
HTTP/3: การปรับปรุงประสิทธิภาพ (ตอนที่ 2)
เผยแพร่แล้ว: 2022-03-10ยินดีต้อนรับกลับสู่ซีรีส์นี้เกี่ยวกับโปรโตคอล HTTP/3 ใหม่ ในส่วนที่ 1 เรามาดูกันว่าทำไมเราถึงต้องการ HTTP/3 และโปรโตคอล QUIC พื้นฐาน และฟีเจอร์ใหม่หลักๆ ของพวกเขาคืออะไร
ในส่วนที่สองนี้ เราจะขยายความใน การปรับปรุงประสิทธิภาพ ที่ QUIC และ HTTP/3 นำมาไว้ที่ตารางสำหรับการโหลดหน้าเว็บ อย่างไรก็ตาม เราจะค่อนข้างสงสัยเกี่ยวกับผลกระทบที่เราคาดหวังได้จากคุณลักษณะใหม่เหล่านี้ในทางปฏิบัติ
อย่างที่เราจะได้เห็นกัน QUIC และ HTTP/3 มีศักยภาพด้านประสิทธิภาพของเว็บที่ยอดเยี่ยม แต่ ส่วนใหญ่สำหรับผู้ใช้ในเครือข่ายที่ช้า หากผู้เข้าชมโดยเฉลี่ยของคุณใช้เครือข่ายเคเบิลหรือเซลลูลาร์ที่รวดเร็ว พวกเขาอาจจะไม่ได้รับประโยชน์จากโปรโตคอลใหม่ทั้งหมดมากนัก อย่างไรก็ตาม โปรดทราบว่าแม้ในประเทศและภูมิภาคที่มีอัปลิงก์ที่รวดเร็ว ผู้ชมของคุณที่ช้าที่สุด 1% ถึง 10% (เปอร์เซ็นไทล์ ที่ 99 หรือ 90 ) ยังคงมีโอกาสได้รับจำนวนมาก นี่เป็นเพราะว่า HTTP/3 และ QUIC ส่วนใหญ่ช่วยจัดการกับปัญหาที่ค่อนข้างแปลกแต่อาจส่งผลกระทบสูงที่อาจเกิดขึ้นบนอินเทอร์เน็ตในปัจจุบัน
ส่วนนี้ ใช้เทคนิคมากกว่าส่วนแรกเล็กน้อย แม้ว่าจะถ่ายเนื้อหาที่ลึกมากส่วนใหญ่ไปยังแหล่งภายนอก โดยเน้นที่การอธิบายว่าทำไมสิ่งเหล่านี้ถึงมีความสำคัญต่อนักพัฒนาเว็บทั่วไป
- ส่วนที่ 1: ประวัติ HTTP/3 และแนวคิดหลัก
บทความนี้มุ่งเป้าไปที่ผู้ที่เพิ่งเริ่มใช้ HTTP/3 และโปรโตคอลโดยทั่วไป และกล่าวถึงพื้นฐานเป็นหลัก - ส่วนที่ 2: คุณสมบัติประสิทธิภาพ HTTP/3
อันนี้เชิงลึกและเชิงเทคนิคมากกว่า ผู้ที่รู้พื้นฐานอยู่แล้วสามารถเริ่มต้นได้ที่นี่ - ส่วนที่ 3: ตัวเลือกการปรับใช้ HTTP/3 ที่ใช้งานได้จริง
บทความที่สามในชุดนี้อธิบายความท้าทายที่เกี่ยวข้องกับการปรับใช้และทดสอบ HTTP/3 ด้วยตัวคุณเอง โดยมีรายละเอียดว่าคุณควรเปลี่ยนหน้าเว็บและแหล่งข้อมูลอย่างไรและควรทำอย่างไร
A Primer on Speed
การอภิปรายเรื่องประสิทธิภาพและ "ความเร็ว" อาจซับซ้อนได้อย่างรวดเร็ว เนื่องจากประเด็นสำคัญหลายประการมีส่วนทำให้การโหลดหน้าเว็บ "ช้า" เนื่องจากเรากำลังจัดการกับโปรโตคอลเครือข่ายที่นี่ เราจะพิจารณาด้านเครือข่ายเป็นหลัก ซึ่งสองส่วนที่สำคัญที่สุด: เวลาแฝงและแบนด์วิดท์
เวลาแฝงสามารถกำหนดคร่าวๆ ได้ตาม เวลาที่ใช้ในการส่งแพ็กเก็ตจากจุด A (เช่น ลูกค้า) ไปยังจุด B (เซิร์ฟเวอร์) มันถูกจำกัดทางกายภาพด้วยความเร็วของแสงหรือว่าสัญญาณสามารถเคลื่อนที่ได้เร็วแค่ไหนในสายไฟหรือในที่โล่ง ซึ่งหมายความว่าเวลาแฝงมักขึ้นอยู่กับระยะห่างทางกายภาพและในโลกแห่งความเป็นจริงระหว่าง A และ B
บนโลกนี้หมายความว่าเวลาแฝงโดยทั่วไปมีขนาดเล็กตามแนวคิด ระหว่างประมาณ 10 ถึง 200 มิลลิวินาที อย่างไรก็ตาม นี่เป็นเพียงวิธีเดียวเท่านั้น: การตอบสนองต่อแพ็กเก็ตจะต้องกลับมาด้วย เวลาแฝงแบบสองทางมักเรียกว่า เวลาไปกลับ (RTT)
เนื่องจากคุณสมบัติต่างๆ เช่น การควบคุมความแออัด (ดูด้านล่าง) เรามักจะต้องเดินทางไปกลับหลายครั้งเพื่อโหลดไฟล์แม้แต่ไฟล์เดียว ดังนั้น แม้แต่เวลาแฝงที่ต่ำเพียงน้อยกว่า 50 มิลลิวินาทีก็สามารถเพิ่มความล่าช้าได้มาก นี่เป็นหนึ่งในสาเหตุหลักว่าทำไมเครือข่ายการจัดส่งเนื้อหา (CDN) จึงมีอยู่: พวกเขาวางเซิร์ฟเวอร์ไว้ใกล้กับผู้ใช้ปลายทางเพื่อลดเวลาแฝงและทำให้ล่าช้ามากที่สุด
แบนด์วิดท์จึงกล่าวได้คร่าวๆ ว่าเป็น จำนวนแพ็กเก็ตที่สามารถส่งได้พร้อมกัน อธิบายยากกว่านี้หน่อยเพราะขึ้นอยู่กับคุณสมบัติทางกายภาพของสื่อ (เช่น ความถี่ที่ใช้ของคลื่นวิทยุ) จำนวนผู้ใช้ในเครือข่าย และอุปกรณ์ที่เชื่อมต่อเครือข่ายย่อยต่างๆ เข้าด้วยกัน (เพราะพวกเขา โดยทั่วไปสามารถประมวลผลได้เฉพาะจำนวนแพ็กเก็ตต่อวินาทีเท่านั้น)
คำอุปมาที่ใช้บ่อยคือท่อที่ใช้ในการขนส่งน้ำ ความยาวของท่อคือเวลาแฝง ในขณะที่ความกว้างของท่อคือแบนด์วิดท์ อย่างไรก็ตาม บนอินเทอร์เน็ต โดยปกติเรามี ท่อเชื่อมต่อแบบยาว ซึ่งบางท่ออาจกว้างกว่าท่ออื่นๆ (นำไปสู่ปัญหาคอขวดที่ลิงก์ที่แคบที่สุด) ด้วยเหตุนี้ แบนด์วิดท์แบบ end-to-end ระหว่างจุด A และ B มักถูกจำกัดโดยส่วนย่อยที่ช้าที่สุด
แม้ว่าส่วนที่เหลือของโพสต์นี้จะไม่จำเป็นต้องเข้าใจแนวคิดเหล่านี้อย่างสมบูรณ์ แต่การมีคำจำกัดความในระดับสูงร่วมกันก็น่าจะดี สำหรับข้อมูลเพิ่มเติม ฉันแนะนำให้ดูบทที่ยอดเยี่ยมของ Ilya Grigorik เกี่ยวกับเวลาแฝงและแบนด์วิดท์ในหนังสือ High Performance Browser Networking ของเขา
การควบคุมความแออัด
ประสิทธิภาพด้านหนึ่งเกี่ยวกับ ประสิทธิภาพ ของโปรโตคอลการขนส่งที่สามารถใช้แบนด์วิดท์ (จริง) แบบเต็มของเครือข่ายได้ (กล่าวคือ สามารถส่งหรือรับแพ็กเก็ตได้กี่แพ็กเก็ตต่อวินาที) ซึ่งจะส่งผลต่อความเร็วในการดาวน์โหลดทรัพยากรของเพจ บางคนอ้างว่า QUIC ทำได้ดีกว่า TCP มาก แต่ก็ไม่เป็นความจริง
เธอรู้รึเปล่า?
ตัวอย่างเช่น การเชื่อมต่อ TCP ไม่เพียงเริ่มส่งข้อมูลด้วยแบนด์วิดท์เต็ม เนื่องจากอาจทำให้เครือข่ายโอเวอร์โหลด (หรือแออัด) เนื่องจากดังที่เราได้กล่าวไปแล้ว ลิงก์เครือข่ายแต่ละลิงก์มีข้อมูลจำนวนหนึ่งเท่านั้นที่สามารถประมวลผล (ทางกายภาพ) ทุกวินาที ให้มันมากกว่านี้และไม่มีทางเลือกอื่นนอกจากการทิ้งแพ็กเก็ตที่มากเกินไป ซึ่งนำไปสู่ การสูญเสียแพ็กเก็ต
ตามที่กล่าวไว้ในตอนที่ 1 สำหรับโปรโตคอลที่เชื่อถือได้ เช่น TCP วิธีเดียวที่จะกู้คืนจากการสูญเสียแพ็กเก็ตคือการส่งสำเนาข้อมูลใหม่อีกครั้ง ซึ่งจะใช้เวลาไปกลับหนึ่งครั้ง โดยเฉพาะอย่างยิ่งในเครือข่ายที่มีความหน่วงสูง (เช่น ด้วย RTT ที่มากกว่า 50 มิลลิวินาที) การสูญเสียแพ็กเก็ตอาจส่งผลกระทบร้ายแรงต่อประสิทธิภาพการทำงาน
ปัญหาอีกประการหนึ่งคือเราไม่ทราบล่วงหน้าว่า แบนด์วิดท์สูงสุด จะเป็นเท่าใด มักขึ้นอยู่กับปัญหาคอขวดในการเชื่อมต่อแบบ end-to-end แต่เราไม่สามารถคาดเดาหรือรู้ว่าสิ่งนี้จะอยู่ที่ใด อินเทอร์เน็ตยังไม่มีกลไก (ยัง) ในการส่งสัญญาณความสามารถในการเชื่อมโยงกลับไปยังปลายทาง
นอกจากนี้ แม้ว่าเราจะทราบแบนด์วิดท์ทางกายภาพที่มีอยู่ แต่ก็ไม่ได้หมายความว่าเราจะใช้แบนด์วิดธ์ทั้งหมดได้ด้วยตนเอง ผู้ใช้หลายคนมักใช้งานบนเครือข่ายพร้อมกัน ซึ่งแต่ละคนต้องการส่วนแบ่งแบนด์วิดธ์ที่พอเหมาะพอควร
ด้วยเหตุนี้ การเชื่อมต่อจึงไม่ทราบว่าสามารถใช้แบนด์วิดท์ได้มากน้อยเพียงใดและแบนด์วิดท์นี้สามารถเปลี่ยนแปลงได้เมื่อผู้ใช้เข้าร่วม ออก และใช้เครือข่าย เพื่อแก้ปัญหานี้ TCP จะพยายามค้นหาแบนด์วิดท์ที่พร้อมใช้งานตลอดเวลาโดยใช้กลไกที่เรียกว่า congestion control
ในช่วงเริ่มต้นของการเชื่อมต่อ จะส่งแพ็กเก็ตเพียงไม่กี่แพ็กเก็ต (ในทางปฏิบัติมีตั้งแต่ 10 ถึง 100 แพ็กเก็ต หรือข้อมูลประมาณ 14 ถึง 140 KB ) และรอการเดินทางไปกลับหนึ่งครั้งจนกว่าผู้รับจะตอบกลับแพ็กเก็ตเหล่านี้ หากยอมรับได้ทั้งหมด แสดงว่าเครือข่ายสามารถรองรับอัตราการส่งนั้นได้ และเราสามารถลองดำเนินการตามขั้นตอนเดิมได้ แต่มีข้อมูลมากขึ้น (ในทางปฏิบัติ อัตราการส่งมักจะเพิ่มขึ้นเป็นสองเท่าในทุก ๆ การวนซ้ำ)
ด้วยวิธีนี้ อัตราการส่ง ยังคงเพิ่มขึ้น จนกว่าบางแพ็กเก็ตจะไม่ได้รับการยอมรับ (ซึ่งบ่งชี้ว่าแพ็กเก็ตสูญหายและความแออัดของเครือข่าย) โดยทั่วไประยะแรกนี้เรียกว่า "การเริ่มช้า" เมื่อตรวจพบการสูญหายของแพ็กเก็ต TCP จะลดอัตราการส่ง และ (หลังจากนั้นครู่หนึ่ง) ก็เริ่มเพิ่มอัตราการส่งอีกครั้ง แม้ว่าจะเพิ่มขึ้นทีละน้อย (มาก) ลอจิกที่ลดแล้วขยายนี้จะถูกทำซ้ำสำหรับทุกๆ แพ็กเก็ตที่สูญเสียไปหลังจากนั้น ในที่สุด นี่หมายความว่า TCP จะพยายามเข้าถึงส่วนแบ่งแบนด์วิดท์ที่เหมาะสมและเหมาะสมที่สุดอย่างต่อเนื่อง กลไกนี้แสดงไว้ในรูปที่ 1
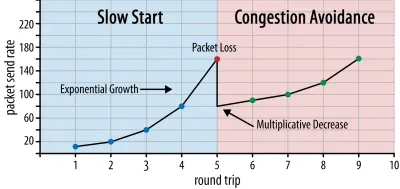
นี่เป็นคำอธิบาย ที่เข้าใจง่ายมาก เกี่ยวกับการควบคุมความแออัด ในทางปฏิบัติ มีหลายปัจจัยที่เกี่ยวข้อง เช่น การบวมของบัฟเฟอร์ ความผันผวนของ RTT อันเนื่องมาจากความแออัด และความจริงที่ว่าผู้ส่งหลายรายพร้อมกันจำเป็นต้องได้รับส่วนแบ่งแบนด์วิดท์ที่ยุติธรรม ด้วยเหตุนี้ จึงมีอัลกอริธึมควบคุมความแออัดที่แตกต่างกันจำนวนมาก และยังคงมีการประดิษฐ์ขึ้นมากมายในปัจจุบัน โดยที่ไม่มีใครทำงานได้ดีที่สุดในทุกสถานการณ์
แม้ว่าการควบคุมความแออัดของ TCP จะทำให้มีประสิทธิภาพ แต่ก็หมายความว่าต้องใช้เวลาสักพักกว่าจะ ถึงอัตราการส่ง ที่เหมาะสมที่สุด ขึ้นอยู่กับ RTT และแบนด์วิดท์ที่มีอยู่จริง สำหรับการโหลดหน้าเว็บ วิธีการเริ่มช้านี้อาจส่งผลต่อเมตริก เช่น การลงสีเนื้อหาแรก เนื่องจากสามารถถ่ายโอนข้อมูลเพียงเล็กน้อย (สิบถึงสองสามร้อย KB) ในการเดินทางไปกลับสองสามครั้งแรก (คุณอาจเคยได้ยินคำแนะนำให้เก็บข้อมูลสำคัญของคุณให้เล็กกว่า 14 KB)
การเลือกวิธีการเชิงรุกอาจนำไปสู่ผลลัพธ์ที่ดีขึ้นในเครือข่ายที่มีแบนด์วิดท์สูงและเวลาแฝงสูง โดยเฉพาะอย่างยิ่งหากคุณไม่สนใจเกี่ยวกับการสูญเสียแพ็กเก็ตเป็นครั้งคราว นี่คือที่ที่ฉันได้เห็นการ ตีความผิดๆ หลายครั้งเกี่ยวกับวิธีการทำงานของ QUIC
ตามที่กล่าวไว้ในตอนที่ 1 ในทางทฤษฎีแล้ว QUIC ได้รับผลกระทบจากการสูญหายของแพ็กเก็ตน้อยกว่า (และการบล็อก head-of-line (HOL) ที่เกี่ยวข้อง) เนื่องจากจะจัดการกับการสูญหายของแพ็กเก็ตบนไบต์สตรีมของทรัพยากรแต่ละรายการอย่างอิสระ นอกจากนี้ QUIC ยังทำงานบน User Datagram Protocol (UDP) ซึ่งไม่เหมือนกับ TCP ที่ไม่มีคุณสมบัติการควบคุมความแออัดในตัว ช่วยให้คุณสามารถลองส่งข้อมูลในอัตราใดก็ได้ที่คุณต้องการและไม่ส่งข้อมูลที่สูญหายซ้ำ
สิ่งนี้นำไปสู่บทความมากมายที่อ้างว่า QUIC ไม่ได้ใช้การควบคุมความแออัด ซึ่ง QUIC สามารถเริ่มส่งข้อมูลในอัตราที่สูงกว่า UDP ได้มาก (อาศัยการนำ HOL blocking ออกเพื่อจัดการกับการสูญหายของแพ็กเก็ต) นั่นคือเหตุผล QUIC เร็วกว่า TCP มาก
ในความเป็นจริง ไม่มีอะไรเพิ่มเติมจากความจริง: จริง ๆ แล้ว QUIC ใช้เทคนิคการจัดการแบนด์วิดท์ที่คล้ายคลึงกันมากเช่น TCP นอกจากนี้ยังเริ่มต้นด้วยอัตราการส่งที่ต่ำกว่าและเพิ่มขึ้นเมื่อเวลาผ่านไป โดยใช้การตอบรับเป็นกลไกสำคัญในการวัดความจุของเครือข่าย นี่คือ (ท่ามกลางเหตุผลอื่นๆ) เพราะ QUIC จำเป็นต้องเชื่อถือได้เพื่อที่จะมีประโยชน์สำหรับบางอย่าง เช่น HTTP เพราะต้องยุติธรรมกับการเชื่อมต่อ QUIC (และ TCP!) อื่นๆ และเนื่องจากการลบการบล็อก HOL ไม่ได้ จริง ๆ แล้วช่วยต่อต้านการสูญหายของแพ็กเก็ตทั้งหมดนั้น (ดังที่เราจะเห็นด้านล่าง)
อย่างไรก็ตาม นั่นไม่ได้หมายความว่า QUIC ไม่สามารถ (เล็กน้อย) อย่างชาญฉลาดเกี่ยวกับวิธีการจัดการแบนด์วิดท์มากกว่า TCP สาเหตุหลักเป็นเพราะ QUIC มีความยืดหยุ่นและวิวัฒนาการได้ง่ายกว่า TCP ดังที่เราได้กล่าวไปแล้ว อัลกอริธึมควบคุมความแออัดยังคงมีการพัฒนาอย่างมากในปัจจุบัน และเราน่าจะจำเป็นต้องปรับเปลี่ยนสิ่งต่างๆ เพื่อให้ได้ประโยชน์สูงสุดจาก 5G ตัวอย่างเช่น
อย่างไรก็ตาม โดยทั่วไปแล้ว TCP จะถูกนำไปใช้ในเคอร์เนลของระบบปฏิบัติการ (OS') ซึ่งเป็นสภาพแวดล้อมที่ปลอดภัยและถูกจำกัดมากขึ้น ซึ่งสำหรับ OS ส่วนใหญ่ไม่ใช่โอเพ่นซอร์สด้วยซ้ำ ด้วยเหตุนี้ การปรับลอจิกความแออัดจึงมักทำได้โดยนักพัฒนาเพียงไม่กี่รายเท่านั้น และวิวัฒนาการก็ช้า
ในทางตรงกันข้าม การใช้งาน QUIC ส่วนใหญ่กำลังดำเนินการอยู่ใน "พื้นที่ผู้ใช้" (ซึ่งโดยปกติแล้วเราจะเรียกใช้แอปที่มาพร้อมเครื่อง) และสร้างเป็นโอเพ่นซอร์ส เพื่อสนับสนุนการทดลองโดยกลุ่มนักพัฒนาในวงกว้างมากขึ้น (ดังที่แสดงไว้แล้ว เช่น โดย Facebook ).
อีกตัวอย่างหนึ่งที่เป็นรูปธรรมคือข้อเสนอการขยาย ความถี่การรับรู้ที่ล่าช้า สำหรับ QUIC แม้ว่าตามค่าเริ่มต้น QUIC จะส่งการตอบรับสำหรับทุกๆ 2 แพ็กเก็ตที่ได้รับ ส่วนขยายนี้อนุญาตให้ปลายทางรับทราบ เช่น ทุกๆ 10 แพ็กเก็ตแทน สิ่งนี้แสดงให้เห็นแล้วว่าให้ ประโยชน์ด้านความเร็ว อย่างมากในเครือข่ายดาวเทียมและเครือข่ายแบนด์วิดท์ที่สูงมาก เนื่องจากค่าใช้จ่ายในการส่งแพ็กเก็ตตอบรับลดลง การเพิ่มส่วนขยายดังกล่าวสำหรับ TCP จะใช้เวลานานกว่าจะถูกนำมาใช้ ในขณะที่ QUIC จะปรับใช้ได้ง่ายกว่ามาก
ด้วยเหตุนี้ เราจึงสามารถคาดหวังได้ว่าความยืดหยุ่นของ QUIC จะนำไปสู่การทดลองที่มากขึ้นและอัลกอริธึมการควบคุมความแออัดที่ดีขึ้นเมื่อเวลาผ่านไป ซึ่งสามารถย้อนกลับไปยัง TCP เพื่อปรับปรุงได้เช่นกัน
เธอรู้รึเปล่า?
QUIC Recovery RFC 9002 อย่างเป็นทางการระบุการใช้อัลกอริธึมการควบคุมความแออัดของ NewReno แม้ว่าวิธีการนี้จะมีประสิทธิภาพ แต่ก็ยัง ค่อนข้างล้าสมัย และไม่ได้ใช้ในทางปฏิบัติอย่างกว้างขวางอีกต่อไป เหตุใดจึงอยู่ใน QUIC RFC เหตุผลแรกคือเมื่อเริ่มต้น QUIC NewReno เป็นอัลกอริธึมการควบคุมความแออัดล่าสุดซึ่งเป็นมาตรฐานในตัวเอง อัลกอริธึมขั้นสูง เช่น BBR และ CUBIC ยังไม่ได้มาตรฐานหรือเพิ่งกลายเป็น RFC
เหตุผลที่สองคือ NewReno เป็นการตั้งค่าที่ค่อนข้างง่าย เนื่องจากอัลกอริธึมต้องการการปรับแต่งเล็กน้อยเพื่อจัดการกับความแตกต่างของ QUIC จาก TCP จึงง่ายต่อการอธิบายการเปลี่ยนแปลงเหล่านั้นในอัลกอริธึมที่ง่ายกว่า ดังนั้น ควรอ่าน RFC 9002 เพิ่มเติมว่า "วิธีปรับอัลกอริธึมการควบคุมความแออัดให้เข้ากับ QUIC" มากกว่า "นี่คือสิ่งที่คุณควรใช้สำหรับ QUIC" อันที่จริง การใช้งาน QUIC ระดับโปรดักชั่นส่วนใหญ่นั้นมีการปรับใช้แบบกำหนดเองของทั้ง Cubic และ BBR
ย้ำว่าอัลกอริธึมการควบคุมความแออัด ไม่ใช่ TCP- หรือ QUIC-specific ; สามารถใช้ได้ทั้งโปรโตคอล และความหวังก็คือความก้าวหน้าใน QUIC ในที่สุดก็จะหาทางไปยังสแต็ก TCP ได้เช่นกัน
เธอรู้รึเปล่า?
โปรดทราบว่า ถัดจากการควบคุมความแออัดคือแนวคิดที่เกี่ยวข้องซึ่งเรียกว่าการควบคุมการไหล คุณลักษณะทั้งสองนี้มักสับสนใน TCP เนื่องจากทั้งสองใช้ "หน้าต่าง TCP" แม้ว่าจะมีสองหน้าต่าง: หน้าต่างความแออัดและหน้าต่างการรับ TCP อย่างไรก็ตาม การควบคุมการไหลเข้ามามีบทบาทน้อยกว่ามากสำหรับกรณีการใช้งานของการโหลดหน้าเว็บที่เราสนใจ ดังนั้นเราจะข้ามไปที่นี่ มีข้อมูลเชิงลึกเพิ่มเติม
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
QUIC ยังคงถูกผูกมัดโดยกฎแห่งฟิสิกส์และจำเป็นต้องทำดีกับผู้ส่งรายอื่นบนอินเทอร์เน็ต ซึ่งหมายความว่า จะไม่ ดาวน์โหลดทรัพยากรเว็บไซต์ของคุณเร็วกว่า TCP อย่างน่าอัศจรรย์ อย่างไรก็ตาม ความยืดหยุ่นของ QUIC หมายความว่าการทดลองกับอัลกอริธึมควบคุมความแออัดแบบใหม่จะง่ายขึ้น ซึ่งควรปรับปรุงสิ่งต่างๆ ในอนาคตสำหรับทั้ง TCP และ QUIC
ตั้งค่าการเชื่อมต่อ 0-RTT
ด้านประสิทธิภาพที่สองคือเกี่ยวกับ จำนวนการเดินทางไปกลับ ก่อนที่คุณจะสามารถส่งข้อมูล HTTP ที่เป็นประโยชน์ (เช่น ทรัพยากรของหน้า) ในการเชื่อมต่อใหม่ บางคนอ้างว่า QUIC สามารถเดินทางไปกลับได้เร็วกว่า TCP + TLS สองถึงสามรอบ แต่เราจะเห็นว่ามีเพียงครั้งเดียวเท่านั้น
เธอรู้รึเปล่า?
ดังที่เราได้กล่าวไปแล้วในตอนที่ 1 โดยปกติแล้ว การเชื่อมต่อจะดำเนินการจับมือหนึ่ง (TCP) หรือสองครั้ง (TCP + TLS) ก่อนที่จะแลกเปลี่ยนคำขอ HTTP และการตอบสนอง การจับมือกันเหล่านี้แลกเปลี่ยนพารามิเตอร์เริ่มต้นที่ทั้งไคลเอนต์และเซิร์ฟเวอร์จำเป็นต้องรู้ ตัวอย่างเช่น เพื่อเข้ารหัสข้อมูล
ดังที่คุณเห็นในรูปที่ 2 ด้านล่าง การจับมือ แต่ละ ครั้งต้องใช้เวลาอย่างน้อยหนึ่งรอบในการจับมือ (TCP + TLS 1.3, (b)) และบางครั้งสองครั้ง (TLS 1.2 และก่อนหน้า (a)) สิ่งนี้ไม่มีประสิทธิภาพ เนื่องจากเราต้องการเวลารอการจับมือกัน อย่างน้อยสอง ครั้ง (ค่าใช้จ่าย) ก่อนที่เราจะสามารถส่งคำขอ HTTP แรกของเราได้ ซึ่งหมายความว่ารออย่างน้อยสามครั้งสำหรับข้อมูลตอบกลับ HTTP แรก (ลูกศรสีแดงที่ส่งคืน) ใน บนเครือข่ายที่ช้า นี่อาจหมายถึงค่าใช้จ่าย 100 ถึง 200 มิลลิวินาที
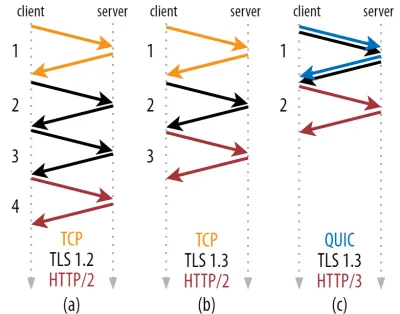
คุณอาจสงสัยว่าเหตุใดการจับมือ TCP + TLS จึงไม่สามารถรวมกันได้ง่ายๆ ในรอบเดียวกัน แม้ว่าสิ่งนี้จะเป็นไปได้ตามแนวคิด (QUIC ทำอย่างนั้นจริงๆ) ในตอนแรกสิ่งต่าง ๆ ไม่ได้ออกแบบมาเช่นนี้เพราะเราจำเป็นต้องใช้ TCP ที่มีและไม่มี TLS อยู่ด้านบน กล่าวอีกนัยหนึ่ง TCP ไม่รองรับการส่งข้อมูลที่ไม่ใช่ TCP ระหว่างการจับมือกัน มีความพยายามที่จะเพิ่มสิ่งนี้ด้วยส่วนขยาย TCP Fast Open; อย่างไรก็ตาม ตามที่กล่าวไว้ในตอนที่ 1 เรื่องนี้กลายเป็นเรื่องยากที่จะปรับใช้ในวงกว้าง
โชคดีที่ QUIC ได้รับการออกแบบโดยคำนึงถึง TLS ตั้งแต่เริ่มต้น และด้วยเหตุนี้จึงรวมทั้งการส่งสัญญาณและการจับมือด้วยการเข้ารหัสไว้ในกลไกเดียว ซึ่งหมายความว่าการจับมือ QUIC จะใช้เวลาไปกลับทั้งหมดเพียงครั้งเดียวเท่านั้น ซึ่งเท่ากับการเดินทางไปกลับที่น้อยกว่า TCP + TLS 1.3 หนึ่งครั้ง (ดูรูปที่ 2c ด้านบน)
คุณอาจสับสน เพราะคุณอาจเคยอ่านว่า QUIC เร็วกว่า TCP ไปกลับสองหรือสามรอบ ไม่ใช่แค่ครั้งเดียว เนื่องจากบทความส่วนใหญ่พิจารณาเฉพาะกรณีที่เลวร้ายที่สุด (TCP + TLS 1.2, (a)) ไม่ได้กล่าวถึงว่า TCP + TLS 1.3 ที่ทันสมัยยัง "เท่านั้น" ไป - กลับสองครั้ง ((b) ไม่ค่อยแสดง) แม้ว่าการเร่งความเร็วของการเดินทางไปกลับครั้งเดียวจะดี แต่ก็แทบจะไม่น่าแปลกใจเลย โดยเฉพาะอย่างยิ่งในเครือข่ายที่รวดเร็ว (เช่น RTT น้อยกว่า 50 มิลลิวินาที) สิ่งนี้จะ แทบไม่สังเกตเห็น แม้ว่าเครือข่ายที่ช้าและการเชื่อมต่อกับเซิร์ฟเวอร์ที่อยู่ห่างไกลจะมีกำไรเพิ่มขึ้นอีกเล็กน้อย
ต่อไป คุณอาจสงสัยว่าทำไมเราต้องรอการจับมือเลย เหตุใดเราจึงไม่สามารถส่งคำขอ HTTP ในการเดินทางไปกลับครั้งแรกได้ สาเหตุหลักเป็นเพราะถ้าเราทำอย่างนั้น คำขอแรกนั้นจะถูกส่งแบบ ไม่เข้ารหัส ซึ่งสามารถอ่านได้โดยผู้ดักฟังทางสาย ซึ่งเห็นได้ชัดว่าไม่เหมาะสำหรับความเป็นส่วนตัวและความปลอดภัย ด้วยเหตุนี้ เราจึงจำเป็นต้องรอให้การจับมือด้วยการเข้ารหัสเสร็จสิ้นก่อนที่จะส่งคำขอ HTTP ครั้งแรก หรือเรา?
นี่คือที่ที่ใช้กลอุบายอันชาญฉลาดในทางปฏิบัติ เราทราบดีว่าผู้ใช้มักจะกลับมาเยี่ยมชมหน้าเว็บอีกครั้งภายในระยะเวลาอันสั้นของการเข้าชมครั้งแรก ด้วยเหตุนี้ เราจึงสามารถใช้การ เชื่อมต่อที่เข้ารหัสเริ่มต้น เพื่อบูตสแตรปการเชื่อมต่อที่สองได้ในอนาคต พูดง่ายๆ ก็คือ บางครั้งในช่วงอายุการใช้งาน การเชื่อมต่อครั้งแรกจะใช้เพื่อสื่อสารพารามิเตอร์การเข้ารหัสใหม่อย่างปลอดภัยระหว่างไคลเอนต์และเซิร์ฟเวอร์ พารามิเตอร์เหล่านี้สามารถใช้เพื่อ เข้ารหัสการเชื่อมต่อที่สอง ตั้งแต่เริ่มต้น โดยไม่ต้องรอให้ TLS handshake เสร็จสมบูรณ์ วิธีการนี้เรียกว่า "การเริ่มเซสชันใหม่"
ช่วยให้มีการเพิ่มประสิทธิภาพที่มีประสิทธิภาพ: ขณะนี้เราสามารถส่งคำขอ HTTP แรกของเราพร้อมกับการจับมือ QUIC/TLS ได้อย่างปลอดภัย ช่วยประหยัดการเดินทางไปกลับอีกครั้ง ! สำหรับ TLS 1.3 การดำเนินการนี้จะลบเวลารอของ TLS handshake ออกอย่างมีประสิทธิภาพ วิธีนี้มักเรียกว่า 0-RTT (แม้ว่าแน่นอนว่ายังต้องใช้เวลาเดินทางไปกลับหนึ่งรอบเพื่อให้ข้อมูลตอบกลับ HTTP เริ่มมาถึง)
ทั้งการเริ่มเซสชันใหม่และ 0-RTT เป็นอีกครั้งที่ฉันมักจะเห็นว่าอธิบายผิดว่าเป็นคุณลักษณะเฉพาะของ QUIC อันที่จริงแล้ว สิ่งเหล่านี้เป็น ฟีเจอร์ TLS ที่มีอยู่แล้วในรูปแบบบางอย่างใน TLS 1.2 และขณะนี้มีคุณลักษณะครบถ้วนใน TLS 1.3
ในอีกแง่หนึ่ง ดังที่คุณเห็นในรูปที่ 3 ด้านล่าง เราจะได้รับประโยชน์ด้านประสิทธิภาพของคุณลักษณะเหล่านี้ผ่าน TCP (และรวมถึง HTTP/2 และแม้แต่ HTTP/1.1) ด้วยเช่นกัน! เราเห็นว่าถึงแม้จะเป็น 0-RTT แต่ QUIC ก็ยังคง เร็วกว่าสแต็ก TCP + TLS 1.3 ที่ทำงานได้อย่างเหมาะสมเพียงรอบเดียวเท่านั้น การอ้างว่า QUIC ไปกลับเร็วกว่า 3 รอบนั้นมาจากการเปรียบเทียบรูปที่ 2 (a) กับรูปที่ 3 (f) ซึ่งอย่างที่เราได้เห็นแล้วว่าไม่ยุติธรรมจริงๆ
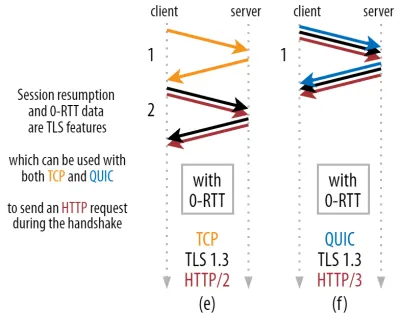
ส่วนที่แย่ที่สุดคือเมื่อใช้ 0-RTT QUIC จะไม่สามารถใช้งานได้จริงเนื่องจากความปลอดภัย เพื่อให้เข้าใจสิ่งนี้ เราต้องเข้าใจเหตุผลหนึ่งว่าทำไม TCP handshake จึงมีอยู่ ประการแรก จะช่วยให้ลูกค้าแน่ใจว่าเซิร์ฟเวอร์ใช้งานได้จริงตามที่อยู่ IP ที่กำหนด ก่อนที่จะส่งข้อมูลในชั้นที่สูงกว่าใดๆ ไป
ประการที่สอง และที่สำคัญที่นี่ มันช่วยให้เซิร์ฟเวอร์ทำให้แน่ใจว่าไคลเอนต์ที่เปิดการเชื่อมต่อนั้นจริง ๆ แล้วใครและพวกเขาบอกว่าพวกเขาอยู่ที่ไหนก่อนที่จะส่งข้อมูล หากคุณจำได้ว่าเรานิยามการเชื่อมต่อกับ 4-tuple ในส่วนที่ 1 อย่างไร คุณจะรู้ว่าลูกค้าส่วนใหญ่ถูกระบุโดยที่อยู่ IP และนี่คือปัญหา: ที่อยู่ IP สามารถปลอมแปลงได้ !
สมมติว่าผู้โจมตีร้องขอไฟล์ขนาดใหญ่มากผ่าน HTTP ผ่าน QUIC 0-RTT อย่างไรก็ตาม พวกเขาปลอมแปลงที่อยู่ IP ทำให้ดูเหมือนว่าคำขอ 0-RTT มาจากคอมพิวเตอร์ของเหยื่อ ดังแสดงในรูปที่ 4 ด้านล่าง เซิร์ฟเวอร์ QUIC ไม่มีทางตรวจพบว่า IP นั้นถูกหลอกหรือไม่ เพราะนี่คือแพ็กเก็ตแรกสุดที่เห็นจากไคลเอนต์นั้น

หากเซิร์ฟเวอร์เริ่มส่งไฟล์ขนาดใหญ่กลับไปที่ IP ปลอม อาจทำให้ แบนด์วิดท์เครือข่ายของเหยื่อทำงานหนักเกินไป (โดยเฉพาะอย่างยิ่งหากผู้โจมตีทำคำขอปลอมจำนวนมากพร้อมกัน) โปรดทราบว่าเหยื่อจะละทิ้งการตอบสนอง QUIC เนื่องจากไม่คาดหวังข้อมูลที่เข้ามา แต่นั่นไม่สำคัญ: เครือข่ายของพวกเขายังคงต้องประมวลผลแพ็กเก็ต!
สิ่งนี้เรียกว่าการ สะท้อนหรือการขยาย การโจมตี และเป็นวิธีสำคัญที่แฮกเกอร์ดำเนินการโจมตีแบบปฏิเสธการให้บริการ (DDoS) แบบกระจาย โปรดทราบว่าสิ่งนี้จะไม่เกิดขึ้นเมื่อ 0-RTT บน TCP + TLS ถูกใช้ เนื่องจาก TCP handshake จำเป็นต้องทำให้เสร็จก่อน ก่อนที่คำขอ 0-RTT จะถูกส่งไปพร้อมกับ TLS handshake
ดังนั้น QUIC จึงต้องระมัดระวัง ในการตอบกลับคำขอ 0-RTT โดยจำกัดจำนวนข้อมูลที่ส่งไปในการตอบสนองจนกว่าลูกค้าจะได้รับการยืนยันว่าเป็นลูกค้าจริงและไม่ใช่เหยื่อ สำหรับ QUIC จำนวนข้อมูลนี้ได้รับการตั้งค่าเป็นสามเท่าของจำนวนเงินที่ได้รับจากลูกค้า
กล่าวอีกนัยหนึ่ง QUIC มี "ปัจจัยการขยาย" สูงสุดสาม ซึ่งได้รับการพิจารณาว่าเป็นการแลกเปลี่ยนที่ยอมรับได้ระหว่างประโยชน์ด้านประสิทธิภาพและความเสี่ยงด้านความปลอดภัย (โดยเฉพาะอย่างยิ่งเมื่อเทียบกับบางเหตุการณ์ที่มีปัจจัยการขยายมากกว่า 51,000 ครั้ง) เนื่องจากโดยปกติแล้วไคลเอนต์จะส่งเพียง 1-2 แพ็กเก็ตก่อน การตอบกลับ 0-RTT ของเซิร์ฟเวอร์ QUIC จะถูก จำกัดไว้ที่ 4 ถึง 6 KB (รวมถึงโอเวอร์เฮด QUIC และ TLS อื่นๆ ด้วย!) ซึ่งค่อนข้างน้อยกว่าที่น่าประทับใจ
นอกจากนี้ ปัญหาด้านความปลอดภัยอื่นๆ อาจนำไปสู่ "การโจมตีซ้ำ" ซึ่งจำกัดประเภทของคำขอ HTTP ที่คุณสามารถทำได้ ตัวอย่างเช่น Cloudflare อนุญาตเฉพาะคำขอ HTTP GET โดยไม่มีพารามิเตอร์การสืบค้นใน 0-RTT สิ่งเหล่านี้จำกัดประโยชน์ของ 0-RTT มากยิ่งขึ้น
โชคดีที่ QUIC มีตัวเลือกในการทำให้ดีขึ้นเล็กน้อย ตัวอย่างเช่น เซิร์ฟเวอร์สามารถตรวจสอบได้ว่า 0-RTT มาจาก IP ที่มีการเชื่อมต่อที่ถูกต้องมาก่อนหรือไม่ อย่างไรก็ตาม ใช้งานได้ก็ต่อเมื่อไคลเอ็นต์อยู่ในเครือข่ายเดียวกัน (จำกัดคุณลักษณะการย้ายการเชื่อมต่อของ QUIC บ้าง) และแม้ว่าจะใช้งานได้ การตอบสนองของ QUIC ก็ยังถูกจำกัดด้วยตรรกะการเริ่มต้นช้าของตัวควบคุมความแออัดที่เรากล่าวถึงข้างต้น ดังนั้นจึง ไม่มีการเร่งความเร็วที่มากเป็นพิเศษ นอกเหนือจากการเดินทางไปกลับครั้งเดียวที่บันทึกไว้
เธอรู้รึเปล่า?
เป็นที่น่าสนใจที่จะทราบว่าขีดจำกัดการขยายเสียงสามเท่าของ QUIC ยังนับรวมสำหรับกระบวนการจับมือปกติแบบ non-0-RTT ในรูปที่ 2c นี่อาจเป็นปัญหาได้ ตัวอย่างเช่น หากใบรับรอง TLS ของเซิร์ฟเวอร์มีขนาดใหญ่เกินกว่าจะใส่ได้ภายใน 4 ถึง 6 KB ในกรณีนั้น จะต้องแยกส่วน โดยที่ส่วนที่สองต้องรอการส่งไปกลับรอบที่สอง (หลังจากรับทราบถึงแพ็กเก็ตสองสามชุดแรกเข้ามา ซึ่งบ่งชี้ว่า IP ของลูกค้าไม่ได้ปลอมแปลง) ในกรณีนี้ การจับมือของ QUIC อาจยังคงจบลงด้วยการไปกลับสองครั้ง เท่ากับ TCP + TLS! นี่คือเหตุผลที่ QUIC เทคนิคเช่นการบีบอัดใบรับรองจะมีความสำคัญเป็นพิเศษ
เธอรู้รึเปล่า?
อาจเป็นไปได้ว่าการตั้งค่าขั้นสูงบางอย่างสามารถบรรเทาปัญหาเหล่านี้ได้มากพอที่จะทำให้ 0-RTT มีประโยชน์มากขึ้น ตัวอย่างเช่น เซิร์ฟเวอร์สามารถจดจำจำนวนแบนด์วิดท์ที่ไคลเอ็นต์ใช้ได้ในครั้งล่าสุดที่มีการดู ซึ่งทำให้จำกัดน้อยลงโดยการเริ่มต้นช้าของการควบคุมความแออัดสำหรับการเชื่อมต่อใหม่ (ไม่ปลอมแปลง) ไคลเอ็นต์ สิ่งนี้ได้รับการตรวจสอบในสถาบันการศึกษา และยังมีการเสนอให้ขยายเวลาใน QUIC เพื่อทำเช่นนี้ หลายบริษัทได้ทำสิ่งนี้เพื่อเร่งความเร็ว TCP เช่นกัน
อีกทางเลือกหนึ่งคือให้ไคลเอนต์ ส่งมากกว่าหนึ่งหรือสองแพ็กเก็ต (เช่น ส่งแพ็กเก็ตเพิ่มอีก 7 แพ็กเก็ตพร้อมช่องว่างภายใน) ดังนั้นการจำกัดสามครั้งจึงแปลเป็นการตอบสนอง 12 ถึง 14 KB ที่น่าสนใจยิ่งขึ้น แม้หลังจากการย้ายการเชื่อมต่อ ฉันได้เขียนเกี่ยวกับเรื่องนี้ในเอกสารของฉัน
สุดท้าย (ทำงานผิดปกติ) เซิร์ฟเวอร์ QUIC อาจจงใจเพิ่มการจำกัดสามครั้งหากพวกเขารู้สึกว่าปลอดภัยที่จะทำอย่างนั้นหรือหากพวกเขาไม่สนใจเกี่ยวกับปัญหาด้านความปลอดภัยที่อาจเกิดขึ้น (ท้ายที่สุด ไม่มีตำรวจโปรโตคอลที่ป้องกันสิ่งนี้)
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
การตั้งค่าการเชื่อมต่อที่เร็วกว่าของ QUIC ด้วย 0-RTT นั้นเป็นการเพิ่มประสิทธิภาพระดับไมโครจริงๆ มากกว่า ฟีเจอร์ใหม่ที่ปฏิวัติวงการ เมื่อเทียบกับการตั้งค่า TCP + TLS 1.3 ที่ล้ำสมัย จะช่วยประหยัดการเดินทางไปกลับได้สูงสุดหนึ่งครั้ง จำนวนข้อมูลที่สามารถส่งได้จริงในการเดินทางไปกลับครั้งแรกนั้นถูกจำกัดเพิ่มเติมด้วยการพิจารณาด้านความปลอดภัยจำนวนหนึ่ง
ดังนั้น คุณลักษณะนี้ส่วนใหญ่จะโดดเด่นหากผู้ใช้ของคุณอยู่ในเครือข่าย ที่มีเวลาแฝงสูงมาก (เช่น เครือข่ายดาวเทียมที่มี RTT มากกว่า 200 มิลลิวินาที) หรือหากคุณไม่ได้ส่งข้อมูลมากนัก ตัวอย่างของหลังนี้เป็นเว็บไซต์ที่แคชจำนวนมาก เช่นเดียวกับแอปหน้าเดียวที่ดึงข้อมูลอัปเดตเล็กๆ เป็นระยะๆ ผ่าน API และโปรโตคอลอื่นๆ เช่น DNS-over-QUIC เหตุผลหนึ่งที่ Google เห็นผลลัพธ์ 0-RTT ที่ดีมากสำหรับ QUIC ก็คือได้ทดสอบมันบนหน้าการค้นหาที่ได้รับการเพิ่มประสิทธิภาพอย่างมากอยู่แล้ว ซึ่งการตอบกลับของแบบสอบถามนั้นค่อนข้างเล็ก
ในกรณีอื่นๆ คุณจะได้รับเพียง ไม่กี่สิบมิลลิวินาที อย่างดีที่สุด แม้จะน้อยกว่านี้หากคุณใช้ CDN อยู่แล้ว (ซึ่งคุณควรจะทำหากคุณสนใจเกี่ยวกับประสิทธิภาพ!)
การโยกย้ายการเชื่อมต่อ
คุณลักษณะด้านประสิทธิภาพที่สามทำให้ QUIC เร็วขึ้นเมื่อถ่ายโอนระหว่างเครือข่าย โดย รักษาการเชื่อมต่อที่มีอยู่เดิม ไว้ แม้ว่าจะใช้งานได้จริง แต่การเปลี่ยนแปลงเครือข่ายประเภทนี้ไม่ได้เกิดขึ้นบ่อยนัก และการเชื่อมต่อยังคงต้องรีเซ็ตอัตราการส่ง
ตามที่กล่าวไว้ในตอนที่ 1 รหัสการเชื่อมต่อ (CID) ของ QUIC อนุญาตให้ทำการย้ายการเชื่อมต่อเมื่อ เปลี่ยนเครือข่าย เราแสดงสิ่งนี้ด้วยไคลเอนต์ที่ย้ายจากเครือข่าย Wi-Fi เป็น 4G ในขณะที่ทำการดาวน์โหลดไฟล์ขนาดใหญ่ บน TCP การดาวน์โหลดนั้นอาจต้องถูกยกเลิก ในขณะที่สำหรับ QUIC อาจดำเนินการต่อไป
อย่างไรก็ตาม อันดับแรก ให้พิจารณาว่าสถานการณ์ประเภทนั้นเกิดขึ้นจริงบ่อยเพียงใด คุณอาจคิดว่าสิ่งนี้เกิดขึ้นเมื่อเคลื่อนที่ไปมาระหว่างจุดเชื่อมต่อ Wi-Fi ภายในอาคารหรือระหว่างเสาสัญญาณมือถือขณะอยู่บนท้องถนน อย่างไรก็ตาม ในการตั้งค่าเหล่านั้น (หากทำอย่างถูกต้อง) โดยทั่วไปอุปกรณ์ของคุณจะคง IP ไว้เหมือนเดิม เนื่องจากการเปลี่ยนระหว่างสถานีฐานไร้สายเกิดขึ้นที่ชั้นโปรโตคอลที่ต่ำกว่า ดังนั้น มันจะเกิดขึ้นก็ต่อเมื่อคุณ ย้ายไปมาระหว่างเครือข่ายที่ต่างกันโดยสิ้นเชิง ซึ่งผมว่าไม่ได้เกิดขึ้นบ่อยขนาดนั้น
ประการที่สอง เราสามารถถามได้ว่าสิ่งนี้ใช้ได้กับกรณีการใช้งานอื่นๆ หรือไม่ นอกเหนือจากการดาวน์โหลดไฟล์ขนาดใหญ่และการประชุมทางวิดีโอสดและการสตรีม หากคุณกำลังโหลดหน้าเว็บในช่วงเวลาของการเปลี่ยนเครือข่าย คุณอาจต้องขอทรัพยากรบางส่วน (ภายหลัง) อีกครั้งแน่นอน
อย่างไรก็ตาม การโหลดหน้าเว็บมักใช้เวลาไม่กี่วินาที ดังนั้นการจับคู่กับสวิตช์เครือข่ายจะไม่เกิดขึ้นบ่อยนัก นอกจากนี้ สำหรับกรณีการใช้งานที่เป็นข้อกังวลเร่งด่วน โดยทั่วไปแล้ว การบรรเทาผลกระทบอื่นๆ ก็มีอยู่แล้ว ตัวอย่างเช่น เซิร์ฟเวอร์ที่เสนอการดาวน์โหลดไฟล์ขนาดใหญ่สามารถรองรับคำขอช่วง HTTP เพื่ออนุญาตให้ดาวน์โหลดต่อได้
เนื่องจากโดยปกติแล้วจะมี เวลาทับซ้อนกัน ระหว่างเครือข่าย 1 ที่หลุดจากเครือข่าย 2 ได้ แอปวิดีโอสามารถเปิดการเชื่อมต่อได้หลายจุด (1 ต่อเครือข่าย) โดยซิงค์ก่อนที่เครือข่ายเก่าจะหายไปโดยสมบูรณ์ ผู้ใช้จะยังสังเกตเห็นสวิตช์ แต่จะไม่ปล่อยฟีดวิดีโอทั้งหมด
ประการที่สาม ไม่มีการรับประกันว่าเครือข่ายใหม่จะมีแบนด์วิดท์มากเท่ากับเครือข่ายเก่า ดังนั้น แม้ว่าการเชื่อมต่อตามแนวคิดจะยังคงอยู่ แต่เซิร์ฟเวอร์ QUIC ไม่สามารถส่งข้อมูลด้วยความเร็วสูงได้ เพื่อหลีกเลี่ยงไม่ให้เครือข่ายใหม่ทำงานหนักเกินไป จำเป็นต้อง รีเซ็ต (หรืออย่างน้อยก็ต่ำกว่า) อัตราการส่งและเริ่มต้นใหม่อีกครั้ง ในช่วงเริ่มต้นช้าของตัวควบคุมความแออัด
เนื่องจากอัตราการส่งเริ่มต้นนี้มักจะต่ำเกินไปที่จะรองรับสิ่งต่างๆ เช่น การสตรีมวิดีโอ คุณจะเห็นว่า คุณภาพลดลง หรือสะดุด แม้แต่ใน QUIC ในแง่หนึ่ง การโยกย้ายการเชื่อมต่อเป็นมากกว่าการป้องกันการเชื่อมต่อบริบทการเชื่อมต่อและโอเวอร์เฮดบนเซิร์ฟเวอร์มากกว่าการปรับปรุงประสิทธิภาพ
เธอรู้รึเปล่า?
โปรดทราบว่า ตามที่กล่าวไว้สำหรับ 0-RTT ข้างต้น เราสามารถคิดค้นเทคนิคขั้นสูงบางอย่างเพื่อปรับปรุงการย้ายการเชื่อมต่อ ตัวอย่างเช่น เราสามารถพยายาม จำอีกครั้งว่าแบนด์วิดท์มีอยู่ในเครือข่ายหนึ่งๆ เท่าใด ในครั้งล่าสุด และพยายามเพิ่มความเร็วให้เร็วขึ้นสำหรับระดับนั้นสำหรับการย้ายข้อมูลใหม่ นอกจากนี้ เราสามารถจินตนาการว่าไม่เพียงแต่สลับไปมาระหว่างเครือข่าย แต่ใช้ทั้งสองเครือข่ายพร้อมกัน แนวคิดนี้เรียกว่า multipath และเราพูดถึงเรื่องนี้ในรายละเอียดเพิ่มเติมด้านล่าง
จนถึงตอนนี้ เราได้พูดถึงการโยกย้ายการเชื่อมต่อที่ใช้งานอยู่เป็นหลัก ซึ่งผู้ใช้จะย้ายไปมาระหว่างเครือข่ายต่างๆ อย่างไรก็ตาม ยังมีกรณีของการย้ายการเชื่อมต่อแบบพาสซีฟ ซึ่งเครือข่ายบางเครือข่ายเองเปลี่ยนพารามิเตอร์ ตัวอย่างที่ดีคือการแปลที่อยู่เครือข่าย (NAT) rebinding แม้ว่าการพูดคุยอย่างเต็มรูปแบบเกี่ยวกับ NAT จะไม่ได้อยู่ในขอบเขตของบทความนี้ แต่โดยหลักแล้วหมายความว่า หมายเลขพอร์ตของการเชื่อมต่อสามารถเปลี่ยนแปลง ได้ตลอดเวลาโดยไม่มีการเตือนล่วงหน้า สิ่งนี้ยังเกิดขึ้นบ่อยสำหรับ UDP มากกว่า TCP ในเราเตอร์ส่วนใหญ่
หากสิ่งนี้เกิดขึ้น QUIC CID จะไม่เปลี่ยนแปลง และการนำไปใช้งานส่วนใหญ่จะถือว่าผู้ใช้ยังคงอยู่ในเครือข่ายทางกายภาพเดียวกัน และจะไม่รีเซ็ตหน้าต่างความแออัดหรือพารามิเตอร์อื่นๆ QUIC ยังมีคุณสมบัติบางอย่างเช่น PING และตัวระบุการหมดเวลาเพื่อป้องกันไม่ให้สิ่งนี้เกิดขึ้น เนื่องจากสิ่งนี้มักเกิดขึ้นสำหรับการเชื่อมต่อที่ไม่ได้ใช้งานเป็นเวลานาน
เราได้พูดคุยกันในตอนที่ 1 ว่า QUIC ไม่ได้เพียงแค่ใช้ CID เดียวด้วยเหตุผลด้านความปลอดภัย แต่จะเปลี่ยนแปลง CID เมื่อทำการย้ายข้อมูล ในทางปฏิบัติ มันซับซ้อนกว่านั้นอีก เนื่องจากทั้งไคลเอ็นต์และเซิร์ฟเวอร์มีรายการ CID แยกจากกัน (เรียกว่า CID ต้นทางและปลายทางใน QUIC RFC) ดังแสดงในรูปที่ 5 ด้านล่าง
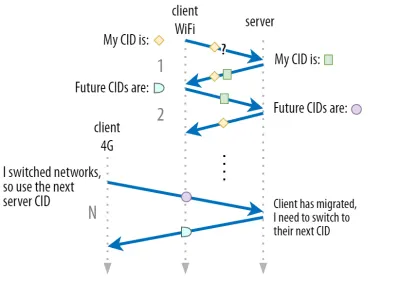
การดำเนินการนี้ทำขึ้นเพื่อ ให้แต่ละปลายทางสามารถเลือกรูปแบบและเนื้อหา CID ของตนเอง ได้ ซึ่งจำเป็นอย่างยิ่งต่อการอนุญาตการกำหนดเส้นทางขั้นสูงและลอจิกการจัดสรรภาระงาน ด้วยการย้ายการเชื่อมต่อ ตัวโหลดบาลานซ์จะไม่เพียงแค่ดูที่ 4-tuple เพื่อระบุการเชื่อมต่อแล้วส่งไปยังเซิร์ฟเวอร์แบ็คเอนด์ที่ถูกต้องอีกต่อไป อย่างไรก็ตาม หากการเชื่อมต่อ QUIC ทั้งหมดใช้ CID แบบสุ่ม สิ่งนี้จะเพิ่มความต้องการหน่วยความจำที่โหลดบาลานเซอร์อย่างมาก เนื่องจากจะต้องจัดเก็บการแมปของ CID กับเซิร์ฟเวอร์ส่วนหลัง นอกจากนี้ ยังใช้ไม่ได้กับการย้ายการเชื่อมต่อ เนื่องจาก CID เปลี่ยนเป็นค่าสุ่มใหม่
ดังนั้น จึงเป็นสิ่งสำคัญที่เซิร์ฟเวอร์แบ็คเอนด์ QUIC ที่ใช้งานเบื้องหลังโหลดบาลานเซอร์ต้องมี รูปแบบที่คาดการณ์ ได้ของ CID เพื่อให้ตัวจัดสรรภาระงานได้รับเซิร์ฟเวอร์ส่วนหลังที่ถูกต้องจาก CID แม้หลังจากการย้ายข้อมูล บางตัวเลือกสำหรับการทำเช่นนี้มีอธิบายไว้ในเอกสารที่เสนอโดย IETF ในการทำให้สิ่งนี้เป็นไปได้ เซิร์ฟเวอร์ต้องสามารถเลือก CID ของตนเองได้ ซึ่งจะไม่สามารถทำได้หากตัวเริ่มต้นการเชื่อมต่อ (ซึ่งสำหรับ QUIC จะเป็นไคลเอ็นต์เสมอ) เลือก CID นี่คือสาเหตุที่ CID ของไคลเอ็นต์และเซิร์ฟเวอร์ใน QUIC มีการแบ่งแยก
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
ดังนั้น การย้ายการเชื่อมต่อจึงเป็นคุณลักษณะตามสถานการณ์ ตัวอย่างเช่น การทดสอบเบื้องต้นโดย Google แสดงการปรับปรุงเปอร์เซ็นต์ต่ำสำหรับกรณีการใช้งาน การใช้งาน QUIC จำนวนมากยังไม่ได้ใช้งานคุณลักษณะนี้ แม้แต่สิ่งที่ทำมักจะจำกัดเฉพาะไคลเอ็นต์และแอปบนอุปกรณ์เคลื่อนที่เท่านั้น และไม่เทียบเท่ากับเดสก์ท็อป บางคนถึงกับคิดว่าไม่จำเป็นต้องใช้คุณลักษณะนี้ เนื่องจากการเปิดการเชื่อมต่อใหม่ด้วย 0-RTT ควรมีคุณสมบัติด้านประสิทธิภาพที่คล้ายคลึงกันในกรณีส่วนใหญ่
อย่างไรก็ตาม ขึ้นอยู่กับกรณีการใช้งานหรือโปรไฟล์ผู้ใช้ของคุณ อาจมีผลกระทบอย่างมาก หากเว็บไซต์หรือแอปของคุณถูกใช้บ่อยที่สุดในขณะเดินทาง (เช่น Uber หรือ Google Maps) คุณอาจได้รับประโยชน์มากกว่าการที่ผู้ใช้ของคุณมักจะนั่งอยู่หลังโต๊ะ Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.

Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
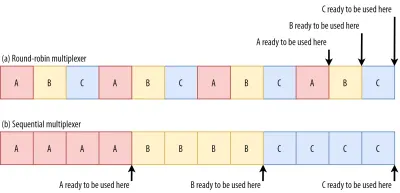
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
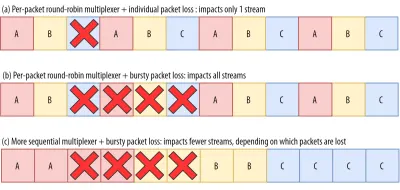
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
ประสิทธิภาพของ UDP และ TLS
ด้านประสิทธิภาพที่ห้าของ QUIC และ HTTP/3 นั้นเกี่ยวกับประสิทธิภาพและประสิทธิภาพที่พวกเขาสามารถ สร้างและส่งแพ็กเก็ต บนเครือข่ายได้จริง เราจะเห็นว่าการใช้ UDP ของ QUIC และการเข้ารหัสที่หนักหน่วงสามารถทำให้ช้ากว่า TCP ได้พอสมควร (แต่สิ่งต่างๆ กำลังดีขึ้น)
อันดับแรก เราได้พูดคุยกันแล้วว่าการใช้งาน UDP ของ QUIC นั้นเกี่ยวกับความยืดหยุ่นและการปรับใช้มากกว่าประสิทธิภาพ สิ่งนี้ชัดเจนยิ่งขึ้นจากข้อเท็จจริงที่ว่า การส่งแพ็กเก็ต QUIC ผ่าน UDP นั้นมักจะช้ากว่าการส่งแพ็กเก็ต TCP มาก จนกระทั่งเมื่อไม่นานมานี้ ส่วนหนึ่งเป็นเพราะว่าโปรโตคอลเหล่านี้มักถูกนำไปใช้ที่ไหนและอย่างไร (ดูรูปที่ 9 ด้านล่าง)
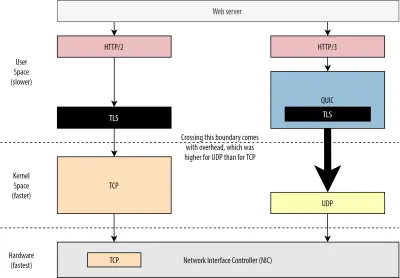
ตามที่กล่าวไว้ข้างต้น โดยทั่วไปแล้ว TCP และ UDP จะถูกนำไปใช้โดยตรงในเคอร์เนลที่รวดเร็วของ OS ในทางตรงกันข้าม การใช้งาน TLS และ QUIC นั้นส่วนใหญ่จะอยู่ในพื้นที่ผู้ใช้ที่ช้ากว่า (โปรดทราบว่าสิ่งนี้ไม่จำเป็นจริงๆ สำหรับ QUIC — ส่วนใหญ่จะทำเสร็จแล้วเพราะมีความยืดหยุ่นมากกว่ามาก) ทำให้ QUIC ช้ากว่า TCP เล็กน้อย
นอกจากนี้ เมื่อส่งข้อมูลจากซอฟต์แวร์พื้นที่ผู้ใช้ของเรา (เช่น เบราว์เซอร์และเว็บเซิร์ฟเวอร์) เราจำเป็นต้อง ส่งข้อมูลนี้ไปยังเคอร์เนลของระบบปฏิบัติการ ซึ่งจะใช้ TCP หรือ UDP เพื่อใส่ลงในเครือข่ายจริงๆ การส่งข้อมูลนี้ทำได้โดยใช้เคอร์เนล API (การเรียกของระบบ) ซึ่งเกี่ยวข้องกับโอเวอร์เฮดจำนวนหนึ่งต่อการเรียก API สำหรับ TCP โอเวอร์เฮดเหล่านี้ต่ำกว่า UDP มาก
สาเหตุส่วนใหญ่เป็นเพราะในอดีต TCP ถูกใช้มากกว่า UDP ด้วยเหตุนี้ เมื่อเวลาผ่านไป จึงได้มีการเพิ่มการเพิ่มประสิทธิภาพหลายอย่างให้กับการใช้งาน TCP และ API ของเคอร์เนล เพื่อลดการส่งแพ็กเก็ตและรับโอเวอร์เฮดให้เหลือน้อยที่สุด ตัวควบคุมอินเทอร์เฟซเครือข่าย (NIC) หลายตัวยังมีฟีเจอร์ออฟโหลดฮาร์ดแวร์ในตัวสำหรับ TCP อย่างไรก็ตาม UDP โชคไม่ดีนัก เนื่องจากการใช้งานที่จำกัดมากกว่านั้นไม่ได้พิสูจน์ให้เห็นถึงการลงทุนในการเพิ่มประสิทธิภาพเพิ่มเติม ในช่วงห้าปีที่ผ่านมา สิ่งนี้ได้เปลี่ยนแปลงไปอย่างโชคดี และ ตั้งแต่นั้นมา OS ส่วนใหญ่ก็ได้เพิ่มตัวเลือกที่ปรับให้เหมาะสมสำหรับ UDP ด้วยเช่นกัน
ประการที่สอง QUIC มีค่าใช้จ่ายจำนวนมากเพราะ เข้ารหัสแต่ละแพ็กเก็ตแยก กัน ซึ่งช้ากว่าการใช้ TLS บน TCP เนื่องจากคุณสามารถเข้ารหัสแพ็กเก็ตเป็นกลุ่ม (สูงสุดประมาณ 16 KB หรือ 11 แพ็กเก็ตในแต่ละครั้ง) ซึ่งมีประสิทธิภาพมากกว่า นี่เป็นการแลกเปลี่ยนอย่างมีสติใน QUIC เนื่องจากการเข้ารหัสจำนวนมากสามารถนำไปสู่การบล็อก HoL ในรูปแบบของตัวเอง
ไม่เหมือนกับจุดแรกที่เราสามารถเพิ่ม API พิเศษเพื่อทำให้ UDP (และ QUIC) เร็วขึ้น ที่นี่ QUIC จะมีข้อเสียโดยธรรมชาติของ TCP + TLS เสมอ อย่างไรก็ตาม สิ่งนี้สามารถจัดการได้ในทางปฏิบัติด้วย ตัวอย่างเช่น ไลบรารีการเข้ารหัสที่ปรับให้เหมาะสมและวิธีการอันชาญฉลาดที่ช่วยให้ส่วนหัวของแพ็กเก็ต QUIC สามารถเข้ารหัสเป็นกลุ่มได้
ด้วยเหตุนี้ แม้ว่า QUIC เวอร์ชันแรกสุดของ Google จะยังคงช้าเป็นสองเท่าของ TCP + TLS แต่สิ่งต่างๆ ก็ดีขึ้นอย่างแน่นอนตั้งแต่นั้นเป็นต้นมา ตัวอย่างเช่น ในการทดสอบล่าสุด QUIC stack ที่ได้รับการปรับแต่งอย่างหนักของ Microsoft สามารถรับ 7.85 Gbps เทียบกับ 11.85 Gbps สำหรับ TCP + TLS ในระบบเดียวกัน (ดังนั้นที่นี่ QUIC นั้นเร็วถึง 66% ของ TCP + TLS)
นี่คือการอัปเดตล่าสุดของ Windows ซึ่งทำให้ UDP เร็วขึ้น (สำหรับการเปรียบเทียบทั้งหมด ปริมาณ UDP ในระบบนั้นอยู่ที่ 19.5 Gbps) เวอร์ชัน QUIC stack ของ Google ที่ปรับให้เหมาะสมที่สุดในปัจจุบันนั้นช้ากว่า TCP + TLS ประมาณ 20% การทดสอบก่อนหน้านี้โดย Fastly บนระบบที่ล้ำหน้าน้อยกว่า และด้วยกลอุบายบางอย่างถึงกับอ้างว่ามีประสิทธิภาพเท่ากัน (ประมาณ 450 Mbps) แสดงให้เห็นว่า QUIC สามารถแข่งขันกับ TCP ได้อย่างแน่นอน ทั้งนี้ขึ้นอยู่กับกรณีการใช้งาน
อย่างไรก็ตาม แม้ว่า QUIC จะช้าเป็นสองเท่าของ TCP + TLS แต่ก็ไม่ได้แย่ขนาดนั้น อย่างแรก การประมวลผล QUIC และ TCP + TLS มักไม่ใช่สิ่งที่หนักที่สุดที่เกิดขึ้นบนเซิร์ฟเวอร์ เนื่องจากตรรกะอื่นๆ (เช่น HTTP, การแคช, การพร็อกซี ฯลฯ) จำเป็นต้องดำเนินการด้วย ด้วยเหตุนี้ คุณจึง ไม่จำเป็นต้องใช้เซิร์ฟเวอร์มากเป็นสองเท่าเพื่อเรียกใช้ QUIC (แต่ยังไม่ชัดเจนว่า จะ มีผลกระทบมากน้อยเพียงใดในศูนย์ข้อมูลจริง เนื่องจากไม่มีบริษัทใหญ่รายใดเปิดเผยข้อมูลเรื่องนี้)
ประการที่สอง ยังมีโอกาสมากมายที่จะเพิ่มประสิทธิภาพการใช้งาน QUIC ในอนาคต ตัวอย่างเช่น เมื่อเวลาผ่านไป การใช้งาน QUIC บางอย่างจะ (บางส่วน) ย้ายไปที่เคอร์เนล OS (เหมือนกับ TCP) หรือเลี่ยงผ่าน (บางส่วนทำไปแล้ว เช่น MsQuic และ Quant) เราสามารถคาดหวังให้ฮาร์ดแวร์เฉพาะ QUIC พร้อมใช้งานได้
ยังคงมีบางกรณีการใช้งานที่ TCP + TLS จะยังคงเป็นตัวเลือกที่ต้องการ ตัวอย่างเช่น Netflix ระบุว่าอาจจะไม่ย้ายไปใช้ QUIC ในเร็วๆ นี้ เนื่องจากลงทุนอย่างมากในการตั้งค่า FreeBSD แบบกำหนดเองเพื่อสตรีมวิดีโอผ่าน TCP + TLS
ในทำนองเดียวกัน Facebook ได้กล่าวว่า QUIC ส่วนใหญ่จะใช้ ระหว่างผู้ใช้ปลายทางและขอบของ CDN แต่ไม่ใช่ระหว่างศูนย์ข้อมูลหรือระหว่างโหนดขอบและเซิร์ฟเวอร์ต้นทาง เนื่องจากโอเวอร์เฮดที่ใหญ่กว่า โดยทั่วไป สถานการณ์ที่มีแบนด์วิดท์สูงมากมักจะสนับสนุน TCP + TLS ต่อไป โดยเฉพาะอย่างยิ่งในอีกไม่กี่ปีข้างหน้า
เธอรู้รึเปล่า?
การเพิ่มประสิทธิภาพกองซ้อนเครือข่ายเป็นรูกระต่ายที่ลึกและทางเทคนิคซึ่งด้านบนเป็นเพียงรอยขีดข่วนบนพื้นผิว (และพลาดความแตกต่างเล็กน้อย) หากคุณกล้าพอหรือต้องการทราบคำศัพท์เช่นGRO/GSO,SO_TXTIME, kernel bypass และsendmmsg()และrecvmmsg()ฉันสามารถแนะนำบทความที่ยอดเยี่ยมเกี่ยวกับการเพิ่มประสิทธิภาพ QUIC โดย Cloudflare และ Fastly ได้เช่นกัน เป็นคำแนะนำโดยละเอียดเกี่ยวกับโค้ดโดย Microsoft และการพูดคุยเชิงลึกจาก Cisco สุดท้าย วิศวกรของ Google ได้ให้คำปราศรัยที่น่าสนใจมากเกี่ยวกับการเพิ่มประสิทธิภาพการใช้งาน QUIC เมื่อเวลาผ่านไป
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
การใช้งานเฉพาะของ QUIC ของโปรโตคอล UDP และ TLS ทำให้ในอดีตช้ากว่า TCP + TLS มาก อย่างไรก็ตาม เมื่อเวลาผ่านไป มีการปรับปรุงหลายอย่าง (และจะดำเนินการต่อไป) ซึ่งปิดช่องว่างไว้บ้าง คุณอาจไม่สังเกตเห็นความคลาดเคลื่อนเหล่านี้ในกรณีการใช้งานทั่วไปของการโหลดหน้าเว็บ แต่อาจทำให้ปวดหัวหากคุณดูแลเซิร์ฟเวอร์ฟาร์มขนาดใหญ่
คุณสมบัติ HTTP/3
จนถึงตอนนี้ เราได้พูดถึงคุณลักษณะด้านประสิทธิภาพใหม่ใน QUIC กับ TCP เป็นหลักแล้ว อย่างไรก็ตาม HTTP/3 กับ HTTP/2 ล่ะ? ตามที่กล่าวไว้ในตอนที่ 1 HTTP/3 เป็น HTTP/2-over-QUIC จริงๆ และด้วยเหตุนี้ จึงไม่มีการเปิดตัวฟีเจอร์ใหม่ขนาดใหญ่ที่แท้จริงในเวอร์ชันใหม่ ซึ่งไม่เหมือนกับการย้ายจาก HTTP/1.1 เป็น HTTP/2 ซึ่งใหญ่กว่ามากและแนะนำคุณลักษณะใหม่ เช่น การบีบอัดส่วนหัว การจัดลำดับความสำคัญของสตรีม และการพุชของเซิร์ฟเวอร์ คุณลักษณะเหล่านี้ทั้งหมดยังคงอยู่ใน HTTP/3 แต่มีความแตกต่างที่สำคัญบางประการเกี่ยวกับวิธีการใช้งานภายใต้ประทุน
ส่วนใหญ่เป็นเพราะวิธีการลบการบล็อก HoL ของ QUIC ดังที่เราได้กล่าวไปแล้ว การสูญเสียสตรีม B ไม่ได้หมายความว่าสตรีม A และ C จะต้องรอการส่งสัญญาณซ้ำของ B เช่นเดียวกับที่ทำผ่าน TCP ดังนั้น หาก A, B และ C ส่งแพ็กเก็ต QUIC ตามลำดับ ข้อมูลของพวกเขาอาจถูกส่งไปยัง (และประมวลผลโดย) เบราว์เซอร์เช่น A, C, B! ต่างจาก TCP ตรงที่ QUIC ไม่ได้ถูกจัดเรียงอย่างสมบูรณ์ ในสตรีมต่างๆ อีกต่อไป!
นี่เป็นปัญหาสำหรับ HTTP/2 ซึ่งอาศัยการเรียงลำดับที่เข้มงวดของ TCP ในการออกแบบคุณสมบัติหลายๆ อย่าง ซึ่งใช้ข้อความควบคุมพิเศษที่สลับกับกลุ่มข้อมูล ใน QUIC ข้อความควบคุมเหล่านี้อาจมาถึง (และนำไปใช้) ในลำดับใดก็ได้ อาจทำให้ฟีเจอร์ต่างๆ ทำ ตรงกันข้ามกับ ที่ตั้งใจไว้! รายละเอียดทางเทคนิคไม่จำเป็นอีกแล้วสำหรับบทความนี้ แต่ครึ่งแรกของบทความนี้ควรให้แนวคิดแก่คุณถึงความซับซ้อนที่โง่เขลาของบทความนี้
ดังนั้นกลไกภายในและการใช้งานคุณลักษณะจึงต้องเปลี่ยนสำหรับ HTTP/3 ตัวอย่างที่เป็นรูปธรรมคือ การบีบอัดส่วนหัว HTTP ซึ่งลดโอเวอร์เฮดของส่วนหัว HTTP ขนาดใหญ่ที่ซ้ำกัน (เช่น คุกกี้และสตริง user-agent) ใน HTTP/2 ทำได้โดยใช้การตั้งค่า HPACK ในขณะที่สำหรับ HTTP/3 มีการปรับเปลี่ยน QPACK ที่ซับซ้อนมากขึ้น ทั้งสองระบบมีคุณสมบัติเดียวกัน (เช่น การบีบอัดส่วนหัว) แต่ในรูปแบบที่แตกต่างกันมาก การอภิปรายทางเทคนิคเชิงลึกที่ยอดเยี่ยมและไดอะแกรมในหัวข้อนี้มีอยู่ในบล็อก Litespeed
สิ่งที่คล้ายคลึงกันนี้เป็นจริงสำหรับคุณลักษณะการจัดลำดับความสำคัญที่ขับเคลื่อนลอจิกมัลติเพล็กซ์สตรีมและเราได้กล่าวไว้ข้างต้นโดยสังเขป ใน HTTP/2 สิ่งนี้ถูกนำมาใช้โดยใช้การตั้งค่า "แผนผังการพึ่งพา" ที่ซับซ้อน ซึ่งพยายามสร้างแบบจำลองทรัพยากรของหน้าทั้งหมดและความสัมพันธ์อย่างชัดเจน (ข้อมูลเพิ่มเติมอยู่ในหัวข้อ "คู่มือขั้นสูงสำหรับการจัดลำดับความสำคัญของทรัพยากร HTTP") การใช้ระบบนี้โดยตรงบน QUIC จะนำไปสู่รูปแบบแผนผังต้นไม้ที่อาจผิดพลาดได้ เนื่องจากการเพิ่มทรัพยากรแต่ละรายการลงในแผนผังจะเป็นข้อความควบคุมที่แยกจากกัน
นอกจากนี้ วิธีการนี้กลับกลายเป็นว่าซับซ้อนโดยไม่จำเป็น นำไปสู่จุดบกพร่องในการใช้งานและความไร้ประสิทธิภาพและประสิทธิภาพย่อยบนเซิร์ฟเวอร์จำนวนมาก ปัญหาทั้งสองได้นำระบบการจัดลำดับความสำคัญในการออกแบบใหม่สำหรับ HTTP/3 ในวิธีที่ง่ายกว่ามาก การตั้งค่าที่ตรงไปตรงมายิ่งขึ้นนี้ทำให้การบังคับใช้สถานการณ์ขั้นสูงบางอย่างยากหรือเป็นไปไม่ได้ (เช่น การพร็อกซีการรับส่งข้อมูลจากไคลเอนต์หลายเครื่องในการเชื่อมต่อเดียว) แต่ยังคงเปิดใช้งานตัวเลือกมากมายสำหรับการเพิ่มประสิทธิภาพการโหลดหน้าเว็บ
ในขณะที่ทั้งสองวิธีนำเสนอคุณลักษณะพื้นฐานที่เหมือนกัน (แนวทางมัลติเพล็กซ์สตรีม) ความหวังก็คือการตั้งค่าที่ง่ายกว่าของ HTTP/3 จะทำให้มีข้อบกพร่องในการใช้งานน้อยลง
ในที่สุดก็มี การพุชเซิร์ฟเวอร์ คุณลักษณะนี้อนุญาตให้เซิร์ฟเวอร์ส่งการตอบกลับ HTTP โดยไม่ต้องรอคำขอที่ชัดเจนสำหรับพวกเขาก่อน ตามทฤษฎีแล้ว สิ่งนี้สามารถให้ประสิทธิภาพที่ยอดเยี่ยม อย่างไรก็ตาม ในทางปฏิบัติ มันกลับกลายเป็นว่ายากต่อการใช้งานอย่างถูกต้องและไม่สอดคล้องกัน ด้วยเหตุนี้ จึงเป็นไปได้ว่าจะถูกลบออกจาก Google Chrome
แม้จะมีทั้งหมดนี้ แต่ ก็ ยังถูกกำหนดให้เป็นคุณลักษณะใน HTTP/3 (แม้ว่าจะมีการใช้งานเพียงไม่กี่อย่างก็ตาม) แม้ว่าการทำงานภายในจะไม่ได้เปลี่ยนแปลงไปมากเท่ากับคุณลักษณะสองประการก่อนหน้านี้ แต่ก็ได้รับการปรับให้เข้ากับการเรียงลำดับแบบไม่กำหนดของ QUIC ด้วยเช่นกัน น่าเศร้าที่วิธีนี้จะช่วยแก้ปัญหาบางอย่างที่มีมายาวนานได้เพียงเล็กน้อย
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
ดังที่เราได้กล่าวไปแล้ว ศักยภาพส่วนใหญ่ของ HTTP/3 นั้นมาจาก QUIC พื้นฐาน ไม่ใช่ HTTP/3 เอง แม้ว่าการใช้งานภายในของโปรโตคอลจะ แตก ต่างจาก HTTP/2 อย่างมาก แต่คุณลักษณะด้านประสิทธิภาพระดับสูงและวิธีการใช้งานและควรใช้ยังคงเหมือนเดิม
การพัฒนาในอนาคตที่น่าจับตามอง
ในชุดนี้ ฉันได้เน้นย้ำอยู่เสมอว่าวิวัฒนาการที่เร็วขึ้นและความยืดหยุ่นที่สูงขึ้นนั้นเป็นองค์ประกอบหลักของ QUIC (และโดยการขยายคือ HTTP/3) ด้วยเหตุนี้ จึงไม่น่าแปลกใจเลยที่ผู้คนกำลัง พัฒนาส่วนขยาย และแอปพลิเคชันใหม่ๆ ของโปรโตคอลอยู่แล้ว รายการด้านล่างนี้เป็นรายการหลักที่คุณอาจพบที่ใดที่หนึ่ง:
ส่งต่อการแก้ไขข้อผิดพลาด
จุดประสงค์ของเทคนิคนี้คือ อีกครั้ง เพื่อ ปรับปรุงความยืดหยุ่นของ QUIC ต่อการสูญเสียแพ็กเก็ต ทำได้โดยส่งสำเนาข้อมูลซ้ำซ้อน (แม้ว่าจะเข้ารหัสและบีบอัดอย่างชาญฉลาดเพื่อไม่ให้มีขนาดใหญ่) จากนั้น หากแพ็กเก็ตสูญหายแต่มีข้อมูลสำรองเข้ามา ก็ไม่จำเป็นต้องทำการส่งข้อมูลซ้ำอีกต่อไป
เดิมเป็นส่วนหนึ่งของ Google QUIC (และเป็นหนึ่งในเหตุผลที่ผู้คนบอกว่า QUIC ดีต่อการสูญเสียแพ็กเก็ต) แต่จะไม่รวมอยู่ใน QUIC เวอร์ชัน 1 ที่เป็นมาตรฐาน เนื่องจากยังไม่ได้รับการพิสูจน์ผลกระทบด้านประสิทธิภาพ ขณะนี้นักวิจัยกำลังทำการทดลองกับมันอยู่ และคุณสามารถช่วยเหลือพวกเขาได้โดยใช้แอปดาวน์โหลด PQUIC-FEC Download ExperimentsMultipath QUIC
ก่อนหน้านี้เราได้พูดถึงการย้ายการเชื่อมต่อและวิธีที่จะช่วยได้เมื่อย้ายจาก Wi-Fi ไปยังเซลลูลาร์ อย่างไรก็ตาม นั่นไม่ได้หมายความว่าเราอาจใช้ทั้ง Wi-Fi และเซลลูลาร์ พร้อมกัน ใช่หรือไม่ การใช้ทั้งสองเครือข่ายพร้อมกันจะทำให้เรามีแบนด์วิดท์ที่มากขึ้นและมีประสิทธิภาพมากขึ้น! นั่นคือแนวคิดหลักที่อยู่เบื้องหลัง multipath
นี่เป็นอีกครั้งที่ Google ทดลองด้วย แต่ไม่ได้ทำให้เป็น QUIC เวอร์ชัน 1 เนื่องจากความซับซ้อนโดยธรรมชาติ อย่างไรก็ตาม นักวิจัยได้แสดงศักยภาพที่สูงตั้งแต่นั้นมา และอาจทำให้มันเป็น QUIC เวอร์ชัน 2 โปรดทราบว่า TCP multipath ก็มีอยู่เช่นกัน แต่ต้องใช้เวลาเกือบทศวรรษกว่าจะสามารถใช้งานได้จริงข้อมูลที่ไม่น่าเชื่อถือผ่าน QUIC และ HTTP/3
ดังที่เราได้เห็นแล้วว่า QUIC เป็นโปรโตคอลที่เชื่อถือได้อย่างสมบูรณ์ อย่างไรก็ตาม เนื่องจากมันทำงานบน UDP ซึ่งไม่น่าเชื่อถือ เราจึงสามารถเพิ่มคุณสมบัติให้กับ QUIC เพื่อส่งข้อมูลที่ไม่น่าเชื่อถือได้เช่นกัน นี่คือโครงร่างในส่วนขยายดาตาแกรมที่เสนอ แน่นอนว่าคุณไม่ต้องการใช้สิ่งนี้เพื่อส่งทรัพยากรของหน้าเว็บ แต่อาจมีประโยชน์สำหรับสิ่งต่าง ๆ เช่นการเล่นเกมและการสตรีมวิดีโอสด ด้วยวิธีนี้ ผู้ใช้จะได้รับประโยชน์ทั้งหมดจาก UDP แต่ด้วยการเข้ารหัสระดับ QUIC และการควบคุมความแออัด (ทางเลือก)เว็บขนส่ง
เบราว์เซอร์ไม่เปิดเผย TCP หรือ UDP ต่อ JavaScript โดยตรง สาเหตุหลักมาจากปัญหาด้านความปลอดภัย แต่เราต้องพึ่งพา API ระดับ HTTP เช่น Fetch และโปรโตคอล WebSocket และ WebRTC ที่ค่อนข้างยืดหยุ่นกว่า ตัวเลือกใหม่ล่าสุดในชุดตัวเลือกนี้เรียกว่า WebTransport ซึ่งส่วนใหญ่อนุญาตให้คุณใช้ HTTP/3 (และโดยส่วนขยาย QUIC) ในระดับที่ต่ำกว่า (แม้ว่าจะสามารถถอยกลับไปเป็น TCP และ HTTP/2 ได้หากจำเป็น ).
สิ่งสำคัญที่สุดคือจะรวมถึงความสามารถในการใช้ข้อมูลที่ไม่น่าเชื่อถือผ่าน HTTP/3 (ดูจุดก่อนหน้า) ซึ่งจะทำให้สิ่งต่าง ๆ เช่นการเล่นเกมใช้งานในเบราว์เซอร์ได้ง่ายขึ้นเล็กน้อย สำหรับการเรียก API (JSON) ตามปกติ คุณจะต้องยังคงใช้การดึงข้อมูล ซึ่งจะใช้ HTTP/3 โดยอัตโนมัติเมื่อเป็นไปได้ ขณะนี้ WebTransport ยังคงอยู่ภายใต้การอภิปรายอย่างหนัก ดังนั้นจึงยังไม่ชัดเจนว่าในที่สุดจะเป็นอย่างไร ในเบราว์เซอร์ มีเพียง Chromium เท่านั้นที่กำลังทำงานเกี่ยวกับการนำแนวคิดการพิสูจน์แนวคิดสาธารณะไปใช้การสตรีมวิดีโอ DASH และ HLS
สำหรับวิดีโอที่ไม่ถ่ายทอดสด (คิดว่าเป็น YouTube และ Netflix) เบราว์เซอร์มักใช้โปรโตคอล Dynamic Adaptive Streaming ผ่าน HTTP (DASH) หรือ HTTP Live Streaming (HLS) โดยพื้นฐานแล้วทั้งคู่หมายความว่าคุณเข้ารหัสวิดีโอของคุณเป็นชิ้นเล็กๆ (จาก 2 ถึง 10 วินาที) และระดับคุณภาพที่แตกต่างกัน (720p, 1080p, 4K เป็นต้น)
ในขณะรันไทม์ เบราว์เซอร์จะประเมินคุณภาพสูงสุดที่เครือข่ายของคุณสามารถจัดการได้ (หรือเหมาะสมที่สุดสำหรับกรณีการใช้งานที่กำหนด) และขอไฟล์ที่เกี่ยวข้องจากเซิร์ฟเวอร์ผ่าน HTTP เนื่องจากเบราว์เซอร์ไม่มีการเข้าถึงโดยตรงไปยังสแต็ก TCP (ตามที่มักใช้ในเคอร์เนล) จึงเกิดข้อผิดพลาดเล็กน้อยในการประมาณการเหล่านี้ หรือต้องใช้เวลาสักครู่เพื่อตอบสนองต่อสภาวะเครือข่ายที่เปลี่ยนแปลง (นำไปสู่แผงวิดีโอ) .
เนื่องจากมีการใช้ QUIC เป็นส่วนหนึ่งของเบราว์เซอร์ จึงควรปรับปรุงให้ดีขึ้นเล็กน้อย โดยให้ตัวประมาณการสตรีมเข้าถึงข้อมูลโปรโตคอลระดับต่ำ (เช่น อัตราการสูญเสีย การประมาณการแบนด์วิดท์ ฯลฯ) นักวิจัยคนอื่นๆ ได้ทดลองผสมข้อมูลที่เชื่อถือได้และไม่น่าเชื่อถือสำหรับการสตรีมวิดีโอด้วย โดยให้ผลลัพธ์ที่น่าพึงพอใจโปรโตคอลอื่นที่ไม่ใช่ HTTP/3
เนื่องจาก QUIC เป็นโปรโตคอลการขนส่งสำหรับใช้งานทั่วไป เราสามารถคาดหวังให้โปรโตคอลเลเยอร์แอปพลิเคชันจำนวนมากที่ตอนนี้ทำงานบน TCP ทำงานบน QUIC ได้เช่นกัน งานที่กำลังดำเนินการอยู่ ได้แก่ DNS-over-QUIC, SMB-over-QUIC และแม้แต่ SSH-over-QUIC เนื่องจากโปรโตคอลเหล่านี้มักมีข้อกำหนดที่แตกต่างจาก HTTP และการโหลดหน้าเว็บอย่างมาก การปรับปรุงประสิทธิภาพของ QUIC ที่เราได้พูดคุยกันอาจทำงานได้ดีกว่ามากสำหรับโปรโตคอลเหล่านี้
มันไม่สิ่งที่ทุกคนหมายถึงอะไร?
QUIC เวอร์ชัน 1 เป็น เพียงการเริ่มต้น คุณลักษณะที่เน้นประสิทธิภาพขั้นสูงหลายอย่างที่ Google ได้ทดลองใช้ก่อนหน้านี้ไม่ได้ทำให้เป็นซ้ำในครั้งแรกนี้ อย่างไรก็ตาม เป้าหมายคือการพัฒนาโปรโตคอลอย่างรวดเร็ว โดยแนะนำส่วนขยายและคุณลักษณะใหม่ๆ ที่ความถี่สูง ดังนั้น เมื่อเวลาผ่านไป QUIC (และ HTTP/3) น่าจะเร็วกว่าและยืดหยุ่นกว่า TCP (และ HTTP/2) อย่างเห็นได้ชัด
บทสรุป
ในส่วนที่สองของซีรีส์นี้ เราได้พูดถึง คุณลักษณะด้านประสิทธิภาพและแง่มุมต่างๆ ของ HTTP/3 และโดยเฉพาะอย่างยิ่ง QUIC เราพบว่าแม้ว่าคุณลักษณะเหล่านี้ส่วนใหญ่จะดูมีผลกระทบอย่างมาก แต่ในทางปฏิบัติแล้ว คุณลักษณะเหล่านี้อาจไม่สามารถทำอะไรได้มากสำหรับผู้ใช้ทั่วไปในกรณีการใช้งานของการโหลดหน้าเว็บที่เรากำลังพิจารณาอยู่
ตัวอย่างเช่น เราพบว่าการใช้ UDP ของ QUIC ไม่ได้หมายความว่าจะสามารถใช้แบนด์วิดท์มากกว่า TCP ได้ในทันที และไม่ได้หมายความว่าจะสามารถดาวน์โหลดทรัพยากรของคุณได้เร็วยิ่งขึ้น คุณลักษณะ 0-RTT ที่มักยกย่องคือการปรับให้เหมาะสมระดับจุลภาคจริงๆ ซึ่งช่วยให้คุณประหยัดเวลาไปกลับหนึ่งเที่ยว ซึ่งคุณสามารถส่งได้ประมาณ 5 KB (ในกรณีที่เลวร้ายที่สุด)
การลบการบล็อก HoL ทำงานได้ไม่ดีหากมี การสูญหายของแพ็คเก็ตแบบ ต่อเนื่องหรือเมื่อคุณกำลังโหลดทรัพยากรการบล็อกการแสดงผล การโยกย้ายการเชื่อมต่อมีสถานการณ์สูง และ HTTP/3 ไม่มีคุณลักษณะใหม่ที่สำคัญที่สามารถทำให้เร็วกว่า HTTP/2
ดังนั้น คุณอาจคาดหวังให้ฉันแนะนำให้คุณข้าม HTTP/3 และ QUIC ทำไมต้องรำคาญใช่มั้ย? อย่างไรก็ตาม ข้าจะไม่ทำอย่างนั้นอย่างแน่นอน! แม้ว่าโปรโตคอลใหม่เหล่านี้อาจไม่ได้ช่วยเหลือผู้ใช้ในเครือข่ายที่รวดเร็ว (ในเมือง) มากนัก แต่ฟีเจอร์ใหม่นี้มีศักยภาพที่จะส่ง ผลกระทบอย่างสูงต่อผู้ใช้มือถือ และผู้คนในเครือข่ายที่ช้าอย่างแน่นอน
แม้แต่ในตลาดตะวันตก เช่น เบลเยี่ยมของฉันเอง ซึ่งโดยทั่วไปแล้วเรามีอุปกรณ์ที่รวดเร็วและการเข้าถึงเครือข่ายเซลลูลาร์ความเร็วสูง สถานการณ์เหล่านี้สามารถส่งผลกระทบต่อ 1% ถึง 10% ของฐานผู้ใช้ของคุณ ขึ้นอยู่กับผลิตภัณฑ์ของคุณ ตัวอย่างคือบางคนบนรถไฟพยายามอย่างยิ่งที่จะค้นหาข้อมูลสำคัญบนเว็บไซต์ของคุณ แต่ต้องรอ 45 วินาทีจึงจะโหลดได้ ฉันรู้แน่นอนว่าฉันเคยอยู่ในสถานการณ์นั้น และอยากให้ใครซักคนใช้ QUIC เพื่อพาฉันออกไป
อย่างไรก็ตาม ยังมีประเทศและภูมิภาคอื่นๆ ที่สิ่งต่างๆ ยังแย่กว่านั้นมาก ที่นั่น ผู้ใช้โดยเฉลี่ยอาจดูเหมือนผู้ใช้ที่ช้าที่สุดในเบลเยียม 10% มากกว่ามาก และ 1% ที่ช้าที่สุดอาจไม่เห็นหน้าที่โหลดเลย ในหลายส่วนของโลก ประสิทธิภาพของเว็บคือปัญหาด้านการเข้าถึงและการผนวกรวม
นี่คือเหตุผลที่เราไม่ควรทดสอบหน้าเว็บของเราบนฮาร์ดแวร์ของเราเอง (แต่ยังใช้บริการเช่น Webpagetest) และเหตุผลที่คุณควร ปรับใช้ QUIC และ HTTP/3 อย่างแน่นอน โดยเฉพาะอย่างยิ่ง ถ้าผู้ใช้ของคุณมักเดินทางหรือแทบไม่มีโอกาสเข้าถึงเครือข่ายเซลลูลาร์ที่รวดเร็ว โปรโตคอลใหม่เหล่านี้อาจสร้างโลกแห่งความแตกต่าง แม้ว่าคุณจะไม่ได้สังเกตอะไรมากใน MacBook Pro แบบมีสายก็ตาม สำหรับรายละเอียดเพิ่มเติม ฉันขอแนะนำโพสต์ของ Fastly เกี่ยวกับประเด็นนี้
หากนั่นไม่ทำให้คุณเชื่อมั่นอย่างเต็มที่ ให้พิจารณาว่า QUIC และ HTTP/3 จะ ยังคงพัฒนาต่อไปและเร็วขึ้น ในปีต่อๆ ไป การได้รับประสบการณ์ใช้งานตั้งแต่เนิ่นๆ กับโปรโตคอลจะคุ้มค่า ช่วยให้คุณได้รับประโยชน์จากคุณสมบัติใหม่โดยเร็วที่สุด นอกจากนี้ QUIC ยังบังคับใช้แนวทางปฏิบัติที่ดีที่สุดด้านความปลอดภัยและความเป็นส่วนตัวในเบื้องหลัง ซึ่งเป็นประโยชน์ต่อผู้ใช้ทุกคนทุกที่
ในที่สุดก็มั่นใจ? จากนั้นไปต่อในตอนที่ 3 ของซีรีส์นี้เพื่ออ่านเกี่ยวกับวิธีใช้งานโปรโตคอลใหม่ในทางปฏิบัติ
- ส่วนที่ 1: ประวัติ HTTP/3 และแนวคิดหลัก
บทความนี้มุ่งเป้าไปที่ผู้ที่เพิ่งเริ่มใช้ HTTP/3 และโปรโตคอลโดยทั่วไป และกล่าวถึงพื้นฐานเป็นหลัก - ส่วนที่ 2: คุณสมบัติประสิทธิภาพ HTTP/3
อันนี้เชิงลึกและเชิงเทคนิคมากกว่า ผู้ที่รู้พื้นฐานอยู่แล้วสามารถเริ่มต้นได้ที่นี่ - ส่วนที่ 3: ตัวเลือกการปรับใช้ HTTP/3 ที่ใช้งานได้จริง
บทความที่สามในชุดนี้อธิบายความท้าทายที่เกี่ยวข้องกับการปรับใช้และทดสอบ HTTP/3 ด้วยตัวคุณเอง โดยมีรายละเอียดว่าคุณควรเปลี่ยนหน้าเว็บและแหล่งข้อมูลอย่างไรและควรทำอย่างไร