
คำสั่ง Hadoop 10 อันดับแรก [ด้วยการใช้งาน]
เผยแพร่แล้ว: 2021-01-29ในยุคนี้ ด้วยข้อมูลจำนวนมหาศาล จึงจำเป็นต้องจัดการกับข้อมูลเหล่านี้ ข้อมูลที่ผุดขึ้นมาจากองค์กรที่มีลูกค้าเพิ่มขึ้นนั้นมีขนาดใหญ่กว่าเครื่องมือการจัดการข้อมูลแบบเดิมที่สามารถจัดเก็บได้ ทำให้เรามีคำถามในการจัดการชุดข้อมูลที่ใหญ่ขึ้น ซึ่งอาจอยู่ในช่วงตั้งแต่กิกะไบต์จนถึงเพตาไบต์ โดยไม่ต้องใช้คอมพิวเตอร์ขนาดใหญ่เครื่องเดียวหรือเครื่องมือการจัดการข้อมูลแบบเดิม
นี่คือจุดที่เฟรมเวิร์ก Apache Hadoop ได้รับความสนใจ ก่อนดำดิ่งสู่การใช้งานคำสั่ง Hadoop เรามาทำความเข้าใจกับกรอบงาน Hadoop และความสำคัญของมันก่อน
สารบัญ
Hadoop คืออะไร?
โดยทั่วไปแล้ว Hadoop จะใช้โดยองค์กรธุรกิจขนาดใหญ่ในการแก้ปัญหาต่างๆ ตั้งแต่การจัดเก็บข้อมูล GB ขนาดใหญ่ (กิกะไบต์) ทุกวัน ไปจนถึงการประมวลผลข้อมูล
ตามเนื้อผ้ากำหนดเป็นเฟรมเวิร์กซอฟต์แวร์โอเพ่นซอร์สที่ใช้ในการจัดเก็บข้อมูลและประมวลผลแอปพลิเคชัน Hadoop โดดเด่นค่อนข้างมากจากเครื่องมือการจัดการข้อมูลแบบดั้งเดิมส่วนใหญ่ ปรับปรุงพลังการประมวลผลและขยายขีดจำกัดการจัดเก็บข้อมูลโดยการเพิ่มโหนดสองสามโหนดในเฟรมเวิร์ก ทำให้สามารถปรับขนาดได้สูง นอกจากนี้ ข้อมูลและกระบวนการแอปพลิเคชันของคุณยังได้รับการปกป้องจากความล้มเหลวของฮาร์ดแวร์ต่างๆ
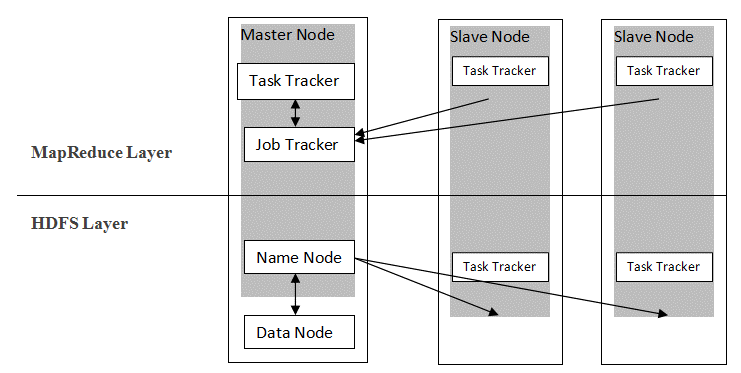
Hadoop ติดตามสถาปัตยกรรมมาสเตอร์ทาสเพื่อแจกจ่ายและจัดเก็บข้อมูลโดยใช้ MapReduce และ HDFS ตามที่แสดงในรูปด้านล่าง สถาปัตยกรรมได้รับการปรับแต่งในลักษณะที่กำหนดไว้เพื่อดำเนินการจัดการข้อมูลโดยใช้โหนดหลักสี่โหนด ได้แก่ ชื่อ ข้อมูล มาสเตอร์ และสเลฟ ส่วนประกอบหลักของ Hadoop สร้างขึ้นโดยตรงบนเฟรมเวิร์ก ส่วนประกอบอื่นๆ รวมเข้ากับส่วนต่างๆ โดยตรง
 แหล่งที่มา
แหล่งที่มา

คำสั่ง Hadoop
คุณสมบัติหลักของเฟรมเวิร์ก Hadoop แสดงให้เห็นลักษณะที่สอดคล้องกัน และเป็นมิตรกับผู้ใช้มากขึ้นเมื่อต้องจัดการข้อมูลขนาดใหญ่ด้วยการเรียนรู้คำสั่ง Hadoop ด้านล่างนี้คือคำสั่ง Hadoop ที่สะดวกสบายซึ่งอนุญาตให้ดำเนินการต่างๆ เช่น การจัดการและการประมวลผลไฟล์คลัสเตอร์ HDFS รายการคำสั่งนี้มักต้องใช้เพื่อให้ได้ผลลัพธ์ของกระบวนการบางอย่าง
1. Hadoop Touchz
hadoop fs -touchz /directory/filename
คำสั่งนี้อนุญาตให้ผู้ใช้สร้างไฟล์ใหม่ในคลัสเตอร์ HDFS "ไดเร็กทอรี" ในคำสั่งหมายถึงชื่อไดเร็กทอรีที่ผู้ใช้ต้องการสร้างไฟล์ใหม่ และ "ชื่อไฟล์" หมายถึงชื่อของไฟล์ใหม่ซึ่งจะถูกสร้างขึ้นเมื่อคำสั่งเสร็จสิ้น
2. คำสั่งทดสอบ Hadoop
hadoop fs -test -[defsz] <เส้นทาง>
คำสั่งเฉพาะนี้ตอบสนองวัตถุประสงค์ของการทดสอบการมีอยู่ของไฟล์ในคลัสเตอร์ HDFS ต้องแก้ไขอักขระจาก "[defsz]" ในคำสั่งตามต้องการ นี่คือคำอธิบายสั้น ๆ ของตัวละครเหล่านี้:
- d -> ตรวจสอบว่าเป็นไดเร็กทอรีหรือไม่
- e -> ตรวจสอบว่าเป็นเส้นทางหรือไม่
- f -> ตรวจสอบว่าเป็นไฟล์หรือไม่
- s -> ตรวจสอบว่าเป็นเส้นทางว่างหรือไม่
- r -> ตรวจสอบการมีอยู่ของเส้นทางและอ่านสิทธิ์
- w -> ตรวจสอบการมีอยู่ของเส้นทางและเขียนสิทธิ์
- z -> ตรวจสอบขนาดไฟล์
3. คำสั่งข้อความ Hadoop
hadoop fs -text <src>
คำสั่งข้อความมีประโยชน์อย่างยิ่งในการแสดงไฟล์ zip ที่จัดสรรในรูปแบบข้อความ มันทำงานโดยการประมวลผลไฟล์ต้นฉบับและให้เนื้อหาในรูปแบบข้อความที่ถอดรหัสธรรมดา

4. Hadoop ค้นหาคำสั่ง
hadoop fs -find <path> … <expression>
โดยทั่วไปคำสั่งนี้ใช้เพื่อวัตถุประสงค์ในการค้นหาไฟล์ในคลัสเตอร์ HDFS โดยจะสแกนนิพจน์ที่กำหนดในคำสั่งพร้อมกับไฟล์ทั้งหมดในคลัสเตอร์ และแสดงไฟล์ที่ตรงกับนิพจน์ที่กำหนดไว้
อ่าน: เครื่องมือ Hadoop ยอดนิยม
5. Hadoop Getmerge คำสั่ง
hadoop fs -getmerge <src> <localdest>
คำสั่ง Getmerge อนุญาตให้รวมไฟล์ตั้งแต่หนึ่งไฟล์ขึ้นไปในไดเร็กทอรีที่กำหนดบนคลัสเตอร์ระบบไฟล์ HDFS มันรวบรวมไฟล์เป็นไฟล์เดียวที่อยู่ในระบบไฟล์ในเครื่อง “src” และ “localdest” หมายถึงความหมายของต้นทาง-ปลายทางและปลายทางในท้องถิ่น
6. Hadoop Count Command
hadoop fs -count [ตัวเลือก] <เส้นทาง>
ชัดเจนตามชื่อคำสั่ง Hadoop count นับจำนวนไฟล์และไบต์ในไดเร็กทอรีที่กำหนด มีตัวเลือกต่าง ๆ ที่ปรับเปลี่ยนผลลัพธ์ตามความต้องการ เหล่านี้มีดังนี้:
- q -> โควต้าแสดงขีดจำกัดของจำนวนชื่อและการใช้พื้นที่ทั้งหมด
- u -> แสดงเฉพาะโควต้าและการใช้งาน
- h -> ให้ขนาดของไฟล์
- v -> แสดงส่วนหัว
7. Hadoop คำสั่ง AppendToFile
hadoop fs -appendToFile <localsrc> <dest>
อนุญาตให้ผู้ใช้ผนวกเนื้อหาของไฟล์หนึ่งไฟล์หรือหลายไฟล์เป็นไฟล์เดียวในไฟล์ปลายทางที่ระบุในคลัสเตอร์ระบบไฟล์ HDFS ในการรันคำสั่งนี้ ไฟล์ต้นฉบับที่กำหนดจะถูกผนวกเข้ากับซอร์สปลายทางตามชื่อไฟล์ที่ระบุในคำสั่ง
8. Hadoop ls Command
hadoop fs -ls /path
คำสั่ง ls ใน Hadoop จะแสดงรายการไฟล์/เนื้อหาในไดเร็กทอรีที่ระบุ เช่น พาธ ในการเพิ่ม “R” ก่อน /path ผลลัพธ์จะแสดงรายละเอียดของเนื้อหา เช่น ชื่อ ขนาด เจ้าของ และอื่นๆ สำหรับแต่ละไฟล์ที่ระบุในไดเร็กทอรีที่กำหนด
9. Hadoop mkdir Command
hadoop fs -mkdir /path/directory_name
คุณลักษณะเฉพาะของคำสั่งนี้คือการสร้างไดเร็กทอรีในคลัสเตอร์ระบบไฟล์ HDFS หากไม่มีไดเร็กทอรี นอกจากนี้ หากมีไดเร็กทอรีที่ระบุ ข้อความที่ส่งออกจะแสดงข้อผิดพลาดที่บ่งบอกถึงการมีอยู่ของไดเร็กทอรี
10. Hadoop chmod Command
hadoop fs -chmod [-R] <โหมด> <เส้นทาง>
คำสั่งนี้ใช้เมื่อจำเป็นต้องเปลี่ยนสิทธิ์ในการเข้าถึงไฟล์ใดไฟล์หนึ่ง ในการให้คำสั่ง chmod การอนุญาตของไฟล์ที่ระบุจะเปลี่ยนไป อย่างไรก็ตาม สิ่งสำคัญคือต้องจำไว้ว่าการอนุญาตจะได้รับการแก้ไขเมื่อเจ้าของไฟล์ดำเนินการคำสั่งนี้
อ่านเพิ่มเติม: Impala Hadoop กวดวิชา
บทสรุป
บทความนี้เริ่มต้นจากปัญหาสำคัญของการจัดเก็บข้อมูลที่องค์กรหลักในโลกปัจจุบันต้องเผชิญ บทความนี้กล่าวถึงโซลูชันสำหรับการจัดเก็บข้อมูลแบบจำกัดโดยแนะนำ Hadoop และผลกระทบต่อการดำเนินการจัดการข้อมูลโดยใช้คำสั่ง Hadoop สำหรับผู้เริ่มต้นใน Hadoop จะมีการอธิบายภาพรวมของกรอบงานพร้อมกับส่วนประกอบและสถาปัตยกรรม

หลังจากอ่านบทความนี้ เราสามารถรู้สึกมั่นใจเกี่ยวกับความรู้ของตนในด้านกรอบงาน Hadoop และคำสั่งที่นำไปใช้ได้อย่างง่ายดาย การรับรอง PG แบบเอกสิทธิ์เฉพาะของ upGrad ใน Big Data: upGrad เสนอโปรแกรมเฉพาะอุตสาหกรรม 7.5 เดือนสำหรับการรับรอง PG ใน Big Data ซึ่งคุณจะจัดระเบียบ วิเคราะห์ และตีความข้อมูลขนาดใหญ่ด้วย IIIT-Bangalore
ได้รับการออกแบบมาอย่างรอบคอบสำหรับมืออาชีพด้านการทำงาน จะช่วยให้นักเรียนได้รับความรู้เชิงปฏิบัติและส่งเสริมการเข้าสู่บทบาท Big Data
ไฮไลท์ของโปรแกรม:
- การเรียนรู้ภาษาและเครื่องมือที่เกี่ยวข้อง
- เรียนรู้แนวคิดขั้นสูงของการเขียนโปรแกรมแบบกระจาย แพลตฟอร์มข้อมูลขนาดใหญ่ ฐานข้อมูล อัลกอริธึม และการทำเหมืองเว็บ
- ใบรับรองที่ได้รับการรับรองจาก IIIT Bangalore
- ความช่วยเหลือด้านตำแหน่งเพื่อซึมซับในบรรษัทข้ามชาติชั้นนำ
- การให้คำปรึกษาแบบ 1:1 เพื่อติดตามความคืบหน้าและช่วยเหลือคุณในทุกจุด
- ทำงานในโครงการ Live และงานที่มอบหมาย
คุณสมบัติ : พื้นฐานคณิตศาสตร์/วิศวกรรมซอฟต์แวร์/สถิติ/การวิเคราะห์
ตรวจสอบหลักสูตรวิศวกรรมซอฟต์แวร์อื่นๆ ของเราที่ upGrad