต่างๆ คือ Node Clinic ซึ่งสามารถติดตั้งได้ด้วย npm:
npm install -g clinicสิ่งนี้จะติดตั้งชุดเครื่องมือจริงๆ เราจะใช้ Clinic Doctor และ Clinic Flame (เสื้อคลุมประมาณ 0x) ในขณะที่เราไป
หมายเหตุ : สำหรับตัวอย่างเชิงปฏิบัตินี้ เราจำเป็นต้องใช้ Node 8.11.2 หรือสูงกว่า
รหัส
กรณีตัวอย่างของเราคือเซิร์ฟเวอร์ REST อย่างง่ายที่มีทรัพยากรเดียว: เพย์โหลด JSON ขนาดใหญ่เปิดเผยเป็นเส้นทาง GET ที่ /seed/v1 เซิร์ฟเวอร์เป็นโฟลเดอร์ app ที่ประกอบด้วยไฟล์ package.json (ขึ้นอยู่กับการ restify 7.1.0 ) ไฟล์ index.js และไฟล์ util.js
ไฟล์ index.js สำหรับเซิร์ฟเวอร์ของเรามีลักษณะดังนี้:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) เซิร์ฟเวอร์นี้เป็นตัวแทนของกรณีทั่วไปของการให้บริการเนื้อหาไดนามิกที่แคชโดยไคลเอ็นต์ สิ่งนี้ทำได้ด้วยมิดเดิลแวร์ etagger ซึ่งคำนวณส่วนหัว ETag สำหรับสถานะล่าสุดของเนื้อหา
ไฟล์ util.js จัดเตรียมชิ้นส่วนการใช้งานที่มักใช้ในสถานการณ์ดังกล่าว ฟังก์ชันเพื่อดึงเนื้อหาที่เกี่ยวข้องจากแบ็กเอนด์ มิดเดิลแวร์ etag และฟังก์ชันประทับเวลาที่จัดเตรียมการประทับเวลาแบบนาทีต่อนาที:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }ไม่ควรใช้โค้ดนี้เป็นตัวอย่างแนวทางปฏิบัติที่ดีที่สุด! ไฟล์นี้มีกลิ่นโค้ดหลายกลิ่น แต่เราจะระบุตำแหน่งขณะที่เราวัดและกำหนดโปรไฟล์ของแอปพลิเคชัน
เพื่อให้ได้แหล่งที่มาเต็มรูปแบบสำหรับจุดเริ่มต้นของเรา เซิร์ฟเวอร์ที่ช้าสามารถพบได้ที่นี่
โปรไฟล์
ในการสร้างโปรไฟล์ เราจำเป็นต้องมีเทอร์มินัลสองเครื่อง เทอร์มินัลหนึ่งสำหรับเริ่มแอปพลิเคชัน และอีกเครื่องหนึ่งสำหรับการทดสอบโหลด
ในเทอร์มินัลเดียว ภายใน app โฟลเดอร์ที่เราเรียกใช้ได้:
node index.jsในเทอร์มินัลอื่น เราสามารถกำหนดโปรไฟล์ได้ดังนี้:
autocannon -c100 localhost:3000/seed/v1การดำเนินการนี้จะเปิดการเชื่อมต่อพร้อมกัน 100 รายการและโจมตีเซิร์ฟเวอร์ด้วยคำขอเป็นเวลาสิบวินาที
ผลลัพธ์ควรเป็นสิ่งที่คล้ายกับต่อไปนี้ (รันการทดสอบ 10 วินาที @ https://localhost:3000/seed/v1 — 100 การเชื่อมต่อ):
| สถิติ | เฉลี่ย | Stdev | แม็กซ์ |
|---|---|---|---|
| เวลาในการตอบสนอง (มิลลิวินาที) | 3086.81 | 1725.2 | 5554 |
| คำขอ/วินาที | 23.1 | 19.18 | 65 |
| ไบต์/วินาที | 237.98 kB | 197.7 kB | 688.13 kB |
ผลลัพธ์จะแตกต่างกันไปขึ้นอยู่กับเครื่อง อย่างไรก็ตาม เมื่อพิจารณาว่าเซิร์ฟเวอร์ Node.js ของ “Hello World” นั้นสามารถขอสามหมื่นคำขอต่อวินาทีบนเครื่องที่สร้างผลลัพธ์เหล่านี้ได้อย่างง่ายดาย 23 คำขอต่อวินาทีโดยมีเวลาแฝงเฉลี่ยเกิน 3 วินาทีนั้นช่างน่าหดหู่
การวินิจฉัย
การค้นพบพื้นที่ปัญหา
เราสามารถวินิจฉัยแอปพลิเคชันด้วยคำสั่งเดียวด้วยคำสั่ง –on-port ของ Clinic Doctor ภายในโฟลเดอร์ app พที่เราเรียกใช้:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsสิ่งนี้จะสร้างไฟล์ HTML ที่จะเปิดโดยอัตโนมัติในเบราว์เซอร์ของเราเมื่อโปรไฟล์เสร็จสมบูรณ์
ผลลัพธ์ควรมีลักษณะดังนี้:
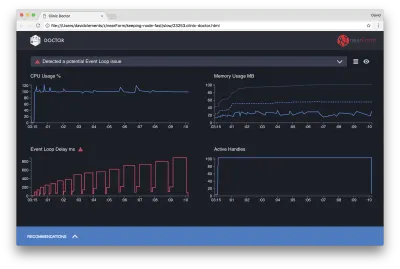
หมอกำลังบอกเราว่าเราน่าจะมีปัญหา Event Loop
นอกจากข้อความที่ด้านบนสุดของ UI แล้ว เรายังพบว่าแผนภูมิวนรอบเหตุการณ์เป็นสีแดง และแสดงการหน่วงเวลาที่เพิ่มขึ้นอย่างต่อเนื่อง ก่อนที่เราจะเจาะลึกลงไปถึงความหมายนี้ ก่อนอื่นมาทำความเข้าใจผลกระทบที่ปัญหาที่ได้รับการวินิจฉัยมีต่อเมตริกอื่นๆ ก่อน
เราจะเห็นว่า CPU อยู่ที่ 100% หรือสูงกว่า 100% เนื่องจากกระบวนการทำงานอย่างหนักเพื่อประมวลผลคำขอที่อยู่ในคิว เอ็นจิ้น JavaScript ของโหนด (V8) ใช้คอร์ CPU สองคอร์ในกรณีนี้เพราะเครื่องเป็นแบบมัลติคอร์และ V8 ใช้สองเธรด อันหนึ่งสำหรับ Event Loop และอีกอันสำหรับ Garbage Collection เมื่อเราเห็น CPU เพิ่มขึ้นถึง 120% ในบางกรณี กระบวนการกำลังรวบรวมวัตถุที่เกี่ยวข้องกับคำขอที่ได้รับการจัดการ
เราเห็นสิ่งนี้สัมพันธ์กันในกราฟหน่วยความจำ เส้นทึบในแผนภูมิ Memory คือเมตริก Heap Used ทุกครั้งที่มี CPU พุ่งสูงขึ้น เราจะเห็นการตกในบรรทัด Heap Used ซึ่งแสดงว่าหน่วยความจำกำลังถูกจัดสรรคืน
Active Handles จะไม่ได้รับผลกระทบจากความล่าช้าของ Event Loop หมายเลขอ้างอิงที่ใช้งานอยู่คืออ็อบเจ็กต์ที่แสดงถึง I/O (เช่น ซ็อกเก็ตหรือตัวจัดการไฟล์) หรือตัวจับเวลา (เช่น setInterval ) เราสั่งให้ AutoCannon เปิดการเชื่อมต่อ 100 ครั้ง ( -c100 ) แฮนเดิลที่แอ็คทีฟมีจำนวนคงที่ที่ 103 อีกสามแฮนเดิลสำหรับ STDOUT, STDERR และแฮนเดิลสำหรับเซิร์ฟเวอร์เอง
หากเราคลิกแผงคำแนะนำที่ด้านล่างของหน้าจอ เราควรจะเห็นสิ่งต่อไปนี้:
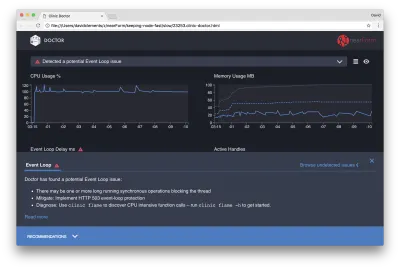
การบรรเทาผลกระทบระยะสั้น
การวิเคราะห์สาเหตุของปัญหาด้านประสิทธิภาพที่ร้ายแรงอาจต้องใช้เวลา ในกรณีของโปรเจ็กต์ที่ใช้งานจริง การเพิ่มการป้องกันโอเวอร์โหลดให้กับเซิร์ฟเวอร์หรือบริการก็คุ้มค่า แนวคิดของการป้องกันการโอเวอร์โหลดคือการตรวจสอบการหน่วงเวลาของลูปเหตุการณ์ (เหนือสิ่งอื่นใด) และตอบสนองด้วย "503 บริการไม่พร้อมใช้งาน" หากผ่านขีดจำกัด วิธีนี้ทำให้ตัวโหลดบาลานซ์สามารถเฟลโอเวอร์ไปยังอินสแตนซ์อื่นได้ หรือในกรณีที่เลวร้ายที่สุด ผู้ใช้จะต้องรีเฟรช โมดูลป้องกันการโอเวอร์โหลดสามารถจัดให้มีโอเวอร์เฮดขั้นต่ำสำหรับ Express, Koa และ Restify กรอบงาน Hapi มีการตั้งค่าการกำหนดค่าโหลดซึ่งให้การป้องกันแบบเดียวกัน
การทำความเข้าใจพื้นที่ปัญหา
ตามคำอธิบายสั้นๆ ใน Clinic Doctor อธิบายว่า หาก Event Loop ล่าช้าไปถึงระดับที่เรากำลังสังเกตอยู่ มีความเป็นไปได้สูงที่ฟังก์ชันอย่างน้อย 1 ฟังก์ชันจะ "บล็อก" Event Loop
เป็นสิ่งสำคัญโดยเฉพาะอย่างยิ่งกับ Node.js ที่จะต้องรู้จักคุณลักษณะ JavaScript หลักนี้: เหตุการณ์แบบอะซิงโครนัสไม่สามารถเกิดขึ้นได้จนกว่าการรันโค้ดในปัจจุบันจะเสร็จสิ้น
นี่คือสาเหตุที่ setTimeout ไม่สามารถแม่นยำได้
ตัวอย่างเช่น ลองเรียกใช้สิ่งต่อไปนี้ใน DevTools ของเบราว์เซอร์หรือ Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() การวัดเวลาที่ได้จะไม่เท่ากับ 100 มิลลิวินาที มีแนวโน้มว่าจะอยู่ในช่วง 150ms ถึง 250ms setTimeout กำหนดเวลาการดำเนินการแบบอะซิงโครนัส ( console.timeEnd ) แต่โค้ดที่กำลังดำเนินการอยู่ยังไม่เสร็จสมบูรณ์ มีอีกสองบรรทัด รหัสที่กำลังดำเนินการอยู่เรียกว่า "ขีด" ปัจจุบัน เพื่อให้ติ๊กสมบูรณ์ ต้องเรียก Math.random สิบล้านครั้ง หากใช้เวลา 100 มิลลิวินาที เวลาทั้งหมดก่อนที่จะหมดเวลาแก้ไขจะเป็น 200 มิลลิวินาที (บวกกับเวลาที่ฟังก์ชัน setTimeout ใช้เวลานานในการจัดคิวการหมดเวลาก่อนจริง ๆ โดยทั่วไปคือสองสามมิลลิวินาที)
ในบริบทฝั่งเซิร์ฟเวอร์ หากการดำเนินการในขีดปัจจุบันใช้เวลานานในการดำเนินการตามคำขอ จะไม่สามารถจัดการได้ และการดึงข้อมูลจะไม่เกิดขึ้นเนื่องจากโค้ดอะซิงโครนัสจะไม่ถูกดำเนินการจนกว่าขีดปัจจุบันจะเสร็จสิ้น ซึ่งหมายความว่าโค้ดที่มีราคาแพงในการประมวลผลจะทำให้การโต้ตอบทั้งหมดกับเซิร์ฟเวอร์ช้าลง ดังนั้นจึงแนะนำให้แยกงานที่ต้องใช้ทรัพยากรมากออกเป็นกระบวนการแยกต่างหากและเรียกใช้จากเซิร์ฟเวอร์หลัก ซึ่งจะหลีกเลี่ยงกรณีที่เส้นทางที่ไม่ค่อยได้ใช้แต่ราคาแพงจะทำให้ประสิทธิภาพของเส้นทางอื่นที่ใช้บ่อยแต่ราคาถูกช้าลง
เซิร์ฟเวอร์ตัวอย่างมีรหัสที่บล็อก Event Loop ดังนั้นขั้นตอนต่อไปคือการค้นหารหัสนั้น
กำลังวิเคราะห์
วิธีหนึ่งในการระบุโค้ดที่มีประสิทธิภาพต่ำอย่างรวดเร็วคือการสร้างและวิเคราะห์กราฟเปลวไฟ กราฟเปลวไฟแสดงถึงการเรียกใช้ฟังก์ชันเป็นบล็อกที่วางทับกัน — ไม่ใช่เมื่อเวลาผ่านไปแต่เป็นการรวม เหตุผลที่เรียกว่า 'กราฟเปลวไฟ' ก็เพราะว่าโดยทั่วไปแล้วจะใช้รูปแบบสีส้มถึงแดง โดยที่ฟังก์ชันยิ่งสีแดงยิ่ง "ร้อนแรง" มากขึ้นเท่านั้น หมายความว่ายิ่งมีแนวโน้มที่จะบล็อกการวนซ้ำของเหตุการณ์มากขึ้นเท่านั้น การจับข้อมูลสำหรับกราฟเปลวไฟจะดำเนินการผ่านการสุ่มตัวอย่าง CPU ซึ่งหมายความว่าจะมีการถ่ายภาพสแนปชอตของฟังก์ชันที่กำลังดำเนินการอยู่และเป็นกองซ้อน ความร้อนถูกกำหนดโดยเปอร์เซ็นต์ของเวลาระหว่างการทำโปรไฟล์ที่ฟังก์ชันที่กำหนดอยู่ที่ด้านบนของสแต็ก (เช่น ฟังก์ชันที่กำลังดำเนินการอยู่) สำหรับแต่ละตัวอย่าง หากไม่ใช่ฟังก์ชันสุดท้ายที่เคยถูกเรียกใช้ภายในสแต็กนั้น ก็มีแนวโน้มว่าจะบล็อกการวนซ้ำของเหตุการณ์
ลองใช้ clinic flame เพื่อสร้างกราฟเปลวไฟของแอปพลิเคชันตัวอย่าง:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsผลลัพธ์ควรเปิดขึ้นในเบราว์เซอร์ของเราโดยมีลักษณะดังนี้:
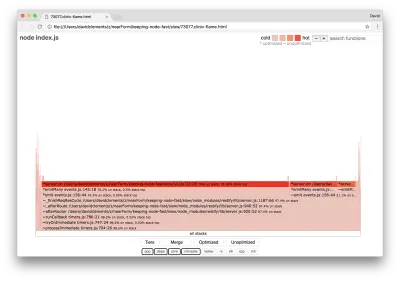
ความกว้างของบล็อกแสดงถึงระยะเวลาที่ใช้กับ CPU โดยรวม สามกองหลักสามารถสังเกตได้กินเวลามากที่สุด โดยทั้งหมดเน้นว่า server.on เป็นฟังก์ชันที่ร้อนแรงที่สุด อันที่จริงทั้งสามกองเหมือนกัน พวกเขาแตกต่างกันเพราะในระหว่างการทำโปรไฟล์ที่ปรับให้เหมาะสมและฟังก์ชั่นที่ไม่ได้ปรับให้เหมาะสมจะถือว่าเป็นเฟรมการโทรที่แยกจากกัน ฟังก์ชันที่นำหน้าด้วย * ได้รับการปรับให้เหมาะสมโดยเอ็นจิ้น JavaScript และฟังก์ชันที่นำหน้าด้วย ~ จะไม่ได้รับการปรับให้เหมาะสม หากสถานะที่ปรับให้เหมาะสมไม่สำคัญสำหรับเรา เราสามารถลดความซับซ้อนของกราฟเพิ่มเติมได้โดยกดปุ่มผสาน สิ่งนี้ควรนำไปสู่การดูคล้ายกับต่อไปนี้:
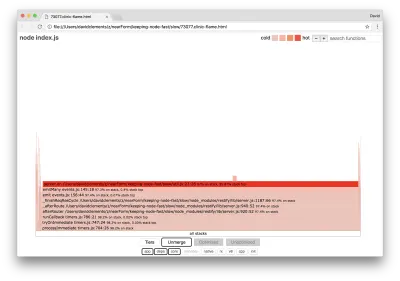
จากจุดเริ่มต้น เราสามารถอนุมานได้ว่ารหัสที่ละเมิดอยู่ในไฟล์ util.js ของรหัสแอปพลิเคชัน
ฟังก์ชันที่ช้ายังเป็นตัวจัดการเหตุการณ์อีกด้วย: ฟังก์ชันที่นำไปสู่ฟังก์ชันนี้เป็นส่วนหนึ่งของโมดูล events หลัก และ server.on เป็นชื่อทางเลือกสำหรับฟังก์ชันที่ไม่ระบุตัวตนที่จัดเตรียมไว้เป็นฟังก์ชันการจัดการเหตุการณ์ นอกจากนี้เรายังสามารถเห็นได้ว่ารหัสนี้ไม่อยู่ในเครื่องหมายเดียวกับรหัสที่จัดการกับคำขอจริงๆ ถ้าเป็นเช่นนั้น ฟังก์ชันจากโมดูล core http , net และ stream จะอยู่ในสแต็ก
ฟังก์ชันหลักดังกล่าวสามารถพบได้โดยการขยายส่วนอื่น ๆ ที่เล็กกว่ามากของกราฟเปลวไฟ ตัวอย่างเช่น ลองใช้อินพุตการค้นหาที่ด้านบนขวาของ UI เพื่อค้นหาการ send (ชื่อของวิธีการภายในทั้ง restify และ http ) ควรอยู่ทางขวาของกราฟ (ฟังก์ชันเรียงตามตัวอักษร):
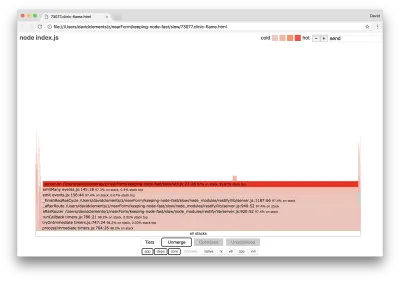
สังเกตว่าบล็อกการจัดการ HTTP จริงทั้งหมดมีขนาดเล็กเพียงใด

เราสามารถคลิกหนึ่งในบล็อกที่ไฮไลต์เป็นสีฟ้า ซึ่งจะขยายเพื่อแสดงฟังก์ชันต่างๆ เช่น writeHead และ write ในไฟล์ http_outgoing.js (ส่วนหนึ่งของไลบรารี Node core http ):
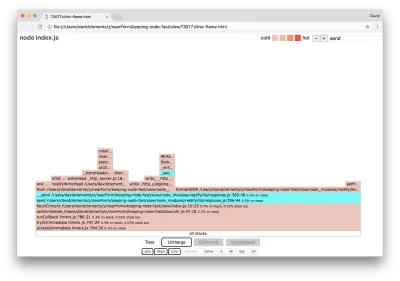
เราสามารถคลิก กองทั้งหมด เพื่อกลับไปที่มุมมองหลัก
จุดสำคัญที่นี่คือแม้ว่าฟังก์ชัน server.on จะไม่อยู่ในเครื่องหมายเดียวกับรหัสการจัดการคำขอจริง แต่ก็ยังส่งผลต่อประสิทธิภาพเซิร์ฟเวอร์โดยรวมโดยการชะลอการทำงานของโค้ดที่มีประสิทธิภาพ
แก้จุดบกพร่อง
เราทราบจากกราฟเปลวไฟว่าฟังก์ชันที่เป็นปัญหาคือตัวจัดการเหตุการณ์ที่ส่งผ่านไปยัง server.on ในไฟล์ util.js
ลองดู:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) เป็นที่ทราบกันดีว่าการเข้ารหัสมีแนวโน้มที่จะมีราคาแพง เช่นเดียวกับการทำให้เป็นอนุกรม ( JSON.stringify ) แต่ทำไมไม่ปรากฏในกราฟเปลวไฟ การดำเนินการเหล่านี้อยู่ในตัวอย่างที่จับได้ แต่ซ่อนอยู่หลังตัวกรอง cpp หากเรากดปุ่ม cpp เราจะเห็นสิ่งต่อไปนี้:
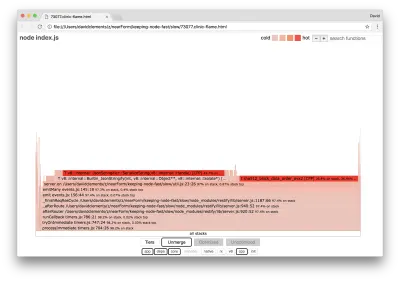
คำแนะนำ V8 ภายในที่เกี่ยวข้องกับทั้งการทำให้เป็นอนุกรมและการเข้ารหัสจะแสดงเป็นสแต็กที่ร้อนแรงที่สุดและใช้เวลาส่วนใหญ่ เมธอด JSON.stringify เรียกโค้ด C++ โดยตรง นี่คือเหตุผลที่เราไม่เห็นฟังก์ชัน JavaScript ในกรณีของการเข้ารหัส ฟังก์ชันต่างๆ เช่น createHash และ update จะอยู่ในข้อมูล แต่ฟังก์ชันเหล่านี้อาจอยู่ในแนวเดียวกัน (ซึ่งหมายความว่าฟังก์ชันเหล่านี้จะหายไปในมุมมองที่ผสาน) หรือมีขนาดเล็กเกินไปที่จะแสดงผล
เมื่อเราเริ่มให้เหตุผลเกี่ยวกับโค้ดในฟังก์ชัน etagger แล้ว จะเห็นได้ชัดเจนว่าโค้ดนี้ออกแบบมาไม่ดี เหตุใดเราจึงใช้อินสแตนซ์ของ server จากบริบทของฟังก์ชัน มีการแฮชเกิดขึ้นมากมาย จำเป็นทั้งหมดหรือไม่ นอกจากนี้ ยังไม่มีการรองรับส่วนหัว If-None-Match ในการใช้งานซึ่งจะช่วยลดภาระงานบางส่วนในสถานการณ์จริงบางสถานการณ์ เนื่องจากลูกค้าจะส่งคำขอหลักเพื่อกำหนดความสดเท่านั้น
ให้ละเว้นประเด็นเหล่านี้ทั้งหมดในขณะนี้และตรวจสอบการค้นพบว่างานจริงที่กำลังดำเนินการใน server.on เป็นคอขวดอย่างแท้จริง สิ่งนี้สามารถทำได้โดยการตั้งค่ารหัส server.on เป็นฟังก์ชันว่างและสร้างแฟล็กกราฟใหม่
เปลี่ยนฟังก์ชัน etagger ดังต่อไปนี้:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } ฟังก์ชันตัวฟังเหตุการณ์ที่ส่งผ่านไปยัง server.on ตอนนี้เป็นแบบ no-op
มาเรียกใช้ clinic flame มกันอีกครั้ง:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsสิ่งนี้ควรสร้างกราฟเปลวไฟที่คล้ายกับต่อไปนี้:
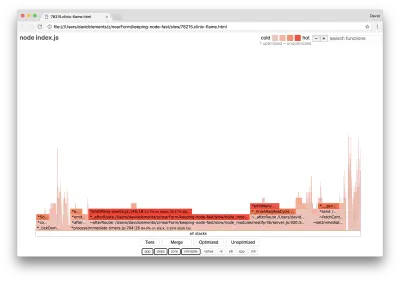
สิ่งนี้ดูดีขึ้น และเราน่าจะสังเกตเห็นการเพิ่มขึ้นของคำขอต่อวินาที แต่ทำไมโค้ดการเปล่งเหตุการณ์ถึงร้อนมาก? เราคาดว่า ณ จุดนี้รหัสการประมวลผล HTTP จะใช้เวลาส่วนใหญ่ของ CPU ไม่มีอะไรดำเนินการเลยในเหตุการณ์ server.on
ปัญหาคอขวดประเภทนี้เกิดจากฟังก์ชันที่ถูกเรียกใช้งานมากกว่าที่ควรจะเป็น
รหัสที่น่าสงสัยต่อไปนี้ที่ด้านบนของ util.js อาจเป็นเบาะแส:
require('events').defaultMaxListeners = Infinity มาลบบรรทัดนี้และเริ่มกระบวนการของเราด้วย --trace-warnings :
node --trace-warnings index.jsหากเราสร้างโปรไฟล์ด้วย AutoCannon ในเทอร์มินัลอื่น เช่น:
autocannon -c100 localhost:3000/seed/v1กระบวนการของเราจะส่งออกสิ่งที่คล้ายกับ:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
โหนดกำลังบอกเราว่ามีการแนบเหตุการณ์จำนวนมากกับวัตถุ เซิร์ฟเวอร์ สิ่งนี้แปลกเพราะมีบูลีนที่ตรวจสอบว่ามีการแนบเหตุการณ์แล้วกลับมาก่อนกำหนดโดยพื้นฐานแล้วทำให้ AttachAfterEvent เป็น no-op หลังจากแนบกิจกรรมแรกแล้ว
มาดูฟังก์ชัน attachAfterEvent กัน:
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } การตรวจสอบเงื่อนไขไม่ถูกต้อง! จะตรวจสอบว่า attachAfterEvent เป็นจริงหรือไม่ แทนที่จะเป็น afterEventAttached ซึ่งหมายความว่าจะมีการแนบเหตุการณ์ใหม่กับอินสแตนซ์ของ server ในทุกคำขอ จากนั้นกิจกรรมที่แนบก่อนหน้าทั้งหมดจะถูกไล่ออกหลังจากแต่ละคำขอ อ๊ะ!
เพิ่มประสิทธิภาพ
ตอนนี้เราได้ค้นพบส่วนปัญหาแล้ว มาดูกันว่าเราจะทำให้เซิร์ฟเวอร์เร็วขึ้นหรือไม่
ผลไม้ห้อยต่ำ
มาใส่รหัสตัวฟังของ server.on กลับกัน (แทนที่จะเป็นฟังก์ชันว่าง) และใช้ชื่อบูลีนที่ถูกต้องในการตรวจสอบตามเงื่อนไข ฟังก์ชัน etagger ของเรามีลักษณะดังนี้:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }ตอนนี้เราตรวจสอบการแก้ไขด้วยการทำโปรไฟล์อีกครั้ง เริ่มเซิร์ฟเวอร์ในเทอร์มินัลเดียว:
node index.jsจากนั้นโปรไฟล์ด้วย AutoCannon:
autocannon -c100 localhost:3000/seed/v1 เราควรเห็นผลลัพธ์ในช่วงของการปรับปรุง 200 เท่า (การทดสอบรัน 10 วินาที @ https://localhost:3000/seed/v1 — การเชื่อมต่อ 100 ครั้ง):
| สถิติ | เฉลี่ย | Stdev | แม็กซ์ |
|---|---|---|---|
| เวลาในการตอบสนอง (มิลลิวินาที) | 19.47 | 4.29 | 103 |
| คำขอ/วินาที | 5011.11 | 506.2 | 5487 |
| ไบต์/วินาที | 51.8 MB | 5.45 MB | 58.72 MB |
สิ่งสำคัญคือต้องปรับสมดุลการลดต้นทุนเซิร์ฟเวอร์ที่อาจเกิดขึ้นกับต้นทุนการพัฒนา เราจำเป็นต้องกำหนดในบริบทสถานการณ์ของเราเองว่าเราต้องใช้ความพยายามในการเพิ่มประสิทธิภาพโครงการมากเพียงใด มิฉะนั้น มันอาจจะง่ายเกินไปที่จะใส่ 80% ของความพยายามลงใน 20% ของการปรับปรุงความเร็ว ข้อ จำกัด ของโครงการพิสูจน์สิ่งนี้หรือไม่?
ในบางสถานการณ์ อาจเหมาะสมที่จะบรรลุการปรับปรุง 200 เท่าด้วยผลไม้ห้อยต่ำและเรียกว่าเป็นวันเดียว ในส่วนอื่นๆ เราอาจต้องการทำให้การติดตั้งใช้งานของเรารวดเร็วที่สุดเท่าที่จะทำได้ มันขึ้นอยู่กับลำดับความสำคัญของโครงการจริงๆ
วิธีหนึ่งในการควบคุมการใช้ทรัพยากรคือการกำหนดเป้าหมาย ตัวอย่างเช่น ปรับปรุง 10 เท่า หรือ 4000 คำขอต่อวินาที การพิจารณาความต้องการทางธุรกิจเป็นสิ่งที่สมเหตุสมผลที่สุด ตัวอย่างเช่น หากเซิร์ฟเวอร์มีค่าใช้จ่ายเกินงบประมาณ 100% เราสามารถตั้งเป้าหมายการปรับปรุงได้ 2 เท่า
ก้าวต่อไป
หากเราสร้างกราฟเปลวไฟใหม่บนเซิร์ฟเวอร์ของเรา เราควรเห็นสิ่งต่อไปนี้:
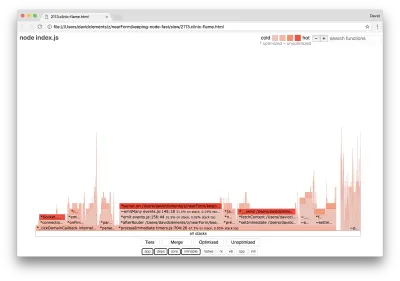
ตัวฟังเหตุการณ์ยังคงเป็นคอขวด แต่ก็ยังใช้เวลา CPU ไปหนึ่งในสามระหว่างการทำโปรไฟล์ (ความกว้างประมาณหนึ่งในสามของกราฟทั้งหมด)
สามารถทำกำไรเพิ่มเติมอะไรได้บ้าง และการเปลี่ยนแปลง (พร้อมกับการหยุดชะงักที่เกี่ยวข้อง) คุ้มค่าหรือไม่?
ด้วยการใช้งานที่ปรับให้เหมาะสมที่สุด ซึ่งยังคงมีข้อจำกัดมากกว่าเล็กน้อย คุณสามารถบรรลุคุณลักษณะด้านประสิทธิภาพต่อไปนี้ (รันการทดสอบ 10 วินาที @ https://localhost:3000/seed/v1 — การเชื่อมต่อ 10 ครั้ง):
| สถิติ | เฉลี่ย | Stdev | แม็กซ์ |
|---|---|---|---|
| เวลาในการตอบสนอง (มิลลิวินาที) | 0.64 | 0.86 | 17 |
| คำขอ/วินาที | 8330.91 | 757.63 | 8991 |
| ไบต์/วินาที | 84.17 MB | 7.64 MB | 92.27 MB |
แม้ว่าการปรับปรุง 1.6 เท่าจะมีความสำคัญ แต่ก็สามารถโต้แย้งได้ขึ้นอยู่กับสถานการณ์ว่าความพยายาม การเปลี่ยนแปลง และการหยุดชะงักของโค้ดที่จำเป็นในการสร้างการปรับปรุงนี้มีความสมเหตุสมผลหรือไม่ โดยเฉพาะอย่างยิ่งเมื่อเทียบกับการปรับปรุง 200x ในการใช้งานดั้งเดิมด้วยการแก้ไขข้อผิดพลาดเพียงครั้งเดียว
เพื่อให้บรรลุการปรับปรุงนี้ มีการใช้เทคนิคการทำซ้ำแบบเดียวกันของโปรไฟล์ สร้าง flamegraph วิเคราะห์ ดีบัก และเพิ่มประสิทธิภาพเพื่อไปยังเซิร์ฟเวอร์ที่ปรับให้เหมาะสมขั้นสุดท้าย ซึ่งสามารถดูรหัสได้ที่นี่
การเปลี่ยนแปลงขั้นสุดท้ายเพื่อให้ถึง 8000 req/s คือ:
- อย่าสร้างวัตถุแล้วทำให้เป็นอนุกรม สร้างสตริงของ JSON โดยตรง
- ใช้สิ่งที่ไม่ซ้ำใครเกี่ยวกับเนื้อหาเพื่อกำหนดเป็น Etag แทนที่จะสร้างแฮช
- อย่าแฮช URL ใช้เป็นคีย์โดยตรง
การเปลี่ยนแปลงเหล่านี้มีความเกี่ยวข้องมากขึ้นเล็กน้อย ก่อกวนต่อฐานโค้ดเล็กน้อย และทำให้มิดเดิลแวร์ etagger มีความยืดหยุ่นน้อยลงเล็กน้อย เนื่องจากเป็นภาระบนเส้นทางในการจัดเตรียมค่า Etag แต่มันบรรลุคำขอพิเศษ 3000 ต่อวินาทีบนเครื่องสร้างโปรไฟล์
มาดูกราฟเปลวไฟสำหรับการปรับปรุงขั้นสุดท้ายเหล่านี้กัน:
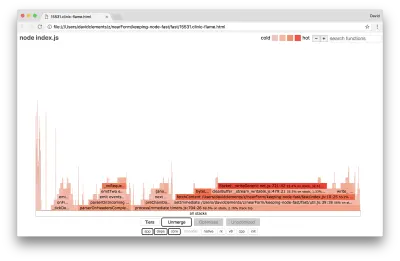
ส่วนที่ร้อนแรงที่สุดของกราฟเปลวไฟเป็นส่วนหนึ่งของแกนโหนดในโมดูล net นี้เหมาะ
การป้องกันปัญหาด้านประสิทธิภาพ
เพื่อเป็นการปิดท้าย ต่อไปนี้คือคำแนะนำบางประการเกี่ยวกับวิธีป้องกันปัญหาด้านประสิทธิภาพก่อนที่จะนำไปใช้งาน
การใช้เครื่องมือประสิทธิภาพเป็นจุดตรวจสอบที่ไม่เป็นทางการระหว่างการพัฒนาสามารถกรองจุดบกพร่องด้านประสิทธิภาพออกก่อนที่จะนำไปใช้จริง แนะนำให้ทำ AutoCannon and Clinic (หรือเทียบเท่า) เป็นส่วนหนึ่งของเครื่องมือในการพัฒนาทุกวัน
เมื่อซื้อกรอบงาน ให้ค้นหาว่านโยบายเกี่ยวกับประสิทธิภาพคืออะไร หากกรอบงานไม่ได้จัดลำดับความสำคัญของประสิทธิภาพ สิ่งสำคัญคือต้องตรวจสอบว่าสอดคล้องกับแนวทางปฏิบัติด้านโครงสร้างพื้นฐานและเป้าหมายทางธุรกิจหรือไม่ ตัวอย่างเช่น Restify ได้ลงทุนอย่างชัดเจน (ตั้งแต่เปิดตัวเวอร์ชัน 7) ในการเพิ่มประสิทธิภาพของไลบรารี อย่างไรก็ตาม หากต้นทุนต่ำและความเร็วสูงเป็นลำดับความสำคัญสูงสุด ให้พิจารณา Fastify ซึ่งผู้มีส่วนร่วมของ Restify วัดได้เร็วกว่า 17%
ระวังตัวเลือกห้องสมุดอื่นๆ ที่ส่งผลกระทบในวงกว้าง — โดยเฉพาะการพิจารณาการบันทึก ในขณะที่นักพัฒนาแก้ไขปัญหา พวกเขาอาจตัดสินใจเพิ่มเอาต์พุตบันทึกเพิ่มเติมเพื่อช่วยดีบักปัญหาที่เกี่ยวข้องในอนาคต หากใช้คนตัดไม้ที่ไม่มีประสิทธิภาพ สิ่งนี้อาจทำให้ประสิทธิภาพการทำงานแย่ลงเมื่อเวลาผ่านไปหลังจากแฟชั่นของนิทานกบที่กำลังเดือด ตัวบันทึก pino เป็นตัวบันทึก JSON ที่คั่นด้วยการขึ้นบรรทัดใหม่ที่เร็วที่สุดสำหรับ Node.js
สุดท้ายนี้ โปรดจำไว้เสมอว่า Event Loop เป็นทรัพยากรที่ใช้ร่วมกัน เซิร์ฟเวอร์ Node.js ถูกจำกัดด้วยตรรกะที่ช้าที่สุดในเส้นทางที่ร้อนแรงที่สุด