
คู่มือการคัดลอกเว็บไซต์แบบไดนามิกอย่างมีจริยธรรมด้วย Node.js และ Puppeteer
เผยแพร่แล้ว: 2022-03-10เริ่มต้นด้วยส่วนเล็กๆ น้อยๆ เกี่ยวกับความหมายของการขูดเว็บ พวกเราทุกคนใช้การขูดเว็บในชีวิตประจำวันของเรา เป็นเพียงการอธิบายขั้นตอนการดึงข้อมูลจากเว็บไซต์ ดังนั้น หากคุณคัดลอกและวางสูตรอาหารก๋วยเตี๋ยวจานโปรดจากอินเทอร์เน็ตลงในสมุดบันทึกส่วนตัว แสดงว่าคุณกำลังทำการ ขูดเว็บ
เมื่อใช้คำนี้ในอุตสาหกรรมซอฟต์แวร์ เรามักจะอ้างถึงการ ทำงานอัตโนมัติของงานที่ทำด้วยตนเองนี้ โดยใช้ซอฟต์แวร์ชิ้นหนึ่ง ยึดตามตัวอย่าง “จานก๋วยเตี๋ยว” ก่อนหน้าของเรา กระบวนการนี้มักประกอบด้วยสองขั้นตอน:
- กำลังดึงหน้า
ก่อนอื่นเราต้องดาวน์โหลดทั้งหน้า ขั้นตอนนี้เหมือนกับการเปิดหน้าในเว็บเบราว์เซอร์ของคุณเมื่อทำการขูดด้วยตนเอง - การแยกวิเคราะห์ข้อมูล
ตอนนี้ เราต้องแยกสูตรใน HTML ของเว็บไซต์และแปลงเป็นรูปแบบที่เครื่องอ่านได้ เช่น JSON หรือ XML
ในอดีต ฉันเคยทำงานเป็นที่ปรึกษาด้านข้อมูลให้กับหลายบริษัท ฉันรู้สึกทึ่งที่เห็นว่างานดึงข้อมูล การรวม และการตกแต่งจำนวนมากยังคงดำเนินการด้วยตนเอง แม้ว่างานเหล่านี้จะถูกทำให้เป็นอัตโนมัติได้อย่างง่ายดายด้วยโค้ดเพียงไม่กี่บรรทัด นั่นคือทั้งหมดที่เกี่ยวกับการขูดเว็บสำหรับฉัน: การ แยกส่วนข้อมูลที่มีค่า จากเว็บไซต์ให้เป็นมาตรฐานเพื่อขับเคลื่อนกระบวนการทางธุรกิจที่ขับเคลื่อนคุณค่าอื่น
ในช่วงเวลานี้ ฉันเห็นบริษัทต่างๆ ใช้การขูดเว็บสำหรับกรณีการใช้งานทุกประเภท บริษัทด้านการลงทุนมุ่งเน้นไปที่การรวบรวมข้อมูลทางเลือกเป็นหลัก เช่น บทวิจารณ์ผลิตภัณฑ์ ข้อมูลราคา หรือโพสต์บนโซเชียลมีเดียเพื่อสนับสนุนการลงทุนทางการเงินของพวกเขา
นี่คือตัวอย่างหนึ่ง ลูกค้ารายหนึ่งเข้ามาหาฉันเพื่อขูดข้อมูลรีวิวผลิตภัณฑ์สำหรับรายการผลิตภัณฑ์จำนวนมากจากเว็บไซต์อีคอมเมิร์ซหลายแห่ง รวมถึงการให้คะแนน สถานที่ตั้งของผู้รีวิว และข้อความรีวิวสำหรับรีวิวที่ส่งมาแต่ละรายการ ข้อมูลผลลัพธ์ช่วยให้ลูกค้า ระบุแนวโน้ม เกี่ยวกับความนิยมของผลิตภัณฑ์ในตลาดต่างๆ ได้ นี่เป็นตัวอย่างที่ดีที่แสดงให้เห็นว่าข้อมูลชิ้นเดียวที่ดูเหมือน "ไร้ประโยชน์" สามารถมีค่าเมื่อเปรียบเทียบกับปริมาณที่มากขึ้น
บริษัทอื่นๆ เร่งกระบวนการขายโดยใช้ web scraping สำหรับการ สร้าง ลูกค้าเป้าหมาย กระบวนการนี้มักจะเกี่ยวข้องกับการดึงข้อมูลติดต่อ เช่น หมายเลขโทรศัพท์ ที่อยู่อีเมล และชื่อผู้ติดต่อสำหรับรายชื่อเว็บไซต์ที่กำหนด การทำงานนี้เป็นแบบอัตโนมัติช่วยให้ทีมขายมีเวลามากขึ้นในการเข้าหาผู้มีแนวโน้มจะเป็นลูกค้า ดังนั้นประสิทธิภาพของกระบวนการขายจึงเพิ่มขึ้น
ยึดตามกฎ
โดยทั่วไป การดึงข้อมูลเว็บที่เปิดเผยต่อสาธารณะนั้นถูกกฎหมาย ตามที่ได้รับการยืนยันโดยเขตอำนาจศาลของคดี Linkedin กับ HiQ อย่างไรก็ตาม ฉันได้ตั้งกฎเกณฑ์ทางจริยธรรมให้กับตัวเองที่ฉันชอบยึดถือเมื่อเริ่มโครงการขูดเว็บใหม่ ซึ่งรวมถึง:
- กำลังตรวจสอบไฟล์ robots.txt
โดยปกติจะมีข้อมูลที่ชัดเจนเกี่ยวกับส่วนใดของไซต์ที่เจ้าของเพจสามารถเข้าถึงได้โดยโรบ็อตและแครปเปอร์ และเน้นส่วนที่ไม่ควรเข้าถึง - การอ่านข้อกำหนดและเงื่อนไข
เมื่อเทียบกับ robots.txt ข้อมูลชิ้นนี้ไม่ได้มีให้บ่อยนัก แต่มักจะระบุวิธีจัดการกับข้อมูลแครปเปอร์ - ขูดด้วยความเร็วปานกลาง
การขูดจะสร้างภาระงานของเซิร์ฟเวอร์บนโครงสร้างพื้นฐานของไซต์เป้าหมาย ขึ้นอยู่กับสิ่งที่คุณขูดและระดับการทำงานพร้อมกันที่มีดโกนของคุณทำงาน การรับส่งข้อมูลอาจทำให้เกิดปัญหาสำหรับโครงสร้างพื้นฐานเซิร์ฟเวอร์ของไซต์เป้าหมาย แน่นอนว่าความจุของเซิร์ฟเวอร์มีบทบาทสำคัญในสมการนี้ ดังนั้น ความเร็วของมีดโกนของฉันจึงเป็น ความสมดุลระหว่างปริมาณข้อมูลที่ฉันตั้งใจจะขูดและความนิยมของไซต์เป้าหมายเสมอ การหาจุดสมดุลนี้สามารถทำได้โดยการตอบคำถามเดียว: "ความเร็วที่วางแผนไว้จะเปลี่ยนการเข้าชมที่เกิดขึ้นเองของไซต์อย่างมากหรือไม่" ในกรณีที่ฉันไม่แน่ใจเกี่ยวกับปริมาณการเข้าชมเว็บไซต์ตามธรรมชาติ ฉันใช้เครื่องมือเช่น ahrefs เพื่อทำความเข้าใจคร่าวๆ
การเลือกเทคโนโลยีที่เหมาะสม
อันที่จริง การ ขูดด้วยเบราว์เซอร์ที่ไม่มีส่วนหัว เป็นหนึ่งในเทคโนโลยีที่มีประสิทธิภาพ น้อยที่สุด ที่คุณสามารถใช้ได้ เนื่องจากจะส่งผลกระทบต่อโครงสร้างพื้นฐานของคุณอย่างมาก หนึ่งคอร์จากโปรเซสเซอร์ในเครื่องของคุณสามารถรองรับอินสแตนซ์ Chrome ได้ประมาณหนึ่งอินสแตนซ์
มาทำการ คำนวณตัวอย่าง อย่างรวดเร็วเพื่อดูว่าสิ่งนี้มีความหมายอย่างไรสำหรับโครงการขูดเว็บในโลกแห่งความเป็นจริง
สถานการณ์
- คุณต้องการขูด 20,000 URLs
- เวลาตอบสนองเฉลี่ยจากไซต์เป้าหมายคือ 6 วินาที
- เซิร์ฟเวอร์ของคุณมีซีพียู 2 คอร์
โครงการจะใช้เวลา 16 ชั่วโมง จึงจะแล้วเสร็จ
ดังนั้นฉันจึงพยายามหลีกเลี่ยงการใช้เบราว์เซอร์เสมอเมื่อทำการทดสอบความเป็นไปได้ในการขูดสำหรับเว็บไซต์แบบไดนามิก
ต่อไปนี้คือรายการตรวจสอบเล็กๆ น้อยๆ ที่ฉันต้องทำเสมอ:
- ฉันสามารถบังคับสถานะของหน้าที่ต้องการผ่านพารามิเตอร์ GET ใน URL ได้หรือไม่ ถ้าใช่ เราสามารถเรียกใช้คำขอ HTTP ด้วยพารามิเตอร์ที่ต่อท้ายได้
- ข้อมูลแบบไดนามิกเป็นส่วนหนึ่งของแหล่งที่มาของหน้าและพร้อมใช้งานผ่านวัตถุ JavaScript ที่ใดที่หนึ่งใน DOM ถ้าใช่ เราสามารถใช้คำขอ HTTP ปกติได้อีกครั้งและแยกวิเคราะห์ข้อมูลจากวัตถุที่ทำให้เป็นสตริง
- ข้อมูลถูกดึงผ่านคำขอ XHR หรือไม่ ถ้าใช่ ฉันสามารถเข้าถึงปลายทางโดยตรงด้วยไคลเอนต์ HTTP ได้หรือไม่ ถ้าใช่ เราสามารถส่งคำขอ HTTP ไปยังปลายทางได้โดยตรง หลายครั้ง การตอบสนองยังอยู่ในรูปแบบ JSON ซึ่งทำให้ชีวิตของเราง่ายขึ้นมาก
หากทุกคำถามมีคำตอบที่แน่ชัดว่า "ไม่" เราไม่มีทางเลือกที่เป็นไปได้สำหรับการใช้ไคลเอ็นต์ HTTP แน่นอน อาจมีการปรับแต่งเฉพาะไซต์มากกว่าที่เราลองทำได้ แต่โดยปกติ เวลาที่ใช้ในการคิดออกนั้นสูงเกินไป เมื่อเทียบกับประสิทธิภาพที่ช้ากว่าของเบราว์เซอร์ที่ไม่มีส่วนหัว ข้อดีของการขูดด้วยเบราว์เซอร์คือคุณสามารถขูดอะไรก็ได้ที่อยู่ภายใต้กฎพื้นฐานต่อไปนี้:
หากคุณสามารถเข้าถึงได้ด้วยเบราว์เซอร์ คุณสามารถขูดได้
ลองใช้ไซต์ต่อไปนี้เป็นตัวอย่างสำหรับมีดโกนของเรา: https://quotes.toscrape.com/search.aspx มันมีคำพูดจากรายชื่อผู้เขียนที่กำหนดสำหรับรายการหัวข้อ ข้อมูลทั้งหมดถูกดึงผ่าน XHR
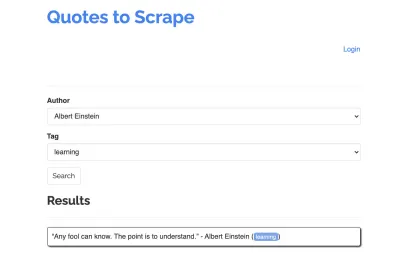
ใครก็ตามที่ตรวจสอบการทำงานของไซต์อย่างใกล้ชิดและผ่านรายการตรวจสอบด้านบนอาจรู้ว่าการอ้างสิทธิ์สามารถขูดออกได้จริงโดยใช้ไคลเอนต์ HTTP เนื่องจากสามารถดึงข้อมูลได้โดยทำการร้องขอ POST บนจุดปลายเครื่องหมายคำพูดโดยตรง แต่เนื่องจากบทช่วยสอนนี้ควรจะครอบคลุมถึงวิธีการขูดเว็บไซต์โดยใช้ Puppeteer เราจะแสร้งทำเป็นว่าเป็นไปไม่ได้
การติดตั้งข้อกำหนดเบื้องต้น
เนื่องจากเราจะสร้างทุกอย่างโดยใช้ Node.js ก่อนอื่นให้สร้างและเปิดโฟลเดอร์ใหม่ และสร้างโปรเจ็กต์ Node ใหม่ภายใน โดยใช้คำสั่งต่อไปนี้:
mkdir js-webscraper cd js-webscraper npm initโปรดตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง npm แล้ว โปรแกรมติดตั้งจะถามคำถามสองสามข้อเกี่ยวกับข้อมูลเมตาเกี่ยวกับโครงการนี้ ซึ่งเราทุกคนสามารถข้ามได้โดยกด Enter
การติดตั้ง Puppeteer
เราเคยพูดถึงการขูดด้วยเบราว์เซอร์มาก่อน Puppeteer เป็น Node.js API ที่ช่วยให้เราสามารถพูดคุยกับ อินสแตนซ์ Chrome ที่ไม่มีส่วนหัว โดยทางโปรแกรม
มาติดตั้งโดยใช้ npm:
npm install puppeteerการสร้างเครื่องขูดของเรา
ตอนนี้ มาเริ่มสร้างมีดโกนของเราโดยสร้างไฟล์ใหม่ที่เรียกว่า scraper.js
ขั้นแรก เรานำเข้าไลบรารีที่ติดตั้งไว้ก่อนหน้านี้ Puppeteer:
const puppeteer = require('puppeteer');ในขั้นตอนต่อไป เราบอกให้ Puppeteer เปิดอินสแตนซ์เบราว์เซอร์ใหม่ภายในฟังก์ชันแบบอะซิงโครนัสและดำเนินการเอง:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();หมายเหตุ : โดยค่าเริ่มต้น โหมดหัวขาดจะถูกปิด เนื่องจากจะเป็นการเพิ่มประสิทธิภาพ อย่างไรก็ตาม เมื่อสร้างมีดโกนใหม่ ฉันชอบปิดโหมดหัวขาด ซึ่งช่วยให้เราสามารถทำตามขั้นตอนที่เบราว์เซอร์กำลังดำเนินการและดูเนื้อหาที่แสดงผลทั้งหมดได้ ซึ่งจะช่วยให้เราดีบักสคริปต์ของเราได้ในภายหลัง
ภายในเบราว์เซอร์ที่เปิดอยู่ ตอนนี้เราเปิดหน้าใหม่และตรงไปยัง URL เป้าหมายของเรา:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); ในส่วนหนึ่งของฟังก์ชันอะซิงโครนัส เราจะใช้คำสั่ง await เพื่อรอให้คำสั่งต่อไปนี้ทำงานก่อนที่จะดำเนินการกับโค้ดบรรทัดถัดไป
ตอนนี้เราได้เปิดหน้าต่างเบราว์เซอร์และนำทางไปยังหน้าสำเร็จแล้ว เราต้อง สร้างสถานะของเว็บไซต์ เพื่อให้มองเห็นข้อมูลที่ต้องการได้สำหรับการขูด
หัวข้อที่มีอยู่จะถูกสร้างขึ้นแบบไดนามิกสำหรับผู้เขียนที่เลือก ดังนั้น ก่อนอื่นเราจะเลือก 'Albert Einstein' และรอรายการหัวข้อที่สร้างขึ้น เมื่อรายการถูกสร้างขึ้นอย่างสมบูรณ์แล้ว เราเลือก 'การเรียนรู้' เป็นหัวข้อและเลือกเป็นพารามิเตอร์รูปแบบที่สอง จากนั้นเราคลิกที่ส่งและดึงใบเสนอราคาที่ดึงมาจากคอนเทนเนอร์ที่ถือผลลัพธ์
เนื่องจากตอนนี้เราจะแปลงสิ่งนี้เป็นตรรกะ JavaScript ก่อนอื่นเรามาสร้างรายการตัวเลือกองค์ประกอบทั้งหมดที่เราได้พูดถึงในย่อหน้าก่อนหน้า:
| ฟิลด์เลือกผู้เขียน | #author |
| แท็กเลือกช่อง | #tag |
| ปุ่มส่ง | input[type="submit"] |
| คอนเทนเนอร์ใบเสนอราคา | .quote |
ก่อนที่เราจะเริ่มโต้ตอบกับเพจ เราจะตรวจสอบให้แน่ใจว่าองค์ประกอบทั้งหมดที่เราจะเข้าถึงนั้นมองเห็นได้ โดยการเพิ่มบรรทัดต่อไปนี้ในสคริปต์ของเรา:

await page.waitForSelector('#author'); await page.waitForSelector('#tag');ต่อไป เราจะเลือกค่าสำหรับสองฟิลด์ที่เลือกของเรา:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');ตอนนี้เราพร้อมที่จะทำการค้นหาโดยกดปุ่ม "ค้นหา" บนหน้าและรอให้คำพูดปรากฏขึ้น:
await page.click('.btn'); await page.waitForSelector('.quote'); เนื่องจากตอนนี้เรากำลังจะเข้าถึงโครงสร้าง HTML DOM ของหน้า เราจึงเรียกใช้ page.evaluate() ที่ให้มา โดยเลือกคอนเทนเนอร์ที่ถือเครื่องหมายคำพูด (ในกรณีนี้คืออันเดียวเท่านั้น) จากนั้นเราสร้างอ็อบเจ็กต์และกำหนด null เป็นค่าทางเลือกสำหรับพารามิเตอร์ object แต่ละตัว:
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });เราสามารถทำให้ผลลัพธ์ทั้งหมดปรากฏในคอนโซลของเราได้โดยการบันทึก:
console.log(quotes);สุดท้าย ให้ปิดเบราว์เซอร์ของเราและเพิ่มคำสั่ง catch:
await browser.close();มีดโกนที่สมบูรณ์มีลักษณะดังนี้:
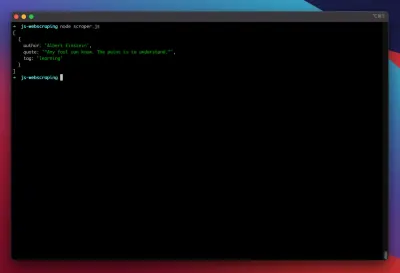
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();ลองใช้มีดโกนของเราด้วย:
node scraper.jsและเราไปกันเลย! มีดโกนส่งคืนอ็อบเจ็กต์ใบเสนอราคาของเราตามที่คาดไว้:
การเพิ่มประสิทธิภาพขั้นสูง
เครื่องขูดพื้นฐานของเรากำลังทำงานอยู่ มาเพิ่มการปรับปรุงเพื่อเตรียมพร้อมสำหรับงานขูดที่จริงจังกว่านี้
การตั้งค่า User-Agent
ตามค่าเริ่มต้น Puppeteer จะใช้ user-agent ที่มีสตริง HeadlessChrome มีเว็บไซต์ไม่กี่แห่งที่มองหาลายเซ็นประเภทนี้และ บล็อกคำขอที่เข้ามา ด้วยลายเซ็นแบบนั้น เพื่อหลีกเลี่ยงไม่ให้เป็นสาเหตุที่เป็นไปได้สำหรับมีดโกนที่จะล้มเหลว ฉันมักจะตั้งค่า user-agent ที่กำหนดเอง โดยเพิ่มบรรทัดต่อไปนี้ในโค้ดของเรา:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');สิ่งนี้สามารถปรับปรุงให้ดียิ่งขึ้นไปอีกโดยการเลือก User-agent แบบสุ่มกับคำขอแต่ละรายการจากอาร์เรย์ของ user-agent ที่พบบ่อยที่สุด 5 อันดับแรก รายชื่อ User-agent ที่พบบ่อยที่สุดสามารถพบได้ใน Most Common User-Agents
การใช้พร็อกซี่
Puppeteer ทำให้การเชื่อมต่อกับพร็อกซีเป็นเรื่องง่ายมาก เนื่องจากที่อยู่พร็อกซีสามารถส่งไปยัง Puppeteer เมื่อเปิดใช้งานได้ เช่นนี้:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies มีรายการพร็อกซีฟรีมากมายที่คุณสามารถใช้ได้ หรือใช้บริการพร็อกซีหมุนเวียนก็ได้ เนื่องจากโดยปกติแล้วพร็อกซี่จะถูกใช้ร่วมกันระหว่างลูกค้าจำนวนมาก (หรือผู้ใช้ฟรีในกรณีนี้) การเชื่อมต่อจึงไม่น่าเชื่อถือมากกว่าที่เป็นอยู่แล้วภายใต้สถานการณ์ปกติ นี่เป็นช่วงเวลาที่เหมาะที่จะพูดคุยเกี่ยวกับการจัดการข้อผิดพลาดและการจัดการลองใหม่
ข้อผิดพลาดและการจัดการลองใหม่
มีหลายปัจจัยที่อาจทำให้มีดโกนของคุณล้มเหลว ดังนั้นจึงเป็นเรื่องสำคัญที่จะต้องจัดการกับข้อผิดพลาดและตัดสินใจว่าจะเกิดอะไรขึ้นในกรณีที่เกิดความล้มเหลว เนื่องจากเราได้เชื่อมต่อมีดโกนของเรากับพร็อกซีและคาดว่าการเชื่อมต่อจะไม่เสถียร (โดยเฉพาะอย่างยิ่งเนื่องจากเราใช้พร็อกซีฟรี) เราจึงต้องการ ลองอีกครั้งสี่ครั้ง ก่อนที่จะยกเลิก
นอกจากนี้ ก็ไม่มีประโยชน์ที่จะลองส่งคำขอด้วยที่อยู่ IP เดิมอีกครั้งหากล้มเหลวก่อนหน้านี้ ดังนั้น เราจะสร้าง ระบบหมุนเวียนพร็อกซี่ ขนาดเล็ก
ก่อนอื่น เราสร้างตัวแปรใหม่สองตัว:
let retry = 0; let maxRetries = 5; ทุกครั้งที่เราเรียกใช้ฟังก์ชัน scrape() เราจะเพิ่มตัวแปรการลองใหม่เป็น 1 จากนั้นเราจะรวมตรรกะการขูดทั้งหมดด้วยคำสั่ง try and catch เพื่อให้เราสามารถจัดการกับข้อผิดพลาดได้ การจัดการลองใหม่เกิดขึ้นภายในฟังก์ชัน catch ของเรา:
อินสแตนซ์ของเบราว์เซอร์ก่อนหน้าจะถูกปิด และหากตัวแปรการลองใหม่ของเราน้อยกว่าตัวแปร maxRetries ฟังก์ชันการขูดจะถูกเรียกซ้ำ
มีดโกนของเราจะมีลักษณะดังนี้:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };ตอนนี้ ให้เราเพิ่มตัวหมุนพร็อกซีที่กล่าวถึงก่อนหน้านี้
ขั้นแรกให้สร้างอาร์เรย์ที่มีรายการพร็อกซี่:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];ตอนนี้ เลือกค่าสุ่มจากอาร์เรย์:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];ตอนนี้เราสามารถเรียกใช้พร็อกซีที่สร้างแบบไดนามิกร่วมกับอินสแตนซ์ Puppeteer ของเรา:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });แน่นอน ตัวหมุนพร็อกซี่นี้สามารถเพิ่มประสิทธิภาพเพิ่มเติมเพื่อตั้งค่าสถานะพร็อกซีที่ไม่ทำงาน และอื่นๆ แต่จะเกินขอบเขตของบทช่วยสอนนี้อย่างแน่นอน
นี่คือรหัสของมีดโกนของเรา (รวมถึงการปรับปรุงทั้งหมด):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();โว้ว! การเรียกใช้เครื่องขูดของเราภายในเทอร์มินัลจะส่งคืนราคา
นักเขียนบทละครทางเลือกแทนคนเชิดหุ่น
Puppeteer ได้รับการพัฒนาโดย Google เมื่อต้นปี 2563 Microsoft ได้เปิดตัวทางเลือกที่เรียกว่า Playwright Microsoft ได้ว่าจ้างวิศวกรจำนวนมากจากทีม Puppeteer-Team ดังนั้น นักเขียนบทละครจึงได้รับการพัฒนาโดยวิศวกรหลายคนที่ได้ลงมือทำ Puppeteer แล้ว นอกจากจะเป็นเด็กใหม่ในบล็อกแล้ว จุดแตกต่างที่ใหญ่ที่สุดของนักเขียนบทละครคือการสนับสนุนข้ามเบราว์เซอร์ เนื่องจากรองรับ Chromium, Firefox และ WebKit (Safari)
การทดสอบประสิทธิภาพ (เช่นการทดสอบนี้ดำเนินการโดย Checkly) แสดงให้เห็นว่าโดยทั่วไป Puppeteer ให้ประสิทธิภาพที่ดีขึ้นประมาณ 30% เมื่อเทียบกับนักเขียนบทละคร ซึ่งตรงกับประสบการณ์ของฉัน - อย่างน้อยก็ในขณะที่เขียน
ความแตกต่างอื่นๆ เช่น ความจริงที่ว่าคุณสามารถเรียกใช้อุปกรณ์หลายเครื่องด้วยอินสแตนซ์เบราว์เซอร์เดียว ไม่ได้มีค่ามากสำหรับบริบทของการขูดเว็บ
แหล่งข้อมูลและลิงค์เพิ่มเติม
- เอกสารเชิดหุ่น
- การเรียนรู้หุ่นกระบอกและนักเขียนบทละคร
- การขูดเว็บด้วย Javascript โดย Zenscrape
- ตัวแทนผู้ใช้ทั่วไปส่วนใหญ่
- Puppeteer vs. นักเขียนบทละคร