
CNN กับ RNN: ความแตกต่างระหว่าง CNN และ RNN
เผยแพร่แล้ว: 2021-02-25สารบัญ
บทนำ
ในสาขาปัญญาประดิษฐ์ Neural Networks ที่ได้รับแรงบันดาลใจจากสมองของมนุษย์ถูกนำมาใช้กันอย่างแพร่หลายในการดึงและประมวลผลข้อมูลที่ซับซ้อนจากข้อมูลต่าง ๆ และการใช้ทั้ง Convolutional Neural Networks (CNN) และ Recurrent Neural Networks (RNN) ในการใช้งานดังกล่าว ได้รับการพิสูจน์แล้วว่ามีประโยชน์
ในบทความนี้ เราจะเข้าใจแนวคิดเบื้องหลังทั้ง Convolutional Neural Networks และ Recurrent Neural Networks ดูการใช้งานและแยกแยะความแตกต่างระหว่าง Neural Networks ยอดนิยมทั้งสองประเภท
เรียน รู้การฝึกอบรมแมชชีนเลิร์นนิ่ง จากมหาวิทยาลัยชั้นนำของโลก รับ Masters, Executive PGP หรือ Advanced Certificate Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
โครงข่ายประสาทเทียมและการเรียนรู้เชิงลึก
ก่อนที่เราจะพูดถึงแนวความคิดของ Convolutional Neural Networks และ Recurrent Neural Networks ให้เราเข้าใจแนวคิดเบื้องหลัง Neural Networks และวิธีการเชื่อมโยงกับ Deep Learning เสียก่อน
ในช่วงไม่นานมานี้ Deep Learning เคยเป็นแนวคิดที่ใช้กันอย่างแพร่หลายในหลายสาขา และด้วยเหตุนี้จึงเป็นประเด็นร้อนในทุกวันนี้ แต่อะไรคือเหตุผลที่อยู่เบื้องหลังการพูดถึงเรื่องนี้อย่างกว้างขวาง? เพื่อตอบคำถามนี้ เราจะเรียนรู้เกี่ยวกับแนวคิดของ Neural Networks
กล่าวโดยย่อ Neural Networks เป็นแกนหลักของการเรียนรู้เชิงลึก เป็นชุดจำนวนชั้นที่ประกอบด้วยองค์ประกอบที่เชื่อมต่อถึงกันอย่างสูงที่เรียกว่าเซลล์ประสาท ซึ่งทำการเปลี่ยนแปลงชุดข้อมูล ซึ่งสร้างความเข้าใจในข้อมูลนั้นเอง ซึ่งเราอ้างถึงคำนั้น ลักษณะเด่น

โครงข่ายประสาทเทียมคืออะไร?
แนวคิดแรกที่เราต้องดำเนินการคือ Neural Networks เรารู้ว่าสมองของมนุษย์เป็นหนึ่งในโครงสร้างที่ซับซ้อนที่เคยมีการศึกษามา เนื่องจากความซับซ้อน จึงมีความยากลำบากอย่างมากในการคลี่คลายการทำงานภายในของมัน แต่ในปัจจุบัน มีการดำเนินการวิจัยหลายประเภทเพื่อเปิดเผยความลับของมัน สมองของมนุษย์นี้ทำหน้าที่เป็นแรงบันดาลใจเบื้องหลังแบบจำลองโครงข่ายประสาทเทียม
ตามคำจำกัดความ Neural Networks เป็นหน่วยทำงานของ Deep Learning ซึ่งใช้ Neural Networks เหล่านี้เพื่อเลียนแบบการทำงานของสมองและแก้ปัญหาที่ซับซ้อน เมื่อป้อนข้อมูลเข้าไปยัง Neural Network ข้อมูลนั้นจะถูกประมวลผลผ่านเลเยอร์ของ Perceptron และสุดท้ายจะให้ผลลัพธ์
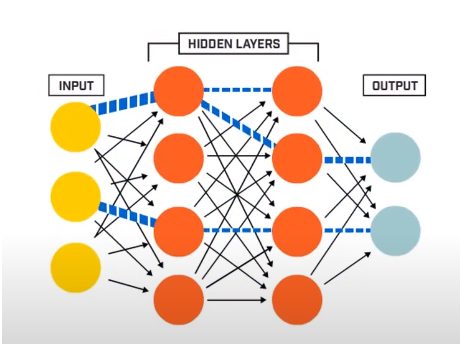
โครงข่ายประสาทเทียมประกอบด้วยโดยทั่วไป 3 ชั้น –
- อินพุตเลเยอร์
- เลเยอร์ที่ซ่อนอยู่
- ชั้นเอาท์พุท
ชั้นอินพุตจะอ่านข้อมูลที่ป้อนเข้าซึ่งป้อนเข้าสู่ระบบโครงข่ายประสาทเทียมเพื่อการประมวลผลล่วงหน้าเพิ่มเติมโดยชั้นเซลล์ประสาทเทียมที่ตามมา เลเยอร์ทั้งหมดที่มีอยู่ระหว่างเลเยอร์อินพุตและเลเยอร์เอาต์พุตเรียกว่าเลเยอร์ที่ซ่อนอยู่
มันอยู่ในเลเยอร์ที่ซ่อนอยู่ซึ่งเซลล์ประสาทที่มีอยู่ในนั้นใช้ประโยชน์จากอินพุตและอคติที่ถ่วงน้ำหนักและสร้างเอาต์พุตโดยใช้ฟังก์ชั่นการเปิดใช้งาน Output Layer เป็นเลเยอร์สุดท้ายของเซลล์ประสาทที่ให้ผลลัพธ์สำหรับโปรแกรมที่กำหนด
แหล่งที่มา
โครงข่ายประสาทเทียมทำงานอย่างไร?
ตอนนี้เรามีแนวคิดเกี่ยวกับโครงสร้างพื้นฐานของ Neural Networks แล้ว เราจะดำเนินการต่อไปและทำความเข้าใจวิธีการทำงานของ Neural Networks เพื่อให้เข้าใจการทำงานของมัน เราต้องเรียนรู้เกี่ยวกับโครงสร้างพื้นฐานอย่างหนึ่งของ Neural Networks ก่อน ซึ่งรู้จักกันในชื่อ Perceptron
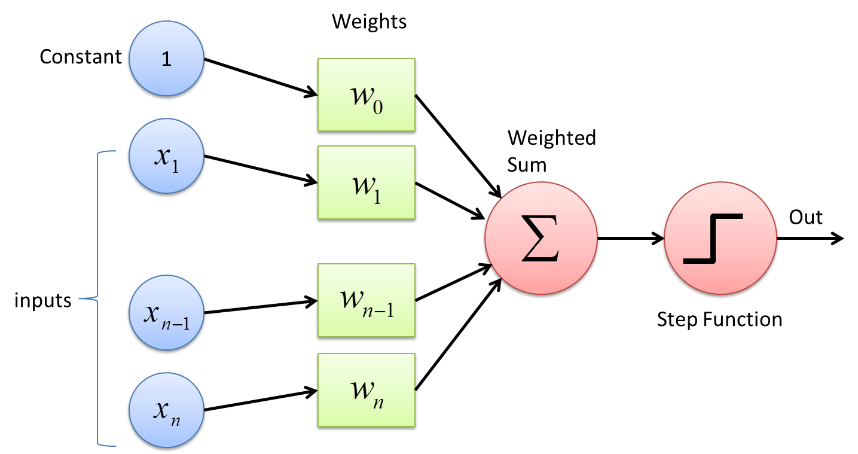
Perceptron เป็นโครงข่ายประสาทชนิดหนึ่งที่มีรูปแบบพื้นฐานที่สุด เป็นโครงข่ายประสาทเทียมแบบ feed-forward แบบธรรมดาที่มีเลเยอร์ที่ซ่อนอยู่เพียงชั้นเดียว ในเครือข่าย Perceptron เซลล์ประสาทแต่ละเซลล์เชื่อมต่อกับเซลล์ประสาทอื่นในทิศทางไปข้างหน้า
การเชื่อมต่อระหว่างเซลล์ประสาทเหล่านี้มีน้ำหนักเนื่องจากข้อมูลที่ถ่ายโอนระหว่างเซลล์ประสาททั้งสองมีความเข้มแข็งหรือลดทอนด้วยน้ำหนักเหล่านี้ ในกระบวนการฝึกอบรมของ Neural Networks จะมีการถ่วงน้ำหนักเหล่านี้เพื่อให้ได้ค่าที่ถูกต้อง
Perceptron ใช้ประโยชน์จากฟังก์ชันตัวแยกประเภทไบนารี ซึ่งแมปเวกเตอร์ของตัวแปรที่มีลักษณะเป็นเลขฐานสองกับเอาต์พุตไบนารีตัวเดียว นอกจากนี้ยังสามารถใช้ในการเรียนรู้ภายใต้การดูแล ขั้นตอนในอัลกอริธึมการเรียนรู้ของ Perceptron คือ -
- คูณอินพุตทั้งหมดด้วยน้ำหนักของ w โดยที่ w เป็นจำนวนจริงที่ตั้งค่าคงที่หรือสุ่มได้ในตอนแรก
- เพิ่มผลิตภัณฑ์เข้าด้วยกันเพื่อให้ได้ผลรวมถ่วงน้ำหนัก ∑ wj xj
- เมื่อได้รับผลรวมถ่วงน้ำหนักของอินพุตแล้ว ฟังก์ชันการเปิดใช้งานจะถูกนำไปใช้เพื่อกำหนดว่าผลรวมถ่วงน้ำหนักนั้นมากกว่าค่าเกณฑ์เฉพาะหรือไม่ขึ้นอยู่กับฟังก์ชันการเปิดใช้งานที่ใช้ เอาต์พุตถูกกำหนดเป็น 1 หรือ 0 ขึ้นอยู่กับเงื่อนไขเกณฑ์ ในที่นี้ค่า "-threshold" ยังหมายถึงคำว่าอคติ b
ด้วยวิธีนี้ อัลกอริธึม Perceptron Learning จึงสามารถใช้เพื่อกระตุ้น (ค่า =1) เซลล์ประสาทที่มีอยู่ใน Neural Networks ที่ได้รับการออกแบบและพัฒนาในปัจจุบัน การนำเสนออัลกอริธึมการเรียนรู้ของ Perceptron อีกประการหนึ่งคือ -
f(x) = 1 ถ้า ∑ wj xj + b ≥ 0
0 ถ้า ∑ wj xj + b < 0
แม้ว่า Perceptrons จะไม่ได้ใช้กันอย่างแพร่หลายในปัจจุบัน แต่ก็ยังคงเป็นหนึ่งในแนวคิดหลักใน Neural Networks ในการวิจัยเพิ่มเติม เป็นที่เข้าใจกันว่าการเปลี่ยนแปลงเล็กน้อยในน้ำหนักหรืออคติในการรับรู้เพียงตัวเดียวสามารถเปลี่ยนผลลัพธ์จาก 1 เป็น 0 อย่างมากมายหรือในทางกลับกัน นี่เป็นข้อเสียเปรียบที่สำคัญอย่างหนึ่งของ Perceptron ดังนั้น ฟังก์ชันการเปิดใช้งานที่ซับซ้อนมากขึ้น เช่น ReLU, ฟังก์ชัน Sigmoid จึงได้รับการพัฒนา ซึ่งนำเสนอการเปลี่ยนแปลงเพียงเล็กน้อยในน้ำหนักและอคติของเซลล์ประสาทเทียม
แหล่งที่มา
โครงข่ายประสาทเทียม
Convolutional Neural Network คืออัลกอริธึมการเรียนรู้เชิงลึกที่รับรูปภาพเป็นอินพุต กำหนดน้ำหนักและความเอนเอียงต่างๆ ให้กับส่วนต่างๆ ของรูปภาพ เพื่อให้สามารถแยกความแตกต่างออกจากกันได้ เมื่อสร้างความแตกต่างได้ การใช้ฟังก์ชันการเปิดใช้งานต่างๆ Convolutional Neural Network Model สามารถทำงานหลายอย่างในโดเมนการประมวลผลภาพ รวมถึงการจดจำภาพ การจัดประเภทภาพ การตรวจจับวัตถุและใบหน้า เป็นต้น
พื้นฐานของ Convolutional Neural Network Model คือรับภาพอินพุต รูปภาพที่ป้อนสามารถติดป้ายกำกับได้ (เช่น แมว สุนัข สิงโต ฯลฯ) หรือไม่มีป้ายกำกับ ทั้งนี้ขึ้นอยู่กับสิ่งนี้ อัลกอริธึมการเรียนรู้เชิงลึกแบ่งออกเป็นสองประเภท ได้แก่ อัลกอริธึมภายใต้การดูแล ซึ่งจะมีป้ายกำกับรูปภาพและอัลกอริธึมที่ไม่ได้ดูแลซึ่งรูปภาพไม่ได้ระบุป้ายกำกับใดโดยเฉพาะ
สำหรับเครื่องคอมพิวเตอร์ รูปภาพที่ป้อนจะถูกมองว่าเป็นอาร์เรย์ของพิกเซล ซึ่งมักจะอยู่ในรูปของเมทริกซ์ รูปภาพส่วนใหญ่จะอยู่ในรูปแบบ hxwxd (โดยที่ h = ความสูง, w = ความกว้าง, d = ขนาด) ตัวอย่างเช่น รูปภาพขนาด 16 x 16 x 3 เมทริกซ์อาร์เรย์หมายถึงรูปภาพ RGB (3 หมายถึงค่า RGB) ในทางกลับกัน รูปภาพของอาร์เรย์เมทริกซ์ขนาด 14 x 14 x 1 แสดงถึงภาพระดับสีเทา
แหล่งที่มา
เลเยอร์ของโครงข่ายประสาทเทียม
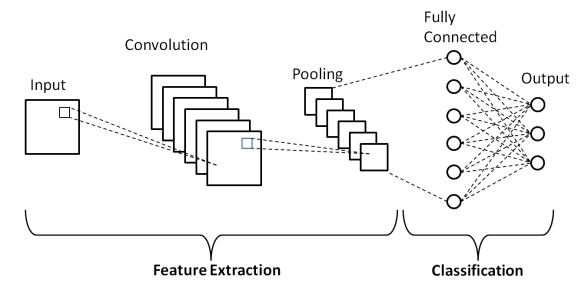
ดังที่แสดงในสถาปัตยกรรมพื้นฐานข้างต้นของ Convolutional Neural Network โมเดล CNN ประกอบด้วยหลายเลเยอร์ซึ่งอิมเมจอินพุตจะผ่านการประมวลผลล่วงหน้าเพื่อให้ได้ผลลัพธ์ โดยพื้นฐานแล้วเลเยอร์เหล่านี้แบ่งออกเป็นสองส่วน -

- สามเลเยอร์แรกรวมถึง Input Layer, Convolution Layer และ Pooling layer ซึ่งทำหน้าที่เป็นเครื่องมือแยกคุณลักษณะเพื่อให้ได้คุณสมบัติระดับฐานจากภาพที่ป้อนเข้าสู่โมเดล
- Fully Connected Layer สุดท้ายและ Output Layer ใช้ประโยชน์จากเอาต์พุตของเลเยอร์การแยกคุณสมบัติและคาดการณ์คลาสสำหรับรูปภาพขึ้นอยู่กับคุณสมบัติที่แยกออกมา
เลเยอร์แรกคือ Input Layer ซึ่งรูปภาพจะถูกป้อนเข้าสู่ Convolutional Neural Network Model ในรูปแบบของอาร์เรย์ของเมทริกซ์ เช่น 32 x 32 x 3 โดยที่ 3 แสดงว่ารูปภาพนั้นเป็นรูปภาพ RGB ที่มีความสูงและความกว้างเท่ากัน ขนาด 32 พิกเซล จากนั้น รูปภาพอินพุตเหล่านี้จะผ่าน Convolutional Layer ซึ่งดำเนินการทางคณิตศาสตร์ของ Convolution
อิมเมจอินพุตถูกรวมเข้าด้วยกันด้วยเมทริกซ์สี่เหลี่ยมจัตุรัสอื่นที่เรียกว่าเคอร์เนลหรือตัวกรอง โดยการเลื่อนเคอร์เนลทีละตัวบนพิกเซลของภาพที่ป้อน เราได้ภาพที่ส่งออกซึ่งเรียกว่าแผนผังคุณลักษณะ ซึ่งให้ข้อมูลเกี่ยวกับคุณลักษณะระดับฐานของภาพ เช่น ขอบและเส้น
Convolutional Layer ตามด้วย เลเยอร์ Pooling ซึ่งมีจุดมุ่งหมายเพื่อลดขนาดของแผนผังคุณลักษณะเพื่อลดต้นทุนในการคำนวณ ทำได้โดยการรวมหลายประเภท เช่น Max Pooling, Average Pooling และ Sum Pooling
เลเยอร์ ที่ เชื่อมต่ออย่างสมบูรณ์ (FC) เป็นเลเยอร์สุดท้ายของ Convolutional Neural Network Model ซึ่งเลเยอร์จะถูกทำให้แบนและป้อนไปยังเลเยอร์ FC ที่นี่ โดยใช้ฟังก์ชันการเปิดใช้งาน เช่น ฟังก์ชัน Sigmoid, ReLU และ tanH การคาดคะเนฉลากจะเกิดขึ้นและแสดงออกมาใน Output Layer สุดท้าย
ที่ CNNs ตกสั้น
ด้วยแอปพลิเคชั่นที่มีประโยชน์มากมายของ Convolutional Neural Network ในข้อมูลภาพด้วยภาพ CNN มีข้อเสียเล็กน้อยเนื่องจากใช้งานไม่ได้กับลำดับของภาพ (วิดีโอ) และล้มเหลวในการตีความข้อมูลชั่วคราวและบล็อกของข้อความ
เพื่อจัดการกับข้อมูลชั่วคราวหรือข้อมูลตามลำดับ เช่น ประโยค เราจำเป็นต้องมีอัลกอริทึมที่เรียนรู้จากข้อมูลในอดีตและข้อมูลในอนาคตในลำดับด้วย โชคดีที่โครงข่ายประสาทที่เกิดซ้ำทำอย่างนั้น
โครงข่ายประสาทกำเริบ
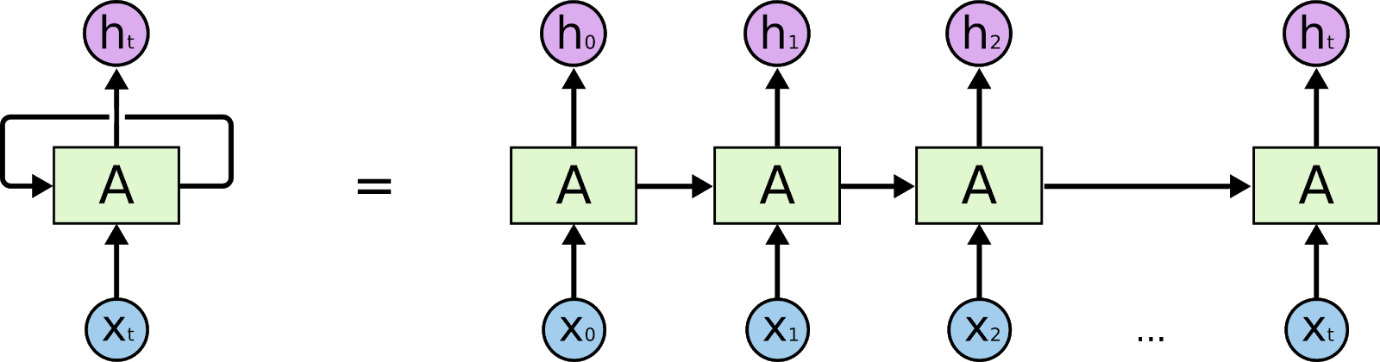
Recurrent Neural Networks คือเครือข่ายที่ออกแบบมาเพื่อตีความข้อมูลชั่วคราวหรือแบบต่อเนื่อง RNN ใช้จุดข้อมูลอื่นๆ ตามลำดับเพื่อคาดการณ์ได้ดีขึ้น โดยทำสิ่งนี้โดยรับอินพุตและนำการเปิดใช้งานโหนดก่อนหน้าหรือโหนดต่อมากลับมาใช้ใหม่ตามลำดับเพื่อให้มีผลกับเอาต์พุต
แหล่งที่มา
เป็นผลมาจากหน่วยความจำภายใน โครงข่ายประสาทเทียมสามารถจดจำรายละเอียดที่สำคัญ เช่น ข้อมูลที่ได้รับ ซึ่งทำให้คาดการณ์ได้อย่างแม่นยำว่าจะเกิดอะไรขึ้นต่อไป ดังนั้นจึงเป็นอัลกอริธึมที่นิยมใช้มากที่สุดสำหรับข้อมูลตามลำดับ เช่น อนุกรมเวลา คำพูด ข้อความ เสียง วิดีโอ และอื่นๆ อีกมากมาย โครงข่ายประสาทที่เกิดซ้ำสามารถสร้างความเข้าใจที่ลึกซึ้งยิ่งขึ้นของลำดับและบริบทของลำดับเมื่อเปรียบเทียบกับอัลกอริทึมอื่นๆ
โครงข่ายประสาทที่เกิดซ้ำทำงานอย่างไร?
พื้นฐานสำหรับการทำความเข้าใจการทำงานบนเครือข่าย Recurrent Neural นั้นเหมือนกับสำหรับเครือข่าย Convolutional Neural ซึ่งเป็น Neural Networks แบบ feed-forward อย่างง่ายหรือที่รู้จักในชื่อ Perceptron นอกจากนี้ ในเครือข่าย Recurrent Neural เอาต์พุตจากขั้นตอนก่อนหน้าจะถูกป้อนเป็นอินพุตไปยังขั้นตอนปัจจุบัน ใน Neural Networks ส่วนใหญ่ เอาต์พุตมักจะไม่ขึ้นกับอินพุตและในทางกลับกัน นี่คือความแตกต่างพื้นฐานระหว่าง RNN และ Neural Networks อื่นๆ
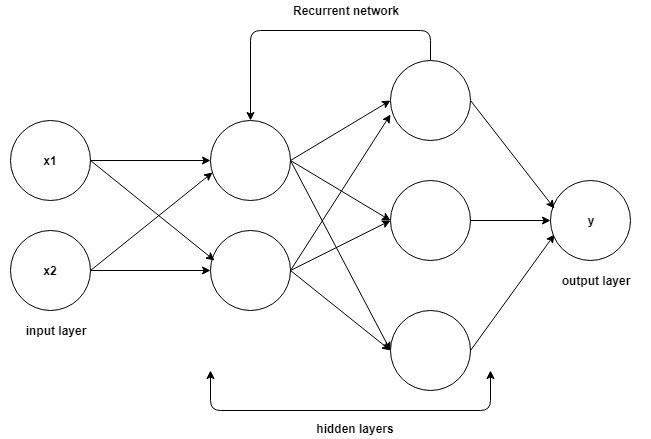
แหล่งที่มา
ดังนั้น RNN จึงมีสองอินพุต: ปัจจุบันและอดีตที่ผ่านมา นี่เป็นสิ่งสำคัญเนื่องจากลำดับของข้อมูลมีข้อมูลสำคัญเกี่ยวกับสิ่งที่กำลังจะเกิดขึ้นต่อไป ซึ่งเป็นสาเหตุที่ RNN สามารถทำสิ่งต่างๆ ที่อัลกอริธึมอื่นไม่สามารถทำได้ คุณลักษณะหลักและสำคัญที่สุดของ Recurrent Neural Networks คือสถานะที่ซ่อนอยู่ ซึ่งจะจดจำข้อมูลบางอย่างเกี่ยวกับลำดับ
Recurrent Neural Networks มีหน่วยความจำที่เก็บข้อมูลทั้งหมดเกี่ยวกับสิ่งที่คำนวณได้ ด้วยการใช้พารามิเตอร์เดียวกันสำหรับอินพุตแต่ละรายการและทำงานเดียวกันบนอินพุตทั้งหมดหรือเลเยอร์ที่ซ่อนอยู่ ความซับซ้อนของพารามิเตอร์จะลดลง
ความแตกต่างระหว่าง CNN และ RNN
| โครงข่ายประสาทเทียม | โครงข่ายประสาทกำเริบ |
| ในการเรียนรู้เชิงลึกนั้น โครงข่ายประสาทเทียม (CNN หรือ ConvNet) เป็นเครือข่ายชั้นลึกของนิวรัล ซึ่งมักใช้ในการวิเคราะห์ภาพ | โครงข่ายประสาทเทียมแบบกำเริบ (RNN) เป็นโครงข่ายประสาทเทียมประเภทหนึ่ง ซึ่งการเชื่อมต่อระหว่างโหนดจะสร้างกราฟกำกับตามลำดับเวลา |
| เหมาะสำหรับข้อมูลเชิงพื้นที่เช่นภาพ | RNN ใช้สำหรับข้อมูลชั่วคราวหรือที่เรียกว่าข้อมูลตามลำดับ |
| CNN เป็นโครงข่ายประสาทเทียมแบบ feed-forward โดยมีรูปแบบต่างๆ ของ perceptron หลายชั้นที่ออกแบบมาเพื่อใช้การประมวลผลล่วงหน้าในปริมาณที่น้อยที่สุด | RNN ซึ่งแตกต่างจากโครงข่ายประสาทเทียมแบบ feed-forward- สามารถใช้หน่วยความจำภายในเพื่อประมวลผลลำดับอินพุตตามอำเภอใจ |
| CNN ถือว่ามีประสิทธิภาพมากกว่า RNN | RNN มีความเข้ากันได้ของฟีเจอร์น้อยกว่าเมื่อเปรียบเทียบกับ CNN |
| CNN นี้รับอินพุตที่มีขนาดคงที่และสร้างเอาต์พุตที่มีขนาดคงที่ | RNN สามารถจัดการความยาวอินพุต/เอาต์พุตได้ตามต้องการ |
| CNN เหมาะอย่างยิ่งสำหรับการประมวลผลภาพและวิดีโอ | RNN เหมาะอย่างยิ่งสำหรับการวิเคราะห์ข้อความและคำพูด |
| แอพพลิเคชั่นรวมถึงการจดจำรูปภาพ การจัดประเภทรูปภาพ การวิเคราะห์ภาพทางการแพทย์ การตรวจจับใบหน้า และคอมพิวเตอร์วิทัศน์ | แอปพลิเคชันต่างๆ ได้แก่ การแปลข้อความ การประมวลผลภาษาธรรมชาติ การแปลภาษา การวิเคราะห์ความรู้สึก และการวิเคราะห์คำพูด |
บทสรุป
ดังนั้น ในบทความนี้เกี่ยวกับความแตกต่างระหว่าง Neural Networks สองประเภทที่ได้รับความนิยมมากที่สุด Convolutional Neural Networks และ Recurrent Neural Networks เราได้เรียนรู้โครงสร้างพื้นฐานของ Neural Network พร้อมกับพื้นฐานของทั้ง CNN และ RNN และในที่สุดก็สรุป เปรียบเทียบสั้น ๆ ระหว่างทั้งสองกับการใช้งานในโลกแห่งความเป็นจริง
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT -B สถานะศิษย์เก่า 5+ โครงการหลักที่ปฏิบัติได้จริง & ความช่วยเหลืองานกับ บริษัท ชั้นนำ
ทำไม CNN ถึงเร็วกว่า RNN
CNN นั้นเร็วกว่า RNN เพราะออกแบบมาเพื่อจัดการรูปภาพ ในขณะที่ RNN ออกแบบมาเพื่อจัดการข้อความ แม้ว่า RNN จะฝึกให้จัดการภาพได้ แต่ก็ยังยากสำหรับ RNN ที่จะแยกคุณลักษณะที่ตัดกันที่อยู่ใกล้กันมากขึ้น ตัวอย่างเช่น หากคุณมีรูปภาพของใบหน้าที่มีตา จมูก และปาก RNNs มีปัญหาในการค้นหาคุณลักษณะที่จะแสดงก่อน CNN ใช้ตารางของจุด และด้วยการใช้อัลกอริธึม พวกเขาสามารถฝึกให้จดจำรูปร่างและรูปแบบได้ CNN ดีกว่า RNN ในการจัดเรียงรูปภาพ เร็วกว่า RNN เพราะคำนวณง่าย และจัดเรียงรูปภาพได้ดีกว่า
RNN ใช้สำหรับอะไร?
โครงข่ายประสาทเทียมแบบเกิดซ้ำ (RNNs) เป็นเครือข่ายประสาทเทียมประเภทหนึ่งซึ่งการเชื่อมต่อระหว่างหน่วยต่างๆ ก่อตัวเป็นวงจรโดยตรง เอาต์พุตของหน่วยหนึ่งจะกลายเป็นอินพุตของอีกหน่วยหนึ่ง เหมือนกับเอาต์พุตของเซลล์ประสาทหนึ่งจะกลายเป็นอินพุตของอีกหน่วยหนึ่ง มีการใช้ RNN อย่างประสบความสำเร็จในการทำงานที่ซับซ้อน เช่น การรู้จำคำพูดและการแปลด้วยคอมพิวเตอร์ ซึ่งยากต่อการดำเนินการด้วยวิธีมาตรฐาน
RNN คืออะไรและแตกต่างจาก Feedforward Neural Networks อย่างไร
Recurrent Neural Networks (RNNs) เป็นเครือข่ายประสาทชนิดหนึ่งที่ใช้สำหรับการประมวลผลข้อมูลตามลำดับ โครงข่ายประสาทเทียมที่เกิดซ้ำประกอบด้วยชั้นอินพุต เลเยอร์ที่ซ่อนอยู่อย่างน้อยหนึ่งเลเยอร์ และเลเยอร์เอาต์พุต เลเยอร์ที่ซ่อนอยู่ได้รับการออกแบบเพื่อเรียนรู้การแทนค่าภายในของข้อมูลที่ป้อนเข้า จากนั้นจึงนำเสนอต่อเลเยอร์เอาต์พุตเพื่อเป็นตัวแทนภายนอก RNN ได้รับการฝึกอบรมด้วยความช่วยเหลือของ backpropagation RNN มักถูกนำมาเปรียบเทียบกับโครงข่ายประสาทฟีดฟอร์เวิร์ด (FNNs) ในขณะที่ทั้ง RNN และ FNN สามารถเรียนรู้การแทนค่าภายในของข้อมูล RNN นั้นสามารถเรียนรู้การพึ่งพาระยะยาว ซึ่ง FNN ไม่สามารถทำได้