
การสร้างบริการตัดไม้จากส่วนกลางภายในองค์กร
เผยแพร่แล้ว: 2022-03-10เราทุกคนทราบดีว่าการดีบักมีความสำคัญเพียงใดในการปรับปรุงประสิทธิภาพและคุณสมบัติของแอปพลิเคชัน BrowserStack รันหนึ่งล้านเซสชันต่อวันบนสแต็กแอปพลิเคชันที่มีการกระจายสูง! แต่ละส่วนเกี่ยวข้องกับส่วนที่เคลื่อนไหวได้หลายส่วน เนื่องจากเซสชันเดียวของลูกค้าสามารถขยายได้หลายองค์ประกอบตามภูมิภาคทางภูมิศาสตร์ต่างๆ
หากไม่มีกรอบงานและเครื่องมือที่เหมาะสม กระบวนการแก้ไขจุดบกพร่องอาจเป็นฝันร้ายได้ ในกรณีของเรา เราต้องการวิธีรวบรวมเหตุการณ์ที่เกิดขึ้นระหว่างขั้นตอนต่างๆ ของแต่ละกระบวนการ เพื่อให้ได้ความเข้าใจอย่างลึกซึ้งเกี่ยวกับทุกสิ่งทุกอย่างที่เกิดขึ้นในระหว่างเซสชัน ด้วยโครงสร้างพื้นฐานของเรา การแก้ปัญหานี้จึงกลายเป็นเรื่องที่ซับซ้อน เนื่องจากแต่ละองค์ประกอบอาจมีหลายเหตุการณ์จากวงจรการประมวลผลคำขอ
นั่นเป็นเหตุผลที่เราพัฒนาเครื่องมือ Central Logging Service (CLS) ของเราเองเพื่อบันทึกเหตุการณ์สำคัญทั้งหมดที่บันทึกไว้ในระหว่างเซสชัน เหตุการณ์เหล่านี้ช่วยให้นักพัฒนาของเราระบุเงื่อนไขที่เกิดข้อผิดพลาดในเซสชันและช่วยติดตามเมตริกผลิตภัณฑ์ที่สำคัญบางอย่าง
ข้อมูลการดีบักมีตั้งแต่สิ่งง่ายๆ เช่น เวลาในการตอบสนองของ API ไปจนถึงการตรวจสอบสถานะเครือข่ายของผู้ใช้ ในบทความนี้ เราแชร์เรื่องราวของเราในการสร้างเครื่องมือ CLS ซึ่งรวบรวมข้อมูลตามลำดับเวลาที่เกี่ยวข้อง 70G ต่อวันจากส่วนประกอบมากกว่า 100 รายการอย่างน่าเชื่อถือ ในระดับต่างๆ และด้วยอินสแตนซ์ M3.large EC2 สองรายการ
การตัดสินใจสร้างภายในองค์กร
อันดับแรก ให้พิจารณาว่าทำไมเราจึงสร้างเครื่องมือ CLS ขึ้นเองภายในแทนที่จะใช้โซลูชันที่มีอยู่ แต่ละเซสชันของเราส่ง 15 เหตุการณ์โดยเฉลี่ย จากหลายองค์ประกอบไปยังบริการ - แปลเป็นกิจกรรมทั้งหมดประมาณ 15 ล้านกิจกรรมต่อวัน
บริการของเราต้องการความสามารถในการจัดเก็บข้อมูลทั้งหมดนี้ เราค้นหาโซลูชันที่สมบูรณ์เพื่อสนับสนุนการจัดเก็บ การส่ง และการสอบถามเหตุการณ์ต่างๆ ขณะที่เราพิจารณาโซลูชันของบริษัทอื่น เช่น Amplitude และ Keen เมตริกการประเมินของเรารวมต้นทุน ประสิทธิภาพในการจัดการคำขอแบบคู่ขนานในระดับสูง และความง่ายในการนำไปใช้ ขออภัย เราไม่พบสิ่งที่ตรงกับความต้องการทั้งหมดของเราภายในงบประมาณ แม้ว่าผลประโยชน์จะรวมถึงการประหยัดเวลาและลดการแจ้งเตือนให้น้อยที่สุด แม้ว่าจะต้องใช้ความพยายามเพิ่มเติม แต่เราตัดสินใจพัฒนาโซลูชันภายในบริษัทเอง

รายละเอียดทางเทคนิค
ในแง่ของการออกแบบสถาปัตยกรรมสำหรับองค์ประกอบของเรา เราได้สรุปข้อกำหนดพื้นฐานดังต่อไปนี้:
- ประสิทธิภาพของไคลเอ็นต์
ไม่กระทบต่อประสิทธิภาพของไคลเอนต์/ส่วนประกอบที่ส่งเหตุการณ์ - มาตราส่วน
สามารถรองรับคำขอจำนวนมากพร้อมกันได้ - ประสิทธิภาพการบริการ
รวดเร็วในการประมวลผลเหตุการณ์ทั้งหมดที่ส่งไป - เจาะลึกข้อมูล
แต่ละเหตุการณ์ที่บันทึกไว้จำเป็นต้องมีข้อมูลเมตาเพื่อให้สามารถระบุส่วนประกอบหรือผู้ใช้ บัญชีหรือข้อความได้โดยไม่ซ้ำกัน และให้ข้อมูลเพิ่มเติมเพื่อช่วยให้นักพัฒนาดีบักได้เร็วขึ้น - อินเทอร์เฟซที่สอบถามได้
นักพัฒนาสามารถสืบค้นเหตุการณ์ทั้งหมดสำหรับเซสชันใดเซสชันหนึ่ง ช่วยดีบักเซสชันเฉพาะ สร้างรายงานความสมบูรณ์ของส่วนประกอบ หรือสร้างสถิติประสิทธิภาพที่สำคัญของระบบของเรา - การรับเลี้ยงบุตรบุญธรรมได้เร็วและง่ายขึ้น
ผสานรวมกับองค์ประกอบที่มีอยู่หรือใหม่ได้อย่างง่ายดายโดยไม่ทำให้ทีมต้องแบกรับภาระและใช้ทรัพยากรของพวกเขา - บำรุงรักษาต่ำ
เราเป็นทีมวิศวกรขนาดเล็ก เราจึงค้นหาวิธีแก้ปัญหาเพื่อลดการแจ้งเตือน!
การสร้างโซลูชัน CLS ของเรา
การตัดสินใจที่ 1: การเลือกอินเทอร์เฟซที่จะเปิดเผย
ในการพัฒนา CLS เห็นได้ชัดว่าเราไม่ต้องการสูญเสียข้อมูลใด ๆ ของเรา แต่เราก็ไม่ต้องการให้ประสิทธิภาพขององค์ประกอบได้รับผลกระทบเช่นกัน ไม่ต้องพูดถึงปัจจัยเพิ่มเติมในการป้องกันไม่ให้ส่วนประกอบที่มีอยู่ซับซ้อนขึ้น เนื่องจากจะทำให้การนำไปใช้และการเปิดตัวโดยรวมล่าช้า ในการพิจารณาอินเทอร์เฟซของเรา เราได้พิจารณาตัวเลือกต่อไปนี้:
- การจัดเก็บเหตุการณ์ใน Redis โลคัลในแต่ละส่วนประกอบ เนื่องจากตัวประมวลผลพื้นหลังพุชไปที่ CLS อย่างไรก็ตาม สิ่งนี้ต้องการการเปลี่ยนแปลงในส่วนประกอบทั้งหมด พร้อมกับการแนะนำ Redis สำหรับส่วนประกอบที่ยังไม่มีอยู่
- ผู้เผยแพร่ - โมเดลสมาชิกที่ Redis อยู่ใกล้กับ CLS ในขณะที่ทุกคนเผยแพร่กิจกรรม เราก็มีปัจจัยของส่วนประกอบที่ทำงานอยู่ทั่วโลกอีกครั้ง ในช่วงเวลาที่มีการจราจรหนาแน่นจะทำให้ส่วนประกอบล่าช้า นอกจากนี้ การเขียนนี้อาจข้ามได้ถึงห้าวินาทีเป็นระยะๆ (เนื่องจากอินเทอร์เน็ตเพียงอย่างเดียว)
- การส่งกิจกรรมผ่าน UDP ซึ่งมีผลกระทบต่อประสิทธิภาพของแอปพลิเคชันน้อยกว่า ในกรณีนี้ข้อมูลจะถูกส่งและลืม แต่ข้อเสียคือข้อมูลสูญหาย
ที่น่าสนใจคือการสูญเสียข้อมูลของเราผ่าน UDP นั้นน้อยกว่า 0.1 เปอร์เซ็นต์ ซึ่งเป็นจำนวนที่ยอมรับได้สำหรับเราในการพิจารณาสร้างบริการดังกล่าว เราสามารถโน้มน้าวทุกทีมว่าการสูญเสียจำนวนนี้คุ้มค่ากับประสิทธิภาพ และเดินหน้าต่อไปเพื่อใช้ประโยชน์จากอินเทอร์เฟซ UDP ที่รับฟังเหตุการณ์ทั้งหมดที่ถูกส่งไป
แม้ว่าผลลัพธ์หนึ่งจะส่งผลเพียงเล็กน้อยต่อประสิทธิภาพของแอปพลิเคชัน แต่เราประสบปัญหาเนื่องจากการรับส่งข้อมูล UDP ไม่อนุญาตจากทุกเครือข่าย ส่วนใหญ่มาจากผู้ใช้ของเรา ทำให้ในบางกรณีเราไม่ได้รับข้อมูลเลย เพื่อเป็นการแก้ปัญหาชั่วคราว เราสนับสนุนการบันทึกเหตุการณ์โดยใช้คำขอ HTTP กิจกรรมทั้งหมดที่มาจากฝั่งผู้ใช้จะถูกส่งผ่าน HTTP ในขณะที่กิจกรรมทั้งหมดที่บันทึกจากคอมโพเนนต์ของเราจะผ่าน UDP
การตัดสินใจที่ 2: Tech Stack (ภาษา กรอบงาน และที่เก็บข้อมูล)
เราคือร้านทับทิม อย่างไรก็ตาม เราไม่แน่ใจว่า Ruby จะเป็นตัวเลือกที่ดีกว่าสำหรับปัญหาเฉพาะของเราหรือไม่ บริการของเราจะต้องจัดการกับคำขอที่เข้ามาจำนวนมาก รวมทั้งดำเนินการเขียนจำนวนมาก ด้วยการล็อก Global Interpreter การบรรลุผลการทำงานแบบมัลติเธรดหรือการทำงานพร้อมกันใน Ruby จะเป็นเรื่องยาก (โปรดอย่าดูถูก - เรารัก Ruby!) ดังนั้นเราจึงต้องการโซลูชันที่จะช่วยให้เราบรรลุถึงภาวะพร้อมกันเช่นนี้
เรายังกระตือรือร้นที่จะประเมินภาษาใหม่ในกลุ่มเทคโนโลยีของเรา และโครงการนี้ดูสมบูรณ์แบบสำหรับการทดลองสิ่งใหม่ๆ นั่นคือตอนที่เราตัดสินใจลอง Golang เพราะมันให้การสนับสนุนในตัวสำหรับเธรดและงานประจำที่มีการทำงานพร้อมกันและน้ำหนักเบา จุดข้อมูลที่บันทึกไว้แต่ละจุดจะคล้ายกับคู่คีย์-ค่า โดยที่ 'คีย์' คือเหตุการณ์ และ 'ค่า' ทำหน้าที่เป็นค่าที่เกี่ยวข้อง
แต่การมีคีย์และค่าที่เรียบง่ายไม่เพียงพอสำหรับการดึงข้อมูลที่เกี่ยวข้องกับเซสชัน - มีข้อมูลเมตามากกว่า เพื่อแก้ไขปัญหานี้ เราตัดสินใจว่าเหตุการณ์ใดๆ ที่จำเป็นต้องบันทึกจะมี ID เซสชันพร้อมกับคีย์และค่าของเหตุการณ์นั้น นอกจากนี้เรายังเพิ่มฟิลด์พิเศษ เช่น การประทับเวลา ID ผู้ใช้ และส่วนประกอบที่บันทึกข้อมูล เพื่อให้ง่ายต่อการดึงและวิเคราะห์ข้อมูล

ตอนนี้เราตัดสินใจเกี่ยวกับโครงสร้างเพย์โหลดแล้ว เราต้องเลือกที่เก็บข้อมูลของเรา เราพิจารณา Elastic Search แล้ว แต่เราต้องการรองรับคำขออัปเดตสำหรับคีย์ด้วย ซึ่งจะทำให้เอกสารทั้งหมดได้รับการจัดทำดัชนีใหม่ ซึ่งอาจส่งผลต่อประสิทธิภาพการเขียนของเรา MongoDB เหมาะสมกว่าในฐานะที่เก็บข้อมูลเนื่องจากจะง่ายกว่าในการสืบค้นเหตุการณ์ทั้งหมดตามฟิลด์ข้อมูลใด ๆ ที่จะเพิ่ม มันง่าย!
การตัดสินใจที่ 3: ขนาดฐานข้อมูลมีขนาดใหญ่ การสืบค้นและการเก็บถาวรแย่มาก!
ในการตัดการบำรุงรักษา บริการของเราจะต้องจัดการกับเหตุการณ์ต่างๆ ให้ได้มากที่สุด จากอัตราที่ BrowserStack ปล่อยฟีเจอร์และผลิตภัณฑ์ เรามั่นใจว่าจำนวนกิจกรรมของเราจะเพิ่มขึ้นในอัตราที่สูงขึ้นเมื่อเวลาผ่านไป ซึ่งหมายความว่าบริการของเราจะต้องทำงานได้ดีต่อไป เมื่อพื้นที่เพิ่มขึ้น การอ่านและเขียนจะใช้เวลามากขึ้น ซึ่งอาจส่งผลกระทบอย่างมากต่อประสิทธิภาพของบริการ
วิธีแก้ปัญหาแรกที่เราสำรวจคือการย้ายบันทึกจากช่วงระยะเวลาหนึ่งออกจากฐานข้อมูล (ในกรณีของเรา เราตัดสินใจเลือกวันที่ 15) ในการทำเช่นนี้ เราได้สร้างฐานข้อมูลที่แตกต่างกันในแต่ละวัน ทำให้เราสามารถค้นหาบันทึกที่เก่ากว่าช่วงเวลาหนึ่งโดยไม่ต้องสแกนเอกสารที่เขียนทั้งหมด ตอนนี้เราลบฐานข้อมูลที่เก่ากว่า 15 วันออกจาก Mongo อย่างต่อเนื่อง ในขณะที่ยังคงสำรองข้อมูลไว้เผื่อไว้ด้วย
ส่วนที่เหลือเพียงส่วนเดียวคืออินเทอร์เฟซสำหรับนักพัฒนาเพื่อค้นหาข้อมูลที่เกี่ยวข้องกับเซสชัน พูดตามตรง นี่เป็นปัญหาที่ง่ายที่สุดในการแก้ไข เรามีอินเทอร์เฟซ HTTP ซึ่งผู้คนสามารถสอบถามเหตุการณ์ที่เกี่ยวข้องกับเซสชันในฐานข้อมูลที่เกี่ยวข้องใน MongoDB สำหรับข้อมูลใดๆ ที่มี ID เซสชันเฉพาะ
สถาปัตยกรรม
มาพูดถึงส่วนประกอบภายในของบริการกันโดยพิจารณาจากประเด็นต่อไปนี้:
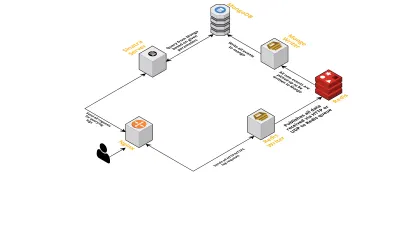
- ตามที่กล่าวไว้ก่อนหน้านี้ เราต้องการอินเทอร์เฟซสองอินเทอร์เฟซ - หนึ่งกำลังฟังผ่าน UDP และอีกอันกำลังฟังผ่าน HTTP ดังนั้นเราจึงสร้างเซิร์ฟเวอร์สองเซิร์ฟเวอร์ อีกครั้งหนึ่งสำหรับแต่ละอินเทอร์เฟซ เพื่อรับฟังเหตุการณ์ ทันทีที่เหตุการณ์มาถึง เราจะแยกวิเคราะห์เพื่อตรวจสอบว่ามีฟิลด์ที่จำเป็นหรือไม่ ซึ่งได้แก่ รหัสเซสชัน คีย์ และค่า หากไม่เป็นเช่นนั้น ข้อมูลจะถูกลบ มิฉะนั้น ข้อมูลจะถูกส่งผ่านช่อง Go ไปยัง goroutine อื่น ซึ่งมีหน้าที่เขียนถึง MongoDB แต่เพียงผู้เดียว
- ข้อกังวลที่เป็นไปได้ที่นี่คือการเขียนถึง MongoDB หากการเขียนไปยัง MongoDB ช้ากว่าที่ได้รับข้อมูลอัตรา จะเป็นการสร้างคอขวด ในทางกลับกัน เหตุการณ์อื่นๆ ที่เข้ามาก็อดตาย และทำให้ข้อมูลลดลง เซิร์ฟเวอร์จึงควรมีความรวดเร็วในการประมวลผลบันทึกขาเข้าและพร้อมที่จะประมวลผลบันทึกที่กำลังจะเกิดขึ้น เพื่อแก้ไขปัญหา เราแยกเซิร์ฟเวอร์ออกเป็นสองส่วน: ส่วนแรกรับเหตุการณ์ทั้งหมดและจัดคิวสำหรับส่วนที่สอง ซึ่งประมวลผลและเขียนลงใน MongoDB
- สำหรับการเข้าคิวเราเลือก Redis ด้วยการแบ่งส่วนประกอบทั้งหมดออกเป็นสองส่วนนี้ เราลดภาระงานของเซิร์ฟเวอร์ ทำให้มีพื้นที่สำหรับจัดการบันทึกได้มากขึ้น
- เราเขียนบริการขนาดเล็กโดยใช้เซิร์ฟเวอร์ Sinatra เพื่อจัดการงานทั้งหมดของการสืบค้น MongoDB ด้วยพารามิเตอร์ที่กำหนด ส่งคืนการตอบสนอง HTML/JSON ให้กับนักพัฒนาเมื่อพวกเขาต้องการข้อมูลเกี่ยวกับเซสชันเฉพาะ
กระบวนการทั้งหมดเหล่านี้ทำงานอย่างมีความสุขบนอินสแตนซ์ m3.large ตัวเดียว
คำขอคุณสมบัติ
เนื่องจากเครื่องมือ CLS ของเรามีการใช้งานมากขึ้นเรื่อยๆ จึงจำเป็นต้องมีคุณลักษณะเพิ่มเติม ด้านล่างนี้ เราจะพูดถึงสิ่งเหล่านี้และวิธีที่เพิ่มเข้ามา
ไม่มีข้อมูลเมตา
เมื่อจำนวนส่วนประกอบใน BrowserStack เพิ่มขึ้นเรื่อย ๆ เราก็เรียกร้องจาก CLS มากขึ้น ตัวอย่างเช่น เราต้องการความสามารถในการบันทึกเหตุการณ์จากส่วนประกอบที่ไม่มี ID เซสชัน มิฉะนั้น การได้มาซึ่งโครงสร้างพื้นฐานของเราจะเป็นภาระ ในรูปแบบของผลกระทบต่อประสิทธิภาพของแอปพลิเคชันและการรับส่งข้อมูลที่เกิดขึ้นบนเซิร์ฟเวอร์หลักของเรา
เราแก้ไขปัญหานี้โดยเปิดใช้งานการบันทึกเหตุการณ์โดยใช้คีย์อื่นๆ เช่น เทอร์มินัลและ ID ผู้ใช้ ตอนนี้เมื่อใดก็ตามที่สร้างหรืออัปเดตเซสชัน CLS จะได้รับแจ้งด้วย ID เซสชัน เช่นเดียวกับผู้ใช้และ ID เทอร์มินัลที่เกี่ยวข้อง มันเก็บแผนที่ที่สามารถเรียกค้นได้โดยขั้นตอนการเขียนไปยัง MongoDB เมื่อใดก็ตามที่มีการดึงข้อมูลเหตุการณ์ที่มี ID ผู้ใช้หรือเทอร์มินัล ID เซสชันจะถูกเพิ่ม
จัดการกับสแปม (ปัญหาโค้ดในส่วนประกอบอื่นๆ)
CLS ยังประสบปัญหาตามปกติในการจัดการเหตุการณ์สแปม เรามักพบว่ามีการปรับใช้ในส่วนประกอบที่สร้างคำขอจำนวนมากที่ส่งไปยัง CLS บันทึกอื่นๆ จะประสบปัญหาในกระบวนการ เนื่องจากเซิร์ฟเวอร์มีงานยุ่งเกินกว่าจะประมวลผลบันทึกเหล่านี้ และบันทึกที่สำคัญหายไป
ข้อมูลส่วนใหญ่ที่บันทึกอยู่ในคำขอ HTTP เพื่อควบคุมพวกเขา เราเปิดใช้งานการจำกัดอัตราการบน nginx (โดยใช้โมดูล limit_req_zone) ซึ่งบล็อกคำขอจาก IP ใด ๆ ที่เราพบว่าส่งคำขอมากกว่าจำนวนที่กำหนดในระยะเวลาอันสั้น แน่นอน เราใช้ประโยชน์จากรายงานสุขภาพของ IP ที่ถูกบล็อกทั้งหมด และแจ้งทีมที่รับผิดชอบ
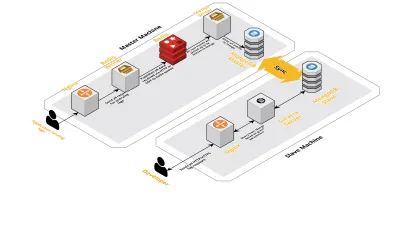
มาตราส่วน v2
เนื่องจากเซสชันของเราต่อวันเพิ่มขึ้น ข้อมูลที่บันทึกไว้ใน CLS ก็เพิ่มขึ้นเช่นกัน สิ่งนี้ส่งผลต่อการสืบค้นที่นักพัฒนาของเราใช้งานทุกวัน และในไม่ช้าคอขวดที่เรามีก็เกิดขึ้นที่ตัวเครื่องเอง การตั้งค่าของเราประกอบด้วยเครื่องหลักสองเครื่องที่ทำงานองค์ประกอบข้างต้นทั้งหมด พร้อมด้วยสคริปต์จำนวนมากเพื่อสืบค้น Mongo และติดตามตัวชี้วัดที่สำคัญสำหรับแต่ละผลิตภัณฑ์ เมื่อเวลาผ่านไป ข้อมูลในเครื่องเพิ่มขึ้นอย่างมาก และสคริปต์เริ่มใช้เวลา CPU เป็นจำนวนมาก แม้หลังจากพยายามเพิ่มประสิทธิภาพการสืบค้น Mongo เราก็กลับมาที่ปัญหาเดิมเสมอ
เพื่อแก้ปัญหานี้ เราได้เพิ่มเครื่องอื่นสำหรับการเรียกใช้สคริปต์รายงานความสมบูรณ์และอินเทอร์เฟซเพื่อสืบค้นเซสชันเหล่านี้ กระบวนการนี้เกี่ยวข้องกับการบูทเครื่องใหม่และตั้งค่าทาสของ Mongo ที่ทำงานบนเครื่องหลัก การดำเนินการนี้ช่วยลดการกระตุกของ CPU ที่เราเห็นทุกวันที่เกิดจากสคริปต์เหล่านี้
บทสรุป
การสร้างบริการสำหรับงานที่ง่ายพอๆ กับการบันทึกข้อมูลอาจซับซ้อน เมื่อปริมาณข้อมูลเพิ่มขึ้น บทความนี้กล่าวถึงโซลูชันที่เราสำรวจ ควบคู่ไปกับความท้าทายที่เผชิญขณะแก้ไขปัญหานี้ เราทดลองกับ Golang เพื่อดูว่ามันจะเข้ากับระบบนิเวศของเราได้ดีเพียงใด และจนถึงตอนนี้เราก็พอใจแล้ว ทางเลือกของเราในการสร้างบริการภายในแทนที่จะจ่ายสำหรับบริการภายนอกนั้นคุ้มค่าคุ้มราคา เรายังไม่ต้องปรับขนาดการตั้งค่าของเราไปยังอีกเครื่องหนึ่งจนกว่าจะถึงเวลานั้นอีกมาก - เมื่อปริมาณของเซสชันของเราเพิ่มขึ้น แน่นอนว่าทางเลือกของเราในการพัฒนา CLS นั้นขึ้นอยู่กับข้อกำหนดและลำดับความสำคัญของเราทั้งหมด
วันนี้ CLS จัดการเหตุการณ์ได้มากถึง 15 ล้านเหตุการณ์ทุกวัน ซึ่งประกอบด้วยข้อมูลมากถึง 70 GB ข้อมูลนี้กำลังถูกใช้เพื่อช่วยเราแก้ปัญหาใดๆ ที่ลูกค้าของเราเผชิญในระหว่างเซสชันใดๆ เรายังใช้ข้อมูลนี้เพื่อวัตถุประสงค์อื่น ด้วยข้อมูลเชิงลึกของแต่ละเซสชันเกี่ยวกับผลิตภัณฑ์และส่วนประกอบภายในที่แตกต่างกัน เราจึงเริ่มใช้ประโยชน์จากข้อมูลนี้เพื่อติดตามผลิตภัณฑ์แต่ละรายการ ซึ่งทำได้โดยแยกเมตริกหลักสำหรับส่วนประกอบที่สำคัญทั้งหมด
โดยรวมแล้ว เราประสบความสำเร็จอย่างมากในการสร้างเครื่องมือ CLS ของเราเอง ถ้ามันสมเหตุสมผลสำหรับคุณ เราขอแนะนำให้คุณลองทำแบบเดียวกัน!