
Data Frames in Python: Python บทช่วยสอนเชิงลึก 2022
เผยแพร่แล้ว: 2021-01-09หากคุณเป็นนักพัฒนาหรือผู้เขียนโค้ดที่ทำงานในภาษาการเขียนโปรแกรม Python คุณต้องคุ้นเคยกับหนึ่งในไลบรารีการจัดการข้อมูลที่น่าทึ่งที่สุด - Pandas ซึ่งเป็นหนึ่งในไลบรารีไพ ธ อนชั้นนำ ในช่วงหลายปีที่ผ่านมา Pandas ได้กลายเป็นเครื่องมือมาตรฐานสำหรับการวิเคราะห์และจัดการข้อมูลโดยใช้ Python อ่านเกี่ยวกับเครื่องมือ Python ที่สำคัญอื่นๆ
Pandas เป็นแพ็คเกจ Python ที่หลากหลายที่สุดสำหรับวิทยาศาสตร์ข้อมูลอย่างไม่ต้องสงสัย มันมีโครงสร้างข้อมูลที่ทรงพลัง แสดงออกได้ และยืดหยุ่นสำหรับการจัดการและวิเคราะห์ข้อมูลอย่างง่ายดาย และ Data Frames ใน Python เป็นหนึ่งในโครงสร้างเหล่านี้
นี่คือหัวข้อการสนทนาของเราในโพสต์นี้ เราจะแนะนำคุณเกี่ยวกับรูปแบบข้อมูลพื้นฐานสำหรับ Pandas นั่นคือ Pandas Data Frame
สารบัญ
Data Frame คืออะไร?
ตาม เอกสารของห้องสมุด Pandas Data Frame คือ "โครงสร้างข้อมูลแบบตารางสองมิติ ปรับขนาดได้ ที่อาจต่างกันได้โดยมีแกนกำกับ (แถวและคอลัมน์)" พูดง่ายๆ ก็คือ Data Frame คือโครงสร้างข้อมูลที่มีการจัดแนวข้อมูลในรูปแบบตาราง กล่าวคือ ในแถวและคอลัมน์
Data Frame มักจะมีลักษณะดังต่อไปนี้:
- อาจมีหลายแถวและหลายคอลัมน์
- แม้ว่าแต่ละแถวจะแสดงตัวอย่างข้อมูล แต่แต่ละคอลัมน์จะประกอบด้วยตัวแปรต่างๆ ที่อธิบายกลุ่มตัวอย่าง (แถว)
- ข้อมูลในทุกคอลัมน์มักจะเป็นข้อมูลประเภทเดียวกัน (เช่น ตัวเลข สตริง วันที่ ฯลฯ)
- ต่างจากชุดข้อมูล excel โดยจะหลีกเลี่ยงการมีค่าที่หายไป ดังนั้นจึงไม่มีช่องว่างหรือค่าว่างระหว่างแถวหรือคอลัมน์
ใน Pandas Data Frame คุณยังสามารถระบุชื่อดัชนีและคอลัมน์สำหรับ Data Frame ของคุณได้ ในขณะที่ดัชนีระบุความแตกต่างในแถว ชื่อคอลัมน์จะแสดงความแตกต่างในคอลัมน์
วิธีสร้าง Data Frame ใน Python (โดยใช้ Pandas)
การสร้าง Data Frame เป็นขั้นตอนแรกสำหรับการแก้ไขข้อมูลใน Python คุณสามารถสร้าง Pandas Data Frame โดยใช้อินพุตเช่น:
- Dict
- รายการ
- ชุด
- Numpy “นดาเรย์”
- กรอบข้อมูลอื่น
- ไฟล์ภายนอกเช่น CS
- การสร้างกรอบข้อมูลที่ว่างเปล่า
มันค่อนข้างง่ายที่จะสร้าง Data Frame พื้นฐาน หรือที่เรียกว่า Empty Data Frame นี่คือตัวอย่าง:
ป้อนข้อมูล -

เอาท์พุต –

- การสร้าง Data Frame จาก Lists
คุณสามารถสร้าง Data Frame โดยใช้รายการเดียวหรือหลายรายการ
ป้อนข้อมูล -

เอาท์พุต –

- การสร้าง Data Frame จาก Dict ของ “ndarrays” หรือ Lists
ในการสร้าง Data Frame จาก dict ของ ndarrays ndarray ทั้งหมดต้องมีความยาวเท่ากัน นอกจากนี้ หากมีการจัดทำดัชนี ความยาวของดัชนีควรเท่ากับความยาวของอาร์เรย์ อย่างไรก็ตาม หากไม่ได้จัดทำดัชนี ดัชนีจะเป็น range(n) โดยค่าเริ่มต้น โดยที่ 'n' หมายถึงความยาวของอาร์เรย์
ป้อนข้อมูล -

เอาท์พุต –

ที่นี่ค่า 0,1,2,3 เป็นดัชนีเริ่มต้นที่กำหนดให้กับแต่ละแถวโดยใช้ช่วงของฟังก์ชัน (n)
การทำงานของกรอบข้อมูลพื้นฐานคืออะไร?
ตอนนี้เราได้เห็นวิธีสร้าง Data Frames ใน Python สามวิธีแล้ว ถึงเวลาเรียนรู้เกี่ยวกับการดำเนินการต่างๆ ภายใน Data Frame
- การเลือกดัชนีหรือคอลัมน์จาก Pandas Data Frame
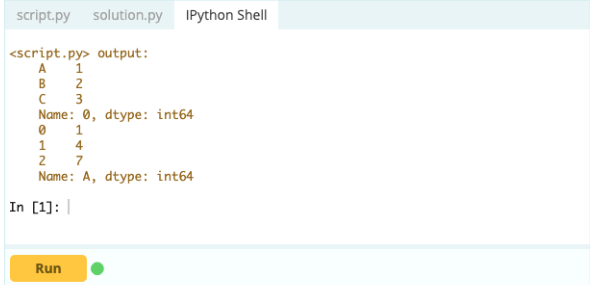
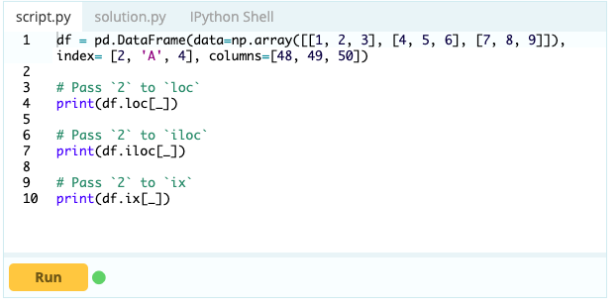
สิ่งสำคัญคือต้องรู้วิธีเลือกดัชนีหรือคอลัมน์ก่อนจึงจะสามารถเริ่มเพิ่ม ลบ และเปลี่ยนชื่อส่วนประกอบภายใน DataFrame ได้ สมมติว่านี่คือกรอบข้อมูลของคุณ:

คุณต้องการเข้าถึงค่าภายใต้ดัชนี 0 ในคอลัมน์ 'A' – ค่าคือ 1 มีหลายวิธีในการเข้าถึงค่านี้ แต่วิธีที่สำคัญที่สุดสองวิธีคือ – .loc[] และ .iloc[]
ป้อนข้อมูล -
เอาท์พุต –
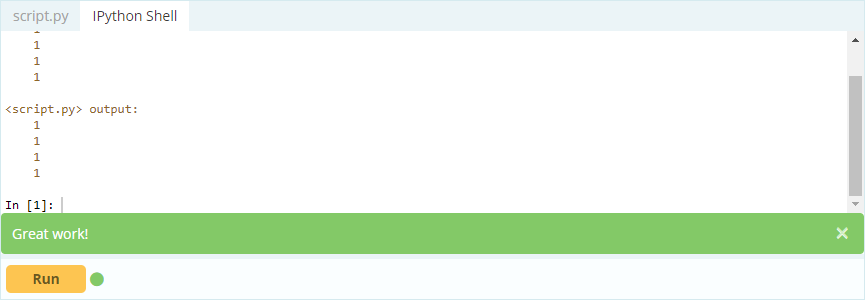
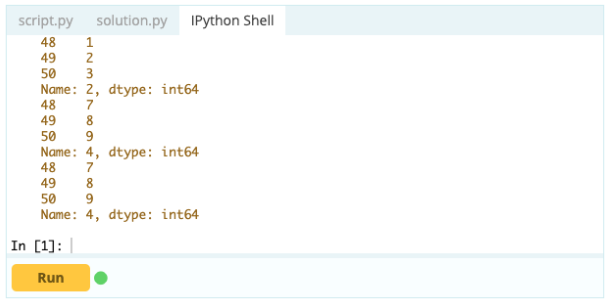
ดังที่คุณเห็นแล้ว คุณสามารถเข้าถึงค่าต่างๆ ได้โดยการเรียกค่าโดยใช้ป้ายกำกับหรือโดยการประกาศตำแหน่งในดัชนีหรือคอลัมน์ ขณะที่กำลังเลือกค่าจาก Data Frame คุณจะเลือกแถวและคอลัมน์จากค่าเดียวกันได้อย่างไร
นี่คือวิธี:
ป้อนข้อมูล -
เอาท์พุต-
- วิธีเพิ่มดัชนี แถว หรือคอลัมน์ใน Pandas DataFrame
เมื่อคุณเรียนรู้วิธีเข้าถึงค่าและเลือกคอลัมน์จาก Data Frame แล้ว คุณสามารถเรียนรู้วิธีเพิ่มดัชนี แถว หรือคอลัมน์ใน Pandas Data Frame
การเพิ่มดัชนี:
ขณะสร้าง Data Frame คุณสามารถเลือกเพิ่มอินพุตไปยังอาร์กิวเมนต์ 'index' เพื่อให้แน่ใจว่าคุณสามารถเข้าถึงดัชนีที่คุณต้องการได้อย่างง่ายดาย ถ้าคุณไม่ระบุดัชนี ตามค่าเริ่มต้น ดัชนีค่าตัวเลขที่ขึ้นต้นด้วย 0 และดำเนินต่อไปจนถึงแถวสุดท้ายของ DataFrame จะถูกเพิ่มเข้าไป แม้ว่าดัชนีจะถูกระบุโดยค่าเริ่มต้นแล้ว คุณสามารถใช้คอลัมน์และแปลงเป็นดัชนีได้โดยการเรียกใช้ฟังก์ชัน set_index() ใน Data Frame

การเพิ่มแถว:
คุณสามารถเพิ่มแถวใน DataFrame โดยใช้ฟังก์ชันผนวก
ป้อนข้อมูล -

เอาท์พุต –

คุณยังสามารถใช้ .loc เพื่อแทรกแถวใน DataFrame ของคุณได้ดังนี้:
ป้อนข้อมูล -
เอาท์พุต –
การเพิ่มคอลัมน์
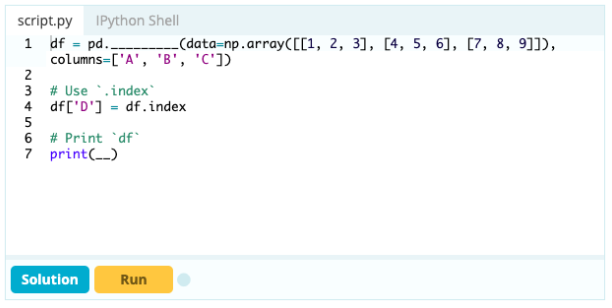
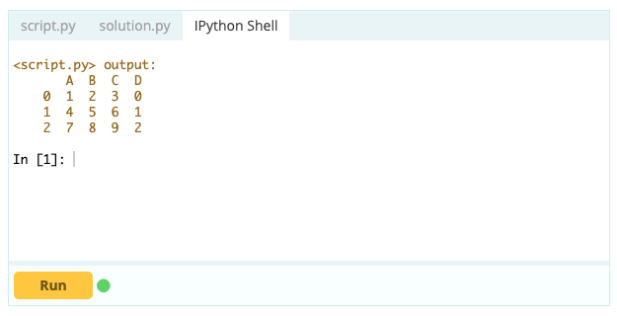
หากคุณต้องการสร้างดัชนีให้เป็นส่วนหนึ่งของ Data Frame คุณสามารถใช้คอลัมน์จาก Data Frame หรืออ้างถึงคอลัมน์ที่ยังไม่ได้สร้าง และกำหนดให้กับคุณสมบัติ .index ดังนี้:
ป้อนข้อมูล -
เอาท์พุต –
สำหรับการเพิ่มคอลัมน์ใน Data Frame คุณยังสามารถใช้วิธีการเดียวกันกับที่คุณจะใช้สำหรับการเพิ่มดัชนีไปยัง Data Frame นั่นคือ คุณสามารถใช้ฟังก์ชัน .loc[ ] หรือ .iloc[ ] ตัวอย่างเช่น:
ป้อนข้อมูล -
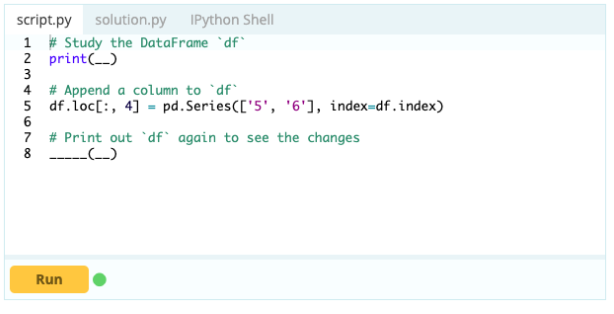
เอาท์พุต
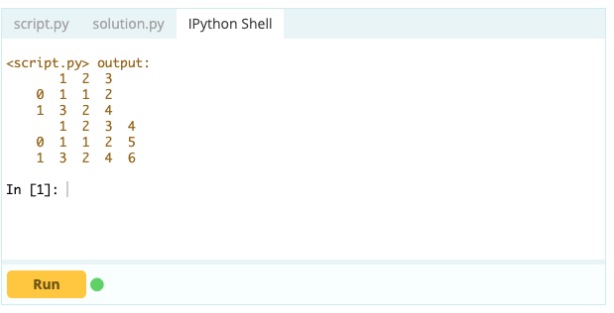
ด้วย .loc[ ] คุณสามารถเพิ่มซีรี่ส์ให้กับ DataFrame ที่มีอยู่ได้ เนื่องจากอ็อบเจ็กต์ Series ค่อนข้างคล้ายกับคอลัมน์ของ Data Frame มันจึงง่ายมากที่จะเพิ่ม Series ไปยัง Data Frame ที่มีอยู่
- จะรีเซ็ตดัชนีของ Data Frame ได้อย่างไร?
คุณสามารถรีเซ็ตดัชนีของ Data Frame ได้หากกรอบไม่เป็นไปตามที่คุณต้องการ คุณสามารถใช้ฟังก์ชัน .reset_index() เพื่อทำสิ่งนี้
ป้อนข้อมูล -
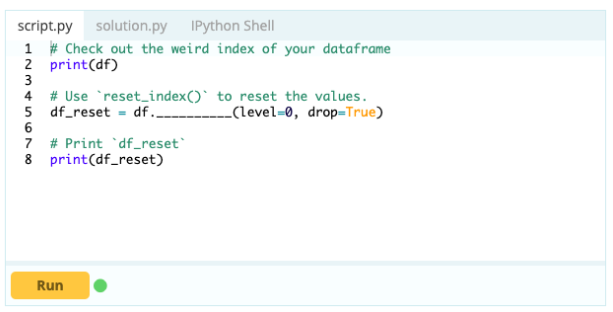
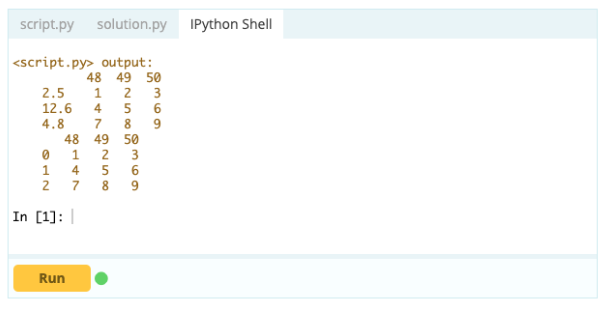
เอาท์พุต –
- วิธีการลบดัชนี แถว หรือคอลัมน์ใน Pandas DataFrame
การลบดัชนี
- การรีเซ็ตดัชนีของ Data Frame
- ลบชื่อดัชนี (ถ้ามี) โดยใช้ฟังก์ชัน del df.index.name
- ลบดัชนีพร้อมกับแถว
- ลบค่าดัชนีที่ซ้ำกันทั้งหมดโดยรีเซ็ตดัชนี ลบคอลัมน์ดัชนีที่ซ้ำกันที่เพิ่มไปยัง Data Frame และคืนสถานะคอลัมน์ใหม่ (ปราศจากดัชนีที่ซ้ำกัน) อีกครั้งเป็นดัชนี
การลบคอลัมน์
สำหรับการลบคอลัมน์ออกจาก Data Frame คุณสามารถใช้ฟังก์ชัน drop()
ป้อนข้อมูล -
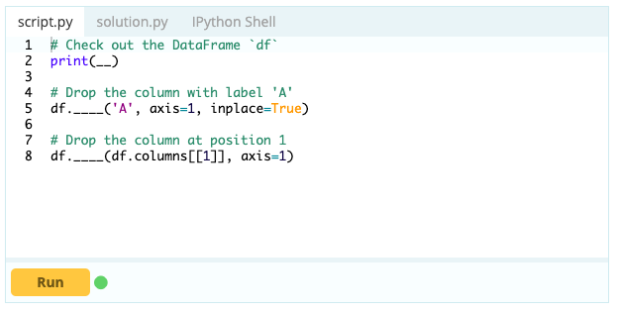
เอาท์พุต –
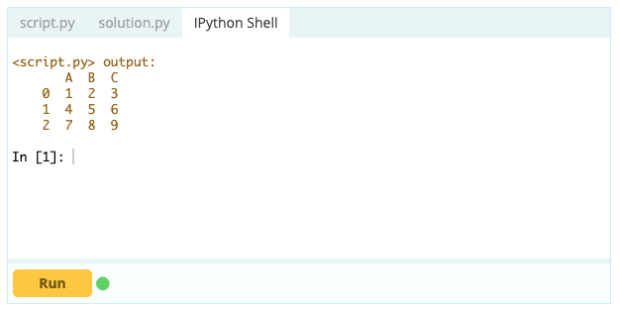
การลบแถว
หากต้องการลบแถวออกจาก Data Frame คุณสามารถใช้ฟังก์ชัน drop() โดยใช้คุณสมบัติ index เพื่อระบุดัชนีของแถวที่คุณต้องการลบออกจาก DataFrame
ป้อนข้อมูล -
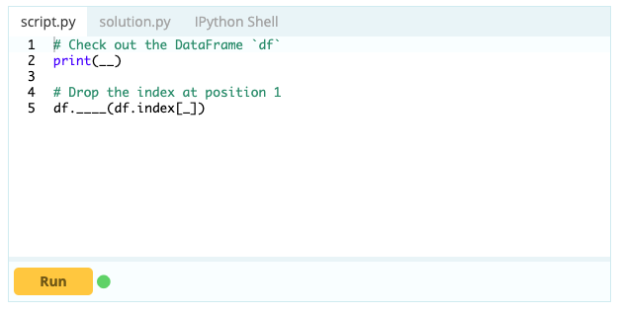
เอาท์พุต –
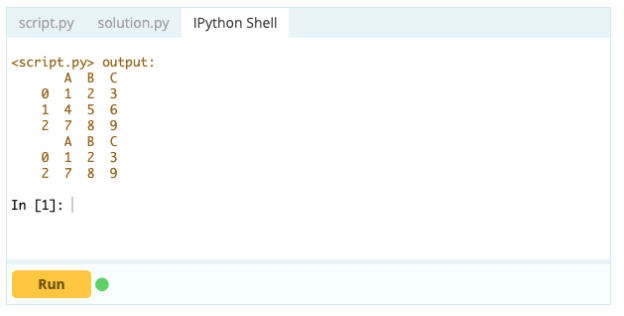
อย่างไรก็ตาม หากต้องการลบแถวที่ซ้ำกัน คุณสามารถใช้ฟังก์ชัน df.drop_duplicates()
ป้อนข้อมูล -
เอาท์พุต –
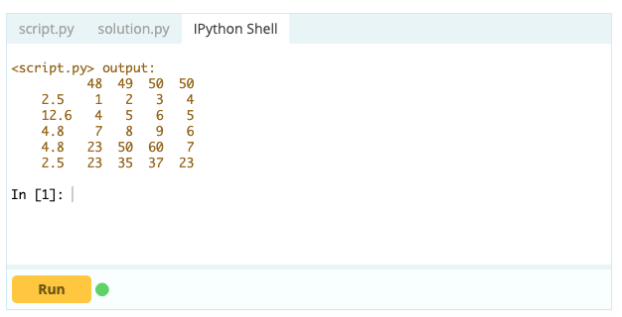
ที่มา: Tutorialspoint Datacamp
บทสรุป
ดังนั้น มีบทช่วยสอนพื้นฐานของคุณสำหรับ Data Frame ใน Python โดยใช้ Pandas
หากคุณสนใจที่จะเรียนรู้ Python วิทยาศาสตร์ข้อมูล ลองดูประกาศนียบัตร PG ด้านวิทยาศาสตร์ข้อมูลของ IIIT-B และ upGrad ซึ่งสร้างขึ้นสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 10 รายการ การประชุมเชิงปฏิบัติการเชิงปฏิบัติ การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม ตัวต่อตัวกับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ทำไม Pandas เป็นหนึ่งในไลบรารี่ที่ต้องการมากที่สุดในการสร้าง data frames ใน Python?
ห้องสมุด Pandas ถือว่าเหมาะสมที่สุดสำหรับการสร้าง data frames เนื่องจากมีฟีเจอร์ต่าง ๆ ที่ทำให้สร้าง data frame ได้อย่างมีประสิทธิภาพ คุณลักษณะเหล่านี้บางส่วนมีดังนี้: Pandas ให้กรอบข้อมูลต่างๆ แก่เรา ซึ่งไม่เพียงแต่ช่วยให้สามารถแสดงข้อมูลได้อย่างมีประสิทธิภาพเท่านั้น แต่ยังช่วยให้เราจัดการได้ มีคุณสมบัติการจัดตำแหน่งและการทำดัชนีที่มีประสิทธิภาพซึ่งให้วิธีการติดฉลากและจัดระเบียบข้อมูลอย่างชาญฉลาด คุณลักษณะบางอย่างของ Pandas ทำให้โค้ดสะอาดและเพิ่มความสามารถในการอ่าน ซึ่งทำให้มีประสิทธิภาพมากขึ้น นอกจากนี้ยังสามารถอ่านไฟล์ได้หลายรูปแบบ JSON, CSV, HDF5 และ Excel เป็นรูปแบบไฟล์บางรูปแบบที่ Pandas รองรับ การรวมชุดข้อมูลหลายชุดเข้าด้วยกันเป็นความท้าทายอย่างแท้จริงสำหรับโปรแกรมเมอร์หลายคน แพนด้าก็เอาชนะสิ่งนี้เช่นกันและรวมชุดข้อมูลหลายชุดเข้าด้วยกันอย่างมีประสิทธิภาพ
ห้องสมุดและเครื่องมืออื่นๆ ที่เสริมห้องสมุด Pandas มีอะไรบ้าง
Pandas ไม่เพียงแต่ทำงานเป็นห้องสมุดกลางสำหรับการสร้างกรอบข้อมูลเท่านั้น แต่ยังทำงานร่วมกับไลบรารี่และเครื่องมืออื่นๆ ของ Python เพื่อให้มีประสิทธิภาพมากขึ้น Pandas สร้างขึ้นบนแพ็คเกจ NumPy Python ซึ่งบ่งชี้ว่าโครงสร้างไลบรารี Pandas ส่วนใหญ่นั้นจำลองจากแพ็คเกจ NumPy การวิเคราะห์ทางสถิติเกี่ยวกับข้อมูลในไลบรารี Pandas ดำเนินการโดย SciPy การพล็อตฟังก์ชันบน Matplotlib และอัลกอริธึมการเรียนรู้ของเครื่องใน Scikit-learn Jupyter Notebook เป็นสภาพแวดล้อมแบบโต้ตอบบนเว็บที่ทำงานเป็น IDE และมีสภาพแวดล้อมที่ดีสำหรับ Pandas
การทำงานของ data frame พื้นฐานคืออะไร?
การเลือกดัชนีหรือคอลัมน์ก่อนเริ่มดำเนินการใดๆ เช่น การเพิ่มหรือการลบเป็นสิ่งสำคัญ เมื่อคุณเรียนรู้วิธีเข้าถึงค่าและเลือกคอลัมน์จาก Data Frame แล้ว คุณสามารถเรียนรู้วิธีเพิ่มดัชนี แถว หรือคอลัมน์ใน Pandas Dataframe หากดัชนีใน data frame ไม่ออกมาตามที่คุณต้องการ คุณสามารถรีเซ็ตได้ สำหรับการรีเซ็ตดัชนี คุณสามารถใช้ฟังก์ชัน “reset_index()”