
ไพรเมอร์ GraphQL: วิวัฒนาการของการออกแบบ API (ตอนที่ 2)
เผยแพร่แล้ว: 2022-03-10ในตอนที่ 1 เรามาดูกันว่า API มีวิวัฒนาการอย่างไรในช่วงสองสามทศวรรษที่ผ่านมา และแต่ละ API ได้พัฒนาไปสู่อีกทางหนึ่งอย่างไร เรายังพูดถึงข้อเสียบางประการของการใช้ REST สำหรับการพัฒนาไคลเอนต์มือถือ ในบทความนี้ ฉันต้องการดูว่าการออกแบบ API ไคลเอนต์มือถือดูเหมือนจะมุ่งไปที่ใด โดยเน้นที่ GraphQL โดยเฉพาะ
มีผู้คน บริษัท และโครงการจำนวนมากที่พยายามแก้ไขข้อบกพร่องของ REST ในช่วงหลายปีที่ผ่านมา: HAL, Swagger/OpenAPI, OData JSON API และโปรเจ็กต์ภายในที่มีขนาดเล็กกว่าหรือภายในอื่นๆ อีกหลายสิบโครงการพยายามที่จะนำคำสั่งมาสู่ โลกแห่ง REST ที่ไม่มีข้อมูลจำเพาะ แทนที่จะเอาโลกไปในสิ่งที่มันเป็นและเสนอการปรับปรุงที่เพิ่มขึ้น หรือพยายามรวบรวมชิ้นส่วนที่แตกต่างกันมากพอที่จะทำให้ REST เป็นสิ่งที่ฉันต้องการ ฉันต้องการลองการทดลองทางความคิด ด้วยความเข้าใจในเทคนิคต่างๆ ที่เคยใช้แล้วและไม่เคยได้ผลมาก่อน ฉันต้องการใช้ข้อจำกัดของวันนี้และภาษาที่แสดงออกอย่างมากของเราเพื่อลองร่าง API ที่เราต้องการ มาทำงานจากประสบการณ์ของนักพัฒนาแบบย้อนหลังมากกว่าที่จะนำไปใช้ข้างหน้า (ฉันกำลังดู SQL ของคุณอยู่)
ปริมาณการใช้ HTTP น้อยที่สุด
เราทราบดีว่าคำขอเครือข่ายทุกรายการ (HTTP/1) มีค่าใช้จ่ายสูงในมาตรการบางอย่างตั้งแต่เวลาแฝงไปจนถึงอายุการใช้งานแบตเตอรี่ ตามหลักการแล้ว ลูกค้าของ API ใหม่ของเราต้องการวิธีที่จะขอข้อมูลทั้งหมดที่พวกเขาต้องการในการไปกลับน้อยที่สุดเท่าที่จะทำได้
น้ำหนักบรรทุกขั้นต่ำ
เรายังทราบด้วยว่าไคลเอนต์โดยเฉลี่ยมีข้อจำกัดด้านทรัพยากร ในแบนด์วิดท์ CPU และหน่วยความจำ ดังนั้นเป้าหมายของเราควรจะส่งเฉพาะข้อมูลที่ลูกค้าต้องการเท่านั้น ในการทำเช่นนี้ เราอาจต้องการวิธีที่ลูกค้าจะขอข้อมูลเฉพาะ
มนุษย์สามารถอ่านได้
เราได้เรียนรู้จากยุค SOAP ว่า API นั้นไม่ง่ายที่จะโต้ตอบด้วย ผู้คนจะดูหมิ่นเมื่อกล่าวถึง ทีมวิศวกรต้องการใช้เครื่องมือเดียวกันกับที่เราเคยใช้มาหลายปี เช่น curl , wget และ Charles และแท็บเครือข่ายของเบราว์เซอร์ของเรา
เครื่องมือรวย
อีกสิ่งหนึ่งที่เราเรียนรู้จาก XML-RPC และ SOAP ก็คือสัญญาไคลเอ็นต์/เซิร์ฟเวอร์และระบบประเภท โดยเฉพาะอย่างยิ่ง มีประโยชน์อย่างน่าอัศจรรย์ หากเป็นไปได้ API ใหม่จะมีรูปแบบที่เบาเช่น JSON หรือ YAML พร้อมความสามารถในการวิปัสสนาของสัญญาที่มีโครงสร้างและประเภทที่ปลอดภัยกว่า
การอนุรักษ์การใช้เหตุผลในท้องถิ่น
หลายปีที่ผ่านมา เราได้ตกลงกันเกี่ยวกับหลักการชี้นำบางประการในการจัดระเบียบ codebase ขนาดใหญ่ ซึ่งหลัก ๆ ก็คือ "การแยกข้อกังวล" น่าเสียดายสำหรับโครงการส่วนใหญ่ สิ่งนี้มีแนวโน้มที่จะพังทลายลงในรูปแบบของชั้นการเข้าถึงข้อมูลแบบรวมศูนย์ หากเป็นไปได้ ส่วนต่างๆ ของแอปพลิเคชันควรมีตัวเลือกในการจัดการความต้องการข้อมูลของตนเองพร้อมกับฟังก์ชันอื่นๆ
เนื่องจากเรากำลังออกแบบ API ที่เน้นลูกค้าเป็นศูนย์กลาง เรามาเริ่มกันที่หน้าตาในการดึงข้อมูลใน API แบบนี้กันดีกว่า หากเรารู้ว่าเราจำเป็นต้องเดินทางทั้งไปและกลับน้อยที่สุดและจำเป็นต้องกรองเขตข้อมูลที่เราไม่ต้องการออกได้ เราต้องการวิธีสำรวจทั้งชุดข้อมูลขนาดใหญ่และขอเฉพาะส่วนที่มี มีประโยชน์กับเรา ภาษาที่ใช้ค้นหาดูเหมือนว่าจะเข้ากันได้ดีที่นี่
เราไม่จำเป็นต้องถามคำถามเกี่ยวกับข้อมูลของเราในลักษณะเดียวกับที่คุณทำกับฐานข้อมูล ดังนั้นภาษาที่จำเป็นอย่าง SQL จึงดูเหมือนเป็นเครื่องมือที่ผิด อันที่จริง เป้าหมายหลักของเราคือการสำรวจความสัมพันธ์ที่มีอยู่ก่อนแล้วและจำกัดขอบเขตที่เราควรจะสามารถทำได้ด้วยบางสิ่งที่ค่อนข้างเรียบง่ายและเปิดเผย อุตสาหกรรมใช้ JSON สำหรับข้อมูลที่ไม่ใช่ไบนารีได้ค่อนข้างดี เรามาเริ่มด้วยภาษาคิวรีที่ประกาศเหมือน JSON กันก่อน เราควรจะสามารถอธิบายข้อมูลที่เราต้องการได้ และเซิร์ฟเวอร์ควรส่งคืน JSON ที่มีฟิลด์เหล่านั้น

ภาษาการสืบค้นที่เปิดเผยเป็นไปตามข้อกำหนดสำหรับทั้งเพย์โหลดที่น้อยที่สุดและปริมาณการใช้ HTTP ที่น้อยที่สุด แต่ยังมีประโยชน์อีกประการหนึ่งที่จะช่วยเราด้วยเป้าหมายการออกแบบอื่น ภาษาประกาศ แบบสอบถาม และอื่นๆ สามารถจัดการได้อย่างมีประสิทธิภาพราวกับว่ามันเป็นข้อมูล หากเราออกแบบอย่างระมัดระวัง ภาษาที่ใช้ค้นหาของเราจะอนุญาตให้นักพัฒนาแยกคำขอจำนวนมากออกจากกันและรวมเข้าด้วยกันใหม่ในลักษณะที่เหมาะสมกับโครงการของพวกเขา การใช้ภาษาที่ใช้ค้นหาเช่นนี้จะช่วยให้เราก้าวไปสู่เป้าหมายสูงสุดของเราในการอนุรักษ์การใช้เหตุผลในท้องถิ่น
มีสิ่งที่น่าตื่นเต้นมากมายที่คุณสามารถทำได้เมื่อคำถามของคุณกลายเป็น "ข้อมูล" ตัวอย่างเช่น คุณสามารถสกัดกั้นคำขอทั้งหมดและแบทช์ได้เหมือนกับการอัพเดต DOM ของ DOM แบบแบตช์ คุณสามารถใช้คอมไพเลอร์เพื่อแยกการสืบค้นข้อมูลขนาดเล็กในเวลาบิลด์เพื่อแคชข้อมูลล่วงหน้า หรือคุณสามารถสร้างระบบแคชที่ซับซ้อนได้ เช่น อพอลโล แคช
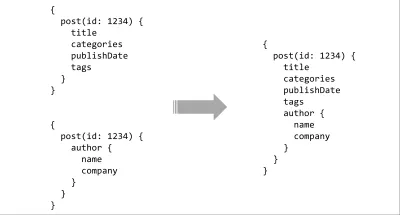
รายการสุดท้ายในรายการความปรารถนาของ API คือเครื่องมือ เราได้สิ่งนี้มาบ้างแล้วโดยใช้ภาษาคิวรี แต่พลังที่แท้จริงมาเมื่อคุณจับคู่กับระบบประเภท ด้วยสคีมาที่พิมพ์อย่างง่ายบนเซิร์ฟเวอร์ มีความเป็นไปได้เกือบไม่รู้จบสำหรับเครื่องมือที่หลากหลาย การสืบค้นข้อมูลสามารถวิเคราะห์และตรวจสอบแบบคงที่โดยเทียบกับสัญญา การผสานรวม IDE สามารถให้คำแนะนำหรือการเติมข้อมูลอัตโนมัติ คอมไพเลอร์สามารถเพิ่มประสิทธิภาพเวลาในการสร้างให้กับการสืบค้น หรือสามารถรวมสคีมาหลายตัวเข้าด้วยกันเพื่อสร้างพื้นผิว API ที่ต่อเนื่องกัน

การออกแบบ API ที่จับคู่ภาษาคิวรีกับระบบประเภทอาจฟังดูเหมือนเป็นข้อเสนอที่น่าทึ่ง แต่ผู้คนได้ทดลองกับสิ่งนี้มาหลายปีแล้วในรูปแบบต่างๆ XML-RPC ผลักดันให้มีการพิมพ์ตอบกลับในช่วงกลางทศวรรษที่ 90 และ SOAP ที่สืบทอดต่อจากนี้ ครอบงำมานานหลายปี! เมื่อไม่นานมานี้ มีสิ่งต่างๆ เช่น MongoDB abstraction ของ Meteor, Horizon ของ RethinkDB (RIP), Falcor ที่น่าทึ่งของ Netflix ซึ่งพวกเขาใช้สำหรับ Netflix.com มาหลายปีแล้ว และล่าสุดก็มี GraphQL ของ Facebook สำหรับส่วนที่เหลือของบทความนี้ ฉันจะเน้นที่ GraphQL เนื่องจากในขณะที่โครงการอื่นๆ เช่น Falcor กำลังทำสิ่งที่คล้ายกัน แต่การแบ่งปันความคิดของชุมชนก็ดูเหมือนจะสนับสนุนอย่างท่วมท้น
GraphQL คืออะไร?
ก่อนอื่นต้องบอกว่าโกหกนิดหน่อย API ที่เราสร้างด้านบนคือ GraphQL GraphQL เป็นเพียงระบบประเภทข้อมูลของคุณ ภาษาที่ใช้ในการสืบค้นข้อมูล ส่วนที่เหลือเป็นเพียงรายละเอียด ใน GraphQL คุณอธิบายข้อมูลของคุณเป็นกราฟของการเชื่อมต่อระหว่างกัน และลูกค้าของคุณจะขอข้อมูลบางส่วนที่ต้องการโดยเฉพาะ มีการพูดและเขียนมากมายเกี่ยวกับสิ่งที่น่าทึ่งทั้งหมดที่ GraphQL เปิดใช้งาน แต่แนวคิดหลักนั้นสามารถจัดการได้และไม่ซับซ้อน
เพื่อให้แนวคิดเหล่านี้เป็นรูปธรรมมากขึ้น และเพื่อช่วยแสดงให้เห็นว่า GraphQL พยายามแก้ไขปัญหาในส่วนที่ 1 อย่างไร ส่วนที่เหลือของโพสต์นี้จะสร้าง GraphQL API ที่สามารถขับเคลื่อนบล็อกได้ในส่วนที่ 1 ของชุดนี้ ก่อนที่จะกระโดดลงไปในโค้ด มีบางสิ่งเกี่ยวกับ GraphQL ที่ควรทราบ
GraphQL เป็นข้อมูลจำเพาะ (ไม่ใช่การนำไปใช้)
GraphQL เป็นเพียงข้อมูลจำเพาะ มันกำหนดระบบประเภทพร้อมกับภาษาแบบสอบถามอย่างง่าย และนั่นแหล่ะ สิ่งแรกที่หลุดออกจากสิ่งนี้คือ GraphQL ไม่ได้ผูกติดอยู่กับภาษาใดภาษาหนึ่ง มีการใช้งานมากกว่าสองโหลในทุกอย่างตั้งแต่ Haskell ไปจนถึง C++ ซึ่ง JavaScript เป็นเพียงตัวเดียวเท่านั้น ไม่นานหลังจากประกาศข้อมูลจำเพาะ Facebook ได้เปิดตัวการใช้งานอ้างอิงใน JavaScript แต่เนื่องจากพวกเขาไม่ได้ใช้ภายใน การใช้งานในภาษาเช่น Go และ Clojure จึงสามารถดีขึ้นหรือเร็วขึ้นได้
ข้อมูลจำเพาะของ GraphQL ไม่ได้กล่าวถึงลูกค้าหรือข้อมูล
หากคุณอ่านข้อมูลจำเพาะ คุณจะสังเกตเห็นว่าสองสิ่งขาดหายไปอย่างเด่นชัด ประการแรก นอกเหนือจากภาษาการสืบค้นแล้ว ยังไม่มีการกล่าวถึงการรวมไคลเอ็นต์ เครื่องมือต่างๆ เช่น Apollo, Relay, Loka และอื่นๆ เป็นไปได้เนื่องจากการออกแบบของ GraphQL แต่เครื่องมือเหล่านี้ไม่ได้เป็นส่วนหนึ่งหรือจำเป็นในการใช้งานแต่อย่างใด ประการที่สอง ไม่มีการกล่าวถึงชั้นข้อมูลใดโดยเฉพาะ เซิร์ฟเวอร์ GraphQL เดียวกันสามารถดึงข้อมูลจากชุดแหล่งที่มาที่แตกต่างกันและบ่อยครั้ง มันสามารถขอข้อมูลแคชจาก Redis ทำการค้นหาที่อยู่จาก USPS API และเรียกใช้ไมโครเซอร์วิสตามโปรโตบัฟ และไคลเอนต์จะไม่มีวันรู้ถึงความแตกต่าง
การเปิดเผยความซับซ้อนที่เพิ่มขึ้น
สำหรับหลายคน GraphQL ได้เจอจุดตัดของพลังและความเรียบง่ายที่หายาก มันทำงานได้อย่างยอดเยี่ยมในการทำให้เรื่องง่าย ๆ เป็นเรื่องง่ายและทำสิ่งที่ยากให้เป็นไปได้ การทำให้เซิร์ฟเวอร์ทำงานและให้บริการข้อมูลที่พิมพ์ผ่าน HTTP อาจเป็นโค้ดเพียงไม่กี่บรรทัดในภาษาใดก็ได้ที่คุณสามารถจินตนาการได้
ตัวอย่างเช่น เซิร์ฟเวอร์ GraphQL สามารถห่อ REST API ที่มีอยู่ และไคลเอนต์สามารถรับข้อมูลด้วยคำขอ GET ปกติ เช่นเดียวกับที่คุณโต้ตอบกับบริการอื่นๆ คุณสามารถดูตัวอย่างได้ที่นี่ หรือหากโปรเจ็กต์ต้องการชุดเครื่องมือที่ซับซ้อนกว่านี้ ก็สามารถใช้ GraphQL เพื่อทำสิ่งต่างๆ เช่น การตรวจสอบสิทธิ์ระดับฟิลด์ การสมัครสมาชิก pub/sub หรือคิวรีที่คอมไพล์ล่วงหน้า/แคช
แอพตัวอย่าง
เป้าหมายของตัวอย่างนี้คือการแสดงพลังและความเรียบง่ายของ GraphQL ใน ~70 บรรทัดของ JavaScript ไม่ใช่เพื่อเขียนบทช่วยสอนที่กว้างขวาง ฉันจะไม่ลงรายละเอียดมากเกินไปเกี่ยวกับไวยากรณ์และความหมาย แต่โค้ดทั้งหมดที่นี่สามารถเรียกใช้ได้ และมีลิงก์ไปยังเวอร์ชันที่ดาวน์โหลดได้ของโครงการอยู่ที่ท้ายบทความ ถ้าหลังจากนี้ คุณต้องการเจาะลึกลงไปอีกหน่อย ฉันมีคอลเลกชันของแหล่งข้อมูลในบล็อกของฉันที่จะช่วยคุณสร้างบริการที่ใหญ่ขึ้นที่มีประสิทธิภาพมากขึ้น
สำหรับการสาธิต ฉันจะใช้ JavaScript แต่ขั้นตอนจะคล้ายกันมากในทุกภาษา เริ่มต้นด้วยข้อมูลตัวอย่างโดยใช้ Mocky.io ที่น่าตื่นตาตื่นใจ
ผู้เขียน
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }กระทู้
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] ขั้นตอนแรกคือการสร้างโปรเจ็กต์ใหม่ด้วยมิดเดิลแวร์ express และ express-graphql
bash npm init -y && npm install --save graphql express express-graphql และเพื่อสร้างไฟล์ index.js ด้วยเซิร์ฟเวอร์ด่วน
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); ในการเริ่มทำงานกับ GraphQL เราสามารถเริ่มต้นด้วยการสร้างแบบจำลองข้อมูลใน REST API ในไฟล์ใหม่ชื่อ schema.js ให้เพิ่มสิ่งต่อไปนี้:

const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); โค้ดด้านบนจับคู่ประเภทต่างๆ ในการตอบสนอง JSON ของ API กับประเภทของ GraphQL GraphQLObjectType สอดคล้องกับ JavaScript Object , GraphQLString สอดคล้องกับ JavaScript String และอื่นๆ ประเภทพิเศษที่ต้องให้ความสนใจคือ GraphQLSchema ในสองสามบรรทัดสุดท้าย GraphQLSchema คือการส่งออกระดับรากของ GraphQL ซึ่งเป็นจุดเริ่มต้นสำหรับการสืบค้นเพื่อสำรวจกราฟ ในตัวอย่างพื้นฐานนี้ เรากำหนดเฉพาะการ query เท่านั้น นี่คือที่ที่คุณจะกำหนดการเปลี่ยนแปลง (เขียน) และการสมัครรับข้อมูล
ต่อไป เราจะเพิ่มสคีมาไปยังเซิร์ฟเวอร์ด่วนของเราในไฟล์ index.js ในการทำเช่นนี้ เราจะเพิ่มมิดเดิลแวร์ express-graphql และส่งผ่านไปยังสคีมา
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); ณ จุดนี้ แม้ว่าเราจะไม่ส่งคืนข้อมูลใดๆ แต่เราก็มีเซิร์ฟเวอร์ GraphQL ที่ใช้งานได้ซึ่งมีสคีมาให้กับลูกค้า เพื่อให้การเริ่มต้นแอปพลิเคชันง่ายขึ้น เราจะเพิ่มสคริปต์เริ่มต้นใน package.json
"scripts": { "start": "nodemon index.js" }, เรียกใช้โครงการและไปที่ https://localhost:5000/ ควรแสดง data explorer ชื่อ GraphiQL GraphiQL จะโหลดตามค่าเริ่มต้นตราบใดที่ส่วนหัว HTTP Accept ไม่ได้ตั้งค่าเป็น application/json การเรียก URL เดียวกันนี้ด้วยการ fetch หรือ cURL โดยใช้ application/json จะส่งคืนผลลัพธ์ JSON อย่าลังเลที่จะลองใช้เอกสารที่มีอยู่แล้วภายในและเขียนคำถาม

สิ่งเดียวที่ต้องทำเพื่อให้เซิร์ฟเวอร์สมบูรณ์คือการโยงข้อมูลพื้นฐานเข้ากับสคีมา ในการดำเนินการนี้ เราต้องกำหนดฟังก์ชันการ resolve ใน GraphQL คิวรีจะเรียกใช้จากบนลงล่างโดยเรียกใช้ฟังก์ชัน resolve ขณะที่ข้ามต้นไม้ ตัวอย่างเช่น สำหรับแบบสอบถามต่อไปนี้:
query homepage { posts { title } } GraphQL จะเรียก posts.resolve(parentData) ก่อน posts.title.resolve(parentData) เริ่มต้นด้วยการกำหนดตัวแก้ไขในรายการโพสต์บล็อกของเรา
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); ฉันกำลังใช้แพ็คเกจ isomorphic-fetch ที่นี่เพื่อส่งคำขอ HTTP เนื่องจากมันแสดงให้เห็นอย่างดีถึงวิธีการส่งคืน Promise จากตัวแก้ไข แต่คุณสามารถใช้อะไรก็ได้ที่คุณต้องการ ฟังก์ชันนี้จะคืนค่าอาร์เรย์ของโพสต์ไปยังประเภทบล็อก ฟังก์ชันแก้ไขเริ่มต้นสำหรับการใช้งาน JavaScript ของ GraphQL คือ parentData.<fieldName> ตัวอย่างเช่น ตัวแก้ไขเริ่มต้นสำหรับฟิลด์ชื่อผู้แต่งจะเป็น:
rawAuthorObject => rawAuthorObject.nameตัวแก้ไขการแทนที่เดี่ยวนี้ควรให้ข้อมูลสำหรับออบเจ็กต์โพสต์ทั้งหมด เรายังจำเป็นต้องกำหนดตัวแก้ไขสำหรับผู้เขียน แต่ถ้าคุณเรียกใช้แบบสอบถามเพื่อดึงข้อมูลที่จำเป็นสำหรับหน้าแรก คุณควรเห็นว่าการทำงานนั้นทำงาน
เนื่องจากแอตทริบิวต์ของผู้เขียนใน API โพสต์ของเราเป็นเพียง ID ผู้เขียน เมื่อ GraphQL ค้นหาอ็อบเจกต์ที่กำหนดชื่อและบริษัทและพบสตริง มันจะส่งคืน null เท่านั้น ในการเชื่อมต่อกับผู้เขียน เราต้องเปลี่ยน Post schema ให้มีลักษณะดังนี้:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });ตอนนี้ เรามีเซิร์ฟเวอร์ GraphQL ที่ทำงานได้อย่างสมบูรณ์ซึ่งรวม REST API สามารถดาวน์โหลดแหล่งข้อมูลฉบับเต็มได้จากลิงก์ Github นี้ หรือเรียกใช้จากแผ่นเปิดใช้ GraphQL นี้
คุณอาจกำลังสงสัยเกี่ยวกับเครื่องมือที่คุณต้องใช้เพื่อใช้จุดปลาย GraphQL แบบนี้ มีตัวเลือกมากมาย เช่น Relay และ Apollo แต่ในการเริ่ม ฉันคิดว่าวิธีที่ง่ายที่สุดคือดีที่สุด หากคุณเล่น GraphiQL บ่อย คุณอาจสังเกตเห็นว่า URL ยาว URL นี้เป็นเพียงเวอร์ชันที่เข้ารหัส URI ของข้อความค้นหาของคุณ ในการสร้างแบบสอบถาม GraphQL ใน JavaScript คุณสามารถทำสิ่งนี้:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);หรือหากต้องการ คุณสามารถคัดลอกและวาง URL จาก GraphiQL ดังนี้:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageเนื่องจากเรามีจุดปลาย GraphQL และวิธีการใช้งาน เราจึงสามารถเปรียบเทียบกับ RESTish API ของเราได้ รหัสที่เราต้องเขียนเพื่อดึงข้อมูลของเราโดยใช้ RESTish API มีลักษณะดังนี้:
การใช้ RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };การใช้ GraphQL API
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);โดยสรุป เราใช้ GraphQL เพื่อ:
- ลดคำขอ 9 รายการ (รายการโพสต์ บล็อกโพสต์ 4 รายการ และผู้เขียนแต่ละโพสต์)
- ลดปริมาณข้อมูลที่ส่งเป็นเปอร์เซ็นต์ที่มีนัยสำคัญ
- ใช้เครื่องมือสำหรับนักพัฒนาที่ยอดเยี่ยมเพื่อสร้างคำค้นหาของเรา
- เขียนโค้ดที่สะอาดกว่าในลูกค้าของเรา
ข้อบกพร่องใน GraphQL
ในขณะที่ฉันเชื่อว่าโฆษณานั้นสมเหตุสมผล แต่ไม่มีสัญลักษณ์แสดงหัวข้อย่อยสีเงิน และ GraphQL นั้นยอดเยี่ยมมาก แต่ก็ไม่ได้ไม่มีข้อบกพร่อง
ความสมบูรณ์ของข้อมูล
บางครั้ง GraphQL ดูเหมือนเครื่องมือที่สร้างขึ้นมาเพื่อข้อมูลที่ดีโดยเฉพาะ มักจะทำงานได้ดีที่สุดในฐานะเกตเวย์ การรวมบริการที่แตกต่างกันหรือตารางที่มีการปรับมาตรฐานสูงเข้าด้วยกัน หากข้อมูลที่กลับมาจากบริการที่คุณใช้มีระเบียบและไม่มีโครงสร้าง การเพิ่มไปป์ไลน์การแปลงข้อมูลภายใต้ GraphQL อาจเป็นเรื่องท้าทายอย่างแท้จริง ขอบเขตของฟังก์ชันแก้ไข GraphQL เป็นเพียงข้อมูลของตัวเองและของฟังก์ชันย่อยเท่านั้น หากงานการประสานต้องการการเข้าถึงข้อมูลในพี่น้องหรือพาเรนต์ในแผนผัง อาจเป็นเรื่องท้าทายอย่างยิ่ง
การจัดการข้อผิดพลาดที่ซับซ้อน
คำขอ GraphQL สามารถเรียกใช้การสืบค้นได้ตามจำนวนที่ต้องการ และแต่ละการสืบค้นสามารถใช้บริการได้ตามจำนวนที่ต้องการ หากส่วนใดส่วนหนึ่งของคำขอล้มเหลว แทนที่จะล้มเหลวในคำขอทั้งหมด โดยค่าเริ่มต้น GraphQL จะส่งกลับข้อมูลบางส่วน ข้อมูลบางส่วนน่าจะเป็นทางเลือกที่เหมาะสมในทางเทคนิค และอาจเป็นประโยชน์อย่างเหลือเชื่อและมีประสิทธิภาพ ข้อเสียคือการจัดการข้อผิดพลาดนั้นไม่ง่ายเหมือนการตรวจสอบรหัสสถานะ HTTP อีกต่อไป ลักษณะการทำงานนี้สามารถปิดได้ แต่บ่อยครั้งกว่านั้น ไคลเอ็นต์จะลงเอยด้วยกรณีข้อผิดพลาดที่ซับซ้อนมากขึ้น
เก็บเอาไว้
แม้ว่ามักจะเป็นความคิดที่ดีที่จะใช้การสืบค้น GraphQL แบบคงที่ สำหรับองค์กรอย่าง Github ที่อนุญาตการสืบค้นโดยอำเภอใจ การแคชเครือข่ายด้วยเครื่องมือมาตรฐาน เช่น Varnish หรือ Fastly จะไม่สามารถทำได้อีกต่อไป
ค่าใช้จ่าย CPU สูง
การแยกวิเคราะห์ การตรวจสอบความถูกต้อง และการตรวจสอบประเภทการสืบค้นเป็นกระบวนการที่ผูกกับ CPU ซึ่งอาจนำไปสู่ปัญหาด้านประสิทธิภาพในภาษาแบบเธรดเดียว เช่น JavaScript
นี่เป็นปัญหาสำหรับการประเมินคิวรีรันไทม์เท่านั้น
ปิดความคิด
คุณสมบัติของ GraphQL ไม่ใช่การปฏิวัติ — ฟีเจอร์บางอย่างมีมาเกือบ 30 ปีแล้ว สิ่งที่ทำให้ GraphQL มีประสิทธิภาพคือระดับของการขัดเกลา การผสานรวม และความสะดวกในการใช้งานทำให้เป็นมากกว่าผลรวมของส่วนต่างๆ
หลายสิ่งที่ GraphQL ทำได้สำเร็จด้วยความพยายามและวินัย สามารถทำได้โดยใช้ REST หรือ RPC แต่ GraphQL นำ API ที่ล้ำสมัยมาสู่โครงการจำนวนมหาศาลที่อาจไม่มีเวลา ทรัพยากร หรือเครื่องมือในการทำสิ่งนี้ด้วยตนเอง เป็นความจริงเช่นกันที่ GraphQL ไม่ใช่สัญลักษณ์แสดงหัวข้อย่อยสีเงิน แต่ข้อบกพร่องมักจะเล็กน้อยและเข้าใจกันดี ในฐานะที่เป็นคนที่สร้างเซิร์ฟเวอร์ GraphQL ที่ซับซ้อนพอสมควร ฉันสามารถพูดได้อย่างง่ายดายว่าประโยชน์ที่ได้รับนั้นมีค่ามากกว่าต้นทุนอย่างง่ายดาย
บทความนี้เน้นเกือบทั้งหมดว่าทำไม GraphQL ถึงมีอยู่และปัญหาที่แก้ไขได้ หากสิ่งนี้ทำให้คุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับความหมายและวิธีใช้มัน เราขอแนะนำให้คุณเรียนรู้วิธีใดๆ ที่ดีที่สุดสำหรับคุณ ไม่ว่าจะเป็นบล็อก, youtube หรือเพียงแค่อ่านแหล่งที่มา (How To GraphQL ดีมาก)
หากคุณชอบบทความนี้ (หรือไม่ชอบบทความนี้) และต้องการแสดงความคิดเห็น โปรดหาฉันบน Twitter ในชื่อ @ebaerbaerbaer หรือ LinkedIn ที่ ericjbaer