
วิธีเลือกวิธีการเลือกคุณสมบัติสำหรับการเรียนรู้ของเครื่อง
เผยแพร่แล้ว: 2021-06-22สารบัญ
แนะนำการเลือกคุณสมบัติ
โมเดลแมชชีนเลิร์นนิงใช้ฟีเจอร์มากมายซึ่งมีเพียงไม่กี่ฟีเจอร์เท่านั้นที่สำคัญ โมเดลมีความแม่นยำลดลงหากใช้ฟีเจอร์ที่ไม่จำเป็นในการฝึกโมเดลข้อมูล นอกจากนี้ ความซับซ้อนของแบบจำลองยังเพิ่มขึ้นและความสามารถในการทำให้เป็นนัยทั่วไปลดลงซึ่งส่งผลให้เกิดแบบจำลองลำเอียง คำว่า "บางครั้งน้อยก็ดีกว่า" เข้ากันได้ดีกับแนวคิดของการเรียนรู้ของเครื่อง ผู้ใช้จำนวนมากประสบกับปัญหาซึ่งพบว่าเป็นการยากที่จะระบุชุดคุณลักษณะที่เกี่ยวข้องจากข้อมูลของตน และละเว้นชุดคุณลักษณะที่ไม่เกี่ยวข้องทั้งหมด มีการเรียกคุณลักษณะที่มีความสำคัญน้อยกว่า เพื่อไม่ให้ส่งผลต่อตัวแปรเป้าหมาย
ดังนั้น หนึ่งในกระบวนการที่สำคัญคือ การเลือกคุณลักษณะในการเรียนรู้ ของ เครื่อง เป้าหมายคือการเลือกชุดคุณลักษณะที่ดีที่สุดสำหรับการพัฒนาโมเดลการเรียนรู้ของเครื่อง มีผลกระทบอย่างมากต่อประสิทธิภาพของโมเดลโดยการเลือกคุณสมบัติ นอกจากการล้างข้อมูลแล้ว การเลือกคุณลักษณะควรเป็นขั้นตอนแรกในการออกแบบแบบจำลอง
การเลือกคุณสมบัติในแมชชีนเลิร์ นนิง อาจสรุปได้ดังนี้
- การเลือกคุณลักษณะเหล่านั้นโดยอัตโนมัติหรือด้วยตนเองซึ่งมีส่วนทำให้เกิดตัวแปรการคาดคะเนหรือผลลัพธ์มากที่สุด
- การมีอยู่ของคุณลักษณะที่ไม่เกี่ยวข้องอาจทำให้ความแม่นยำของแบบจำลองลดลง เนื่องจากจะเรียนรู้จากคุณลักษณะที่ไม่เกี่ยวข้อง
ประโยชน์ของการเลือกคุณสมบัติ
- ลดการใช้ข้อมูลมากเกินไป: ข้อมูลจำนวนน้อยลงนำไปสู่ความซ้ำซ้อนที่น้อยลง ดังนั้นจึงมีโอกาสน้อยในการตัดสินใจเรื่องเสียงรบกวน
- ปรับปรุงความแม่นยำของแบบจำลอง: ด้วยโอกาสที่ข้อมูลทำให้เข้าใจผิดน้อยลง ความแม่นยำของแบบจำลองก็เพิ่มขึ้น
- เวลาการฝึกอบรมลดลง: การนำคุณลักษณะที่ไม่เกี่ยวข้องออกช่วยลดความซับซ้อนของอัลกอริทึมเนื่องจากมีจุดข้อมูลเพียงไม่กี่จุด ดังนั้นอัลกอริธึมจะฝึกเร็วขึ้น
- ความซับซ้อนของแบบจำลองลดลงด้วยการตีความข้อมูลที่ดีขึ้น
วิธีการเลือกคุณสมบัติภายใต้การดูแลและไม่ได้รับการดูแล
วัตถุประสงค์หลักของ อัลกอริธึมการเลือกคุณลักษณะ คือการเลือกชุดคุณลักษณะที่ดีที่สุดสำหรับการพัฒนาโมเดล วิธีการเลือกคุณลักษณะในการเรียนรู้ของเครื่อง สามารถจำแนกได้เป็นวิธีการที่มีการควบคุมดูแลและไม่ได้รับการดูแล
- วิธีการภายใต้การดูแล : วิธี การภายใต้การดูแลจะใช้สำหรับการเลือกคุณสมบัติจากข้อมูลที่ติดฉลาก และยังใช้สำหรับการจัดประเภทคุณสมบัติที่เกี่ยวข้อง ดังนั้นจึงมีประสิทธิภาพเพิ่มขึ้นของแบบจำลองที่สร้างขึ้น
- Unsupervised method : วิธีการเลือกคุณลักษณะนี้ใช้สำหรับข้อมูลที่ไม่มีป้ายกำกับ
รายการวิธีการภายใต้วิธีการดูแล
วิธีการภายใต้การดูแลของ การเลือกคุณสมบัติในการเรียนรู้ของเครื่อง สามารถจำแนกได้เป็น

1. วิธีการห่อตัว
อัลกอริธึมการเลือกคุณสมบัติ ประเภทนี้จะ ประเมินกระบวนการประสิทธิภาพของคุณสมบัติตามผลลัพธ์ของอัลกอริทึม หรือที่เรียกว่าอัลกอริทึมโลภ มันฝึกอัลกอริทึมโดยใช้ชุดย่อยของคุณสมบัติซ้ำ ๆ เกณฑ์การหยุดมักจะกำหนดโดยผู้ฝึกอัลกอริทึม การเพิ่มและการลบคุณลักษณะในโมเดลเกิดขึ้นจากการฝึกหัดก่อนหน้าของโมเดล สามารถใช้อัลกอริทึมการเรียนรู้ประเภทใดก็ได้ในกลยุทธ์การค้นหานี้ โมเดลมีความแม่นยำมากกว่าเมื่อเปรียบเทียบกับวิธีการกรอง
เทคนิคที่ใช้ในวิธี Wrapper คือ:
- การเลือกไปข้างหน้า: กระบวนการเลือกไปข้างหน้าเป็นกระบวนการวนซ้ำซึ่งมีการเพิ่มคุณสมบัติใหม่ที่ปรับปรุงแบบจำลองหลังจากการทำซ้ำแต่ละครั้ง มันเริ่มต้นด้วยชุดคุณสมบัติที่ว่างเปล่า การวนซ้ำจะดำเนินต่อไปและหยุดลงจนกว่าจะมีการเพิ่มคุณสมบัติที่ไม่ปรับปรุงประสิทธิภาพของโมเดลต่อไป
- การเลือก/กำจัดย้อนหลัง: กระบวนการนี้เป็นกระบวนการแบบวนซ้ำที่เริ่มต้นด้วยคุณสมบัติทั้งหมด หลังจากการทำซ้ำแต่ละครั้ง คุณลักษณะที่มีนัยสำคัญน้อยที่สุดจะถูกลบออกจากชุดของคุณลักษณะเริ่มต้น เกณฑ์การหยุดสำหรับการทำซ้ำคือเมื่อประสิทธิภาพของโมเดลไม่ดีขึ้นเมื่อนำคุณลักษณะนี้ออก อัลกอริทึมเหล่านี้ถูกนำมาใช้ในแพ็คเกจ mlxtend
- การกำจัดแบบสองทิศทาง : ทั้งสองวิธีการของการเลือกไปข้างหน้าและเทคนิคการกำจัดย้อนกลับถูกนำมาใช้พร้อมกันในวิธีการกำจัดแบบสองทิศทาง เพื่อให้ได้วิธีแก้ปัญหาที่ไม่เหมือนใคร
- การเลือกคุณลักษณะอย่างละเอียดถี่ถ้วน: เรียกอีกอย่างว่าแนวทางกำลังเดรัจฉานสำหรับการประเมินชุดย่อยของคุณลักษณะ มีการสร้างชุดย่อยที่เป็นไปได้และอัลกอริทึมการเรียนรู้ถูกสร้างขึ้นสำหรับแต่ละชุดย่อย เซตย่อยนั้นถูกเลือกว่ารุ่นใดให้ประสิทธิภาพดีที่สุด
- การกำจัดคุณสมบัติแบบเรียกซ้ำ (RFE): วิธีการนี้เรียกว่าโลภเนื่องจากเลือกคุณสมบัติโดยพิจารณาซ้ำโดยพิจารณาจากชุดคุณสมบัติที่เล็กกว่าและเล็กกว่า คุณลักษณะชุดแรกใช้สำหรับการฝึกอบรมตัวประมาณ และรับความสำคัญโดยใช้ feature_importance_attribute จากนั้นจะตามด้วยการนำคุณลักษณะที่มีความสำคัญน้อยที่สุดออก โดยเหลือไว้เฉพาะจำนวนคุณลักษณะที่ต้องการเท่านั้น อัลกอริทึมถูกนำไปใช้ในแพ็คเกจ scikit-learn
รูปที่ 4: ตัวอย่างโค้ดที่แสดงเทคนิคการขจัดคุณสมบัติแบบเรียกซ้ำ
2. วิธีการฝังตัว
วิธีการเลือกคุณลักษณะ แบบฝัง ในการเรียนรู้ของเครื่อง มีข้อได้เปรียบเหนือวิธีการกรองและตัวตัดทอน โดยรวมการโต้ตอบของคุณลักษณะและการรักษาต้นทุนในการคำนวณที่สมเหตุสมผล เทคนิคที่ใช้ในวิธีการฝังตัวคือ:
- การทำให้เป็นมาตรฐาน : โมเดลหลีกเลี่ยงการใช้ข้อมูลมากเกินไปโดยเพิ่มบทลงโทษให้กับพารามิเตอร์ของแบบจำลอง ค่าสัมประสิทธิ์จะถูกเพิ่มเข้าไปพร้อมกับบทลงโทษส่งผลให้ค่าสัมประสิทธิ์บางส่วนเป็นศูนย์ ดังนั้นคุณลักษณะเหล่านั้นที่มีค่าสัมประสิทธิ์เป็นศูนย์จะถูกลบออกจากชุดคุณลักษณะ แนวทางการเลือกคุณลักษณะใช้ Lasso (การทำให้เป็นมาตรฐาน L1) และ Elastic nets (การทำให้เป็นมาตรฐาน L1 และ L2)
- SMLR (Sparse Multinomial Logistic Regression): อัลกอริธึมใช้การทำให้เป็นมาตรฐานแบบเบาบางโดย ARD ก่อนหน้า (การกำหนดความเกี่ยวข้องอัตโนมัติ) สำหรับการถดถอยโลจิสติกข้ามชาติแบบคลาสสิก การทำให้เป็นมาตรฐานนี้จะประเมินความสำคัญของแต่ละคุณลักษณะและตัดมิติข้อมูลที่ไม่เป็นประโยชน์สำหรับการคาดคะเน การนำอัลกอริธึมไปใช้ทำได้ใน SMLR
- ARD (Automatic Relevance Determination Regression): อัลกอริธึมจะเปลี่ยนน้ำหนักสัมประสิทธิ์ไปทางศูนย์และอิงจากการถดถอย Bayesian Ridge อัลกอริทึมสามารถนำไปใช้ใน scikit-learn
- ความสำคัญของป่าสุ่ม: อัลกอริธึมการเลือกคุณลักษณะ นี้ เป็นการรวมต้นไม้ตามจำนวนที่ระบุ กลยุทธ์แบบต้นไม้ในอัลกอริทึมนี้จัดลำดับโดยพิจารณาจากการเพิ่มสิ่งเจือปนของโหนดหรือการลดสิ่งเจือปน (Gini impurity) จุดสิ้นสุดของต้นไม้ประกอบด้วยโหนดที่มีความเจือปนน้อยที่สุดและจุดเริ่มต้นของต้นไม้ประกอบด้วยโหนดที่มีความเจือปนลดลงมากที่สุด ดังนั้นคุณสมบัติที่สำคัญสามารถเลือกได้ผ่านการตัดแต่งต้นไม้ใต้โหนดใดโหนดหนึ่ง
3. วิธีการกรอง
มีการใช้วิธีการในระหว่างขั้นตอนก่อนการประมวลผล วิธีการนี้ค่อนข้างเร็วและราคาไม่แพง และทำงานได้ดีที่สุดในการลบคุณลักษณะที่ซ้ำกัน สัมพันธ์กัน และซ้ำซ้อน แทนที่จะใช้วิธีการเรียนรู้ภายใต้การดูแล ความสำคัญของคุณลักษณะจะได้รับการประเมินตามลักษณะโดยธรรมชาติ ค่าใช้จ่ายในการคำนวณของอัลกอริธึมนั้นน้อยกว่าเมื่อเปรียบเทียบกับวิธีการแรปเปอร์ของการเลือกคุณสมบัติ อย่างไรก็ตาม หากไม่มีข้อมูลเพียงพอเพื่อให้ได้มาซึ่งความสัมพันธ์ทางสถิติระหว่างคุณลักษณะ ผลลัพธ์อาจแย่กว่าวิธีการของตัวห่อหุ้ม ดังนั้น อัลกอริธึมจึงถูกใช้กับข้อมูลที่มีมิติสูง ซึ่งจะนำไปสู่ต้นทุนในการคำนวณที่สูงขึ้น หากใช้วิธีแรปเปอร์

เทคนิคที่ใช้ในวิธีการกรองคือ :
- ข้อมูลที่ได้รับ : ข้อมูลที่ได้รับหมายถึงจำนวนข้อมูลที่ได้รับจากคุณลักษณะต่างๆ เพื่อระบุค่าเป้าหมาย จากนั้นจะวัดการลดค่าเอนโทรปี ข้อมูลที่ได้มาของแต่ละแอตทริบิวต์จะคำนวณโดยพิจารณาจากค่าเป้าหมายสำหรับการเลือกคุณลักษณะ
- การทดสอบไคสแควร์ : โดยทั่วไปวิธีไคสแควร์ (X 2 ) จะใช้เพื่อทดสอบความสัมพันธ์ระหว่างตัวแปรหมวดหมู่สองตัว การทดสอบใช้เพื่อระบุว่ามีความแตกต่างที่มีนัยสำคัญระหว่างค่าที่สังเกตได้จากคุณลักษณะต่างๆ ของชุดข้อมูลกับค่าที่คาดไว้หรือไม่ สมมติฐานว่างระบุว่าไม่มีความสัมพันธ์ระหว่างสองตัวแปร
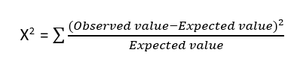
แหล่งที่มา
สูตรการทดสอบไคสแควร์
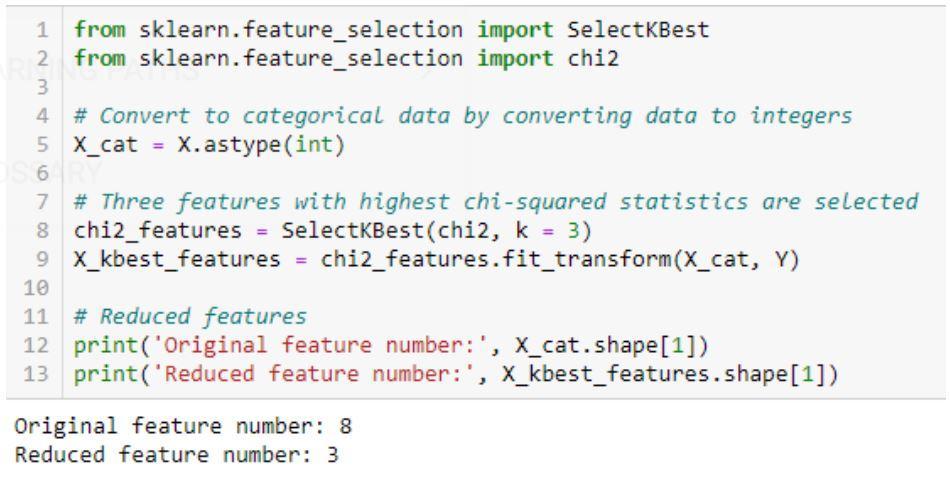
การใช้อัลกอริทึม Chi-Squared: sklearn, scipy
ตัวอย่างโค้ดสำหรับการทดสอบ Chi-square
แหล่งที่มา
- CFS (การเลือกคุณสมบัติตามสหสัมพันธ์): วิธีการดังต่อไปนี้ “ การใช้งาน CFS (การเลือกคุณสมบัติตามสหสัมพันธ์): scikit-feature
เข้าร่วม หลักสูตร AI & ML ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
- FCBF (ตัวกรองตามสหสัมพันธ์ที่รวดเร็ว): เมื่อเปรียบเทียบกับวิธีการบรรเทาและ CFS ที่กล่าวถึงข้างต้น วิธี FCBF นั้นเร็วกว่าและมีประสิทธิภาพมากกว่า เริ่มแรก การคำนวณความไม่แน่นอนแบบสมมาตรจะดำเนินการสำหรับคุณลักษณะทั้งหมด เมื่อใช้เกณฑ์เหล่านี้ คุณลักษณะจะถูกแยกออกและคุณลักษณะที่ซ้ำซ้อนจะถูกลบออก
ความไม่แน่นอนสมมาตร= ข้อมูลที่ได้รับของ x | y หารด้วยผลรวมของเอนโทรปีของพวกมัน การนำ FCBF ไปใช้: skfeature
- คะแนน Fischer: Fischer ration (FIR) ถูกกำหนดให้เป็นระยะห่างระหว่างค่าเฉลี่ยตัวอย่างสำหรับแต่ละชั้นเรียนต่อคุณลักษณะหารด้วยความแปรปรวน แต่ละฟีเจอร์จะได้รับการคัดเลือกอย่างอิสระตามคะแนนของพวกเขาภายใต้เกณฑ์ของฟิชเชอร์ สิ่งนี้นำไปสู่ชุดคุณสมบัติที่ไม่เหมาะสม คะแนนของฟิชเชอร์ที่มากขึ้นแสดงถึงคุณสมบัติที่เลือกได้ดีกว่า
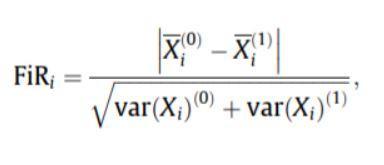
แหล่งที่มา
สูตรคะแนนฟิสเชอร์
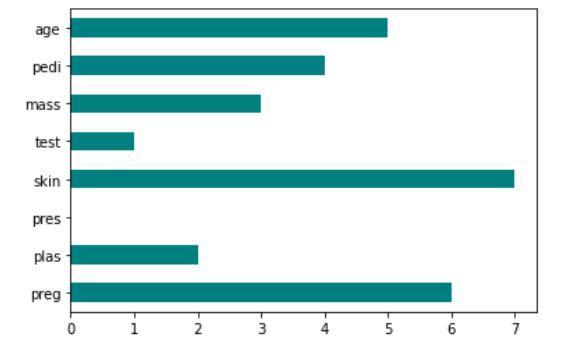
การนำคะแนน Fisher ไปใช้: scikit-feature
ผลลัพธ์ของโค้ดแสดงเทคนิค Fisher Score
แหล่งที่มา
สัมประสิทธิ์สหสัมพันธ์ของเพียร์สัน: เป็นการวัดปริมาณความสัมพันธ์ระหว่างตัวแปรต่อเนื่องสองตัว ค่าของสัมประสิทธิ์สหสัมพันธ์มีตั้งแต่ -1 ถึง 1 ซึ่งกำหนดทิศทางความสัมพันธ์ระหว่างตัวแปร
- เกณฑ์ความแปรปรวน: คุณลักษณะที่มีความแปรปรวนไม่ตรงกับเกณฑ์เฉพาะจะถูกลบออก คุณลักษณะที่มีความแปรปรวนเป็นศูนย์จะถูกลบออกด้วยวิธีนี้ สมมติฐานที่พิจารณาคือคุณสมบัติความแปรปรวนที่สูงขึ้นมีแนวโน้มที่จะมีข้อมูลเพิ่มเติม
รูปที่ 15: ตัวอย่างโค้ดที่แสดงการใช้งาน Variance threshold
- Mean Absolute Difference (MAD): วิธีการคำนวณค่าสัมบูรณ์เฉลี่ย
ความแตกต่างจากค่าเฉลี่ย
ตัวอย่างโค้ดและผลลัพธ์ที่แสดงการใช้งาน Mean Absolute Difference (MAD)
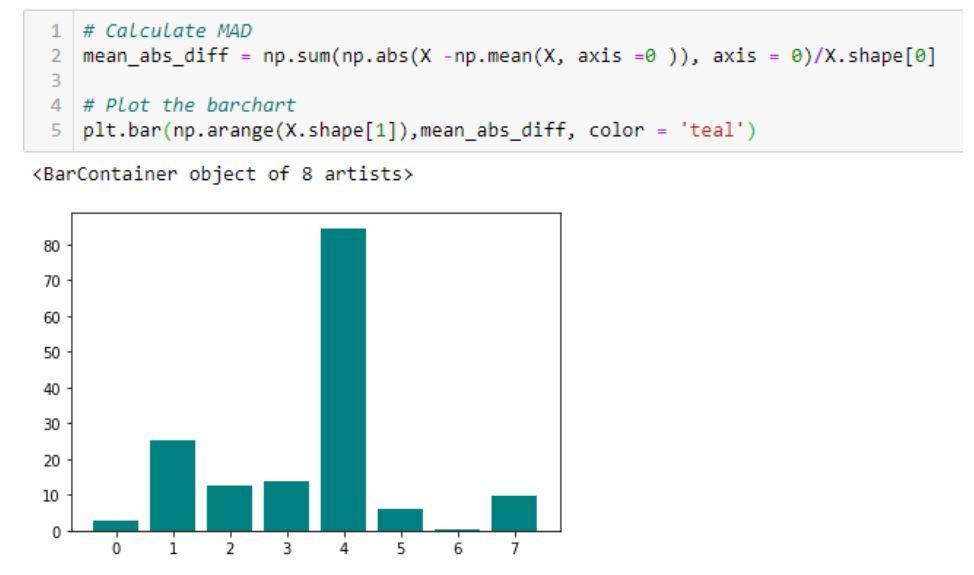
แหล่งที่มา
- อัตราส่วนการ กระจาย: อัตราส่วน การกระจายถูกกำหนดให้เป็นอัตราส่วนของค่าเฉลี่ยเลขคณิต (AM) กับค่าเฉลี่ยเรขาคณิต (GM) สำหรับจุดสนใจที่กำหนด ค่าของมันอยู่ในช่วง +1 ถึง ∞ เป็น AM ≥ GM สำหรับคุณลักษณะที่กำหนด
อัตราส่วนการกระจายตัวที่สูงขึ้นแสดงถึงค่า Ri ที่สูงขึ้น ดังนั้นจึงเป็นคุณลักษณะที่เกี่ยวข้องกันมากขึ้น ในทางกลับกัน เมื่อ Ri เข้าใกล้ 1 แสดงว่ามีคุณลักษณะที่มีความเกี่ยวข้องต่ำ
- การพึ่งพาซึ่งกันและกัน: วิธีการนี้ใช้เพื่อวัดการพึ่งพาซึ่งกันและกันระหว่างสองตัวแปร ข้อมูลที่ได้รับจากตัวแปรหนึ่งอาจใช้เพื่อให้ได้ข้อมูลสำหรับตัวแปรอื่น
- Laplacian Score: ข้อมูลจากคลาสเดียวกันมักจะอยู่ใกล้กัน ความสำคัญของจุดสนใจสามารถประเมินได้ด้วยพลังของการรักษาพื้นที่ คะแนน Laplacian สำหรับแต่ละคุณสมบัติจะถูกคำนวณ ค่าที่น้อยที่สุดจะเป็นตัวกำหนดมิติที่สำคัญ การนำคะแนน Laplacian ไปใช้: scikit-feature
บทสรุป
การเลือกคุณสมบัติใน กระบวนการเรียนรู้ของเครื่องสามารถสรุปได้ว่าเป็นขั้นตอนสำคัญประการหนึ่งในการพัฒนารูปแบบการเรียนรู้ของเครื่อง กระบวนการของอัลกอริธึมการเลือกคุณสมบัตินำไปสู่การลดมิติของข้อมูลด้วยการลบคุณสมบัติที่ไม่เกี่ยวข้องหรือมีความสำคัญต่อแบบจำลองที่กำลังพิจารณา คุณสมบัติที่เกี่ยวข้องสามารถเร่งเวลาการฝึกอบรมของรุ่นต่างๆ ส่งผลให้ประสิทธิภาพสูง
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT -B สถานะศิษย์เก่า 5+ โครงการหลักที่ปฏิบัติได้จริง & ความช่วยเหลืองานกับ บริษัท ชั้นนำ
วิธีการกรองต่างจากวิธีการห่ออย่างไร?
วิธีการห่อช่วยในการวัดว่าคุณลักษณะต่างๆ มีประโยชน์เพียงใดโดยพิจารณาจากประสิทธิภาพของตัวแยกประเภท ในทางกลับกัน วิธีการกรองจะประเมินคุณภาพที่แท้จริงของจุดสนใจโดยใช้สถิติที่ไม่มีตัวแปรมากกว่าประสิทธิภาพการตรวจสอบข้าม ซึ่งหมายความว่าพวกเขาตัดสินความเกี่ยวข้องของคุณสมบัติ ด้วยเหตุนี้ วิธีการของ wrapper จึงมีประสิทธิภาพมากขึ้น เนื่องจากเป็นการปรับประสิทธิภาพของตัวแยกประเภทให้เหมาะสมที่สุด อย่างไรก็ตาม เนื่องจากกระบวนการเรียนรู้ซ้ำๆ และการตรวจสอบข้าม เทคนิค wrapper จึงมีราคาแพงกว่าวิธีการกรองในเชิงคำนวณ
Sequential Forward Selection ในการเรียนรู้ของเครื่องคืออะไร?
เป็นการเลือกคุณสมบัติตามลำดับแม้ว่าจะมีราคาแพงกว่าการเลือกตัวกรองมาก เป็นเทคนิคการค้นหาที่โลภซึ่งเลือกคุณลักษณะซ้ำ ๆ ตามประสิทธิภาพของตัวแยกประเภท เพื่อค้นหาชุดย่อยของคุณลักษณะที่เหมาะสมที่สุด เริ่มต้นด้วยชุดย่อยของฟีเจอร์ที่ว่างเปล่าและเพิ่มฟีเจอร์หนึ่งรายการต่อไปในทุกรอบ คุณลักษณะหนึ่งนี้ถูกเลือกจากกลุ่มคุณลักษณะทั้งหมดที่ไม่ได้อยู่ในชุดย่อยของคุณลักษณะของเรา และเป็นคุณลักษณะที่ส่งผลให้ประสิทธิภาพของตัวแยกประเภทดีที่สุดเมื่อรวมกับคุณลักษณะอื่นๆ
ข้อจำกัดของการใช้วิธีการกรองสำหรับการเลือกคุณสมบัติมีอะไรบ้าง?
วิธีการกรองมีราคาไม่แพงนักเมื่อเทียบกับวิธีการเลือก wrapper และวิธีการเลือกคุณลักษณะแบบฝัง แต่มีข้อเสียบางประการ ในกรณีของแนวทางที่ไม่แปรผัน กลยุทธ์นี้มักจะละเว้นการพึ่งพาอาศัยกันของฟีเจอร์ในขณะที่เลือกคุณสมบัติและประเมินแต่ละฟีเจอร์อย่างอิสระ เมื่อเปรียบเทียบกับวิธีการเลือกคุณสมบัติอีกสองวิธี บางครั้งสิ่งนี้อาจส่งผลให้ประสิทธิภาพการประมวลผลต่ำ