
การแปลงรูปภาพเป็นข้อความด้วย React และ Tesseract.js (OCR)
เผยแพร่แล้ว: 2022-03-10ข้อมูลเป็นแกนหลักของซอฟต์แวร์ทุกแอปพลิเคชัน เนื่องจากวัตถุประสงค์หลักของแอปพลิเคชันคือเพื่อแก้ปัญหาของมนุษย์ เพื่อแก้ปัญหาของมนุษย์ จำเป็นต้องมีข้อมูลบางอย่างเกี่ยวกับปัญหาเหล่านั้น
ข้อมูลดังกล่าวแสดงเป็นข้อมูล โดยเฉพาะอย่างยิ่งผ่านการคำนวณ บนเว็บ ข้อมูลส่วนใหญ่จะถูกเก็บรวบรวมในรูปแบบของข้อความ รูปภาพ วิดีโอ และอื่นๆ อีกมากมาย บางครั้ง รูปภาพอาจมีข้อความสำคัญที่ต้องประมวลผลเพื่อให้บรรลุวัตถุประสงค์บางอย่าง รูปภาพเหล่านี้ส่วนใหญ่ประมวลผลด้วยตนเองเนื่องจากไม่มีวิธีประมวลผลโดยทางโปรแกรม
การไม่สามารถดึงข้อความออกจากรูปภาพเป็นข้อจำกัดในการประมวลผลข้อมูลที่ฉันพบโดยตรงที่บริษัทสุดท้ายของฉัน เราจำเป็นต้องดำเนินการกับบัตรของขวัญที่สแกนและ เราต้องทำด้วยตนเอง เนื่องจากเราไม่สามารถแยกข้อความออกจากรูปภาพได้
มีแผนกที่เรียกว่า "ปฏิบัติการ" ภายในบริษัทซึ่งรับผิดชอบในการยืนยันบัตรของขวัญและให้เครดิตบัญชีของผู้ใช้ด้วยตนเอง แม้ว่าเราจะมีเว็บไซต์ที่ผู้ใช้เชื่อมต่อกับเรา แต่การประมวลผลบัตรของขวัญได้ดำเนินการด้วยตนเองเบื้องหลัง
ในขณะนั้น เว็บไซต์ของเราสร้างขึ้นด้วย PHP (Laravel) เป็นหลักสำหรับแบ็กเอนด์และ JavaScript (jQuery และ Vue) สำหรับส่วนหน้า สแตกทางเทคนิคของเราดีพอที่จะทำงานกับ Tesseract.js หากว่าปัญหานั้นถือว่าสำคัญโดยฝ่ายบริหาร
ฉันยินดีที่จะแก้ปัญหา แต่ไม่จำเป็นต้องแก้ปัญหาโดยตัดสินจากมุมมองของธุรกิจหรือผู้บริหาร หลังจากออกจากบริษัท ฉันตัดสินใจค้นคว้า และพยายามหาทางแก้ไขที่เป็นไปได้ ในที่สุดฉันก็ค้นพบ OCR
OCR คืออะไร?
OCR ย่อมาจาก "Optical Character Recognition" หรือ "Optical Character Reader" ใช้สำหรับดึงข้อความจากรูปภาพ
วิวัฒนาการของ OCR สามารถโยงไปถึงการประดิษฐ์หลายอย่าง แต่ Optophone, “Gismo” , CCD flatbed scanner, Newton MesssagePad และ Tesseract เป็นสิ่งประดิษฐ์สำคัญที่ยกระดับการจดจำตัวละครไปสู่อีกระดับของประโยชน์
เหตุใดจึงต้องใช้ OCR การรู้จำอักขระด้วยแสงช่วยแก้ปัญหาได้มากมาย ซึ่งหนึ่งในนั้นกระตุ้นให้ฉันเขียนบทความนี้ ฉันตระหนักว่าความสามารถในการดึงข้อความจากรูปภาพทำให้มั่นใจได้ถึงความเป็นไปได้มากมาย เช่น:
- ระเบียบข้อบังคับ
ทุกองค์กรจำเป็นต้องควบคุมกิจกรรมของผู้ใช้ด้วยเหตุผลบางประการ ข้อบังคับนี้อาจใช้เพื่อปกป้องสิทธิ์ของผู้ใช้และรักษาความปลอดภัยจากภัยคุกคามหรือการหลอกลวง
การแยกข้อความออกจากรูปภาพทำให้องค์กรสามารถประมวลผลข้อมูลที่เป็นข้อความบนรูปภาพเพื่อควบคุม โดยเฉพาะอย่างยิ่งเมื่อผู้ใช้บางคนให้รูปภาพ
ตัวอย่างเช่น การควบคุมจำนวนข้อความบนรูปภาพที่ใช้สำหรับโฆษณาแบบ Facebook สามารถทำได้ด้วย OCR นอกจากนี้ OCR ยังทำให้การซ่อนเนื้อหาที่ละเอียดอ่อนบน Twitter เป็นไปได้ด้วย - ความสามารถในการค้นหา
การค้นหาเป็นหนึ่งในกิจกรรมที่พบบ่อยที่สุด โดยเฉพาะบนอินเทอร์เน็ต การค้นหาอัลกอริธึมส่วนใหญ่ขึ้นอยู่กับการจัดการข้อความ ด้วยการรู้จำอักขระด้วยแสง ทำให้สามารถจดจำอักขระบนรูปภาพ และใช้อักขระเหล่านี้เพื่อให้ผลลัพธ์ของรูปภาพที่เกี่ยวข้องแก่ผู้ใช้ได้ กล่าวโดยย่อ ขณะนี้สามารถค้นหารูปภาพและวิดีโอได้ด้วยความช่วยเหลือของ OCR - การช่วยสำหรับการเข้าถึง
การมีข้อความบนรูปภาพเป็นสิ่งที่ท้าทายสำหรับการเข้าถึงได้เสมอ และกฎง่ายๆ ก็คือการมีข้อความสองสามข้อความบนรูปภาพ ด้วย OCR โปรแกรมอ่านหน้าจอสามารถเข้าถึงข้อความบนรูปภาพเพื่อมอบประสบการณ์ที่จำเป็นแก่ผู้ใช้ - การประมวลผลข้อมูลอัตโนมัติ การประมวลผลข้อมูลส่วนใหญ่เป็นแบบอัตโนมัติสำหรับขนาด การมีข้อความบนรูปภาพเป็นข้อจำกัดในการประมวลผลข้อมูล เนื่องจากไม่สามารถประมวลผลข้อความได้ ยกเว้นด้วยตนเอง การรู้จำอักขระด้วยแสง (OCR) ทำให้สามารถแยกข้อความบนรูปภาพโดยใช้โปรแกรมได้ ซึ่งจะทำให้การประมวลผลข้อมูลเป็นไปอย่างอัตโนมัติ โดยเฉพาะอย่างยิ่งเมื่อต้องดำเนินการกับการประมวลผลข้อความบนรูปภาพ
- การแปลงเป็นดิจิทัลของสื่อสิ่งพิมพ์
ทุกอย่างกำลังเข้าสู่ยุคดิจิทัล และยังมีเอกสารอีกมากที่ต้องแปลงเป็นดิจิทัล ขณะนี้ เช็ค ใบรับรอง และเอกสารทางกายภาพอื่นๆ สามารถแปลงเป็นดิจิทัลด้วยการใช้การรู้จำอักขระด้วยแสง
การค้นหาการใช้งานทั้งหมดข้างต้นทำให้ฉันสนใจมากขึ้น ดังนั้นฉันจึงตัดสินใจทำต่อไปโดยถามคำถาม:
“ฉันจะใช้ OCR บนเว็บได้อย่างไร โดยเฉพาะในแอปพลิเคชัน React”
คำถามนั้นทำให้ฉันไปที่ Tesseract.js
Tesseract.js คืออะไร?
Tesseract.js เป็นไลบรารี JavaScript ที่รวบรวม Tesseract ดั้งเดิมจาก C ถึง JavaScript WebAssembly ทำให้ OCR สามารถเข้าถึงได้ในเบราว์เซอร์ เดิมทีเอ็นจิน Tesseract.js เขียนด้วย ASM.js และต่อมาถูกย้ายไปยัง WebAssembly แต่ ASM.js ยังคงทำหน้าที่เป็นตัวสำรองในบางกรณีเมื่อ WebAssembly ไม่รองรับ
ตามที่ระบุไว้ในเว็บไซต์ของ Tesseract.js รองรับมากกว่า 100 ภาษา การวางแนวข้อความอัตโนมัติและการตรวจจับสคริปต์ อินเทอร์เฟซที่เรียบง่ายสำหรับการอ่านย่อหน้า คำ และกล่องขอบเขตอักขระ
Tesseract เป็นเอ็นจิ้นการรู้จำอักขระด้วยแสงสำหรับระบบปฏิบัติการต่างๆ เป็นซอฟต์แวร์ฟรีที่เผยแพร่ภายใต้ Apache Licence Hewlett-Packard พัฒนา Tesseract เป็นซอฟต์แวร์ที่เป็นกรรมสิทธิ์ในทศวรรษ 1980 เปิดตัวเป็นโอเพ่นซอร์สในปี 2548 และการพัฒนาได้รับการสนับสนุนจาก Google ตั้งแต่ปี 2549
Tesseract เวอร์ชันล่าสุดเวอร์ชัน 4 ได้รับการเผยแพร่ในเดือนตุลาคม 2018 และมีเอ็นจิ้น OCR ใหม่ที่ใช้ ระบบเครือข่ายประสาทเทียมตาม Long Short-Term Memory (LSTM) และมีจุดมุ่งหมายเพื่อสร้างผลลัพธ์ที่แม่นยำยิ่งขึ้น
ทำความเข้าใจ Tesseract APIs
เพื่อให้เข้าใจถึงวิธีการทำงานของ Tesseract อย่างแท้จริง เราจำเป็นต้องแยกย่อย API และส่วนประกอบบางส่วน ตามเอกสาร Tesseract.js มีวิธีการใช้งานสองวิธี ด้านล่างนี้เป็นแนวทางแรกในการแยกย่อย:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } วิธีการ recognize จะใช้รูปภาพเป็นอาร์กิวเมนต์แรก ภาษา (ซึ่งสามารถมีหลายค่าได้) เป็นอาร์กิวเมนต์ที่สอง และ { logger: m => console.log(me) } เป็นอาร์กิวเมนต์สุดท้าย รูปแบบรูปภาพที่ Tesseract รองรับคือ jpg, png, bmp และ pbm ซึ่งจัดหาได้เฉพาะในรูปแบบองค์ประกอบ (img, วิดีโอหรือแคนวาส), วัตถุไฟล์ ( <input> ), วัตถุหยด, เส้นทางหรือ URL ไปยังรูปภาพและภาพที่เข้ารหัส base64 . (อ่านที่นี่สำหรับข้อมูลเพิ่มเติมเกี่ยวกับรูปแบบรูปภาพทั้งหมดที่ Tesseract สามารถจัดการได้)
ภาษาถูกจัดให้เป็นสตริงเช่น eng เครื่องหมาย + สามารถใช้เพื่อเชื่อมหลายภาษาเช่นใน eng+chi_tra อาร์กิวเมนต์ภาษาใช้เพื่อกำหนดข้อมูลภาษาที่ผ่านการฝึกอบรมเพื่อใช้ในการประมวลผลภาพ
หมายเหตุ : คุณจะพบภาษาที่ใช้ได้ทั้งหมดและรหัสที่นี่
{ logger: m => console.log(m) } มีประโยชน์มากในการรับข้อมูลเกี่ยวกับความคืบหน้าของภาพที่กำลังประมวลผล คุณสมบัติ logger ใช้ฟังก์ชันที่จะถูกเรียกหลายครั้งเนื่องจาก Tesseract ประมวลผลรูปภาพ พารามิเตอร์ของฟังก์ชัน logger ควรเป็นอ็อบเจ็กต์ที่มี workerId , jobId , status และ progress เป็นคุณสมบัติ:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress คือตัวเลขระหว่าง 0 ถึง 1 และเป็นเปอร์เซ็นต์ที่จะแสดงความคืบหน้าของกระบวนการรับรู้ภาพ
Tesseract จะสร้างอ็อบเจ็กต์โดยอัตโนมัติเป็นพารามิเตอร์สำหรับฟังก์ชัน logger แต่สามารถจัดหาด้วยตนเองได้เช่นกัน เนื่องจากกระบวนการรับรู้กำลังเกิดขึ้น คุณสมบัติอ็อบเจ็กต์ logger จะได้ รับการอัปเดตทุกครั้งที่มีการเรียกใช้ฟังก์ชัน ดังนั้นจึงสามารถใช้เพื่อแสดงแถบความคืบหน้าของการแปลง แก้ไขบางส่วนของแอปพลิเคชัน หรือใช้เพื่อให้ได้ผลลัพธ์ที่ต้องการ
result ในโค้ดด้านบนเป็นผลจากกระบวนการจดจำภาพ คุณสมบัติของ result แต่ละรายการมีคุณสมบัติ bbox เป็นพิกัด x/y ของกล่องขอบเขต
นี่คือคุณสมบัติของวัตถุ result ความหมายหรือการใช้งาน:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: ข้อความที่รู้จักทั้งหมดเป็นสตริง -
lines: อาร์เรย์ของทุกบรรทัดที่รู้จักทีละบรรทัดของข้อความ -
words: อาร์เรย์ของทุกคำที่รู้จัก -
symbols: อาร์เรย์ของอักขระแต่ละตัวที่รู้จัก -
paragraphs: อาร์เรย์ของทุกย่อหน้าที่รู้จัก เราจะพูดถึง "ความมั่นใจ" ในภายหลังในบทความนี้
Tesseract ยังสามารถนำมาใช้โดยไม่จำเป็นเช่นใน:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();แนวทางนี้เกี่ยวข้องกับแนวทางแรกแต่มีการนำไปปฏิบัติต่างกัน
createWorker(options) สร้าง web worker หรือ node child process ที่สร้าง Tesseract worker พนักงานช่วยตั้งค่าเอ็นจิ้น Tesseract OCR วิธีการ load() จะโหลด Tesseract core-scripts, loadLanguage() จะโหลดภาษาใดๆ ก็ตามที่จัดให้เป็นสตริง, initialize() ทำให้แน่ใจว่า Tesseract พร้อมใช้งานอย่างสมบูรณ์แล้วจึงใช้วิธีการจดจำเพื่อประมวลผลภาพที่ให้มา ยกเลิก() วิธีการหยุดคนงานและล้างทุกอย่าง
หมายเหตุ : โปรดตรวจสอบเอกสาร Tesseract APIs สำหรับข้อมูลเพิ่มเติม
ตอนนี้ เราต้องสร้างบางสิ่งเพื่อดูว่า Tesseract.js มีประสิทธิภาพเพียงใด
เรากำลังจะสร้างอะไร?
เรากำลังจะสร้างตัวแยก PIN ของบัตรของขวัญเพราะการแยก PIN ออกจากบัตรของขวัญเป็นปัญหาที่นำไปสู่การผจญภัยในการเขียนตั้งแต่แรก
เราจะสร้าง แอปพลิเคชันง่ายๆ ที่ดึง PIN ออกจากบัตรของขวัญที่สแกน เมื่อฉันเริ่มสร้างเครื่องแยกรหัสบัตรของขวัญแบบง่ายๆ ฉันจะแนะนำคุณเกี่ยวกับความท้าทายบางอย่างที่ฉันเผชิญ วิธีแก้ปัญหาที่ฉันให้ไว้ และข้อสรุปตามประสบการณ์ของฉัน
- ไปที่ซอร์สโค้ด →
ด้านล่างนี้คือรูปภาพที่เราจะใช้ในการทดสอบ เพราะมันมีคุณสมบัติที่เหมือนจริงบางอย่างที่เป็นไปได้ในโลกแห่งความเป็นจริง

เราจะแยก AQUX-QWMB6L-R6JAU ออกจากการ์ด มาเริ่มกันเลยดีกว่า
การติดตั้ง React และ Tesseract
มีคำถามที่ต้องดูแลก่อนติดตั้ง React และ Tesseract.js และคำถามคือ ทำไมต้องใช้ React กับ Tesseract ในทางปฏิบัติ เราสามารถใช้ Tesseract กับ Vanilla JavaScript, ไลบรารี JavaScript หรือเฟรมเวิร์กใดๆ เช่น React, Vue และ Angular
การใช้ React ในกรณีนี้เป็นความชอบส่วนบุคคล ตอนแรกฉันต้องการใช้ Vue แต่ฉันตัดสินใจใช้ React เพราะฉันคุ้นเคยกับ React มากกว่า Vue
ตอนนี้ ดำเนินการติดตั้งต่อ
ในการติดตั้ง React ด้วย create-react-app คุณต้องเรียกใช้โค้ดด้านล่าง:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsหรือ
npm install tesseract.jsฉันตัดสินใจเลือกใช้ไหมพรมเพื่อติดตั้ง Tesseract.js เพราะฉันไม่สามารถติดตั้ง Tesseract ด้วย npm ได้ แต่เส้นด้ายก็ทำงานให้เสร็จโดยปราศจากความเครียด คุณสามารถใช้ npm ได้ แต่ฉันแนะนำให้ติดตั้ง Tesseract ด้วยการตัดสินเส้นด้ายจากประสบการณ์ของฉัน
ตอนนี้ มาเริ่มเซิร์ฟเวอร์การพัฒนาของเราโดยเรียกใช้โค้ดด้านล่าง:
yarn startหรือ
npm startหลังจากรัน yarn start หรือ npm start เบราว์เซอร์เริ่มต้นของคุณควรเปิดหน้าเว็บที่มีลักษณะดังนี้:

คุณยังสามารถนำทางไปยัง localhost:3000 ในเบราว์เซอร์ได้ โดยที่หน้าจะไม่เปิดขึ้นโดยอัตโนมัติ
หลังจากติดตั้ง React และ Tesseract.js แล้ว อะไรต่อไป?
การตั้งค่าแบบฟอร์มอัพโหลด
ในกรณีนี้ เราจะปรับหน้าแรก (App.js) ที่เราเพิ่งดูในเบราว์เซอร์ให้มีรูปแบบที่เราต้องการ:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App ส่วนของโค้ดด้านบนที่ต้องการความสนใจจากเราในตอนนี้คือฟังก์ชัน handleChange
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } ในฟังก์ชัน URL.createObjectURL จะนำไฟล์ที่เลือกผ่าน event.target.files[0] และสร้าง URL อ้างอิงที่สามารถใช้กับแท็ก HTML เช่น img เสียง และวิดีโอ เราใช้ setImagePath เพื่อเพิ่ม URL ไปยังสถานะ ขณะนี้ สามารถเข้าถึง URL ได้ด้วย imagePath
<img src={imagePath} className="App-logo" alt="image"/> เราตั้งค่าแอตทริบิวต์ src ของรูปภาพเป็น {imagePath} เพื่อดูตัวอย่างในเบราว์เซอร์ก่อนดำเนินการ
การแปลงรูปภาพที่เลือกเป็นข้อความ
ขณะที่เราจับเส้นทางไปยังรูปภาพที่เลือก เราสามารถส่งพาธของรูปภาพไปยัง Tesseract.js เพื่อดึงข้อความออกจากรูปภาพได้
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default Appเราเพิ่มฟังก์ชัน "handleClick" ไปที่ "App.js และมี Tesseract.js API ที่ใช้พา ธ ไปยังรูปภาพที่เลือก Tesseract.js ใช้ "imagePath", "language", "a setting object"
ปุ่มด้านล่างถูกเพิ่มลงในแบบฟอร์มเพื่อเรียก "handClick" ซึ่งจะทริกเกอร์การแปลงรูปภาพเป็นข้อความทุกครั้งที่มีการคลิกปุ่ม
<button onClick={handleClick} style={{height:50}}> convert to text</button>เมื่อการประมวลผลสำเร็จ เราจะเข้าถึงทั้ง "ความมั่นใจ" และ "ข้อความ" จากผลลัพธ์ จากนั้น เราเพิ่ม "ข้อความ" ลงในสถานะด้วย "setText (ข้อความ)"
โดยการเพิ่ม <p> {text} </p> เราจะแสดงข้อความที่แยกออกมา
เห็นได้ชัดว่า "ข้อความ" ถูกดึงออกจากภาพ แต่ความมั่นใจคืออะไร?
ความมั่นใจแสดงให้เห็นว่าการแปลงนั้นแม่นยำเพียงใด ระดับความเชื่อมั่นอยู่ระหว่าง 1 ถึง 100 1 หมายถึงแย่ที่สุดในขณะที่ 100 หมายถึงดีที่สุดในแง่ของความแม่นยำ นอกจากนี้ยังสามารถใช้เพื่อกำหนดว่าข้อความที่แยกออกมาควรได้รับการยอมรับว่าถูกต้องหรือไม่
แล้วคำถามคือปัจจัยใดบ้างที่ส่งผลต่อคะแนนความเชื่อมั่นหรือความถูกต้องของการแปลงทั้งหมด ส่วนใหญ่ได้รับผลกระทบจากปัจจัยหลักสามประการ ได้แก่ คุณภาพและลักษณะของเอกสารที่ใช้ คุณภาพของการสแกนที่สร้างจากเอกสาร และความสามารถในการประมวลผลของกลไก Tesseract
ตอนนี้ มาเพิ่มโค้ดด้านล่างไปที่ “App.css” เพื่อกำหนดสไตล์ของแอปพลิเคชั่นสักหน่อย
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }นี่คือผล การทดสอบครั้งแรก ของฉัน:
ผลลัพธ์ใน Firefox
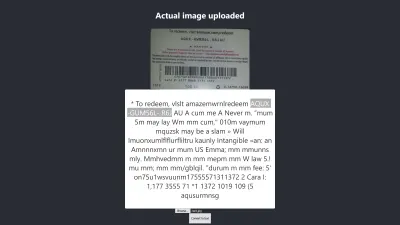
ระดับความเชื่อมั่นของผลลัพธ์ข้างต้นคือ 64 เป็นที่น่าสังเกตว่าภาพบัตรของขวัญมีสีเข้มและส่งผลต่อผลลัพธ์ที่เราได้รับอย่างแน่นอน

หากคุณดูภาพด้านบนให้ละเอียดยิ่งขึ้น คุณจะเห็นหมุดจากการ์ดเกือบจะแม่นยำในข้อความที่แยกออกมา ไม่ถูกต้องเนื่องจากบัตรของขวัญไม่ชัดเจนจริงๆ
โอ้รอ! ใน Chrome จะมีลักษณะอย่างไร
ผลลัพธ์ใน Chrome
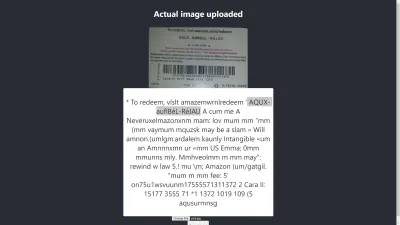
อา! ผลลัพธ์ที่ได้จะยิ่งแย่ลงไปอีกใน Chrome แต่เหตุใดผลลัพธ์ใน Chrome จึงแตกต่างจาก Mozilla Firefox เบราว์เซอร์ต่างๆ จัดการรูปภาพและโปรไฟล์สีต่างกัน นั่นหมายความว่า รูปภาพสามารถแสดงผลได้แตกต่างกันไปตามเบราว์เซอร์ การจัดหา image.data ที่แสดงผลล่วงหน้าให้กับ Tesseract นั้นมีแนวโน้มที่จะให้ผลลัพธ์ที่แตกต่างกันในเบราว์เซอร์ที่แตกต่างกัน เนื่องจาก image.data ที่แตกต่างกันนั้นถูกจัดเตรียมให้กับ Tesseract ขึ้นอยู่กับเบราว์เซอร์ที่ใช้งาน การประมวลผลภาพล่วงหน้าดังที่เราจะเห็นในบทความนี้จะช่วยให้ได้ผลลัพธ์ที่สม่ำเสมอ
เราต้องแม่นยำมากขึ้นเพื่อให้มั่นใจว่าเราได้รับหรือให้ข้อมูลที่ถูกต้อง เลยต้องไปไกลกว่านี้หน่อย
มาลองดูกันมากขึ้นเพื่อดูว่าเราจะบรรลุเป้าหมายในที่สุดหรือไม่
การทดสอบความแม่นยำ
มีหลายปัจจัยที่ส่งผลต่อการแปลงรูปภาพเป็นข้อความด้วย Tesseract.js ปัจจัยเหล่านี้ส่วนใหญ่เกี่ยวกับธรรมชาติของภาพที่เราต้องการประมวลผล และส่วนที่เหลือขึ้นอยู่กับว่ากลไก Tesseract จัดการกับการแปลงอย่างไร
ภายใน Tesseract จะประมวลผลภาพล่วงหน้าก่อนการแปลง OCR จริง แต่ไม่ได้ให้ผลลัพธ์ที่ถูกต้องเสมอไป
เพื่อเป็นการแก้ปัญหา เราสามารถประมวลผลภาพล่วงหน้าเพื่อให้ได้การแปลงที่แม่นยำ เราสามารถ binarise, invert, dilate, deskew หรือ rescale รูปภาพเพื่อประมวลผลล่วงหน้าสำหรับ Tesseract.js
การประมวลผลภาพล่วงหน้า เป็นงานที่หนักหนาสาหัสหรือเป็นพื้นที่กว้างขวางในตัวเอง โชคดีที่ P5.js ได้จัดเตรียมเทคนิคการประมวลผลภาพล่วงหน้าทั้งหมดที่เราต้องการใช้ แทนที่จะสร้างวงล้อใหม่หรือใช้ห้องสมุดทั้งหมดเพียงเพราะเราต้องการใช้ส่วนเล็กๆ ของวงล้อ ฉันได้คัดลอกส่วนที่เราต้องการแล้ว เทคนิคการประมวลผลภาพล่วงหน้าทั้งหมดรวมอยู่ใน preprocess.js
Binarization คืออะไร?
Binarization คือการแปลงพิกเซลของรูปภาพเป็นขาวดำ เราต้องการเปรียบเทียบบัตรของขวัญก่อนหน้านี้เพื่อตรวจสอบว่าความถูกต้องจะดีกว่าหรือไม่
ก่อนหน้านี้ เราได้ดึงข้อความบางส่วนจากบัตรของขวัญ แต่ PIN เป้าหมายไม่ถูกต้องตามที่เราต้องการ จึงต้องหาวิธีอื่นเพื่อให้ได้ผลลัพธ์ที่ถูกต้อง
ตอนนี้ เราต้องการสร้าง ไบนารีของบัตรของขวัญ นั่นคือ เราต้องการแปลงพิกเซลเป็นขาวดำ เพื่อให้เราสามารถดูว่าจะทำได้ระดับความแม่นยำที่ดีขึ้นหรือไม่
ฟังก์ชันด้านล่างจะใช้สำหรับการสร้างไบนารีและจะรวมอยู่ในไฟล์แยกต่างหากที่เรียกว่า preprocess.js
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageรหัสด้านบนทำอะไร?
เราแนะนำผืนผ้าใบเพื่อเก็บข้อมูลรูปภาพเพื่อใช้ฟิลเตอร์ เพื่อประมวลผลภาพล่วงหน้า ก่อนที่จะส่งต่อไปยัง Tesseract สำหรับการแปลง
ฟังก์ชัน preprocessImage แรกอยู่ใน preprocess.js และเตรียมแคนวาสสำหรับใช้งานโดยรับพิกเซล ฟังก์ชัน thresholdFilter จะทำการแบ่งไบนารีของรูปภาพโดย แปลงพิกเซลเป็นขาวดำ
เรามาเรียกการ preprocessImage ของ Image เพื่อดูว่าข้อความที่ดึงมาจากบัตรของขวัญก่อนหน้านั้นแม่นยำกว่าหรือไม่
เมื่อเราอัปเดต App.js ตอนนี้ควรมีลักษณะดังนี้:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default Appอันดับแรก เราต้องนำเข้า “preprocessImage” จาก “preprocess.js” ด้วยรหัสด้านล่าง:
import preprocessImage from './preprocess'; จากนั้น เราเพิ่มแท็กผ้าใบลงในแบบฟอร์ม เราตั้งค่าแอตทริบิวต์การอ้างอิงของทั้งแท็ก canvas และ img เป็น { canvasRef } และ { imageRef } ตามลำดับ ผู้อ้างอิงใช้เพื่อเข้าถึงผืนผ้าใบและรูปภาพจากองค์ประกอบแอป เราได้รับทั้งผืนผ้าใบและรูปภาพด้วย "useRef" เช่นใน:
const canvasRef = useRef(null); const imageRef = useRef(null);ในโค้ดส่วนนี้ เรารวมรูปภาพเข้ากับแคนวาส เนื่องจากเราสามารถประมวลผลแคนวาสล่วงหน้าใน JavaScript เท่านั้น จากนั้นเราจะแปลงเป็น URL ข้อมูลโดยมี "jpeg" เป็นรูปแบบรูปภาพ
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl” ถูกส่งไปยัง Tesseract เป็นภาพที่จะประมวลผล
ตอนนี้ มาดูกันว่าข้อความที่แยกออกมาจะแม่นยำกว่าหรือไม่
การทดสอบ #2

ภาพด้านบนแสดงผลใน Firefox เห็นได้ชัดว่าส่วนที่มืดของภาพเปลี่ยนเป็นสีขาวแล้ว แต่การประมวลผลภาพล่วงหน้าไม่ได้ทำให้ได้ผลลัพธ์ที่แม่นยำขึ้น มันเลวร้ายยิ่งกว่า
การแปลงครั้งแรกมีอักขระที่ ไม่ถูกต้องเพียงสองตัว แต่ตัวนี้มีอักขระที่ไม่ถูกต้อง สี่ ตัว ฉันพยายามเปลี่ยนระดับธรณีประตูแต่ก็ไม่เป็นผล เราไม่ได้ผลลัพธ์ที่ดีกว่านี้ ไม่ใช่เพราะไบนารี่ไม่ดี แต่เพราะไบนาไรซ์ภาพไม่ได้แก้ไขธรรมชาติของภาพในลักษณะที่เหมาะสมกับกลไก Tesseract
มาดูกันว่ามันมีลักษณะอย่างไรใน Chrome:

เราได้รับผลลัพธ์เดียวกัน
หลังจากที่ได้ผลลัพธ์ที่แย่ลงโดยการทำภาพไบนารี่แล้ว ก็จำเป็นต้องตรวจสอบเทคนิคการประมวลผลภาพล่วงหน้าอื่นๆ เพื่อดูว่าเราจะสามารถแก้ปัญหาได้หรือไม่ ดังนั้น เราจะลองขยาย ผกผัน และเบลอต่อไป
มารับโค้ดสำหรับแต่ละเทคนิคจาก P5.js ที่ใช้ในบทความนี้กัน เราจะเพิ่มเทคนิคการประมวลผลภาพลงใน preprocess.js และใช้ทีละรายการ จำเป็นต้องเข้าใจเทคนิคการประมวลผลภาพล่วงหน้าแต่ละอย่างที่เราต้องการใช้ก่อนใช้งาน ดังนั้นเราจะมาพูดถึงกันก่อน
การขยายคืออะไร?
การขยายคือการเพิ่มพิกเซลให้กับขอบเขตของวัตถุในภาพเพื่อให้กว้างขึ้น ใหญ่ขึ้น หรือเปิดกว้างขึ้น เทคนิค "ขยาย" ใช้ในการประมวลผลภาพล่วงหน้าเพื่อเพิ่มความสว่างของวัตถุบนภาพ เราจำเป็นต้องมีฟังก์ชันเพื่อขยายรูปภาพโดยใช้ JavaScript ดังนั้นข้อมูลโค้ดสำหรับขยายรูปภาพจึงถูกเพิ่มลงใน preprocess.js
เบลอคืออะไร?
การเบลอจะทำให้สีของภาพมีความเรียบเนียนโดยการลดความคมชัดลง บางครั้ง รูปภาพอาจมีจุด/แพทช์เล็กๆ หากต้องการลบแพทช์ เราสามารถเบลอภาพได้ ข้อมูลโค้ดสำหรับเบลอรูปภาพรวมอยู่ใน preprocess.js
การผกผันคืออะไร?
การผกผันกำลังเปลี่ยนพื้นที่แสงของภาพเป็นสีเข้ม และบริเวณที่มืดเป็นสีอ่อน ตัวอย่างเช่น หากรูปภาพมีพื้นหลังสีดำและพื้นหน้าสีขาว เราสามารถกลับภาพเพื่อให้พื้นหลังเป็นสีขาวและพื้นหน้าจะเป็นสีดำ เรายังได้เพิ่มข้อมูลโค้ดเพื่อแปลงรูปภาพเป็น preprocess.js
หลังจากเพิ่ม dilate , invertColors และ blurARGB ไปที่ “preprocess.js” แล้ว เราก็สามารถใช้พวกมันเพื่อประมวลผลภาพล่วงหน้าได้แล้ว ในการใช้งาน เราจำเป็นต้องอัปเดตฟังก์ชัน "preprocessImage" เริ่มต้นใน preprocess.js:
preprocessImage(...) ตอนนี้มีลักษณะดังนี้:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } ใน preprocessImage ด้านบน เราใช้เทคนิคการประมวลผลล่วงหน้าสี่แบบกับรูปภาพ: blurARGB() เพื่อลบจุดบนรูปภาพ dilate() เพื่อเพิ่มความสว่างของรูปภาพ invertColors() เพื่อเปลี่ยนสีพื้นหน้าและพื้นหลังของรูปภาพและ thresholdFilter() เพื่อแปลงภาพเป็นขาวดำซึ่งเหมาะสำหรับการแปลง Tesseract มากกว่า
thresholdFilter() ใช้ image.data และ level เป็นพารามิเตอร์ level ใช้เพื่อกำหนดว่าภาพควรเป็นสีขาวหรือดำ เรากำหนดระดับ thresholdFilter และ blurRGB รัศมีโดยการลองผิดลองถูก เนื่องจากเราไม่แน่ใจว่าภาพควรเป็นสีขาว มืด หรือเรียบเพียงใดเพื่อให้ Tesseract ได้ผลลัพธ์ที่ยอดเยี่ยม
ทดสอบ #3
นี่คือผลลัพธ์ใหม่หลังจากใช้สี่เทคนิค:

ภาพด้านบนแสดงผลลัพธ์ที่เราได้รับทั้งใน Chrome และ Firefox
อ๊ะ! ผลที่ได้คือแย่มาก
แทนที่จะใช้ทั้งสี่เทคนิค ทำไมเราไม่ใช้แค่สองอย่างพร้อมกันล่ะ?
ใช่! เราสามารถใช้เทคนิค invertColors และ thresholdFilter เพื่อแปลงรูปภาพเป็นขาวดำ และสลับพื้นหน้าและพื้นหลังของรูปภาพ แต่ เราจะรู้ได้อย่างไรว่าต้องรวมเทคนิคอะไรและอะไร? เรารู้ว่าจะรวมอะไรโดยพิจารณาจากลักษณะของภาพที่เราต้องการประมวลผลล่วงหน้า
ตัวอย่างเช่น ต้องแปลงรูปภาพดิจิทัลเป็นขาวดำ และรูปภาพที่มีแพทช์ต้องเบลอเพื่อลบจุด/แพตช์ สิ่งที่สำคัญจริงๆ คือต้องเข้าใจว่าแต่ละเทคนิคใช้ทำอะไร
ในการใช้ invertColors และ thresholdFilter เราจำเป็นต้องใส่ความคิดเห็นทั้ง blurARGB และ dilate ใน preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }ทดสอบ #4
นี่คือผลลัพธ์ใหม่:

ผลลัพธ์ยังคงแย่กว่าที่ไม่มีการประมวลผลล่วงหน้า หลังจากปรับเทคนิคแต่ละอย่างสำหรับรูปภาพนี้และรูปภาพอื่นแล้ว ฉันได้ข้อสรุปว่ารูปภาพที่มีลักษณะแตกต่างกันต้องใช้เทคนิคการประมวลผลล่วงหน้าที่แตกต่างกัน
กล่าวโดยย่อ การใช้ Tesseract.js โดยไม่มีการประมวลผลภาพล่วงหน้าจะให้ผลลัพธ์ที่ดีที่สุดสำหรับบัตรของขวัญด้านบน การทดลองอื่นๆ ทั้งหมดที่มีการประมวลผลภาพล่วงหน้าให้ผลลัพธ์ที่แม่นยำน้อยกว่า
ปัญหา
ในตอนแรก ฉันต้องการดึง PIN ออกจากบัตรของขวัญ Amazon แต่ทำไม่ได้เพราะไม่มีประเด็นที่จะจับคู่ PIN ที่ไม่สอดคล้องกันเพื่อให้ได้ผลลัพธ์ที่สอดคล้องกัน แม้ว่าจะสามารถประมวลผลภาพเพื่อรับ PIN ที่ถูกต้องได้ แต่การประมวลผลล่วงหน้าดังกล่าวจะไม่สอดคล้องกันเมื่อมีการใช้รูปภาพอื่นที่มีลักษณะแตกต่างกัน
ผลงานที่ดีที่สุด
ภาพด้านล่างแสดงผลลัพธ์ที่ดีที่สุดจากการทดลอง
ทดสอบ #5

ข้อความบนรูปภาพและข้อความที่แยกออกมานั้นเหมือนกันทั้งหมด การแปลงมีความแม่นยำ 100% ฉันพยายามสร้างผลลัพธ์ซ้ำ แต่ฉันสามารถทำซ้ำได้เมื่อใช้ภาพที่มีลักษณะใกล้เคียงกันเท่านั้น
การสังเกตและบทเรียน
- รูปภาพบางรูปที่ไม่ได้ประมวลผลล่วงหน้าอาจให้ ผลลัพธ์ที่แตกต่างกันในเบราว์เซอร์ที่ต่างกัน การอ้างสิทธิ์นี้ปรากฏชัดในการทดสอบครั้งแรก ผลลัพธ์ใน Firefox นั้นแตกต่างจากผลลัพธ์ใน Chrome อย่างไรก็ตาม การประมวลผลภาพล่วงหน้าช่วยให้ได้ผลลัพธ์ที่สม่ำเสมอในการทดสอบอื่นๆ
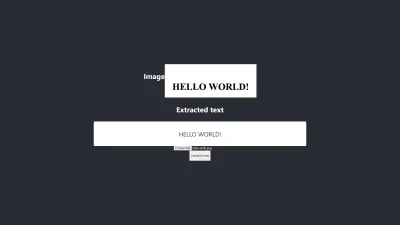
- สีดำบนพื้นหลังสีขาวมักจะให้ผลลัพธ์ที่จัดการได้ ภาพด้านล่างเป็นตัวอย่างของ ผลลัพธ์ที่แม่นยำโดยไม่ต้องประมวลผลล่วงหน้า ฉันยังได้ระดับความแม่นยำเท่าเดิมด้วยการประมวลผลภาพล่วงหน้า แต่ฉันต้องปรับหลายอย่างซึ่งไม่จำเป็น
การแปลงมีความถูกต้อง 100%
- ข้อความที่มี ขนาดตัวอักษรใหญ่ มักจะแม่นยำกว่า
- แบบอักษรที่มี ขอบโค้ง มักจะทำให้ Tesseract สับสน ผลลัพธ์ที่ดีที่สุดที่ฉันได้รับคือเมื่อใช้ Arial (แบบอักษร)
- ปัจจุบัน OCR ยังไม่ดีพอสำหรับการแปลงรูปภาพเป็นข้อความโดยอัตโนมัติ โดยเฉพาะอย่างยิ่งเมื่อต้องการระดับความแม่นยำมากกว่า 80% อย่างไรก็ตาม สามารถใช้เพื่อทำให้การประมวลผลข้อความบนรูปภาพแบบแมนนวล ลดความตึงเครียดลง ได้โดยการแยกข้อความเพื่อแก้ไขด้วยตนเอง
- ปัจจุบัน OCR ยังไม่ดีพอที่จะส่งข้อมูลที่เป็นประโยชน์ไปยังโปรแกรมอ่านหน้าจอเพื่อการช่วยสำหรับการ เข้าถึง การให้ข้อมูลที่ไม่ถูกต้องกับโปรแกรมอ่านหน้าจออาจทำให้ผู้ใช้เข้าใจผิดหรือเบี่ยงเบนความสนใจได้ง่าย
- OCR มีแนวโน้มที่ดีเนื่องจากโครงข่ายประสาทเทียมช่วยให้เรียนรู้และปรับปรุงได้ การเรียนรู้อย่างลึกซึ้งจะ ทำให้ OCR เป็นตัวเปลี่ยนเกมในอนาคตอันใกล้
- การตัดสินใจด้วยความมั่นใจ สามารถใช้คะแนนความมั่นใจในการตัดสินใจที่อาจส่งผลกระทบอย่างมากต่อแอปพลิเคชันของเรา คะแนนความเชื่อมั่นสามารถใช้เพื่อกำหนดว่าจะยอมรับหรือปฏิเสธผลลัพธ์ จากประสบการณ์และการทดสอบของฉัน ฉันตระหนักว่าคะแนนความมั่นใจที่ต่ำกว่า 90 นั้นไม่มีประโยชน์จริงๆ หากฉันต้องการแยกหมุดบางส่วนออกจากข้อความ ฉันจะคาดหวังคะแนนความเชื่อมั่นระหว่าง 75 ถึง 100 และ สิ่งใดที่ต่ำกว่า 75 จะถูกปฏิเสธ
ในกรณีที่ฉันกำลังจัดการกับข้อความโดยไม่จำเป็นต้องแยกส่วนใดส่วนหนึ่งของมัน ฉันจะยอมรับคะแนนความมั่นใจระหว่าง 90 ถึง 100 แน่นอน แต่ปฏิเสธคะแนนใด ๆ ที่ต่ำกว่านั้น ตัวอย่างเช่น คาดว่าจะมีความแม่นยำ 90 ขึ้นไป หากฉันต้องการแปลงเอกสารให้เป็นดิจิทัล เช่น เช็ค ดราฟต์ประวัติศาสตร์ หรือเมื่อใดก็ตามที่จำเป็นต้องมีสำเนาที่ถูกต้อง แต่คะแนนที่อยู่ระหว่าง 75 ถึง 90 เป็นที่ยอมรับได้เมื่อสำเนาถูกต้องไม่สำคัญ เช่น การรับ PIN จากบัตรของขวัญ กล่าวโดยสรุป คะแนนความเชื่อมั่นช่วยในการตัดสินใจ ที่ส่งผลต่อการสมัครของเรา
บทสรุป
เนื่องจากข้อจำกัดในการประมวลผลข้อมูลที่เกิดจากข้อความบนรูปภาพและข้อเสียที่เกี่ยวข้อง การรู้จำอักขระด้วยแสง (OCR) จึงเป็นเทคโนโลยีที่มีประโยชน์ที่นำมาใช้ได้ แม้ว่า OCR จะมีข้อจำกัด แต่ก็มีแนวโน้มที่ดีเนื่องจากมีการใช้โครงข่ายประสาทเทียม
เมื่อเวลาผ่านไป OCR จะเอาชนะข้อจำกัดส่วนใหญ่ด้วยความช่วยเหลือของการเรียนรู้เชิงลึก แต่ก่อนหน้านั้น แนวทางที่เน้นในบทความนี้สามารถใช้เพื่อจัดการกับการดึงข้อความจากรูปภาพ อย่างน้อย เพื่อ ลดความยากลำบากและความสูญเสียที่เกี่ยวข้องกับคู่มือ การประมวลผล — โดยเฉพาะจากมุมมองทางธุรกิจ
ตอนนี้ถึงตาคุณแล้วที่จะลองใช้ OCR เพื่อดึงข้อความจากรูปภาพ ขอให้โชคดี!
อ่านเพิ่มเติม
- P5.js
- การประมวลผลล่วงหน้าใน OCR
- การปรับปรุงคุณภาพของผลผลิต
- การใช้ JavaScript เพื่อประมวลผลภาพล่วงหน้าสำหรับ OCR
- OCR ในเบราว์เซอร์ด้วย Tesseract.js
- ประวัติโดยย่อของการรู้จำอักขระด้วยแสง
- อนาคตของ OCR คือการเรียนรู้เชิงลึก
- เส้นเวลาของการรู้จำอักขระด้วยแสง