
สร้างแอปพลิเคชันบุ๊กมาร์กด้วย FaunaDB, Netlify และ 11ty
เผยแพร่แล้ว: 2022-03-10การปฏิวัติ JAMstack (JavaScript, APIs และ Markup) กำลังดำเนินการอย่างเต็มที่ ไซต์แบบคงที่มีความปลอดภัย รวดเร็ว เชื่อถือได้ และสนุกในการทำงาน หัวใจของ JAMstack คือเครื่องมือสร้างไซต์สแตติก (SSG) ที่จัดเก็บข้อมูลของคุณเป็นไฟล์แฟล็ต: Markdown, YAML, JSON, HTML และอื่นๆ บางครั้ง การจัดการข้อมูลด้วยวิธีนี้อาจซับซ้อนเกินไป บางครั้งเรายังต้องการฐานข้อมูล
ด้วยเหตุนี้ Netlify ซึ่งเป็นโฮสต์ของไซต์แบบสแตติกและ FaunaDB ซึ่งเป็นฐานข้อมูลบนระบบคลาวด์แบบไร้เซิร์ฟเวอร์จึงทำงานร่วมกันเพื่อทำให้การรวมทั้งสองระบบทำได้ง่ายขึ้น
ทำไมต้องเป็นเว็บไซต์บุ๊กมาร์ก?
JAMstack นั้นยอดเยี่ยมสำหรับการใช้งานระดับมืออาชีพหลายอย่าง แต่แง่มุมที่ฉันโปรดปรานของเทคโนโลยีชุดนี้ก็คืออุปสรรคในการใช้เครื่องมือและโครงการส่วนบุคคลเพียงเล็กน้อย
มีผลิตภัณฑ์ดีๆ มากมายในท้องตลาดสำหรับแอปพลิเคชันส่วนใหญ่ที่ฉันสามารถทำได้ แต่ไม่มีผลิตภัณฑ์ใดที่เหมาะกับฉันอย่างแน่นอน ไม่มีใครให้ฉันควบคุมเนื้อหาของฉันได้อย่างเต็มที่ จะไม่มีใครมาโดยไม่มีค่าใช้จ่าย (ทางการเงินหรือข้อมูล)
ด้วยเหตุนี้ เราจึงสามารถสร้างบริการขนาดเล็กของเราเองโดยใช้วิธี JAMstack ในกรณีนี้ เราจะสร้างไซต์เพื่อจัดเก็บและเผยแพร่บทความที่น่าสนใจที่ฉันพบในการอ่านเทคโนโลยีประจำวันของฉัน
ฉันใช้เวลามากในการอ่านบทความที่แชร์บน Twitter เมื่อฉันชอบฉันกดไอคอน "หัวใจ" จากนั้นภายในสองสามวัน แทบจะเป็นไปไม่ได้เลยที่จะพบกับรายการโปรดใหม่ๆ หลั่งไหลเข้ามา ฉันต้องการสร้างบางสิ่งที่ใกล้เคียงกับความสบายของ "หัวใจ" แต่ฉันเป็นเจ้าของและควบคุม
เราจะทำอย่างนั้นได้อย่างไร? ฉันดีใจที่คุณถาม
สนใจรับรหัสไหม คุณสามารถคว้ามันบน Github หรือเพียงแค่ปรับใช้กับ Netlify โดยตรงจากที่เก็บนั้น! ดูผลิตภัณฑ์สำเร็จรูปที่นี่
เทคโนโลยีของเรา
ฟังก์ชั่นการโฮสต์และไร้เซิร์ฟเวอร์: Netlify
สำหรับฟังก์ชั่นโฮสติ้งและไร้เซิร์ฟเวอร์ เราจะใช้ Netlify ในฐานะที่เป็นโบนัสเพิ่มเติม ด้วยการทำงานร่วมกันใหม่ที่กล่าวมาข้างต้น CLI ของ Netlify — “Netlify Dev” — จะเชื่อมต่อกับ FaunaDB โดยอัตโนมัติและจัดเก็บคีย์ API ของเราเป็นตัวแปรสภาพแวดล้อม
ฐานข้อมูล: FaunaDB
FaunaDB เป็นฐานข้อมูล NoSQL "ไร้เซิร์ฟเวอร์" เราจะใช้มันเพื่อเก็บข้อมูลบุ๊กมาร์กของเรา
ตัวสร้างไซต์แบบคงที่: 11ty
ฉันเชื่อใน HTML มาก ด้วยเหตุนี้ บทช่วยสอนจะไม่ใช้ JavaScript ส่วนหน้าเพื่อแสดงบุ๊กมาร์กของเรา เราจะใช้ 11ty เป็นเครื่องมือสร้างไซต์แบบคงที่แทน 11ty มีฟังก์ชันข้อมูลในตัวที่ทำให้ดึงข้อมูลจาก API ได้ง่ายเหมือนกับการเขียนฟังก์ชัน JavaScript สั้นๆ สองสามอย่าง
ทางลัด iOS
เราต้องการวิธีง่ายๆ ในการโพสต์ข้อมูลไปยังฐานข้อมูลของเรา ในกรณีนี้ เราจะใช้แอปคำสั่งลัดของ iOS สามารถแปลงเป็น bookmarklet JavaScript ของ Android หรือเดสก์ท็อปได้เช่นกัน
การตั้งค่า FaunaDB ผ่าน Netlify Dev
ไม่ว่าคุณจะสมัคร FaunaDB แล้วหรือต้องการสร้างบัญชีใหม่ วิธีที่ง่ายที่สุดในการตั้งค่าลิงก์ระหว่าง FaunaDB และ Netlify คือผ่าน CLI ของ Netlify: Netlify Dev คุณสามารถค้นหาคำแนะนำแบบเต็มจาก FaunaDB ได้ที่นี่ หรือปฏิบัติตามด้านล่าง
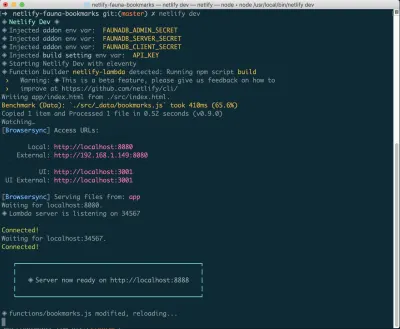
หากคุณยังไม่ได้ติดตั้งสิ่งนี้ คุณสามารถเรียกใช้คำสั่งต่อไปนี้ใน Terminal:
npm install netlify-cli -gจากภายในไดเร็กทอรีโครงการของคุณ รันคำสั่งต่อไปนี้:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account เมื่อเชื่อมต่อทั้งหมดนี้แล้ว คุณสามารถเรียกใช้ netlify dev ในโครงการของคุณได้ สิ่งนี้จะเรียกใช้สคริปต์บิลด์ที่เราตั้งค่าไว้ แต่ยังเชื่อมต่อกับบริการ Netlify และ FaunaDB และดึงตัวแปรสภาพแวดล้อมที่จำเป็น มีประโยชน์!
การสร้างข้อมูลแรกของเรา
จากที่นี่ เราจะเข้าสู่ระบบ FaunaDB และสร้างชุดข้อมูลชุดแรกของเรา เราจะเริ่มต้นด้วยการสร้างฐานข้อมูลใหม่ที่เรียกว่า “บุ๊กมาร์ก” ภายในฐานข้อมูล เรามีคอลเลกชัน เอกสาร และดัชนี
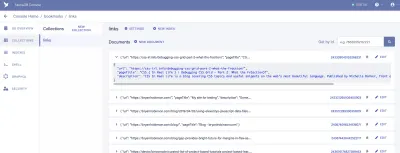
คอลเล็กชันคือกลุ่มข้อมูลที่ถูกจัดหมวดหมู่ ข้อมูลแต่ละส่วนจะอยู่ในรูปแบบของเอกสาร เอกสารเป็น "บันทึกเดียวที่เปลี่ยนแปลงได้ภายในฐานข้อมูล FaunaDB" ตามเอกสารของ Fauna คุณสามารถคิดว่าคอลเลคชันเป็นตารางฐานข้อมูลแบบดั้งเดิมและเอกสารเป็นแถวได้
สำหรับแอปพลิเคชันของเรา เราต้องการหนึ่งคอลเล็กชัน ซึ่งเราจะเรียกว่า “ลิงก์” เอกสารแต่ละฉบับภายในคอลเล็กชัน "ลิงก์" จะเป็นออบเจ็กต์ JSON แบบง่ายพร้อมคุณสมบัติสามประการ ในการเริ่มต้น เราจะเพิ่มเอกสารใหม่ที่เราจะใช้สร้างการดึงข้อมูลครั้งแรกของเรา
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }ซึ่งเป็นการสร้างพื้นฐานสำหรับข้อมูลที่เราจำเป็นต้องดึงจากบุ๊กมาร์ก รวมทั้งให้ข้อมูลชุดแรกเพื่อดึงเข้าสู่เทมเพลตของเรา
ถ้าคุณเป็นเหมือนฉัน คุณอยากเห็นผลงานของคุณทันที มาเอาของลงเพจกันเถอะ!
ติดตั้ง 11ty และดึงข้อมูลลงในเทมเพลต
เนื่องจากเราต้องการให้บุ๊กมาร์กแสดงผลในรูปแบบ HTML และไม่ถูกดึงข้อมูลโดยเบราว์เซอร์ เราจึงต้องดำเนินการบางอย่างในการแสดงผล มีวิธีที่ยอดเยี่ยมมากมายในการทำสิ่งนี้ แต่เพื่อความสะดวกและประสิทธิภาพ ฉันชอบใช้ตัวสร้างไซต์สแตติก 11ty
เนื่องจาก 11ty เป็นตัวสร้างไซต์แบบสแตติก JavaScript เราจึงสามารถติดตั้งผ่าน NPM ได้
npm install --save @11ty/eleventy จากการติดตั้งนั้น เราสามารถเรียกใช้ eleventy หรือ eleventy --serve ในโครงการของเราเพื่อเริ่มต้นใช้งาน
Netlify Dev มักจะตรวจพบ 11ty เป็นข้อกำหนดและเรียกใช้คำสั่งสำหรับเรา เพื่อให้ได้งานนี้ และต้องแน่ใจว่าเราพร้อมที่จะปรับใช้ เรายังสามารถสร้างคำสั่ง “serve” และ “build” ใน package.json ของเรา
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }ไฟล์ข้อมูลของ 11ty
ตัวสร้างไซต์แบบคงที่ส่วนใหญ่มีแนวคิดเกี่ยวกับ "ไฟล์ข้อมูล" ในตัว โดยปกติ ไฟล์เหล่านี้จะเป็นไฟล์ JSON หรือ YAML ที่ให้คุณเพิ่มข้อมูลเพิ่มเติมในเว็บไซต์ของคุณ
ใน 11ty คุณสามารถใช้ไฟล์ข้อมูล JSON หรือไฟล์ข้อมูล JavaScript การใช้ไฟล์ JavaScript ทำให้เราสามารถเรียก API ของเราและส่งคืนข้อมูลไปยังเทมเพลตได้โดยตรง
โดยค่าเริ่มต้น 11ty ต้องการไฟล์ข้อมูลที่เก็บไว้ในไดเร็กทอรี _data จากนั้นคุณสามารถเข้าถึงข้อมูลได้โดยใช้ชื่อไฟล์เป็นตัวแปรในเทมเพลตของคุณ ในกรณีของเรา เราจะสร้างไฟล์ที่ _data/bookmarks.js และเข้าถึงได้โดยใช้ชื่อตัวแปร {{ bookmarks }}
หากคุณต้องการเจาะลึกลงไปในการกำหนดค่าไฟล์ข้อมูล คุณสามารถอ่านตัวอย่างในเอกสารประกอบ 11ty หรือดูบทแนะนำเกี่ยวกับการใช้ไฟล์ข้อมูล 11ty กับ Meetup API
ไฟล์จะเป็นโมดูล JavaScript ดังนั้นเพื่อให้ทำงานได้ เราต้องส่งออกข้อมูลหรือฟังก์ชันของเรา ในกรณีของเรา เราจะส่งออกฟังก์ชัน
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } มาทำลายมันกันเถอะ เรามีสองฟังก์ชันที่ทำงานหลักที่นี่: mapBookmarks() และ getBookmarks()
getBookmarks() จะดึงข้อมูลของเราจากฐานข้อมูล FaunaDB และ mapBookmarks() จะนำบุ๊กมาร์กมาจัดเรียงใหม่และจัดโครงสร้างใหม่เพื่อให้ทำงานได้ดีขึ้นสำหรับเทมเพลตของเรา
มาขุดลึกลงไปใน getBookmarks()
getBookmarks()
ขั้นแรก เราจะต้องติดตั้งและเริ่มต้นอินสแตนซ์ของไดรเวอร์ FaunaDB JavaScript
npm install --save faunadbตอนนี้เราได้ติดตั้งแล้ว มาเพิ่มที่ด้านบนสุดของไฟล์ข้อมูลของเรากัน รหัสนี้ส่งตรงจากเอกสารของ Fauna
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); หลังจากนั้น เราสามารถสร้างฟังก์ชันของเราได้ เราจะเริ่มต้นด้วยการสร้างแบบสอบถามแรกของเราโดยใช้วิธีการที่มีอยู่แล้วในไดรเวอร์ โค้ดบิตแรกนี้จะส่งคืนการอ้างอิงฐานข้อมูลที่เราสามารถใช้เพื่อรับข้อมูลทั้งหมดสำหรับลิงก์ที่คั่นหน้าทั้งหมดของเรา เราใช้วิธีการแบ่งหน้า เป็นตัวช่วยในการจัดการสถานะเคอร์เซอร์ หากเราตัดสินใจแบ่งหน้าข้อมูลก่อนที่จะมอบให้ Paginate ในกรณีของเรา เราจะส่งคืนข้อมูลอ้างอิงทั้งหมด
ในตัวอย่างนี้ ฉันคิดว่าคุณติดตั้งและเชื่อมต่อ FaunaDB ผ่าน Netlify Dev CLI เมื่อใช้กระบวนการนี้ คุณจะได้รับตัวแปรสภาพแวดล้อมภายในเครื่องของความลับของ FaunaDB หากคุณไม่ได้ติดตั้งด้วยวิธีนี้หรือไม่ได้ใช้งาน netlify dev ในโครงการของคุณ คุณจะต้องมีแพ็คเกจอย่าง dotenv เพื่อสร้างตัวแปรสภาพแวดล้อม คุณจะต้องเพิ่มตัวแปรสภาพแวดล้อมของคุณไปยังการกำหนดค่าไซต์ Netlify เพื่อให้การปรับใช้ทำงานในภายหลัง
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })รหัสนี้จะส่งคืนอาร์เรย์ของลิงก์ทั้งหมดของเราในรูปแบบอ้างอิง ตอนนี้ เราสามารถสร้างรายการแบบสอบถามเพื่อส่งไปยังฐานข้อมูลของเราได้แล้ว
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) จากที่นี่ เราเพียงแค่ต้องล้างข้อมูลที่ส่งคืน นั่นคือที่มาของ mapBookmarks() !
mapBookmarks()
ในฟังก์ชันนี้ เราจัดการกับข้อมูลสองด้าน
อันดับแรก เราได้รับ dateTime ฟรีใน FaunaDB สำหรับข้อมูลที่สร้างขึ้น จะมีคุณสมบัติการประทับเวลา ( ts ) ไม่ได้จัดรูปแบบในลักษณะที่ทำให้ตัวกรองวันที่เริ่มต้นของ Liquid มีความสุข เรามาแก้ไขกัน
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } ด้วยวิธีนี้ เราสามารถสร้างวัตถุใหม่สำหรับข้อมูลของเราได้ ในกรณีนี้ มันจะมีคุณสมบัติของ time และเราจะใช้ตัวดำเนินการ Spread เพื่อทำลายโครงสร้าง data ของเราเพื่อให้พวกมันใช้งานได้ในระดับเดียว
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }นี่คือข้อมูลของเราก่อนหน้าที่ของเรา:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }นี่คือข้อมูลของเราหลังจากฟังก์ชันของเรา:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }ตอนนี้ เรามีข้อมูลที่จัดรูปแบบอย่างดีที่พร้อมสำหรับเทมเพลตของเราแล้ว!
มาเขียนเทมเพลตง่ายๆ กัน เราจะวนดูบุ๊กมาร์กและตรวจสอบว่าแต่ละรายการมีชื่อ pageTitle และ url เพื่อไม่ให้ดูงี่เง่า
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>ขณะนี้เรากำลังนำเข้าและแสดงข้อมูลจาก FaunaDB ลองใช้เวลาสักครู่แล้วลองคิดดูว่ามันดีแค่ไหนที่มันแสดงผล HTML ล้วนๆ และไม่จำเป็นต้องดึงข้อมูลในฝั่งไคลเอ็นต์!
แต่นั่นยังไม่เพียงพอที่จะทำให้แอปนี้เป็นแอปที่มีประโยชน์สำหรับเรา มาหาวิธีที่ดีกว่าการเพิ่มบุ๊กมาร์กในคอนโซล FaunaDB
ป้อนฟังก์ชัน Netlify
โปรแกรมเสริมฟังก์ชันของ Netlify เป็นหนึ่งในวิธีที่ง่ายกว่าในการปรับใช้ฟังก์ชันแลมบ์ดาของ AWS เนื่องจากไม่มีขั้นตอนการกำหนดค่า จึงเหมาะอย่างยิ่งสำหรับโครงการ DIY ที่คุณต้องการเพียงแค่เขียนโค้ด
ฟังก์ชันนี้จะอยู่ที่ URL ในโครงการของคุณซึ่งมีลักษณะดังนี้: https://myproject.com/.netlify/functions/bookmarks สมมติว่าไฟล์ที่เราสร้างในโฟลเดอร์ฟังก์ชันของเราคือ bookmarks.js
การไหลขั้นพื้นฐาน
- ส่ง URL เป็นพารามิเตอร์การค้นหาไปยัง URL ฟังก์ชันของเรา
- ใช้ฟังก์ชันนี้เพื่อโหลด URL และขูดชื่อและคำอธิบายของหน้า หากมี
- จัดรูปแบบรายละเอียดสำหรับ FaunaDB
- ส่งรายละเอียดไปที่คอลเลกชัน FaunaDB ของเรา
- สร้างไซต์ใหม่
ความต้องการ
เรามีแพ็คเกจสองสามอย่างที่เราจำเป็นต้องใช้ในขณะที่สร้างสิ่งนี้ เราจะใช้ netlify-lambda CLI เพื่อสร้างฟังก์ชันของเราในเครื่อง request-promise เป็นแพ็คเกจที่เราจะใช้สำหรับการร้องขอ Cheerio.js เป็นแพ็คเกจที่เราจะใช้เพื่อขูดรายการเฉพาะจากหน้าที่ร้องขอของเรา (คิดว่า jQuery สำหรับโหนด) และสุดท้าย เราต้องการ FaunaDb (ซึ่งควรติดตั้งไว้แล้ว
npm install --save netlify-lambda request-promise cheerioเมื่อติดตั้งแล้ว ให้กำหนดค่าโปรเจ็กต์ของเราเพื่อสร้างและให้บริการฟังก์ชันในเครื่อง
เราจะแก้ไขสคริปต์ "build" และ "serve" ใน package.json ให้มีลักษณะดังนี้:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } คำเตือน: มีข้อผิดพลาดเกิดขึ้นกับไดรเวอร์ NodeJS ของ Fauna เมื่อทำการคอมไพล์ด้วย Webpack ซึ่งฟังก์ชันของ Netlify ใช้ในการสร้าง เพื่อแก้ไขปัญหานี้ เราต้องกำหนดไฟล์การกำหนดค่าสำหรับ Webpack คุณสามารถบันทึกรหัสต่อไปนี้เป็น webpack.config.js ใหม่ หรือที่มีอยู่
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; เมื่อไฟล์นี้มีอยู่แล้ว เมื่อเราใช้คำสั่ง netlify-lambda เราจะต้องบอกให้เรียกใช้จากการกำหนดค่านี้ นี่คือเหตุผลที่สคริปต์ "ให้บริการ" และ "สร้างของเราใช้ค่า --config สำหรับคำสั่งนั้น
ฟังก์ชั่นการดูแลทำความสะอาด
เพื่อให้ไฟล์ Function หลักของเราสะอาดอยู่เสมอ เราจะสร้างฟังก์ชันของเราในไดเร็กทอรี bookmarks แยกต่างหาก และนำเข้ามาไว้ในไฟล์ Function หลักของเรา
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails() จะใช้ URL ที่ส่งผ่านจากตัวจัดการที่ส่งออกของเรา จากที่นั่น เราจะเข้าถึงไซต์ที่ URL นั้นและคว้าส่วนที่เกี่ยวข้องของหน้าเพื่อจัดเก็บเป็นข้อมูลสำหรับบุ๊กมาร์กของเรา
เราเริ่มต้นด้วยการกำหนดแพ็คเกจ NPM ที่เราต้องการ:
const rp = require('request-promise'); const cheerio = require('cheerio'); จากนั้น เราจะใช้โมดูล request-promise เพื่อส่งคืนสตริง HTML สำหรับหน้าที่ร้องขอและส่งผ่านไปยัง cheerio เพื่อให้อินเทอร์เฟซ jQuery-esque แก่เรา
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }จากที่นี่ เราจำเป็นต้องได้รับชื่อหน้าและคำอธิบายเมตา ในการทำเช่นนั้น เราจะใช้ตัวเลือกเช่นเดียวกับที่คุณทำใน jQuery
หมายเหตุ: ในโค้ดนี้ เราใช้ 'head > title' เป็นตัวเลือกเพื่อรับชื่อของเพจ ถ้าคุณไม่ระบุสิ่งนี้ คุณอาจได้รับ แท็ก <title> ภายใน SVG ทั้งหมดบนหน้า ซึ่งน้อยกว่าอุดมคติ
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }เมื่อมีข้อมูลในมือ ก็ถึงเวลาส่งบุ๊คมาร์คของเราไปที่คอลเล็กชันของเราใน FaunaDB!
saveBookmark(details)
สำหรับฟังก์ชันบันทึก เราต้องการส่งรายละเอียดที่เราได้รับจาก getDetails รวมถึง URL เป็นวัตถุเอกพจน์ ผู้ดำเนินการสเปรดนัดหยุดงานอีกครั้ง!
const savedResponse = await saveBookmark({url, ...details}); ในไฟล์ create.js ของเรา เราจำเป็นต้องกำหนดและตั้งค่าไดรเวอร์ FaunaDB ของเราด้วย สิ่งนี้ควรดูคุ้นเคยมากจากไฟล์ข้อมูล 11ty ของเรา
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });เมื่อเราจัดการได้แล้ว เราก็สามารถเข้ารหัสได้
อันดับแรก เราต้องจัดรูปแบบรายละเอียดของเราให้เป็นโครงสร้างข้อมูลที่ Fauna คาดหวังสำหรับข้อความค้นหาของเรา Fauna คาดหวังวัตถุที่มีคุณสมบัติข้อมูลที่มีข้อมูลที่เราต้องการจัดเก็บ
const saveBookmark = async function(details) { const data = { data: details }; ... }จากนั้นเราจะเปิดข้อความค้นหาใหม่เพื่อเพิ่มลงในคอลเล็กชันของเรา ในกรณีนี้ เราจะใช้ตัวช่วยค้นหาของเราและใช้วิธีสร้าง Create() รับสองอาร์กิวเมนต์ อย่างแรกคือคอลเลกชั่นที่เราต้องการจัดเก็บข้อมูลของเรา และอย่างที่สองคือตัวข้อมูลเอง
หลังจากที่เราบันทึก เราจะคืนความสำเร็จหรือความล้มเหลวให้กับตัวจัดการของเรา
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }มาดูไฟล์ Function แบบเต็มกัน
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
สายตาที่เฉียบแหลมจะสังเกตเห็นว่าเรามีอีกหนึ่งฟังก์ชันที่นำเข้ามาสู่ตัวจัดการของเรา: rebuildSite() ฟังก์ชันนี้จะใช้ฟังก์ชัน Deploy Hook ของ Netlify เพื่อสร้างไซต์ของเราใหม่จากข้อมูลใหม่ทุกครั้งที่เราส่งบันทึกบุ๊คมาร์คใหม่ที่ประสบความสำเร็จ — สำเร็จ
ในการตั้งค่าไซต์ของคุณใน Netlify คุณสามารถเข้าถึงการตั้งค่า Build & Deploy และสร้าง "Build Hook" ใหม่ได้ Hooks มีชื่อที่ปรากฏในส่วน Deploy และมีตัวเลือกสำหรับสาขาที่ไม่ใช่มาสเตอร์ในการปรับใช้หากคุณต้องการ ในกรณีของเรา เราจะตั้งชื่อว่า "new_link" และปรับใช้สาขาหลักของเรา
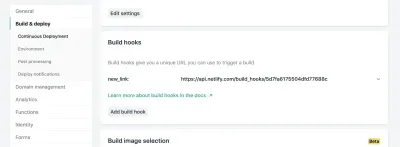
จากนั้น เราเพียงแค่ส่งคำขอ POST ไปยัง URL ที่ให้ไว้
เราต้องการวิธีการส่งคำขอ และเนื่องจากเราได้ติดตั้ง request-promise แล้ว เราจะใช้แพ็คเกจนั้นต่อไปโดยกำหนดให้อยู่ที่ด้านบนสุดของไฟล์
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } การตั้งค่าทางลัด iOS
ดังนั้น เรามีฐานข้อมูล วิธีแสดงข้อมูลและฟังก์ชันในการเพิ่มข้อมูล แต่เรายังไม่เป็นมิตรกับผู้ใช้มากนัก
Netlify มี URL สำหรับฟังก์ชัน Lambda ของเรา แต่การพิมพ์ลงในอุปกรณ์เคลื่อนที่ไม่ใช่เรื่องสนุก เรายังต้องส่ง URL เป็นพารามิเตอร์การค้นหาเข้าไปด้วย นั่นเป็นความพยายามอย่างมาก เราจะพยายามให้น้อยที่สุดเท่าที่จะทำได้ได้อย่างไร
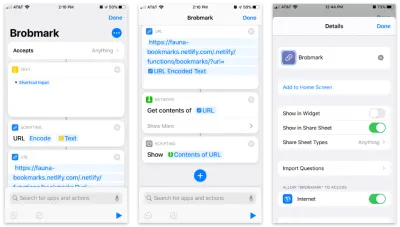
แอปทางลัดของ Apple อนุญาตให้สร้างรายการที่กำหนดเองลงในแผ่นการแชร์ของคุณ ภายในทางลัดเหล่านี้ เราสามารถส่งคำขอข้อมูลประเภทต่างๆ ที่เก็บรวบรวมในกระบวนการแชร์ได้
นี่คือทางลัดทีละขั้นตอน:
- ยอมรับรายการใด ๆ และเก็บรายการนั้นไว้ในบล็อก "ข้อความ"
- ส่งข้อความนั้นไปที่บล็อก "การเขียนสคริปต์" เพื่อเข้ารหัส URL (ในกรณี)
- ส่งสตริงนั้นไปยังบล็อก URL ด้วย URL ของฟังก์ชัน Netlify และพารามิเตอร์การค้นหาของ
url - จาก "เครือข่าย" ใช้บล็อก "รับเนื้อหา" เพื่อโพสต์ไปยัง JSON ไปยัง URL ของเรา
- ไม่บังคับ: จาก "การเขียนสคริปต์" "แสดง" เนื้อหาของขั้นตอนสุดท้าย (เพื่อยืนยันข้อมูลที่เรากำลังส่ง)
ในการเข้าถึงสิ่งนี้จากเมนูการแบ่งปัน เราเปิดการตั้งค่าสำหรับทางลัดนี้และเปิดใช้งานตัวเลือก "แสดงในแผ่นแบ่งปัน"
สำหรับ iOS13 นั้น “การกระทำ” ที่แชร์เหล่านี้สามารถเป็นรายการโปรดและย้ายไปยังตำแหน่งสูงในกล่องโต้ตอบได้
ตอนนี้เรามี "แอพ" ที่ใช้งานได้สำหรับการแบ่งปันบุ๊กมาร์กในหลาย ๆ แพลตฟอร์ม!
มีความพยายาม!
หากคุณได้รับแรงบันดาลใจให้ลองทำด้วยตัวเอง มีความเป็นไปได้อื่นๆ มากมายที่จะเพิ่มฟังก์ชันการทำงาน ความสุขของเว็บ DIY คือคุณสามารถทำให้แอปพลิเคชันประเภทนี้ทำงานให้กับคุณได้ นี่คือแนวคิดบางประการ:
- ใช้ "คีย์ API" ปลอมเพื่อการตรวจสอบสิทธิ์อย่างรวดเร็ว ดังนั้นผู้ใช้รายอื่นจะไม่โพสต์ในไซต์ของคุณ (ของฉันใช้คีย์ API ดังนั้นอย่าพยายามโพสต์ไปที่มัน!)
- เพิ่มฟังก์ชันแท็กเพื่อจัดระเบียบบุ๊คมาร์ค
- เพิ่มฟีด RSS สำหรับเว็บไซต์ของคุณเพื่อให้ผู้อื่นสามารถสมัครรับข้อมูลได้
- ส่งอีเมลสรุปรายสัปดาห์โดยทางโปรแกรมสำหรับลิงก์ที่คุณเพิ่มไว้
จริง ๆ แล้วท้องฟ้ามีขีดจำกัด เริ่มทดลองได้เลย!