
วิธีการใช้การจำแนกประเภทในการเรียนรู้ของเครื่อง?
เผยแพร่แล้ว: 2021-03-12การประยุกต์ใช้แมชชีนเลิร์นนิงในสาขาต่างๆ เพิ่มขึ้นอย่างก้าวกระโดดในช่วงไม่กี่ปีที่ผ่านมา และยังคงเป็นเช่นนั้นต่อไป งานยอดนิยมอย่างหนึ่งของโมเดล Machine Learning คือการจดจำวัตถุและแยกวัตถุออกเป็นชั้นเรียนที่กำหนด
นี่เป็นวิธีการจำแนกประเภทที่เป็นหนึ่งในแอพพลิเคชั่นยอดนิยมของ Machine Learning การจำแนกประเภทใช้เพื่อแยกข้อมูลจำนวนมากออกเป็นชุดของค่าที่ไม่ต่อเนื่องซึ่งอาจเป็นเลขฐานสอง เช่น 0/1, ใช่/ไม่ใช่ หรือหลายชั้น เช่น สัตว์ รถยนต์ นก เป็นต้น
ในบทความต่อไปนี้ เราจะเข้าใจแนวคิดของการจำแนกประเภทในการเรียนรู้ของเครื่อง ประเภทของข้อมูลที่เกี่ยวข้อง และดูอัลกอริธึมการจำแนกประเภทที่ได้รับความนิยมมากที่สุดซึ่งใช้ในการเรียนรู้ของเครื่องเพื่อจัดประเภทข้อมูลต่างๆ
สารบัญ
การเรียนรู้ภายใต้การดูแลคืออะไร?
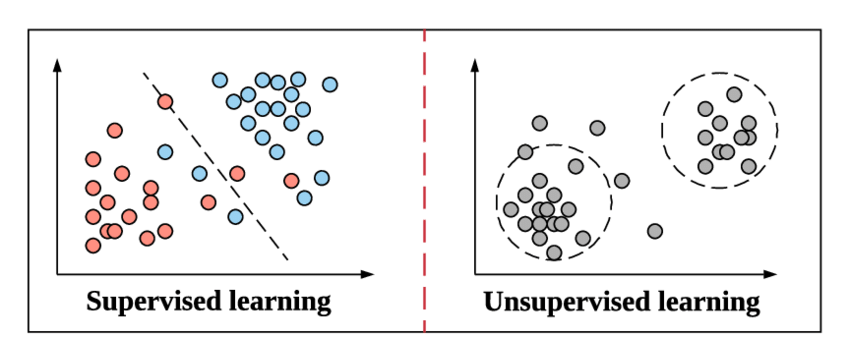
ในขณะที่เราพร้อมที่จะดำดิ่งสู่แนวคิดของการจำแนกประเภทและประเภทของมัน ให้เรารีเฟรชตัวเองอย่างรวดเร็วด้วยความหมายของการเรียนรู้ภายใต้การดูแล และความแตกต่างจากวิธีการอื่นของการเรียนรู้แบบไม่ต้องดูแลในการเรียนรู้ของเครื่อง
ให้เราเข้าใจสิ่งนี้โดยยกตัวอย่างง่ายๆ จากชั้นเรียนฟิสิกส์ในโรงเรียนมัธยมศึกษาตอนปลาย สมมติว่ามีปัญหาง่าย ๆ ที่เกี่ยวข้องกับวิธีการใหม่ หากเราถูกนำเสนอคำถามที่เราต้องแก้ปัญหาโดยใช้วิธีการเดียวกัน เราทุกคนจะไม่อ้างถึงปัญหาตัวอย่างด้วยวิธีเดียวกันและพยายามแก้ไขหรือไม่ เมื่อเรามั่นใจในวิธีการนั้นแล้ว เราก็ไม่ต้องอ้างอิงอีกและดำเนินการแก้ไขต่อไป
แหล่งที่มา

นี่เป็นวิธีเดียวกับที่ Supervised Learning ทำงานในแมชชีนเลิร์นนิง มันเรียนรู้จากตัวอย่าง เพื่อให้ง่ายยิ่งขึ้นใน Supervised Learning ข้อมูลทั้งหมดจะถูกป้อนด้วยป้ายกำกับที่เกี่ยวข้อง ดังนั้นในระหว่างกระบวนการฝึกอบรม โมเดล Machine Learning จะเปรียบเทียบผลลัพธ์สำหรับข้อมูลเฉพาะกับผลลัพธ์ที่แท้จริงของข้อมูลเดียวกันและพยายาม ลดข้อผิดพลาดระหว่างค่าฉลากที่คาดการณ์ไว้และค่าจริง
อัลกอริทึมการจัดประเภทที่เราจะพูดถึงในบทความนี้จะใช้วิธีการเรียนรู้ภายใต้การดูแลนี้ เช่น การตรวจจับสแปมและการรับรู้วัตถุ
Unsupervised Learning เป็นขั้นตอนข้างต้นซึ่งข้อมูลจะไม่ถูกป้อนด้วยป้ายกำกับ ขึ้นอยู่กับความรับผิดชอบและประสิทธิภาพของโมเดล Machine Learning ในการหารูปแบบจากข้อมูลและให้ผลลัพธ์ อัลกอริธึมการจัดกลุ่มทำตามวิธีการเรียนรู้แบบไม่มีผู้ดูแล
การจำแนกประเภทคืออะไร?
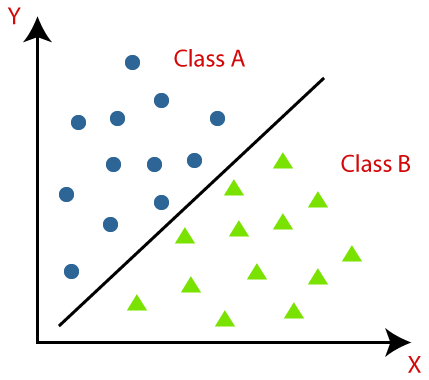
การจัดประเภทหมายถึงการรับรู้ ความเข้าใจ และการจัดกลุ่มวัตถุหรือข้อมูลเป็นคลาสที่กำหนดไว้ล่วงหน้า โดยการจัดหมวดหมู่ข้อมูลก่อนกระบวนการฝึกอบรมของโมเดล Machine Learning เราสามารถใช้อัลกอริธึมการจำแนกประเภทต่างๆ เพื่อจำแนกข้อมูลออกเป็นหลายคลาส ปัญหาการจำแนกประเภทต่างจาก Regression คือเมื่อตัวแปรเอาต์พุตเป็นหมวดหมู่ เช่น "ใช่" หรือ "ไม่ใช่" หรือ "โรค" หรือ "ไม่มีโรค"
ในปัญหาส่วนใหญ่ของ Machine Learning เมื่อโหลดชุดข้อมูลลงในโปรแกรมแล้ว ก่อนการฝึก ให้แยกชุดข้อมูลออกเป็นชุดการฝึกและชุดทดสอบที่มีอัตราส่วนคงที่ (โดยปกติคือ ชุดการฝึก 70% และชุดทดสอบ 30%) กระบวนการแยกส่วนนี้อนุญาตให้โมเดลดำเนินการ backpropagation โดยที่มันพยายามแก้ไขข้อผิดพลาดของค่าที่ทำนายไว้กับค่าจริงโดยการประมาณทางคณิตศาสตร์หลายๆ ครั้ง
ในทำนองเดียวกัน ก่อนที่เราจะเริ่มต้นการจำแนกประเภท ชุดข้อมูลการฝึกอบรมจะถูกสร้างขึ้น อัลกอริธึมการจำแนกประเภทได้รับการฝึกอบรมในขณะที่ทดสอบชุดข้อมูลทดสอบด้วยการวนซ้ำแต่ละครั้ง เรียกว่ายุค
แหล่งที่มา
แอปพลิเคชันอัลกอริธึมการจัดหมวดหมู่ที่พบบ่อยที่สุดตัวหนึ่งคือการกรองอีเมลว่าเป็น "สแปม" หรือ "ไม่ใช่สแปม" กล่าวโดยย่อ เราสามารถกำหนด Classification ใน Machine Learning ให้เป็นรูปแบบ "Pattern Recognition" ซึ่งอัลกอริธึมเหล่านี้ที่ใช้กับข้อมูลการฝึกอบรมใช้เพื่อแยกรูปแบบต่างๆ ออกจากข้อมูล (เช่น คำหรือลำดับตัวเลข ความรู้สึก ฯลฯ ที่คล้ายคลึงกัน .)
การจัดประเภทเป็นกระบวนการของการจัดประเภทชุดข้อมูลที่กำหนดเป็นคลาส สามารถทำได้ทั้งกับข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้าง เริ่มต้นด้วยการทำนายคลาสของจุดข้อมูลที่กำหนด คลาสเหล่านี้เรียกอีกอย่างว่าตัวแปรเอาต์พุต ป้ายชื่อเป้าหมาย ฯลฯ อัลกอริธึมหลายตัวมีฟังก์ชันทางคณิตศาสตร์ในตัวเพื่อประมาณฟังก์ชันการแมปจากตัวแปรจุดข้อมูลอินพุตไปยังคลาสเป้าหมายเอาต์พุต เป้าหมายหลักของการจัดประเภทคือการระบุว่าข้อมูลใหม่จะจัดอยู่ในประเภท/หมวดหมู่ใด
ประเภทของอัลกอริทึมการจำแนกประเภทในการเรียนรู้ของเครื่อง
ขึ้นอยู่กับประเภทของข้อมูลที่ใช้อัลกอริทึมการจำแนกประเภท มีอัลกอริธึมกว้างๆ สองประเภท ได้แก่ โมเดลเชิงเส้นและโมเดลไม่เชิงเส้น
โมเดลเชิงเส้น
- การถดถอยโลจิสติก
- รองรับเวคเตอร์แมชชีน (SVM)
โมเดลที่ไม่ใช่เชิงเส้น
- การจำแนกประเภท K-Nearest Neighbors (KNN)
- เคอร์เนล SVM
- การจำแนก Naive Bayes
- การจำแนกต้นไม้การตัดสินใจ
- การจำแนกป่าแบบสุ่ม
ในบทความนี้ เราจะอธิบายสั้น ๆ เกี่ยวกับแนวคิดเบื้องหลังแต่ละอัลกอริทึมที่กล่าวถึงข้างต้น
การประเมินแบบจำลองการจำแนกในการเรียนรู้ของเครื่อง
ก่อนที่เราจะพูดถึงแนวคิดของอัลกอริทึมเหล่านี้ที่กล่าวถึงข้างต้น เราต้องเข้าใจวิธีที่เราสามารถประเมินแบบจำลองการเรียนรู้ของเครื่องของเราที่สร้างขึ้นจากอัลกอริทึมเหล่านี้ จำเป็นต้องประเมินแบบจำลองของเราเพื่อความแม่นยำทั้งในชุดฝึกและชุดทดสอบ
การสูญเสียเอนโทรปีหรือการสูญเสียบันทึก
นี่เป็นฟังก์ชันการสูญเสียประเภทแรกที่เราจะใช้ในการประเมินประสิทธิภาพของตัวแยกประเภทซึ่งมีเอาต์พุตอยู่ระหว่าง 0 ถึง 1 ซึ่งส่วนใหญ่จะใช้สำหรับโมเดลการจำแนกแบบไบนารี สูตร Log Loss กำหนดโดย
บันทึกการสูญเสีย = -((1 – y) * บันทึก (1 – yhat) + y * บันทึก (yhat))
โดยที่นั่นคือค่าที่ทำนายไว้ และ y คือค่าจริง
เมทริกซ์ความสับสน
เมทริกซ์ความสับสนคือเมทริกซ์ NXN โดยที่ N คือจำนวนคลาสที่คาดการณ์ เมทริกซ์ความสับสนทำให้เรามีเมทริกซ์/ตารางเป็นเอาต์พุตและอธิบายประสิทธิภาพของโมเดล ประกอบด้วยผลการคาดคะเนในรูปแบบของเมทริกซ์ซึ่งเราสามารถหาตัววัดประสิทธิภาพหลายตัวเพื่อประเมินแบบจำลองการจำแนกประเภท เป็นรูปเป็นร่าง,
| บวกจริง | เชิงลบที่เกิดขึ้นจริง | |
| คาดการณ์ในเชิงบวก | ทรูบวก | บวกเท็จ |
| คาดการณ์เชิงลบ | ลบเท็จ | ทรูเนกาทีฟ |
ตัวชี้วัดประสิทธิภาพบางส่วนที่สามารถดึงมาจากตารางด้านบนแสดงไว้ด้านล่าง
1.ความแม่นยำ – สัดส่วนของจำนวนคำทำนายที่ถูกต้องทั้งหมด
2. Positive Predictive Value หรือ Precision – สัดส่วนของกรณีบวกที่ระบุอย่างถูกต้อง
3. Negative Predictive Value – สัดส่วนของกรณีเชิงลบที่ระบุอย่างถูกต้อง
4. Sensitivity or Recall – สัดส่วนของกรณีบวกที่เกิดขึ้นจริงซึ่งระบุได้อย่างถูกต้อง
5. ความจำเพาะ – สัดส่วนของกรณีเชิงลบที่เกิดขึ้นจริงซึ่งระบุได้อย่างถูกต้อง
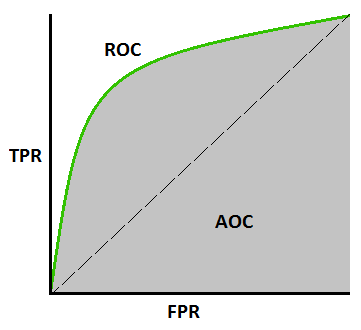
AUC-ROC เคิร์ฟ –
นี่เป็นเมตริกเส้นโค้งที่สำคัญอีกตัวหนึ่งที่ประเมินโมเดลแมชชีนเลิร์นนิง เส้นโค้ง ROC ย่อมาจาก Curve ลักษณะการทำงานของตัวรับ และ AUC ย่อมาจาก พื้นที่ใต้เส้นโค้ง กราฟ ROC ถูกพล็อตด้วย TPR และ FPR โดยที่ TPR (True Positive Rate) บนแกน Y และ FPR (False Positive Rate) บนแกน X จะแสดงประสิทธิภาพของแบบจำลองการจัดประเภทที่เกณฑ์ต่างๆ
แหล่งที่มา
1. การถดถอยโลจิสติก
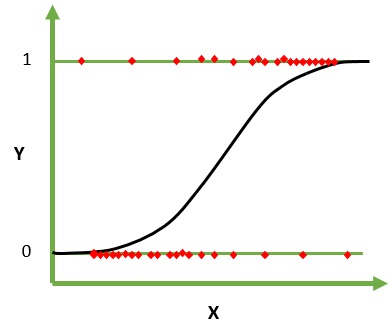
Logistic Regression เป็นอัลกอริธึมการเรียนรู้ของเครื่องสำหรับการจำแนกประเภท ในอัลกอริธึมนี้ ความน่าจะเป็นที่อธิบายผลลัพธ์ที่เป็นไปได้ของการทดลองครั้งเดียวนั้นถูกจำลองโดยใช้ฟังก์ชันลอจิสติกส์ โดยถือว่าตัวแปรอินพุตเป็นตัวเลขและมีการแจกแจงแบบเกาส์เซียน (เส้นโค้งระฆัง)
ฟังก์ชันลอจิสติกส์ หรือที่เรียกว่าฟังก์ชันซิกมอยด์ เริ่มแรกใช้โดยนักสถิติเพื่ออธิบายการเติบโตของประชากรในระบบนิเวศ ฟังก์ชัน sigmoid เป็นฟังก์ชันทางคณิตศาสตร์ที่ใช้ในการจับคู่ค่าที่คาดการณ์ไว้กับความน่าจะเป็น Logistic Regression มีเส้นโค้งรูปตัว S และสามารถรับค่าได้ระหว่าง 0 ถึง 1 แต่ไม่เคยอยู่ที่ขีดจำกัดนั้นแน่นอน

แหล่งที่มา
Logistic Regression ใช้เพื่อทำนายผลลัพธ์ไบนารีเป็นหลัก เช่น ใช่/ไม่ใช่ และ ผ่าน/ไม่ผ่าน ตัวแปรอิสระสามารถจัดหมวดหมู่หรือเป็นตัวเลขได้ แต่ตัวแปรตามจะเป็นการจัดหมวดหมู่เสมอ สูตรสำหรับการถดถอยโลจิสติกถูกกำหนดโดย
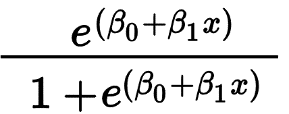
โดยที่ e แทนเส้นโค้งรูปตัว S ซึ่งมีค่าระหว่าง 0 ถึง 1
2. รองรับเครื่องเวกเตอร์
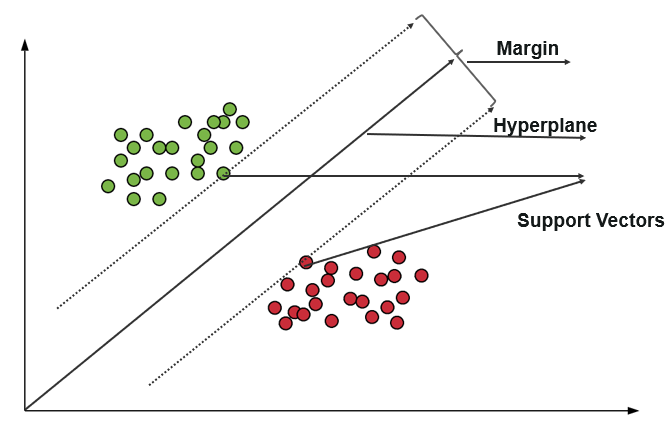
Support vector machine (SVM) ใช้อัลกอริธึมในการฝึกและจำแนกข้อมูลภายในระดับของขั้ว ทำให้เกินการทำนาย X/Y ใน SVM บรรทัดที่ใช้แยกคลาสเรียกว่า Hyperplane จุดข้อมูลที่ด้านใดด้านหนึ่งของไฮเปอร์เพลนที่ใกล้กับไฮเปอร์เพลนที่สุดเรียกว่า Support Vectors ที่ใช้ในการพล็อตเส้นเขต
Support Vector Machine ใน Classification นี้แสดงข้อมูลการฝึกเป็นจุดข้อมูลในพื้นที่ซึ่งหลายหมวดหมู่แยกเป็นหมวดหมู่ Hyperplane เมื่อมีจุดใหม่เข้ามา จะจัดประเภทตามการคาดการณ์ว่าอยู่ในหมวดหมู่ใดและอยู่ในพื้นที่เฉพาะ
แหล่งที่มา
เป้าหมายหลักของเครื่อง Support Vector คือการเพิ่มระยะขอบระหว่าง Support Vectors ทั้งสองให้มากที่สุด
เข้าร่วม หลักสูตร ML ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท โปรแกรม Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
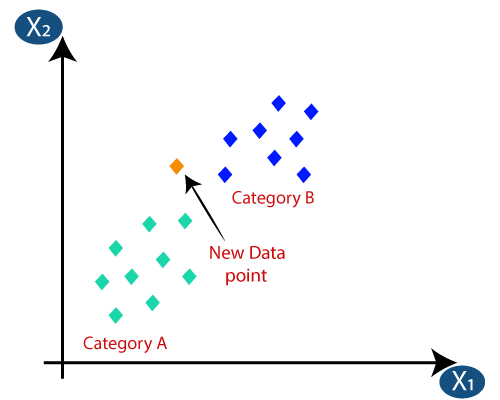
3. การจำแนก K-Nearest Neighbors (KNN)
KNN Classification เป็นหนึ่งในอัลกอริธึมที่ง่ายที่สุดในการจำแนกประเภท แต่มีการนำไปใช้อย่างมากเนื่องจากมีประสิทธิภาพสูงและใช้งานง่าย ในวิธีนี้ ชุดข้อมูลทั้งหมดจะถูกจัดเก็บไว้ในเครื่องตั้งแต่แรก จากนั้นเลือกค่า – k ซึ่งแทนจำนวนเพื่อนบ้าน ด้วยวิธีนี้ เมื่อมีการเพิ่มจุดข้อมูลใหม่ลงในชุดข้อมูล จะใช้คะแนนเสียงข้างมากของป้ายกำกับระดับเพื่อนบ้านที่ใกล้ที่สุด k ไปยังจุดข้อมูลใหม่นั้น ด้วยการลงคะแนนนี้ จุดข้อมูลใหม่จะถูกเพิ่มไปยังชั้นเรียนนั้นๆ ด้วยคะแนนโหวตสูงสุด
แหล่งที่มา
4. เคอร์เนล SVM
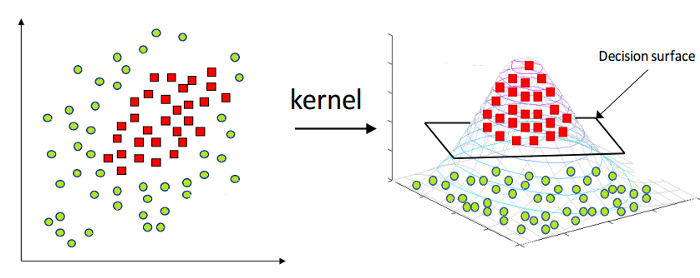
ตามที่กล่าวไว้ข้างต้น Linear Support Vector Machine สามารถใช้ได้กับข้อมูลเชิงเส้นในธรรมชาติเท่านั้น อย่างไรก็ตาม ข้อมูลทั้งหมดในโลกนี้ไม่สามารถแบ่งแยกแบบเชิงเส้นได้ ดังนั้นเราจึงจำเป็นต้องพัฒนา Support Vector Machine เพื่อพิจารณาข้อมูลที่ไม่สามารถแยกออกเชิงเส้นได้ เคล็ดลับ Kernel หรือที่เรียกว่า Kernel Support Vector Machine หรือ Kernel SVM มาถึงแล้ว
ใน Kernel SVM เราเลือกเคอร์เนล เช่น RBF หรือ Gaussian Kernel จุดข้อมูลทั้งหมดถูกแมปไปยังมิติที่สูงกว่า โดยที่จุดข้อมูลเหล่านี้แยกออกได้เป็นเส้นตรง ด้วยวิธีนี้ เราสามารถสร้างขอบเขตการตัดสินใจระหว่างคลาสต่างๆ ของชุดข้อมูล
แหล่งที่มา
ดังนั้น ด้วยวิธีนี้ โดยใช้แนวคิดพื้นฐานของ Support Vector Machines เราจึงสามารถออกแบบ Kernel SVM สำหรับ non-linear ได้
5. การจำแนกแบบไร้เดียงสา
การจำแนกประเภท Naive Bayes มีรากฐานมาจากทฤษฎีบท Bayes โดยถือว่าตัวแปรอิสระ (คุณลักษณะ) ของชุดข้อมูลเป็นอิสระ พวกเขามีความสำคัญเท่าเทียมกันในการทำนายผล สมมติฐานของทฤษฎีบทเบย์ทำให้ชื่อ- 'ไร้เดียงสา' ใช้สำหรับงานต่างๆ เช่น การกรองสแปม และส่วนอื่นๆ ของการจัดประเภทข้อความ Naive Bayes คำนวณความเป็นไปได้ว่าจุดข้อมูลอยู่ในหมวดหมู่ใดหมวดหมู่หนึ่งหรือไม่
สูตรของการจำแนก Naive Bayes กำหนดโดย
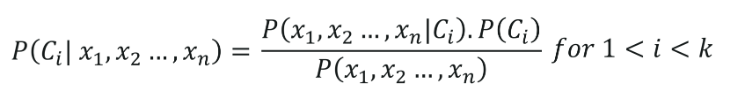
6. การจำแนกต้นไม้การตัดสินใจ
โครงสร้างการตัดสินใจคืออัลกอริธึมการเรียนรู้ภายใต้การดูแลซึ่งเหมาะสำหรับปัญหาการจำแนกประเภท เนื่องจากสามารถจัดลำดับชั้นเรียนในระดับที่แม่นยำได้ มันทำงานในรูปแบบของผังงานที่แยกจุดข้อมูลในแต่ละระดับ โครงสร้างสุดท้ายดูเหมือนต้นไม้ที่มีปมและใบ

แหล่งที่มา
โหนดการตัดสินใจจะมีสาขาตั้งแต่สองสาขาขึ้นไป และลีฟแสดงถึงการจำแนกประเภทหรือการตัดสินใจ ในตัวอย่างข้างต้นของ Decision Tree โดยถามคำถามหลายข้อ ผังงานจะถูกสร้างขึ้น ซึ่งช่วยให้เราแก้ปัญหาง่ายๆ ของการทำนายว่าจะไปตลาดหรือไม่
7. การจำแนกป่าแบบสุ่ม
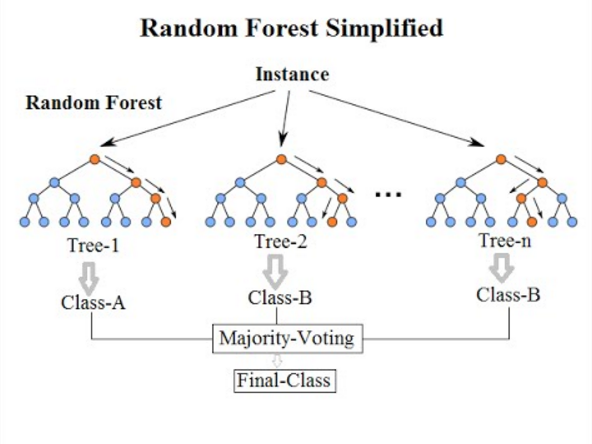
มาถึงอัลกอริธึมการจำแนกประเภทสุดท้ายในรายการนี้ The Random Forest เป็นเพียงส่วนขยายของอัลกอริทึมทรีการตัดสินใจเท่านั้น Random Forest เป็นวิธีการเรียนรู้แบบกลุ่มที่มีต้นไม้ตัดสินใจหลายต้น มันทำงานในลักษณะเดียวกับต้นไม้ตัดสินใจ
แหล่งที่มา
Random Forest Algorithm เป็นความก้าวหน้าของ Decision Tree Algorithm ที่มีอยู่ ซึ่งประสบปัญหาที่สำคัญของ " overfitting " นอกจากนี้ยังถือว่าเร็วกว่าและแม่นยำกว่าเมื่อเปรียบเทียบกับอัลกอริทึมแผนผังการตัดสินใจ
อ่านเพิ่มเติม: แนวคิดและหัวข้อโครงการการเรียนรู้ของเครื่อง
บทสรุป
ดังนั้น ในบทความเรื่อง Machine Learning Methods for Classification เราจึงเข้าใจพื้นฐานของ Classification and Supervised Learning, Types and Evaluation metrics of Classification models และสุดท้ายคือบทสรุปของแบบจำลองการจำแนกประเภทที่ใช้บ่อยที่สุด Machine Learning
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT -B สถานะศิษย์เก่า 5+ โครงการหลักที่ปฏิบัติได้จริง & ความช่วยเหลืองานกับ บริษัท ชั้นนำ
ไตรมาสที่ 1 อัลกอริทึมใดที่ใช้ในการเรียนรู้ของเครื่องมากที่สุด
แมชชีนเลิร์นนิงใช้อัลกอริธึมต่างๆ มากมาย ซึ่งสามารถจำแนกอย่างกว้างๆ ได้เป็น 3 ประเภทหลัก ได้แก่ อัลกอริธึมการเรียนรู้ภายใต้การดูแล อัลกอริธึมการเรียนรู้แบบไม่มีผู้ดูแล และอัลกอริธึมการเรียนรู้แบบเสริมกำลัง ในการจำกัดขอบเขตและตั้งชื่ออัลกอริธึมที่ใช้บ่อยที่สุดบางส่วนที่ต้องกล่าวถึง ได้แก่ การถดถอยเชิงเส้น, การถดถอยโลจิสติก, SVM, แผนผังการตัดสินใจ, อัลกอริธึมฟอเรสต์แบบสุ่ม, kNN, ทฤษฎี Naive Bayes, K-Means, การลดขนาด และอัลกอริธึมการไล่ระดับความชัน อัลกอริทึม XGBoost, GBM, LightGBM และ CatBoost สมควรได้รับการกล่าวถึงเป็นพิเศษในอัลกอริธึมการไล่ระดับการไล่ระดับสี อัลกอริทึมเหล่านี้สามารถนำไปใช้แก้ปัญหาข้อมูลได้แทบทุกประเภท
ไตรมาสที่ 2 การจำแนกประเภทและการถดถอยในการเรียนรู้ของเครื่องคืออะไร?
อัลกอริธึมการจำแนกประเภทและการถดถอยถูกนำมาใช้อย่างกว้างขวางในการเรียนรู้ของเครื่อง อย่างไรก็ตาม มีความแตกต่างกันหลายประการ ซึ่งท้ายที่สุดแล้วจะเป็นตัวกำหนดการใช้งานหรือวัตถุประสงค์ ความแตกต่างหลัก ๆ ก็คือ แม้ว่าอัลกอริธึมการจำแนกประเภทจะใช้เพื่อจำแนกหรือทำนายค่าที่ไม่ต่อเนื่อง เช่น ชาย-หญิง หรือจริง-เท็จ แต่อัลกอริธึมการถดถอยจะใช้ในการคาดการณ์ค่าที่ไม่ต่อเนื่องและต่อเนื่อง เช่น เงินเดือน อายุ ราคา ฯลฯ ฟอเรสต์สุ่ม, Kernel SVM และการถดถอยโลจิสติกเป็นอัลกอริธึมการจำแนกประเภทที่พบบ่อยที่สุด ในขณะที่การถดถอยเชิงเส้นแบบง่ายและพหุคูณ สนับสนุนการถดถอยเวกเตอร์ การถดถอยพหุนาม และการถดถอยทรีการตัดสินใจเป็นอัลกอริธึมการถดถอยที่นิยมใช้กันมากที่สุดในการเรียนรู้ของเครื่อง
ไตรมาสที่ 3 ข้อกำหนดเบื้องต้นสำหรับการเรียนรู้ด้วยเครื่องคืออะไร
ในการเริ่มต้นใช้งานแมชชีนเลิร์นนิง คุณไม่จำเป็นต้องเป็นนักคณิตศาสตร์หรือโปรแกรมเมอร์ที่เชี่ยวชาญ อย่างไรก็ตาม ด้วยพื้นที่ที่กว้างขวาง คุณอาจรู้สึกหวาดกลัวเมื่อคุณเพิ่งจะเริ่มต้นกับเส้นทางการเรียนรู้ของเครื่อง ในกรณีเช่นนี้ การรู้ข้อกำหนดเบื้องต้นสามารถช่วยให้คุณเริ่มต้นได้อย่างราบรื่น ข้อกำหนดเบื้องต้นเป็นทักษะหลักที่คุณจำเป็นต้องได้รับเพื่อทำความเข้าใจแนวคิดของแมชชีนเลิร์นนิง ก่อนอื่นคุณต้องเรียนรู้วิธีเขียนโค้ดโดยใช้ Python ต่อไป ความเข้าใจพื้นฐานเกี่ยวกับสถิติและคณิตศาสตร์ โดยเฉพาะพีชคณิตเชิงเส้นและแคลคูลัสหลายตัวแปร จะเป็นประโยชน์เพิ่มเติม