
ไพรเมอร์ GraphQL: เหตุใดเราจึงต้องการ API ชนิดใหม่ (ตอนที่ 1)
เผยแพร่แล้ว: 2022-03-10ในชุดนี้ ผมอยากแนะนำให้คุณรู้จักกับ GraphQL ในตอนท้าย คุณควรเข้าใจไม่เพียงแค่ว่ามันคืออะไร แต่ยังรวมถึงที่มาของมัน ข้อเสีย และพื้นฐานของวิธีการทำงานกับมันด้วย ในบทความแรกนี้ แทนที่จะกระโดดไปสู่การใช้งานจริง ฉันต้องการอธิบายว่าเรามาถึง GraphQL (และเครื่องมือที่คล้ายกัน) ได้อย่างไรและทำไม (และเครื่องมือที่คล้ายกัน) โดยดูจากบทเรียนที่ได้รับจากการพัฒนา API ในช่วง 60 ปีที่ผ่านมา ตั้งแต่ RPC จนถึงปัจจุบัน ท้ายที่สุด ตามที่ Mark Twain อธิบายไว้อย่างมีสีสัน ไม่มีแนวคิดใหม่
“ไม่มีสิ่งที่เรียกว่าความคิดใหม่ มันเป็นไปไม่ได้ เราเพียงแค่นำความคิดเก่า ๆ มามากมายและใส่ลงในลานตาทางจิต”
— Mark Twain ใน "อัตชีวประวัติของ Mark Twain: บทจากบทวิจารณ์อเมริกาเหนือ"
แต่ก่อนอื่นฉันต้องพูดกับช้างในห้องก่อน สิ่งใหม่ๆ น่าตื่นเต้นอยู่เสมอ แต่ก็สามารถรู้สึกเหนื่อยได้เช่นกัน คุณอาจเคยได้ยินเกี่ยวกับ GraphQL และคิดกับตัวเองว่า “ทำไม…” หรือบางทีคุณอาจคิดว่า “ทำไมฉันถึงสนใจเกี่ยวกับแนวโน้มการออกแบบ API ใหม่ REST คือ… ได้” คำถามเหล่านี้เป็นคำถามที่ถูกต้องตามกฎหมาย ดังนั้นให้ฉันช่วยอธิบายว่าทำไมคุณควรให้ความสนใจกับคำถามนี้
บทนำ
ประโยชน์ของการนำเครื่องมือใหม่ๆ มาสู่ทีมต้องชั่งน้ำหนักเทียบกับต้นทุน มีหลายอย่างให้วัด ต้องใช้เวลาในการเรียนรู้ เวลาในการแปลงใช้เวลาออกจากการพัฒนาคุณลักษณะ ค่าใช้จ่ายในการบำรุงรักษาสองระบบ ด้วยต้นทุนที่สูงเช่นนี้ เทคโนโลยีใหม่ใดๆ จะต้องดีกว่า เร็วขึ้น หรือให้ผลผลิตมากขึ้น ในปริมาณมหาศาล การปรับปรุงที่เพิ่มขึ้นแม้จะน่าตื่นเต้น แต่ก็ไม่คุ้มกับการลงทุน ประเภทของ API ที่ฉันต้องการจะพูดถึง โดยเฉพาะ GraphQL ถือเป็นก้าวที่ยิ่งใหญ่ในความคิดของฉัน และให้ประโยชน์ที่มากเกินพอที่จะปรับต้นทุนได้
แทนที่จะสำรวจคุณลักษณะก่อน คุณควรใส่ไว้ในบริบทและทำความเข้าใจว่าคุณลักษณะเหล่านี้เกิดขึ้นได้อย่างไร ในการทำเช่นนี้ ฉันจะเริ่มต้นด้วยการสรุปประวัติของ API เล็กน้อย
RPC
RPC น่าจะเป็นรูปแบบ API หลักรูปแบบแรกและต้นกำเนิดของมันย้อนกลับไปสู่การคำนวณในช่วงต้นในช่วงกลางทศวรรษที่ 60 ในขณะนั้น คอมพิวเตอร์ยังคงมีขนาดใหญ่และมีราคาแพงมากจนแนวคิดของการพัฒนาแอปพลิเคชันที่ขับเคลื่อนด้วย API อย่างที่เราคิดนั้นส่วนใหญ่เป็นเพียงแค่ทฤษฎีเท่านั้น ข้อจำกัด เช่น แบนด์วิดท์/เวลาแฝง กำลังในการคำนวณ เวลาประมวลผลที่ใช้ร่วมกัน และความใกล้ชิดทางกายภาพ บังคับให้วิศวกรคิดในแง่ของระบบแบบกระจาย มากกว่าบริการที่แสดงข้อมูล ตั้งแต่ ARPANET ในยุค 60 ไปจนถึงกลางทศวรรษ 90 ด้วยสิ่งต่างๆ เช่น CORBA และ RMI ของ Java คอมพิวเตอร์ส่วนใหญ่โต้ตอบกันโดยใช้ Remote Procedure Calls (RPC) ซึ่งเป็นโมเดลการโต้ตอบระหว่างไคลเอ็นต์กับเซิร์ฟเวอร์ โดยที่ไคลเอ็นต์ทำให้เกิดกระบวนการ (หรือวิธีการ) เพื่อดำเนินการบนเซิร์ฟเวอร์ระยะไกล
มีเรื่องดีๆ มากมายเกี่ยวกับ RPC หลักการสำคัญคืออนุญาตให้นักพัฒนาจัดการโค้ดในสภาพแวดล้อมระยะไกลราวกับว่าอยู่ในระบบภายในเครื่อง แม้ว่าจะช้ากว่าและเชื่อถือได้น้อยกว่ามาก ซึ่งสร้างความต่อเนื่องในระบบที่แตกต่างและแตกต่างออกไป เช่นเดียวกับหลาย ๆ อย่างที่ออกมา ARPANET เกิดขึ้น มันมาก่อนเวลาเนื่องจากความต่อเนื่องประเภทนี้เป็นสิ่งที่เรายังคงพยายามทำเมื่อทำงานกับการกระทำที่ไม่น่าเชื่อถือและไม่ตรงกัน เช่น การเข้าถึงฐานข้อมูลและการเรียกใช้บริการภายนอก
ตลอดหลายทศวรรษที่ผ่านมา มีการวิจัยจำนวนมหาศาลเกี่ยวกับวิธีการอนุญาตให้นักพัฒนาฝังพฤติกรรมแบบอะซิงโครนัสเช่นนี้ลงในโฟลว์ทั่วไปของโปรแกรม หากมีสิ่งต่างๆ เช่น Promises, Futures และ ScheduledTasks พร้อมใช้งานในขณะนั้น เป็นไปได้ว่าภาพรวม API ของเราจะดูแตกต่างออกไป
อีกสิ่งที่ยอดเยี่ยมเกี่ยวกับ RPC ก็คือ เนื่องจากไม่มีข้อจำกัดโดยโครงสร้างของข้อมูลจึงสามารถเขียนวิธีการเฉพาะทางขั้นสูงสำหรับลูกค้าที่ร้องขอและดึงข้อมูลที่ต้องการได้อย่างแม่นยำ ซึ่งอาจส่งผลให้ค่าใช้จ่ายของเครือข่ายน้อยที่สุดและเพย์โหลดมีขนาดเล็กลง
อย่างไรก็ตาม มีสิ่งที่ทำให้ RPC ยากขึ้น อย่างแรก ความต่อเนื่องต้องมีบริบท โดยการออกแบบ RPC ทำให้เกิดการเชื่อมโยงกันค่อนข้างมากระหว่างระบบในพื้นที่และระบบระยะไกล คุณสูญเสียขอบเขตระหว่างรหัสท้องถิ่นและรหัสระยะไกลของคุณ สำหรับบางโดเมน วิธีนี้ใช้ได้หรือแม้แต่ต้องการเหมือนใน SDK ของไคลเอ็นต์ แต่สำหรับ API ที่โค้ดไคลเอ็นต์ไม่เข้าใจดี อาจมีความยืดหยุ่นน้อยกว่าบางอย่างที่เน้นข้อมูลมากกว่า
ที่สำคัญกว่านั้นคือ ศักยภาพในการเพิ่มจำนวนของเมธอด API ตามทฤษฎีแล้ว บริการ RPC จะเปิดเผย API เล็กๆ น้อยๆ ที่รอบคอบซึ่งสามารถจัดการกับงานใดๆ ก็ได้ ในทางปฏิบัติ อุปกรณ์ปลายทางภายนอกจำนวนมากสามารถเพิ่มขึ้นได้โดยไม่ต้องมีโครงสร้างมากนัก ต้องใช้วินัยอย่างมากในการป้องกัน API ที่ทับซ้อนกันและการทำซ้ำเมื่อเวลาผ่านไป เนื่องจากสมาชิกในทีมเข้าๆ ออกๆ และเปลี่ยนโครงการ
เป็นความจริงที่การเปลี่ยนแปลงเครื่องมือและเอกสารที่เหมาะสม เช่นที่ฉันพูดถึง สามารถจัดการได้ แต่ในเวลาที่ฉันเขียนซอฟต์แวร์ ฉันพบบริการด้านเอกสารอัตโนมัติและบริการที่มีระเบียบวินัยเพียงเล็กน้อย สำหรับฉัน นี่เป็นเรื่องเล็กน้อย ปลาชนิดหนึ่งสีแดง.
สบู่
API หลักประเภทต่อไปที่จะตามมาคือ SOAP ซึ่งถือกำเนิดขึ้นในช่วงปลายยุค 90 ที่ Microsoft Research SOAP ( S imple O bject A access P rotocol) เป็นข้อกำหนดโปรโตคอลที่มีความทะเยอทะยานสำหรับการสื่อสารแบบ XML ระหว่างแอปพลิเคชัน ความทะเยอทะยานที่ระบุไว้ของ SOAP คือการจัดการกับข้อเสียบางประการของ RPC โดยเฉพาะ XML-RPC โดยการสร้างพื้นฐานที่มีโครงสร้างที่ดีสำหรับบริการเว็บที่ซับซ้อน ผลที่ได้ นี้หมายถึงการเพิ่มระบบประเภทพฤติกรรมลงใน XML น่าเศร้าที่มันสร้างสิ่งกีดขวางมากกว่าที่จะแก้ไขโดยเห็นได้จากข้อเท็จจริงที่ว่ามีการเขียน SOAP endpoint ใหม่น้อยมากในปัจจุบัน
"SOAP คือสิ่งที่คนส่วนใหญ่ถือว่าประสบความสำเร็จในระดับปานกลาง"
— ดอนกล่อง
SOAP มีบางสิ่งที่ดีเกิดขึ้นแม้ว่าจะมีการใช้คำฟุ่มเฟือยและชื่อที่น่ากลัว สัญญาที่บังคับใช้ใน WSDL และ WADL (อ่านว่า “wizdle” และ “waddle”) ระหว่างไคลเอนต์และเซิร์ฟเวอร์รับประกันผลลัพธ์ที่คาดการณ์ได้ ปลอดภัยต่อการพิมพ์ และ WSDL สามารถใช้เพื่อสร้างเอกสารประกอบหรือเพื่อสร้างการผสานรวมกับ IDE และเครื่องมืออื่นๆ
การเปิดเผยครั้งใหญ่ของ SOAP เกี่ยวกับวิวัฒนาการของ API คือการแนะนำการเรียกที่เน้นทรัพยากรอย่างค่อยเป็นค่อยไปและอาจไม่ตั้งใจ ตำแหน่งข้อมูล SOAP อนุญาตให้คุณร้องขอข้อมูลด้วยโครงสร้างที่กำหนดไว้ล่วงหน้า แทนที่จะคิดถึงวิธีการที่จำเป็นในการสร้างข้อมูล (สมมติว่าเขียนในลักษณะนี้)
ข้อเสียที่สำคัญที่สุดของ SOAP คือความละเอียดอ่อนมาก แทบจะเป็นไปไม่ได้เลยที่จะใช้งานโดยไม่มีเครื่องมือ มากมาย คุณต้องมีเครื่องมือในการเขียนการทดสอบ การใช้เครื่องมือเพื่อตรวจสอบการตอบสนองจากเซิร์ฟเวอร์ และเครื่องมือเพื่อแยกวิเคราะห์ข้อมูลทั้งหมด ระบบที่เก่ากว่าจำนวนมากยังคงใช้ SOAP แต่ข้อกำหนดของเครื่องมือทำให้ยุ่งยากเกินไปสำหรับโครงการใหม่ส่วนใหญ่ และจำนวนไบต์ที่จำเป็นสำหรับโครงสร้าง XML ทำให้เป็นทางเลือกที่ไม่ดีสำหรับการให้บริการอุปกรณ์เคลื่อนที่หรือระบบกระจายเสียงพูด
สำหรับข้อมูลเพิ่มเติม ควรอ่านข้อกำหนดของ SOAP และประวัติที่น่าสนใจของ SOAP จาก Don Box ซึ่งเป็นหนึ่งในสมาชิกทีมดั้งเดิม
พักผ่อน
ในที่สุด เราก็มาถึงรูปแบบการออกแบบ API du jour: REST REST ซึ่งเปิดตัวในวิทยานิพนธ์ระดับปริญญาเอกโดย Roy Fielding ในปี 2000 เหวี่ยงลูกตุ้มไปในทิศทางที่ต่างไปจากเดิมอย่างสิ้นเชิง REST นั้นตรงกันข้ามกับ SOAP ในหลาย ๆ ด้านและการดูเคียงข้างกันทำให้คุณรู้สึกว่าวิทยานิพนธ์ของเขาเป็นการเลิกโกรธเล็กน้อย
SOAP ใช้ HTTP เป็นการขนส่งที่โง่เขลา และสร้างโครงสร้างในเนื้อหาคำขอและการตอบสนอง ในทางกลับกัน REST จะแสดงสัญญาไคลเอนต์-เซิร์ฟเวอร์ เครื่องมือ XML และส่วนหัวตามความต้องการ โดยแทนที่ด้วยความหมายของ HTTP เนื่องจากเป็นโครงสร้างที่เลือกแทนที่จะใช้กริยา HTTP โต้ตอบกับข้อมูลและ URI ที่อ้างอิงทรัพยากรในลำดับชั้นบางชั้นของ ข้อมูล.
| สบู่ | พักผ่อน | |
|---|---|---|
| กริยา HTTP | รับ, วาง, โพสต์, แพทช์, ลบ | |
| รูปแบบข้อมูล | XML | อะไรก็ได้ที่คุณต้องการ |
| สัญญาลูกค้า/เซิร์ฟเวอร์ | ทั้งวัน 'ทุกวัน! | ใครต้องการสิ่งนั้น |
| พิมพ์ระบบ | JavaScript ได้ unsigned short ใช่ไหม | |
| URL | อธิบายการดำเนินงาน | ทรัพยากรที่มีชื่อ |
REST เปลี่ยนการออกแบบ API อย่างสมบูรณ์และชัดเจนจากการโต้ตอบของการสร้างแบบจำลองเป็นเพียงแค่การสร้างแบบจำลองข้อมูลของโดเมน การเน้นทรัพยากรอย่างเต็มที่เมื่อทำงานกับ REST API คุณไม่จำเป็นต้องรู้หรือสนใจอีกต่อไปว่าจะต้องทำอะไรเพื่อดึงข้อมูลที่กำหนด คุณไม่จำเป็นต้องรู้อะไรเกี่ยวกับการใช้บริการแบ็กเอนด์

ความเรียบง่ายไม่เพียงเป็นประโยชน์สำหรับนักพัฒนาเท่านั้น แต่เนื่องจาก URL แสดงถึงข้อมูลที่มีเสถียรภาพ จึงสามารถแคชได้ง่าย การไร้สัญชาติทำให้ง่ายต่อการปรับขนาดในแนวนอน และเนื่องจากเป็นแบบจำลองข้อมูลแทนที่จะคาดการณ์ความต้องการของผู้บริโภค จึงสามารถลดพื้นที่ผิวของ API ได้อย่างมาก .
REST นั้นยอดเยี่ยม และการแพร่หลายของมันคือความสำเร็จที่น่าอัศจรรย์ แต่เช่นเดียวกับวิธีแก้ปัญหาทั้งหมดที่เกิดขึ้นก่อนหน้า REST ก็ไม่มีข้อบกพร่อง ในการพูดถึงข้อบกพร่องบางประการอย่างเป็นรูปธรรม เรามาดูตัวอย่างพื้นฐานกัน สมมติว่าเราต้องสร้างหน้า Landing Page ของบล็อกซึ่งแสดงรายการโพสต์ในบล็อกและชื่อผู้เขียน
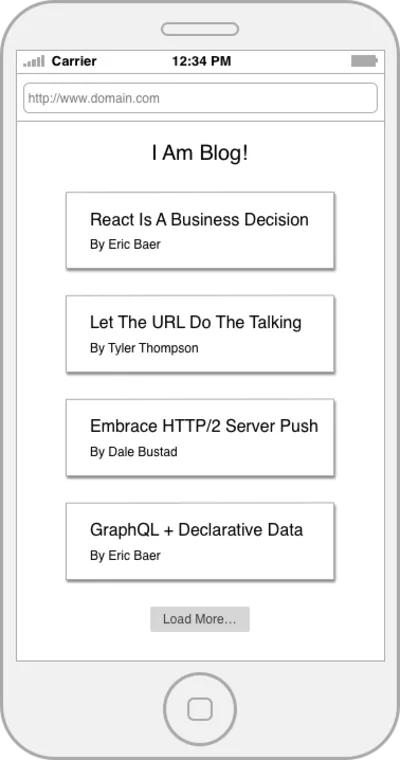
มาเขียนโค้ดที่สามารถดึงข้อมูลหน้าแรกจาก REST API ธรรมดากัน เราจะเริ่มต้นด้วยฟังก์ชันสองสามอย่างที่รวบรวมทรัพยากรของเรา
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);เอาล่ะ มาเตรียมการกันเถอะ!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };ดังนั้นรหัสของเราจะทำสิ่งต่อไปนี้:
- ดึงกระทู้ทั้งหมด;
- ดึงรายละเอียดเกี่ยวกับแต่ละโพสต์
- ดึงทรัพยากรผู้เขียนสำหรับแต่ละโพสต์
สิ่งที่ดีคือมันค่อนข้างง่ายต่อการให้เหตุผล มีการจัดระเบียบอย่างดี และขอบเขตแนวคิดของแต่ละทรัพยากรนั้นถูกวาดออกมาอย่างดี คนเกียจคร้านที่นี่คือเราเพิ่งส่งคำขอเครือข่ายแปดรายการซึ่งส่วนใหญ่เกิดขึ้นในแบบอนุกรม
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 ใช่ คุณสามารถวิพากษ์วิจารณ์ตัวอย่างนี้โดยแนะนำว่า API อาจมีจุดปลาย /posts ที่มีเลขหน้า แต่นั่นเป็นเส้นแบ่ง ความจริงก็คือคุณมักจะมีคอลเล็กชันการเรียก API ที่ต้องพึ่งพาซึ่งกันและกันเพื่อแสดงแอปพลิเคชันหรือเพจที่สมบูรณ์
การพัฒนาไคลเอ็นต์และเซิร์ฟเวอร์ REST นั้นดีกว่าที่เคยมีมาอย่างแน่นอน หรืออย่างน้อยก็เป็นการพิสูจน์ที่งี่เง่ามากขึ้น แต่มีการเปลี่ยนแปลงมากมายในช่วงสองทศวรรษที่ผ่านมาตั้งแต่รายงานของ Fielding ในขณะนั้น คอมพิวเตอร์ทุกเครื่องเป็นพลาสติกสีเบจ ตอนนี้มันเป็นอลูมิเนียม! อย่างจริงจังแม้ว่า 2000 อยู่ใกล้กับจุดสูงสุดของการระเบิดในคอมพิวเตอร์ส่วนบุคคล ทุกๆ ปี โปรเซสเซอร์มีความเร็วเพิ่มขึ้นเป็นสองเท่า และเครือข่ายก็เร็วขึ้นในอัตราที่เหลือเชื่อ การเจาะตลาดของอินเทอร์เน็ตอยู่ที่ประมาณ 45% โดยไม่มีที่ไปแต่เพิ่มขึ้น
จากนั้น ประมาณปี 2008 คอมพิวเตอร์พกพากลายเป็นกระแสหลัก เมื่อใช้อุปกรณ์เคลื่อนที่ เราถดถอยอย่างมีประสิทธิภาพเป็นเวลา 10 ปีในแง่ของความเร็ว/ประสิทธิภาพในชั่วข้ามคืน ในปี 2560 เรามีสมาร์ทโฟนในประเทศเกือบ 80% และการเจาะสมาร์ทโฟนทั่วโลกมากกว่า 50% และถึงเวลาแล้วที่จะคิดใหม่เกี่ยวกับสมมติฐานของเราเกี่ยวกับการออกแบบ API
จุดอ่อนของ REST
ต่อไปนี้คือลักษณะสำคัญที่ REST จากมุมมองของนักพัฒนาแอปพลิเคชันไคลเอ็นต์ โดยเฉพาะที่ทำงานในอุปกรณ์เคลื่อนที่ API แบบ GraphQL และ GraphQL ไม่ใช่เรื่องใหม่และไม่ได้แก้ปัญหาที่อยู่นอกเหนือความเข้าใจของนักพัฒนา REST การสนับสนุนที่สำคัญที่สุดของ GraphQL คือความสามารถในการแก้ปัญหาเหล่านี้อย่างเป็นระบบและด้วยระดับของการบูรณาการที่ไม่พร้อมในที่อื่น กล่าวคือเป็นโซลูชัน "รวมแบตเตอรี่"
ผู้เขียนหลักของ REST รวมถึง Fielding ได้ตีพิมพ์บทความเมื่อปลายปี 2017 (Reflections on the REST Architectural Style และ "Principled Design of the Modern Web Architecture") สะท้อนถึง REST สองทศวรรษและรูปแบบมากมายที่ได้รับแรงบันดาลใจ สั้นและคุ้มค่าแก่การอ่านสำหรับทุกคนที่สนใจในการออกแบบ API
ด้วยบริบททางประวัติศาสตร์และแอปอ้างอิง มาดูจุดอ่อนหลักสามประการของ REST
REST Is Chatty
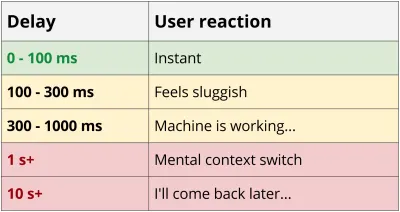
บริการ REST มักจะค่อนข้าง "ช่างพูด" เนื่องจากต้องใช้การเดินทางไปกลับหลายครั้งระหว่างไคลเอนต์และเซิร์ฟเวอร์เพื่อรับข้อมูลเพียงพอที่จะแสดงผลแอปพลิเคชัน คำขอที่เรียงซ้อนนี้ส่งผลกระทบด้านประสิทธิภาพอย่างรุนแรง โดยเฉพาะบนมือถือ กลับไปที่ตัวอย่างบล็อก แม้แต่ในสถานการณ์ที่ดีที่สุดกับโทรศัพท์ใหม่และเครือข่ายที่เชื่อถือได้ด้วยการเชื่อมต่อ 4G คุณใช้เวลาเกือบ 0.5 วินาทีไปกับค่าใช้จ่ายแฝงก่อนที่จะดาวน์โหลดข้อมูลไบต์แรก
เวลาแฝง 4G 55ms * 8 คำขอ = ค่าใช้จ่าย 440ms
ปัญหาอีกประการของบริการช่างพูดคือ ในหลายกรณี การดาวน์โหลดคำขอขนาดใหญ่หนึ่งครั้งจะใช้เวลาน้อยกว่าคำขอขนาดเล็กจำนวนมาก ประสิทธิภาพที่ลดลงของคำขอขนาดเล็กนั้นเกิดขึ้นได้จากหลายสาเหตุ รวมถึง TCP Slow Start การขาดการบีบอัดส่วนหัวและประสิทธิภาพของ gzip และหากคุณอยากรู้เกี่ยวกับเรื่องนี้ ฉันขอแนะนำให้อ่าน High-Performance Browser Networking ของ Ilya Grigorik บล็อก MaxCDN ยังมีภาพรวมที่ดีอีกด้วย
ปัญหานี้ไม่ใช่ในทางเทคนิคกับ REST แต่กับ HTTP โดยเฉพาะ HTTP/1 HTTP/2 ทั้งหมดแต่แก้ปัญหาการพูดคุยโดยไม่คำนึงถึงรูปแบบ API และมีการสนับสนุนในวงกว้างในไคลเอนต์ เช่น เบราว์เซอร์และ SDK ดั้งเดิม ขออภัย การเปิดตัวช้าในด้าน API ในบรรดาเว็บไซต์ 10k อันดับต้น ๆ การนำไปใช้นั้นอยู่ที่ประมาณ 20% (และเพิ่มขึ้นเรื่อยๆ) ณ สิ้นปี 2560 แม้แต่ Node.js ที่ฉันประหลาดใจมากก็ยังได้รับการสนับสนุน HTTP/2 ในรุ่น 8.x หากคุณมีความสามารถ โปรดอัปเดตโครงสร้างพื้นฐานของคุณ! ในระหว่างนี้ อย่าคิดมากเพราะนี่เป็นเพียงส่วนหนึ่งของสมการ
นอกจาก HTTP แล้ว เหตุผลสุดท้ายที่ว่าทำไมการสนทนาถึงมีความสำคัญ เกี่ยวข้องกับวิธีการทำงานของอุปกรณ์พกพา และโดยเฉพาะอย่างยิ่งวิทยุของพวกเขาทำงาน ส่วนที่สั้นและยาวก็คือ การใช้งานวิทยุเป็นส่วนที่ใช้พลังงานแบตเตอรี่มากที่สุดแห่งหนึ่งของโทรศัพท์ ดังนั้น OS จะปิดการทำงานในทุกโอกาส ไม่เพียงแต่การสตาร์ทวิทยุจะทำให้แบตเตอรี่หมด แต่ยังเพิ่มค่าใช้จ่ายให้กับคำขอแต่ละรายการอีกด้วย
TMI (การดึงข้อมูลมากเกินไป)
ปัญหาต่อไปของบริการสไตล์ REST คือการส่งข้อมูลมากกว่าที่จำเป็น ในตัวอย่างบล็อกของเรา ทั้งหมดที่เราต้องการคือชื่อของแต่ละโพสต์และชื่อผู้แต่ง ซึ่งมีเพียงประมาณ 17% ของจำนวนที่ส่งคืน นั่นคือการสูญเสีย 6x สำหรับน้ำหนักบรรทุกที่ง่ายมาก ใน API ในโลกแห่งความเป็นจริง ค่าใช้จ่ายประเภทนั้นอาจมีค่ามหาศาล ตัวอย่างเช่น ไซต์อีคอมเมิร์ซมักแสดงผลิตภัณฑ์เดียวเป็น JSON หลายพันบรรทัด เช่นเดียวกับปัญหาของการสนทนา บริการ REST สามารถจัดการกับสถานการณ์นี้ได้ในปัจจุบันโดยใช้ "ชุดเขตข้อมูลแบบกระจัดกระจาย" เพื่อรวมหรือแยกข้อมูลบางส่วนตามเงื่อนไข ขออภัย การสนับสนุนนี้ไม่ชัดเจน ไม่สมบูรณ์ หรือมีปัญหาในการแคชเครือข่าย
เครื่องมือและวิปัสสนา
สิ่งสุดท้ายที่ REST API ขาดคือกลไกสำหรับการวิปัสสนา หากไม่มีสัญญาที่มีข้อมูลเกี่ยวกับประเภทการส่งคืนหรือโครงสร้างของปลายทาง ไม่มีทางที่จะสร้างเอกสาร สร้างเครื่องมือ หรือโต้ตอบกับข้อมูลได้อย่างน่าเชื่อถือ เป็นไปได้ที่จะทำงานภายใน REST เพื่อแก้ปัญหานี้ในระดับต่างๆ โปรเจ็กต์ที่ใช้ OpenAPI, OData หรือ JSON API อย่างเต็มรูปแบบมักจะสะอาด มีการระบุอย่างดี และมีการจัดทำเป็นเอกสารอย่างดีในขอบเขตที่แตกต่างกัน แต่แบ็กเอนด์เช่นนี้หายาก แม้แต่ Hypermedia ซึ่งเป็นผลไม้แขวนคอที่ค่อนข้างต่ำ แม้จะถูกโน้มน้าวในการประชุมใหญ่เป็นเวลาหลายสิบปี แต่ก็ยังทำได้ไม่ดีนักหากเป็นเช่นนั้น
บทสรุป
API แต่ละประเภทมีข้อบกพร่อง แต่ทุกรูปแบบมี งานเขียนนี้ไม่ใช่การตัดสินรากฐานอันมหัศจรรย์ที่ยักษ์ใหญ่ในซอฟต์แวร์วางไว้ เพียงเพื่อประเมินรูปแบบเหล่านี้อย่างมีสติ ใช้ในรูปแบบที่ "บริสุทธิ์" จากมุมมองของนักพัฒนาไคลเอนต์ ฉันหวังว่าแทนที่จะออกจากความคิดนี้ รูปแบบเช่น REST หรือ RPC เสีย ที่คุณสามารถลองนึกดูว่าแต่ละอย่างทำให้เกิดการแลกเปลี่ยนได้อย่างไร และพื้นที่ที่ องค์กรด้านวิศวกรรมอาจมุ่งเน้นความพยายามในการปรับปรุง API ของตนเอง
ในบทความถัดไป ผมจะมาศึกษาเกี่ยวกับ GraphQL และวิธีการแก้ไขปัญหาที่ผมได้กล่าวมาข้างต้น นวัตกรรมใน GraphQL และเครื่องมือที่คล้ายคลึงกันนั้นอยู่ในระดับของการบูรณาการและไม่ได้อยู่ในการใช้งาน ได้โปรด หากคุณหรือทีมของคุณไม่ได้มองหา API ที่ "รวมแบตเตอรี่" ไว้ ให้พิจารณามองหาบางอย่าง เช่น ข้อมูลจำเพาะ OpenAPI ใหม่ที่สามารถช่วยสร้างรากฐานที่แข็งแกร่งขึ้นได้ในวันนี้!
หากคุณชอบบทความนี้ (หรือไม่ชอบบทความนี้) และต้องการแสดงความคิดเห็น โปรดหาฉันบน Twitter ในชื่อ @ebaerbaerbaer หรือ LinkedIn ที่ ericjbaer