
การจำแนกรูปภาพใน CNN: ทุกสิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2021-02-25สารบัญ
บทนำ
ขณะดูฟีด Facebook คุณเคยสงสัยหรือไม่ว่าซอฟต์แวร์ของ Facebook ติดป้ายกำกับบุคคลในภาพกลุ่มโดยอัตโนมัติหรือไม่ เบื้องหลังอินเทอร์เฟซผู้ใช้แบบโต้ตอบทุกอันของ Facebook ที่คุณเห็น มีอัลกอริธึมที่ซับซ้อนและแข็งแกร่งที่ใช้ในการจดจำและติดป้ายกำกับแต่ละรูปภาพที่เราอัปโหลดไปยังแพลตฟอร์มโซเชียลมีเดีย ทุกภาพของเรา เราช่วยในการปรับปรุงประสิทธิภาพของอัลกอริธึมเท่านั้น ใช่ การจัดประเภทรูปภาพเป็นหนึ่งในอัลกอริธึมที่ใช้กันอย่างแพร่หลายมากที่สุด ซึ่งเราเห็นการประยุกต์ใช้ปัญญาประดิษฐ์
ในช่วงไม่กี่ครั้งที่ผ่านมา Convolutional Neural Networks (CNN) ได้กลายเป็นหนึ่งในผู้สนับสนุนที่แข็งแกร่งที่สุดของ Deep Learning แอปพลิเคชั่นยอดนิยมอย่างหนึ่งของ Convolutional Networks เหล่านี้คือการจำแนกรูปภาพ ในบทช่วยสอนนี้ เราจะพูดถึงพื้นฐานของ Convolutional Neural Networks ดูเลเยอร์ต่างๆ ที่เกี่ยวข้องกับการสร้างแบบจำลอง CNN และสุดท้ายเห็นภาพตัวอย่างของงานการจำแนกรูปภาพ
การจำแนกรูปภาพ
ก่อนที่เราจะเข้าไปดูรายละเอียดของ Deep Learning และ Convolutional Neural Networks ให้เราเข้าใจพื้นฐานของการจัดประเภทรูปภาพก่อน โดยทั่วไป การจัดประเภทรูปภาพถูกกำหนดให้เป็นงานที่เราให้รูปภาพเป็นอินพุตไปยังโมเดลที่สร้างขึ้นโดยใช้อัลกอริธึมเฉพาะที่ส่งออกคลาสหรือความน่าจะเป็นของคลาสที่เป็นของรูปภาพ กระบวนการที่เราติดป้ายกำกับรูปภาพให้กับชั้นเรียนหนึ่งๆ นี้เรียกว่า Supervised Learning
มีความแตกต่างกันมากระหว่างวิธีที่เราเห็นรูปภาพกับวิธีที่เครื่อง (คอมพิวเตอร์) เห็นภาพเดียวกัน สำหรับเรา เราสามารถเห็นภาพและกำหนดลักษณะตามสีและขนาดได้ ในทางกลับกัน สำหรับเครื่อง สิ่งที่เห็นคือตัวเลข ตัวเลขที่เห็นเรียกว่าพิกเซล
แต่ละพิกเซลมีค่าระหว่าง 0 ถึง 255 ดังนั้น ด้วยข้อมูลตัวเลขเหล่านี้ เครื่องจึงต้องมีขั้นตอนก่อนการประมวลผลบางอย่างเพื่อให้ได้มาซึ่งรูปแบบหรือคุณลักษณะเฉพาะบางอย่างที่ทำให้ภาพหนึ่งแตกต่างจากอีกภาพหนึ่ง Convolutional Neural Networks ช่วยเราสร้างอัลกอริธึมที่สามารถรับรูปแบบเฉพาะจากภาพได้
สิ่งที่เราเห็น Vs สิ่งที่คอมพิวเตอร์เห็น
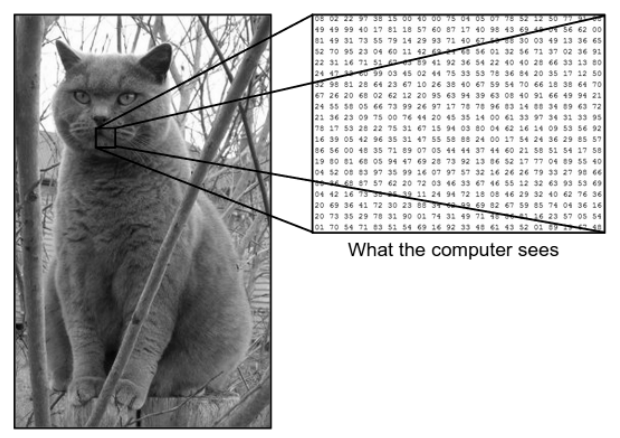 ที่มา - ความแตกต่างระหว่างคอมพิวเตอร์กับสายตามนุษย์
ที่มา - ความแตกต่างระหว่างคอมพิวเตอร์กับสายตามนุษย์

การเรียนรู้เชิงลึกสำหรับการจำแนกรูปภาพ
ตอนนี้เราเข้าใจแล้วว่า Image Classification คืออะไร มาดูกันว่าเราจะใช้ปัญญาประดิษฐ์ได้อย่างไร สำหรับสิ่งนี้ เราใช้วิธีการเรียนรู้เชิงลึกที่เป็นที่นิยม การเรียนรู้เชิงลึกเป็นส่วนย่อยของปัญญาประดิษฐ์ที่ใช้ชุดข้อมูลรูปภาพขนาดใหญ่เพื่อจดจำและรับรูปแบบจากรูปภาพต่างๆ เพื่อแยกความแตกต่างระหว่างคลาสต่างๆ ที่มีอยู่ในชุดข้อมูลรูปภาพ
ความท้าทายหลักที่ Deep Learning ต้องเผชิญคือสำหรับฐานข้อมูลขนาดใหญ่ ใช้เวลานานมากและมีค่าใช้จ่ายในการคำนวณสูง อย่างไรก็ตาม Convolutional Neural Networks ซึ่งเป็นอัลกอริธึม Deep Learning ชนิดหนึ่งสามารถแก้ปัญหานี้ได้อย่างดี
โครงข่ายประสาทเทียม
ในการเรียนรู้เชิงลึก Convolutional Neural Networks เป็นคลาสของ Deep Neural Networks ที่ส่วนใหญ่ใช้ในจินตภาพ เป็นสถาปัตยกรรมพิเศษของเครือข่ายประสาทเทียม (ANN) ซึ่งเสนอโดย Yann LeCunn ในปี 2541 Convolutional Neural Networks ประกอบด้วยสองส่วน
ส่วนแรกประกอบด้วยเลเยอร์ Convolutional และเลเยอร์ Pooling ซึ่งกระบวนการแยกคุณลักษณะหลักเกิดขึ้น ในส่วนที่สอง เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์และหนาแน่นจะทำการแปลงแบบไม่เชิงเส้นหลายอย่างบนคุณสมบัติที่แยกออกมา และทำหน้าที่เป็นส่วนลักษณนาม เรียนรู้ CNN สำหรับการจัดประเภทรูปภาพ
พิจารณาตัวอย่างภาพที่แสดงให้เห็นข้างต้นซึ่งเป็นสิ่งที่มนุษย์และเครื่องจักรมองเห็น อย่างที่เราเห็น คอมพิวเตอร์เห็นอาร์เรย์ของพิกเซล ตัวอย่างเช่น หากขนาดรูปภาพถ้า 500×500 ขนาดของอาร์เรย์จะเป็น 500x500x3 ในที่นี้ 500 หมายถึงแต่ละความสูงและความกว้าง 3 หมายถึงช่อง RGB ซึ่งแต่ละช่องสีจะแสดงด้วยอาร์เรย์ที่แยกจากกัน ความเข้มของพิกเซลแตกต่างกันไปตั้งแต่ 0 ถึง 255
ตอนนี้สำหรับการจัดประเภทรูปภาพ คอมพิวเตอร์จะมองหาคุณสมบัติที่ระดับพื้นฐาน ตามที่เราเป็นมนุษย์ คุณสมบัติระดับพื้นฐานเหล่านี้ของแมวคือหู จมูก และหนวดของมัน สำหรับคอมพิวเตอร์ คุณลักษณะระดับพื้นฐานเหล่านี้คือส่วนโค้งและขอบเขต ด้วยวิธีนี้โดยใช้เลเยอร์ต่างๆ เช่น เลเยอร์ Convolutional และเลเยอร์ Pooling คอมพิวเตอร์จะแยกคุณสมบัติระดับพื้นฐานออกจากรูปภาพ
ในโมเดล Convolutional Neural Network มีเลเยอร์หลายประเภท เช่น –
- อินพุตเลเยอร์
- Convolutional Layer
- Pooling Layer
- เชื่อมต่ออย่างสมบูรณ์ Layer
- ชั้นเอาท์พุท
- ฟังก์ชั่นการเปิดใช้งาน
ให้เราอธิบายแต่ละเลเยอร์โดยสังเขปก่อนที่เราจะนำไปใช้ในการจัดประเภทรูปภาพ
อินพุตเลเยอร์
จากชื่อ เราเข้าใจดีว่านี่คือเลเยอร์ที่จะป้อนอิมเมจอินพุตลงในโมเดล CNN ขึ้นอยู่กับความต้องการของเรา เราสามารถปรับรูปร่างของภาพเป็นขนาดต่างๆ เช่น (28,28,3)
Convolutional Layer
จากนั้นชั้นที่สำคัญที่สุดซึ่งประกอบด้วยตัวกรอง (หรือที่เรียกว่าเคอร์เนล) ที่มีขนาดคงที่ การดำเนินการทางคณิตศาสตร์ของ Convolution ดำเนินการระหว่างภาพที่ป้อนเข้าและตัวกรอง นี่คือขั้นตอนที่คุณสมบัติพื้นฐานส่วนใหญ่ เช่น ขอบและส่วนโค้งที่คมชัด ถูกดึงออกมาจากภาพ ดังนั้นเลเยอร์นี้จึงเรียกอีกอย่างว่าเลเยอร์ตัวแยกคุณลักษณะ
Pooling Layer
หลังจากดำเนินการ Convolution เราดำเนินการ Pooling สิ่งนี้เรียกอีกอย่างว่าการลดขนาดตัวอย่างโดยที่ปริมาณเชิงพื้นที่ของภาพลดลง ตัวอย่างเช่น หากเราดำเนินการรวมกลุ่มด้วยอัตราก้าว 2 บนรูปภาพที่มีขนาด 28×28 จากนั้นขนาดรูปภาพจะลดลงเหลือ 14×14 ก็จะลดลงเหลือครึ่งหนึ่งของขนาดดั้งเดิม
เชื่อมต่ออย่างสมบูรณ์ Layer
Fully Connected Layer (FC) วางไว้ก่อนเอาต์พุตการจัดหมวดหมู่สุดท้ายของโมเดล CNN เลเยอร์เหล่านี้ใช้เพื่อทำให้ผลลัพธ์เรียบขึ้นก่อนจัดประเภท มันเกี่ยวข้องกับอคติ น้ำหนัก และเซลล์ประสาทหลายอย่าง การแนบเลเยอร์ FC ก่อนการจัดประเภทจะส่งผลให้เวกเตอร์มิติ N โดยที่ N คือจำนวนคลาสที่โมเดลต้องเลือกคลาส
ชั้นเอาท์พุท
สุดท้าย Output Layer ประกอบด้วยฉลากซึ่งส่วนใหญ่เข้ารหัสโดยใช้วิธีการเข้ารหัสแบบร้อนครั้งเดียว
ฟังก์ชั่นการเปิดใช้งาน
ฟังก์ชันการเปิดใช้งานเหล่านี้เป็นแกนหลักของโมเดล Convolutional Neural Network ฟังก์ชันเหล่านี้ใช้เพื่อกำหนดผลลัพธ์ของโครงข่ายประสาทเทียม กล่าวโดยย่อ จะเป็นตัวกำหนดว่าควรเปิดใช้งานเซลล์ประสาทเฉพาะ (“ถูกไล่ออก”) หรือไม่ สิ่งเหล่านี้มักจะเป็นฟังก์ชันที่ไม่เป็นเชิงเส้นซึ่งดำเนินการกับสัญญาณอินพุต เอาต์พุตที่แปลงแล้วนี้จะถูกส่งเป็นอินพุตไปยังเซลล์ประสาทชั้นถัดไป มีฟังก์ชันการเปิดใช้งานหลายอย่าง เช่น Sigmoid, ReLU, Leaky ReLU, TanH และ Softmax
สถาปัตยกรรม CNN ขั้นพื้นฐาน
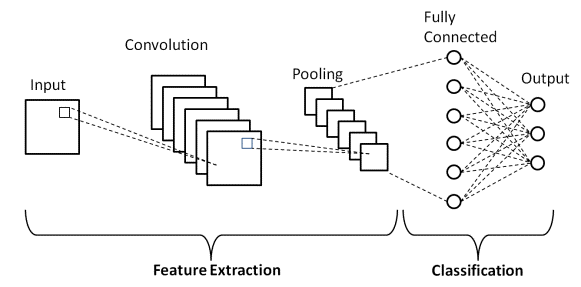
ที่มา : Basic CNN Architecture
ตามที่กำหนดไว้ก่อนหน้านี้ ไดอะแกรมที่แสดงด้านบนเป็นสถาปัตยกรรมพื้นฐานของโมเดล Convolutional Neural Network ตอนนี้เราพร้อมแล้วกับพื้นฐานของ Image Classification และ CNN ให้เราลงลึกในแอปพลิเคชันที่มีปัญหาแบบเรียลไทม์ เรียนรู้เพิ่มเติมเกี่ยวกับสถาปัตยกรรม CNN พื้นฐาน
การติดตั้งโครงข่ายประสาทเทียม
ตอนนี้เราเข้าใจพื้นฐานของ Image Classification และ Convolutional Neural Networks แล้ว ให้เราเห็นภาพการใช้งานใน TensorFlow/Keras ด้วย Python coding ในเรื่องนี้ เราจะสร้าง Convolutional Neural Network Model อย่างง่ายด้วยสถาปัตยกรรม LeNet พื้นฐาน ฝึกโมเดลในชุดการฝึก & ชุดทดสอบ และสุดท้ายจะได้รับความถูกต้องของแบบจำลองจากข้อมูลชุดทดสอบ
ชุดปัญหา
ในบทความนี้สำหรับการสร้างและฝึกอบรม Convolutional Neural Network Model เราจะใช้ชุดข้อมูล Fashion MNIST ที่มีชื่อเสียง MNIST ย่อมาจาก Modified National Institute of Standards and Technology Fashion-MNIST เป็นชุดข้อมูลรูปภาพบทความของ Zalando ซึ่งประกอบด้วยชุดฝึก 60,000 ตัวอย่างและชุดทดสอบ 10,000 ตัวอย่าง แต่ละตัวอย่างคือรูปภาพระดับสีเทา 28×28 ซึ่งเชื่อมโยงกับป้ายกำกับจาก 10 คลาส
ตัวอย่างการฝึกอบรมและการทดสอบแต่ละรายการถูกกำหนดให้กับหนึ่งในป้ายกำกับต่อไปนี้:

0 – เสื้อยืด/เสื้อ
1 – กางเกง
2 – เสื้อสวมหัว
3 – ชุดเดรส
4 – โค้ท
5 – รองเท้าแตะ
6 – เสื้อเชิ้ต
7 – รองเท้าผ้าใบ
8 – กระเป๋า
9 – รองเท้าบูทหุ้มข้อ
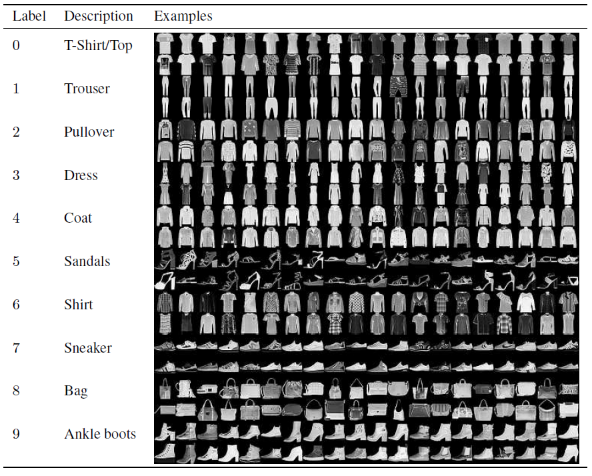
ที่มา : Fashion MNIST Dataset Images
รหัสโปรแกรม
ขั้นตอนที่ 1 – การนำเข้าไลบรารี
ขั้นตอนแรกในการสร้างโมเดล Deep Learning คือการนำเข้าไลบรารีที่จำเป็นสำหรับโปรแกรม ในตัวอย่างของเรา ในขณะที่เราใช้เฟรมเวิร์ก TensorFlow เราจะนำเข้าไลบรารี Keras และไลบรารีที่สำคัญอื่นๆ เช่น ตัวเลขสำหรับการคำนวณและ matplotlib สำหรับการพล็อตแผนผัง
#TensorFlow – การนำเข้าไลบรารี
นำเข้า numpy เป็น np
นำเข้า matplotlib.pyplot เป็น plt
%matplotlib แบบอินไลน์
นำเข้าเทนเซอร์โฟลว์เป็น tf
จากการนำเข้าเทนเซอร์โฟลว์ Keras
ขั้นตอนที่ 2 – การรับและแยกชุดข้อมูล
เมื่อเรานำเข้าไลบรารีแล้ว ขั้นตอนต่อไปคือการดาวน์โหลดชุดข้อมูลและแบ่งชุดข้อมูล Fashion MNIST ออกเป็น 60,000 การฝึกอบรมและ 10,000 ข้อมูลการทดสอบตามลำดับ โชคดีที่ keras มีฟังก์ชันที่กำหนดไว้ล่วงหน้าเพื่อนำเข้าชุดข้อมูล Fashion MNIST และเราสามารถแยกพวกมันออกเป็นบรรทัดถัดไปโดยใช้บรรทัดโค้ดง่ายๆ ที่เข้าใจในตัวเอง
#TensorFlow – การรับและแยกชุดข้อมูล
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
ขั้นตอนที่ 3 – การแสดงภาพข้อมูล
เนื่องจากชุดข้อมูลถูกดาวน์โหลดพร้อมกับรูปภาพและป้ายกำกับที่เกี่ยวข้อง เพื่อให้ผู้ใช้เข้าใจได้ชัดเจนยิ่งขึ้น ขอแนะนำให้ดูข้อมูลเสมอเพื่อให้เราเข้าใจประเภทของข้อมูลที่เรากำลังจัดการกับ Convolutional Neural โมเดลเครือข่ายตามลำดับ ในที่นี้ ด้วยโค้ดง่ายๆ ด้านล่างนี้ เราจะเห็นภาพ 3 ภาพแรกของชุดข้อมูลการฝึกอบรมที่สุ่มแบบสุ่ม
#TensorFlow – การแสดงภาพข้อมูล
def imshowTensorFlow (img):
plt.imshow(img, cmap='สีเทา')
พิมพ์("ป้ายกำกับ:", img[0])
imshowTensorFlow(train_images_tf[0])
ป้ายกำกับ: 9 ป้ายกำกับ: 0 ป้ายกำกับ: 3
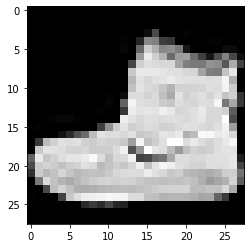


รูปภาพที่ระบุด้านบนและป้ายกำกับสามารถตรวจสอบได้ด้วยป้ายกำกับที่ให้ไว้ในรายละเอียดชุดข้อมูล Fashion MNIST ด้านบน จากนี้ เราอนุมานว่าภาพข้อมูลของเราเป็นภาพระดับสีเทาที่มีความสูง 28 พิกเซล และความกว้าง 28 พิกเซล
ดังนั้น โมเดลสามารถสร้างได้ด้วยขนาดอินพุตที่ (28,28,1) โดยที่ 1 หมายถึงภาพระดับสีเทา
ขั้นตอนที่ 4 – การสร้างแบบจำลอง
ดังที่ได้กล่าวไว้ข้างต้น ในบทความนี้เราจะสร้าง Convolutional Neural Network อย่างง่ายด้วยสถาปัตยกรรม LeNet LeNet เป็นโครงสร้างโครงข่ายประสาทเทียมที่เสนอโดย Yann LeCun et al ในปี 1989 โดยทั่วไป LeNet หมายถึง LeNet-5 และเป็น Convolutional Neural Network อย่างง่าย
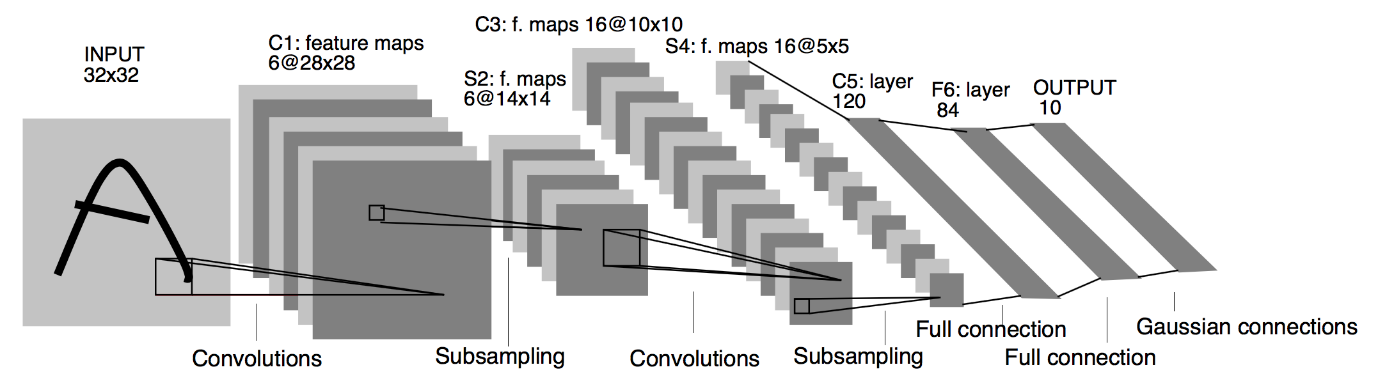
ที่มา : The LeNet Architecture
จากแผนภาพสถาปัตยกรรมที่ระบุข้างต้นของ LeNet CNN Model เราจะเห็นว่ามี 5+2 เลเยอร์ ชั้นแรกและชั้นที่สองเป็นชั้น Convolutional ตามด้วยชั้น Pooling อีกครั้ง เลเยอร์ที่สามและสี่ประกอบด้วยเลเยอร์ Convolutional และเลเยอร์ Pooling จากการดำเนินการเหล่านี้ ขนาดของภาพอินพุตจาก 28×28 จะลดลงเหลือ 7×7
เลเยอร์ที่ห้าของ LeNet Model คือ Fully Connected Layer ซึ่งจะทำให้เอาต์พุตของเลเยอร์ก่อนหน้าราบเรียบ ตามด้วยเลเยอร์หนาแน่นสองชั้น เลเยอร์เอาต์พุตสุดท้ายของรุ่น CNN ประกอบด้วยฟังก์ชันการเปิดใช้งาน Softmax ที่มี 10 ยูนิต ฟังก์ชัน Softmax คาดการณ์ความน่าจะเป็นของคลาสสำหรับ 10 คลาสของชุดข้อมูล Fashion MNIST
#TensorFlow – การสร้างแบบจำลอง
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), ตัวกรอง=6, kernel_size=5, ก้าว=1, ช่องว่างภายใน=”เหมือนเดิม”, การเปิดใช้งาน=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, ก้าว=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, enable=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, ก้าว=2),
keras.layers.Flatten(),
keras.layers.Dense (120, การเปิดใช้งาน = tf.nn.relu),
keras.layers.Dense (84, การเปิดใช้งาน = tf.nn.relu),
keras.layers.Dense (10, การเปิดใช้งาน = tf.nn.softmax)
])
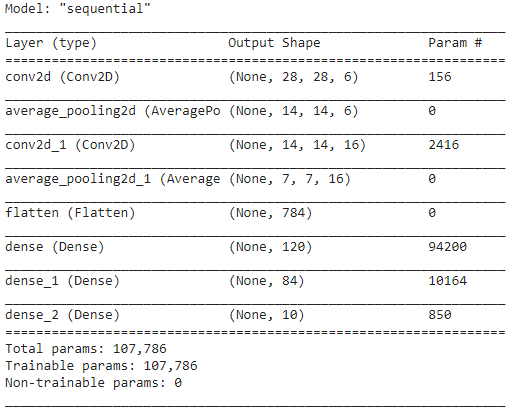
ขั้นตอนที่ 5 – สรุปแบบจำลอง
เมื่อเลเยอร์ของโมเดล LeNet ได้รับการสรุปแล้ว เราสามารถดำเนินการรวบรวมโมเดลและดูเวอร์ชันสรุปของโมเดล CNN ที่ออกแบบได้
#TensorFlow – สรุปแบบจำลอง
model.compile(loss=keras.losses.categorical_crossentropy,
เครื่องมือเพิ่มประสิทธิภาพ = 'adam',
metrics=['acc'])
model.summary()
ในเรื่องนี้ เนื่องจากผลลัพธ์สุดท้ายมีมากกว่า 2 คลาส (10 คลาส) เราจึงใช้ crossentropy ที่เป็นหมวดหมู่เป็นฟังก์ชันการสูญเสีย และใช้ Adam Optimizer กับแบบจำลองของเราที่สร้างขึ้น สรุปแบบจำลองได้รับด้านล่าง
ขั้นตอนที่ 6 – ฝึกโมเดล
ในที่สุด เราก็มาถึงส่วนที่เริ่มกระบวนการฝึกอบรม LeNet CNN model ประการแรก เราปรับรูปร่างชุดข้อมูลการฝึกอบรมและทำให้เป็นค่ามาตรฐานที่น้อยลงโดยหารด้วย 255.0 เพื่อลดต้นทุนการคำนวณ จากนั้นป้ายกำกับการฝึกอบรมจะถูกแปลงจากเวกเตอร์คลาสจำนวนเต็มเป็นเมทริกซ์คลาสไบนารี ตัวอย่างเช่น ป้ายกำกับ 3 จะถูกแปลงเป็น [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – การฝึกโมเดล
train_images_tensorflow = (train_images_tf / 255.0).reshape (train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
เมื่อสิ้นสุดการฝึกอบรมหลังจาก 30 ยุค เราได้รับความแม่นยำและการสูญเสียการฝึกอบรมขั้นสุดท้ายดังนี้
ยุค 30/30
1875/1875 [==============================] – 4 วินาที 2ms/ขั้นตอน – การสูญเสีย: 0.0421 – ตาม: 0.9850
ความแม่นยำในการฝึก: 98.294997215271 %
การสูญเสียการฝึกอบรม: 0.04584110900759697
ขั้นตอนที่ 7 – การทำนายผลลัพธ์
สุดท้าย เมื่อเราเสร็จสิ้นกระบวนการฝึกอบรมแบบจำลอง CNN แล้ว เราจะใส่แบบจำลองเดียวกันในชุดข้อมูลการทดสอบและคาดการณ์ความถูกต้องของภาพทดสอบ 10,000 ภาพ
#TensorFlow – การเปรียบเทียบผลลัพธ์
การคาดคะเน = model.predict(test_images_tensorflow)
ถูกต้อง = 0
สำหรับฉัน pred ในการแจกแจง (การคาดการณ์):
ถ้า np.argmax(pred) == test_labels_tf[i]:
ถูกต้อง += 1
print('ทดสอบความแม่นยำของแบบจำลองใน {} ภาพทดสอบ: {}% ด้วย TensorFlow'.format(test_images_tf.shape[0],100 * ถูกต้อง/test_images_tf.shape[0]))
ผลลัพธ์ที่เราได้รับคือ
ทดสอบความแม่นยำของแบบจำลองบนภาพทดสอบ 10,000 ภาพ: 90.67% ด้วย TensorFlow
ด้วยเหตุนี้ เราจึงได้สิ้นสุดโปรแกรมในการสร้างแบบจำลองการจำแนกรูปภาพด้วย Convolutional Neural Networks
อ่านเพิ่มเติม: แนวคิดโครงการการเรียนรู้ของเครื่อง
บทสรุป
ดังนั้น ในบทช่วยสอนนี้เกี่ยวกับการนำ Image Classification ไปใช้ใน CNN เราจึงเข้าใจแนวคิดพื้นฐานที่อยู่เบื้องหลัง Image Classification, Convolutional Neural Networks ควบคู่ไปกับการใช้งานในภาษาการเขียนโปรแกรม Python ด้วยเฟรมเวิร์ก TensorFlow
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
CNN รุ่นใดที่ถือว่าเหมาะสมที่สุดสำหรับการจัดหมวดหมู่รูปภาพ
โมเดล CNN ที่ดีที่สุดสำหรับการจัดประเภทรูปภาพคือ VGG-16 ซึ่งย่อมาจาก Very Deep Convolutional Networks สำหรับการจดจำภาพขนาดใหญ่ VGG ซึ่งได้รับการออกแบบให้เป็น CNN เชิงลึก มีประสิทธิภาพเหนือกว่าพื้นฐานในงานและชุดข้อมูลที่หลากหลายนอก ImageNet ลักษณะเด่นของโมเดลคือ เมื่อถูกสร้างขึ้น จะมีการให้ความสำคัญกับการรวมเลเยอร์การบิดที่ยอดเยี่ยมมากกว่าการเน้นที่การเพิ่มพารามิเตอร์ไฮเปอร์จำนวนมาก มีทั้งหมด 16 ชั้น 5 บล็อก และแต่ละบล็อกมีชั้นรวมสูงสุด ทำให้เป็นเครือข่ายที่ค่อนข้างใหญ่
ข้อเสียของการใช้โมเดล CNN สำหรับการจัดประเภทรูปภาพคืออะไร?
เมื่อพูดถึงการจัดประเภทรูปภาพ โมเดล CNN ประสบความสำเร็จอย่างมาก อย่างไรก็ตาม มีข้อเสียหลายประการในการใช้ CNN หากรูปภาพที่จะระบุเอียงหรือหมุน แบบจำลอง CNN จะมีปัญหาในการระบุรูปภาพอย่างถูกต้อง เมื่อ CNN แสดงภาพ จะไม่มีการแสดงส่วนประกอบภายในและการเชื่อมต่อทั้งหมดบางส่วน นอกจากนี้ หากโมเดล CNN ที่ใช้มีเลเยอร์ที่เกิดการบิดเบี้ยวจำนวนมาก กระบวนการจัดหมวดหมู่จะใช้เวลานาน
เหตุใดจึงนิยมใช้โมเดล CNN มากกว่า ANN สำหรับข้อมูลรูปภาพเป็นอินพุต
ด้วยการรวมฟิลเตอร์หรือการแปลงเข้าด้วยกัน CNN สามารถเรียนรู้การแสดงคุณสมบัติหลายชั้นสำหรับรูปภาพทุกรูปที่ให้ไว้เป็นอินพุต Overfitting ลดลงเนื่องจากจำนวนของพารามิเตอร์สำหรับเครือข่ายที่จะเรียนรู้ใน CNN นั้นน้อยกว่าในเครือข่ายนิวรัลหลายชั้นอย่างมาก เมื่อใช้ ANN โครงข่ายประสาทเทียมอาจเรียนรู้การแสดงคุณลักษณะเดียวของรูปภาพ แต่ในกรณีของรูปภาพที่ซับซ้อน ANN จะล้มเหลวในการแสดงภาพหรือการจัดหมวดหมู่ที่ได้รับการปรับปรุง เนื่องจากไม่สามารถเรียนรู้การพึ่งพาพิกเซลที่มีอยู่ในรูปภาพที่นำเข้า