
KNN Classifier สำหรับการเรียนรู้ของเครื่อง: ทุกสิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2021-09-28จำช่วงเวลาที่ปัญญาประดิษฐ์ (AI) เป็นเพียงแนวคิดที่จำกัดเฉพาะนิยายและภาพยนตร์ไซไฟเท่านั้นหรือไม่? ต้องขอบคุณความก้าวหน้าทางเทคโนโลยีที่ทำให้ AI เป็นสิ่งที่เราอาศัยอยู่ทุกวัน ตั้งแต่ Alexa และ Siri อยู่ที่นั่นและเรียกร้องให้แพลตฟอร์ม OTT "คัดสรร" ภาพยนตร์ที่เราอยากดูเป็นพิเศษ AI เกือบจะกลายเป็นคำสั่งของวันนี้และพร้อมที่จะพูดสำหรับอนาคตอันใกล้นี้
ทั้งหมดนี้เป็นไปได้ด้วยอัลกอริธึม ML ขั้นสูง วันนี้ เราจะมาพูดถึงอัลกอริธึม ML ที่มีประโยชน์อย่างหนึ่ง K-NN Classifier
แมชชีนเลิร์นนิงเป็นสาขาหนึ่งของ AI และวิทยาการคอมพิวเตอร์ ใช้ข้อมูลและอัลกอริทึมเพื่อเลียนแบบความเข้าใจของมนุษย์ ในขณะเดียวกันก็ค่อยๆ ปรับปรุงความแม่นยำของอัลกอริทึม แมชชีนเลิร์นนิงเกี่ยวข้องกับอัลกอริธึมการฝึกอบรมเพื่อคาดการณ์หรือจำแนกประเภท และค้นหาข้อมูลเชิงลึกที่สำคัญที่ขับเคลื่อนการตัดสินใจเชิงกลยุทธ์ภายในธุรกิจและแอปพลิเคชัน
อัลกอริธึม KNN (k-neighbour nighbour) เป็นอัลกอริธึมการเรียนรู้ด้วยเครื่องพื้นฐานภายใต้การดูแลที่ใช้เพื่อแก้ปัญหาการถดถอยและการจำแนกปัญหา มาดูข้อมูลเพิ่มเติมเกี่ยวกับ K-NN Classifier กันดีกว่า
สารบัญ
แมชชีนเลิร์นนิงภายใต้การดูแล vs แมชชีนเลิร์นนิง
การเรียนรู้แบบมีผู้ดูแลและการเรียนรู้แบบไม่มีผู้ดูแลเป็นแนวทางพื้นฐานทางวิทยาศาสตร์ข้อมูลสองแนวทาง และจำเป็นต้องทราบความแตกต่างก่อนที่เราจะพูดถึงรายละเอียดของ KNN
การเรียนรู้ภายใต้ การดูแล เป็นวิธีการเรียนรู้ของเครื่องที่ใช้ชุดข้อมูลที่มีป้ายกำกับเพื่อช่วยคาดการณ์ผลลัพธ์ ชุดข้อมูลดังกล่าวได้รับการออกแบบมาเพื่อ "ควบคุม" หรือฝึกอัลกอริทึมให้คาดการณ์ผลลัพธ์หรือจัดประเภทข้อมูลได้อย่างแม่นยำ ดังนั้น อินพุตและเอาต์พุตที่มีป้ายกำกับทำให้โมเดลสามารถเรียนรู้เมื่อเวลาผ่านไปในขณะที่ปรับปรุงความแม่นยำ

การเรียนรู้ภายใต้การดูแลเกี่ยวข้องกับปัญหาสองประเภท – การจำแนกและการถดถอย ใน ปัญหา การจำแนกประเภท อัลกอริธึมจะจัดสรรข้อมูลการทดสอบออกเป็นหมวดหมู่ที่ไม่ต่อเนื่อง เช่น การแยกแมวออกจากสุนัข
ตัวอย่างในชีวิตจริงที่สำคัญคือการจัดประเภทอีเมลขยะลงในโฟลเดอร์ที่แยกจากกล่องจดหมายของคุณ ในทางกลับกัน วิธี การถดถอย ของการเรียนรู้ภายใต้การดูแลจะฝึกอัลกอริทึมเพื่อทำความเข้าใจความสัมพันธ์ระหว่างตัวแปรอิสระและตัวแปรตาม ใช้จุดข้อมูลที่แตกต่างกันเพื่อคาดการณ์ค่าตัวเลข เช่น การคาดการณ์รายได้จากการขายสำหรับธุรกิจ
ในทางตรงกันข้าม Unsupervised Learning ใช้อัลกอริธึมการเรียนรู้ของเครื่องสำหรับการวิเคราะห์และจัดกลุ่มชุดข้อมูลที่ไม่มีป้ายกำกับ ดังนั้นจึงไม่จำเป็นต้องมีการแทรกแซงของมนุษย์ ("unsupervised") สำหรับอัลกอริทึมในการระบุรูปแบบที่ซ่อนอยู่ในข้อมูล
โมเดลการเรียนรู้แบบไม่มีผู้ดูแลมีแอปพลิเคชันหลักสามประการ – การเชื่อมโยง การจัดกลุ่ม และการลดมิติ อย่างไรก็ตาม เราจะไม่ลงรายละเอียดเนื่องจากอยู่นอกเหนือขอบเขตของการสนทนา
K-เพื่อนบ้านที่ใกล้ที่สุด (KNN)
K-Nearest Neighbor หรืออัลกอริทึม KNN เป็นอัลกอริธึมการเรียนรู้ของเครื่องตามรูปแบบการเรียนรู้ภายใต้การดูแล อัลกอริทึม K-NN ทำงานโดยสมมติว่ามีสิ่งที่คล้ายกันอยู่ใกล้กัน ดังนั้น อัลกอริทึม K-NN จึงใช้ความคล้ายคลึงกันของคุณลักษณะระหว่างจุดข้อมูลใหม่กับจุดในชุดการฝึก (กรณีที่มี) เพื่อคาดการณ์ค่าของจุดข้อมูลใหม่ โดยพื้นฐานแล้ว อัลกอริธึม K-NN จะกำหนดค่าให้กับจุดข้อมูลล่าสุดโดยพิจารณาจากความใกล้เคียงของจุดในชุดการฝึก อัลกอริธึม K-NN ค้นหาแอปพลิเคชันทั้งในปัญหาการจำแนกและการถดถอย แต่ส่วนใหญ่จะใช้สำหรับปัญหาการจำแนกประเภท
นี่คือตัวอย่างเพื่อทำความเข้าใจ K-NN Classifier

แหล่งที่มา
ในภาพด้านบน ค่าอินพุตเป็นสิ่งมีชีวิตที่มีความคล้ายคลึงกันกับทั้งแมวและสุนัข อย่างไรก็ตาม เราต้องการจำแนกเป็นแมวหรือสุนัข ดังนั้นเราจึงสามารถใช้อัลกอริทึม K-NN สำหรับการจัดหมวดหมู่นี้ได้ โมเดล K-NN จะพบความคล้ายคลึงกันระหว่างชุดข้อมูลใหม่ (อินพุต) กับภาพแมวและสุนัขที่มีอยู่ (ชุดข้อมูลการฝึก) ต่อจากนี้ โมเดลจะวางจุดข้อมูลใหม่ไว้ในหมวดหมู่ cat หรือ dog ตามคุณลักษณะที่คล้ายคลึงกันมากที่สุด
ในทำนองเดียวกัน หมวดหมู่ A (จุดสีเขียว) และหมวดหมู่ B (จุดสีส้ม) มีตัวอย่างกราฟิกด้านบนเช่นเดียวกัน เรายังมีจุดข้อมูลใหม่ (จุดสีน้ำเงิน) ที่จะจัดอยู่ในหมวดหมู่ใดหมวดหมู่หนึ่ง เราสามารถแก้ปัญหาการจัดหมวดหมู่นี้ได้โดยใช้อัลกอริทึม K-NN และระบุหมวดหมู่จุดข้อมูลใหม่
การกำหนดคุณสมบัติของอัลกอริทึม K-NN
คุณสมบัติสองประการต่อไปนี้กำหนดอัลกอริทึม K-NN ได้ดีที่สุด:
- เป็น อัลกอริธึมการเรียนรู้แบบขี้เกียจ เพราะแทนที่จะเรียนรู้จากชุดการฝึกทันที อัลกอริธึม K-NN จะจัดเก็บชุดข้อมูลและฝึกจากชุดข้อมูลในขณะที่จัดประเภท
- K-NN ยังเป็น อัลกอริธึมที่ไม่มีพารามิเตอร์ ด้วย ซึ่งหมายความว่าไม่ได้ตั้งสมมติฐานใดๆ เกี่ยวกับข้อมูลพื้นฐาน
การทำงานของ K-NN Algorithm
ตอนนี้ มาดูขั้นตอนต่อไปนี้เพื่อทำความเข้าใจว่าอัลกอริธึม K-NN ทำงานอย่างไร
ขั้นตอนที่ 1: โหลดข้อมูลการฝึกอบรมและทดสอบ
ขั้นตอนที่ 2: เลือกจุดข้อมูลที่ใกล้ที่สุด นั่นคือ ค่าของ K
ขั้นตอนที่ 3: คำนวณระยะทาง K จำนวนเพื่อนบ้าน (ระยะห่างระหว่างข้อมูลการฝึกแต่ละแถวและข้อมูลการทดสอบ) วิธีแบบยุคลิดมักใช้ในการคำนวณระยะทาง
ขั้นตอนที่ 4: พาเพื่อนบ้านที่ใกล้ที่สุด K ตามระยะทางแบบยุคลิดที่คำนวณ
ขั้นตอนที่ 5: ในบรรดาเพื่อนบ้าน K ที่ใกล้ที่สุด ให้นับจำนวนจุดข้อมูลในแต่ละหมวดหมู่
ขั้นตอนที่ 6: จัดสรรจุดข้อมูลใหม่ไปยังหมวดหมู่นั้นซึ่งมีเพื่อนบ้านมากที่สุด
ขั้นตอนที่ 7: สิ้นสุด โมเดลพร้อมแล้ว
เข้าร่วม หลักสูตรปัญญาประดิษฐ์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท โปรแกรม Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
การเลือกค่า K
K เป็นพารามิเตอร์ที่สำคัญในอัลกอริทึม K-NN ดังนั้น เราต้องจำบางจุดก่อนที่เราจะตัดสินใจเกี่ยวกับค่า K
การใช้ เส้นโค้งข้อผิดพลาด เป็นวิธีการทั่วไปในการกำหนดค่า K รูปภาพด้านล่างแสดงเส้นโค้งข้อผิดพลาดสำหรับค่า K ต่างๆ สำหรับข้อมูลการทดสอบและการฝึก


แหล่งที่มา
ในตัวอย่างกราฟิกด้านบน ข้อผิดพลาดของรถไฟเป็นศูนย์ที่ K=1 ในข้อมูลการฝึก เนื่องจากเพื่อนบ้านที่ใกล้ที่สุดไปยังจุดนั้นคือจุดนั้นเอง อย่างไรก็ตาม ข้อผิดพลาดในการทดสอบสูงแม้ที่ค่า K ต่ำ ซึ่งเรียกว่าความแปรปรวนสูงหรือข้อมูลที่มากเกินไป ข้อผิดพลาดในการทดสอบลดลงเมื่อเราเพิ่มค่า K แต่หลังจากค่า K เราจะเห็นว่าข้อผิดพลาดในการทดสอบเพิ่มขึ้นอีกครั้ง เรียกว่า bias หรือ underfitting ดังนั้น ข้อผิดพลาดของข้อมูลการทดสอบในขั้นต้นจึงสูงเนื่องจากความแปรปรวน ต่อมาจึงลดลงและทำให้เสถียร และด้วยค่า K ที่เพิ่มขึ้นอีก ข้อผิดพลาดในการทดสอบก็จะเพิ่มขึ้นอีกครั้งเนื่องจากมีอคติ
ดังนั้น ค่าของ K ที่ข้อผิดพลาดในการทดสอบคงที่และต่ำจึงเป็นค่าที่เหมาะสมที่สุดของ K เมื่อพิจารณาจากเส้นโค้งข้อผิดพลาดข้างต้น K=8 จะเป็นค่าที่เหมาะสมที่สุด
ตัวอย่างการทำความเข้าใจการทำงานของ K-NN Algorithm
พิจารณาชุดข้อมูลที่ได้วางแผนไว้ดังนี้:

แหล่งที่มา
สมมติว่ามีจุดข้อมูลใหม่ (จุดสีดำ) ที่ (60,60) ซึ่งเราต้องจัดเป็นคลาสสีม่วงหรือสีแดง เราจะใช้ K=3 ซึ่งหมายความว่าจุดข้อมูลใหม่จะค้นหาจุดข้อมูลที่ใกล้ที่สุดสามจุด สองจุดในคลาสสีแดง และอีกหนึ่งจุดในคลาสสีม่วง
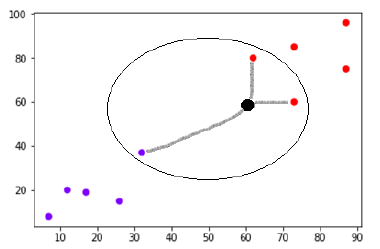
แหล่งที่มา
เพื่อนบ้านที่ใกล้ที่สุดถูกกำหนดโดยการคำนวณระยะทางแบบยุคลิดระหว่างสองจุด นี่คือภาพประกอบเพื่อแสดงวิธีการคำนวณ

แหล่งที่มา
ตอนนี้ เนื่องจากสอง (ในสาม) ของเพื่อนบ้านที่ใกล้ที่สุดของจุดข้อมูลใหม่ (จุดสีดำ) อยู่ในคลาสสีแดง จุดข้อมูลใหม่จะถูกกำหนดให้กับคลาสสีแดงด้วย
เข้าร่วมหลักสูตรแมชชีนเลิร์นนิงออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
K-NN เป็นตัวแยกประเภท (การใช้งานใน Python)
ตอนนี้เรามีคำอธิบายแบบง่ายของอัลกอริทึม K-NN แล้ว ให้เราดำเนินการตามขั้นตอนวิธี K-NN ใน Python กัน เราจะเน้นที่ K-NN Classifier เท่านั้น
ขั้นตอนที่ 1: นำเข้าแพ็คเกจ Python ที่จำเป็น

แหล่งที่มา
ขั้นตอนที่ 2: ดาวน์โหลดชุดข้อมูลไอริสจาก UCI Machine Learning Repository เว็บลิงค์ของมันคือ “https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
ขั้นตอนที่ 3: กำหนดชื่อคอลัมน์ให้กับชุดข้อมูล

แหล่งที่มา
ขั้นตอนที่ 4: อ่านชุดข้อมูลไปยัง Pandas DataFrame

แหล่งที่มา
ขั้นตอนที่ 5: การประมวลผลข้อมูลล่วงหน้าทำได้โดยใช้บรรทัดสคริปต์ต่อไปนี้

แหล่งที่มา
ขั้นตอนที่ 6: แบ่งชุดข้อมูลออกเป็นการทดสอบและแยกการฝึก รหัสด้านล่างจะแบ่งชุดข้อมูลออกเป็นข้อมูลการทดสอบ 40% และข้อมูลการฝึกอบรม 60%

แหล่งที่มา
ขั้นตอนที่ 7: การปรับขนาดข้อมูลทำได้ดังนี้:

แหล่งที่มา
ขั้นตอนที่ 8: ฝึกโมเดลโดยใช้คลาส KNeighborsClassifier ของ sklearn

แหล่งที่มา
ขั้นตอนที่ 9: ทำการทำนายโดยใช้สคริปต์ต่อไปนี้:

แหล่งที่มา
ขั้นตอนที่ 10: พิมพ์ผลลัพธ์

แหล่งที่มา
เอาท์พุท:

แหล่งที่มา
อะไรต่อไป? ลงทะเบียนสำหรับโปรแกรมประกาศนียบัตรขั้นสูงในการเรียนรู้ของเครื่องจาก IIT Madras และ upGrad
สมมติว่าคุณใฝ่ฝันที่จะเป็นผู้เชี่ยวชาญด้าน Data Scientist หรือ Machine Learning ในกรณีนี้ หลักสูตรการรับรองขั้นสูงในการเรียนรู้ของเครื่องและคลาวด์จาก IIT Madras และ upGrad เหมาะสำหรับคุณเท่านั้น!
โปรแกรมออนไลน์ 12 เดือนได้รับการออกแบบมาเป็นพิเศษสำหรับมืออาชีพด้านการทำงานที่ต้องการเรียนรู้แนวคิดหลักในการเรียนรู้ของเครื่อง การประมวลผลข้อมูลขนาดใหญ่ การจัดการข้อมูล คลังข้อมูล ระบบคลาวด์ และการใช้งานโมเดลการเรียนรู้ของเครื่อง
ต่อไปนี้คือไฮไลท์ของหลักสูตรบางส่วนเพื่อให้คุณมีแนวคิดที่ดีขึ้นเกี่ยวกับข้อเสนอของโปรแกรม:
- การรับรองอันทรงเกียรติที่ได้รับการยอมรับทั่วโลกจาก IIT Madras
- การเรียนรู้มากกว่า 500 ชั่วโมง, กรณีศึกษาและโครงการมากกว่า 20+ ครั้ง, เซสชันการให้คำปรึกษาในอุตสาหกรรมมากกว่า 25+ ครั้ง, งานเขียนโค้ด 8+ งาน
- ครอบคลุมภาษาและเครื่องมือการเขียนโปรแกรม 7 ภาษา
- 4 สัปดาห์ของโครงการสำคัญในอุตสาหกรรม
- เวิร์คช็อปแบบลงมือปฏิบัติ
- เครือข่ายเพียร์ทูเพียร์ออฟไลน์
ลงทะเบียนวันนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับโปรแกรม!
บทสรุป
เมื่อเวลาผ่านไป Big Data ก็เติบโตขึ้นเรื่อยๆ และปัญญาประดิษฐ์ก็เข้ามาพัวพันกับชีวิตของเรามากขึ้น เป็นผลให้มีความต้องการผู้เชี่ยวชาญด้านวิทยาศาสตร์ข้อมูลเพิ่มขึ้นอย่างรวดเร็วซึ่งสามารถใช้ประโยชน์จากพลังของโมเดลการเรียนรู้ของเครื่องเพื่อรวบรวมข้อมูลเชิงลึกและปรับปรุงกระบวนการทางธุรกิจที่สำคัญและโดยทั่วไปแล้วโลกของเรา ไม่ต้องสงสัยเลยว่าสาขาปัญญาประดิษฐ์และการเรียนรู้ของเครื่องมีแนวโน้มดีอย่างแน่นอน ด้วย upGrad คุณสามารถมั่นใจได้ว่าอาชีพของคุณในด้านการเรียนรู้ของเครื่องและระบบคลาวด์เป็นสิ่งที่คุ้มค่า!
ทำไม K-NN ถึงเป็นตัวแยกประเภทที่ดี?
ข้อได้เปรียบหลักของ K-NN เหนืออัลกอริธึมการเรียนรู้ของเครื่องอื่นๆ คือ เราสามารถใช้ K-NN สำหรับการจำแนกประเภทหลายคลาสได้อย่างสะดวก ดังนั้น K-NN จึงเป็นอัลกอริธึมที่ดีที่สุด หากเราจำเป็นต้องจำแนกข้อมูลออกเป็นมากกว่าสองหมวดหมู่ หรือหากข้อมูลประกอบด้วยป้ายกำกับมากกว่าสองป้าย นอกจากนี้ยังเหมาะสำหรับข้อมูลที่ไม่เป็นเชิงเส้นและมีความแม่นยำสูงอีกด้วย
ข้อจำกัดของอัลกอริทึม K-NN คืออะไร?
อัลกอริทึม K-NN ทำงานโดยการคำนวณระยะห่างระหว่างจุดข้อมูล ดังนั้นจึงค่อนข้างชัดเจนว่าอัลกอริธึมค่อนข้างใช้เวลานาน และจะใช้เวลาในการจัดหมวดหมู่มากกว่าในบางกรณี ดังนั้นจึงเป็นการดีที่สุดที่จะไม่ใช้จุดข้อมูลมากเกินไปในขณะที่ใช้ K-NN สำหรับการจำแนกประเภทหลายคลาส ข้อจำกัดอื่นๆ ได้แก่ ที่เก็บข้อมูลหน่วยความจำสูงและความไวต่อคุณสมบัติที่ไม่เกี่ยวข้อง
แอปพลิเคชั่น K-NN ในโลกแห่งความเป็นจริงคืออะไร?
K-NN มีกรณีการใช้งานในชีวิตจริงหลายอย่างในการเรียนรู้ของเครื่อง เช่น การตรวจจับลายมือ การรู้จำเสียง การรู้จำวิดีโอ และการจดจำภาพ ในการธนาคาร K-NN ใช้เพื่อทำนายว่าบุคคลมีสิทธิ์ได้รับเงินกู้หรือไม่โดยพิจารณาจากลักษณะที่คล้ายกับผู้ผิดนัดชำระหนี้ ในการเมือง สามารถใช้ K-NN เพื่อจำแนกผู้มีสิทธิเลือกตั้งออกเป็นประเภทต่างๆ เช่น "จะลงคะแนนให้พรรค X" หรือ "จะลงคะแนนให้พรรค Y" เป็นต้น