
7 อัลกอริธึมการเรียนรู้ของเครื่องที่ใช้มากที่สุดใน Python ที่คุณควรรู้
เผยแพร่แล้ว: 2021-03-04การเรียนรู้ของเครื่องเป็นสาขาหนึ่งของปัญญาประดิษฐ์ (AI) ซึ่งเกี่ยวข้องกับอัลกอริทึมของคอมพิวเตอร์ที่ใช้กับข้อมูลใดๆ โดยเน้นการเรียนรู้โดยอัตโนมัติจากข้อมูลที่ป้อนเข้าไป และให้ผลลัพธ์โดยการปรับปรุงการคาดคะเนครั้งก่อนทุกครั้ง
สารบัญ
อัลกอริธึมการเรียนรู้ของเครื่องยอดนิยมที่ใช้ใน Python
ด้านล่างนี้คืออัลกอริธึมแมชชีนเลิร์นนิงชั้นนำบางส่วนที่ใช้ใน Python พร้อมด้วยข้อมูลโค้ดแสดงการใช้งานและการแสดงภาพขอบเขตการจัดหมวดหมู่
1. การถดถอยเชิงเส้น
การถดถอยเชิงเส้นเป็นหนึ่งในเทคนิคการเรียนรู้ของเครื่องภายใต้การดูแลที่ใช้บ่อยที่สุด ตามชื่อของมัน การถดถอยนี้พยายามจำลองความสัมพันธ์ระหว่างตัวแปรสองตัวโดยใช้สมการเชิงเส้นและปรับเส้นนั้นให้เข้ากับข้อมูลที่สังเกตได้ เทคนิคนี้ใช้เพื่อประเมินมูลค่าต่อเนื่องที่แท้จริง เช่น ยอดขายรวมหรือต้นทุนบ้าน
เส้นที่พอดีที่สุดเรียกอีกอย่างว่าเส้นถดถอย มันถูกกำหนดโดยสมการต่อไปนี้:
Y = a*X + b
โดยที่ Y คือตัวแปรตาม a คือความชัน X คือตัวแปรอิสระและ b คือค่าการสกัดกั้น สัมประสิทธิ์ a และ b ได้มาจากการลดกำลังสองของผลต่างของระยะห่างนั้นระหว่างจุดข้อมูลต่างๆ และสมการเส้นถดถอย

# ชุดข้อมูลสังเคราะห์สำหรับการถดถอยอย่างง่าย
จาก sklearn.datasets นำเข้า make_regression
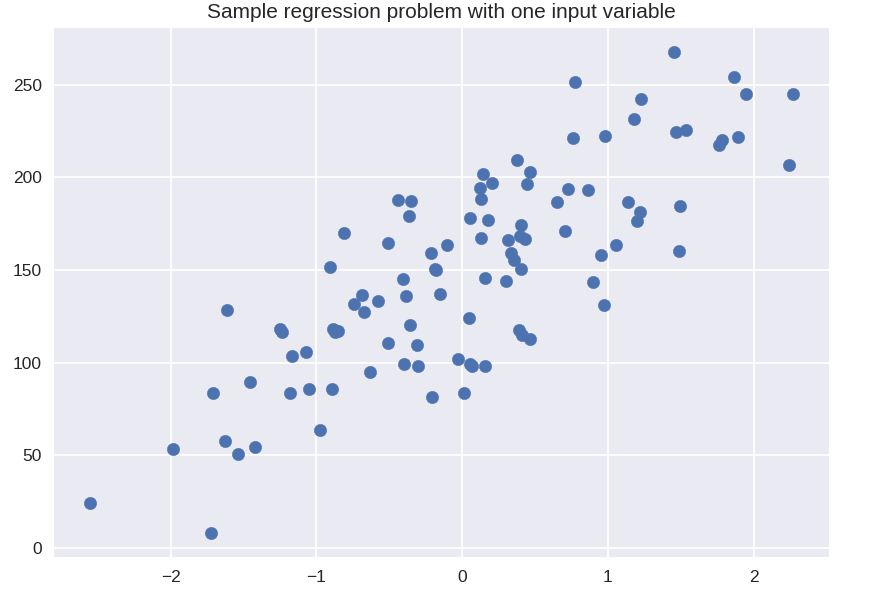
plt.figure()
plt.title( 'ปัญหาการถดถอยตัวอย่างกับตัวแปรอินพุตหนึ่งตัว' )
X_R1, y_R1 = make_regression( n_samples = 100, n_features = 1, n_informative = 1, bias = 150.0, noise = 30, random_state = 0 )
plt.scatter ( X_R1, y_R1, เครื่องหมาย = 'o', s = 50 )
plt.show()
จาก sklearn.linear_model นำเข้า LinearRegression
X_train, X_test, y_train, y_test = train_test_split ( X_R1, y_R1,
random_state = 0 )
linreg = การถดถอยเชิงเส้น ().fit ( X_train, y_train )
พิมพ์ ( 'coeff โมเดลเชิงเส้น (w): {}'.format( linreg.coef_ ) )
พิมพ์ ( 'การสกัดกั้นแบบจำลองเชิงเส้น (b): {:.3f}'z.format ( linreg.intercept_ ) )
พิมพ์ ( 'R-squared score (การฝึก): {:.3f}'.format( linreg.score( X_train, y_train ) ) )
พิมพ์ ( 'R-squared score (ทดสอบ): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
เอาท์พุต
coeff แบบจำลองเชิงเส้น (w): [45.71]
การสกัดกั้นแบบจำลองเชิงเส้น (b): 148.446
คะแนน R-squared (การฝึก): 0.679
คะแนน R-squared (ทดสอบ): 0.492
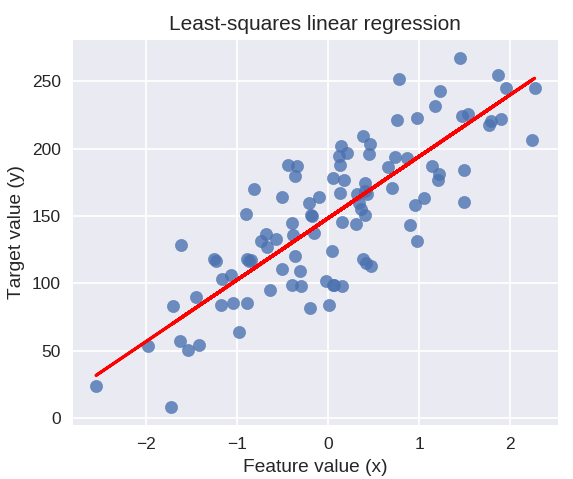
รหัสต่อไปนี้จะวาดเส้นการถดถอยที่ติดตั้งบนจุดข้อมูลของเรา
plt.figure( ขนาดฟิก = ( 5, 4) )
plt.scatter ( X_R1, y_R1, marker = 'o', s = 50, alpha = 0.8 )
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title( 'การถดถอยเชิงเส้นกำลังสองน้อยที่สุด' )
plt.xlabel( 'ค่าคุณลักษณะ (x)' )
plt.ylabel( 'ค่าเป้าหมาย (y)' )
plt.show()
การเตรียมชุดข้อมูลทั่วไปสำหรับการสำรวจเทคนิคการจำแนกประเภท
ข้อมูลต่อไปนี้จะใช้เพื่อแสดงอัลกอริธึมการจำแนกประเภทต่างๆ ซึ่งมักใช้ในการเรียนรู้ของเครื่องใน Python
ชุด ข้อมูลเห็ด UCI ถูกเก็บไว้ใน Mushrooms.csv
%matplotlib สมุดบันทึก
นำเข้าแพนด้าเป็น pd
นำเข้า numpy เป็น np
นำเข้า matplotlib.pyplot เป็น plt
จาก sklearn.decomposition นำเข้า PCA
จาก sklearn.model_selection นำเข้า train_test_split
df = pd.read_csv( 'อ่านอย่างเดียว/mushrooms.csv' )
df2 = pd.get_dummies( df )
df3 = df2.sample( frac = 0.08)
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
pca = PCA( n_components = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
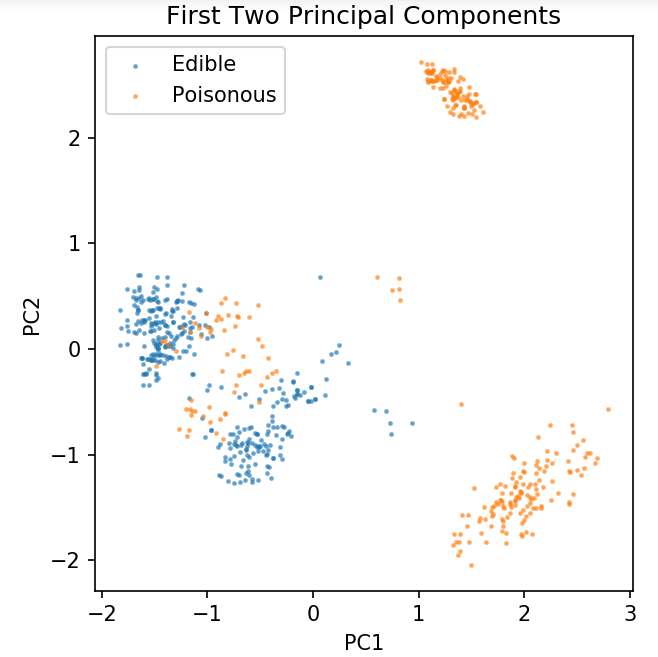
plt.figure (dpi = 120 )
plt.scatter ( pca[y.values == 0, 0], pca[y.values == 0, 1], alpha = 0.5, label = 'กินได้', s = 2 )
plt.scatter ( pca[y.values == 1, 0], pca[y.values == 1, 1], alpha = 0.5, label = 'เป็นพิษ', s = 2 )
plt.ตำนาน()
plt.title( 'ชุดข้อมูลเห็ด\nส่วนประกอบหลักสองส่วนแรก' )
plt.xlabel( 'PC1' )
plt.ylabel( 'PC2' )
plt.gca().set_aspect( 'เท่ากับ' )
เราจะใช้ฟังก์ชันที่กำหนดไว้ด้านล่างเพื่อรับขอบเขตการตัดสินใจของตัวแยกประเภทต่างๆ ที่เราจะใช้กับชุดข้อมูลเห็ด
def plot_mushroom_boundary ( X, y, Fit_model ):
plt.figure( figsize = (9.8, 5), dpi = 100 )
สำหรับฉัน plot_type ในการแจกแจง ( ['ขอบเขตการตัดสินใจ', 'ความน่าจะเป็นในการตัดสินใจ'] ):
plt.subplot( 1, 2, i + 1 )
mesh_step_size = 0.01 # ขนาดขั้นตอนใน mesh
x_min, x_max = X[:, 0].min() – .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange( y_min, y_max, mesh_step_size ) )
ถ้าฉัน == 0:
Z = fit_model.predict( np.c_[xx.ravel(), yy.ravel()] )
อื่น:
พยายาม:
Z = Fitt_model.predict_proba( np.c_[xx.ravel(), yy.ravel()] )[:, 1]
ยกเว้น:
plt.text ( 0.4, 0.5, 'ความน่าจะเป็นไม่พร้อมใช้งาน', การจัดแนวแนวนอน = 'ศูนย์กลาง', การจัดแนวแนวตั้ง = 'ศูนย์กลาง', การแปลง = plt.gca().transAxes, ขนาดฟอนต์ = 12 )
plt.axis( 'ปิด' )
หยุดพัก
Z = Z.reshape ( xx.รูปร่าง )
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alpha = 0.4, label = 'กินได้', s = 5 )
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alpha = 0.4, label = 'Posionous', s = 5 )
plt.imshow ( Z, การประมาณค่า = 'ใกล้ที่สุด', cmap = 'RdYlBu_r', alpha = 0.15, ขอบเขต = ( x_min, x_max, y_min, y_max ), origin = 'lower' )
plt.title( plot_type + '\n' + str( Fit_model ).split( '(' )[0] + ' ความแม่นยำในการทดสอบ: ' + str( np.round( Fit_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect( 'เท่ากับ' );
plt.tight_layout()
plt.subplots_adjust( บน = 0.9, ล่าง = 0.08, wspace = 0.02 )
2. การถดถอยโลจิสติก
แตกต่างจากการถดถอยเชิงเส้นตรง การถดถอยโลจิสติกเกี่ยวข้องกับการประมาณค่าที่ไม่ต่อเนื่อง (ค่าไบนารี 0/1, จริง/เท็จ, ใช่/ไม่ใช่) เทคนิคนี้เรียกอีกอย่างว่า logit regression เนื่องจากเป็นการทำนายความน่าจะเป็นของเหตุการณ์โดยใช้ฟังก์ชัน logit เพื่อฝึกข้อมูลที่กำหนด ค่าจะอยู่ระหว่าง 0 ถึง 1 เสมอ (เนื่องจากเป็นการคำนวณความน่าจะเป็น)
อัตราต่อรองจากการบันทึกของผลลัพธ์ถูกสร้างขึ้นจากการรวมกันเชิงเส้นของตัวแปรทำนายดังนี้:
อัตราต่อรอง = p / (1 – p) = ความน่าจะเป็นของเหตุการณ์ที่เกิดขึ้นหรือความน่าจะเป็นของเหตุการณ์ที่ไม่เกิดขึ้น
ln( อัตราต่อรอง ) = ln( p / (1 – p) )
logit( p ) = ln( p / (1 – p) ) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
โดยที่ p คือความน่าจะเป็นของการมีอยู่ของคุณลักษณะ
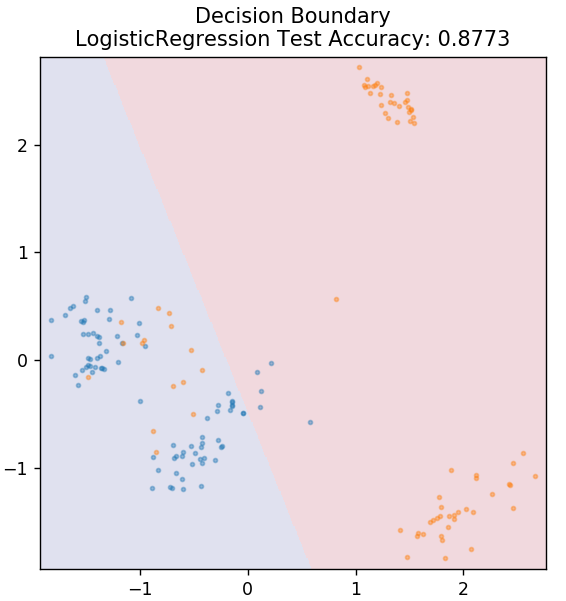
จาก sklearn.linear_model นำเข้า LogisticRegression
รุ่น = LogisticRegression()
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
รับ ใบรับรองปัญญาประดิษฐ์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว

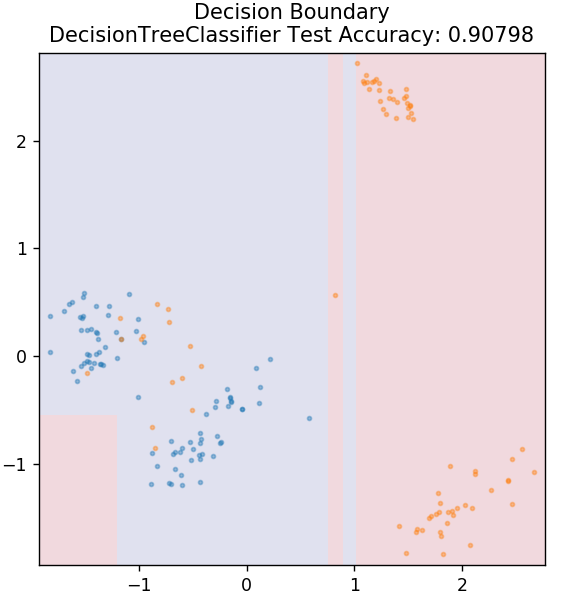
3. ต้นไม้การตัดสินใจ
นี่เป็นอัลกอริธึมยอดนิยมที่สามารถใช้ในการจำแนกตัวแปรข้อมูลทั้งแบบต่อเนื่องและแบบไม่ต่อเนื่อง ในทุกขั้นตอน ข้อมูลจะถูกแบ่งออกเป็นชุดที่เป็นเนื้อเดียวกันมากกว่าหนึ่งชุดตามแอตทริบิวต์/เงื่อนไขการแยกบางส่วน
จาก sklearn.tree นำเข้า DecisionTreeClassifier
รุ่น = DecisionTreeClassifier ( max_depth = 3 )
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
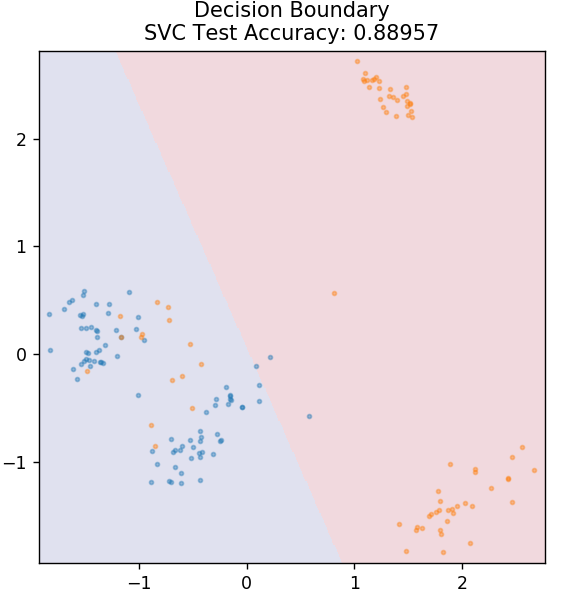
4. SVM
SVM ย่อมาจาก Support Vector Machines แนวคิดพื้นฐานในที่นี้คือการจำแนกจุดข้อมูลโดยใช้ไฮเปอร์เพลนสำหรับการแยก เป้าหมายคือการค้นหาไฮเปอร์เพลนที่มีระยะห่างสูงสุด (หรือระยะขอบ) ระหว่างจุดข้อมูลของทั้งสองคลาสหรือหมวดหมู่
เราเลือกเครื่องบินในลักษณะที่ดูแลการจำแนกจุดที่ไม่รู้จักในอนาคตด้วยความมั่นใจสูงสุด SVM เป็นที่นิยมใช้เนื่องจากให้ความแม่นยำสูงในขณะที่ใช้พลังงานในการคำนวณน้อยมาก นอกจากนี้ยังสามารถใช้ SVM สำหรับปัญหาการถดถอย
จาก sklearn.svm นำเข้า SVC
รุ่น = SVC (เคอร์เนล = 'เชิงเส้น')
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
ชำระเงิน: โครงการ Python บน GitHub
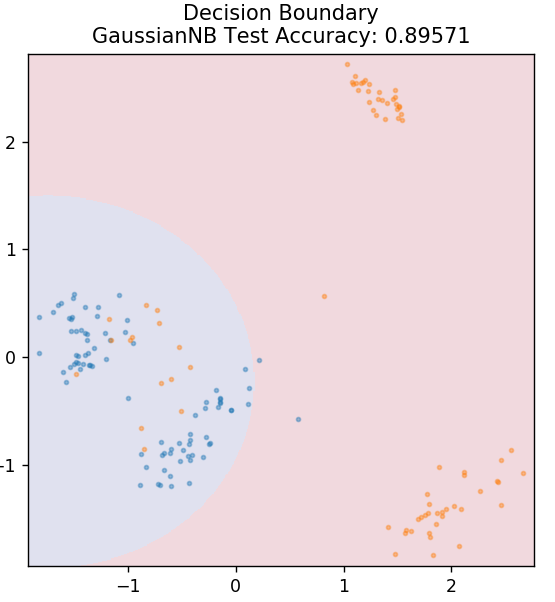
5. อ่าวไร้เดียงสา
ตามชื่อที่แนะนำ อัลกอริทึม Naive Bayes เป็นอัลกอริธึมการเรียนรู้ภายใต้การดูแลตาม ทฤษฎีบท Bayes ทฤษฎีบทเบย์ใช้ความน่าจะเป็นแบบมีเงื่อนไขเพื่อให้ความน่าจะเป็นของเหตุการณ์ตามความรู้ที่ให้มา
ที่ไหน, 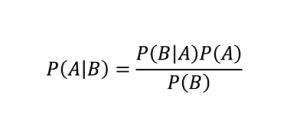
P (A | B): ความน่าจะเป็นแบบมีเงื่อนไขที่เหตุการณ์ A เกิดขึ้น โดยที่เหตุการณ์ B ได้เกิดขึ้นแล้ว (เรียกอีกอย่างว่าความน่าจะเป็นหลัง)
P(A): ความน่าจะเป็นของเหตุการณ์ A
P(B): ความน่าจะเป็นของเหตุการณ์ B
P (B | A): ความน่าจะเป็นแบบมีเงื่อนไขที่เหตุการณ์ B เกิดขึ้น โดยที่เหตุการณ์ A ได้เกิดขึ้นแล้ว
ทำไมอัลกอริธึมนี้จึงมีชื่อว่า Naive? นี่เป็นเพราะถือว่าเหตุการณ์ทั้งหมดเกิดขึ้นไม่ขึ้นต่อกัน ดังนั้นแต่ละคุณลักษณะจะกำหนดคลาสของจุดข้อมูลแยกกัน โดยไม่ต้องมีการพึ่งพากันเอง Naive Bayes เป็นตัวเลือกที่ดีที่สุดสำหรับการจัดหมวดหมู่ข้อความ มันจะทำงานได้ดีเพียงพอกับข้อมูลการฝึกอบรมจำนวนเล็กน้อย
จาก sklearn.naive_bayes นำเข้า GaussianNB
รุ่น = GaussianNB()
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
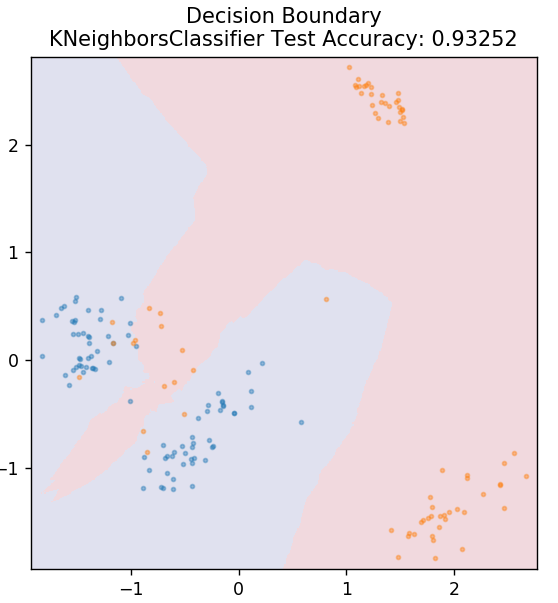
5. KNN
KNN ย่อมาจาก K-Nearest Neighbours เป็นอัลกอริธึมการเรียนรู้ภายใต้การดูแลที่ใช้กันอย่างแพร่หลายซึ่งจัดประเภทข้อมูลการทดสอบตามความคล้ายคลึงกันกับข้อมูลการฝึกอบรมที่จัดไว้ก่อนหน้านี้ KNN ไม่ได้จัดประเภทจุดข้อมูลทั้งหมดระหว่างการฝึก แต่จะเก็บเฉพาะชุดข้อมูลและเมื่อได้รับข้อมูลใหม่ ก็จะจัดประเภทจุดข้อมูลเหล่านั้นตามความคล้ายคลึงกัน ทำได้โดยการคำนวณระยะทางแบบยุคลิดของจำนวน K ของเพื่อนบ้านที่ใกล้ที่สุด (ในที่นี้ n_neighbors ) ของจุดข้อมูลนั้น
จาก sklearn.neighbors นำเข้า KNeighborsClassifier
รุ่น = KNeighborsClassifier ( n_neighbors = 20 )
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
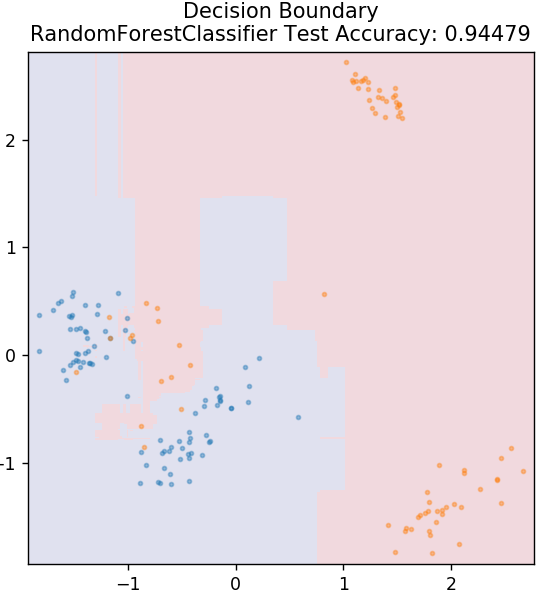
6. ป่าสุ่ม
Random Forest เป็นอัลกอริธึมการเรียนรู้ของเครื่องที่เรียบง่ายและหลากหลายซึ่งใช้เทคนิคการเรียนรู้ภายใต้การดูแล อย่างที่คุณเดาได้จากชื่อ ป่าสุ่มประกอบด้วยต้นไม้ตัดสินใจจำนวนมาก ซึ่งทำหน้าที่เป็นวงดนตรี โครงสร้างการตัดสินใจแต่ละอันจะคำนวณเอาท์พุตคลาสของจุดข้อมูล และคลาสส่วนใหญ่จะถูกเลือกเป็นเอาต์พุตสุดท้ายของโมเดล แนวคิดในที่นี้คือ ต้นไม้จำนวนมากที่ทำงานบนข้อมูลเดียวกันมักจะให้ผลลัพธ์ที่แม่นยำกว่าต้นไม้แต่ละต้น
จาก sklearn.ensemble นำเข้า RandomForestClassifier
รุ่น = RandomForestClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
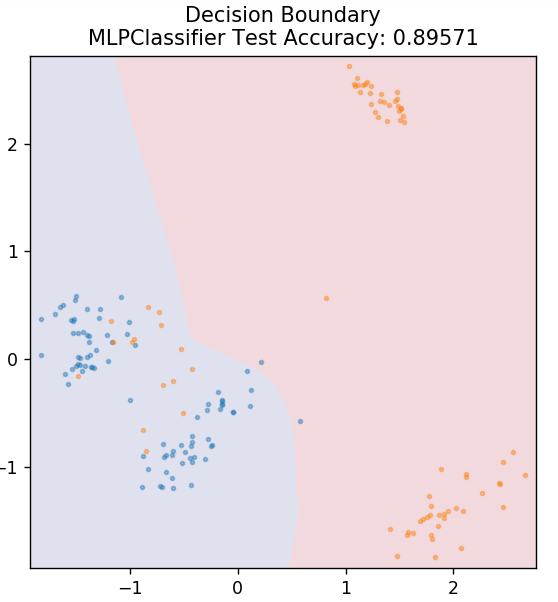
7. Perceptron หลายชั้น
Multi-Layer Perceptron (หรือ MLP) เป็นอัลกอริธึมที่น่าสนใจมากซึ่งอยู่ภายใต้สาขาของการเรียนรู้เชิงลึก โดยเฉพาะอย่างยิ่ง มันอยู่ในคลาสของโครงข่ายประสาทเทียมแบบ feed-forward (ANN) MLP สร้างเครือข่ายของเพอร์เซปตรอนหลายตัวที่มีอย่างน้อยสามเลเยอร์: เลเยอร์อินพุต เลเยอร์เอาต์พุต และเลเยอร์ที่ซ่อนอยู่ MLP สามารถแยกแยะระหว่างข้อมูลที่แยกไม่ออกเชิงเส้นได้
เซลล์ประสาทแต่ละเซลล์ในเลเยอร์ที่ซ่อนอยู่จะใช้ฟังก์ชันการเปิดใช้งานเพื่อไปยังชั้นถัดไป ในที่นี้ อัลกอริธึม backpropagation ใช้เพื่อปรับแต่งพารามิเตอร์จริง ๆ และด้วยเหตุนี้จึงฝึกโครงข่ายประสาทเทียม ส่วนใหญ่จะใช้สำหรับปัญหาการถดถอยอย่างง่าย
จาก sklearn.neural_network นำเข้า MLPClassifier
รุ่น = MLPClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary ( X_test, y_test รุ่น )
อ่านเพิ่มเติม: แนวคิดและหัวข้อโครงการ Python
บทสรุป
เราสามารถสรุปได้ว่าอัลกอริธึมการเรียนรู้ของเครื่องที่แตกต่างกันให้ขอบเขตการตัดสินใจที่แตกต่างกัน และด้วยเหตุนี้จึงส่งผลให้มีความแม่นยำต่างกันในการจำแนกชุดข้อมูลเดียวกัน
ไม่มีวิธีใดที่จะประกาศว่าอัลกอริทึมของใครก็ตามเป็นอัลกอริทึมที่ดีที่สุดสำหรับข้อมูลทุกประเภทโดยทั่วไป แมชชีนเลิร์นนิงต้องการการทดลองใช้และข้อผิดพลาดอย่างเข้มงวดสำหรับอัลกอริทึมต่างๆ เพื่อพิจารณาว่าสิ่งใดดีที่สุดสำหรับชุดข้อมูลแต่ละชุดแยกกัน รายการอัลกอริทึม ML ไม่ได้สิ้นสุดที่นี่อย่างชัดเจน มีเทคนิคอื่นๆ อีกมากมายที่รอให้คุณสำรวจในไลบรารี Scikit-Learn ของ Python ไปข้างหน้าและฝึกชุดข้อมูลของคุณโดยใช้สิ่งเหล่านี้และสนุกไปกับมัน!
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแผนผังการตัดสินใจ แมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program ใน Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษามากกว่า 30+ การมอบหมายงาน, สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ข้อสันนิษฐานที่สำคัญของการถดถอยเชิงเส้นคืออะไร?
มีข้อสันนิษฐานที่สำคัญ 4 ข้อสำหรับการถดถอยเชิงเส้น: ลิเนียริตี, โฮโมสเคดาสติกซิตี, เอกราช และภาวะปกติ ลิเนียริตี้หมายความว่าความสัมพันธ์ระหว่างตัวแปรอิสระ (X) กับค่าเฉลี่ยของตัวแปรตาม (Y) จะถือเป็นเชิงเส้นเมื่อเราใช้การถดถอยเชิงเส้น Homoscedasticity หมายความว่าความแปรปรวนในข้อผิดพลาดของจุดที่เหลือของกราฟจะถือว่าคงที่ ความเป็นอิสระหมายถึงการสังเกตทั้งหมดจากข้อมูลที่ป้อนเข้าเพื่อพิจารณาว่าเป็นอิสระจากกัน ความปกติหมายความว่าการกระจายข้อมูลอินพุตสามารถเป็นแบบเดียวกันหรือไม่สม่ำเสมอ แต่สันนิษฐานว่าจะมีการกระจายอย่างสม่ำเสมอในกรณีของการถดถอยเชิงเส้น
ต้นไม้แห่งการตัดสินใจและป่าสุ่มแตกต่างกันอย่างไร
โครงสร้างการตัดสินใจใช้กระบวนการตัดสินใจ โดยใช้โครงสร้างแบบต้นไม้ที่แสดงถึงผลลัพธ์ที่เป็นไปได้สำหรับการดำเนินการเฉพาะ ฟอเรสต์สุ่มใช้กลุ่มของทรีการตัดสินใจดังกล่าวเพื่อวิเคราะห์ข้อมูล โดยกระบวนการนี้ ฟอเรสต์สุ่มจะใช้ข้อมูลมากขึ้น แต่จะช่วยป้องกันไม่ให้เกินพอดีและให้ผลลัพธ์ที่แม่นยำ มีขอบเขตของการปรับมากเกินไปในอัลกอริธึมแผนผังการตัดสินใจและสามารถให้ผลลัพธ์ที่แม่นยำน้อยกว่าได้ โครงสร้างการตัดสินใจนั้นง่ายต่อการตีความเนื่องจากต้องใช้การคำนวณน้อยกว่า ในขณะที่ฟอเรสต์สุ่มนั้นตีความได้ยากเนื่องจากการวิเคราะห์ที่ซับซ้อน
ไลบรารีมาตรฐานใดบ้างที่ใช้สำหรับอัลกอริธึมการเรียนรู้ของเครื่องใน Python
Python ได้เข้ามาแทนที่ภาษาอื่นเกือบทั้งหมดในการเรียนรู้ของเครื่องเนื่องจากมีไลบรารีจำนวนมากและกฎไวยากรณ์ที่ง่าย มีไลบรารี Python มากมายสำหรับการเรียนรู้ของเครื่อง เช่น Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas เป็นต้น การใช้ฟังก์ชันจากไลบรารีเหล่านี้ช่วยประหยัดเวลาในการเขียนอัลกอริธึมสำหรับแต่ละงานได้มาก กระบวนการนี้ใช้เวลาน้อยลงและให้ผลลัพธ์ที่มีประสิทธิภาพ ไลบรารีเหล่านี้มีแอปพลิเคชันต่างๆ เช่น การประมวลผลเมทริกซ์ ปัญหาการปรับให้เหมาะสม การทำเหมืองข้อมูล การวิเคราะห์ทางสถิติ การคำนวณที่เกี่ยวข้องกับเทนเซอร์ การตรวจจับวัตถุ โครงข่ายประสาทเทียม และอื่นๆ อีกมากมาย