
การวิเคราะห์ข้อมูลเชิงสำรวจใน Python คืออะไร เรียนรู้ตั้งแต่เริ่มต้น
เผยแพร่แล้ว: 2021-03-04สรุปการวิเคราะห์ข้อมูลเชิงสำรวจหรือ EDA ประกอบด้วยเกือบ 70% ของโครงการ Data Science EDA เป็นกระบวนการสำรวจข้อมูลโดยใช้เครื่องมือวิเคราะห์ต่างๆ เพื่อให้ได้สถิติอนุมานจากข้อมูล การสำรวจเหล่านี้ทำได้โดยการดูตัวเลขธรรมดาหรือโดยพล็อตกราฟและแผนภูมิประเภทต่างๆ
กราฟหรือแผนภูมิแต่ละรายการแสดงเรื่องราวและมุมที่แตกต่างกันของข้อมูลเดียวกัน สำหรับการวิเคราะห์และทำความสะอาดข้อมูลส่วนใหญ่ Pandas เป็นเครื่องมือที่ใช้มากที่สุด สำหรับการแสดงภาพและการพล็อตกราฟ/แผนภูมิ จะใช้ไลบรารีการพล็อต เช่น Matplotlib, Seaborn และ Plotly
EDA มีความจำเป็นอย่างยิ่งที่จะต้องดำเนินการ เนื่องจากจะทำให้ข้อมูลเป็นที่ยอมรับของคุณ นักวิทยาศาสตร์ข้อมูลที่ทำ EDA ได้ดีมาก รู้เรื่องข้อมูลเป็นอย่างดี ดังนั้นแบบจำลองที่พวกเขาจะสร้างจะดีกว่า Data Scientist ที่ไม่ได้ทำ EDA ที่ดีโดยอัตโนมัติ
ในตอนท้ายของบทช่วยสอนนี้ คุณจะทราบสิ่งต่อไปนี้:
- การตรวจสอบภาพรวมพื้นฐานของข้อมูล
- การตรวจสอบสถิติเชิงพรรณนาของข้อมูล
- การจัดการชื่อคอลัมน์และประเภทข้อมูล
- การจัดการค่าที่หายไป & แถวที่ซ้ำกัน
- การวิเคราะห์สองตัวแปร
สารบัญ
ภาพรวมพื้นฐานของข้อมูล
เราจะใช้ชุดข้อมูลรถยนต์สำหรับบทช่วยสอนนี้ซึ่งสามารถ ดาวน์โหลด ได้ จาก Kaggle ขั้นตอนแรกสำหรับชุดข้อมูลเกือบทุกชุดคือ นำเข้าและตรวจสอบภาพรวมพื้นฐานของชุดข้อมูล เช่น รูปร่าง คอลัมน์ ประเภทคอลัมน์ แถวบนสุด 5 แถว ฯลฯ ขั้นตอนนี้จะช่วยให้คุณทราบส่วนสำคัญของข้อมูลที่คุณจะใช้งานได้อย่างรวดเร็ว เรามาดูวิธีการทำสิ่งนี้ใน Python
| # การนำเข้าไลบรารีที่จำเป็น นำเข้า แพนด้า เป็น pd นำเข้า numpy เป็น np นำเข้า seaborn เป็น sns #visualisation นำเข้า matplotlib.pyplot เป็น plt #visualisation %matplotlib แบบอินไลน์ sns.set(color_codes= True ) |
Data Head & Tail
| data = pd.read_csv( “เส้นทาง/dataset.csv” ) # ตรวจสอบ 5 แถวบนสุดของ dataframe data.head() |
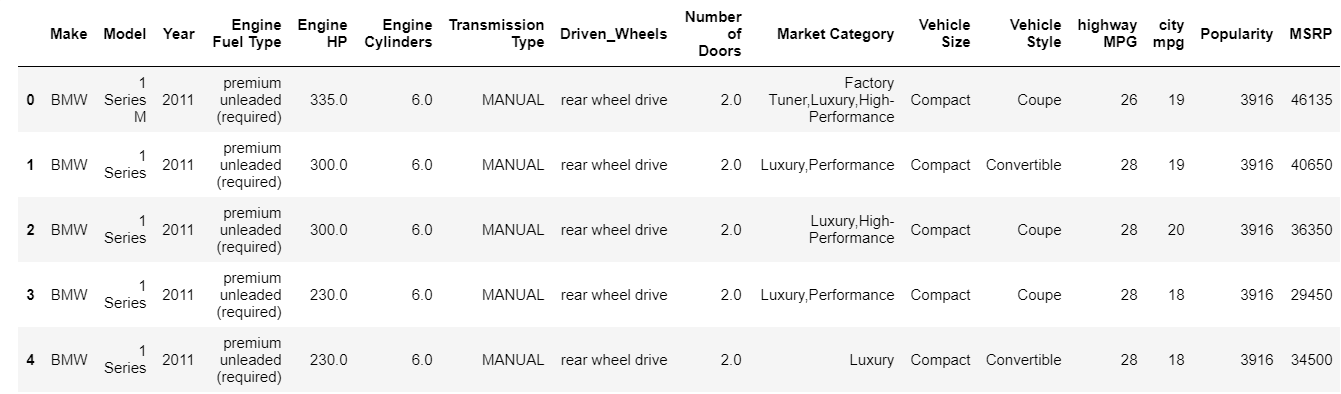
ฟังก์ชัน head พิมพ์ดัชนี 5 อันดับแรกของ data frame โดยค่าเริ่มต้น คุณยังสามารถระบุจำนวนดัชนีระดับบนสุดที่คุณต้องการเพื่อดูการข้ามค่านั้นไปยังส่วนหัว การพิมพ์หัวพิมพ์ในทันทีช่วยให้เราดูได้อย่างรวดเร็วว่าเรามีข้อมูลประเภทใด มีคุณลักษณะประเภทใด และมีค่าใดบ้าง แน่นอนว่าสิ่งนี้ไม่ได้บอกเล่าเรื่องราวทั้งหมดเกี่ยวกับข้อมูล แต่จะช่วยให้คุณเห็นข้อมูลได้อย่างรวดเร็ว คุณสามารถพิมพ์ส่วนล่างของกรอบข้อมูลได้เช่นเดียวกันโดยใช้ฟังก์ชันหาง
| # พิมพ์ 10 แถวสุดท้ายของ dataframe data.tail( 10 ) |
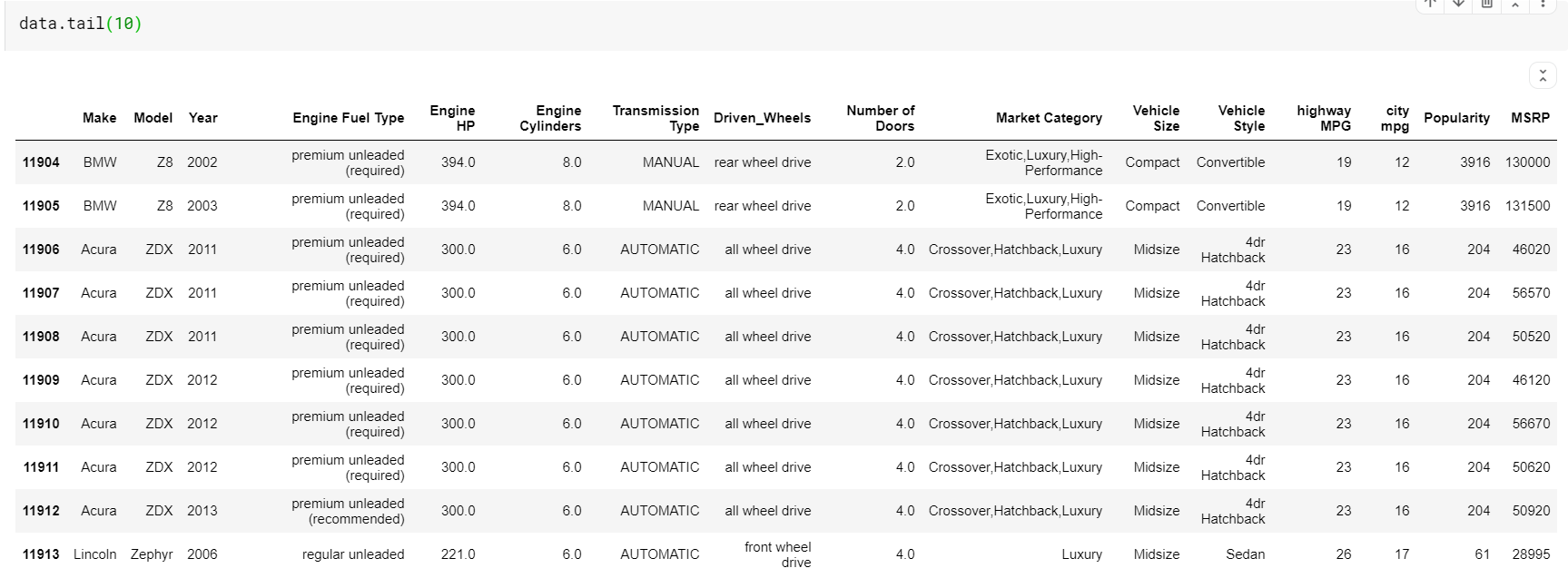
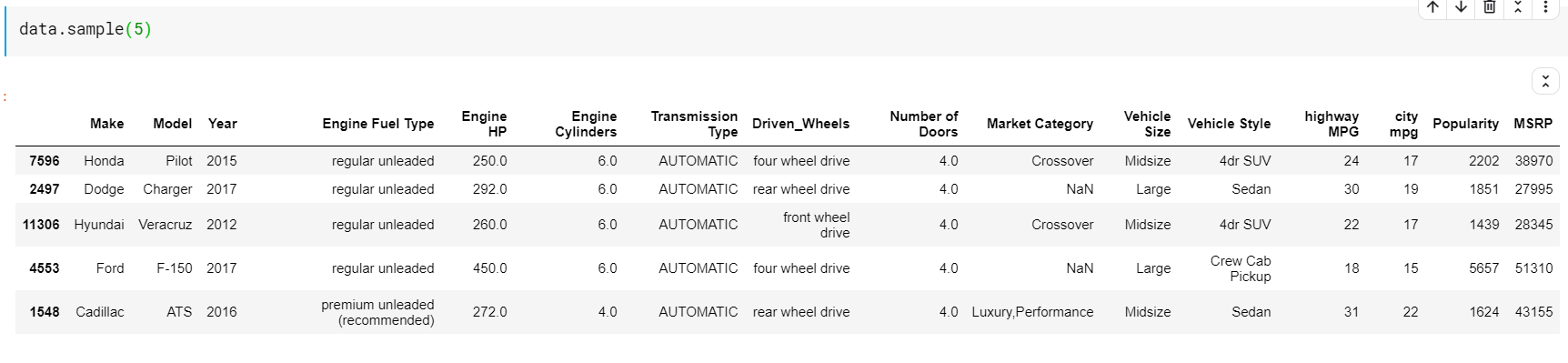
สิ่งหนึ่งที่ควรสังเกตในที่นี้คือ ทั้งฟังก์ชัน head และ tail ให้ดัชนีด้านบนหรือด้านล่างแก่เรา แต่แถวบนหรือล่างไม่ใช่การแสดงตัวอย่างข้อมูลที่ดีเสมอไป ดังนั้น คุณจึงสามารถพิมพ์แถวจำนวนเท่าใดก็ได้ที่สุ่มสุ่มตัวอย่างจากชุดข้อมูลโดยใช้ฟังก์ชัน sample()
| #พิมพ์สุ่ม5แถว data.sample( 5 ) |
สถิติเชิงพรรณนา
ต่อไป มาดูสถิติเชิงพรรณนาของชุดข้อมูลกัน สถิติเชิงพรรณนาประกอบด้วยทุกสิ่งที่ “อธิบาย” ชุดข้อมูล เราตรวจสอบรูปร่างของ data frame ว่าคอลัมน์ทั้งหมดมีอะไรบ้าง คุณลักษณะตัวเลขและหมวดหมู่ทั้งหมดมีอะไรบ้าง เราจะดูวิธีการทำทั้งหมดนี้ด้วยฟังก์ชันง่ายๆ
รูปร่าง
| # ตรวจสอบรูปร่างดาต้าเฟรม (mxn) # m=จำนวนแถว # n=จำนวนคอลัมน์ data.shape |

อย่างที่เราเห็น data frame นี้มี 11914 แถวและ 16 คอลัมน์
คอลัมน์
| #พิมพ์ชื่อคอลัมน์ data.columns |
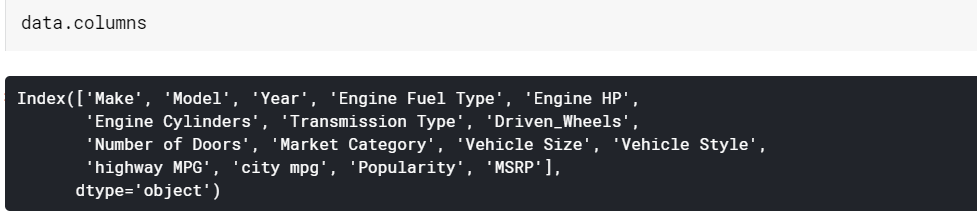
ข้อมูลดาต้าเฟรม
| # พิมพ์ประเภทข้อมูลคอลัมน์และจำนวนค่าที่ขาดหายไป data.info() |
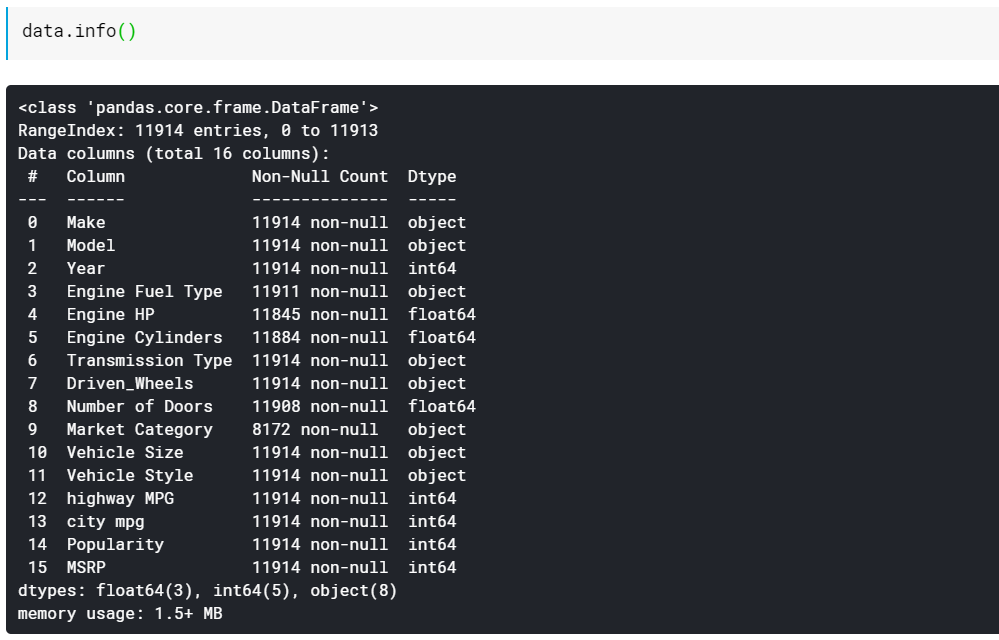
ดังที่คุณเห็น ฟังก์ชัน info() ให้คอลัมน์ทั้งหมดแก่เรา จำนวนค่าที่ไม่เป็นค่าว่างหรือค่าที่ขาดหายไปในคอลัมน์เหล่านั้น และประเภทข้อมูลสุดท้ายของคอลัมน์เหล่านั้น นี่เป็นวิธีที่รวดเร็วที่ดีในการดูว่าคุณลักษณะทั้งหมดเป็นตัวเลขและคุณลักษณะทั้งหมดเป็นแบบใดแบบเป็นหมวดหมู่/แบบข้อความ นอกจากนี้ ขณะนี้เรามีข้อมูลเกี่ยวกับคอลัมน์ทั้งหมดที่มีค่าที่ขาดหายไป เราจะมาดูวิธีการทำงานกับค่าที่หายไปในภายหลัง
การจัดการชื่อคอลัมน์และประเภทข้อมูล
การตรวจสอบและจัดการแต่ละคอลัมน์อย่างรอบคอบมีความสำคัญอย่างยิ่งใน EDA เราจำเป็นต้องดูว่าคอลัมน์/คุณลักษณะประกอบด้วยเนื้อหาประเภทใด และสิ่งใดที่แพนด้าอ่านประเภทข้อมูล ชนิดข้อมูลตัวเลขส่วนใหญ่เป็น int64 หรือ float64 คุณลักษณะตามข้อความหรือการจัดหมวดหมู่ถูกกำหนดประเภทข้อมูล 'วัตถุ'
มีการกำหนดคุณสมบัติตามวันที่และเวลา มีบางครั้งที่ Pandas ไม่เข้าใจประเภทข้อมูลของคุณสมบัติ ในกรณีเช่นนี้ มันก็แค่กำหนดประเภทข้อมูล 'วัตถุ' ให้อย่างเกียจคร้าน เราสามารถระบุประเภทข้อมูลของคอลัมน์ได้อย่างชัดเจนในขณะที่อ่านข้อมูลด้วย read_csv
การเลือกคอลัมน์หมวดหมู่และตัวเลข
| # เพิ่มคอลัมน์หมวดหมู่และตัวเลขทั้งหมดเพื่อแยกรายการ หมวดหมู่ = data.select_dtypes ( 'object' ).columns ตัวเลข = data.select_dtypes ( 'number' ).columns |

ที่นี่ประเภทที่เราส่งผ่านเป็น 'ตัวเลข' จะเลือกคอลัมน์ทั้งหมดที่มีประเภทข้อมูลที่มีตัวเลขประเภทใดก็ได้ ไม่ว่าจะเป็น int64 หรือ float64

การเปลี่ยนชื่อคอลัมน์
| # การเปลี่ยนชื่อคอลัมน์ data = data.rename(columns={ “Engine HP” : “HP” , “กระบอกสูบเครื่องยนต์” : “กระบอกสูบ” , “ประเภทการส่งสัญญาณ” : “การส่งสัญญาณ” , “Driven_Wheels” : “โหมดขับเคลื่อน” , “ทางหลวง MPG” : “MPG-H” , “MSRP” : “ราคา” }) data.head( 5 ) |

ฟังก์ชันเปลี่ยนชื่อจะใช้ในพจนานุกรมที่มีชื่อคอลัมน์ที่จะเปลี่ยนชื่อและชื่อใหม่
การจัดการค่าที่หายไปและแถวที่ซ้ำกัน
ค่าที่หายไปเป็นหนึ่งในปัญหา/ความคลาดเคลื่อนที่พบบ่อยที่สุดในชุดข้อมูลในชีวิตจริง การจัดการกับค่าที่หายไปนั้นเป็นหัวข้อกว้างใหญ่ เนื่องจากมีหลายวิธีที่จะทำได้ บางวิธีเป็นวิธีทั่วไป และบางวิธีเฉพาะเจาะจงมากขึ้นสำหรับชุดข้อมูลที่อาจต้องรับมือ
การตรวจสอบค่าที่หายไป
| #ตรวจสอบค่าที่หายไป data.isnull().sum() |
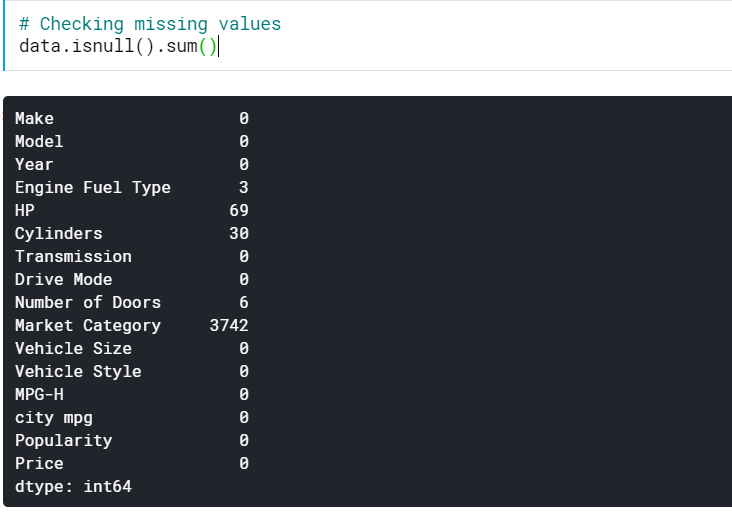
สิ่งนี้ทำให้เรามีจำนวนค่าที่ขาดหายไปในทุกคอลัมน์ เรายังสามารถดูเปอร์เซ็นต์ของค่าที่หายไปได้ด้วย
| # เปอร์เซ็นต์ของค่าที่หายไป data.isnull().mean()* 100 |
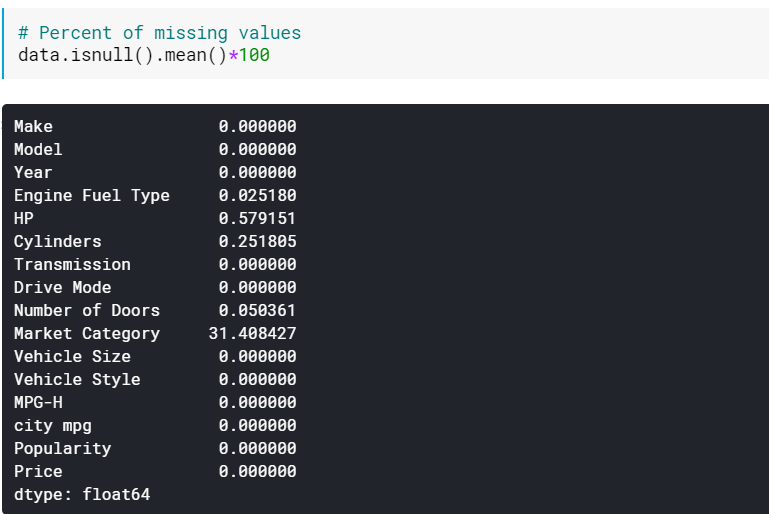
การตรวจสอบเปอร์เซ็นต์อาจมีประโยชน์เมื่อมีคอลัมน์จำนวนมากที่มีค่าที่ขาดหายไป ในกรณีเช่นนี้ คอลัมน์ที่มีค่าขาดหายไปจำนวนมาก (เช่น >60% หายไป) ก็สามารถทิ้งได้
การใส่ค่าที่หายไป
| #Imputing ค่าที่ขาดหายไปของคอลัมน์ตัวเลขโดยความหมาย data[ตัวเลข] = data[ตัวเลข].fillna(data[ตัวเลข].mean().iloc[ 0 ]) #Imputing ค่าที่ขาดหายไปของคอลัมน์หมวดหมู่ตามโหมด data[หมวดหมู่] = data[หมวดหมู่].fillna(ข้อมูล[หมวดหมู่].mode().iloc[ 0 ]) |
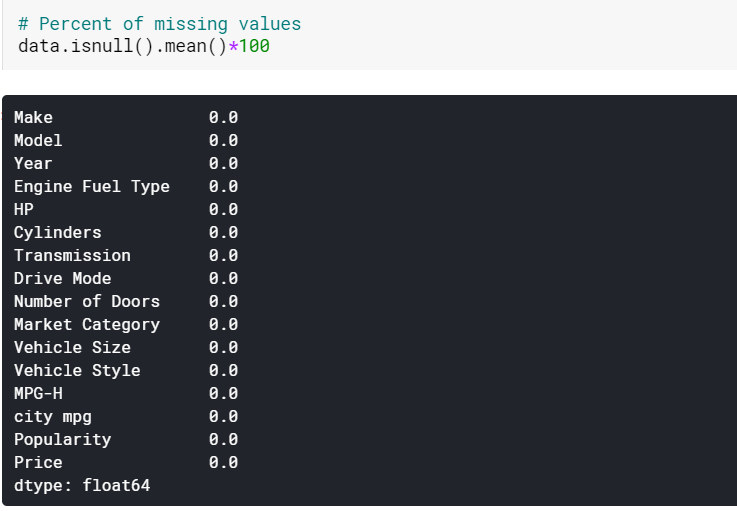
ที่นี่เราเพียงแค่ใส่ค่าที่ขาดหายไปในคอลัมน์ตัวเลขโดยใช้วิธีการที่เกี่ยวข้องและค่าในคอลัมน์หมวดหมู่ตามโหมด และอย่างที่เราเห็น ตอนนี้ไม่มีค่าที่ขาดหายไป
โปรดทราบว่านี่เป็นวิธีพื้นฐานที่สุดในการระบุค่านิยม และใช้ไม่ได้ในกรณีในชีวิตจริงที่มีการพัฒนาวิธีการที่ซับซ้อนยิ่งขึ้น เช่น การประมาณการ KNN เป็นต้น
การจัดการแถวที่ซ้ำกัน
| # วางแถวที่ซ้ำกัน data.drop_duplicates(inplace= True ) |
นี่เป็นเพียงการลดแถวที่ซ้ำกัน
ชำระเงิน: แนวคิดและหัวข้อโครงการ Python
การวิเคราะห์สองตัวแปร
ตอนนี้เรามาดูวิธีรับข้อมูลเชิงลึกเพิ่มเติมโดยทำการวิเคราะห์แบบสองตัวแปร Bivariate หมายถึง การวิเคราะห์ที่ประกอบด้วย 2 ตัวแปรหรือคุณลักษณะ มีแปลงหลายประเภทสำหรับคุณสมบัติประเภทต่างๆ
สำหรับตัวเลข – ตัวเลข
- พล็อตกระจาย
- พล็อตเส้น
- แผนที่ความร้อนสำหรับความสัมพันธ์
สำหรับหมวดหมู่-ตัวเลข
- แผนภูมิแท่ง
- พล็อตไวโอลิน
- พล็อตฝูง
สำหรับหมวดหมู่-หมวดหมู่
- แผนภูมิแท่ง
- พล็อตจุด
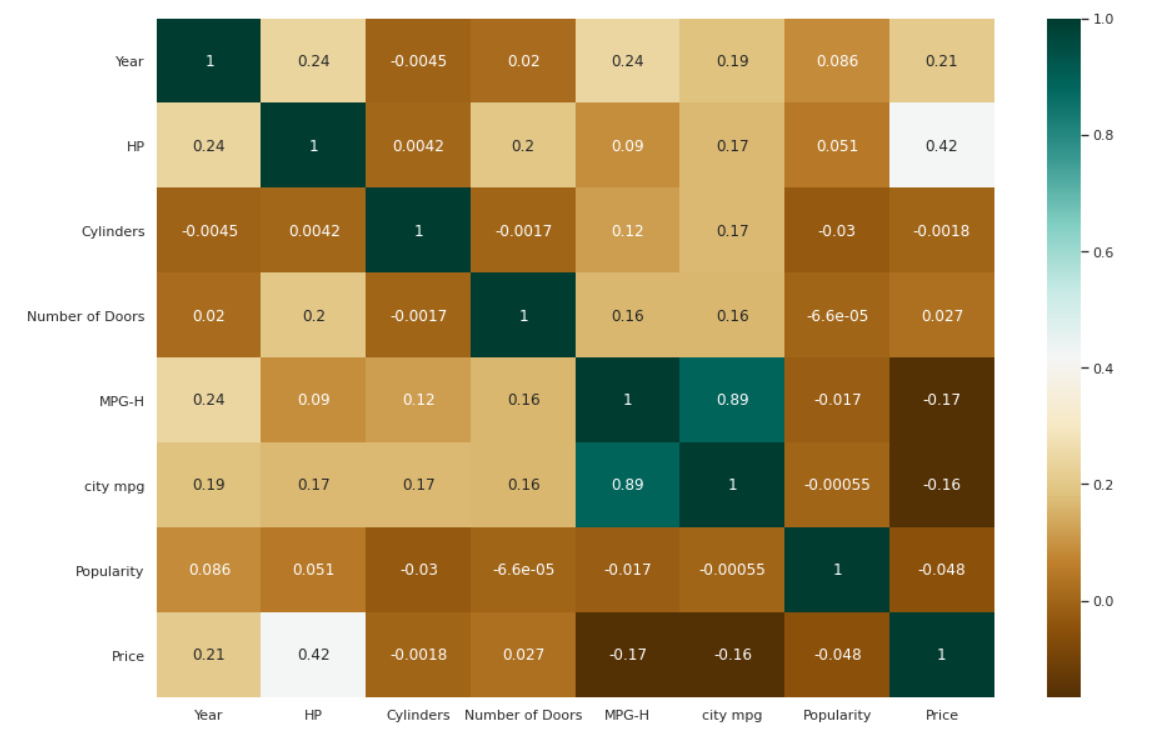
แผนที่ความร้อนสำหรับสหสัมพันธ์
| # ตรวจสอบความสัมพันธ์ระหว่างตัวแปร plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= “BrBG” ,annot= True ) |
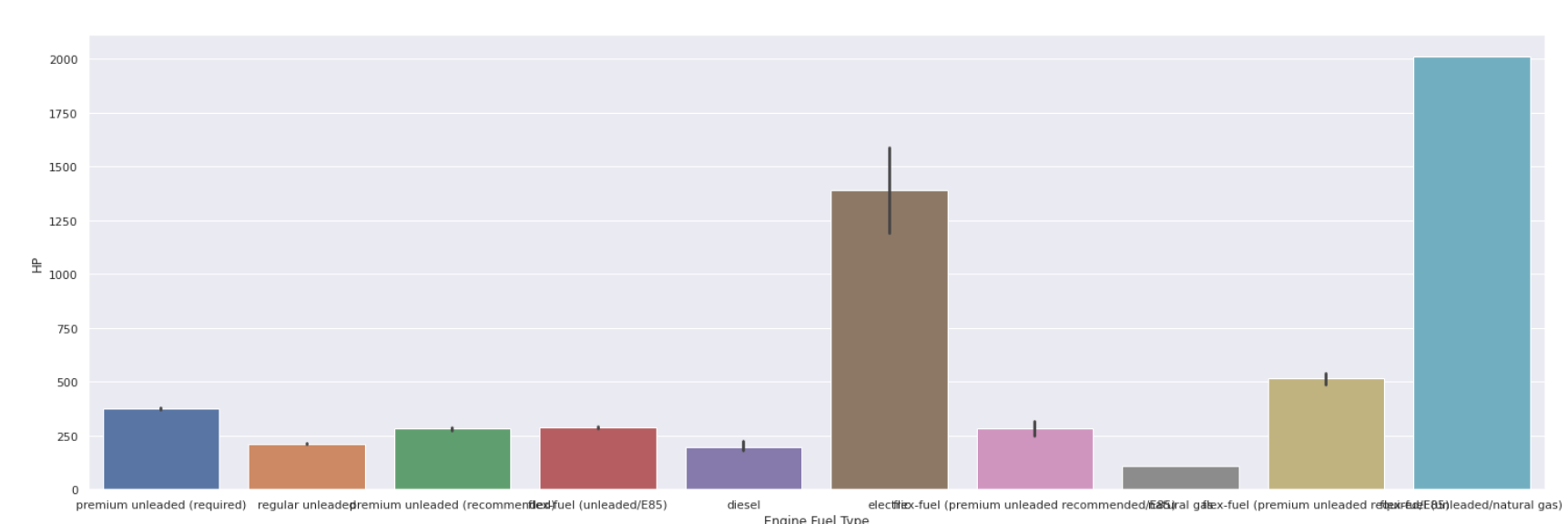
พล็อตบาร์
| sns.barplot(ข้อมูล[ 'ประเภทเชื้อเพลิงเครื่องยนต์' ], ข้อมูล[ 'HP' ]) |
รับ ใบรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก เรียนรู้หลักสูตร Executive PG Programs, Advanced Certificate Programs หรือ Masters Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
บทสรุป
ดังที่เราเห็น มีขั้นตอนมากมายที่ต้องกล่าวถึงขณะสำรวจชุดข้อมูล ในบทช่วยสอนนี้เราได้กล่าวถึงแง่มุมต่างๆ เพียงไม่กี่แง่มุม แต่สิ่งนี้จะให้มากกว่าความรู้พื้นฐานเกี่ยวกับ EDA ที่ดี
หากคุณอยากเรียนรู้เกี่ยวกับ Python ทุกเรื่องเกี่ยวกับวิทยาศาสตร์ข้อมูล ลองไปที่ IIIT-B & upGrad's PG Diploma in Data Science ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 แบบ เวิร์กช็อปภาคปฏิบัติ การให้คำปรึกษากับภาคอุตสาหกรรม ผู้เชี่ยวชาญ ตัวต่อตัวกับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ขั้นตอนในการวิเคราะห์ข้อมูลเชิงสำรวจมีอะไรบ้าง?
ขั้นตอนหลักที่คุณต้องดำเนินการเพื่อทำการวิเคราะห์ข้อมูลเชิงสำรวจคือ -
ต้องระบุตัวแปรและประเภทข้อมูล
การวิเคราะห์ตัวชี้วัดพื้นฐาน
การวิเคราะห์ที่ไม่ใช่กราฟิกแบบตัวแปรเดียว
การวิเคราะห์กราฟิกแบบตัวแปรเดียว
การวิเคราะห์ข้อมูลสองตัวแปร
การเปลี่ยนแปลงที่แปรผัน
การรักษาค่าที่หายไป
การรักษาค่าผิดปกติ
การวิเคราะห์สหสัมพันธ์
การลดมิติ
วัตถุประสงค์ของการวิเคราะห์ข้อมูลเชิงสำรวจคืออะไร?
เป้าหมายหลักของ EDA คือการช่วยในการวิเคราะห์ข้อมูลก่อนที่จะทำการตั้งสมมติฐานใดๆ สามารถช่วยในการตรวจจับข้อผิดพลาดที่เห็นได้ชัด ตลอดจนความเข้าใจที่ดีขึ้นเกี่ยวกับรูปแบบข้อมูล การตรวจหาค่าผิดปกติหรือเหตุการณ์ผิดปกติ และการค้นพบความสัมพันธ์ที่น่าสนใจระหว่างตัวแปร
นักวิทยาศาสตร์ข้อมูลสามารถใช้การวิเคราะห์เชิงสำรวจเพื่อรับประกันว่าผลลัพธ์ที่สร้างขึ้นนั้นถูกต้องและเหมาะสมกับผลลัพธ์ทางธุรกิจและเป้าหมายที่เป็นเป้าหมาย EDA ยังช่วยเหลือผู้มีส่วนได้ส่วนเสียด้วยการทำให้มั่นใจว่าพวกเขากำลังตอบคำถามที่เหมาะสม EDA สามารถตอบค่าเบี่ยงเบนมาตรฐาน ข้อมูลตามหมวดหมู่ และช่วงความเชื่อมั่นได้ หลังจากเสร็จสิ้น EDA และการดึงข้อมูลเชิงลึกแล้ว ฟีเจอร์ต่างๆ ของ EDA สามารถนำไปใช้กับการวิเคราะห์ข้อมูลหรือการสร้างแบบจำลองขั้นสูงขึ้น รวมถึงการเรียนรู้ด้วยเครื่อง
การวิเคราะห์ข้อมูลเชิงสำรวจประเภทต่าง ๆ มีอะไรบ้าง
เทคนิค EDA มีสองประเภท: แบบกราฟิกและเชิงปริมาณ (ไม่ใช่แบบกราฟิก) ในทางกลับกัน วิธีการเชิงปริมาณต้องการการรวบรวมสถิติสรุป ในขณะที่วิธีการแบบกราฟิกจะรวมการรวบรวมข้อมูลในลักษณะไดอะแกรมหรือภาพ วิธีการแบบตัวแปรเดียวและหลายตัวแปรเป็นส่วนย่อยของวิธีการสองประเภทนี้
ในการตรวจสอบความสัมพันธ์ วิธีการแบบไม่มีตัวแปรจะดูที่ตัวแปรหนึ่งตัว (คอลัมน์ข้อมูล) ในแต่ละครั้ง ในขณะที่วิธีการแบบหลายตัวแปรจะพิจารณาตัวแปรตั้งแต่สองตัวขึ้นไปในคราวเดียว ตัวแปรเดียวและหลายตัวแปรทั้งกราฟิกและไม่ใช่กราฟิกเป็น EDA สี่รูปแบบ ขั้นตอนเชิงปริมาณมีวัตถุประสงค์มากกว่าในขณะที่วิธีการแสดงภาพมีความเป็นอัตนัยมากกว่า