
วิธีสร้างเครื่องขูดผลิตภัณฑ์ Amazon ด้วย Node.js
เผยแพร่แล้ว: 2022-03-10คุณเคยอยู่ในตำแหน่งที่คุณจำเป็นต้องรู้ตลาดสำหรับผลิตภัณฑ์ใดผลิตภัณฑ์หนึ่งอย่างใกล้ชิดหรือไม่? บางทีคุณอาจกำลังเปิดตัวซอฟต์แวร์บางตัวและต้องการทราบราคา หรือบางทีคุณอาจมีผลิตภัณฑ์ของตัวเองอยู่ในตลาดแล้วและต้องการดูคุณสมบัติที่จะเพิ่มเพื่อความได้เปรียบในการแข่งขัน หรือบางทีคุณแค่ต้องการซื้อบางอย่างให้ตัวเองและต้องการให้แน่ใจว่าคุณได้ผลตอบแทนดีที่สุดจากเงินที่จ่ายไป
สถานการณ์ทั้งหมดนี้มีสิ่งหนึ่งที่เหมือนกัน: คุณต้องการข้อมูลที่ถูกต้องเพื่อการตัดสินใจที่ถูกต้อง อันที่จริงมีอีกสิ่งหนึ่งที่พวกเขาแบ่งปัน ทุกสถานการณ์สามารถได้รับประโยชน์จากการใช้เว็บสแครปเปอร์
การขูดเว็บเป็นแนวทางปฏิบัติในการดึงข้อมูลเว็บจำนวนมากผ่านการใช้ซอฟต์แวร์ โดยพื้นฐานแล้วมันเป็นวิธีที่จะทำให้กระบวนการที่น่าเบื่อของการกดปุ่ม 'คัดลอก' และ 'วาง' 200 ครั้งเป็นไปโดยอัตโนมัติ แน่นอน บอทสามารถทำได้ในเวลาที่คุณอ่านประโยคนี้ จึงไม่เพียงแค่น่าเบื่อน้อยลงเท่านั้น แต่ยังเร็วกว่ามากอีกด้วย
แต่คำถามที่เผาไหม้คือ: ทำไมบางคนถึงต้องการขูดหน้า Amazon?
คุณกำลังจะค้นพบ! แต่ก่อนอื่น ฉันต้องการชี้แจงให้กระจ่างในตอนนี้ แม้ว่าการขูดข้อมูลที่เปิดเผยต่อสาธารณะนั้นถูกกฎหมาย แต่ Amazon ก็มีมาตรการบางอย่างที่จะป้องกันไม่ให้มีข้อมูลดังกล่าวบนหน้าเว็บของพวกเขา ดังนั้น เราขอแนะนำให้คุณคำนึงถึงเว็บไซต์ในขณะที่ทำการขูด ระวังอย่าให้เกิดความเสียหาย และปฏิบัติตามหลักเกณฑ์ด้านจริยธรรม
การอ่านที่แนะนำ : “คำแนะนำในการขูดเว็บไซต์แบบไดนามิกด้วย Node.js และ Puppeteer” โดย Andreas Altheimer
ทำไมคุณควรแยกข้อมูลผลิตภัณฑ์ Amazon
ในฐานะผู้ค้าปลีกออนไลน์ที่ใหญ่ที่สุดในโลก พูดได้เลยว่าหากคุณต้องการซื้ออะไรซักอย่าง คุณสามารถซื้อได้ใน Amazon ดังนั้นจึงเป็นไปโดยไม่ได้บอกว่าเว็บไซต์มีคลังข้อมูลขนาดใหญ่เพียงใด
เมื่อขูดเว็บ คำถามหลักของคุณควรจะทำอย่างไรกับข้อมูลทั้งหมดนั้น แม้ว่าจะมีสาเหตุหลายประการ แต่ก็รวมเอากรณีการใช้งานที่โดดเด่นสองกรณี: เพิ่มประสิทธิภาพผลิตภัณฑ์ของคุณและค้นหาข้อเสนอที่ดีที่สุด
“
เริ่มจากสถานการณ์แรกกัน เว้นแต่คุณจะออกแบบผลิตภัณฑ์ใหม่ที่เป็นนวัตกรรมอย่างแท้จริง มีโอกาสที่คุณจะพบบางสิ่งที่คล้ายคลึงกันใน Amazon เป็นอย่างน้อย การขูดหน้าผลิตภัณฑ์เหล่านั้นสามารถทำให้คุณมีข้อมูลอันล้ำค่าเช่น:
- กลยุทธ์การกำหนดราคาของคู่แข่ง
เพื่อให้คุณสามารถปรับราคาให้แข่งขันได้และทำความเข้าใจว่าผู้อื่นจัดการกับข้อเสนอส่งเสริมการขายอย่างไร - ความคิดเห็นของลูกค้า
เพื่อดูว่าฐานลูกค้าในอนาคตของคุณให้ความสำคัญกับอะไรมากที่สุดและจะปรับปรุงประสบการณ์ของพวกเขาอย่างไร - คุณสมบัติที่พบบ่อยที่สุด
เพื่อดูว่าคู่แข่งของคุณนำเสนออะไรเพื่อให้รู้ว่าฟังก์ชันใดมีความสำคัญและสามารถเก็บไว้ใช้ในภายหลังได้
โดยพื้นฐานแล้ว Amazon มีทุกสิ่งที่คุณต้องการสำหรับตลาดเชิงลึกและการวิเคราะห์ผลิตภัณฑ์ คุณจะพร้อมมากขึ้นในการออกแบบ เปิดตัว และขยายกลุ่มผลิตภัณฑ์ของคุณด้วยข้อมูลนั้น
สถานการณ์ที่สองใช้ได้กับทั้งธุรกิจและบุคคลทั่วไป แนวคิดนี้ค่อนข้างคล้ายกับที่ฉันพูดถึงก่อนหน้านี้ คุณสามารถขูดราคา คุณลักษณะ และบทวิจารณ์ของผลิตภัณฑ์ทั้งหมดที่คุณสามารถเลือกได้ ดังนั้น คุณจะสามารถเลือกผลิตภัณฑ์ที่ให้ประโยชน์สูงสุดในราคาต่ำสุดได้ ท้ายที่สุดใครไม่ชอบการจัดการที่ดี?
ไม่ใช่ผลิตภัณฑ์ทุกชนิดที่สมควรได้รับความใส่ใจในรายละเอียดในระดับนี้ แต่สามารถสร้างความแตกต่างอย่างมากเมื่อซื้อสินค้าราคาแพง น่าเสียดายที่ผลประโยชน์นั้นชัดเจน แต่ปัญหามากมายก็เกิดขึ้นควบคู่ไปกับการทำลายอเมซอน
ความท้าทายในการขูดข้อมูลผลิตภัณฑ์ของ Amazon
ไม่ใช่ทุกเว็บไซต์จะเหมือนกัน ตามหลักการแล้ว ยิ่งเว็บไซต์มีความซับซ้อนและแพร่หลายมากเท่าไหร่ ก็ยิ่งขูดได้ยากเท่านั้น จำได้ไหมว่าฉันบอกว่า Amazon เป็นไซต์อีคอมเมิร์ซที่โดดเด่นที่สุด? นั่นทำให้มันเป็นที่นิยมอย่างมากและซับซ้อนพอสมควร
ก่อนอื่น Amazon รู้ดีว่าการขูดบอททำงานอย่างไร ดังนั้นเว็บไซต์จึงมีมาตรการรับมือ กล่าวคือ หากมีดโกนเป็นไปตามรูปแบบที่คาดการณ์ได้ ส่งคำขอในช่วงเวลาที่แน่นอน เร็วกว่าที่มนุษย์จะทำได้หรือด้วยพารามิเตอร์ที่เกือบจะเหมือนกัน Amazon จะสังเกตและบล็อก IP พร็อกซีสามารถแก้ปัญหานี้ได้ แต่ฉันไม่ต้องการมัน เนื่องจากเราจะไม่ดึงหน้ามากเกินไปในตัวอย่าง
ขั้นต่อไป Amazon จงใจใช้โครงสร้างหน้าที่แตกต่างกันสำหรับผลิตภัณฑ์ของตน กล่าวคือ หากคุณตรวจสอบหน้าเว็บสำหรับผลิตภัณฑ์ต่างๆ มีโอกาสสูงที่คุณจะพบความแตกต่างที่มีนัยสำคัญในโครงสร้างและคุณลักษณะของผลิตภัณฑ์ เหตุผลเบื้องหลังนี้ค่อนข้างง่าย คุณต้อง ปรับโค้ดของสแครปเปอร์ของคุณสำหรับระบบเฉพาะ และหากคุณใช้สคริปต์เดียวกันบนหน้าประเภทใหม่ คุณจะต้องเขียนบางส่วนของมันใหม่ ดังนั้นมันจึงทำให้คุณทำงานมากขึ้นสำหรับข้อมูล
สุดท้าย Amazon เป็นเว็บไซต์ขนาดใหญ่ หากคุณต้องการรวบรวมข้อมูลจำนวนมาก การเรียกใช้ซอฟต์แวร์การดึงข้อมูลบนคอมพิวเตอร์ของคุณอาจทำให้ต้องใช้เวลามากเกินไปสำหรับความต้องการของคุณ ปัญหานี้ถูกรวมเข้าด้วยกันโดยข้อเท็จจริงที่ว่าการไปเร็วเกินไปจะทำให้มีดโกนของคุณถูกบล็อก ดังนั้น หากคุณต้องการข้อมูลจำนวนมากอย่างรวดเร็ว คุณจะต้องมีมีดโกนที่ทรงพลังอย่างแท้จริง
ก็พอคุยเรื่องปัญหา มาโฟกัสที่วิธีแก้ปัญหากัน!
วิธีสร้าง Web Scraper สำหรับ Amazon
เพื่อให้ง่ายขึ้น เราจะใช้วิธีการทีละขั้นตอนในการเขียนโค้ด รู้สึกอิสระที่จะทำงานควบคู่ไปกับคำแนะนำ
ค้นหาข้อมูลที่เราต้องการ
นี่คือสถานการณ์: อีกไม่กี่เดือนฉันจะย้ายไปอยู่ที่ใหม่ และฉันต้องการชั้นวางใหม่สองสามชั้นเพื่อเก็บหนังสือและนิตยสาร ฉันต้องการทราบตัวเลือกทั้งหมดของฉันและรับข้อเสนอที่ดีที่สุด ไปที่ตลาด Amazon ค้นหา "ชั้นวาง" และดูสิ่งที่เราได้รับ
URL สำหรับการค้นหานี้และหน้าที่เราจะคัดลอกอยู่ที่นี่
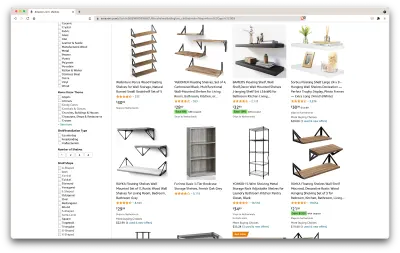
ตกลง มาดูสิ่งที่เรามีที่นี่กัน เพียงแค่เหลือบมองที่หน้า เราก็ได้ภาพที่ดีเกี่ยวกับ:
- ชั้นวางมีลักษณะอย่างไร
- สิ่งที่รวมอยู่ในแพ็คเกจ;
- วิธีที่ลูกค้าให้คะแนนพวกเขา
- ราคาของพวกเขา;
- ลิงค์ไปยังผลิตภัณฑ์
- ข้อเสนอแนะสำหรับทางเลือกที่ถูกกว่าสำหรับบางรายการ
นั่นเป็นมากกว่าที่เราจะขอได้!
รับเครื่องมือที่จำเป็น
ตรวจสอบให้แน่ใจว่าเราได้ติดตั้งและกำหนดค่าเครื่องมือต่อไปนี้ทั้งหมดก่อนที่จะดำเนินการในขั้นตอนต่อไป
- โครเมียม
เราสามารถดาวน์โหลดได้จากที่นี่ - VSCode
ทำตามคำแนะนำในหน้านี้เพื่อติดตั้งบนอุปกรณ์เฉพาะของคุณ - Node.js
ก่อนเริ่มใช้ Axios หรือ Cheerio เราจำเป็นต้องติดตั้ง Node.js และ Node Package Manager วิธีที่ง่ายที่สุดในการติดตั้ง Node.js และ NPM คือการรับตัวติดตั้งตัวใดตัวหนึ่งจากแหล่งที่เป็นทางการของ Node.Js และเรียกใช้งาน
ตอนนี้ มาสร้างโปรเจ็กต์ NPM ใหม่กัน สร้างโฟลเดอร์ใหม่สำหรับโครงการและเรียกใช้คำสั่งต่อไปนี้:
npm init -yในการสร้าง Web Scraper เราจำเป็นต้องติดตั้งการพึ่งพาในโครงการของเรา:
- ไชโย
ไลบรารีโอเพนซอร์สที่ช่วยให้เราดึงข้อมูลที่เป็นประโยชน์โดยแยกวิเคราะห์มาร์กอัปและจัดเตรียม API สำหรับจัดการข้อมูลผลลัพธ์ Cheerio อนุญาตให้เราเลือกแท็กของเอกสาร HTML โดยใช้ตัวเลือก:$("div")ตัวเลือกเฉพาะนี้ช่วยให้เราเลือกองค์ประกอบ<div>ทั้งหมดบนหน้าเว็บ ในการติดตั้ง Cheerio โปรดเรียกใช้คำสั่งต่อไปนี้ในโฟลเดอร์ของโปรเจ็กต์:
npm install cheerio- Axios
ไลบรารี JavaScript ที่ใช้ในการส่งคำขอ HTTP จาก Node.js
npm install axiosตรวจสอบแหล่งที่มาของหน้า
ในขั้นตอนต่อไปนี้ เราจะเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการจัดระเบียบข้อมูลในหน้า แนวคิดคือการทำความเข้าใจสิ่งที่เราสามารถขูดจากแหล่งที่มาของเราได้ดีขึ้น
เครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ช่วยให้เราสำรวจ Document Object Model (DOM) ของเว็บไซต์แบบโต้ตอบได้ เราจะใช้เครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ใน Chrome แต่คุณสามารถใช้เว็บเบราว์เซอร์ใดก็ได้ที่คุณสะดวก
มาเปิดโดยคลิกขวาที่ใดก็ได้บนหน้าแล้วเลือกตัวเลือก "ตรวจสอบ":
ซึ่งจะเป็นการเปิดหน้าต่างใหม่ที่มีซอร์สโค้ดของหน้า ดังที่เราได้กล่าวไว้ก่อนหน้านี้ เรากำลังมองหาการขูดข้อมูลทุกชั้นวาง
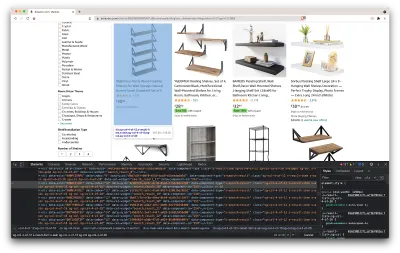
ดังที่เราเห็นได้จากภาพหน้าจอด้านบน คอนเทนเนอร์ที่เก็บข้อมูลทั้งหมดมีคลาสต่อไปนี้:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20ในขั้นตอนต่อไป เราจะใช้ Cheerio เพื่อเลือกองค์ประกอบทั้งหมดที่มีข้อมูลที่เราต้องการ

ดึงข้อมูล
หลังจากที่เราติดตั้งการพึ่งพาทั้งหมดที่แสดงด้านบนแล้ว ให้สร้างไฟล์ index.js ใหม่และพิมพ์โค้ดต่อไปนี้:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); ดังที่เราเห็น เรานำเข้าการขึ้นต่อกันที่เราต้องการในสองบรรทัดแรก จากนั้นเราสร้าง fetchShelves() ที่ใช้ Cheerio รับองค์ประกอบทั้งหมดที่มีข้อมูลผลิตภัณฑ์ของเราจากหน้าเว็บ
มันวนซ้ำแต่ละรายการและผลักไปยังอาร์เรย์ว่างเพื่อให้ได้ผลลัพธ์ที่มีรูปแบบที่ดีขึ้น
fetchShelves() จะส่งคืนเฉพาะชื่อผลิตภัณฑ์ในขณะนี้ ดังนั้น มาดูข้อมูลที่เหลือที่เราต้องการกัน โปรดเพิ่มบรรทัดของรหัสต่อไปนี้หลังบรรทัดที่เรากำหนด title ตัวแปร
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } และแทนที่ shelves.push(title) ด้วย shelves.push(element)
ตอนนี้เรากำลังเลือกข้อมูลทั้งหมดที่เราต้องการและเพิ่มลงในวัตถุใหม่ที่เรียกว่า element จากนั้นทุกองค์ประกอบจะถูกผลักไปที่อาร์เรย์ shelves เพื่อรับรายการของอ็อบเจ็กต์ที่มีเพียงข้อมูลที่เรากำลังมองหา
นี่คือลักษณะของวัตถุ shelf ก่อนที่จะเพิ่มลงในรายการของเรา:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }จัดรูปแบบข้อมูล
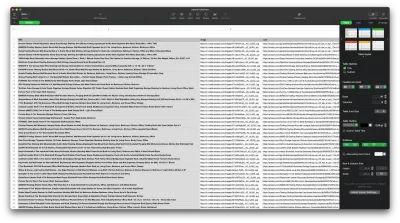
ตอนนี้เราได้ดึงข้อมูลที่เราต้องการแล้ว ขอแนะนำให้บันทึกเป็นไฟล์ .CSV เพื่อปรับปรุงความสามารถในการอ่าน หลังจากได้รับข้อมูลทั้งหมดแล้ว เราจะใช้โมดูล fs ที่ Node.js จัดเตรียมไว้ให้และบันทึกไฟล์ใหม่ชื่อ saved-shelves.csv ลงในโฟลเดอร์ของโปรเจ็กต์ นำเข้าโมดูล fs ที่ด้านบนของไฟล์และคัดลอกหรือเขียนตามบรรทัดของรหัสต่อไปนี้:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) ดังที่เราเห็น ในสามบรรทัดแรก เราจัดรูปแบบข้อมูลที่เราได้รวบรวมไว้ก่อนหน้านี้โดยการรวมค่าทั้งหมดของออบเจกต์ชั้นวางโดยใช้เครื่องหมายจุลภาค จากนั้น เมื่อใช้โมดูล fs เราจะสร้างไฟล์ที่ชื่อ saved-shelves.csv เพิ่มแถวใหม่ที่มีส่วนหัวของคอลัมน์ เพิ่มข้อมูลที่เราเพิ่งจัดรูปแบบ และสร้างฟังก์ชันเรียกกลับที่จัดการข้อผิดพลาด
ผลลัพธ์ควรมีลักษณะดังนี้:
เคล็ดลับโบนัส!
ขูดแอปพลิเคชั่นหน้าเดียว
เนื้อหาแบบไดนามิกกลายเป็นมาตรฐานในปัจจุบัน เนื่องจากเว็บไซต์มีความซับซ้อนมากกว่าที่เคยเป็นมา เพื่อให้ผู้ใช้ได้รับประสบการณ์ที่ดีที่สุด นักพัฒนาซอฟต์แวร์ต้องใช้กลไกการโหลดที่แตกต่างกันสำหรับเนื้อหาแบบไดนามิก ทำให้งานของเราซับซ้อนขึ้นเล็กน้อย หากคุณไม่ทราบว่าหมายความว่าอย่างไร ลองนึกภาพเบราว์เซอร์ที่ไม่มีส่วนต่อประสานกราฟิกกับผู้ใช้ โชคดีที่มี Puppeteer — ไลบรารี Node มหัศจรรย์ที่มี API ระดับสูงเพื่อควบคุมอินสแตนซ์ของ Chrome ผ่านโปรโตคอล DevTools ถึงกระนั้น มันมีฟังก์ชันการทำงานเหมือนกับเบราว์เซอร์ แต่ต้องควบคุมโดยทางโปรแกรมโดยการพิมพ์โค้ดสองสามบรรทัด เรามาดูกันว่ามันทำงานอย่างไร
ในโปรเจ็กต์ที่สร้างไว้ก่อนหน้านี้ ติดตั้งไลบรารี Puppeteer โดยรัน npm install puppeteer สร้างไฟล์ puppeteer.js ใหม่ และคัดลอกหรือเขียนตามบรรทัดของโค้ดต่อไปนี้:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() ในตัวอย่างข้างต้น เราสร้างอินสแตนซ์ของ Chrome และเปิดหน้าเบราว์เซอร์ใหม่ที่จำเป็นสำหรับไปที่ลิงก์นี้ ในบรรทัดต่อไปนี้ เราบอกเบราว์เซอร์หัวขาดให้รอจนกว่าองค์ประกอบที่มีคลาส rpBJOHq2PR60pnwJlUyP0 จะปรากฏบนหน้า เราได้ระบุ ด้วยว่าเบราว์เซอร์ควรรอให้โหลดหน้าเว็บนานเท่าใด (2000 มิลลิวินาที)
โดยใช้วิธีการ evaluate บนตัวแปร page เราสั่งให้ Puppeteer เรียกใช้งานตัวอย่าง Javascript ภายในบริบทของหน้าหลังจากโหลดองค์ประกอบในที่สุด ซึ่งจะทำให้เราสามารถเข้าถึงเนื้อหา HTML ของหน้าและส่งคืนเนื้อหาของหน้าเป็นผลลัพธ์ จากนั้นเราจะปิดอินสแตนซ์ของ Chrome โดยเรียกใช้เมธอด close บนตัวแปร chrome ผลงานที่ได้ควรประกอบด้วยโค้ด HTML ที่สร้างขึ้นแบบไดนามิกทั้งหมด นี่คือวิธีที่ Puppeteer สามารถช่วยเรา โหลดเนื้อหา HTML แบบไดนามิก ได้
หากคุณรู้สึกไม่สะดวกใจที่จะใช้ Puppeteer โปรดทราบว่ามีทางเลือกอยู่สองสามทาง เช่น NightwatchJS, NightmareJS หรือ CasperJS พวกเขาแตกต่างกันเล็กน้อย แต่ในท้ายที่สุด กระบวนการนี้ค่อนข้างคล้ายกัน
การตั้งค่าส่วนหัว user-agent
user-agent เป็นส่วนหัวของคำขอที่บอกเว็บไซต์ที่คุณกำลังเยี่ยมชมเกี่ยวกับตัวคุณเอง ได้แก่ เบราว์เซอร์และระบบปฏิบัติการของคุณ ข้อมูลนี้ใช้เพื่อเพิ่มประสิทธิภาพเนื้อหาสำหรับการตั้งค่าของคุณ แต่เว็บไซต์ยังใช้เพื่อระบุบอทที่ส่งคำขอจำนวนมาก แม้ว่าจะเปลี่ยน IPS ก็ตาม
ส่วนหัวของ user-agent มีลักษณะดังนี้:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36เพื่อไม่ให้ถูกตรวจจับและบล็อก คุณควรเปลี่ยนส่วนหัวนี้เป็นประจำ ระมัดระวังเป็นพิเศษที่จะไม่ส่งส่วนหัวที่ว่างเปล่าหรือล้าสมัย เนื่องจากสิ่งนี้ไม่ควรเกิดขึ้นกับผู้ใช้ที่ใช้งานจริง และคุณจะโดดเด่น
การจำกัดอัตรา
เว็บแครปเปอร์สามารถรวบรวมเนื้อหาได้เร็วมาก แต่คุณควรหลีกเลี่ยงการใช้ความเร็วสูงสุด มีสองเหตุผลสำหรับสิ่งนี้:
- คำขอมากเกินไป ในระยะเวลาอันสั้นอาจทำให้เซิร์ฟเวอร์ของเว็บไซต์ช้าลงหรือแม้กระทั่งทำให้เซิร์ฟเวอร์หยุดทำงาน ทำให้เกิดปัญหากับเจ้าของและผู้เยี่ยมชมคนอื่นๆ มันสามารถกลายเป็นการโจมตี DoS ได้
- หากไม่มีการหมุนพร็อกซี ก็เหมือนกับการประกาศเสียงดังว่า คุณกำลังใช้บอท เนื่องจากไม่มีมนุษย์คนใดส่งคำขอหลายร้อยหรือพันรายการต่อวินาที
วิธีแก้ปัญหาคือการทำให้เกิดความล่าช้าระหว่างคำขอของคุณ วิธีปฏิบัติที่เรียกว่า "การจำกัดอัตรา" ( มันค่อนข้างง่ายที่จะนำไปใช้เช่นกัน! )
ในตัวอย่าง Puppeteer ที่ให้ไว้ข้างต้น ก่อนที่จะสร้างตัวแปร body เราสามารถใช้เมธอด waitForTimeout ที่ Puppeteer จัดเตรียมไว้ให้เพื่อรอสองสามวินาทีก่อนที่จะทำการร้องขอใหม่:
await page.waitForTimeout(3000); โดยที่ ms คือจำนวนวินาทีที่คุณต้องการรอ
นอกจากนี้ หากเราต้องการทำสิ่งเดียวกันสำหรับตัวอย่าง axios เราสามารถสร้างสัญญาที่เรียกใช้เมธอด setTimeout() เพื่อช่วยให้เรารอจำนวนมิลลิวินาทีที่ต้องการได้:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))ด้วยวิธีนี้ คุณสามารถหลีกเลี่ยงการกดดันเซิร์ฟเวอร์เป้าหมายมากเกินไป และยังนำแนวทางที่เป็นมนุษย์มาใช้ในการขูดเว็บด้วย
ปิดความคิด
และนั่นคือคำแนะนำทีละขั้นตอนในการสร้างเว็บมีดโกนของคุณเองสำหรับข้อมูลผลิตภัณฑ์ของ Amazon! แต่จำไว้ว่านี่เป็นเพียงสถานการณ์เดียวเท่านั้น หากคุณต้องการขูดเว็บไซต์อื่น คุณจะต้องปรับแต่งเล็กน้อยเพื่อให้ได้ผลลัพธ์ที่มีความหมาย
การอ่านที่เกี่ยวข้อง
หากคุณยังคงต้องการดูการใช้งานการขูดเว็บเพิ่มเติม ต่อไปนี้คือเอกสารการอ่านที่มีประโยชน์สำหรับคุณ:
- “คู่มือขั้นสูงสำหรับการขูดเว็บด้วย JavaScript และ Node.Js” Robert Sfichi
- “Advanced Node.JS Web Scraping ด้วย Puppeteer” Gabriel Cioci
- “Python Web Scraping: คู่มือขั้นสูงสุดในการสร้างเครื่องขูดของคุณ” Raluca Penciuc