
การวิเคราะห์ข้อมูลเชิงสำรวจใน Python: สิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2021-03-12การวิเคราะห์ข้อมูลเชิงสำรวจ (EDA) เป็นแนวทางปฏิบัติทั่วไปที่สำคัญมาก ตามด้วยนักวิทยาศาสตร์ด้านข้อมูลทั้งหมด เป็นกระบวนการในการดูตารางและตารางข้อมูลจากมุมต่างๆ เพื่อให้เข้าใจอย่างถ่องแท้ การมีความเข้าใจในข้อมูลเป็นอย่างดีช่วยให้เราทำความสะอาดและสรุปข้อมูลได้ ซึ่งจะดึงข้อมูลเชิงลึกและแนวโน้มที่ไม่ชัดเจนออกมา
EDA ไม่มีกฎเกณฑ์ที่เข้มงวดที่จะต้องปฏิบัติตามเช่นใน 'การวิเคราะห์ข้อมูล' เป็นต้น ผู้ที่ยังใหม่ในสาขานี้มักจะสับสนระหว่างคำสองคำ ซึ่งส่วนใหญ่คล้ายกันแต่แตกต่างในจุดประสงค์ ต่างจาก EDA ตรงที่การวิเคราะห์ข้อมูลมีแนวโน้มที่จะใช้ความน่าจะเป็นและวิธีการทางสถิติเพื่อเปิดเผยข้อเท็จจริงและความสัมพันธ์ระหว่างตัวแปรต่างๆ
กลับมาอีกครั้ง ไม่มีทางถูกหรือผิดในการทำ EDA แตกต่างกันไปในแต่ละบุคคล อย่างไรก็ตาม มีแนวทางหลักบางประการที่มักปฏิบัติตามซึ่งมีการระบุไว้ด้านล่าง
- การจัดการกับค่าที่หายไป: ค่า Null สามารถมองเห็นได้เมื่อข้อมูลทั้งหมดอาจไม่มีอยู่หรือถูกบันทึกไว้ในระหว่างการรวบรวม
- การลบข้อมูลที่ซ้ำกัน: สิ่งสำคัญคือต้องป้องกันไม่ให้เกิดการโอเวอร์ฟิตหรืออคติที่เกิดขึ้นระหว่างการฝึกอัลกอริธึมการเรียนรู้ของเครื่องโดยใช้การบันทึกข้อมูลซ้ำ
- การจัดการค่าผิดปกติ: ค่า ผิดปกติคือบันทึกที่แตกต่างจากข้อมูลที่เหลืออย่างมากและไม่เป็นไปตามแนวโน้ม อาจเกิดขึ้นเนื่องจากข้อยกเว้นบางประการหรือความไม่ถูกต้องในระหว่างการรวบรวมข้อมูล
- การปรับมาตราส่วนและการทำให้เป็นมาตรฐาน: ดำเนินการนี้สำหรับตัวแปรข้อมูลตัวเลขเท่านั้น โดยส่วนใหญ่แล้วตัวแปรจะแตกต่างกันอย่างมากในช่วงและขนาดซึ่งทำให้ยากต่อการเปรียบเทียบและหาความสัมพันธ์
- การวิเคราะห์แบบตัวแปรเดียว และแบบสองตัวแปร: การวิเคราะห์แบบตัวแปรเดียวมักจะทำโดยการดูว่าตัวแปรตัวหนึ่งส่งผลต่อตัวแปรเป้าหมายอย่างไร การวิเคราะห์แบบ Bivariate ดำเนินการระหว่างตัวแปร 2 ตัว มันสามารถเป็นตัวเลขหรือหมวดหมู่หรือทั้งสองอย่าง
เราจะดูว่าบางส่วนเหล่านี้ถูกนำไปใช้อย่างไรโดยใช้ชุดข้อมูล 'Home Credit Default Risk' ที่มีชื่อเสียงซึ่งมีอยู่ใน Kaggle ที่ นี่ ข้อมูลประกอบด้วยข้อมูลเกี่ยวกับผู้ขอสินเชื่อ ณ เวลาที่สมัครขอสินเชื่อ ประกอบด้วยสถานการณ์สองประเภท:
- ลูกค้าที่มีปัญหาการชำระเงิน : เขา/เธอมีการชำระเงินล่าช้ามากกว่า X วัน
อย่างน้อยหนึ่งงวด Y แรกของเงินกู้ในตัวอย่างของเรา
- กรณีอื่นๆ ทั้งหมด : กรณีอื่นๆ ทั้งหมดเมื่อชำระเงินตรงเวลา
เราจะดำเนินการเฉพาะกับไฟล์ข้อมูลแอปพลิเคชันเพื่อประโยชน์ของบทความนี้
ที่เกี่ยวข้อง: แนวคิดและหัวข้อโครงการ Python สำหรับผู้เริ่มต้น
สารบัญ
การดูข้อมูล
app_data = pd.read_csv ( 'application_data.csv' )
app_data.info()
หลังจากอ่านข้อมูลแอปพลิเคชันแล้ว เราใช้ฟังก์ชัน info() เพื่อดูภาพรวมสั้นๆ ของข้อมูลที่เราจะจัดการด้วย ผลลัพธ์ด้านล่างแจ้งให้เราทราบว่าเรามีบันทึกสินเชื่อประมาณ 300,000 รายการพร้อมตัวแปร 122 รายการ จากจำนวนนี้มี 16 ตัวแปรตามหมวดหมู่และตัวเลขที่เหลือ
<คลาส 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 รายการ 0 ถึง 307510
คอลัมน์: 122 รายการ SK_ID_CURR ถึง AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), วัตถุ(16)
การใช้หน่วยความจำ: 286.2+ MB
แนวทางปฏิบัติที่ดีในการจัดการและวิเคราะห์ข้อมูลที่เป็นตัวเลขและหมวดหมู่แยกกันถือเป็นแนวทางปฏิบัติที่ดี
หมวดหมู่ = app_data.select_dtypes (รวม = วัตถุ) คอลัมน์
app_data[หมวดหมู่].apply(pd.Series.nunique, แกน = 0)
เมื่อพิจารณาเฉพาะคุณสมบัติการจัดหมวดหมู่ด้านล่าง เราจะเห็นว่าส่วนใหญ่มีเพียงไม่กี่หมวดหมู่เท่านั้น ซึ่งช่วยให้วิเคราะห์ได้ง่ายขึ้นโดยใช้แผนภาพอย่างง่าย
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
สำหรับคุณสมบัติเชิงตัวเลข วิธีการอธิบาย () จะให้สถิติข้อมูลของเราแก่เรา:
ตัวเลข= app_data.describe()
ตัวเลข= numer.columns
ตัวเลข
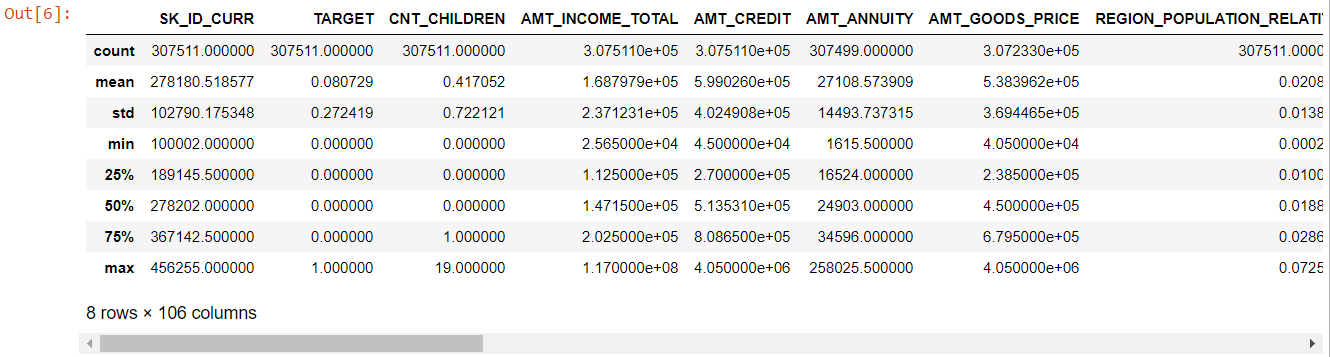
เมื่อดูทั้งโต๊ะ จะเห็นได้ชัดว่า:
- days_birth เป็นค่าลบ: อายุของผู้สมัคร (เป็นวัน) เทียบกับวันที่สมัคร
- days_ลูกจ้างมี ค่าผิดปกติ (ค่าสูงสุดประมาณ 100 ปี) (635243)
- amt_annuity- หมายถึงน้อยกว่าค่าสูงสุดมาก
ตอนนี้เรารู้แล้วว่าคุณสมบัติใดจะต้องได้รับการวิเคราะห์เพิ่มเติม
ไม่มีข้อมูล
เราสามารถสร้างจุดพล็อตของคุณสมบัติทั้งหมดที่มีค่าที่หายไปโดยพล็อต % ของข้อมูลที่ขาดหายไปตามแกน Y
หายไป = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))

ax = sns.pointplot('index', 0, data = missing)
plt.xticks(การหมุน = 90, ขนาดตัวอักษร = 7)
plt.title("เปอร์เซ็นต์ของค่าที่หายไป")
plt.ylabel("PERCENTAGE")
plt.show()
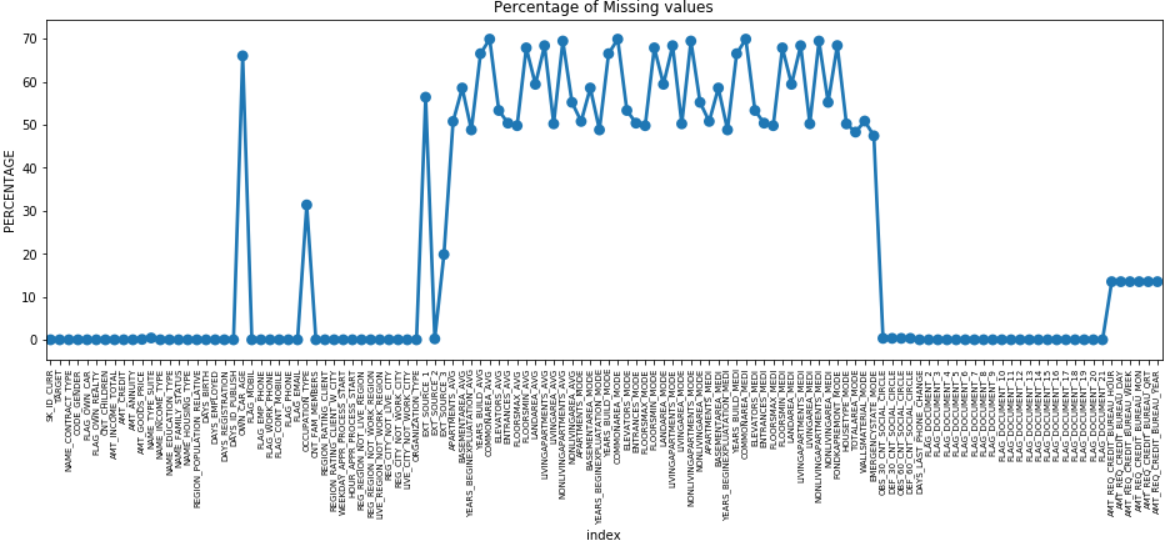
หลายคอลัมน์มีข้อมูลที่ขาดหายไปจำนวนมาก (30-70%) บางคอลัมน์มีข้อมูลที่ขาดหายไปเล็กน้อย (13-19%) และหลายคอลัมน์ก็ไม่มีข้อมูลที่ขาดหายไปเลย ไม่จำเป็นจริงๆ ที่จะแก้ไขชุดข้อมูลเมื่อคุณต้องดำเนินการ EDA อย่างไรก็ตาม การประมวลผลข้อมูลล่วงหน้า เราควรทราบวิธีจัดการกับค่าที่หายไป
สำหรับจุดสนใจที่มีค่าขาดหายไปน้อยกว่า เราสามารถใช้การถดถอยเพื่อคาดการณ์ค่าที่หายไปหรือเติมด้วยค่าเฉลี่ยของค่าที่มีอยู่ ทั้งนี้ขึ้นอยู่กับคุณสมบัติ และสำหรับคุณลักษณะที่มีค่าที่ขาดหายไปจำนวนมาก จะเป็นการดีกว่าที่จะทิ้งคอลัมน์เหล่านั้น เนื่องจากให้ข้อมูลเชิงลึกเกี่ยวกับการวิเคราะห์น้อยมาก
ข้อมูลไม่สมดุล
ในชุดข้อมูลนี้ ระบุผู้ผิดนัดเงินกู้โดยใช้ตัวแปรไบนารี 'TARGET'
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
ชื่อ: เป้าหมาย dtype: float64
เราเห็นว่าข้อมูลมีความไม่สมดุลอย่างมากด้วยอัตราส่วน 92:8 เงินกู้ส่วนใหญ่จ่ายคืนตรงเวลา (เป้าหมาย = 0) ดังนั้นเมื่อใดก็ตามที่มีความไม่สมดุลอย่างมาก ควรใช้คุณสมบัติและเปรียบเทียบกับตัวแปรเป้าหมาย (การวิเคราะห์ที่กำหนดเป้าหมาย) เพื่อพิจารณาว่าหมวดหมู่ใดในคุณสมบัติเหล่านั้นมีแนวโน้มที่จะผิดนัดในสินเชื่อมากกว่าประเภทอื่น
ด้านล่างนี้เป็นเพียงตัวอย่างเล็กๆ น้อยๆ ของกราฟที่สามารถทำได้โดยใช้ ไลบรารี่ของ Seaborn ของ python และฟังก์ชันที่ผู้ใช้กำหนดเองอย่างง่าย
เพศ
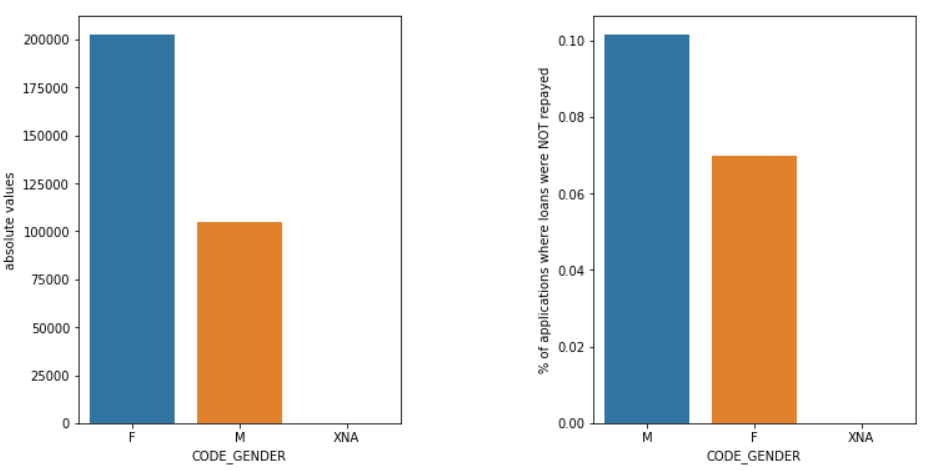
ผู้ชาย (M) มีโอกาสผิดนัดมากกว่าผู้หญิง (F) แม้ว่าจำนวนผู้สมัครหญิงจะเพิ่มขึ้นเกือบสองเท่า ดังนั้นผู้หญิงจึงมีความน่าเชื่อถือมากกว่าผู้ชายในการชำระคืนเงินกู้
ประเภทการศึกษา
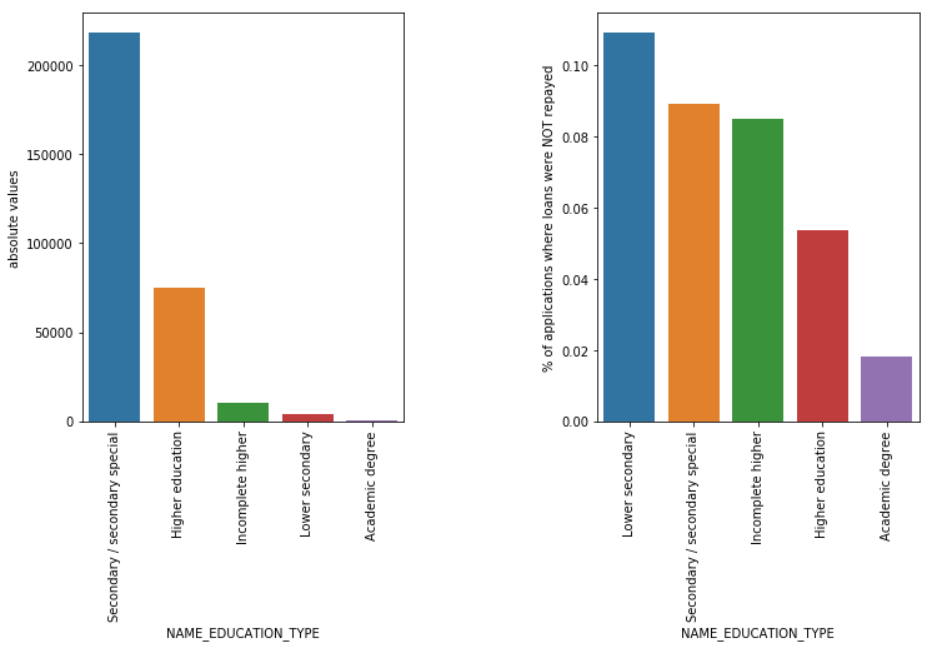
แม้ว่าเงินกู้นักเรียนส่วนใหญ่จะใช้สำหรับการศึกษาระดับมัธยมศึกษาหรือระดับอุดมศึกษา แต่ก็เป็นเงินกู้เพื่อการศึกษาระดับมัธยมศึกษาตอนต้นที่มีความเสี่ยงมากที่สุดสำหรับบริษัท รองลงมาคือเงินกู้ระดับมัธยมศึกษา
อ่านเพิ่มเติม: อาชีพใน Data Science
บทสรุป
การวิเคราะห์ในลักษณะดังกล่าวข้างต้นนั้นทำขึ้นอย่างมากในการวิเคราะห์ความเสี่ยงในบริการธนาคารและการเงิน วิธีนี้สามารถใช้ที่เก็บข้อมูลเพื่อลดความเสี่ยงในการสูญเสียเงินในขณะที่ให้ยืมแก่ลูกค้า ขอบเขตของ EDA ในภาคอื่น ๆ นั้นไม่มีที่สิ้นสุดและควรใช้อย่างกว้างขวาง
หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ลองดู Executive PG ของ IIIT-B & upGrad ใน Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 แบบ เวิร์กช็อปภาคปฏิบัติ การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1- on-1 กับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
การวิเคราะห์ข้อมูลเชิงสำรวจถือเป็นระดับเริ่มต้นเมื่อคุณเริ่มสร้างแบบจำลองข้อมูลของคุณ นี่เป็นเทคนิคที่ชาญฉลาดในการวิเคราะห์แนวทางปฏิบัติที่ดีที่สุดสำหรับการสร้างแบบจำลองข้อมูลของคุณ คุณจะสามารถแยกแผนภาพ กราฟ และรายงานออกจากข้อมูลเพื่อให้เข้าใจได้อย่างสมบูรณ์ ค่าผิดปกติจะอ้างอิงถึงความผิดปกติหรือความแปรปรวนเล็กน้อยในข้อมูลของคุณ อาจเกิดขึ้นระหว่างการรวบรวมข้อมูล มี 4 วิธีในการตรวจหาค่าผิดปกติในชุดข้อมูล วิธีการเหล่านี้มีดังนี้: ต่างจากการวิเคราะห์ข้อมูลตรงที่ไม่มีกฎเกณฑ์และข้อบังคับที่เข้มงวดและรวดเร็วให้ปฏิบัติตามสำหรับ EDA ไม่มีใครบอกได้ว่านี่เป็นวิธีการที่ถูกต้องหรือเป็นวิธีที่ผิดในการทำ EDA ผู้เริ่มต้นมักเข้าใจผิดและสับสนระหว่าง EDA กับการวิเคราะห์ข้อมูลเหตุใดจึงต้องมีการวิเคราะห์ข้อมูลเชิงสำรวจ (EDA)
EDA เกี่ยวข้องกับขั้นตอนบางอย่างในการวิเคราะห์ข้อมูลทั้งหมด รวมถึงการได้มาซึ่งผลลัพธ์ทางสถิติ การค้นหาค่าข้อมูลที่ขาดหายไป การจัดการการป้อนข้อมูลที่ผิดพลาด และสุดท้าย การอนุมานพล็อตและกราฟต่างๆ
จุดประสงค์หลักของการวิเคราะห์นี้คือเพื่อให้แน่ใจว่าชุดข้อมูลที่คุณใช้มีความเหมาะสมในการเริ่มใช้อัลกอริธึมการสร้างแบบจำลอง นั่นเป็นเหตุผลที่เป็นขั้นตอนแรกที่คุณควรดำเนินการกับข้อมูลของคุณก่อนที่จะย้ายไปยังขั้นตอนการสร้างแบบจำลอง ค่าผิดปกติคืออะไรและจะจัดการอย่างไร
1. Boxplot - Boxplot เป็นวิธีการตรวจหาค่าผิดปกติที่เราแยกข้อมูลผ่านควอร์ไทล์
2. Scatterplot - พล็อตกระจายแสดงข้อมูลของตัวแปร 2 ตัวในรูปแบบของการรวบรวมจุดที่ทำเครื่องหมายบนระนาบคาร์ทีเซียน ค่าของตัวแปรหนึ่งแทนแกนนอน (x-ais) และค่าของตัวแปรอื่นแทนแกนตั้ง (แกน y)
3. คะแนน Z - ขณะคำนวณคะแนน Z เราจะมองหาจุดที่อยู่ห่างจากจุดศูนย์กลางและถือว่าเป็นค่าผิดปกติ
4. ช่วงระหว่างควอไทล์ (IQR) - ช่วงอินเตอร์ควอไทล์หรือ IQR คือความแตกต่างระหว่างควอไทล์บนและควอไทล์ที่ต่ำกว่าหรือควอร์ไทล์ที่ 75 และ 25 ซึ่งมักเรียกว่าการกระจายทางสถิติ แนวทางปฏิบัติในการทำ EDA คืออะไร?
อย่างไรก็ตาม มีแนวทางปฏิบัติบางประการที่ปฏิบัติกันโดยทั่วไป:
1. การจัดการกับค่าที่หายไป
2. การลบข้อมูลที่ซ้ำกัน
3. การจัดการค่าผิดปกติ
4. การปรับขนาดและการทำให้เป็นมาตรฐาน
5. การวิเคราะห์แบบตัวแปรเดียวและแบบสองตัวแปร