
แผ่นโกงวิทยาศาสตร์ข้อมูลขั้นสูงสุดที่นักวิทยาศาสตร์ข้อมูลทุกคนควรมี
เผยแพร่แล้ว: 2021-01-29สำหรับมืออาชีพรุ่นใหม่และมือใหม่ที่กำลังคิดที่จะดำดิ่งสู่โลกแห่งวิทยาศาสตร์ข้อมูลที่เฟื่องฟู เราได้รวบรวมเอกสารสรุปฉบับย่อเพื่อให้คุณได้เข้าใจถึงพื้นฐานและวิธีการที่เน้นย้ำในด้านนี้
สารบัญ
วิทยาศาสตร์ข้อมูล-พื้นฐาน
ข้อมูลที่สร้างขึ้นในโลกของเราอยู่ในรูปแบบดิบ เช่น ตัวเลข รหัส คำ ประโยค ฯลฯ Data Science นำข้อมูลดิบๆ นี้ไปประมวลผลโดยใช้วิธีการทางวิทยาศาสตร์เพื่อแปลงเป็นรูปแบบที่มีความหมายเพื่อให้ได้ความรู้และข้อมูลเชิงลึก .
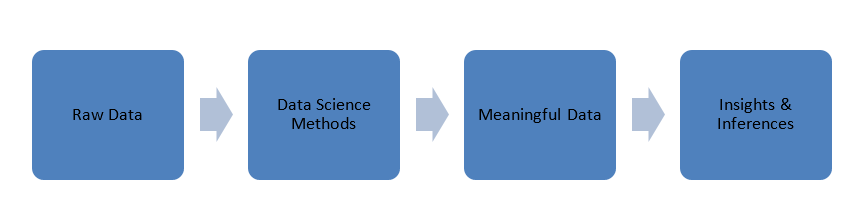
ข้อมูล
ก่อนที่เราจะดำดิ่งสู่หลักการของวิทยาศาสตร์ข้อมูล เรามาพูดถึงข้อมูล ประเภทของข้อมูล และการประมวลผลข้อมูลกันก่อนดีกว่า
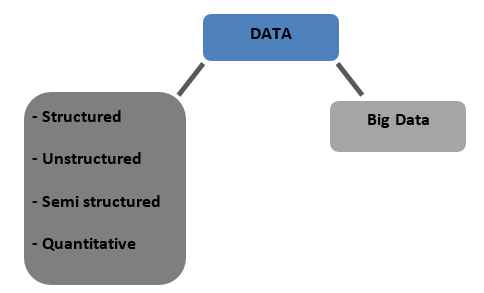
ประเภทของข้อมูล
โครงสร้าง – ข้อมูลที่จัดเก็บในรูปแบบตารางในฐานข้อมูล จะเป็นตัวเลขหรือข้อความก็ได้
ไม่มีโครงสร้าง – ข้อมูลที่ไม่สามารถจัดตารางด้วยโครงสร้างที่ชัดเจนใด ๆ ที่จะพูดถึงเรียกว่าข้อมูลที่ไม่มีโครงสร้าง
กึ่งมีโครงสร้าง – ข้อมูลผสมผสานกับลักษณะของทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
เชิงปริมาณ – ข้อมูลที่มีค่าตัวเลขที่แน่นอนที่สามารถหาปริมาณได้
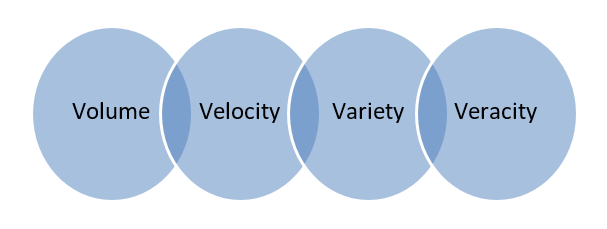
Big Data – ข้อมูลที่เก็บไว้ในฐานข้อมูลขนาดใหญ่ที่ครอบคลุมคอมพิวเตอร์หลายเครื่องหรือเซิร์ฟเวอร์ฟาร์มเรียกว่า Big Data ข้อมูลไบโอเมตริก ข้อมูลโซเชียลมีเดีย ฯลฯ ถือเป็นบิ๊กดาต้า ข้อมูลขนาดใหญ่มีลักษณะ 4 V's
การประมวลผลข้อมูลล่วงหน้า
การจัดประเภทข้อมูล – เป็นกระบวนการในการจัดหมวดหมู่หรือติดป้ายกำกับข้อมูลเป็นคลาสต่างๆ เช่น ตัวเลข ข้อความหรือรูปภาพ ข้อความ วิดีโอ ฯลฯ
การล้างข้อมูล - ประกอบด้วยการกำจัดข้อมูลที่ขาดหายไป/ไม่สอดคล้องกัน/เข้ากันไม่ได้ หรือแทนที่ข้อมูลโดยใช้วิธีใดวิธีหนึ่งต่อไปนี้
- การแก้ไข
- ฮิวริสติก
- สุ่มแจก
- เพื่อนบ้านที่ใกล้ที่สุด
การปกปิดข้อมูล – การซ่อนหรือปิดบังข้อมูลที่เป็นความลับเพื่อรักษาความเป็นส่วนตัวของข้อมูลที่ละเอียดอ่อนในขณะที่ยังสามารถประมวลผลได้
Data Science ทำมาจากอะไร?
แนวคิดของสถิติ
การถดถอย
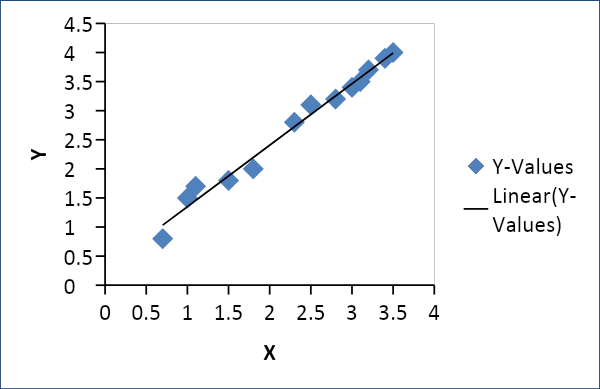
การถดถอยเชิงเส้น
การถดถอยเชิงเส้นใช้เพื่อสร้างความสัมพันธ์ระหว่างสองตัวแปร เช่น อุปสงค์และอุปทาน ราคาและการบริโภค ฯลฯ สัมพันธ์กับตัวแปร x ตัวหนึ่งเป็นฟังก์ชันเชิงเส้นของตัวแปร y อีกตัวหนึ่งดังนี้
Y = f(x) หรือ Y =mx + c โดยที่ m = สัมประสิทธิ์
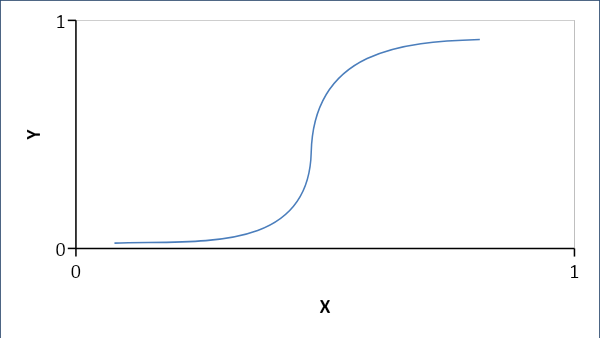
การถดถอยโลจิสติก
การถดถอยโลจิสติกสร้างความสัมพันธ์ที่น่าจะเป็นมากกว่าความสัมพันธ์เชิงเส้นตรงระหว่างตัวแปร คำตอบที่ได้คือ 0 หรือ 1 และเรามองหาความน่าจะเป็นและเส้นโค้งเป็นรูปตัว S
ถ้า p < 0.5 แสดงว่าเป็น 0 อื่น 1
สูตร:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
โดยที่ b0 = อคติและ b1 = สัมประสิทธิ์
ความน่าจะเป็น
ความน่าจะเป็นช่วยในการทำนายความน่าจะเป็นของเหตุการณ์ คำศัพท์บางคำ:
ตัวอย่าง: ชุดของผลลัพธ์ที่เป็นไปได้
เหตุการณ์: มันเป็นสับเซตของสเปซตัวอย่าง
ตัวแปรสุ่ม: ตัวแปรสุ่มช่วยในการแมปหรือหาจำนวนผลลัพธ์ที่น่าจะเป็นไปได้กับตัวเลขหรือเส้นในพื้นที่ตัวอย่าง
การแจกแจงความน่าจะเป็น
การแจกแจงแบบแยกส่วน: ให้ความน่าจะเป็นเป็นชุดของค่าที่ไม่ต่อเนื่อง (จำนวนเต็ม)
พี[X=x] = พี(x)
 ที่มาของภาพ
ที่มาของภาพ
การแจกแจงแบบต่อเนื่อง: ให้ความน่าจะเป็นมากกว่าจุดหรือช่วงต่อเนื่องจำนวนหนึ่ง แทนที่จะเป็นค่าที่ไม่ต่อเนื่อง สูตร:
P[a ≤ x ≤ b] = a∫bf(x) dx โดยที่ a, b คือจุด
ที่มาของภาพ
ความสัมพันธ์และความแปรปรวนร่วม
ค่าเบี่ยงเบนมาตรฐาน: ความผันแปรหรือค่าเบี่ยงเบนของชุดข้อมูลที่กำหนดจากค่ากลาง
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
ความแปรปรวนร่วม
มันกำหนดขอบเขตของการเบี่ยงเบนของตัวแปรสุ่ม X และ Y ด้วยค่าเฉลี่ยของชุดข้อมูล
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
ความสัมพันธ์
ความสัมพันธ์กำหนดขอบเขตของความสัมพันธ์เชิงเส้นตรงระหว่างตัวแปรพร้อมกับทิศทาง +ve หรือ -ve
ρXY= σ2XY/ σX * *σY
ปัญญาประดิษฐ์
ความสามารถของเครื่องจักรในการรับความรู้และตัดสินใจโดยอิงจากอินพุตนั้นเรียกว่าปัญญาประดิษฐ์หรือ AI เพียงอย่างเดียว
ประเภท
- Reactive Machines: Reactive machine AI ทำงานโดยการเรียนรู้ที่จะตอบสนองต่อสถานการณ์ที่กำหนดไว้ล่วงหน้าโดยจำกัดให้เหลือตัวเลือกที่เร็วและดีที่สุด พวกเขาขาดหน่วยความจำและดีที่สุดสำหรับงานที่มีชุดพารามิเตอร์ที่กำหนดไว้ เชื่อถือได้สูงและสม่ำเสมอ
- หน่วยความจำที่ จำกัด : AI นี้มีข้อมูลการสังเกตและดั้งเดิมในโลกแห่งความเป็นจริงที่ป้อนเข้าไป สามารถเรียนรู้และตัดสินใจตามข้อมูลที่กำหนด แต่ไม่สามารถได้รับประสบการณ์ใหม่ๆ
- ทฤษฎีความคิด: เป็น AI แบบโต้ตอบที่สามารถตัดสินใจตามพฤติกรรมของหน่วยงานโดยรอบ
- การตระหนักรู้ในตนเอง: AI นี้ตระหนักถึงการดำรงอยู่และการทำงานนอกเหนือจากสภาพแวดล้อม มันสามารถพัฒนาความสามารถทางปัญญาและเข้าใจและประเมินผลกระทบของการกระทำของตัวเองที่มีต่อสิ่งแวดล้อม
เงื่อนไข AI
โครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมเป็นกลุ่มหรือเครือข่ายของโหนดที่เชื่อมต่อถึงกันซึ่งถ่ายทอดข้อมูลและข้อมูลในระบบ NN ถูกสร้างแบบจำลองเพื่อเลียนแบบเซลล์ประสาทในสมองของเรา และสามารถตัดสินใจได้ด้วยการเรียนรู้และการทำนาย
ฮิวริสติก
ฮิวริสติกคือความสามารถในการคาดการณ์ตามการประมาณและการประมาณการอย่างรวดเร็วโดยใช้ประสบการณ์ก่อนหน้าในสถานการณ์ที่ข้อมูลที่มีอยู่เป็นหย่อมๆ รวดเร็วแต่ไม่แม่นยำหรือแม่นยำ
การใช้เหตุผลตามกรณี
ความสามารถในการเรียนรู้จากกรณีการแก้ปัญหาก่อนหน้านี้และประยุกต์ใช้ในสถานการณ์ปัจจุบันเพื่อให้ได้วิธีแก้ปัญหาที่ยอมรับได้
การประมวลผลภาษาธรรมชาติ
เป็นเพียงความสามารถของเครื่องในการทำความเข้าใจและโต้ตอบโดยตรงด้วยคำพูดหรือข้อความของมนุษย์ เช่น คำสั่งเสียงในรถยนต์
การเรียนรู้ของเครื่อง
การเรียนรู้ของเครื่องเป็นเพียงแอปพลิเคชันของ AI โดยใช้โมเดลและอัลกอริทึมต่างๆ เพื่อทำนายและแก้ปัญหา

ประเภท
ดูแล
วิธีนี้อาศัยข้อมูลอินพุตที่เชื่อมโยงกับข้อมูลเอาต์พุต เครื่องมีชุดของตัวแปรเป้าหมาย Y และจะต้องไปถึงตัวแปรเป้าหมายผ่านชุดของตัวแปรอินพุต X ภายใต้การควบคุมดูแลของอัลกอริธึมการปรับให้เหมาะสม ตัวอย่างของการเรียนรู้ภายใต้การดูแล ได้แก่ Neural Networks, Random Forest, Deep Learning, Support Vector Machines เป็นต้น
ไม่ได้รับการดูแล
ในวิธีนี้ ตัวแปรอินพุตไม่มีป้ายกำกับหรือการเชื่อมโยง และอัลกอริธึมทำงานเพื่อค้นหารูปแบบและคลัสเตอร์ที่ส่งผลให้เกิดความรู้และข้อมูลเชิงลึกใหม่
เสริมแรง
การเรียนรู้แบบเสริมกำลังมุ่งเน้นไปที่เทคนิคการด้นสดเพื่อฝึกฝนหรือขัดเกลาพฤติกรรมการเรียนรู้ เป็นวิธีการให้รางวัลโดยเครื่องจะค่อยๆ ปรับปรุงเทคนิคเพื่อรับรางวัลตามเป้าหมาย
วิธีการสร้างแบบจำลอง
การถดถอย
ตัวแบบถดถอยจะให้ตัวเลขเป็นเอาต์พุตผ่านการประมาณค่าหรือการอนุมานข้อมูลอย่างต่อเนื่อง
การจำแนกประเภท
โมเดลการจัดประเภทมาพร้อมกับผลลัพธ์เป็นคลาสหรือป้ายกำกับ และคาดการณ์ผลลัพธ์ที่ไม่ต่อเนื่อง เช่น 'ชนิดใด' ได้ดีกว่า
ทั้งการถดถอยและการจำแนกประเภทเป็นแบบจำลองภายใต้การดูแล
การจัดกลุ่ม
การทำคลัสเตอร์เป็นรูปแบบที่ไม่มีผู้ดูแลซึ่งระบุคลัสเตอร์ตามลักษณะ คุณลักษณะ คุณลักษณะ ฯลฯ
ML Algorithms
ต้นไม้ตัดสินใจ
ต้นไม้แห่งการตัดสินใจใช้วิธีการแบบเลขฐานสองเพื่อให้ได้คำตอบโดยอิงจากคำถามที่ต่อเนื่องกันในแต่ละขั้นตอน ซึ่งผลลัพธ์จะเป็นแบบใดแบบหนึ่งจากสองแบบที่เป็นไปได้ เช่น 'ใช่' หรือ 'ไม่ใช่' ต้นไม้แห่งการตัดสินใจนั้นง่ายต่อการนำไปใช้และตีความ
สุ่มป่าหรือห่อ
Random Forest เป็นอัลกอริธึมขั้นสูงของแผนผังการตัดสินใจ ใช้ต้นไม้ตัดสินใจจำนวนมากซึ่งทำให้โครงสร้างหนาแน่นและซับซ้อนเหมือนป่า มันสร้างผลลัพธ์ที่หลากหลายและนำไปสู่ผลลัพธ์และประสิทธิภาพที่แม่นยำยิ่งขึ้น
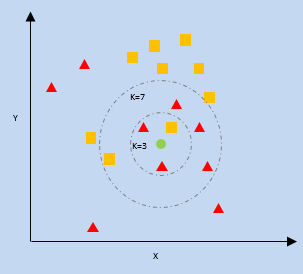
K- เพื่อนบ้านที่ใกล้ที่สุด (KNN)
kNN ใช้ประโยชน์จากความใกล้เคียงของจุดข้อมูลที่ใกล้ที่สุดบนพล็อตที่สัมพันธ์กับจุดข้อมูลใหม่เพื่อคาดการณ์ว่าจุดข้อมูลนั้นอยู่ในหมวดหมู่ใด จุดข้อมูลใหม่ถูกกำหนดให้กับหมวดหมู่ที่มีจำนวนเพื่อนบ้านสูงกว่า
k = จำนวนเพื่อนบ้านที่ใกล้ที่สุด
Naive Bayes
Naive Bayes ทำงานบนสองเสาหลัก ประการแรกคือทุกคุณสมบัติของจุดข้อมูลมีความเป็นอิสระ ไม่เกี่ยวข้องกัน กล่าวคือ มีลักษณะเฉพาะ และประการที่สองในทฤษฎีบท Bayes ซึ่งทำนายผลลัพธ์ตามเงื่อนไขหรือสมมติฐาน
ทฤษฎีบทเบย์:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
โดยที่ P(X|Y) = ความน่าจะเป็นแบบมีเงื่อนไขของ X ที่กำหนดให้ Y
P(Y|X) = ความน่าจะเป็นแบบมีเงื่อนไขของ Y จากการเกิดขึ้นของ X
P(X), P(Y) = ความน่าจะเป็นของ X และ Y แยกกัน
รองรับ Vector Machines
อัลกอริธึมนี้พยายามแยกข้อมูลในอวกาศตามขอบเขตซึ่งอาจเป็นเส้นหรือระนาบก็ได้ ขอบเขตนี้เรียกว่า 'ไฮเปอร์เพลน' และถูกกำหนดโดยจุดข้อมูลที่ใกล้ที่สุดของแต่ละคลาส ซึ่งจะเรียกว่า 'เวกเตอร์สนับสนุน' ระยะห่างสูงสุดระหว่างเวกเตอร์สนับสนุนของด้านใดด้านหนึ่งเรียกว่าระยะขอบ
โครงข่ายประสาทเทียม
เพอร์เซ็ปตรอน
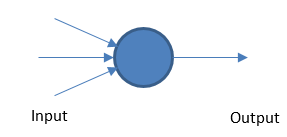
โครงข่ายประสาทเทียมพื้นฐานทำงานโดยรับอินพุตและเอาต์พุตแบบถ่วงน้ำหนักตามค่าเกณฑ์
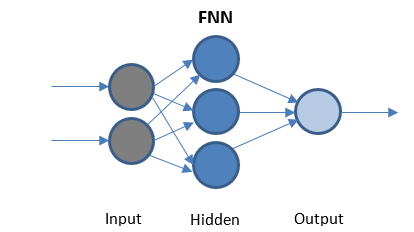
ฟีด Forward Neural Network
FFN เป็นเครือข่ายที่ง่ายที่สุดที่ส่งข้อมูลในทิศทางเดียวเท่านั้น อาจมีหรือไม่มีเลเยอร์ที่ซ่อนอยู่
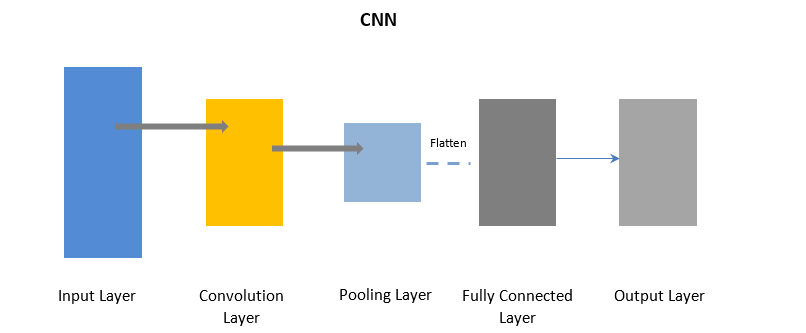
โครงข่ายประสาทเทียม
CNN ใช้ชั้น Convolution เพื่อประมวลผลบางส่วนของข้อมูลที่ป้อนเข้าเป็นชุดๆ ตามด้วยชั้นการรวมกลุ่มเพื่อให้ผลลัพธ์สมบูรณ์
โครงข่ายประสาทกำเริบ
RNN ประกอบด้วยเลเยอร์ที่เกิดซ้ำสองสามชั้นระหว่างเลเยอร์ I/O ที่สามารถจัดเก็บข้อมูล 'ประวัติ' กระแสข้อมูลเป็นแบบสองทิศทางและถูกส่งไปยังเลเยอร์ที่เกิดซ้ำเพื่อปรับปรุงการคาดการณ์
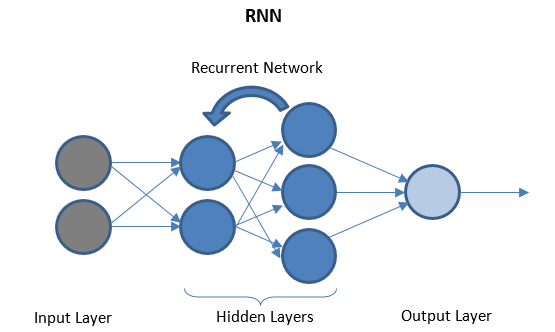
โครงข่ายประสาทลึกและการเรียนรู้เชิงลึก
DNN เป็นเครือข่ายที่มีเลเยอร์ที่ซ่อนอยู่หลายชั้นระหว่างเลเยอร์ I/O เลเยอร์ที่ซ่อนอยู่จะใช้การแปลงข้อมูลอย่างต่อเนื่องก่อนที่จะส่งไปยังเลเยอร์เอาต์พุต
'การเรียนรู้เชิงลึก' ได้รับการอำนวยความสะดวกผ่าน DNN และสามารถจัดการข้อมูลที่ซับซ้อนจำนวนมากและบรรลุความถูกต้องแม่นยำสูงเนื่องจากมีเลเยอร์ที่ซ่อนอยู่หลายชั้น
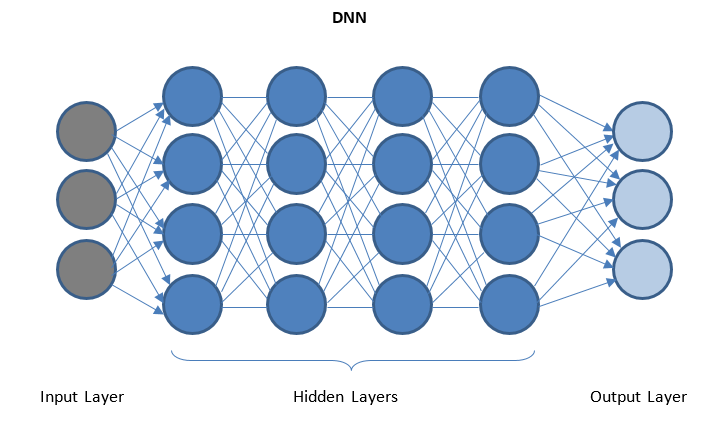
รับ ใบรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก เรียนรู้หลักสูตร Executive PG Programs, Advanced Certificate Programs หรือ Masters Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
บทสรุป
วิทยาศาสตร์ข้อมูลเป็นสาขากว้างใหญ่ที่ไหลผ่านลำธารที่แตกต่างกัน แต่กลับกลายเป็นการปฏิวัติและการเปิดเผยสำหรับเรา วิทยาศาสตร์ข้อมูลกำลังเฟื่องฟูและจะเปลี่ยนวิธีทำงานและความรู้สึกของระบบของเราในอนาคต
หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ให้ลองดูประกาศนียบัตร PG ด้านวิทยาศาสตร์ข้อมูลของ IIIT-B และ upGrad ซึ่งสร้างขึ้นสำหรับมืออาชีพด้านการทำงานและเสนอกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1- on-1 กับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ภาษาโปรแกรมใดที่เหมาะสมที่สุดสำหรับ Data Science และเพราะเหตุใด
มีภาษาโปรแกรมมากมายสำหรับ Data Science ที่มีอยู่ แต่ชุมชน Data Science ส่วนใหญ่เชื่อว่าหากคุณต้องการเป็นเลิศในด้านวิทยาศาสตร์ข้อมูล Python เป็นตัวเลือกที่เหมาะสม ด้านล่างนี้คือเหตุผลบางส่วนที่สนับสนุนความเชื่อนี้:
1. Python มีโมดูลและไลบรารีที่หลากหลาย เช่น TensorFlow และ PyTorch ที่ทำให้ง่ายต่อการจัดการกับแนวคิดด้านวิทยาศาสตร์ข้อมูล
2. ชุมชนนักพัฒนา Python จำนวนมากคอยช่วยเหลือมือใหม่ให้ผ่านไปยังขั้นตอนถัดไปของเส้นทางวิทยาศาสตร์ข้อมูล
3. ภาษานี้เป็นหนึ่งในภาษาเขียนที่สะดวกและง่ายที่สุดด้วยรูปแบบไวยากรณ์ที่สะอาดตาซึ่งช่วยปรับปรุงความสามารถในการอ่าน
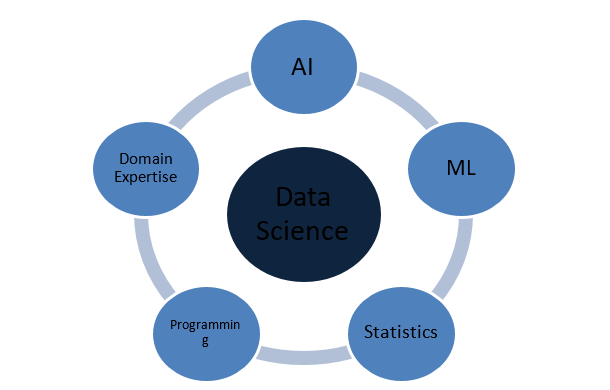
แนวคิดที่ทำให้วิทยาศาสตร์ข้อมูลสมบูรณ์มีอะไรบ้าง?
Data Science เป็นโดเมนขนาดใหญ่ที่ทำหน้าที่เป็นร่มสำหรับโดเมนที่สำคัญอื่นๆ ต่อไปนี้เป็นแนวคิดที่โดดเด่นที่สุดที่ประกอบเป็นวิทยาศาสตร์ข้อมูล:
สถิติ
สถิติเป็นแนวคิดที่สำคัญที่คุณต้องเป็นเลิศ เพื่อก้าวไปข้างหน้าในด้านวิทยาศาสตร์ข้อมูล นอกจากนี้ยังมีหัวข้อย่อยบางส่วน:
1. การถดถอยเชิงเส้น
2. ความน่าจะเป็น
3. การกระจายความน่าจะเป็น
ปัญญาประดิษฐ์
วิทยาศาสตร์ในการจัดหาสมองให้กับเครื่องจักรและปล่อยให้พวกเขาตัดสินใจเองโดยอิงจากปัจจัยการผลิตนั้นเรียกว่าปัญญาประดิษฐ์ เครื่องปฏิกรณ์ ความจำที่จำกัด ทฤษฎีความคิด และความตระหนักในตนเองเป็นปัญญาประดิษฐ์บางประเภท
การเรียนรู้ของเครื่อง
แมชชีนเลิร์นนิงเป็นอีกหนึ่งองค์ประกอบที่สำคัญของ Data Science ที่เกี่ยวข้องกับเครื่องสอนเพื่อทำนายผลลัพธ์ในอนาคตโดยอิงจากข้อมูลที่ให้มา แมชชีนเลิร์นนิงมีวิธีการสร้างแบบจำลองที่โดดเด่นสามวิธี ได้แก่ การทำคลัสเตอร์ การถดถอย และการจัดประเภท
อธิบายประเภทของแมชชีนเลิร์นนิง?
แมชชีนเลิร์นนิงหรือ ML แบบง่ายมีสามประเภทหลักตามวิธีการทำงาน ประเภทเหล่านี้มีดังนี้:
1. การเรียนรู้ภายใต้การดูแล
นี่คือ ML ประเภทดั้งเดิมที่สุดที่มีป้ายกำกับข้อมูลอินพุต เครื่องมีชุดข้อมูลขนาดเล็กกว่าที่ช่วยให้เครื่องเข้าใจปัญหาและได้รับการฝึกอบรม
2. การเรียนรู้ โดยไม่ได้รับการดูแล
ข้อได้เปรียบที่ใหญ่ที่สุดของประเภทนี้คือข้อมูลไม่มีป้ายกำกับที่นี่ และแรงงานมนุษย์แทบไม่มีความสำคัญ ซึ่งจะเปิดประตูสำหรับชุดข้อมูลขนาดใหญ่กว่าที่จะนำมาใช้กับโมเดล
3. Reinforced Learning ซึ่งเป็น ML ขั้นสูงที่ได้รับแรงบันดาลใจจากชีวิตมนุษย์ ผลลัพธ์ที่ต้องการจะได้รับการเสริมในขณะที่ผลลัพธ์ที่ไร้ประโยชน์ถูกกีดกัน