
15 คำถามและคำตอบสำหรับการสัมภาษณ์แมชชีนเลิร์นนิงสำหรับปี 2022
เผยแพร่แล้ว: 2021-01-08คุณเป็นคนที่ปรารถนาที่จะประสบความสำเร็จในอาชีพการเรียนรู้ของเครื่องหรือไม่? ถ้าใช่ก็ดีสำหรับคุณ!
แต่ก่อนอื่น คุณต้องเตรียมตัวสำหรับ ice-breaker – การสัมภาษณ์ ML
เนื่องจากขั้นตอนการเตรียมตัวสำหรับการสัมภาษณ์อาจยากเกินไป เราจึงตัดสินใจเข้าร่วม – นี่คือรายการคำถามที่พบบ่อย 15 ข้อที่รวบรวมไว้ซึ่งได้รับการคัดสรรมาอย่างดีในการสัมภาษณ์แมชชีนเลิร์นนิง!
- อะไรคือความแตกต่างระหว่างการเรียนรู้เชิงลึกและการเรียนรู้ของเครื่อง?
ในขณะที่แมชชีนเลิร์นนิงเกี่ยวข้องกับแอปพลิเคชันและการใช้อัลกอริธึมขั้นสูงเพื่อแยกวิเคราะห์ข้อมูล เปิดเผยรูปแบบที่ซ่อนอยู่ภายในข้อมูลและเรียนรู้จากข้อมูลนั้น และสุดท้ายนำข้อมูลเชิงลึกที่เรียนรู้มาใช้เพื่อประกอบการตัดสินใจทางธุรกิจอย่างมีข้อมูล สำหรับ Deep Learning เป็นชุดย่อยของ Machine Learning ที่เกี่ยวข้องกับการใช้ Artificial Neural Nets ซึ่งดึงแรงบันดาลใจจากโครงสร้าง Neural Net ของสมองมนุษย์ Deep Learning ใช้กันอย่างแพร่หลายในการตรวจจับคุณสมบัติ
- กำหนด – ความแม่นยำและการเรียกคืน
การวัดค่าที่แม่นยำหรือค่าการทำนายผลบวกหรือคาดการณ์จำนวนผลบวกที่แท้จริงในการอ้างสิทธิ์โดยแบบจำลองได้อย่างแม่นยำมากขึ้นเมื่อเทียบกับจำนวนผลบวกที่อ้างสิทธิ์จริง
Recall หรือ True Positive Rate หมายถึงจำนวนผลบวกที่โมเดลอ้างสิทธิ์ เทียบกับจำนวนผลบวกที่เกิดขึ้นจริงในข้อมูล

เข้าร่วม หลักสูตรแมชชีนเลิ ร์นนิง ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
- อธิบายคำว่า 'อคติ' และ 'ความแปรปรวน' '
ในระหว่างกระบวนการฝึกอบรม ข้อผิดพลาดที่คาดหวังของอัลกอริธึมการเรียนรู้โดยทั่วไปจะถูกจำแนกหรือแบ่งออกเป็นสองส่วน - ความลำเอียงและความแปรปรวน แม้ว่า 'อคติ' เป็นสถานการณ์ข้อผิดพลาดที่เกิดจากการใช้สมมติฐานง่ายๆ ในอัลกอริทึมการเรียนรู้ แต่ 'ความแปรปรวน' หมายถึงข้อผิดพลาดที่เกิดจากความซับซ้อนของอัลกอริทึมการเรียนรู้นั้นในการวิเคราะห์ข้อมูล อคติวัดความใกล้เคียงของตัวแยกประเภทเฉลี่ยที่สร้างโดยอัลกอริธึมการเรียนรู้กับฟังก์ชันเป้าหมาย และความแปรปรวนจะวัดโดยการคาดการณ์ของอัลกอริทึมการเรียนรู้จะแตกต่างกันมากน้อยเพียงใดสำหรับชุดข้อมูลการฝึกที่แตกต่างกัน
- ROC Curve ทำงานอย่างไร?
ROC หรือกราฟลักษณะการทำงานของผู้รับคือการแสดงกราฟิกของการเปลี่ยนแปลงระหว่างอัตราผลบวกที่แท้จริงและอัตราผลบวกเท็จที่เกณฑ์ที่แตกต่างกัน เป็นเครื่องมือพื้นฐานสำหรับการประเมินการทดสอบวินิจฉัย และมักใช้แทนการแลกเปลี่ยนระหว่างความไวของแบบจำลอง (ผลบวกที่แท้จริง) กับความน่าจะเป็นที่จะกระตุ้นสัญญาณเตือนที่ผิดพลาด (ผลบวกที่ผิดพลาด)
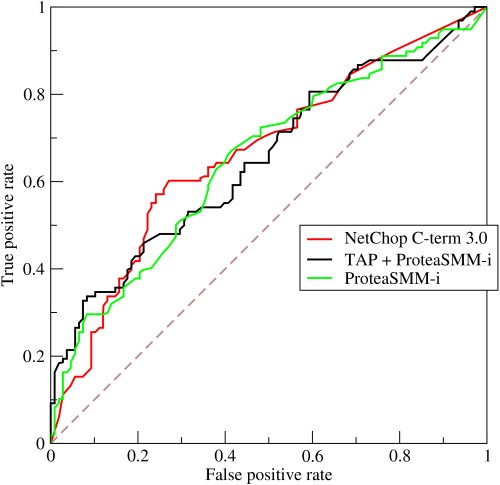
แหล่งที่มา
- เส้นโค้งแสดงให้เห็นการประนีประนอมระหว่างความไวและความจำเพาะ – หากความไวเพิ่มขึ้น ความจำเพาะจะลดลง
- หากเส้นโค้งล้อมรอบไปทางแกนซ้ายมือและด้านบนของสเปซ ROC มากกว่า การทดสอบมักจะแม่นยำกว่า อย่างไรก็ตาม หากเส้นโค้งเข้าใกล้เส้นทแยงมุม 45 องศาของพื้นที่ ROC มากขึ้น การทดสอบจะแม่นยำหรือเชื่อถือได้น้อยกว่า
- ความชันของเส้นสัมผัสที่จุดตัดแสดงถึงอัตราส่วนความน่าจะเป็น (LR) สำหรับค่าเฉพาะของการทดสอบ
- พื้นที่ใต้เส้นโค้งวัดความแม่นยำในการทดสอบ
- อธิบายความแตกต่างระหว่างข้อผิดพลาดประเภท 1 และประเภท 2
ข้อผิดพลาดประเภทที่ 1 เป็นข้อผิดพลาดเชิงบวกเท็จที่ 'อ้างว่า' เหตุการณ์เกิดขึ้นเมื่อที่จริงแล้วไม่มีอะไรเกิดขึ้น ตัวอย่างที่ดีที่สุดของข้อผิดพลาดเชิงบวกที่ผิดพลาดคือสัญญาณเตือนไฟไหม้ที่ผิดพลาด – สัญญาณเตือนจะเริ่มดังขึ้นเมื่อไม่มีไฟไหม้ ตรงกันข้าม ข้อผิดพลาดประเภทที่ 2 เป็นข้อผิดพลาดเชิงลบที่เป็นเท็จซึ่ง 'อ้างว่า' ไม่มีอะไรเกิดขึ้นเมื่อมีบางอย่างเกิดขึ้นอย่างแน่นอน มันจะเป็นข้อผิดพลาดประเภท 2 ที่จะบอกหญิงตั้งครรภ์ว่าเธอไม่ได้อุ้มเด็ก
- เหตุใด Bayes จึงเรียกว่า "Naive Bayes"
Naive Bayes ถูกเรียกว่า "ไร้เดียงสา" เพราะถึงแม้จะมีการใช้งานจริงมากมาย แต่ก็ขึ้นอยู่กับสมมติฐานที่หาไม่ได้ในข้อมูลในชีวิตจริง คุณลักษณะทั้งหมดในชุดข้อมูลมีความสำคัญ เป็นอิสระ และเท่าเทียมกัน ในแนวทาง Naive Bayes ความน่าจะเป็นแบบมีเงื่อนไขจะคำนวณเป็นผลคูณของความน่าจะเป็นของส่วนประกอบแต่ละส่วน ดังนั้นจึงแสดงถึงความเป็นอิสระอย่างสมบูรณ์ของคุณลักษณะ น่าเสียดายที่สมมติฐานนี้ไม่สามารถบรรลุได้ในสถานการณ์จริง
- คำว่า 'โอเวอร์ฟิตติ้ง' หมายถึงอะไร? คุณสามารถหลีกเลี่ยงได้หรือไม่ ถ้าเป็นเช่นนั้นอย่างไร?
โดยปกติ ในระหว่างกระบวนการฝึกอบรม แบบจำลองจะได้รับข้อมูลจำนวนมาก ในระหว่างกระบวนการ ข้อมูลจะเริ่มเรียนรู้แม้จากข้อมูลที่ไม่ถูกต้องและสัญญาณรบกวนที่มีอยู่ในชุดข้อมูลตัวอย่าง สิ่งนี้สร้างอิทธิพลเชิงลบต่อประสิทธิภาพของแบบจำลองบนข้อมูลใหม่ กล่าวคือ โมเดลไม่สามารถจำแนกอินสแตนซ์/ข้อมูลใหม่ได้อย่างถูกต้องแม่นยำ นอกเหนือจากของชุดการฝึก สิ่งนี้เรียกว่า Overfitting
ใช่ เป็นไปได้ที่จะหลีกเลี่ยงการสวมใส่มากเกินไป โดยใช้วิธีดังนี้:
- รวบรวมข้อมูลมากขึ้น (จากแหล่งที่มาที่แตกต่างกัน) เพื่อฝึกโมเดลด้วยตัวอย่างต่างๆ
- ใช้วิธีการรวมกลุ่ม (เช่น Random Forest) ที่ใช้วิธีการบรรจุถุงเพื่อลดความผันแปรในการทำนายโดยการวางผลลัพธ์ของแผนผังการตัดสินใจหลายชุดในหน่วยต่างๆ ของชุดข้อมูล
- ตรวจสอบให้แน่ใจว่าใช้เทคนิคการตรวจสอบข้าม
- ตั้งชื่อสองวิธีที่ใช้สำหรับการสอบเทียบในการเรียนรู้ภายใต้การดูแล
วิธีการสอบเทียบสองวิธีในการเรียนรู้ภายใต้การดูแลคือ – Platt Calibration และ Isotonic Regression ทั้งสองวิธีนี้ได้รับการออกแบบมาโดยเฉพาะสำหรับการจำแนกประเภทไบนารี

- ทำไมคุณถึงตัดแต่งต้นไม้การตัดสินใจ?
ต้องตัดแต่งต้นไม้เพื่อการตัดสินใจเพื่อกำจัดกิ่งที่มีความสามารถในการคาดการณ์ที่อ่อนแอ ซึ่งช่วยลดผลหารความซับซ้อนของแบบจำลอง Decision Tree และปรับความแม่นยำในการทำนายให้เหมาะสม การตัดแต่งกิ่งสามารถทำได้ทั้งจากบนลงล่างหรือล่างขึ้นบน การตัดแต่งกิ่งที่ผิดพลาดที่ลดลง การตัดแต่งกิ่งที่มีต้นทุนซับซ้อน การตัดแต่งกิ่งที่มีความซับซ้อนของข้อผิดพลาด และการตัดแต่งกิ่งที่ผิดพลาดน้อยที่สุดคือวิธีการตัดแต่งกิ่งต้นไม้การตัดสินใจที่ใช้กันมากที่สุด
- คะแนน F1 หมายถึงอะไร
กล่าวอย่างง่าย ๆ คะแนน F1 เป็นตัววัดประสิทธิภาพของแบบจำลอง – ค่าเฉลี่ยของความแม่นยำและการเรียกคืนของแบบจำลอง โดยผลลัพธ์ที่ใกล้เคียงกับ 1 นั้นดีที่สุด และคะแนนที่ใกล้ถึง 0 นั้นแย่ที่สุด คะแนน F1 สามารถใช้ในการทดสอบการจำแนกประเภทที่ไม่ให้ความสำคัญกับผลเชิงลบที่แท้จริง
- แยกความแตกต่างระหว่างอัลกอริธึม Generative และ Discriminative
แม้ว่าอัลกอริธึมทั่วไปจะเรียนรู้เกี่ยวกับหมวดหมู่ของข้อมูล ส่วนอัลกอริธึม Discriminative จะเรียนรู้ความแตกต่างระหว่างหมวดหมู่ของข้อมูลต่างๆ เมื่อพูดถึงงานการจัดประเภท แบบจำลองการเลือกปฏิบัติมักจะแซงหน้าแบบจำลองกำเนิด
- Ensemble Learning คืออะไร?
Ensemble Learning ใช้อัลกอริธึมการเรียนรู้ร่วมกันเพื่อเพิ่มประสิทธิภาพการทำนายของแบบจำลอง ในวิธีนี้ โมเดลต่างๆ เช่น ตัวแยกประเภทหรือผู้เชี่ยวชาญ ถูกสร้างและรวมเข้าด้วยกันอย่างมีกลยุทธ์ เพื่อป้องกัน Overfitting ในแบบจำลอง ส่วนใหญ่จะใช้เพื่อปรับปรุงการทำนาย การจัดประเภท การประมาณฟังก์ชัน ประสิทธิภาพ ฯลฯ ของแบบจำลอง
- กำหนด 'เคล็ดลับเคอร์เนล'
วิธี Kernel Trick เกี่ยวข้องกับการใช้ฟังก์ชันเคอร์เนลที่สามารถทำงานได้ในพื้นที่คุณลักษณะที่มีมิติสูงและโดยนัย โดยไม่ต้องคำนวณพิกัดของจุดภายในมิตินั้นอย่างชัดเจน ฟังก์ชันเคอร์เนลคำนวณผลิตภัณฑ์ภายในระหว่างรูปภาพของข้อมูลทุกคู่ที่อยู่ในพื้นที่คุณลักษณะ ขั้นตอนนี้มีราคาถูกกว่าการคำนวณเมื่อเทียบกับการคำนวณพิกัดอย่างชัดเจนและเรียกว่า Kernel Trick
- คุณควรจัดการกับข้อมูลที่สูญหายหรือเสียหายในชุดข้อมูลอย่างไร
ในการค้นหาข้อมูลที่ขาดหายไป/เสียหายในชุดข้อมูล คุณต้องวางแถวและคอลัมน์หรือแทนที่ด้วยค่าอื่น ห้องสมุด Pandas มีวิธีที่ยอดเยี่ยมสองวิธีในการค้นหาข้อมูลที่ขาดหายไป/เสียหาย – isnull() และ dropna() ฟังก์ชันทั้งสองนี้ได้รับการออกแบบมาโดยเฉพาะเพื่อช่วยให้คุณค้นหาแถว/คอลัมน์ของข้อมูลที่มีข้อมูลที่ขาดหายไป/เสียหายและปล่อยค่าเหล่านั้น
- ตารางแฮชคืออะไร?
ตารางแฮชเป็นโครงสร้างข้อมูลที่สร้างอาร์เรย์ที่เชื่อมโยง โดยที่คีย์จะถูกจับคู่กับค่าเฉพาะโดยใช้ฟังก์ชันแฮช ตารางแฮชส่วนใหญ่จะใช้ในการสร้างดัชนีฐานข้อมูล
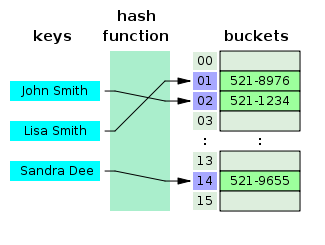
แหล่งที่มา
รายการคำถามนี้มีขึ้นเพื่อแนะนำคุณเกี่ยวกับพื้นฐานของการเรียนรู้ด้วยเครื่อง และตามจริงแล้ว คำถามทั้ง 20 ข้อนี้เป็นเพียงหยดเล็กๆ ในทะเล การเรียนรู้ด้วยเครื่องกำลังก้าวหน้าในขณะที่เราพูด ดังนั้นเมื่อเวลาผ่านไป แนวคิดใหม่ก็จะปรากฏขึ้น กุญแจสำคัญในการสัมภาษณ์ ML ของคุณนั้นอยู่ที่การกระตุ้นให้เรียนรู้และเพิ่มทักษะอย่างต่อเนื่อง ดังนั้น เริ่มต้นและเผยแพร่อินเทอร์เน็ต อ่านวารสาร เข้าร่วมชุมชนออนไลน์ เข้าร่วมการประชุมและสัมมนาของ ML - มีหลายวิธีในการเรียนรู้
ในการเข้าสู่องค์กรขนาดใหญ่ จำเป็นต้องมีใบรับรองจากสถาบันที่มีชื่อเสียง ตรวจสอบ โปรแกรม Executive PG ของ IIIT-B ในการเรียนรู้ของเครื่องและ AI และรับความช่วยเหลือด้านงานจากบริษัท ML & AI ชั้นนำ
Ensemble Learning มีข้อจำกัดอะไรบ้าง?
แนวทางทั้งมวลสามารถช่วยในการลดความแปรปรวนและการพัฒนาแบบจำลองที่แข็งแกร่งยิ่งขึ้น อย่างไรก็ตาม มีข้อเสียบางประการในการใช้เทคนิคของวงดนตรี เช่น ขาดความสามารถในการอธิบายและประสิทธิภาพ นอกจากนี้ พึงระลึกไว้เสมอว่าประสิทธิภาพของตระการตามาจากความสามารถในการรวมแบบจำลองหลายๆ แบบที่เน้นด้านต่างๆ ของปัญหา อย่างไรก็ตาม มีระยะเวลาการคาดการณ์ที่ยาวนานกว่า เนื่องจากคุณอาจต้องการการคาดการณ์จากแบบจำลองหลายร้อยแบบ แม้ว่าจะมีการคาดการณ์ที่ดีขึ้น แต่ความแม่นยำที่เพิ่มขึ้นอาจไม่คุ้มค่า
ต้องใช้เวลาเท่าใดในการเรียนรู้แมชชีนเลิร์นนิง
เมื่อพูดถึงแมชชีนเลิร์นนิง เทคโนโลยีที่ซับซ้อนที่ใช้สำหรับสิ่งเดียวกันอาจทำให้ผู้คนหวาดกลัวได้ง่าย อย่างไรก็ตาม การทำความเข้าใจทีละน้อยไม่ใช่เรื่องยาก ประสบการณ์ก่อนหน้าในด้านสถิติ คณิตศาสตร์ขั้นสูง และอื่นๆ จะช่วยให้คุณเข้าใจแนวคิดทั้งหมดได้อย่างรวดเร็ว อย่างไรก็ตาม เนื่องจากภูมิหลังทางการศึกษาและทักษะแตกต่างกันไปในแต่ละบุคคล บุคคลหนึ่งอาจเรียนรู้ ML ได้ภายในสามสัปดาห์ในขณะที่อีกคนหนึ่งอาจต้องใช้เวลาหนึ่งปี
Machine Learning ถูกนำมาใช้ในชีวิตประจำวันอย่างไร?
Gmail จัดหมวดหมู่อีเมลตามความจำเป็นโดยจัดเรียงเป็นอีเมลหลัก โปรโมชัน โซเชียล และอัปเดตโดยใช้แมชชีนเลิร์นนิง บริษัทต่างๆ กำลังใช้โครงข่ายประสาทเทียมในการตรวจจับธุรกรรมที่เป็นการฉ้อโกงโดยอิงจากข้อมูล เช่น ความถี่ล่าสุดของการทำธุรกรรม จำนวนธุรกรรม และประเภทผู้ค้า เครื่องตรวจจับการลอกเลียนแบบยังใช้ประโยชน์จากการเรียนรู้ของเครื่องอีกด้วย เมื่อพูดถึงวิศวกรรม ML จะใช้เวลาประมาณหกเดือนจึงจะเสร็จ