
การตรวจจับข่าวปลอมในการเรียนรู้ของเครื่อง [อธิบายด้วยตัวอย่างการเข้ารหัส]
เผยแพร่แล้ว: 2021-02-08ข่าวปลอมเป็นหนึ่งในปัญหาที่ใหญ่ที่สุดในยุคปัจจุบันของอินเทอร์เน็ตและโซเชียลมีเดีย แม้ว่าข่าวจะไหลจากมุมหนึ่งไปยังอีกมุมหนึ่งของโลกภายในเวลาไม่กี่ชั่วโมงก็ตาม นับเป็นเรื่องน่ายินดี แต่ก็เป็นเรื่องที่น่าเจ็บปวดที่เห็นผู้คนและกลุ่มต่างๆ จำนวนมากเผยแพร่ข่าวปลอม
เทคนิคการเรียนรู้ของเครื่องโดยใช้การประมวลผลภาษาธรรมชาติและการเรียนรู้เชิงลึกสามารถใช้เพื่อแก้ไขปัญหานี้ได้ในระดับหนึ่ง เราจะสร้างแบบจำลองการตรวจจับข่าวปลอมโดยใช้การเรียนรู้ของเครื่องในบทช่วยสอนนี้
ในตอนท้ายของบทความนี้ คุณจะทราบสิ่งต่อไปนี้:
- การจัดการข้อมูลข้อความ
- เทคนิคการประมวลผล NLP
- นับ vectorization & TF-IDF
- ทำนายและจำแนกข้อความข่าว
เข้าร่วม หลักสูตร AI & ML ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท โปรแกรม Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
สารบัญ
ข้อมูลและปัญหา
เราจะใช้ข้อมูลท้าทาย Kaggle Fake News เพื่อสร้างตัวแยกประเภท ชุดข้อมูลประกอบด้วย 4 คุณสมบัติและ 1 เป้าหมายไบนารี 4 คุณสมบัติดังต่อไปนี้:
- id : id เฉพาะสำหรับบทความข่าว
- title : ชื่อบทความข่าว
- ผู้เขียน : ผู้เขียนบทความข่าว
- text : เนื้อหาของบทความ; อาจไม่สมบูรณ์
และเป้าหมายคือ "label" ซึ่งมีค่าไบนารี 0s และ 1s โดยที่ 0 หมายความว่าเป็นแหล่งข่าวที่เชื่อถือได้หรืออีกนัยหนึ่งคือไม่ใช่ของปลอม 1 หมายความว่าเป็นข่าวปลอมที่อาจไม่น่าเชื่อถือ ชุดข้อมูลที่เราได้ประกอบด้วย 20800 อินสแตนซ์ ไปดำน้ำกันเลย

การประมวลผลข้อมูลล่วงหน้าและการทำความสะอาด
| นำเข้า แพนด้า เป็น pd df=pd.read_csv( 'ข่าวปลอม/train.csv' ) df.head() |
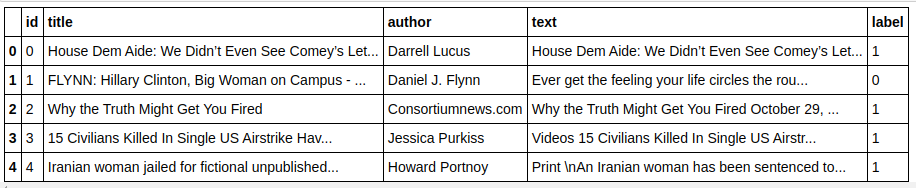
| X=df.drop( 'label' ,axis= 1 ) # Features y=df[ 'label' ] # Target |
เราจำเป็นต้องดรอปอินสแตนซ์ที่มีข้อมูลที่ขาดหายไปในขณะนี้
| df=df.dropna() |
![]()
อย่างที่เราเห็น มันทิ้งอินสแตนซ์ทั้งหมดที่มีข้อมูลที่ขาดหายไป
| ข้อความ=df.copy() message.reset_index(inplace= True ) ข้อความหัว( 10 ) |
ลองมาดูข้อมูลกันสักครั้ง
| ข้อความ['ข้อความ'][6] |

อย่างที่เราเห็น มีความจำเป็นต้องทำตามขั้นตอนต่อไปนี้:
- การลบคำหยุด: มีคำจำนวนมากที่ไม่เพิ่มคุณค่าให้กับข้อความใดๆ ไม่ว่าข้อมูลจะเป็นอย่างไรก็ตาม ตัวอย่างเช่น “I”, “a”, “am” เป็นต้น คำเหล่านี้ไม่มีค่าข้อมูล จึงสามารถลบออกเพื่อลดขนาดคลังข้อมูลของเรา เพื่อให้เราสามารถเน้นเฉพาะคำ/โทเค็นที่มีค่าจริงเท่านั้น .
- การสะกดคำ: Stemming and Lemmatization เป็นเทคนิคในการลดคำให้เหลือต้นกำเนิดหรือราก ข้อได้เปรียบหลักของขั้นตอนนี้คือการลดขนาดของคำศัพท์ ตัวอย่างเช่น คำเช่น เล่น เล่น เล่น จะถูกลดขนาดเป็น "เล่น" ต้นกำเนิดเพียงตัดคำให้เหลือคำที่สั้นที่สุด และไม่คำนึงถึงลักษณะทางไวยากรณ์ของข้อความ ในทางกลับกัน Lemmatization จะพิจารณาไวยากรณ์ด้วยและด้วยเหตุนี้จึงให้ผลลัพธ์ที่ดีกว่ามาก อย่างไรก็ตาม Lemmatization มักจะช้ากว่าการเกิดขึ้นเนื่องจากจำเป็นต้องอ้างถึงพจนานุกรมและพิจารณาด้านไวยากรณ์
- การลบทุกอย่างยกเว้นค่าตัวอักษร: ค่าที่ ไม่ใช่ตัวอักษรไม่ค่อยมีประโยชน์ในที่นี้ จึงสามารถลบออกได้ อย่างไรก็ตาม คุณสามารถสำรวจเพิ่มเติมเพื่อดูว่าการมีอยู่ของข้อมูลที่เป็นตัวเลขหรือประเภทอื่นๆ มีผลกระทบต่อเป้าหมายหรือไม่
- ตัวพิมพ์เล็กคำ: ตัวพิมพ์เล็กคำเพื่อลดคำศัพท์
- โทเค็นไลซ์ประโยค: การ สร้างโทเค็นจากประโยค
| จาก sklearn.feature_extract.text นำเข้า CountVectorizer, TfidfVectorizer, HashingVectorizer จาก nltk.corpus นำเข้าคำหยุด จาก nltk.stem.porter นำเข้า PorterStemmer นำเข้าอีกครั้ง ps = พอร์เตอร์สตีมเมอร์() corpus = [] สำหรับฉันในช่วง(0, len(ข้อความ)): รีวิว = re.sub('[^a-zA-Z]', ' ', ข้อความ['text'][i]) ทบทวน = ทบทวน. ล่าง () ตรวจสอบ = ตรวจสอบแยก () รีวิว = [ps.stem(word) สำหรับคำที่กำลังตรวจสอบ หากไม่ใช่คำใน stopwords.words('english')] บทวิจารณ์ = ' '.join(review) corpus.append(ตรวจสอบ) |
มาดูคลังข้อมูลของเรากันตอนนี้
| คลังข้อมูล[ 3 ] |
![]()
อย่างที่เราเห็น ตอนนี้คำต่างๆ ได้มาจากรากศัพท์แล้ว
TF-IDF Vectorizer
ตอนนี้ เราต้องทำให้เวกเตอร์คำเป็นข้อมูลตัวเลขที่เรียกว่า vectorization วิธีที่ง่ายที่สุดในการทำให้เป็นเวกเตอร์คือการใช้ Bag of Words แต่ Bag of Words สร้างเมทริกซ์กระจัดกระจายและด้วยเหตุนี้จึงมีความจำเป็นในการประมวลผลจำนวนมาก นอกจากนี้ BoW ไม่ได้คำนึงถึงความถี่ของคำซึ่งทำให้เป็นอัลกอริธึมที่ไม่ดี
TF-IDF (ความถี่ระยะ – ความถี่ของเอกสารผกผัน) เป็นอีกวิธีหนึ่งในการแปลงคำให้เป็นภาพเวกเตอร์ซึ่งพิจารณาความถี่ของคำ ตัวอย่างเช่น คำทั่วไปเช่น “เรา”, “ของเรา”, “the” อยู่ในทุกเอกสาร/อินสแตนซ์ ดังนั้นค่า BoW จะสูงเกินไปและทำให้เข้าใจผิด สิ่งนี้จะนำไปสู่รูปแบบที่ไม่ดี TF-IDF คือการคูณของ Term Frequency และ Inverse Document Frequency
ความถี่คำคำนึงถึงความถี่ของคำในเอกสารและความถี่ของเอกสารผกผันจะพิจารณาคำที่มีอยู่ในคลังทั้งหมด คำที่มีอยู่ทั่วทั้งคลังมีความสำคัญน้อยลงเนื่องจากค่า IDF ต่ำกว่ามาก คำที่มีอยู่ในเอกสารฉบับเดียวมีค่า IDF สูง ซึ่งทำให้ค่า TF-IDF ทั้งหมดสูง
| ## TFi df Vectorizer จาก sklearn.feature_extract.text นำเข้า TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=ข้อความ[ 'label' ] |
ในโค้ดด้านบนนี้ เรานำเข้า TF-IDF Vectorizer จากโมดูลการแยกคุณลักษณะของ Sklearn เราสร้างวัตถุโดยส่ง max_features เป็น 5000 และ ngram_range เป็น (1,3) พารามิเตอร์ max_features กำหนดจำนวนสูงสุดของคุณลักษณะเวกเตอร์ที่เราต้องการสร้าง และพารามิเตอร์ ngram_range กำหนดชุดค่าผสม ngram ที่เราต้องการรวม ในกรณีของเรา เราจะได้ 1 คำ 2 คำ และ 3 คำรวมกัน 3 ชุด มาดูคุณสมบัติบางอย่างที่สร้างขึ้น

| tfidf_v.get_feature_names()[: 20 ] |

อย่างที่เราเห็น มีหลายประเภทรวมกันเกิดขึ้น มีชื่อคุณสมบัติที่มี 1 โทเค็น 2 โทเค็นและ 3 โทเค็น
การทำดาต้าเฟรม
| ## แบ่งชุดข้อมูลออกเป็น Train และ Test จาก sklearn.model_selection นำเข้า train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
เราแบ่งชุดข้อมูลออกเป็นการฝึกและทดสอบ เพื่อให้เราสามารถทดสอบประสิทธิภาพของแบบจำลองกับข้อมูลที่มองไม่เห็น จากนั้นเราสร้าง Dataframe ใหม่ที่มีเวกเตอร์คุณสมบัติใหม่อยู่ในนั้น
การสร้างแบบจำลองและการปรับแต่ง
MultinomialNB อัลกอริธึม
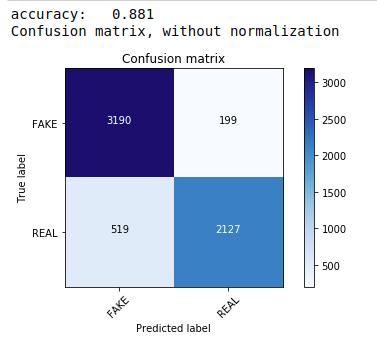
อันดับแรก เราใช้ทฤษฎีบท Multinomial Naive Bayes ซึ่งเป็นอัลกอริธึมที่ใช้บ่อยและง่ายที่สุดสำหรับการจัดประเภทข้อมูลข้อความ เราพอดีกับข้อมูลการฝึกอบรมและคาดการณ์ข้อมูลการทดสอบ ต่อมาเราคำนวณและพล็อตเมทริกซ์ความสับสนและได้ความแม่นยำ 88.1%
| จาก sklearn.naive_bayes นำเข้า MultinomialNB จาก เมตริก การนำเข้า sklearn นำเข้า numpy เป็น np นำเข้า itertools จาก sklearn.metrics นำเข้า plot_confusion_matrix ลักษณนาม= MultinomialNB() classifier.fit(X_train, y_train) pred = classifier.predict(X_test) คะแนน = metrics.accuracy_score(y_test, pred) พิมพ์ ( “ความแม่นยำ: %0.3f” % คะแนน) ซม. = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, คลาส=[ 'FAKE' , 'REAL' ]) |
ลักษณนามพหุนามพร้อมการปรับไฮเปอร์พารามิเตอร์
MultinomialNB มีอัลฟ่าพารามิเตอร์ที่สามารถปรับแต่งเพิ่มเติมได้ ดังนั้นเราจึงเรียกใช้การวนซ้ำเพื่อลองใช้ตัวแยกประเภท MultinomialNB ที่มีค่าอัลฟาต่างกันและตรวจสอบคะแนนความถูกต้อง และเราตรวจสอบว่าคะแนนปัจจุบันมากกว่าคะแนนก่อนหน้าหรือไม่ หากเป็นเช่นนั้น เราจะตั้งค่าตัวแยกประเภทเป็นตัวแยกประเภทปัจจุบัน
| Previous_score= 0 สำหรับ อัลฟ่า ใน np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(อัลฟา=อัลฟา) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) คะแนน = metrics.accuracy_score(y_test, y_pred) ถ้า คะแนน>previous_score: ลักษณนาม=sub_classifier พิมพ์ ( “อัลฟ่า: {}, คะแนน: {}” .format (อัลฟ่า, คะแนน)) |
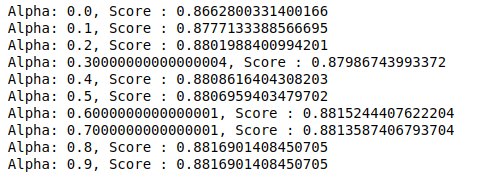
ดังนั้นเราจึงสามารถเห็นได้ว่าค่าอัลฟาที่ 0.9 หรือ 0.8 ให้คะแนนความแม่นยำสูงสุด
การตีความผลลัพธ์
ตอนนี้เรามาดูกันว่าค่าสัมประสิทธิ์ตัวแยกประเภทเหล่านี้หมายถึงอะไร ก่อนอื่นเราจะบันทึกชื่อคุณลักษณะทั้งหมดในตัวแปรอื่น
| ## G et F กินชื่อ feature_names = cv.get_feature_names() |
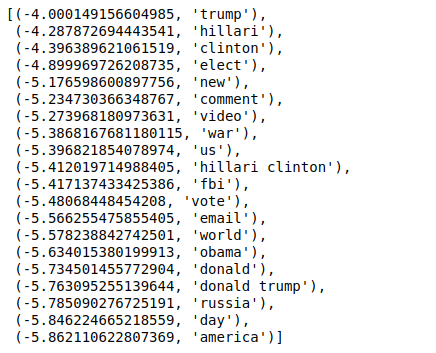
เมื่อเราจัดเรียงค่าในลำดับที่กลับกัน เราจะได้ค่าที่มีค่าต่ำสุดที่ -4 สิ่งเหล่านี้แสดงถึงคำที่เป็นจริงหรือปลอมน้อยที่สุด
| ### M ost จริง sorted (zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
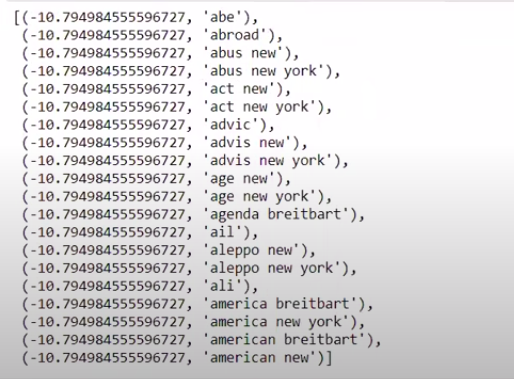
เมื่อเราจัดเรียงค่าในลำดับที่ไม่กลับด้าน เราจะได้ค่าที่มีค่าต่ำสุดที่ -10 เหล่านี้แสดงถึงคำที่เป็นจริงน้อยที่สุดหรือปลอมมากที่สุด
| ### M ost จริง sorted (zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
บทสรุป
ในบทช่วยสอนนี้ เราใช้อัลกอริธึม ML เท่านั้น แต่คุณใช้วิธีเครือข่ายประสาทเทียมอื่นๆ ด้วย นอกจากนี้ ในการทำให้ข้อมูลข้อความเป็นเวกเตอร์ เราใช้ TF-IDF vectorizer มี vectorizers อื่นๆ เช่น Count Vectorizer, Hashing Vectorizer เป็นต้น ซึ่งทำงานได้ดีกว่า ลองใช้และทดลองกับอัลกอริธึมและเทคนิคอื่นๆ เพื่อดูว่าคุณสามารถให้ผลลัพธ์ที่ดีขึ้นหรือไม่
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT -B สถานะศิษย์เก่า 5+ โครงการหลักที่ปฏิบัติได้จริง & ความช่วยเหลืองานกับ บริษัท ชั้นนำ
เหตุใดจึงต้องตรวจจับข่าวปลอม
ในสภาพปัจจุบัน แพลตฟอร์มโซเชียลมีเดียมีประสิทธิภาพและมีค่าสูง เนื่องจากอนุญาตให้ผู้ใช้อภิปรายและแลกเปลี่ยนความคิดเห็นตลอดจนหัวข้ออภิปราย เช่น ประชาธิปไตย การศึกษา และสุขภาพ อย่างไรก็ตาม หน่วยงานบางแห่งใช้แพลตฟอร์มดังกล่าวในทางที่ผิด เพื่อผลประโยชน์ทางการเงินในบางสถานการณ์ และเพื่อสร้างมุมมองที่มีอคติ ปรับเปลี่ยนทัศนคติ และเผยแพร่การเสียดสีหรือเรื่องไร้สาระในผู้อื่น ข่าวปลอมเป็นคำที่ใช้เรียกปรากฏการณ์นี้ การแพร่กระจายของการโพสต์รายการออนไลน์ที่ไม่เป็นไปตามความเป็นจริงส่งผลให้เกิดปัญหามากมายในด้านการเมือง กีฬา สุขภาพ วิทยาศาสตร์ และสาขาอื่นๆ
บริษัทใดบ้างที่ใช้ประโยชน์จากการตรวจจับข่าวปลอมเป็นหลัก
การตรวจจับข่าวปลอมถูกใช้บนแพลตฟอร์มต่างๆ เช่น โซเชียลมีเดียและเว็บไซต์ข่าว สื่อสังคมออนไลน์เช่น Facebook, Instagram และ Twitter มีความเสี่ยงต่อข่าวปลอมเนื่องจากผู้ใช้ส่วนใหญ่พึ่งพาพวกเขาเป็นแหล่งข่าวรายวันเพื่อรับข้อมูลล่าสุด บริษัทสื่อยังใช้เทคนิคการตรวจจับการปลอมเพื่อระบุความถูกต้องของข้อมูลที่พวกเขามีอยู่ อีเมลเป็นอีกสื่อกลางที่บุคคลทั่วไปสามารถรับข่าวสารได้ ซึ่งทำให้ยากต่อการระบุและยืนยันความจริงของตน การหลอกลวง สแปม และเมลขยะเป็นที่รู้จักกันดีว่าถูกส่งผ่านอีเมล ด้วยเหตุนี้ แพลตฟอร์มอีเมลส่วนใหญ่จึงใช้การตรวจจับข่าวปลอมเพื่อระบุสแปมและเมลขยะ