
ขอแนะนำ API แบบอิงส่วนประกอบ
เผยแพร่แล้ว: 2022-03-10บทความนี้ได้รับการปรับปรุงเมื่อวันที่ 31 มกราคม 2019 เพื่อตอบสนองต่อคำติชมของผู้อ่าน ผู้เขียนได้เพิ่มความสามารถในการค้นหาแบบกำหนดเองให้กับ API แบบอิงส่วนประกอบ และอธิบายวิธีการทำงาน
API คือช่องทางการสื่อสารสำหรับแอปพลิเคชันเพื่อโหลดข้อมูลจากเซิร์ฟเวอร์ ในโลกของ API นั้น REST เป็นวิธีการที่เป็นที่ยอมรับมากขึ้น แต่เมื่อเร็ว ๆ นี้ถูกบดบังโดย GraphQL ซึ่งมีข้อได้เปรียบที่สำคัญเหนือ REST ในขณะที่ REST ต้องการคำขอ HTTP หลายรายการเพื่อดึงชุดข้อมูลเพื่อแสดงส่วนประกอบ GraphQL สามารถสืบค้นและเรียกข้อมูลดังกล่าวในคำขอเดียว และการตอบสนองจะเป็นสิ่งที่จำเป็นอย่างแท้จริง โดยไม่ต้องดึงข้อมูลมากหรือน้อยเกินไปตามปกติ พักผ่อน.
ในบทความนี้ ผมจะอธิบายวิธีการดึงข้อมูลอีกวิธีหนึ่ง ซึ่งผมได้ออกแบบและเรียกว่า “PoP” (และโอเพ่นซอร์สที่นี่) ซึ่งขยายแนวคิดในการดึงข้อมูลสำหรับหลาย ๆ หน่วยงานในคำขอเดียวที่ GraphQL นำเสนอและนำไป ก้าวไปอีกขั้น กล่าวคือ ในขณะที่ REST ดึงข้อมูลสำหรับทรัพยากรหนึ่งรายการ และ GraphQL ดึงข้อมูลสำหรับทรัพยากรทั้งหมดในองค์ประกอบเดียว API แบบอิงองค์ประกอบสามารถดึงข้อมูลสำหรับทรัพยากรทั้งหมดจากส่วนประกอบทั้งหมดในหน้าเดียว
การใช้ API แบบอิงองค์ประกอบเหมาะสมที่สุดเมื่อเว็บไซต์สร้างขึ้นโดยใช้ส่วนประกอบ เช่น เมื่อหน้าเว็บประกอบด้วยส่วนประกอบที่วนรอบส่วนประกอบอื่นๆ ซ้ำๆ จนกระทั่งเราได้รับส่วนประกอบเดียวที่แสดงถึงหน้านั้นที่ด้านบนสุด ตัวอย่างเช่น หน้าเว็บที่แสดงในภาพด้านล่างสร้างขึ้นด้วยส่วนประกอบ ซึ่งถูกจัดกรอบด้วยสี่เหลี่ยม:
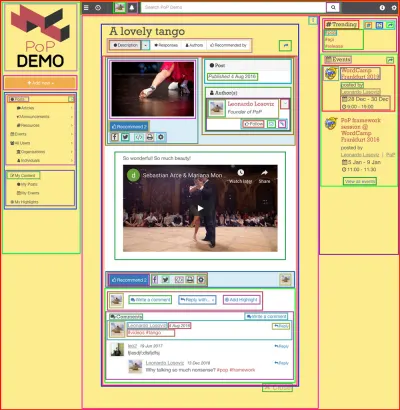
API แบบอิงองค์ประกอบสามารถสร้างคำขอเดียวไปยังเซิร์ฟเวอร์โดยขอข้อมูลสำหรับทรัพยากรทั้งหมดในแต่ละองค์ประกอบ (รวมถึงส่วนประกอบทั้งหมดในหน้า) ซึ่งทำได้โดยการรักษาความสัมพันธ์ระหว่างส่วนประกอบใน โครงสร้าง API เอง
โครงสร้างนี้มีประโยชน์หลายประการดังต่อไปนี้:
- หน้าที่มีองค์ประกอบหลายอย่างจะเรียกคำขอเพียงรายการเดียวแทนที่จะเป็นหลายรายการ
- ข้อมูลที่แชร์ระหว่างส่วนประกอบสามารถดึงได้เพียงครั้งเดียวจากฐานข้อมูลและพิมพ์เพียงครั้งเดียวในการตอบกลับ
- สามารถลดความจำเป็นในการจัดเก็บข้อมูลได้แม้กระทั่งลบออกโดยสิ้นเชิง
เราจะสำรวจรายละเอียดเหล่านี้ตลอดทั้งบทความ แต่ก่อนอื่น มาสำรวจว่าจริง ๆ แล้วส่วนประกอบคืออะไรและเราสามารถสร้างเว็บไซต์ตามส่วนประกอบดังกล่าวได้อย่างไร และสุดท้าย สำรวจว่า API แบบอิงองค์ประกอบทำงานอย่างไร
การอ่านที่แนะนำ : A GraphQL Primer: เหตุใดเราจึงต้องการ API ชนิดใหม่
การสร้างไซต์ผ่านส่วนประกอบ
ส่วนประกอบเป็นเพียงชุดของโค้ด HTML, JavaScript และ CSS ที่รวมกันเพื่อสร้างเอนทิตีอิสระ สิ่งนี้สามารถห่อส่วนประกอบอื่น ๆ เพื่อสร้างโครงสร้างที่ซับซ้อนมากขึ้นและถูกห่อหุ้มด้วยส่วนประกอบอื่น ๆ ด้วย องค์ประกอบมีวัตถุประสงค์ ซึ่งสามารถมีตั้งแต่บางอย่างพื้นฐานมาก (เช่น ลิงก์หรือปุ่ม) ไปจนถึงบางสิ่งที่ซับซ้อนมาก (เช่น ภาพหมุน หรือเครื่องมืออัปโหลดรูปภาพแบบลากและวาง) ส่วนประกอบจะมีประโยชน์มากที่สุดเมื่อเป็นแบบทั่วไปและเปิดใช้งานการปรับแต่งผ่านคุณสมบัติที่แทรก (หรือ “อุปกรณ์ประกอบฉาก”) เพื่อให้สามารถให้บริการกรณีการใช้งานที่หลากหลาย ในกรณีอย่างที่สุด ไซต์เองจะกลายเป็นส่วนประกอบ
คำว่า "ส่วนประกอบ" มักใช้เพื่ออ้างถึงทั้งการทำงานและการออกแบบ ตัวอย่างเช่น เกี่ยวกับการทำงาน กรอบงาน JavaScript เช่น React หรือ Vue อนุญาตให้สร้างส่วนประกอบฝั่งไคลเอ็นต์ ซึ่งสามารถแสดงผลได้เอง (เช่น หลังจากที่ API ดึงข้อมูลที่ต้องการ) และใช้อุปกรณ์ประกอบฉากเพื่อกำหนดค่าการกำหนดค่าบน ส่วนประกอบที่ห่อหุ้มไว้ ทำให้โค้ดสามารถนำกลับมาใช้ใหม่ได้ เกี่ยวกับการออกแบบ Bootstrap ได้กำหนดมาตรฐานว่าเว็บไซต์มีลักษณะและความรู้สึกอย่างไรผ่านไลบรารีองค์ประกอบส่วนหน้า และมันได้กลายเป็นเทรนด์ที่ดีสำหรับทีมในการสร้างระบบการออกแบบเพื่อดูแลเว็บไซต์ของตน ซึ่งช่วยให้สมาชิกในทีมที่แตกต่างกัน (นักออกแบบและนักพัฒนา แต่ยัง นักการตลาดและพนักงานขาย) เพื่อพูดภาษาที่เป็นหนึ่งเดียวและแสดงเอกลักษณ์ที่สม่ำเสมอ
การจัดองค์ประกอบเว็บไซต์เป็นวิธีที่สมเหตุสมผลในการทำให้เว็บไซต์สามารถบำรุงรักษาได้มากขึ้น ไซต์ที่ใช้เฟรมเวิร์ก JavaScript เช่น React และ Vue นั้นอิงตามส่วนประกอบอยู่แล้ว (อย่างน้อยก็ในฝั่งไคลเอ็นต์) การใช้ไลบรารี่คอมโพเนนต์เช่น Bootstrap ไม่ได้ทำให้ไซต์เป็นแบบคอมโพเนนต์ (อาจเป็น HTML ขนาดใหญ่) อย่างไรก็ตาม รวมแนวคิดขององค์ประกอบที่ใช้ซ้ำได้สำหรับอินเทอร์เฟซผู้ใช้
หากไซต์ เป็น HTML จำนวนมาก เพื่อให้เราจัดองค์ประกอบได้ เราต้องแบ่งเลย์เอาต์ออกเป็นชุดของรูปแบบที่เกิดซ้ำ ซึ่งเราต้องระบุและจัดหมวดหมู่ส่วนต่างๆ บนหน้าตามความคล้ายคลึงของการทำงานและสไตล์ และทำลายสิ่งเหล่านี้ แยกย่อยออกเป็นชั้นๆ ให้ละเอียดที่สุด โดยพยายามให้แต่ละชั้นเน้นไปที่เป้าหมายหรือการดำเนินการเดียว และพยายามจับคู่เลเยอร์ทั่วไปในส่วนต่างๆ
หมายเหตุ : “การออกแบบปรมาณู” ของแบรด ฟรอสต์เป็นวิธีการที่ยอดเยี่ยมในการระบุรูปแบบทั่วไปเหล่านี้และสร้างระบบการออกแบบที่นำกลับมาใช้ใหม่ได้
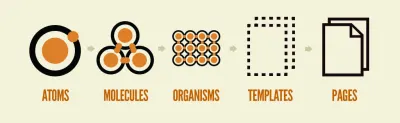
ดังนั้น การสร้างไซต์โดยใช้ส่วนประกอบจึงคล้ายกับการเล่นเลโก้ แต่ละองค์ประกอบเป็นฟังก์ชันของอะตอม องค์ประกอบของส่วนประกอบอื่น หรือทั้งสองอย่างรวมกัน
ดังที่แสดงด้านล่าง องค์ประกอบพื้นฐาน (อวาตาร์) จะประกอบด้วยองค์ประกอบอื่นๆ ซ้ำๆ จนกระทั่งได้หน้าเว็บที่ด้านบน:

ข้อมูลจำเพาะ API ตามส่วนประกอบ
สำหรับ API แบบอิงส่วนประกอบที่ฉันออกแบบไว้ คอมโพเนนต์จะเรียกว่า "โมดูล" ดังนั้นจากนี้ไปคำว่า "ส่วนประกอบ" และ "โมดูล" จะใช้แทนกันได้
ความสัมพันธ์ของโมดูลทั้งหมดที่ห่อหุ้มกันและกัน ตั้งแต่โมดูลบนสุดไปจนถึงระดับสุดท้าย เรียกว่า "ลำดับชั้นของส่วนประกอบ" ความสัมพันธ์นี้สามารถแสดงผ่านอาเรย์ที่เชื่อมโยง (อาร์เรย์ของคุณสมบัติคีย์ =>) บนฝั่งเซิร์ฟเวอร์ ซึ่งแต่ละโมดูลระบุชื่อเป็นแอตทริบิวต์คีย์และโมดูลภายในภายใต้ modules คุณสมบัติ จากนั้น API จะเข้ารหัสอาร์เรย์นี้เป็นออบเจกต์ JSON สำหรับการบริโภค:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }ความสัมพันธ์ระหว่างโมดูลถูกกำหนดโดยวิธีจากบนลงล่างอย่างเคร่งครัด: โมดูลห่อหุ้มโมดูลอื่น ๆ และรู้ว่าใครเป็นใคร แต่ก็ไม่ทราบและไม่สนใจว่าโมดูลใดที่ห่อหุ้มไว้
ตัวอย่างเช่น ในโค้ด JSON ด้านบน module module-level1 รู้ว่ามัน wraps modules modules module-level11 และ module-level12 และในเชิงสกรรมกริยา มันยังรู้ว่ามัน wraps module-level121 ; แต่โมดูล module-level11 ไม่สนใจว่าใครเป็นคนห่อมัน ดังนั้นจึงไม่รู้ module-level1
การมีโครงสร้างแบบอิงองค์ประกอบ ทำให้ตอนนี้เราสามารถเพิ่มข้อมูลจริงที่แต่ละโมดูลต้องการ ซึ่งจัดอยู่ในการตั้งค่าอย่างใดอย่างหนึ่ง (เช่น ค่าการกำหนดค่าและคุณสมบัติอื่นๆ) และข้อมูล (เช่น ID ของออบเจ็กต์ฐานข้อมูลที่สืบค้นและคุณสมบัติอื่นๆ) และวางไว้ตามรายการ modulesettings และ moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } ต่อไปนี้ API จะเพิ่มข้อมูลออบเจ็กต์ฐานข้อมูล ข้อมูลนี้ไม่ได้อยู่ภายใต้แต่ละโมดูล แต่อยู่ภายใต้ส่วนที่ใช้ร่วมกันที่เรียกว่า databases เพื่อหลีกเลี่ยงข้อมูลซ้ำซ้อนเมื่อโมดูลที่แตกต่างกันสองโมดูลขึ้นไปดึงวัตถุเดียวกันจากฐานข้อมูล
นอกจากนี้ API ยังแสดงข้อมูลออบเจ็กต์ฐานข้อมูลในลักษณะเชิงสัมพันธ์ เพื่อหลีกเลี่ยงข้อมูลซ้ำซ้อนเมื่อออบเจ็กต์ฐานข้อมูลที่แตกต่างกันสองรายการขึ้นไปเกี่ยวข้องกับออบเจ็กต์ทั่วไป (เช่น สองโพสต์ที่มีผู้เขียนคนเดียวกัน) กล่าวอีกนัยหนึ่ง ข้อมูลอ็อบเจ็กต์ฐานข้อมูลจะถูกทำให้เป็นมาตรฐาน
การอ่านที่แนะนำ : การ สร้างแบบฟอร์มการติดต่อแบบไร้เซิร์ฟเวอร์สำหรับไซต์แบบคงที่ของคุณ
โครงสร้างเป็นพจนานุกรม จัดระเบียบภายใต้แต่ละประเภทวัตถุก่อน และ ID วัตถุที่สอง ซึ่งเราจะได้รับคุณสมบัติของวัตถุ:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }ออบเจ็กต์ JSON นี้เป็นการตอบสนองจาก API แบบอิงคอมโพเนนต์แล้ว รูปแบบของมันคือข้อกำหนดทั้งหมดโดยตัวมันเอง: ตราบใดที่เซิร์ฟเวอร์ส่งคืนการตอบสนอง JSON ในรูปแบบที่ต้องการ ไคลเอนต์สามารถใช้ API ได้โดยไม่ขึ้นกับวิธีการนำไปใช้ ดังนั้น API สามารถนำไปใช้กับภาษาใดก็ได้ (ซึ่งเป็นหนึ่งในความสวยงามของ GraphQL: เป็นข้อกำหนดและไม่ใช่การใช้งานจริงทำให้สามารถใช้งานได้ในภาษาต่างๆ มากมาย)
หมายเหตุ : ในบทความต่อๆ ไป ฉันจะอธิบายการใช้งาน API แบบอิงส่วนประกอบใน PHP (ซึ่งมีอยู่ใน repo)
ตัวอย่างการตอบสนอง API
ตัวอย่างเช่น การตอบสนอง API ด้านล่างมีลำดับชั้นขององค์ประกอบที่มีสองโมดูล คือ page => post-feed โดยที่ module post-feed ดึงข้อมูลโพสต์ในบล็อก โปรดสังเกตสิ่งต่อไปนี้:
- แต่ละโมดูลรู้ว่าวัตถุใดที่สืบค้นจากคุณสมบัติ
dbobjectids(รหัส4และ9สำหรับโพสต์ในบล็อก) - แต่ละโมดูลรู้ประเภทอ็อบเจ็กต์สำหรับออบเจ็กต์ที่สืบค้นจากคุณสมบัติ
dbkeys(ข้อมูลของโพสต์แต่ละโพสต์อยู่ใต้postsและข้อมูลผู้เขียนโพสต์ ซึ่งสอดคล้องกับผู้เขียนด้วย ID ที่กำหนดภายใต้authorคุณสมบัติของโพสต์ อยู่ภายใต้users) - เนื่องจากข้อมูลอ็อบเจ็กต์ฐานข้อมูลเป็นแบบสัมพันธ์กัน
authorคุณสมบัติจึงมี ID ไปยังอ็อบเจ็กต์ผู้สร้าง แทนที่จะพิมพ์ข้อมูลผู้สร้างโดยตรง
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }ความแตกต่างในการดึงข้อมูลจาก API ที่ใช้ทรัพยากร แบบสคีมา และแบบคอมโพเนนต์
มาดูกันว่า API แบบอิงองค์ประกอบ เช่น PoP เป็นอย่างไร เมื่อดึงข้อมูล กับ API แบบอิงทรัพยากร เช่น REST และกับ API แบบอิงสคีมา เช่น GraphQL
สมมติว่า IMDB มีหน้าที่มีองค์ประกอบสองส่วนซึ่งจำเป็นต้องดึงข้อมูล: “ผู้กำกับที่โดดเด่น” (แสดงคำอธิบายของ George Lucas และรายชื่อภาพยนตร์ของเขา) และ “ภาพยนตร์ที่แนะนำสำหรับคุณ” (แสดงภาพยนตร์เช่น Star Wars: Episode I - ภัยคุกคามของแฟนทอม และ เทอ ร์มิเนเตอร์ ) อาจมีลักษณะดังนี้:
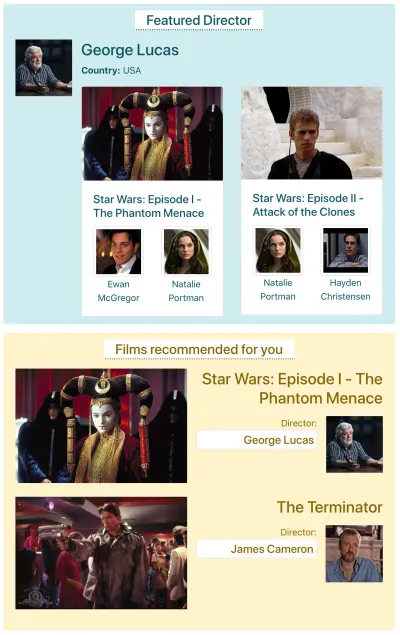
มาดูกันว่าต้องใช้คำขอจำนวนเท่าใดในการดึงข้อมูลผ่านแต่ละวิธีของ API สำหรับตัวอย่างนี้ องค์ประกอบ "ผู้กำกับที่โดดเด่น" นำผลลัพธ์หนึ่งรายการ ("จอร์จ ลูคัส") ซึ่งจะดึงภาพยนตร์สองเรื่อง ( Star Wars: Episode I — The Phantom Menace และ Star Wars: Episode II - Attack of the Clones ) และ สำหรับภาพยนตร์แต่ละเรื่อง นักแสดงสองคน (“Ewan McGregor” และ “Natalie Portman” สำหรับภาพยนตร์เรื่องแรก และ “Natalie Portman” และ “Hayden Christensen” สำหรับภาพยนตร์เรื่องที่สอง) องค์ประกอบ “ภาพยนตร์ที่แนะนำสำหรับคุณ” ให้ผลลัพธ์สองประการ ( Star Wars: Episode I — The Phantom Menace และ The Terminator ) จากนั้นจึงเรียกผู้กำกับ (“George Lucas” และ “James Cameron” ตามลำดับ)
การใช้ REST เพื่อแสดงส่วนประกอบ featured-director เราอาจต้องการคำขอ 7 รายการต่อไปนี้ (จำนวนนี้อาจแตกต่างกันไปขึ้นอยู่กับจำนวนข้อมูลที่ให้โดยแต่ละปลายทางเช่นมีการใช้การดึงข้อมูลมากเกินไป):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL อนุญาตให้ดึงข้อมูลที่จำเป็นทั้งหมดในคำขอเดียวต่อองค์ประกอบโดยใช้สคีมาที่พิมพ์อย่างเข้มงวด คิวรีเพื่อดึงข้อมูลผ่าน GraphQL สำหรับส่วนประกอบ featuredDirector Director มีลักษณะดังนี้ (หลังจากที่เราใช้สคีมาที่เกี่ยวข้อง):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }และทำให้เกิดการตอบสนองต่อไปนี้:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }และการสอบถามส่วนประกอบ "ภาพยนตร์ที่แนะนำสำหรับคุณ" ทำให้เกิดคำตอบต่อไปนี้:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP จะออกคำขอเพียงครั้งเดียวเพื่อดึงข้อมูลทั้งหมดสำหรับส่วนประกอบทั้งหมดในหน้าและทำให้ผลลัพธ์เป็นมาตรฐาน ปลายทางที่จะเรียกนั้นเหมือนกับ URL ที่เราต้องการเพื่อรับข้อมูล เพียงแค่เพิ่มพารามิเตอร์เพิ่มเติม output=json เพื่อระบุให้นำข้อมูลมาในรูปแบบ JSON แทนการพิมพ์เป็น HTML:
GET - /url-of-the-page/?output=json สมมติว่าโครงสร้างโมดูลมีโมดูลบนสุดที่มีชื่อ page ซึ่งมีโมดูล featured-director และ films-recommended-for-you และสิ่งเหล่านี้ยังมีโมดูลย่อยดังนี้:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"การตอบกลับ JSON ที่ส่งคืนครั้งเดียวจะมีลักษณะดังนี้:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }มาวิเคราะห์ว่าทั้งสามวิธีนี้เปรียบเทียบกันอย่างไรในแง่ของความเร็วและปริมาณข้อมูลที่ดึงมาได้
ความเร็ว
ผ่าน REST การดึงคำขอ 7 รายการเพียงเพื่อแสดงองค์ประกอบหนึ่งอาจช้ามาก ส่วนใหญ่ในการเชื่อมต่อข้อมูลมือถือและสั่นคลอน ดังนั้น การข้ามจาก REST ไปเป็น GraphQL แสดงถึงความเร็วอย่างมาก เนื่องจากเราสามารถแสดงส่วนประกอบด้วยคำขอเดียวเท่านั้น
เนื่องจาก PoP สามารถดึงข้อมูลทั้งหมดสำหรับส่วนประกอบจำนวนมากในคำขอเดียว จะเร็วกว่าสำหรับการแสดงส่วนประกอบจำนวนมากในคราวเดียว อย่างไรก็ตาม ไม่น่าจะมีความจำเป็นสำหรับสิ่งนี้ การแสดงองค์ประกอบตามลำดับ (ตามที่ปรากฏในหน้า) ถือเป็นแนวทางปฏิบัติที่ดีอยู่แล้ว และสำหรับส่วนประกอบเหล่านั้นซึ่งปรากฏอยู่ครึ่งหน้าบน ไม่จำเป็นต้องรีบแสดงผลอย่างแน่นอน ดังนั้นทั้ง API ที่ใช้สคีมาและ API แบบอิงส่วนประกอบจึงค่อนข้างดีและเหนือกว่า API แบบอิงทรัพยากรอย่างชัดเจน
ปริมาณข้อมูล
ในแต่ละคำขอ ข้อมูลในการตอบสนองของ GraphQL อาจซ้ำกันได้: นักแสดงหญิง “นาตาลี พอร์ตแมน” ถูกดึงสองครั้งในการตอบสนองจากองค์ประกอบแรก และเมื่อพิจารณาผลลัพธ์ร่วมกันสำหรับทั้งสององค์ประกอบ เรายังพบข้อมูลที่แชร์ เช่น ภาพยนตร์ สตาร์ วอร์ส: ตอนที่ 1 – ภัยอันตราย
ในทางกลับกัน PoP ทำให้ข้อมูลฐานข้อมูลเป็นมาตรฐานและพิมพ์เพียงครั้งเดียว อย่างไรก็ตาม มันมีค่าใช้จ่ายในการพิมพ์โครงสร้างโมดูล ดังนั้น ขึ้นอยู่กับคำขอที่มีข้อมูลที่ซ้ำกันหรือไม่ API แบบอิงสคีมาหรือ API แบบคอมโพเนนต์จะมีขนาดที่เล็กกว่า
โดยสรุป API ที่ใช้สคีมา เช่น GraphQL และ API แบบอิงส่วนประกอบ เช่น PoP นั้นมีประสิทธิภาพที่ดีในทำนองเดียวกัน และเหนือกว่า API ตามทรัพยากร เช่น REST
การอ่านที่แนะนำ : การ ทำความเข้าใจและการใช้ REST APIs
คุณสมบัติเฉพาะของ API แบบคอมโพเนนต์
หาก API แบบอิงองค์ประกอบไม่จำเป็นต้องดีกว่าในแง่ของประสิทธิภาพมากกว่า API แบบอิงสคีมา คุณอาจสงสัยว่าฉันกำลังพยายามทำอะไรให้สำเร็จในบทความนี้
ในส่วนนี้ ฉันจะพยายามเกลี้ยกล่อมคุณว่า API ดังกล่าวมีศักยภาพที่เหลือเชื่อ โดยมีคุณสมบัติหลายอย่างที่เป็นที่ต้องการอย่างมาก ทำให้เป็นคู่แข่งสำคัญในโลกของ API ฉันอธิบายและสาธิตคุณลักษณะที่ยอดเยี่ยมแต่ละอย่างด้านล่างนี้
ข้อมูลที่จะดึงจากฐานข้อมูลสามารถอนุมานได้จากลำดับชั้นของส่วนประกอบ
เมื่อโมดูลแสดงคุณสมบัติจากอ็อบเจ็กต์ DB โมดูลอาจไม่รู้หรือสนใจว่ามันคืออ็อบเจกต์อะไร สิ่งที่สนใจคือการกำหนดคุณสมบัติจากอ็อบเจ็กต์ที่โหลดไว้
ตัวอย่างเช่น พิจารณาภาพด้านล่าง โมดูลโหลดอ็อบเจ็กต์จากฐานข้อมูล (ในกรณีนี้ โพสต์เดียว) จากนั้นโมดูลที่สืบทอดจะแสดงคุณสมบัติบางอย่างจากอ็อบเจ็กต์ เช่น title และ content :
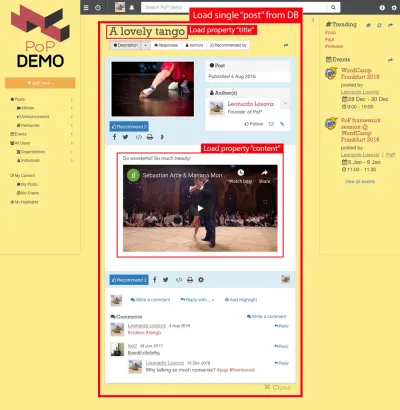
ดังนั้น ตามลำดับชั้นของส่วนประกอบ โมดูล "การโหลดข้อมูล" จะรับผิดชอบในการโหลดออบเจ็กต์ที่สืบค้น (โมดูลที่โหลดโพสต์เดียว ในกรณีนี้) และโมดูลย่อยจะกำหนดคุณสมบัติจากวัตถุ DB ที่ต้องการ ( title และ content ในกรณีนี้)
การดึงคุณสมบัติที่จำเป็นทั้งหมดสำหรับอ็อบเจ็กต์ DB สามารถทำได้โดยอัตโนมัติโดยผ่านลำดับชั้นของส่วนประกอบ: เริ่มจากโมดูลการโหลดข้อมูล เราวนซ้ำโมดูลที่สืบทอดมาทั้งหมดจนถึงโมดูลการโหลดข้อมูลใหม่ หรือจนกว่าจะสิ้นสุดทรี ในแต่ละระดับ เราได้รับคุณสมบัติที่จำเป็นทั้งหมด จากนั้นรวมคุณสมบัติทั้งหมดเข้าด้วยกัน และสืบค้นจากฐานข้อมูล ทั้งหมดเพียงครั้งเดียว
ในโครงสร้างด้านล่าง โมดูล single-post จะดึงผลลัพธ์จาก DB (โพสต์ที่มี ID 37) และโมดูลย่อยของ post-title และ post-content จะกำหนดคุณสมบัติที่จะโหลดสำหรับอ็อบเจ็กต์ DB ที่สืบค้น ( title และ content ตามลำดับ) โมดูลย่อย post-layout และ fetch-next-post-button ไม่ต้องการฟิลด์ข้อมูลใด ๆ
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"คิวรีที่จะดำเนินการคำนวณโดยอัตโนมัติจากลำดับชั้นของส่วนประกอบและฟิลด์ข้อมูลที่จำเป็น ซึ่งประกอบด้วยคุณสมบัติทั้งหมดที่โมดูลและโมดูลย่อยทั้งหมดต้องการ:
SELECT title, content FROM posts WHERE id = 37 โดยการดึงคุณสมบัติเพื่อดึงข้อมูลโดยตรงจากโมดูล แบบสอบถามจะได้รับการปรับปรุงโดยอัตโนมัติทุกครั้งที่มีการเปลี่ยนแปลงลำดับชั้นของส่วนประกอบ ตัวอย่างเช่น หากเราเพิ่มโมดูลย่อย post-thumbnail ซึ่งต้องใช้ thumbnail ของฟิลด์ข้อมูล :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"จากนั้น แบบสอบถามจะได้รับการอัปเดตโดยอัตโนมัติเพื่อดึงคุณสมบัติเพิ่มเติม:
SELECT title, content, thumbnail FROM posts WHERE id = 37เนื่องจากเราได้สร้างข้อมูลออบเจ็กต์ฐานข้อมูลเพื่อดึงข้อมูลในลักษณะเชิงสัมพันธ์ เราจึงสามารถใช้กลยุทธ์นี้กับความสัมพันธ์ระหว่างออบเจ็กต์ฐานข้อมูลได้
พิจารณาภาพด้านล่าง: เริ่มจากประเภทวัตถุ post และเลื่อนลำดับชั้นของส่วนประกอบ เราจะต้องเปลี่ยนประเภทวัตถุ DB เป็น user และ comment ให้สอดคล้องกับผู้เขียนโพสต์และความคิดเห็นของโพสต์แต่ละรายการตามลำดับ จากนั้นสำหรับแต่ละรายการ ความคิดเห็นจะต้องเปลี่ยนประเภทวัตถุอีกครั้งให้กับ user ที่สอดคล้องกับผู้เขียนความคิดเห็น
การย้ายจากวัตถุฐานข้อมูลไปยังวัตถุเชิงสัมพันธ์ (อาจเปลี่ยนประเภทวัตถุเช่นใน post => author ที่เปลี่ยนจาก post เป็น user หรือไม่เช่นใน author => ผู้ติดตามที่เปลี่ยนจาก user เป็น user ) คือสิ่งที่ฉันเรียกว่า "การสลับโดเมน ”
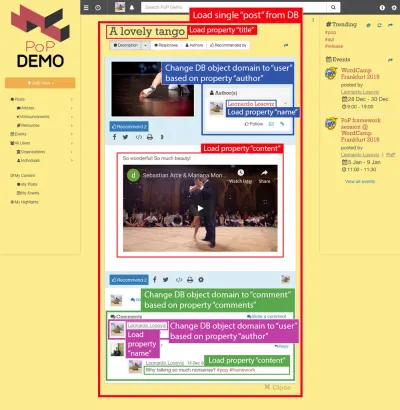
หลังจากเปลี่ยนไปใช้โดเมนใหม่ จากระดับนั้นที่ลำดับชั้นขององค์ประกอบลงมา คุณสมบัติที่จำเป็นทั้งหมดจะอยู่ภายใต้โดเมนใหม่:
-
nameถูกดึงมาจากวัตถุuser(เป็นตัวแทนของผู้เขียนโพสต์) - ดึง
contentจากออบเจ็กต์comment(แสดงถึงความคิดเห็นของโพสต์แต่ละรายการ) -
nameถูกดึงมาจากวัตถุuser(เป็นตัวแทนของผู้เขียนความคิดเห็นแต่ละข้อ)
เมื่อข้ามผ่านลำดับชั้นของคอมโพเนนต์ API จะรู้เมื่อเปลี่ยนเป็นโดเมนใหม่ และอัปเดตการสืบค้นเพื่อดึงข้อมูลออบเจ็กต์ที่เกี่ยวข้องอย่างเหมาะสม
ตัวอย่างเช่น หากเราจำเป็นต้องแสดงข้อมูลจากผู้เขียน post-author โมดูลย่อยที่ซ้อนกันจะเปลี่ยนโดเมนที่ระดับนั้นจาก post เป็น user ที่เกี่ยวข้อง และจากระดับนี้ลงวัตถุ DB ที่โหลดเข้าสู่บริบทที่ส่งผ่านไปยังโมดูลคือ ผู้ใช้งาน. จากนั้น submodules user-name และ user-avatar ภายใต้ post-author จะโหลดคุณสมบัติ name และ avatar ภายใต้ user object:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"ส่งผลให้แบบสอบถามต่อไปนี้:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idโดยสรุป โดยการกำหนดค่าแต่ละโมดูลอย่างเหมาะสม ไม่จำเป็นต้องเขียนแบบสอบถามเพื่อดึงข้อมูลสำหรับ API แบบอิงองค์ประกอบ แบบสอบถามถูกสร้างขึ้นโดยอัตโนมัติจากโครงสร้างของลำดับชั้นของส่วนประกอบ โดยได้รับสิ่งที่ต้องโหลดโดยโมดูล dataloading ฟิลด์ที่จะดึงข้อมูลสำหรับแต่ละวัตถุที่โหลดซึ่งกำหนดไว้ที่แต่ละโมดูลลูกหลานและการสลับโดเมนที่กำหนดไว้ในแต่ละโมดูลลูกหลาน
การเพิ่ม ลบ แทนที่ หรือแก้ไขโมดูลใดๆ จะเป็นการอัปเดตการสืบค้นโดยอัตโนมัติ หลังจากดำเนินการสืบค้นข้อมูลแล้ว ข้อมูลที่ดึงมาจะเป็นสิ่งที่จำเป็นอย่างแท้จริง ไม่มีอะไรมากหรือน้อย
การสังเกตข้อมูลและการคำนวณคุณสมบัติเพิ่มเติม
ตั้งแต่โมดูลการโหลดข้อมูลจนถึงลำดับชั้นของส่วนประกอบ โมดูลใดๆ สามารถสังเกตผลลัพธ์ที่ส่งคืนและคำนวณรายการข้อมูลเพิ่มเติมตามโมดูล หรือค่า feedback ซึ่งอยู่ภายใต้รายการ moduledata
ตัวอย่างเช่น module fetch-next-post-button สามารถเพิ่มคุณสมบัติที่ระบุว่ามีผลลัพธ์เพิ่มเติมที่จะดึงหรือไม่ (ขึ้นอยู่กับค่าข้อเสนอแนะนี้ หากไม่มีผลลัพธ์เพิ่มเติม ปุ่มจะถูกปิดใช้งานหรือซ่อนไว้):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }ความรู้โดยปริยายเกี่ยวกับข้อมูลที่ต้องการลดความซับซ้อนและทำให้แนวคิดของ "ปลายทาง" ล้าสมัย
ดังที่แสดงไว้ข้างต้น API แบบอิงส่วนประกอบสามารถดึงข้อมูลที่ต้องการได้อย่างแม่นยำ เพราะมีโมเดลของส่วนประกอบทั้งหมดบนเซิร์ฟเวอร์และแต่ละส่วนประกอบต้องการฟิลด์ข้อมูลใดบ้าง จากนั้นจะทำให้ความรู้เกี่ยวกับฟิลด์ข้อมูลที่จำเป็นโดยปริยาย

ข้อดีคือการกำหนดข้อมูลที่ต้องการโดยคอมโพเนนต์สามารถอัปเดตได้ทางฝั่งเซิร์ฟเวอร์โดยไม่ต้องปรับใช้ไฟล์ JavaScript ซ้ำ และไคลเอ็นต์ก็กลายเป็นใบ้ได้ เพียงขอให้เซิร์ฟเวอร์ให้ข้อมูลตามที่ต้องการ ซึ่งช่วยลดความซับซ้อนของแอปพลิเคชันฝั่งไคลเอ็นต์
นอกจากนี้ การเรียก API เพื่อดึงข้อมูลสำหรับส่วนประกอบทั้งหมดสำหรับ URL เฉพาะสามารถทำได้โดยการสืบค้น URL นั้นบวกกับการเพิ่มพารามิเตอร์พิเศษ output=json เพื่อระบุการส่งคืนข้อมูล API แทนการพิมพ์หน้า ดังนั้น URL จะกลายเป็นปลายทางของตัวเอง หรือเมื่อพิจารณาในแนวทางที่ต่างออกไป แนวคิดของ "ปลายทาง" จะล้าสมัย
การดึงข้อมูลชุดย่อย: สามารถดึงข้อมูลสำหรับโมดูลเฉพาะ ซึ่งพบได้ที่ระดับใดๆ ของลำดับชั้นของส่วนประกอบ
จะเกิดอะไรขึ้นหากเราไม่ต้องการดึงข้อมูลสำหรับโมดูลทั้งหมดในหน้าเว็บ แต่เพียงแค่ข้อมูลสำหรับโมดูลเฉพาะที่เริ่มต้นที่ระดับของลำดับชั้นของส่วนประกอบใดๆ ตัวอย่างเช่น หากโมดูลใช้การเลื่อนแบบไม่สิ้นสุด เมื่อเลื่อนลงมา เราต้องดึงเฉพาะข้อมูลใหม่สำหรับโมดูลนี้ ไม่ใช่สำหรับโมดูลอื่นๆ บนหน้า
ซึ่งสามารถทำได้โดยการกรองสาขาของลำดับชั้นของส่วนประกอบที่จะรวมอยู่ในการตอบสนอง เพื่อรวมคุณสมบัติเฉพาะที่เริ่มต้นจากโมดูลที่ระบุและละเว้นทุกอย่างที่อยู่เหนือระดับนี้ ในการใช้งานของฉัน (ซึ่งฉันจะอธิบายในบทความถัดไป) การกรองถูกเปิดใช้งานโดยการเพิ่มพารามิเตอร์ modulefilter=modulepaths ไปยัง URL และโมดูลที่เลือก (หรือโมดูล) จะถูกระบุผ่านพารามิเตอร์ modulepaths[] โดยที่ "เส้นทางของโมดูล ” เป็นรายการของโมดูลที่เริ่มต้นจากโมดูลบนสุดไปยังโมดูลเฉพาะ (เช่น module1 => module2 => module3 มีเส้นทางของโมดูล [ module1 , module2 , module3 ] และถูกส่งผ่านเป็นพารามิเตอร์ URL เป็น module1.module2.module3 ) .
ตัวอย่างเช่น ในลำดับชั้นองค์ประกอบด้านล่างทุกโมดูลมีรายการ dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] จากนั้นขอ URL ของหน้าเว็บเพิ่มพารามิเตอร์ modulefilter=modulepaths และ modulepaths[]=module1.module2.module5 จะสร้างการตอบสนองต่อไปนี้:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] โดยพื้นฐานแล้ว API จะเริ่มโหลดข้อมูลโดยเริ่มจาก module1 => module2 => module5 นั่นเป็นสาเหตุที่ module6 ซึ่งอยู่ภายใต้ module5 นำข้อมูลมาด้วยในขณะที่ module3 และ module4 ไม่นำข้อมูลมาด้วย
นอกจากนี้ เราสามารถสร้างตัวกรองโมดูลที่กำหนดเองเพื่อรวมชุดโมดูลที่จัดเตรียมไว้ล่วงหน้า ตัวอย่างเช่น การเรียกเพจด้วย modulefilter=userstate สามารถพิมพ์เฉพาะโมดูลที่ต้องการสถานะผู้ใช้สำหรับการแสดงผลในไคลเอนต์ เช่น modules module3 และ module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] ข้อมูลที่เป็นโมดูลเริ่มต้นอยู่ภายใต้ส่วน requestmeta ภายใต้รายการ filteredmodules เป็นอาร์เรย์ของเส้นทางโมดูล:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }คุณลักษณะนี้อนุญาตให้ใช้แอปพลิเคชันหน้าเดียวที่ไม่ซับซ้อน ซึ่งเฟรมของไซต์ถูกโหลดในคำขอเริ่มต้น:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] แต่จากนี้ไป เราสามารถผนวกพารามิเตอร์ modulefilter=page กับ URL ที่ร้องขอทั้งหมด กรองเฟรมและนำเฉพาะเนื้อหาของหน้า:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] คล้ายกับตัวกรองโมดูล userstate และ page อธิบายข้างต้น เราสามารถใช้ตัวกรองโมดูลที่กำหนดเองและสร้างประสบการณ์ผู้ใช้ที่หลากหลาย
โมดูลนี้เป็น API ของตัวเอง
ดังที่แสดงไว้ข้างต้น เราสามารถกรองการตอบสนอง API เพื่อดึงข้อมูลที่เริ่มต้นจากโมดูลใดก็ได้ เป็นผลให้ทุกโมดูลสามารถโต้ตอบกับตัวเองจากไคลเอนต์ไปยังเซิร์ฟเวอร์โดยการเพิ่มเส้นทางโมดูลไปยัง URL ของหน้าเว็บที่รวมอยู่
ฉันหวังว่าคุณจะแก้ตัวจากความตื่นเต้นของฉัน แต่ฉันไม่สามารถเน้นได้อย่างแท้จริงว่าคุณลักษณะนี้ยอดเยี่ยมเพียงใด เมื่อสร้างส่วนประกอบ เราไม่จำเป็นต้องสร้าง API เพื่อทำงานร่วมกับมันเพื่อดึงข้อมูล (REST, GraphQL หรืออย่างอื่นเลย) เพราะส่วนประกอบนั้นสามารถพูดคุยกับตัวเองในเซิร์ฟเวอร์และโหลดของตัวเองได้แล้ว ข้อมูล — มันเป็นอิสระอย่างสมบูรณ์และให้บริการ ตนเอง
โมดูล dataloading แต่ละโมดูลส่งออก URL เพื่อโต้ตอบกับมันภายใต้รายการ dataloadsource จากภายใต้ส่วน datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }การดึงข้อมูลถูกแยกระหว่างโมดูลและ DRY
เพื่อให้ประเด็นของฉันที่ดึงข้อมูลใน API แบบอิงองค์ประกอบนั้นแยกออกสูงและ DRY ( D บนไม่ R epeat Y ด้วยตัวเอง) ก่อนอื่นฉันต้องแสดงให้เห็นว่าใน API แบบสคีมาเช่น GraphQL นั้นแยกส่วนน้อยกว่าและ ไม่แห้ง
ใน GraphQL การสืบค้นเพื่อดึงข้อมูลต้องระบุฟิลด์ข้อมูลสำหรับส่วนประกอบ ซึ่งอาจรวมถึงองค์ประกอบย่อย และอาจรวมถึงองค์ประกอบย่อย และอื่นๆ จากนั้น ส่วนประกอบระดับบนสุดจำเป็นต้องรู้ว่าส่วนประกอบย่อยทั้งหมดต้องการข้อมูลใดบ้าง เพื่อที่จะดึงข้อมูลนั้น
ตัวอย่างเช่น การแสดงองค์ประกอบ <FeaturedDirector> อาจต้องการส่วนประกอบย่อยต่อไปนี้:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> ในสถานการณ์สมมตินี้ แบบสอบถาม GraphQL ถูกนำมาใช้ที่ระดับ <FeaturedDirector> จากนั้น หากมีการอัปเดตองค์ประกอบย่อย <Film> การขอชื่อเรื่องผ่านคุณสมบัติ filmTitle แทน title การสืบค้นจากองค์ประกอบ <FeaturedDirector> จะต้องได้รับการอัปเดตด้วยเพื่อสะท้อนข้อมูลใหม่นี้ (GraphQL มีกลไกการกำหนดเวอร์ชันที่สามารถจัดการได้ กับปัญหานี้ แต่ไม่ช้าก็เร็ว เรายังควรปรับปรุงข้อมูล) สิ่งนี้ทำให้เกิดความซับซ้อนในการบำรุงรักษา ซึ่งอาจจัดการได้ยากเมื่อส่วนประกอบภายในมักจะเปลี่ยนแปลงหรือผลิตโดยนักพัฒนาบุคคลที่สาม ดังนั้น ส่วนประกอบจึงไม่ถูกแยกออกจากกันอย่างทั่วถึง
ในทำนองเดียวกัน เราอาจต้องการแสดงองค์ประกอบ <Film> โดยตรงสำหรับภาพยนตร์บางเรื่อง ซึ่งจากนั้นเราต้องใช้การสืบค้น GraphQL ที่ระดับนี้ เพื่อดึงข้อมูลสำหรับภาพยนตร์และนักแสดง ซึ่งเพิ่มโค้ดซ้ำซ้อน: บางส่วนของ แบบสอบถามเดียวกันจะอยู่ที่ระดับต่างๆ ของโครงสร้างส่วนประกอบ ดังนั้น GraphQL จึงไม่ DRY
เนื่องจาก API แบบอิงส่วนประกอบรู้อยู่แล้วว่าส่วนประกอบต่างๆ รวมเข้าด้วยกันในโครงสร้างของตัวเองอย่างไร ปัญหาเหล่านี้จึงหลีกเลี่ยงได้โดยสิ้นเชิง ประการหนึ่ง ลูกค้าสามารถขอข้อมูลที่จำเป็นได้อย่างง่ายดาย ไม่ว่าข้อมูลนี้จะเป็นอย่างไร if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
อย่างไรก็ตาม ใน API แบบอิงองค์ประกอบ เราสามารถใช้ความสัมพันธ์ระหว่างโมดูลที่อธิบายไว้แล้วใน API เพื่อจับคู่โมดูลเข้าด้วยกันได้อย่างง่ายดาย ในขณะที่เดิมเราจะได้รับคำตอบนี้:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }หลังจากเพิ่ม Instagram เราจะได้รับการตอบกลับที่อัปเกรดแล้ว:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } และเพียงแค่ทำซ้ำค่าทั้งหมดภายใต้ modulesettings["share-on-social-media"].modules ส่วนประกอบ <ShareOnSocialMedia> สามารถอัปเกรดเพื่อแสดงองค์ประกอบ <InstagramShare> โดยไม่ต้องปรับใช้ไฟล์ JavaScript ใหม่ ดังนั้น API จึงสนับสนุนการเพิ่มและการนำโมดูลออกโดยไม่กระทบต่อโค้ดจากโมดูลอื่นๆ เพื่อให้ได้โมดูลในระดับที่สูงขึ้น
Native Client-Side Cache/ที่เก็บข้อมูล
ข้อมูลฐานข้อมูลที่ดึงออกมาจะถูกทำให้เป็นมาตรฐานในโครงสร้างพจนานุกรม และทำให้เป็นมาตรฐาน ดังนั้น เริ่มต้นจากค่าบน dbobjectids ชิ้นส่วนของข้อมูลใด ๆ ภายใต้ databases สามารถเข้าถึงได้โดยทำตามเส้นทางที่ระบุผ่านรายการ dbkeys ไม่ว่าจะมีโครงสร้างอย่างไร . ดังนั้น ตรรกะในการจัดระเบียบข้อมูลจึงมีอยู่แล้วใน API
เราสามารถใช้ประโยชน์จากสถานการณ์นี้ได้หลายวิธี ตัวอย่างเช่น ข้อมูลที่ส่งคืนสำหรับแต่ละคำขอสามารถเพิ่มลงในแคชฝั่งไคลเอ็นต์ซึ่งมีข้อมูลทั้งหมดที่ผู้ใช้ร้องขอตลอดเซสชัน ดังนั้นจึงเป็นไปได้ที่จะหลีกเลี่ยงการเพิ่มที่เก็บข้อมูลภายนอก เช่น Redux ลงในแอปพลิเคชัน (ฉันหมายถึงการจัดการข้อมูล ไม่เกี่ยวกับคุณสมบัติอื่นๆ เช่น การเลิกทำ/ทำซ้ำ สภาพแวดล้อมการทำงานร่วมกัน หรือการดีบักการเดินทางข้ามเวลา)
โครงสร้างตามส่วนประกอบส่งเสริมการแคชด้วย: ลำดับชั้นขององค์ประกอบไม่ได้ขึ้นอยู่กับ URL แต่ขึ้นอยู่กับส่วนประกอบที่จำเป็นใน URL นั้น ด้วยวิธีนี้ สองเหตุการณ์ภายใต้ /events/1/ และ /events/2/ จะใช้ลำดับชั้นของคอมโพเนนต์เดียวกัน และข้อมูลของโมดูลที่จำเป็นสามารถนำกลับมาใช้ใหม่ได้ ด้วยเหตุนี้ คุณสมบัติทั้งหมด (นอกเหนือจากข้อมูลฐานข้อมูล) สามารถแคชบนไคลเอ็นต์ได้หลังจากดึงข้อมูลเหตุการณ์แรกและนำกลับมาใช้ใหม่ตั้งแต่นั้นเป็นต้นมา ดังนั้นต้องดึงเฉพาะข้อมูลฐานข้อมูลสำหรับแต่ละเหตุการณ์ที่ตามมาเท่านั้น และไม่มีสิ่งอื่นใดอีก
การขยายและการนำกลับมาใช้ใหม่
ส่วน databases ของ API สามารถขยายได้ ทำให้สามารถจัดหมวดหมู่ข้อมูลเป็นส่วนย่อยที่กำหนดเองได้ โดยค่าเริ่มต้น ข้อมูลออบเจ็กต์ฐานข้อมูลทั้งหมดจะอยู่ภายใต้รายการ primary อย่างไรก็ตาม เรายังสามารถสร้างรายการที่กำหนดเองเพื่อวางคุณสมบัติของอ็อบเจ็กต์ DB เฉพาะได้
ตัวอย่างเช่น หากองค์ประกอบ “ภาพยนตร์ที่แนะนำสำหรับคุณ” ที่อธิบายไว้ก่อนหน้านี้แสดงรายชื่อเพื่อนของผู้ใช้ที่เข้าสู่ระบบซึ่งเคยดูภาพยนตร์เรื่องนี้ภายใต้คุณสมบัติ friendsWhoWatchedFilm บนวัตถุ DB ของ film เนื่องจากค่านี้จะเปลี่ยนไปขึ้นอยู่กับการเข้าสู่ระบบ จากนั้นเราบันทึกคุณสมบัตินี้ภาย userstate รายการสถานะผู้ใช้แทน ดังนั้นเมื่อผู้ใช้ออกจากระบบ เราจะลบเฉพาะสาขานี้ออกจากฐานข้อมูลที่แคชบนไคลเอนต์ แต่ข้อมูล primary ทั้งหมดยังคงอยู่:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }นอกจากนี้ โครงสร้างของการตอบสนอง API สามารถกำหนดวัตถุประสงค์ใหม่ได้จนถึงจุดหนึ่ง โดยเฉพาะอย่างยิ่ง ผลลัพธ์ของฐานข้อมูลสามารถพิมพ์ในโครงสร้างข้อมูลที่แตกต่างกัน เช่น อาร์เรย์แทนที่จะเป็นพจนานุกรมเริ่มต้น
ตัวอย่างเช่น หากประเภทอ็อบเจ็กต์มีเพียงหนึ่งประเภท (เช่น films ) ก็สามารถจัดรูปแบบเป็นอาร์เรย์เพื่อป้อนลงในคอมโพเนนต์ของตัวพิมพ์โดยตรงได้:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]รองรับการเขียนโปรแกรมเชิงมุมมอง
นอกเหนือจากการดึงข้อมูลแล้ว API แบบอิงองค์ประกอบยังสามารถโพสต์ข้อมูลได้อีกด้วย เช่น สำหรับการสร้างโพสต์หรือเพิ่มความคิดเห็น และดำเนินการใดๆ เช่น การล็อกผู้ใช้เข้าหรือออก การส่งอีเมล บันทึก การวิเคราะห์ และอื่นๆ ไม่มีข้อจำกัด: ฟังก์ชันใด ๆ ที่มีให้โดย CMS พื้นฐานสามารถเรียกใช้ผ่านโมดูล — ในทุกระดับ
ตามลำดับชั้นของส่วนประกอบ เราสามารถเพิ่มโมดูลจำนวนเท่าใดก็ได้ และแต่ละโมดูลสามารถดำเนินการได้เอง ดังนั้น การดำเนินการทั้งหมดไม่จำเป็นต้องเกี่ยวข้องกับการดำเนินการที่คาดหวังของคำขอเสมอไป เช่น เมื่อทำการดำเนินการ POST, PUT หรือ DELETE ใน REST หรือส่งการกลายพันธุ์ใน GraphQL แต่สามารถเพิ่มฟังก์ชันเพิ่มเติมได้ เช่น การส่งอีเมล ถึงผู้ดูแลระบบเมื่อผู้ใช้สร้างโพสต์ใหม่
ดังนั้น โดยการกำหนดลำดับชั้นของส่วนประกอบผ่านไฟล์การพึ่งพาการฉีดหรือการกำหนดค่า API สามารถกล่าวได้ว่าสนับสนุนการเขียนโปรแกรมที่เน้น Aspect ซึ่งเป็น "กระบวนทัศน์การเขียนโปรแกรมที่มีจุดมุ่งหมายเพื่อเพิ่มโมดูลาร์โดยอนุญาตให้แยกข้อกังวลแบบไขว้"
การอ่านที่แนะนำ : การปกป้องเว็บไซต์ของคุณด้วยนโยบายคุณสมบัติ
ความปลอดภัยขั้นสูง
ชื่อของโมดูลไม่จำเป็นต้องกำหนดตายตัวเมื่อพิมพ์ในเอาต์พุต แต่สามารถย่อ ทำลาย เปลี่ยนแปลงแบบสุ่ม หรือ (โดยย่อ) สร้างตัวแปรตามที่ต้องการได้ ในขณะที่เดิมคิดว่าจะย่อเอาต์พุต API (เพื่อให้ชื่อโมดูล carousel-featured-posts หรือ drag-and-drop-user-images สามารถย่อให้สั้นลงเป็นสัญกรณ์ 64 ฐานเช่น a1 , a2 และอื่น ๆ สำหรับสภาพแวดล้อมการผลิต ) คุณลักษณะนี้ช่วยให้เปลี่ยนชื่อโมดูลในการตอบกลับจาก API ได้บ่อยๆ ด้วยเหตุผลด้านความปลอดภัย
ตัวอย่างเช่น ตามค่าเริ่มต้น ชื่ออินพุตจะถูกตั้งชื่อเป็นโมดูลที่เกี่ยวข้อง จากนั้นโมดูลที่เรียกว่า username และ password ซึ่งจะแสดงผลในไคลเอนต์เป็น <input type="text" name="{input_name}"> และ <input type="password" name="{input_name}"> ตามลำดับ สามารถตั้งค่าสุ่มที่แตกต่างกันสำหรับชื่ออินพุตของพวกเขา (เช่น zwH8DSeG และ QBG7m6EF วันนี้และ c3oMLBjo และ c46oVgN6 ในวันพรุ่งนี้) ทำให้ผู้ส่งอีเมลขยะและบอทกำหนดเป้าหมายไซต์ได้ยากขึ้น
ความเก่งกาจผ่านโมเดลทางเลือก
การซ้อนโมดูลช่วยให้สามารถแยกสาขาออกไปยังโมดูลอื่นเพื่อเพิ่มความเข้ากันได้สำหรับสื่อหรือเทคโนโลยีเฉพาะ หรือเปลี่ยนรูปแบบหรือการทำงานบางอย่าง แล้วกลับไปที่สาขาเดิม
ตัวอย่างเช่น สมมติว่าหน้าเว็บมีโครงสร้างดังต่อไปนี้:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" ในกรณีนี้ เราต้องการทำให้เว็บไซต์ใช้งานได้กับ AMP ด้วย อย่างไรก็ตาม โมดูล module2 , module4 และ module5 ไม่รองรับ AMP เราสามารถแยกโมดูลเหล่านี้ออกเป็นโมดูลที่เข้ากันได้กับ AMP module2AMP , module4AMP และ module5AMP ที่คล้ายคลึงกัน หลังจากนั้นเราจะโหลดลำดับชั้นของส่วนประกอบดั้งเดิม ดังนั้นจึงมีเพียงสามโมดูลเท่านั้นที่ถูกแทนที่ (และไม่มีอะไรอื่น):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"สิ่งนี้ทำให้ค่อนข้างง่ายที่จะสร้างผลลัพธ์ที่แตกต่างจากฐานรหัสเดียว เพิ่มส้อมที่นี่และที่นั่นตามความจำเป็น และกำหนดขอบเขตและจำกัดไว้ในแต่ละโมดูลเสมอ
เวลาสาธิต
โค้ดที่ใช้ API ตามที่อธิบายไว้ในบทความนี้มีอยู่ในที่เก็บโอเพนซอร์สนี้
ฉันได้ปรับใช้ PoP API ภายใต้ https://nextapi.getpop.org เพื่อวัตถุประสงค์ในการสาธิต เว็บไซต์ทำงานบน WordPress ดังนั้น ลิงก์ถาวรของ URL จึงเป็นเรื่องปกติสำหรับ WordPress ดังที่ได้กล่าวไว้ก่อนหน้านี้ โดยการเพิ่มพารามิเตอร์ output=json เข้าไป URL เหล่านี้จะกลายเป็นจุดปลาย API ของตัวเอง
ไซต์ได้รับการสนับสนุนโดยฐานข้อมูลเดียวกันจากเว็บไซต์ PoP Demo ดังนั้นการแสดงภาพลำดับชั้นของส่วนประกอบและข้อมูลที่ดึงมาสามารถทำได้โดยการสืบค้น URL เดียวกันในเว็บไซต์อื่นนี้ (เช่น ไปที่ https://demo.getpop.org/u/leo/ อธิบายข้อมูลจาก https://nextapi.getpop.org/u/leo/?output=json )
ลิงก์ด้านล่างแสดง API สำหรับกรณีต่างๆ ที่อธิบายไว้ก่อนหน้านี้ใน:
- หน้าแรก โพสต์เดียว ผู้เขียน รายชื่อโพสต์ และรายชื่อผู้ใช้
- เหตุการณ์ การกรองจากโมดูลเฉพาะ
- แท็ก โมดูลการกรองที่ต้องการสถานะผู้ใช้และการกรองเพื่อดึงเฉพาะหน้าจากแอปพลิเคชันหน้าเดียว
- อาร์เรย์ของสถานที่เพื่อป้อนลงในพิมพ์ล่วงหน้า
- โมเดลทางเลือกสำหรับหน้า “เราเป็นใคร”: Normal, Printable, Embeddable
- การเปลี่ยนชื่อโมดูล: ต้นฉบับเทียบกับ mangled
- ข้อมูลการกรอง: เฉพาะการตั้งค่าโมดูล ข้อมูลโมดูล และข้อมูลฐานข้อมูล
บทสรุป
API ที่ดีคือก้าวสำคัญสำหรับการสร้างแอปพลิเคชันที่น่าเชื่อถือ บำรุงรักษาง่าย และมีประสิทธิภาพ ในบทความนี้ ฉันได้อธิบายแนวคิดที่ขับเคลื่อน API แบบอิงส่วนประกอบ ซึ่งฉันเชื่อว่าเป็น API ที่ดีทีเดียว และฉันก็หวังว่าคุณจะเชื่อเช่นกัน
จนถึงตอนนี้ การออกแบบและการใช้งาน API นั้นมีการทำซ้ำหลายครั้งและใช้เวลานานกว่าห้าปี และยังไม่พร้อมอย่างสมบูรณ์ อย่างไรก็ตาม มันอยู่ในสภาพที่ค่อนข้างดี ไม่พร้อมสำหรับการผลิต แต่เป็นอัลฟ่าที่เสถียร วันนี้ฉันยังคงทำงานอยู่ ทำงานเกี่ยวกับการกำหนดข้อกำหนดเปิด การใช้เลเยอร์เพิ่มเติม (เช่น การเรนเดอร์) และการเขียนเอกสารประกอบ
ในบทความต่อๆ ไป ฉันจะอธิบายวิธีการใช้งาน API ของฉัน ถึงเวลานั้น หากคุณมีความคิดใดๆ เกี่ยวกับเรื่องนี้ ไม่ว่าจะเชิงบวกหรือเชิงลบ ฉันชอบที่จะอ่านความคิดเห็นของคุณด้านล่าง
อัปเดต (31 ม.ค.): ความสามารถในการสืบค้นแบบกำหนดเอง
Alain Schlesser ให้ความเห็นว่า API ที่ลูกค้าไม่สามารถสอบถามเองได้นั้นไร้ค่า ทำให้เรากลับไปใช้ SOAP ได้ เนื่องจากไม่สามารถแข่งขันกับ REST หรือ GraphQL ได้ หลังจากที่ให้ความคิดเห็นของเขาอยู่สองสามวันแล้ว ผมต้องยอมรับว่าเขาพูดถูก อย่างไรก็ตาม แทนที่จะละทิ้ง API แบบอิงคอมโพเนนต์เนื่องจากเป็นความพยายามที่มีเจตนาดีแต่ยังไม่ค่อนข้างดี ฉันทำสิ่งที่ดีกว่ามาก: ฉันต้องใช้ความสามารถในการค้นหาแบบกำหนดเองสำหรับมัน และมันก็ใช้งานได้เหมือนมีเสน่ห์!
ในลิงก์ต่อไปนี้ ข้อมูลสำหรับทรัพยากรหรือคอลเลกชั่นของทรัพยากรจะถูกดึงออกมาตามปกติผ่าน REST อย่างไรก็ตาม ผ่าน fields พารามิเตอร์ เรายังสามารถระบุข้อมูลเฉพาะที่จะดึงสำหรับแต่ละทรัพยากร หลีกเลี่ยงข้อมูลที่มากเกินไปหรือน้อยเกินไป:
- โพสต์เดียวและคอลเลกชันของโพสต์ที่เพิ่มพารามิเตอร์
fields=title,content,datetime - ผู้ใช้และกลุ่มผู้ใช้ที่เพิ่มพารามิเตอร์
fields=name,username,description
ลิงก์ด้านบนแสดงการดึงข้อมูลสำหรับทรัพยากรที่สืบค้นเท่านั้น แล้วความสัมพันธ์ของพวกเขาล่ะ? ตัวอย่างเช่น สมมติว่าเราต้องการดึงรายการโพสต์ที่มีฟิลด์ "title" และ "content" ความคิดเห็นของแต่ละโพสต์โดยระบุฟิลด์ "content" และ "date" และผู้เขียนความคิดเห็นแต่ละรายการด้วยฟิลด์ "name" และ "url" . เพื่อให้บรรลุสิ่งนี้ใน GraphQL เราจะใช้แบบสอบถามต่อไปนี้:
query { post { title content comments { content date author { name url } } } } สำหรับการใช้งาน API แบบอิงองค์ประกอบ ฉันได้แปลข้อความค้นหาเป็นนิพจน์ "รูปแบบจุด" ที่สอดคล้องกัน ซึ่งสามารถระบุได้ผ่าน fields พารามิเตอร์ สอบถามทรัพยากร "โพสต์" ค่านี้คือ:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url หรือทำให้ง่ายขึ้นโดยใช้ | เพื่อจัดกลุ่มฟิลด์ทั้งหมดที่ใช้กับทรัพยากรเดียวกัน:
fields=title|content,comments.content|date,comments.author.name|urlเมื่อดำเนินการค้นหานี้ในโพสต์เดียว เราได้รับข้อมูลที่จำเป็นสำหรับทรัพยากรที่เกี่ยวข้องทั้งหมด:
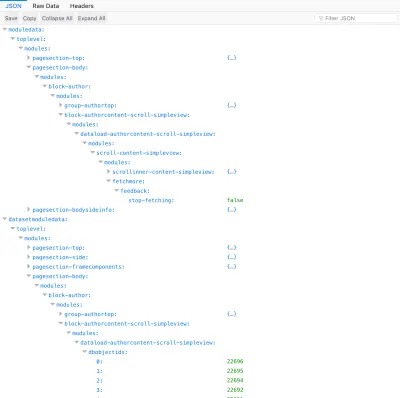
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } ดังนั้นเราจึงสามารถสืบค้นทรัพยากรในรูปแบบ REST และระบุการสืบค้นตามสคีมาในรูปแบบ GraphQL และเราจะได้รับสิ่งที่จำเป็นอย่างแท้จริง โดยไม่ต้องดึงข้อมูลมากเกินไปหรือน้อยเกินไป และทำให้ข้อมูลในฐานข้อมูลเป็นมาตรฐานเพื่อไม่ให้มีข้อมูลซ้ำกัน ในทางที่ดี คิวรีสามารถรวมความสัมพันธ์จำนวนเท่าใดก็ได้ ซึ่งฝังลึกลงไป และสิ่งเหล่านี้ได้รับการแก้ไขด้วยเวลาความซับซ้อนเชิงเส้น: กรณีที่เลวร้ายที่สุดของ O(n+m) โดยที่ n คือจำนวนโหนดที่สลับโดเมน (ในกรณีนี้ 2: comments และ comments.author ผู้เขียน ) และ m คือจำนวนผลลัพธ์ที่ได้รับ (ในกรณีนี้ 5: 1 โพสต์ + 2 ความคิดเห็น + 2 ผู้ใช้) และกรณีเฉลี่ยของ O(n) (ซึ่งมีประสิทธิภาพมากกว่า GraphQL ซึ่งมีเวลาความซับซ้อนของพหุนาม O(n^c) และได้รับผลกระทบจากเวลาดำเนินการที่เพิ่มขึ้นเมื่อระดับความลึกเพิ่มขึ้น)
สุดท้าย API นี้ยังสามารถใช้ตัวแก้ไขเมื่อทำการสืบค้นข้อมูลได้ เช่น สำหรับการกรองว่าทรัพยากรใดบ้างที่ดึงออกมา เช่น สามารถทำได้ผ่าน GraphQL เพื่อให้บรรลุสิ่งนี้ API จะอยู่ด้านบนของแอปพลิเคชันและสามารถใช้ฟังก์ชันการทำงานได้อย่างสะดวก ดังนั้นจึงไม่จำเป็นต้องสร้างวงล้อใหม่ ตัวอย่างเช่น การเพิ่มพารามิเตอร์ filter=posts&searchfor=internet จะกรองโพสต์ทั้งหมดที่มี "internet" จากคอลเล็กชันของโพสต์
การใช้งานคุณลักษณะใหม่นี้จะอธิบายไว้ในบทความต่อไป